 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Benchmarking Generative Latent Variable Models for Speech
Feb 22, 2022
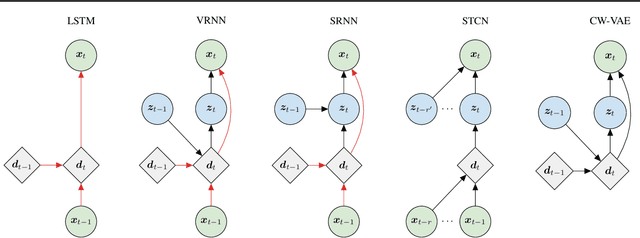
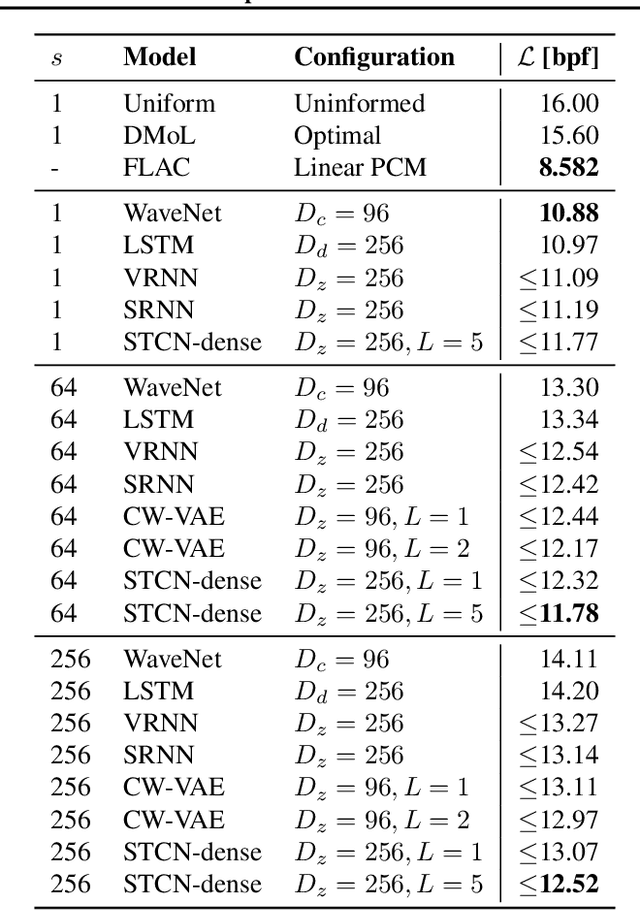
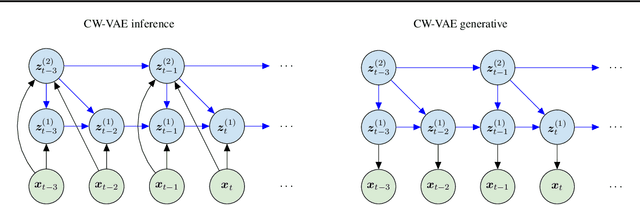
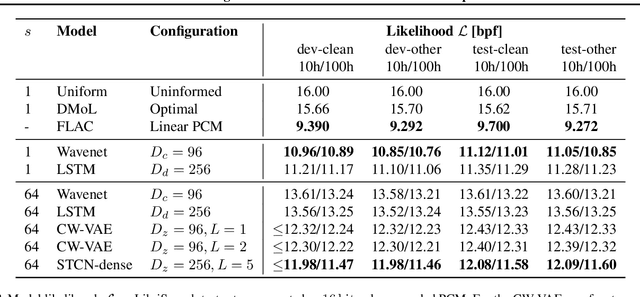
Stochastic latent variable models (LVMs) achieve state-of-the-art performance on natural image generation but are still inferior to deterministic models on speech. In this paper, we develop a speech benchmark of popular temporal LVMs and compare them against state-of-the-art deterministic models. We report the likelihood, which is a much used metric in the image domain, but rarely, and often incomparably, reported for speech models. To assess the quality of the learned representations, we also compare their usefulness for phoneme recognition. Finally, we adapt the Clockwork VAE, a state-of-the-art temporal LVM for video generation, to the speech domain. Despite being autoregressive only in latent space, we find that the Clockwork VAE can outperform previous LVMs and reduce the gap to deterministic models by using a hierarchy of latent variables.
Learning Patch-to-Cluster Attention in Vision Transformer
Mar 22, 2022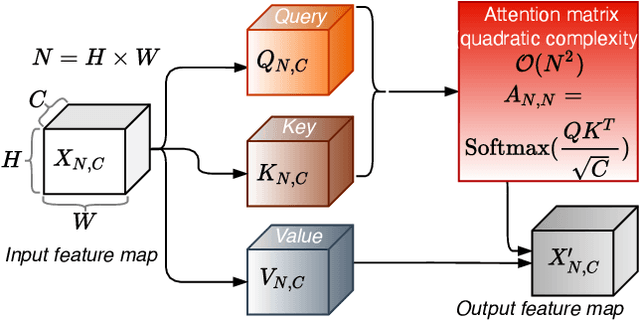
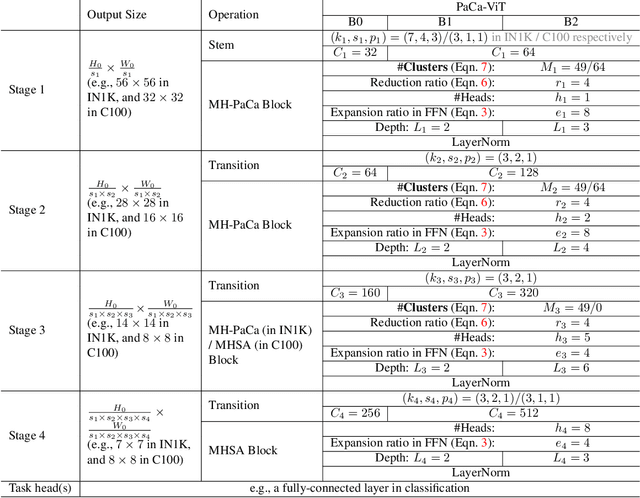
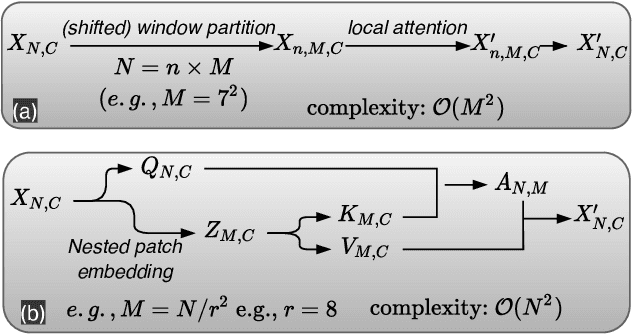
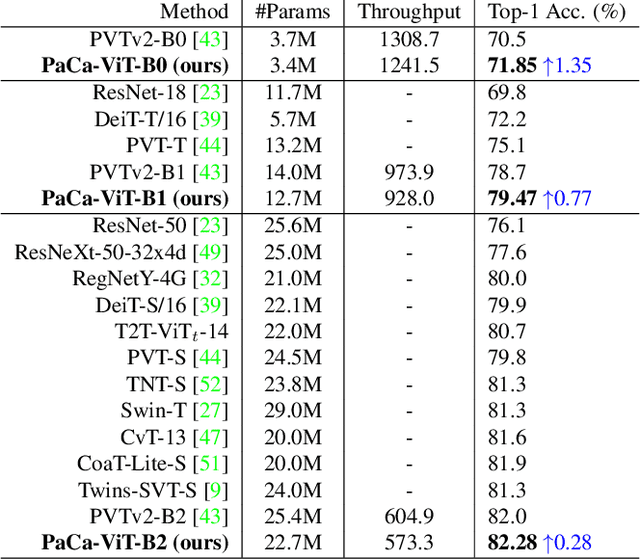
The Vision Transformer (ViT) model is built on the assumption of treating image patches as "visual tokens" and learning patch-to-patch attention. The patch embedding based tokenizer is a workaround in practice and has a semantic gap with respect to its counterpart, the textual tokenizer. The patch-to-patch attention suffers from the quadratic complexity issue, and also makes it non-trivial to explain learned ViT models. To address these issues in ViT models, this paper proposes to learn patch-to-cluster attention (PaCa) based ViT models. Queries in our PaCaViT are based on patches, while keys and values are based on clustering (with a predefined small number of clusters). The clusters are learned end-to-end, leading to better tokenizers and realizing joint clustering-for-attention and attention-for-clustering when deployed in ViT models. The quadratic complexity is relaxed to linear complexity. Also, directly visualizing the learned clusters can reveal how a trained ViT model learns to perform a task (e.g., object detection). In experiments, the proposed PaCa-ViT is tested on CIFAR-100 and ImageNet-1000 image classification, and MS-COCO object detection and instance segmentation. Compared with prior arts, it obtains better performance in classification and comparable performance in detection and segmentation. It is significantly more efficient in COCO due to the linear complexity. The learned clusters are also semantically meaningful and shed light on designing more discriminative yet interpretable ViT models.
Beam-Shape Effects and Noise Removal from THz Time-Domain Images in Reflection Geometry in the 0.25-6 THz Range
Mar 01, 2022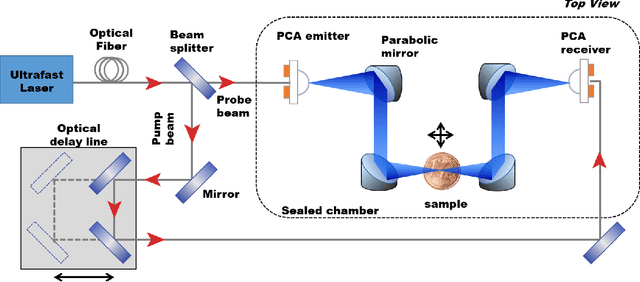


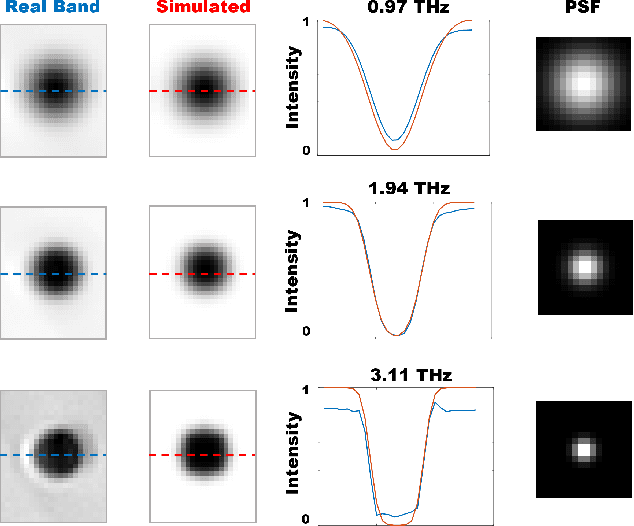
The increasing need of restoring high-resolution Hyper-Spectral (HS) images is determining a growing reliance on Computer Vision-based processing to enhance the clarity of the image content. HS images can, in fact, suffer from degradation effects or artefacts caused by instrument limitations. This paper focuses on a procedure aimed at reducing the degradation effects, frequency-dependent blur and noise, in Terahertz Time-Domain Spectroscopy (THz-TDS) images in reflection geometry. It describes the application of a joint deblurring and denoising approach that had been previously proved to be effective for the restoration of THz-TDS images in transmission geometry, but that had never been tested in reflection modality. This mode is often the only one that can be effectively used in most cases, for example when analyzing objects that are either opaque in the THz range, or that cannot be displaced from their location (e.g., museums), such as those of cultural interest. Compared to transmission mode, reflection geometry introduces, however, further distortion to THz data, neglected in existing literature. In this work, we successfully implement image deblurring and denoising of both uniform-shape samples (a contemporary 1 Euro cent coin and an inlaid pendant) and samples with the uneven reliefs and corrosion products on the surface which make the analysis of the object particularly complex (an ancient Roman silver coin). The study demonstrates the ability of image processing to restore data in the 0.25 - 6 THz range, spanning over more than four octaves, and providing the foundation for future analytical approaches of cultural heritage using the far-infrared spectrum still not sufficiently investigated in literature.
Combating COVID-19 using Generative Adversarial Networks and Artificial Intelligence for Medical Images: A Scoping Review
May 15, 2022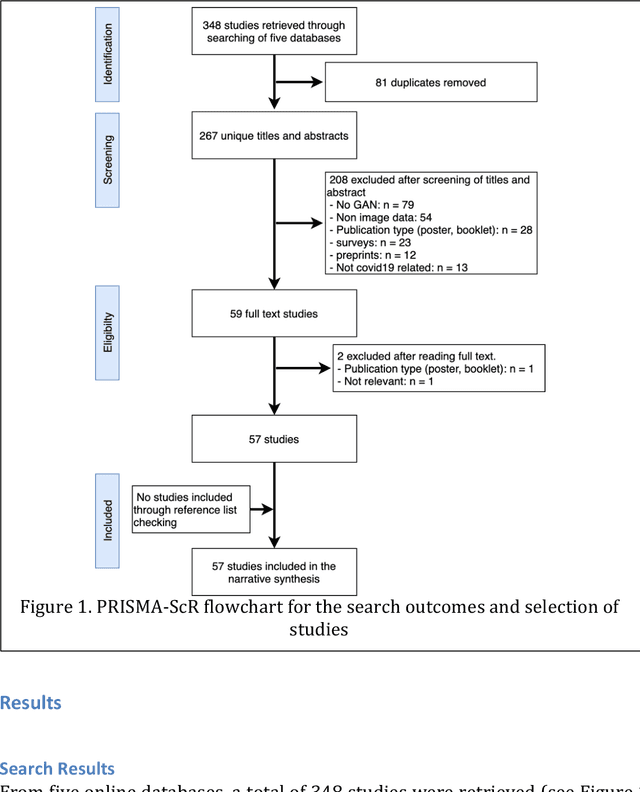
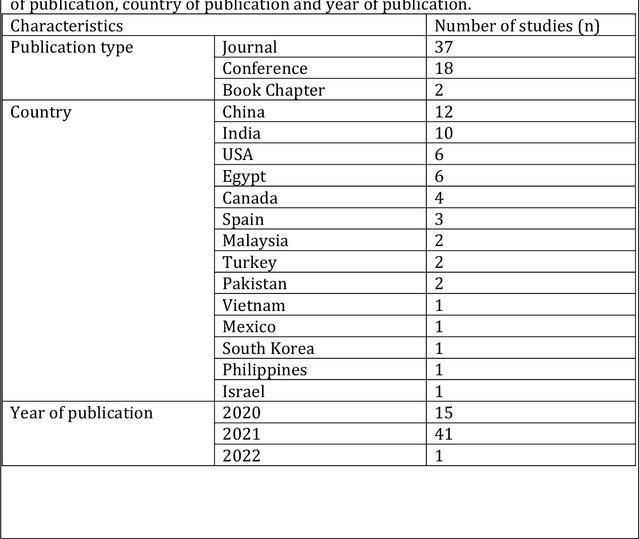
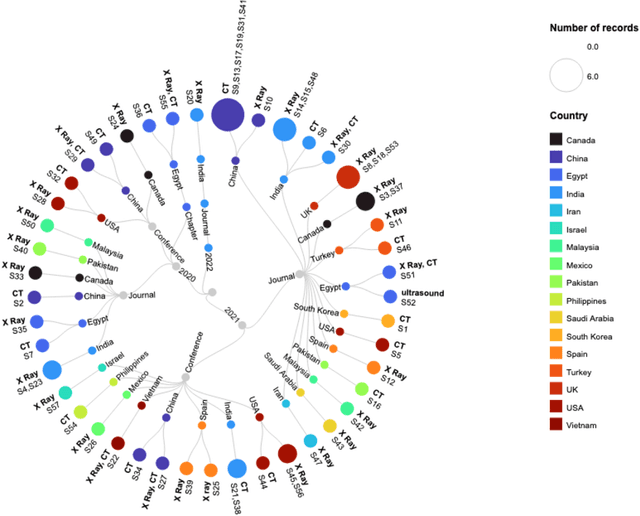
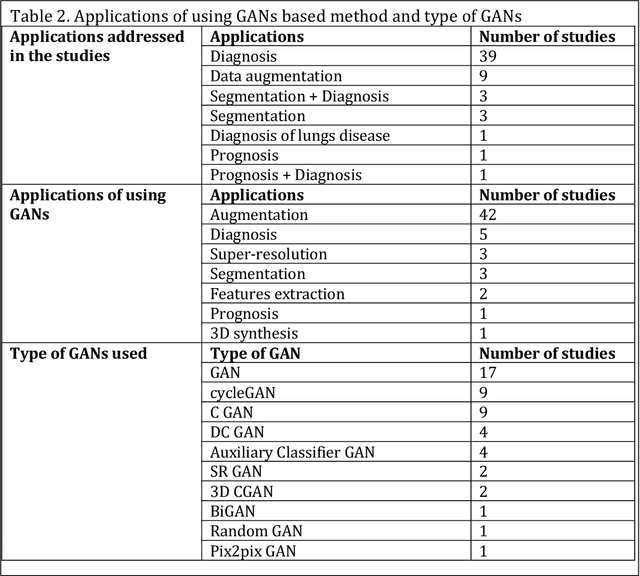
This review presents a comprehensive study on the role of GANs in addressing the challenges related to COVID-19 data scarcity and diagnosis. It is the first review that summarizes the different GANs methods and the lungs images datasets for COVID-19. It attempts to answer the questions related to applications of GANs, popular GAN architectures, frequently used image modalities, and the availability of source code. This review included 57 full-text studies that reported the use of GANs for different applications in COVID-19 lungs images data. Most of the studies (n=42) used GANs for data augmentation to enhance the performance of AI techniques for COVID-19 diagnosis. Other popular applications of GANs were segmentation of lungs and super-resolution of the lungs images. The cycleGAN and the conditional GAN were the most commonly used architectures used in nine studies each. 29 studies used chest X-Ray images while 21 studies used CT images for the training of GANs. For majority of the studies (n=47), the experiments were done and results were reported using publicly available data. A secondary evaluation of the results by radiologists/clinicians was reported by only two studies. Conclusion: Studies have shown that GANs have great potential to address the data scarcity challenge for lungs images of COVID-19. Data synthesized with GANs have been helpful to improve the training of the Convolutional Neural Network (CNN) models trained for the diagnosis of COVID-19. Besides, GANs have also contributed to enhancing the CNNs performance through the super-resolution of the images and segmentation. This review also identified key limitations of the potential transformation of GANs based methods in clinical applications.
Complete identification of complex salt-geometries from inaccurate migrated images using Deep Learning
Apr 22, 2022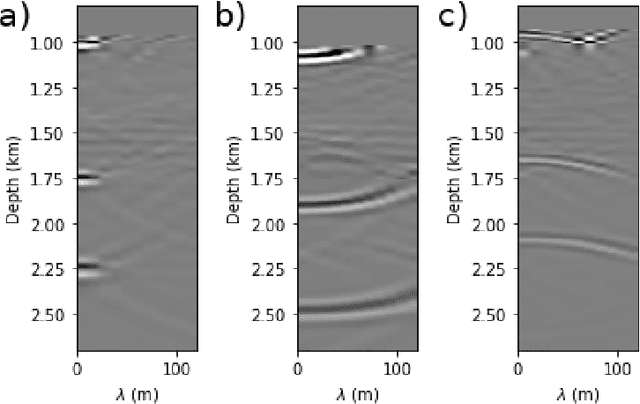
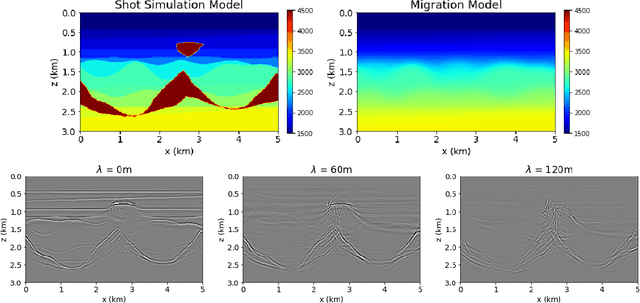
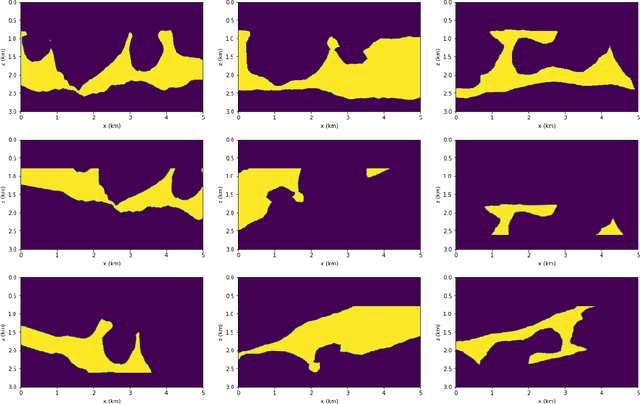
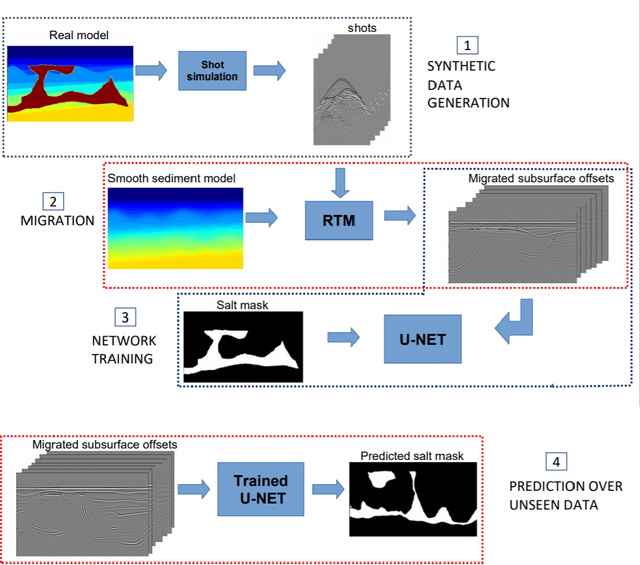
Delimiting salt inclusions from migrated images is a time-consuming activity that relies on highly human-curated analysis and is subject to interpretation errors or limitations of the methods available. We propose to use migrated images produced from an inaccurate velocity model (with a reasonable approximation of sediment velocity, but without salt inclusions) to predict the correct salt inclusions shape using a Convolutional Neural Network (CNN). Our approach relies on subsurface Common Image Gathers to focus the sediments' reflections around the zero offset and to spread the energy of salt reflections over large offsets. Using synthetic data, we trained a U-Net to use common-offset subsurface images as input channels for the CNN and the correct salt-masks as network output. The network learned to predict the salt inclusions masks with high accuracy; moreover, it also performed well when applied to synthetic benchmark data sets that were not previously introduced. Our training process tuned the U-Net to successfully learn the shape of complex salt bodies from partially focused subsurface offset images.
Nonnegative-Constrained Joint Collaborative Representation with Union Dictionary for Hyperspectral Anomaly Detection
Mar 18, 2022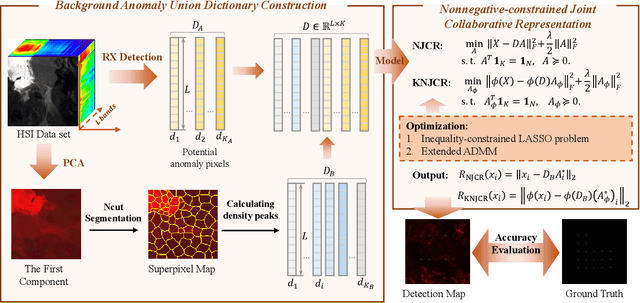
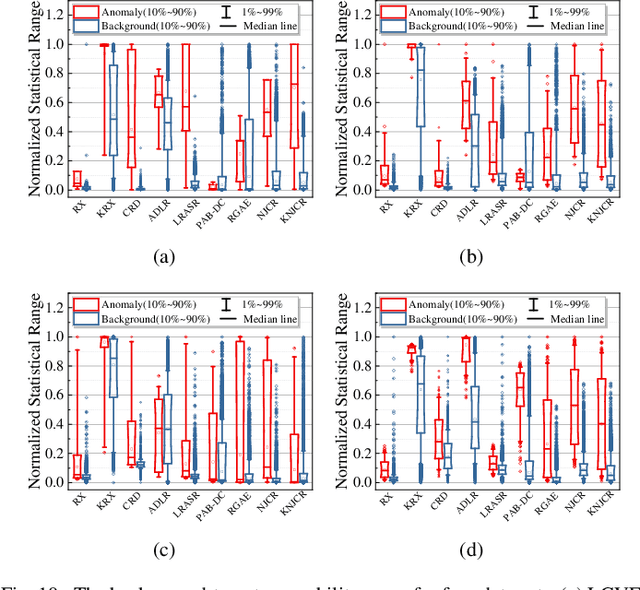
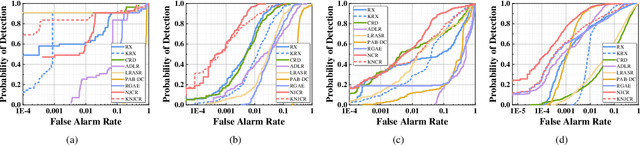
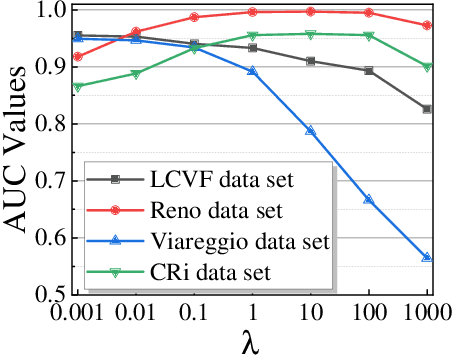
Recently, many collaborative representation-based (CR) algorithms have been proposed for hyperspectral anomaly detection. CR-based detectors approximate the image by a linear combination of background dictionaries and the coefficient matrix, and derive the detection map by utilizing recovery residuals. However, these CR-based detectors are often established on the premise of precise background features and strong image representation, which are very difficult to obtain. In addition, pursuing the coefficient matrix reinforced by the general $l_2$-min is very time consuming. To address these issues, a nonnegative-constrained joint collaborative representation model is proposed in this paper for the hyperspectral anomaly detection task. To extract reliable samples, a union dictionary consisting of background and anomaly sub-dictionaries is designed, where the background sub-dictionary is obtained at the superpixel level and the anomaly sub-dictionary is extracted by the pre-detection process. And the coefficient matrix is jointly optimized by the Frobenius norm regularization with a nonnegative constraint and a sum-to-one constraint. After the optimization process, the abnormal information is finally derived by calculating the residuals that exclude the assumed background information. To conduct comparable experiments, the proposed nonnegative-constrained joint collaborative representation (NJCR) model and its kernel version (KNJCR) are tested in four HSI data sets and achieve superior results compared with other state-of-the-art detectors.
Heterogeneous Ensemble Knowledge Transfer for Training Large Models in Federated Learning
Apr 27, 2022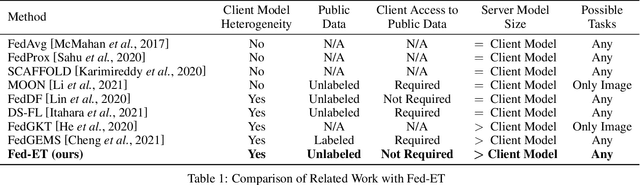
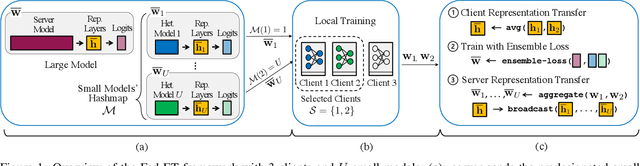
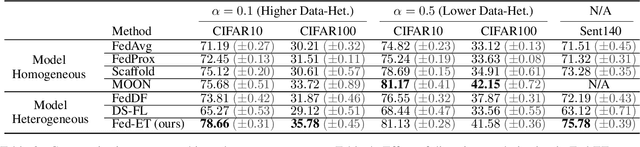
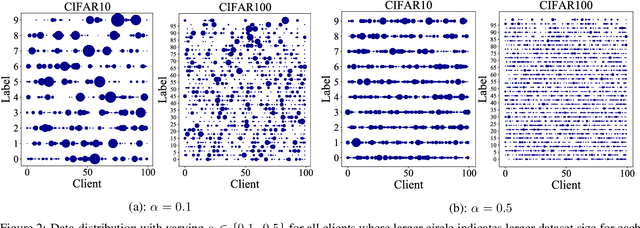
Federated learning (FL) enables edge-devices to collaboratively learn a model without disclosing their private data to a central aggregating server. Most existing FL algorithms require models of identical architecture to be deployed across the clients and server, making it infeasible to train large models due to clients' limited system resources. In this work, we propose a novel ensemble knowledge transfer method named Fed-ET in which small models (different in architecture) are trained on clients, and used to train a larger model at the server. Unlike in conventional ensemble learning, in FL the ensemble can be trained on clients' highly heterogeneous data. Cognizant of this property, Fed-ET uses a weighted consensus distillation scheme with diversity regularization that efficiently extracts reliable consensus from the ensemble while improving generalization by exploiting the diversity within the ensemble. We show the generalization bound for the ensemble of weighted models trained on heterogeneous datasets that supports the intuition of Fed-ET. Our experiments on image and language tasks show that Fed-ET significantly outperforms other state-of-the-art FL algorithms with fewer communicated parameters, and is also robust against high data-heterogeneity.
Robust image stitching with multiple registrations
Nov 23, 2020


Panorama creation is one of the most widely deployed techniques in computer vision. In addition to industry applications such as Google Street View, it is also used by millions of consumers in smartphones and other cameras. Traditionally, the problem is decomposed into three phases: registration, which picks a single transformation of each source image to align it to the other inputs, seam finding, which selects a source image for each pixel in the final result, and blending, which fixes minor visual artifacts. Here, we observe that the use of a single registration often leads to errors, especially in scenes with significant depth variation or object motion. We propose instead the use of multiple registrations, permitting regions of the image at different depths to be captured with greater accuracy. MRF inference techniques naturally extend to seam finding over multiple registrations, and we show here that their energy functions can be readily modified with new terms that discourage duplication and tearing, common problems that are exacerbated by the use of multiple registrations. Our techniques are closely related to layer-based stereo, and move image stitching closer to explicit scene modeling. Experimental evidence demonstrates that our techniques often generate significantly better panoramas when there is substantial motion or parallax.
Improving the Transferability of Adversarial Examples with Restructure Embedded Patches
Apr 27, 2022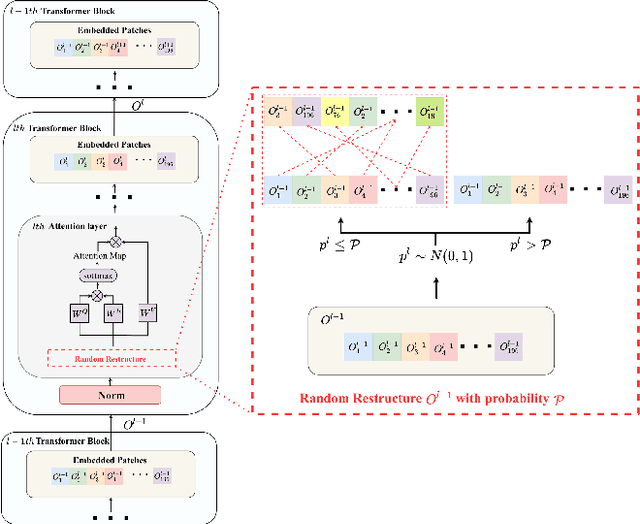
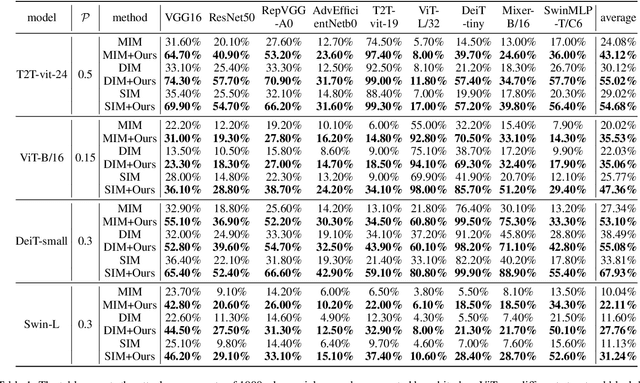

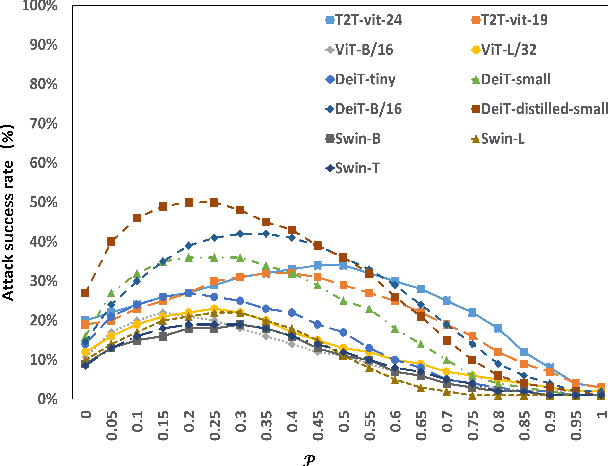
Vision transformers (ViTs) have demonstrated impressive performance in various computer vision tasks. However, the adversarial examples generated by ViTs are challenging to transfer to other networks with different structures. Recent attack methods do not consider the specificity of ViTs architecture and self-attention mechanism, which leads to poor transferability of the generated adversarial samples by ViTs. We attack the unique self-attention mechanism in ViTs by restructuring the embedded patches of the input. The restructured embedded patches enable the self-attention mechanism to obtain more diverse patches connections and help ViTs keep regions of interest on the object. Therefore, we propose an attack method against the unique self-attention mechanism in ViTs, called Self-Attention Patches Restructure (SAPR). Our method is simple to implement yet efficient and applicable to any self-attention based network and gradient transferability-based attack methods. We evaluate attack transferability on black-box models with different structures. The result show that our method generates adversarial examples on white-box ViTs with higher transferability and higher image quality. Our research advances the development of black-box transfer attacks on ViTs and demonstrates the feasibility of using white-box ViTs to attack other black-box models.
Unsupervised Anomaly Detection in Medical Images with a Memory-augmented Multi-level Cross-attentional Masked Autoencoder
Mar 22, 2022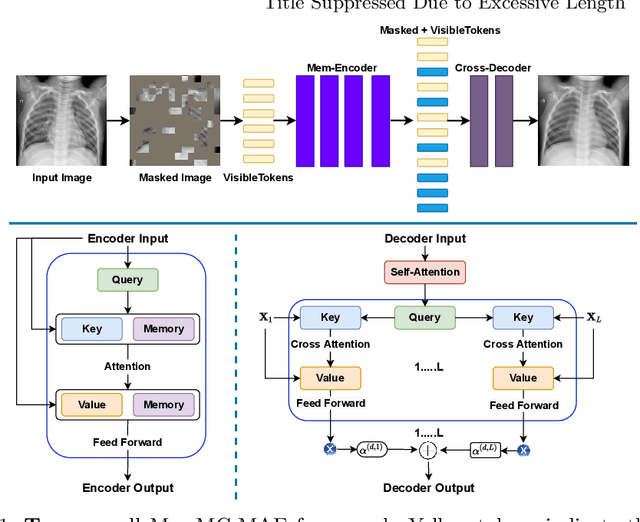



Unsupervised anomaly detection (UAD) aims to find anomalous images by optimising a detector using a training set that contains only normal images. UAD approaches can be based on reconstruction methods, self-supervised approaches, and Imagenet pre-trained models. Reconstruction methods, which detect anomalies from image reconstruction errors, are advantageous because they do not rely on the design of problem-specific pretext tasks needed by self-supervised approaches, and on the unreliable translation of models pre-trained from non-medical datasets. However, reconstruction methods may fail because they can have low reconstruction errors even for anomalous images. In this paper, we introduce a new reconstruction-based UAD approach that addresses this low-reconstruction error issue for anomalous images. Our UAD approach, the memory-augmented multi-level cross-attentional masked autoencoder (MemMC-MAE), is a transformer-based approach, consisting of a novel memory-augmented self-attention operator for the encoder and a new multi-level cross-attention operator for the decoder. MemMC-MAE masks large parts of the input image during its reconstruction, reducing the risk that it will produce low reconstruction errors because anomalies are likely to be masked and cannot be reconstructed. However, when the anomaly is not masked, then the normal patterns stored in the encoder's memory combined with the decoder's multi-level cross-attention will constrain the accurate reconstruction of the anomaly. We show that our method achieves SOTA anomaly detection and localisation on colonoscopy and Covid-19 Chest X-ray datasets.