 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Continual Learning for Blind Image Quality Assessment
Feb 19, 2021
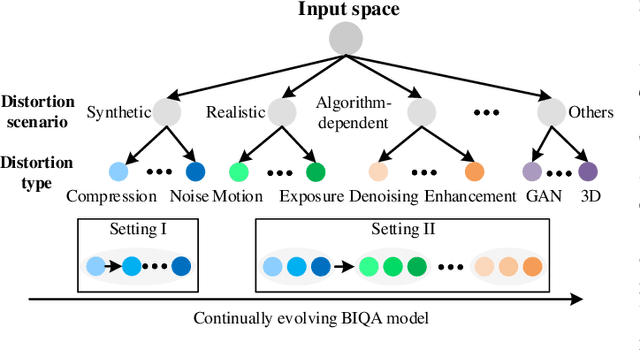


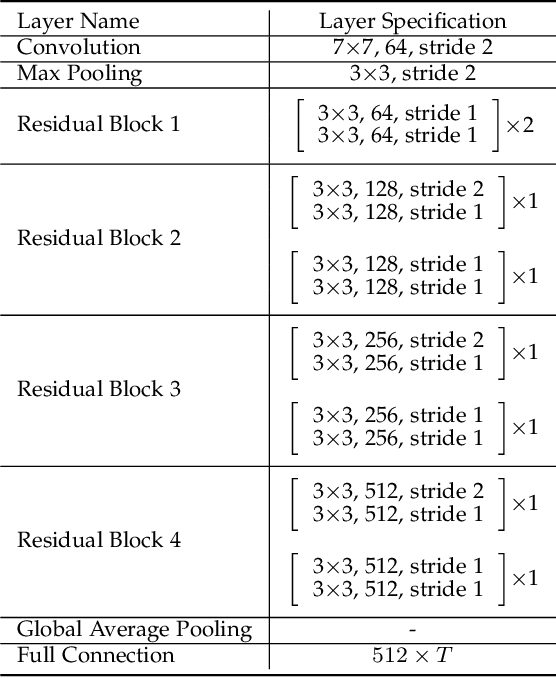
The explosive growth of image data facilitates the fast development of image processing and computer vision methods for emerging visual applications, meanwhile introducing novel distortions to the processed images. This poses a grand challenge to existing blind image quality assessment (BIQA) models, failing to continually adapt to such subpopulation shift. Recent work suggests training BIQA methods on the combination of all available human-rated IQA datasets. However, this type of approach is not scalable to a large number of datasets, and is cumbersome to incorporate a newly created dataset as well. In this paper, we formulate continual learning for BIQA, where a model learns continually from a stream of IQA datasets, building on what was learned from previously seen data. We first identify five desiderata in the new setting with a measure to quantify the plasticity-stability trade-off. We then propose a simple yet effective method for learning BIQA models continually. Specifically, based on a shared backbone network, we add a prediction head for a new dataset, and enforce a regularizer to allow all prediction heads to evolve with new data while being resistant to catastrophic forgetting of old data. We compute the quality score by an adaptive weighted summation of estimates from all prediction heads. Extensive experiments demonstrate the promise of the proposed continual learning method in comparison to standard training techniques for BIQA.
DH-GAN: A Physics-driven Untrained Generative Adversarial Network for 3D Microscopic Imaging using Digital Holography
May 25, 2022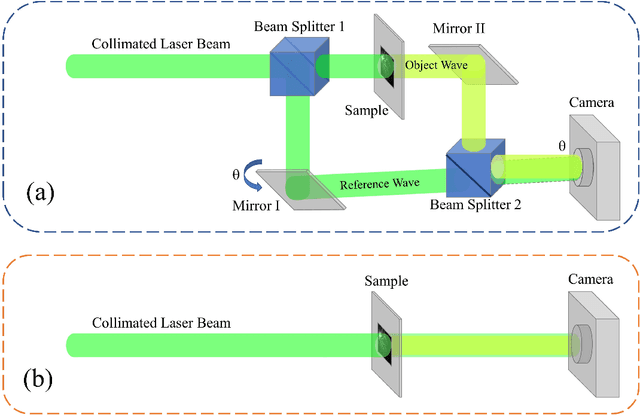

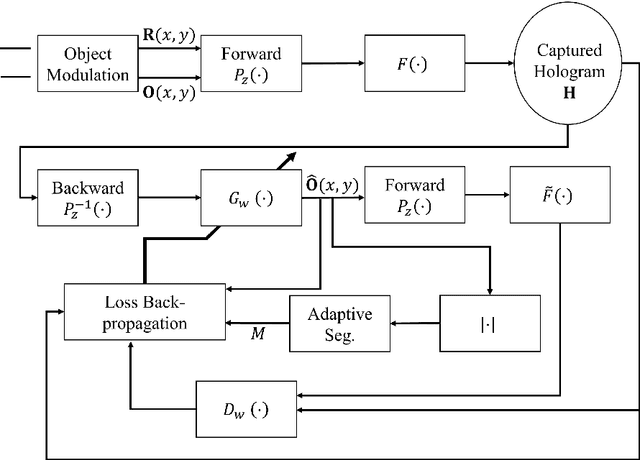

Digital holography is a 3D imaging technique by emitting a laser beam with a plane wavefront to an object and measuring the intensity of the diffracted waveform, called holograms. The object's 3D shape can be obtained by numerical analysis of the captured holograms and recovering the incurred phase. Recently, deep learning (DL) methods have been used for more accurate holographic processing. However, most supervised methods require large datasets to train the model, which is rarely available in most DH applications due to the scarcity of samples or privacy concerns. A few one-shot DL-based recovery methods exist with no reliance on large datasets of paired images. Still, most of these methods often neglect the underlying physics law that governs wave propagation. These methods offer a black-box operation, which is not explainable, generalizable, and transferrable to other samples and applications. In this work, we propose a new DL architecture based on generative adversarial networks that uses a discriminative network for realizing a semantic measure for reconstruction quality while using a generative network as a function approximator to model the inverse of hologram formation. We impose smoothness on the background part of the recovered image using a progressive masking module powered by simulated annealing to enhance the reconstruction quality. The proposed method is one of its kind that exhibits high transferability to similar samples, which facilitates its fast deployment in time-sensitive applications without the need for retraining the network. The results show a considerable improvement to competitor methods in reconstruction quality (about 5 dB PSNR gain) and robustness to noise (about 50% reduction in PSNR vs noise increase rate).
Hybrid Routing Transformer for Zero-Shot Learning
Mar 29, 2022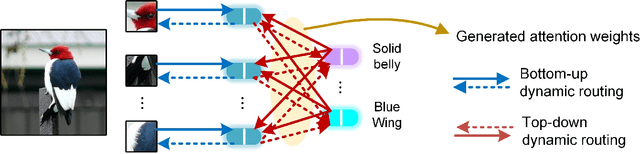
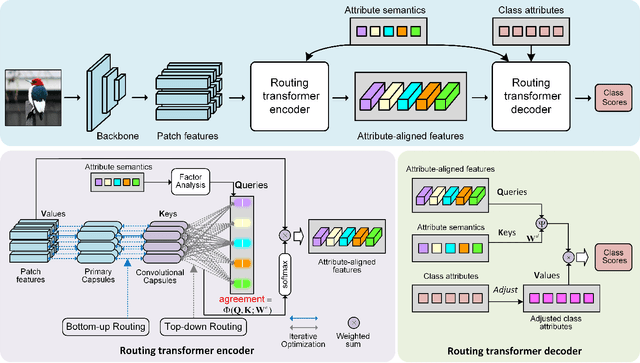
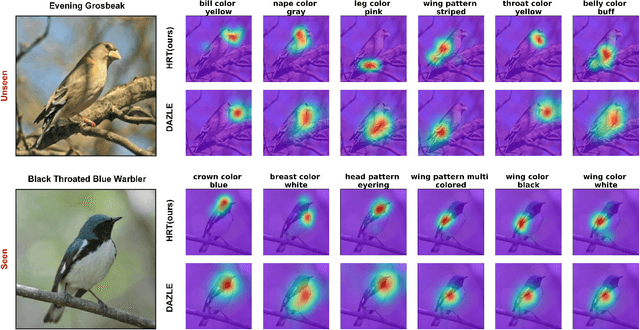
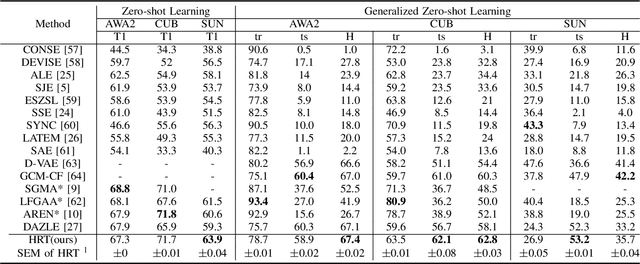
Zero-shot learning (ZSL) aims to learn models that can recognize unseen image semantics based on the training of data with seen semantics. Recent studies either leverage the global image features or mine discriminative local patch features to associate the extracted visual features to the semantic attributes. However, due to the lack of the necessary top-down guidance and semantic alignment for ensuring the model attending to the real attribute-correlation regions, these methods still encounter a significant semantic gap between the visual modality and the attribute modality, which makes their prediction on unseen semantics unreliable. To solve this problem, this paper establishes a novel transformer encoder-decoder model, called hybrid routing transformer (HRT). In HRT encoder, we embed an active attention, which is constructed by both the bottom-up and the top-down dynamic routing pathways to generate the attribute-aligned visual feature. While in HRT decoder, we use static routing to calculate the correlation among the attribute-aligned visual features, the corresponding attribute semantics, and the class attribute vectors to generate the final class label predictions. This design makes the presented transformer model a hybrid of 1) top-down and bottom-up attention pathways and 2) dynamic and static routing pathways. Comprehensive experiments on three widely-used benchmark datasets, namely CUB, SUN, and AWA2, are conducted. The obtained experimental results demonstrate the effectiveness of the proposed method.
Playable Environments: Video Manipulation in Space and Time
Mar 15, 2022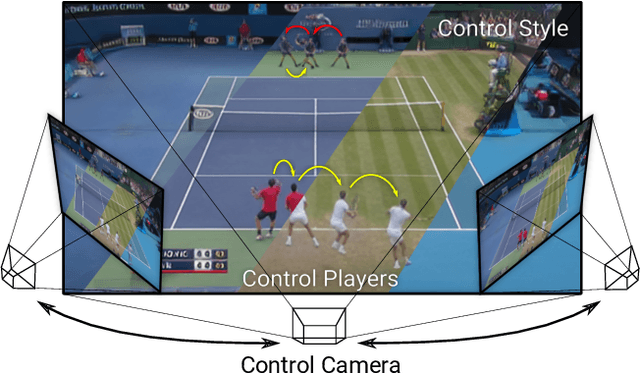

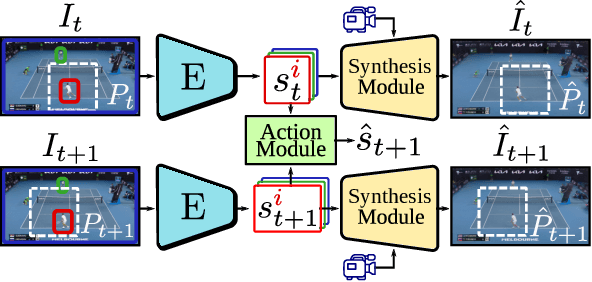
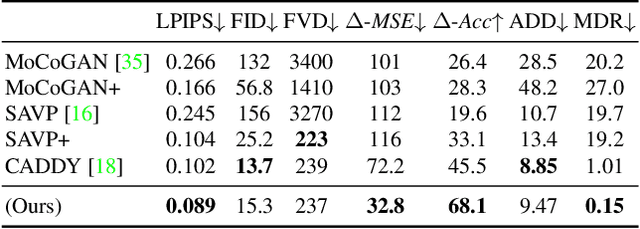
We present Playable Environments - a new representation for interactive video generation and manipulation in space and time. With a single image at inference time, our novel framework allows the user to move objects in 3D while generating a video by providing a sequence of desired actions. The actions are learnt in an unsupervised manner. The camera can be controlled to get the desired viewpoint. Our method builds an environment state for each frame, which can be manipulated by our proposed action module and decoded back to the image space with volumetric rendering. To support diverse appearances of objects, we extend neural radiance fields with style-based modulation. Our method trains on a collection of various monocular videos requiring only the estimated camera parameters and 2D object locations. To set a challenging benchmark, we introduce two large scale video datasets with significant camera movements. As evidenced by our experiments, playable environments enable several creative applications not attainable by prior video synthesis works, including playable 3D video generation, stylization and manipulation. Further details, code and examples are available at https://willi-menapace.github.io/playable-environments-website
On hallucinations in tomographic image reconstruction
Dec 01, 2020
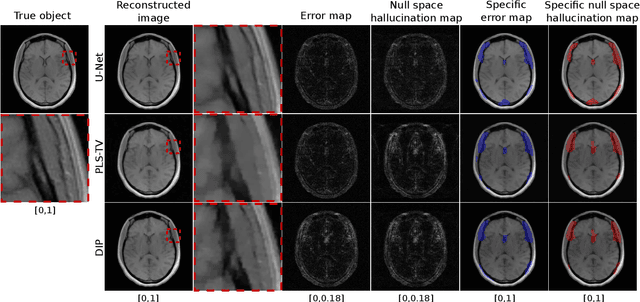
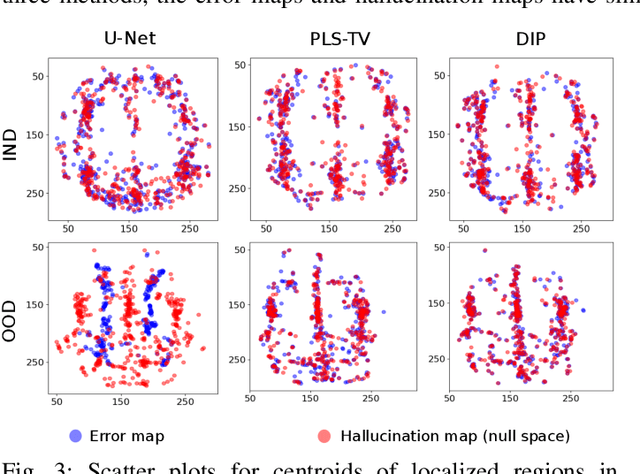
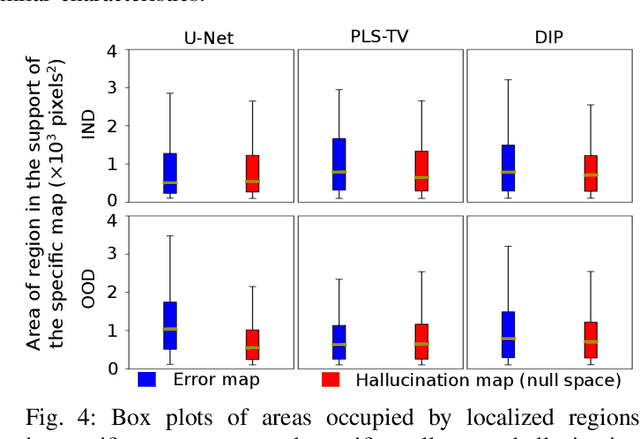
Tomographic image reconstruction is generally an ill-posed linear inverse problem. Such ill-posed inverse problems are typically regularized using prior knowledge of the sought-after object property. Recently, deep neural networks have been actively investigated for regularizing image reconstruction problems by learning a prior for the object properties from training images. However, an analysis of the prior information learned by these deep networks and their ability to generalize to data that may lie outside the training distribution is still being explored. An inaccurate prior might lead to false structures being hallucinated in the reconstructed image and that is a cause for serious concern in medical imaging. In this work, we propose to illustrate the effect of the prior imposed by a reconstruction method by decomposing the image estimate into generalized measurement and null components. The concept of a hallucination map is introduced for the general purpose of understanding the effect of the prior in regularized reconstruction methods. Numerical studies are conducted corresponding to a stylized tomographic imaging modality. The behavior of different reconstruction methods under the proposed formalism is discussed with the help of the numerical studies.
Deep Image Retrieval: A Survey
Feb 03, 2021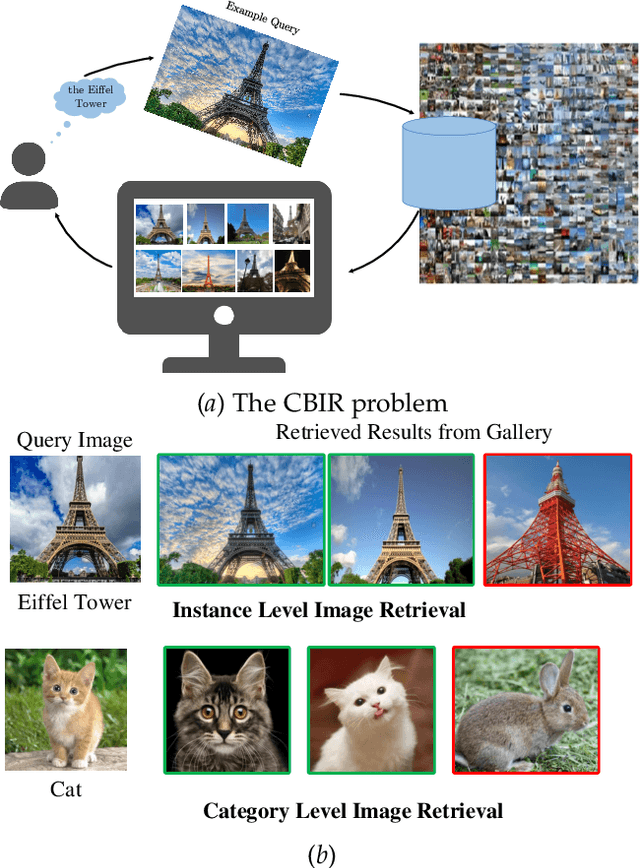
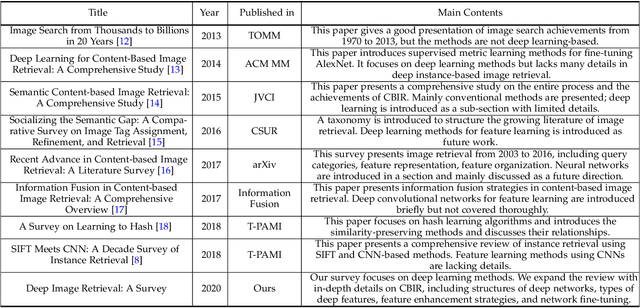
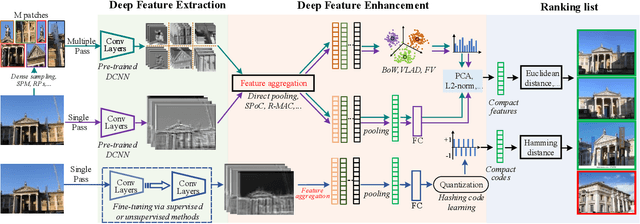
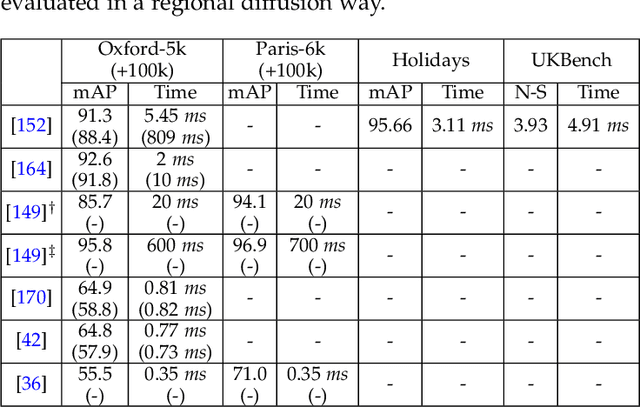
In recent years a vast amount of visual content has been generated and shared from various fields, such as social media platforms, medical images, and robotics. This abundance of content creation and sharing has introduced new challenges. In particular, searching databases for similar content, i.e.content based image retrieval (CBIR), is a long-established research area, and more efficient and accurate methods are needed for real time retrieval. Artificial intelligence has made progress in CBIR and has significantly facilitated the process of intelligent search. In this survey we organize and review recent CBIR works that are developed based on deep learning algorithms and techniques, including insights and techniques from recent papers. We identify and present the commonly-used benchmarks and evaluation methods used in the field. We collect common challenges and propose promising future directions. More specifically, we focus on image retrieval with deep learning and organize the state of the art methods according to the types of deep network structure, deep features, feature enhancement methods, and network fine-tuning strategies. Our survey considers a wide variety of recent methods, aiming to promote a global view of the field of instance-based CBIR.
Improving the Energy Efficiency and Robustness of tinyML Computer Vision using Log-Gradient Input Images
Mar 04, 2022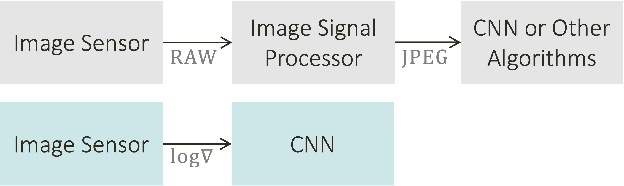
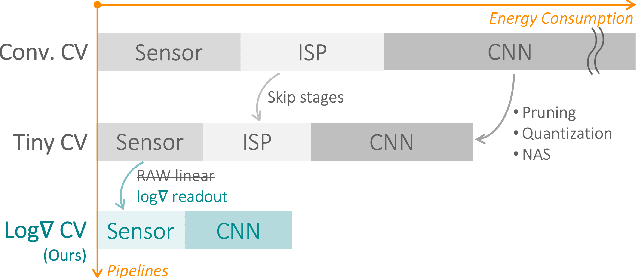
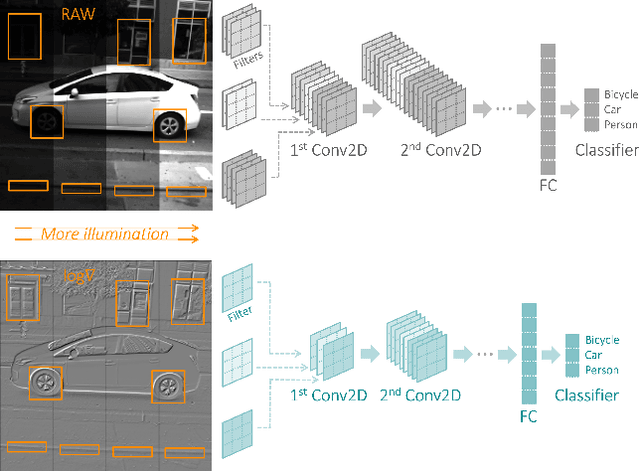

This paper studies the merits of applying log-gradient input images to convolutional neural networks (CNNs) for tinyML computer vision (CV). We show that log gradients enable: (i) aggressive 1.5-bit quantization of first-layer inputs, (ii) potential CNN resource reductions, and (iii) inherent robustness to illumination changes (1.7% accuracy loss across 1/32...8 brightness variation vs. up to 10% for JPEG). We establish these results using the PASCAL RAW image data set and through a combination of experiments using neural architecture search and a fixed three-layer network. The latter reveal that training on log-gradient images leads to higher filter similarity, making the CNN more prunable. The combined benefits of aggressive first-layer quantization, CNN resource reductions, and operation without tight exposure control and image signal processing (ISP) are helpful for pushing tinyML CV toward its ultimate efficiency limits.
Emotion-Controllable Generalized Talking Face Generation
May 02, 2022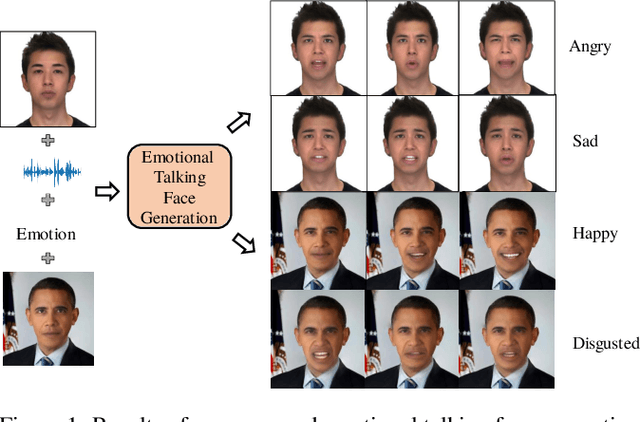
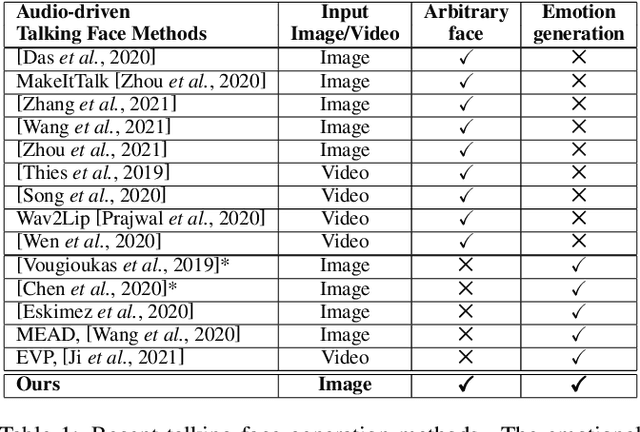
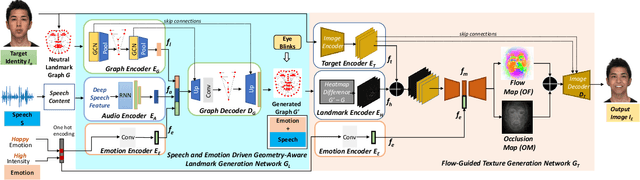

Despite the significant progress in recent years, very few of the AI-based talking face generation methods attempt to render natural emotions. Moreover, the scope of the methods is majorly limited to the characteristics of the training dataset, hence they fail to generalize to arbitrary unseen faces. In this paper, we propose a one-shot facial geometry-aware emotional talking face generation method that can generalize to arbitrary faces. We propose a graph convolutional neural network that uses speech content feature, along with an independent emotion input to generate emotion and speech-induced motion on facial geometry-aware landmark representation. This representation is further used in our optical flow-guided texture generation network for producing the texture. We propose a two-branch texture generation network, with motion and texture branches designed to consider the motion and texture content independently. Compared to the previous emotion talking face methods, our method can adapt to arbitrary faces captured in-the-wild by fine-tuning with only a single image of the target identity in neutral emotion.
Quality and Complexity Assessment of Learning-Based Image Compression Solutions
Jul 19, 2021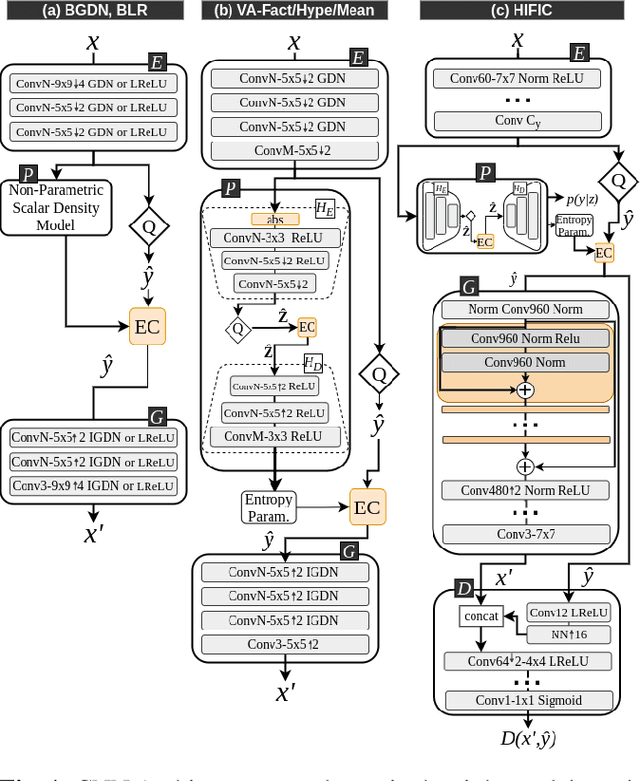
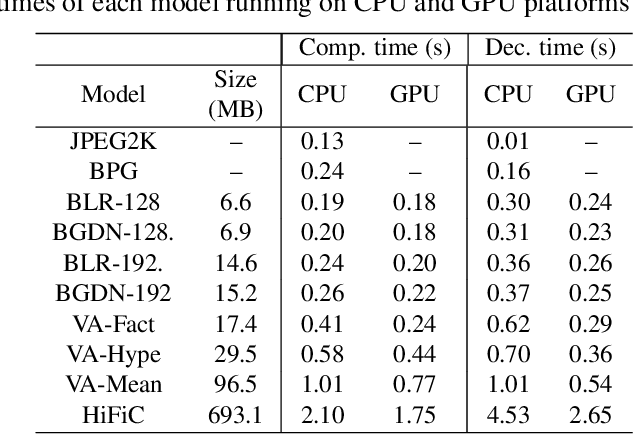
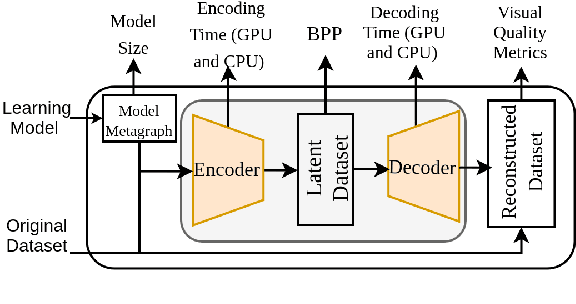
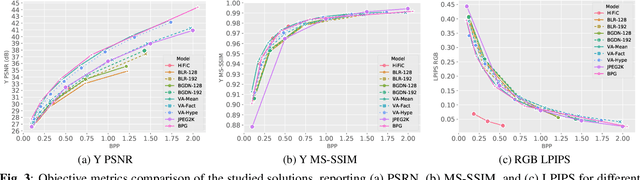
This work presents an analysis of state-of-the-art learning-based image compression techniques. We compare 8 models available in the Tensorflow Compression package in terms of visual quality metrics and processing time, using the KODAK data set. The results are compared with the Better Portable Graphics (BPG) and the JPEG2000 codecs. Results show that JPEG2000 has the lowest execution times compared with the fastest learning-based model, with a speedup of 1.46x in compression and 30x in decompression. However, the learning-based models achieved improvements over JPEG2000 in terms of quality, specially for lower bitrates. Our findings also show that BPG is more efficient in terms of PSNR, but the learning models are better for other quality metrics, and sometimes even faster. The results indicate that learning-based techniques are promising solutions towards a future mainstream compression method.
Coupled Feature Learning for Multimodal Medical Image Fusion
Feb 17, 2021
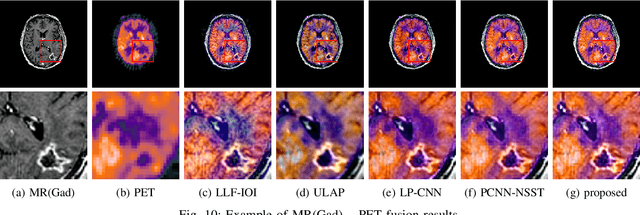
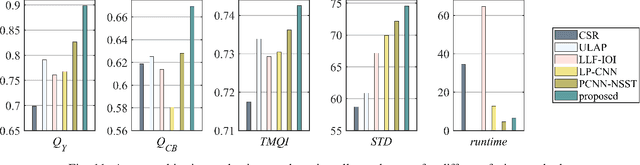
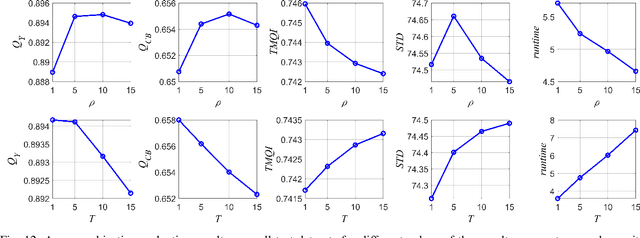
Multimodal image fusion aims to combine relevant information from images acquired with different sensors. In medical imaging, fused images play an essential role in both standard and automated diagnosis. In this paper, we propose a novel multimodal image fusion method based on coupled dictionary learning. The proposed method is general and can be employed for different medical imaging modalities. Unlike many current medical fusion methods, the proposed approach does not suffer from intensity attenuation nor loss of critical information. Specifically, the images to be fused are decomposed into coupled and independent components estimated using sparse representations with identical supports and a Pearson correlation constraint, respectively. An alternating minimization algorithm is designed to solve the resulting optimization problem. The final fusion step uses the max-absolute-value rule. Experiments are conducted using various pairs of multimodal inputs, including real MR-CT and MR-PET images. The resulting performance and execution times show the competitiveness of the proposed method in comparison with state-of-the-art medical image fusion methods.