 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual and Object Geo-localization: A Comprehensive Survey
Dec 30, 2021
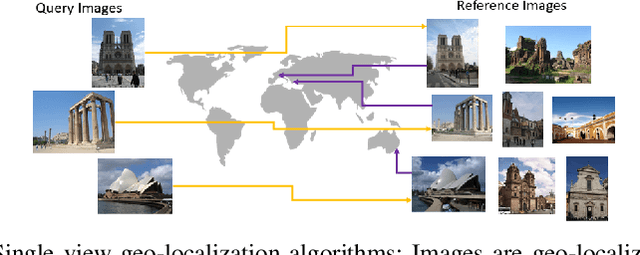
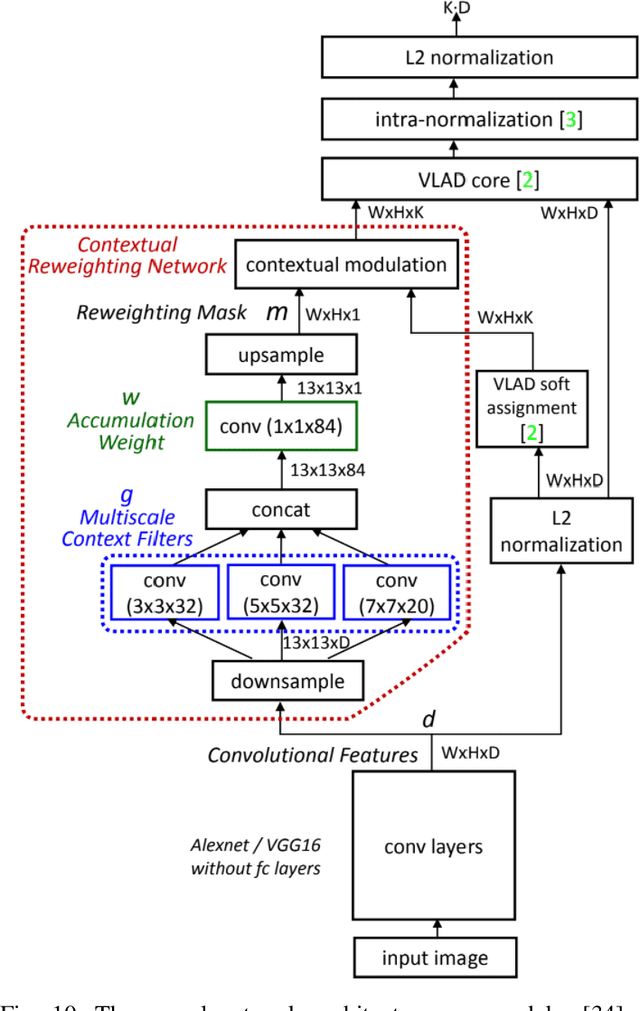
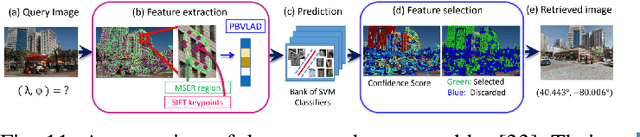
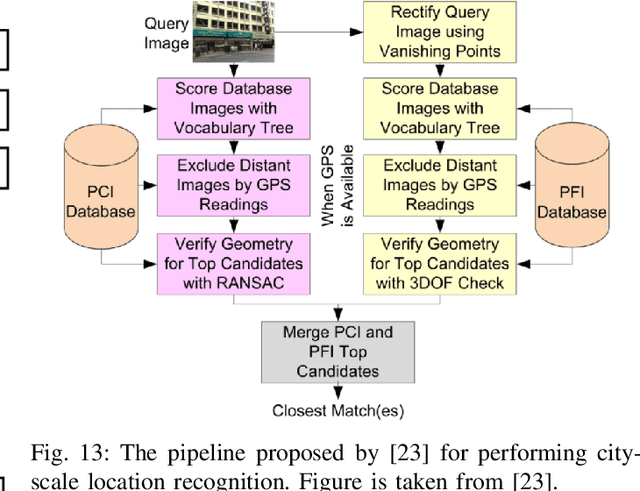
The concept of geo-localization refers to the process of determining where on earth some `entity' is located, typically using Global Positioning System (GPS) coordinates. The entity of interest may be an image, sequence of images, a video, satellite image, or even objects visible within the image. As massive datasets of GPS tagged media have rapidly become available due to smartphones and the internet, and deep learning has risen to enhance the performance capabilities of machine learning models, the fields of visual and object geo-localization have emerged due to its significant impact on a wide range of applications such as augmented reality, robotics, self-driving vehicles, road maintenance, and 3D reconstruction. This paper provides a comprehensive survey of geo-localization involving images, which involves either determining from where an image has been captured (Image geo-localization) or geo-locating objects within an image (Object geo-localization). We will provide an in-depth study, including a summary of popular algorithms, a description of proposed datasets, and an analysis of performance results to illustrate the current state of each field.
PlaneRecNet: Multi-Task Learning with Cross-Task Consistency for Piece-Wise Plane Detection and Reconstruction from a Single RGB Image
Oct 21, 2021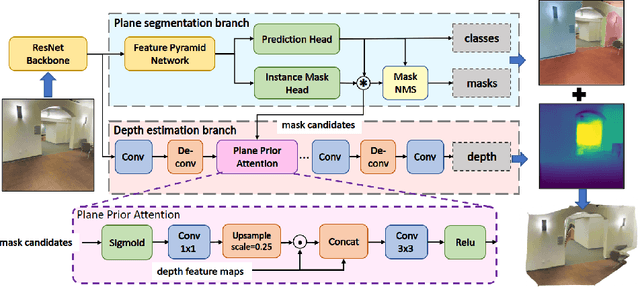

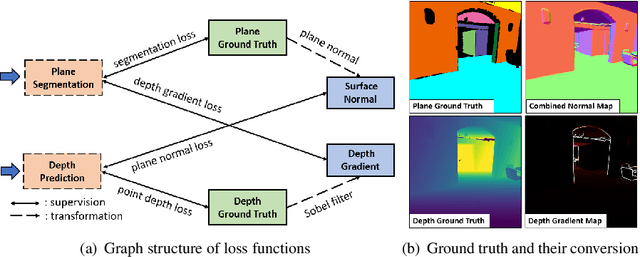

Piece-wise 3D planar reconstruction provides holistic scene understanding of man-made environments, especially for indoor scenarios. Most recent approaches focused on improving the segmentation and reconstruction results by introducing advanced network architectures but overlooked the dual characteristics of piece-wise planes as objects and geometric models. Different from other existing approaches, we start from enforcing cross-task consistency for our multi-task convolutional neural network, PlaneRecNet, which integrates a single-stage instance segmentation network for piece-wise planar segmentation and a depth decoder to reconstruct the scene from a single RGB image. To achieve this, we introduce several novel loss functions (geometric constraint) that jointly improve the accuracy of piece-wise planar segmentation and depth estimation. Meanwhile, a novel Plane Prior Attention module is used to guide depth estimation with the awareness of plane instances. Exhaustive experiments are conducted in this work to validate the effectiveness and efficiency of our method.
Simple black-box universal adversarial attacks on medical image classification based on deep neural networks
Aug 11, 2021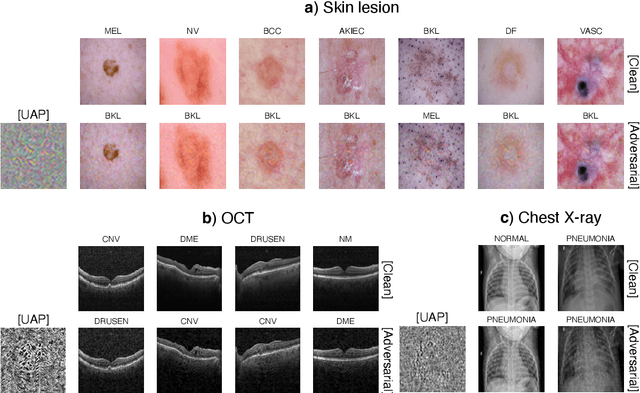
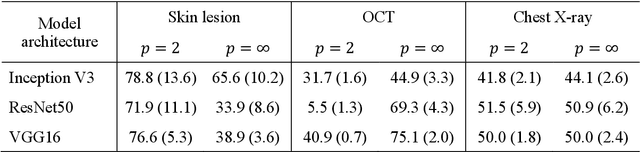
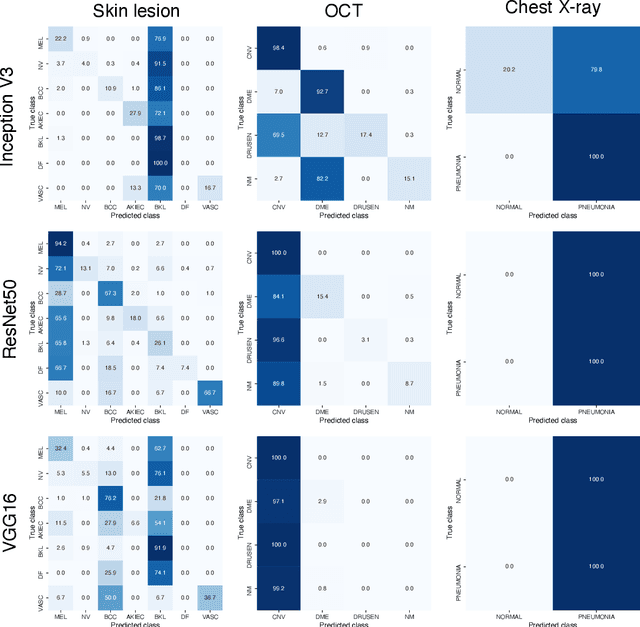
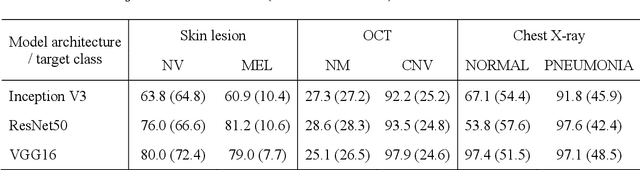
Universal adversarial attacks, which hinder most deep neural network (DNN) tasks using only a small single perturbation called a universal adversarial perturbation (UAP), is a realistic security threat to the practical application of a DNN. In particular, such attacks cause serious problems in medical imaging. Given that computer-based systems are generally operated under a black-box condition in which only queries on inputs are allowed and outputs are accessible, the impact of UAPs seems to be limited because well-used algorithms for generating UAPs are limited to a white-box condition in which adversaries can access the model weights and loss gradients. Nevertheless, we demonstrate that UAPs are easily generatable using a relatively small dataset under black-box conditions. In particular, we propose a method for generating UAPs using a simple hill-climbing search based only on DNN outputs and demonstrate the validity of the proposed method using representative DNN-based medical image classifications. Black-box UAPs can be used to conduct both non-targeted and targeted attacks. Overall, the black-box UAPs showed high attack success rates (40% to 90%), although some of them had relatively low success rates because the method only utilizes limited information to generate UAPs. The vulnerability of black-box UAPs was observed in several model architectures. The results indicate that adversaries can also generate UAPs through a simple procedure under the black-box condition to foil or control DNN-based medical image diagnoses, and that UAPs are a more realistic security threat.
Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment
Mar 06, 2022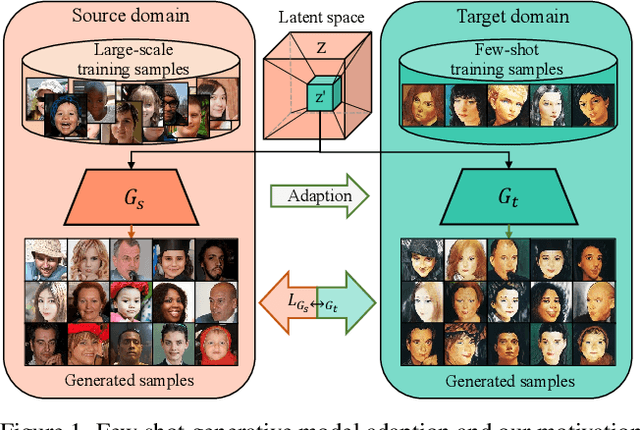
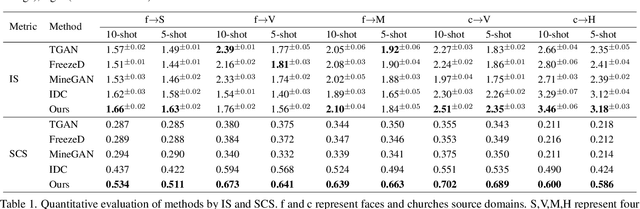
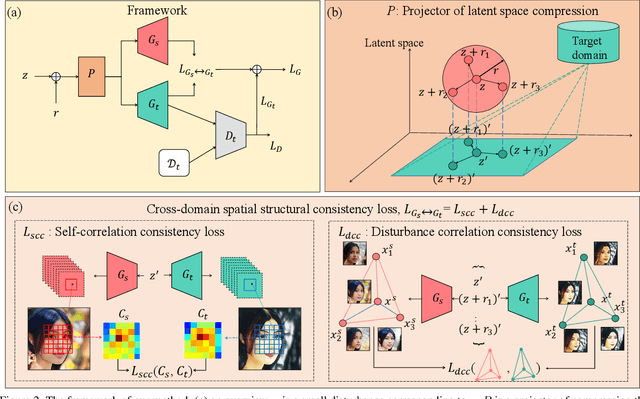

Training a generative adversarial network (GAN) with limited data has been a challenging task. A feasible solution is to start with a GAN well-trained on a large scale source domain and adapt it to the target domain with a few samples, termed as few shot generative model adaption. However, existing methods are prone to model overfitting and collapse in extremely few shot setting (less than 10). To solve this problem, we propose a relaxed spatial structural alignment method to calibrate the target generative models during the adaption. We design a cross-domain spatial structural consistency loss comprising the self-correlation and disturbance correlation consistency loss. It helps align the spatial structural information between the synthesis image pairs of the source and target domains. To relax the cross-domain alignment, we compress the original latent space of generative models to a subspace. Image pairs generated from the subspace are pulled closer. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
UV Volumes for Real-time Rendering of Editable Free-view Human Performance
Mar 27, 2022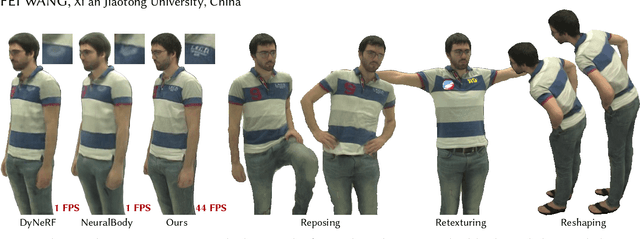
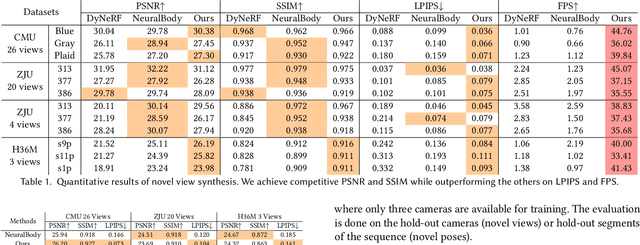
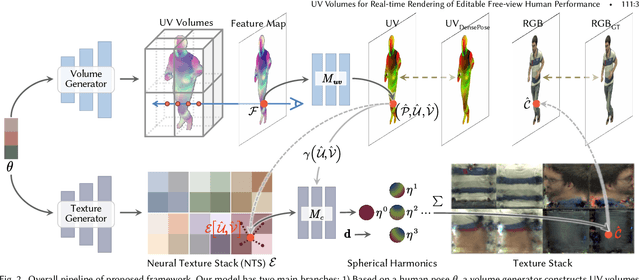

Neural volume rendering has been proven to be a promising method for efficient and photo-realistic rendering of a human performer in free-view, a critical task in many immersive VR/AR applications. However, existing approaches are severely limited by their high computational cost in the rendering process. To solve this problem, we propose the UV Volumes, an approach that can render an editable free-view video of a human performer in real-time. It is achieved by removing the high-frequency (i.e., non-smooth) human textures from the 3D volume and encoding them into a 2D neural texture stack (NTS). The smooth UV volume allows us to employ a much smaller and shallower structure for 3D CNN and MLP, to obtain the density and texture coordinates without losing image details. Meanwhile, the NTS only needs to be queried once for each pixel in the UV image to retrieve its RGB value. For editability, the 3D CNN and MLP decoder can easily fit the function that maps the input structured-and-posed latent codes to the relatively smooth densities and texture coordinates. It gives our model a better generalization ability to handle novel poses and shapes. Furthermore, the use of NST enables new applications, e.g., retexturing. Extensive experiments on CMU Panoptic, ZJU Mocap, and H36M datasets show that our model can render 900 * 500 images in 40 fps on average with comparable photorealism to state-of-the-art methods. The project and supplementary materials are available at https://fanegg.github.io/UV-Volumes.
DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection
Mar 15, 2022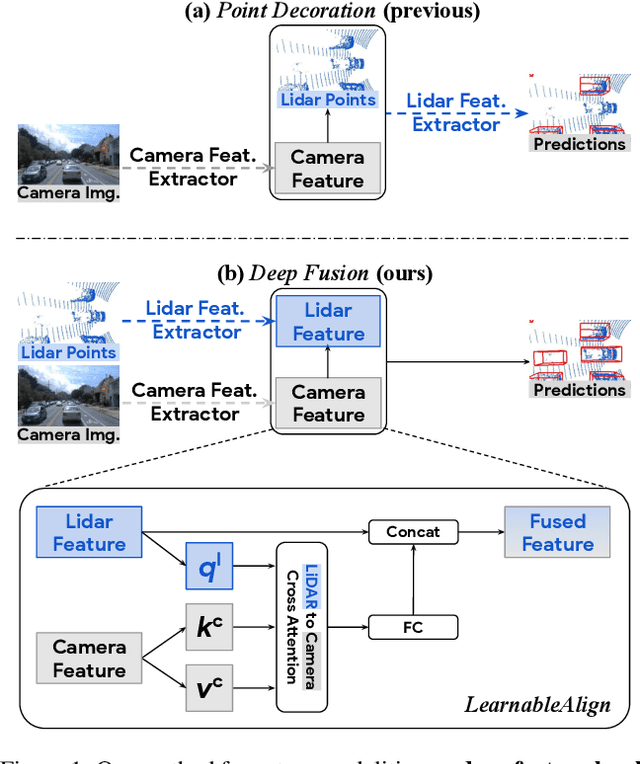
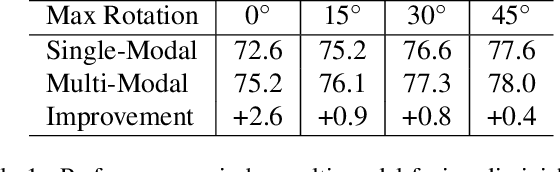
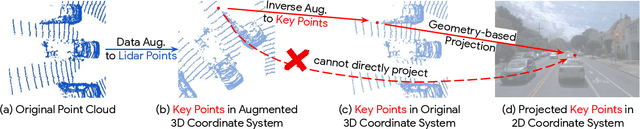
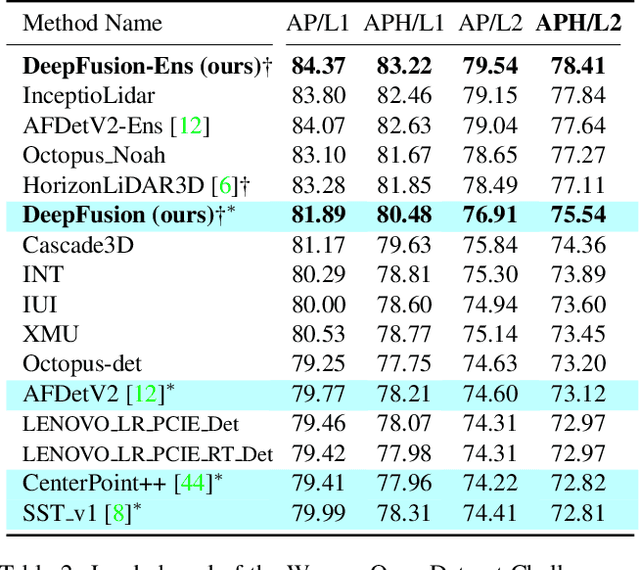
Lidars and cameras are critical sensors that provide complementary information for 3D detection in autonomous driving. While prevalent multi-modal methods simply decorate raw lidar point clouds with camera features and feed them directly to existing 3D detection models, our study shows that fusing camera features with deep lidar features instead of raw points, can lead to better performance. However, as those features are often augmented and aggregated, a key challenge in fusion is how to effectively align the transformed features from two modalities. In this paper, we propose two novel techniques: InverseAug that inverses geometric-related augmentations, e.g., rotation, to enable accurate geometric alignment between lidar points and image pixels, and LearnableAlign that leverages cross-attention to dynamically capture the correlations between image and lidar features during fusion. Based on InverseAug and LearnableAlign, we develop a family of generic multi-modal 3D detection models named DeepFusion, which is more accurate than previous methods. For example, DeepFusion improves PointPillars, CenterPoint, and 3D-MAN baselines on Pedestrian detection for 6.7, 8.9, and 6.2 LEVEL_2 APH, respectively. Notably, our models achieve state-of-the-art performance on Waymo Open Dataset, and show strong model robustness against input corruptions and out-of-distribution data. Code will be publicly available at https://github.com/tensorflow/lingvo/tree/master/lingvo/.
MSRF-Net: A Multi-Scale Residual Fusion Network for Biomedical Image Segmentation
May 16, 2021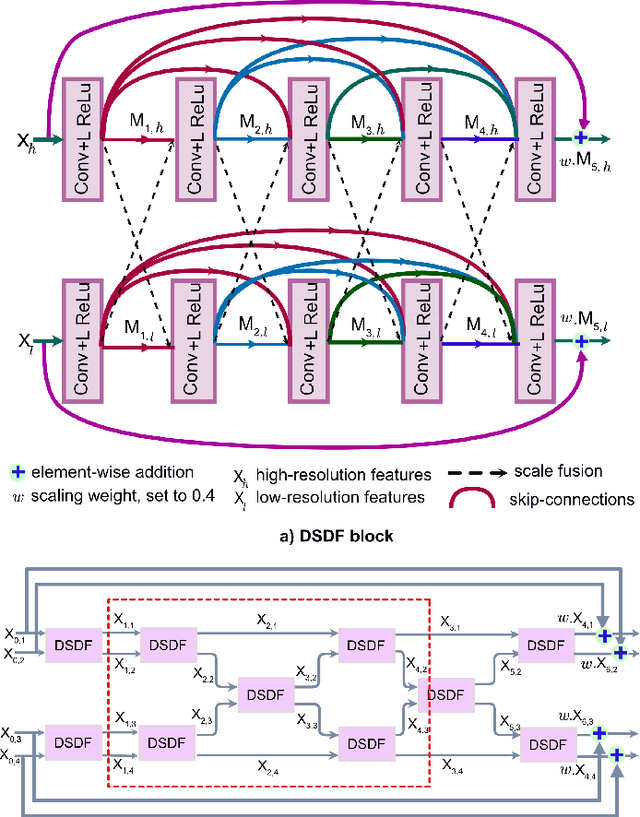
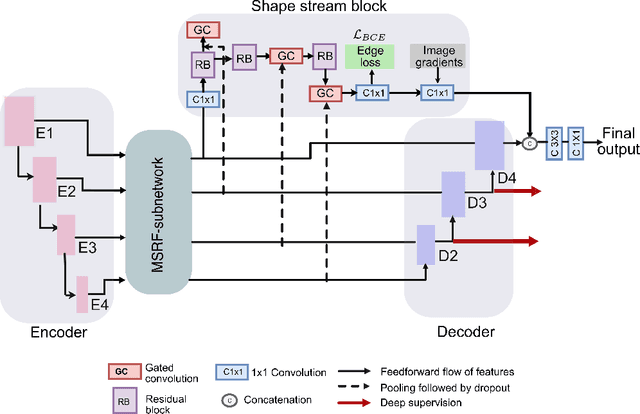
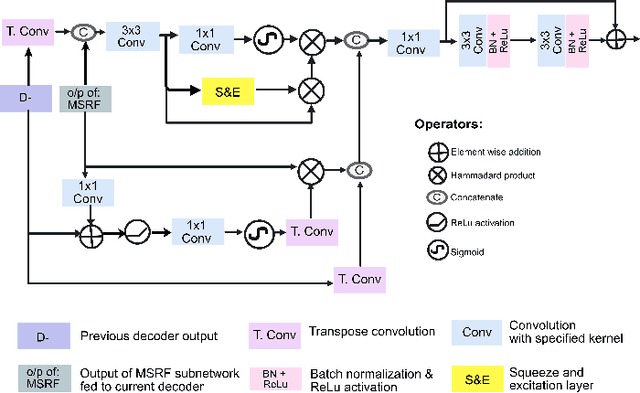
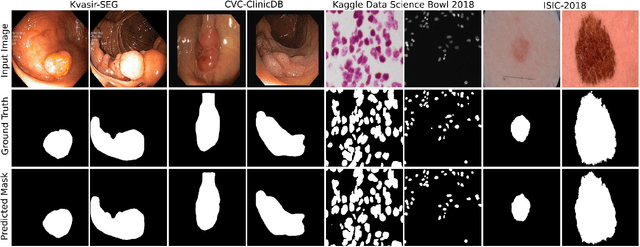
Methods based on convolutional neural networks have improved the performance of biomedical image segmentation. However, most of these methods cannot efficiently segment objects of variable sizes and train on small and biased datasets, which are common in biomedical use cases. While methods exist that incorporate multi-scale fusion approaches to address the challenges arising with variable sizes, they usually use complex models that are more suitable for general semantic segmentation computer vision problems. In this paper, we propose a novel architecture called MSRF-Net, which is specially designed for medical image segmentation tasks. The proposed MSRF-Net is able to exchange multi-scale features of varying receptive fields using a dual-scale dense fusion block (DSDF). Our DSDF block can exchange information rigorously across two different resolution scales, and our MSRF sub-network uses multiple DSDF blocks in sequence to perform multi-scale fusion. This allows the preservation of resolution, improved information flow, and propagation of both high- and low-level features to obtain accurate segmentation maps. The proposed MSRF-Net allows to capture object variabilities and provides improved results on different biomedical datasets. Extensive experiments on MSRF-Net demonstrate that the proposed method outperforms most of the cutting-edge medical image segmentation state-of-the-art methods. MSRF-Net advances the performance on four publicly available datasets, and also, MSRF-Net is more generalizable as compared to state-of-the-art methods.
Sketch-QNet: A Quadruplet ConvNet for Color Sketch-based Image Retrieval
Apr 22, 2021
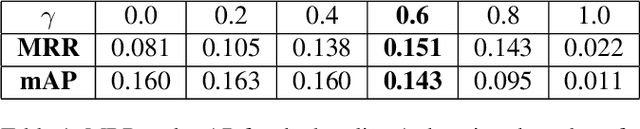
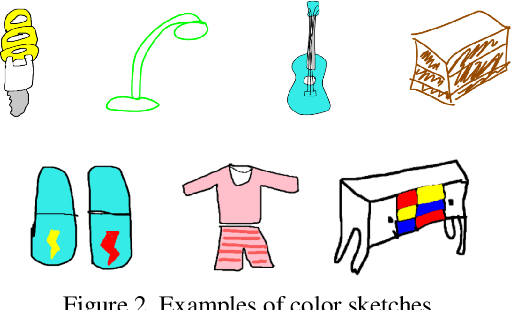
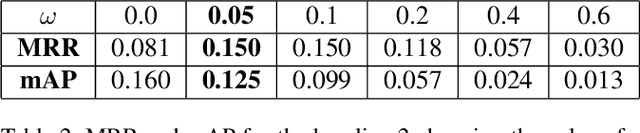
Architectures based on siamese networks with triplet loss have shown outstanding performance on the image-based similarity search problem. This approach attempts to discriminate between positive (relevant) and negative (irrelevant) items. However, it undergoes a critical weakness. Given a query, it cannot discriminate weakly relevant items, for instance, items of the same type but different color or texture as the given query, which could be a serious limitation for many real-world search applications. Therefore, in this work, we present a quadruplet-based architecture that overcomes the aforementioned weakness. Moreover, we present an instance of this quadruplet network, which we call Sketch-QNet, to deal with the color sketch-based image retrieval (CSBIR) problem, achieving new state-of-the-art results.
Generative Convolution Layer for Image Generation
Nov 30, 2021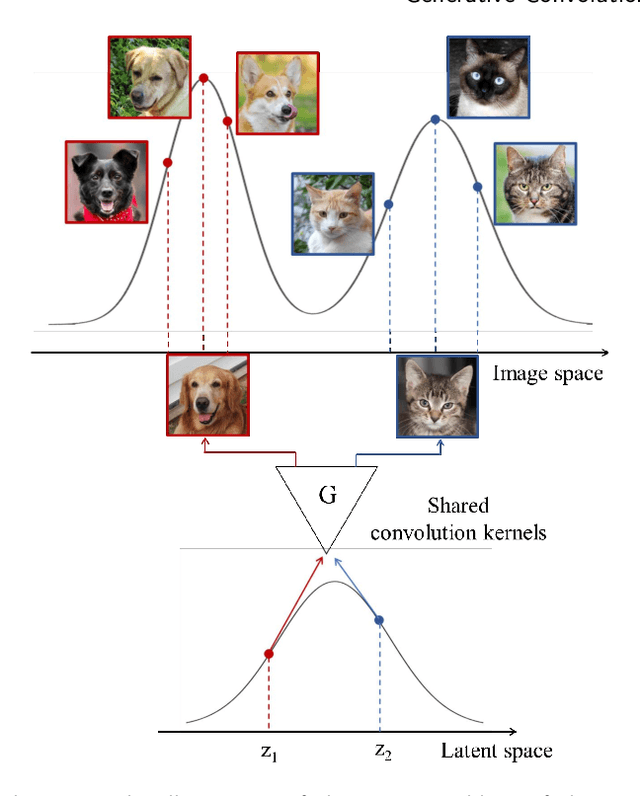
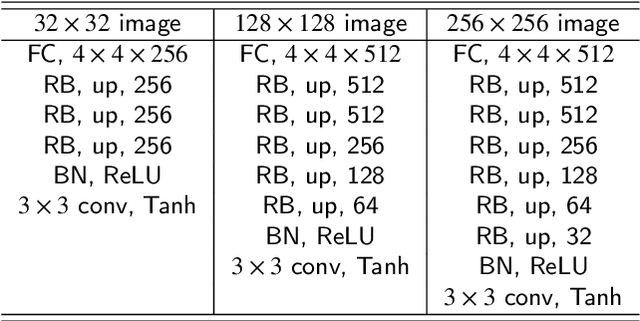
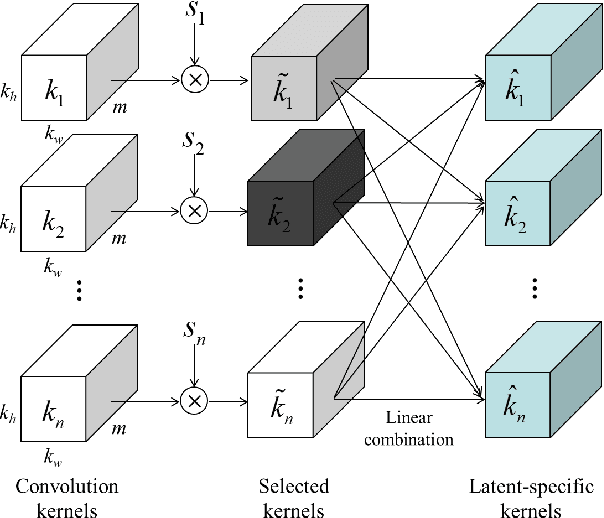
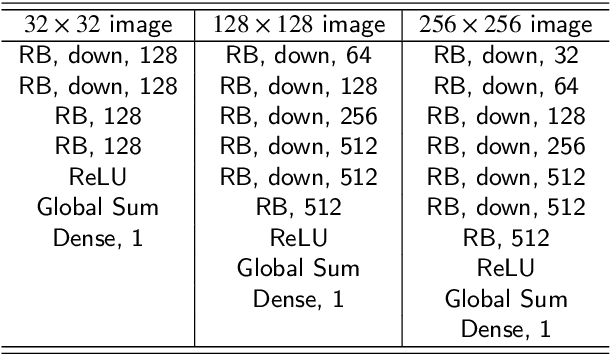
This paper introduces a novel convolution method, called generative convolution (GConv), which is simple yet effective for improving the generative adversarial network (GAN) performance. Unlike the standard convolution, GConv first selects useful kernels compatible with the given latent vector, and then linearly combines the selected kernels to make latent-specific kernels. Using the latent-specific kernels, the proposed method produces the latent-specific features which encourage the generator to produce high-quality images. This approach is simple but surprisingly effective. First, the GAN performance is significantly improved with a little additional hardware cost. Second, GConv can be employed to the existing state-of-the-art generators without modifying the network architecture. To reveal the superiority of GConv, this paper provides extensive experiments using various standard datasets including CIFAR-10, CIFAR-100, LSUN-Church, CelebA, and tiny-ImageNet. Quantitative evaluations prove that GConv significantly boosts the performances of the unconditional and conditional GANs in terms of Inception score (IS) and Frechet inception distance (FID). For example, the proposed method improves both FID and IS scores on the tiny-ImageNet dataset from 35.13 to 29.76 and 20.23 to 22.64, respectively.
A Survey on Unsupervised Industrial Anomaly Detection Algorithms
Apr 28, 2022


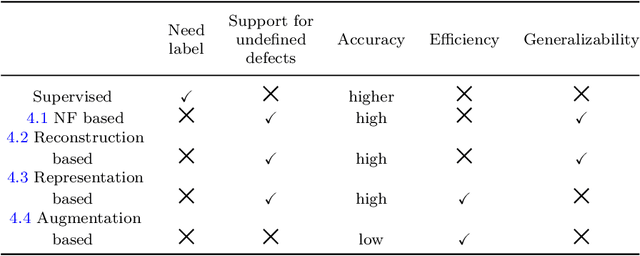
In line with the development of Industry 4.0, more and more attention is attracted to the field of surface defect detection. Improving efficiency as well as saving labor costs has steadily become a matter of great concern in industry field, where deep learning-based algorithms performs better than traditional vision inspection methods in recent years. While existing deep learning-based algorithms are biased towards supervised learning, which not only necessitates a huge amount of labeled data and a significant amount of labor, but it is also inefficient and has certain limitations. In contrast, recent research shows that unsupervised learning has great potential in tackling above disadvantages for visual anomaly detection. In this survey, we summarize current challenges and provide a thorough overview of recently proposed unsupervised algorithms for visual anomaly detection covering five categories, whose innovation points and frameworks are described in detail. Meanwhile, information on publicly available datasets containing surface image samples are provided. By comparing different classes of methods, the advantages and disadvantages of anomaly detection algorithms are summarized. It is expected to assist both the research community and industry in developing a broader and cross-domain perspective.