 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scene Clustering Based Pseudo-labeling Strategy for Multi-modal Aerial View Object Classification
May 04, 2022
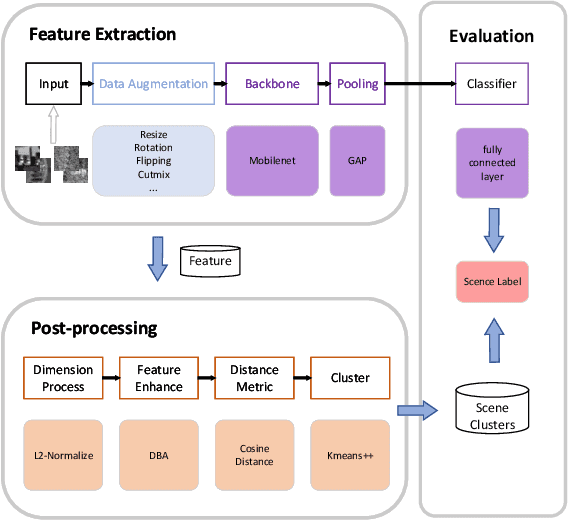
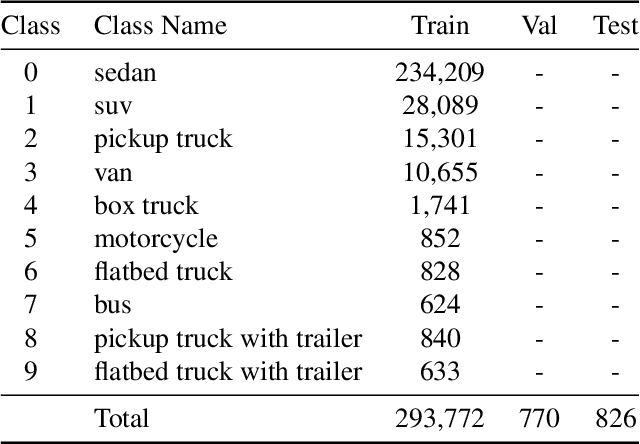
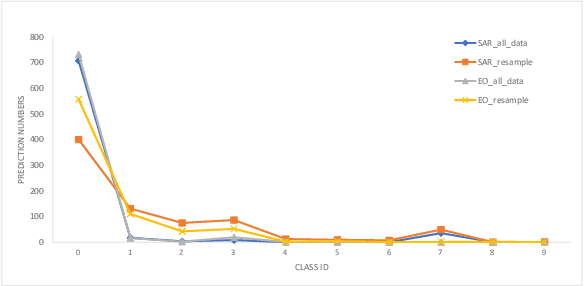
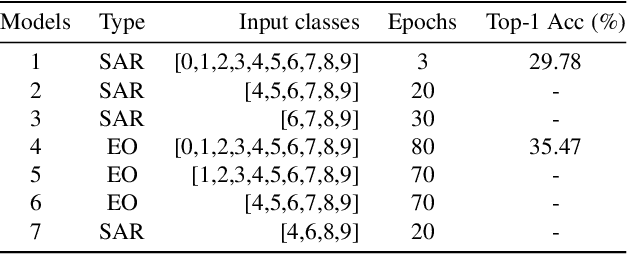
Multi-modal aerial view object classification (MAVOC) in Automatic target recognition (ATR), although an important and challenging problem, has been under studied. This paper firstly finds that fine-grained data, class imbalance and various shooting conditions preclude the representational ability of general image classification. Moreover, the MAVOC dataset has scene aggregation characteristics. By exploiting these properties, we propose Scene Clustering Based Pseudo-labeling Strategy (SCP-Label), a simple yet effective method to employ in post-processing. The SCP-Label brings greater accuracy by assigning the same label to objects within the same scene while also mitigating bias and confusion with model ensembles. Its performance surpasses the official baseline by a large margin of +20.57% Accuracy on Track 1 (SAR), and +31.86% Accuracy on Track 2 (SAR+EO), demonstrating the potential of SCP-Label as post-processing. Finally, we win the championship both on Track1 and Track2 in the CVPR 2022 Perception Beyond the Visible Spectrum (PBVS) Workshop MAVOC Challenge. Our code is available at https://github.com/HowieChangchn/SCP-Label.
Novel Light Field Imaging Device with Enhanced Light Collection for Cold Atom Clouds
May 23, 2022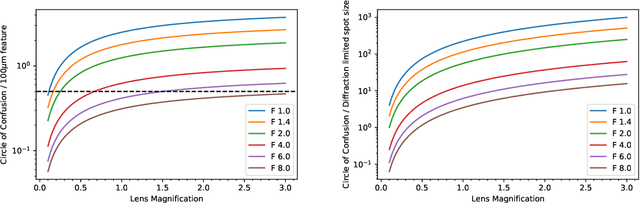
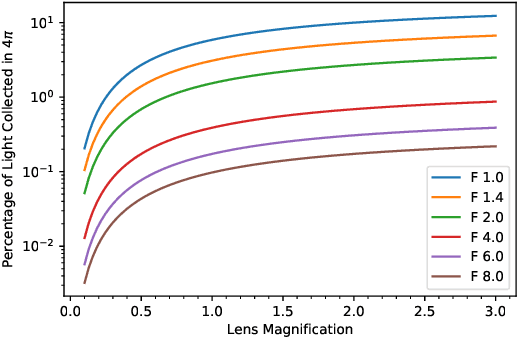
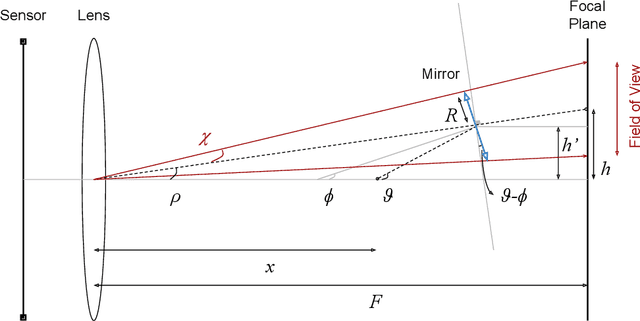
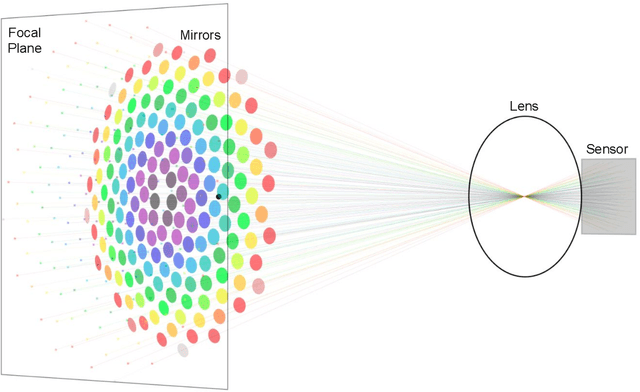
We present a light field imaging system that captures multiple views of an object with a single shot. The system is designed to maximize the total light collection by accepting a larger solid angle of light than a conventional lens with equivalent depth of field. This is achieved by populating a plane of virtual objects using mirrors and fully utilizing the available field of view and depth of field. Simulation results demonstrate that this design is capable of single-shot tomography of objects of size $\mathcal{O}$(1 mm$^3$), reconstructing the 3-dimensional (3D) distribution and features not accessible from any single view angle in isolation. In particular, for atom clouds used in atom interferometry experiments, the system can reconstruct 3D fringe patterns with size $\mathcal{O}$(100 $\mu$m). We also demonstrate this system with a 3D-printed prototype. The prototype is used to take images of $\mathcal{O}$(1 mm$^{3}$) sized objects, and 3D reconstruction algorithms running on a single-shot image successfully reconstruct $\mathcal{O}$(100 $\mu$m) internal features. The prototype also shows that the system can be built with 3D printing technology and hence can be deployed quickly and cost-effectively in experiments with needs for enhanced light collection or 3D reconstruction. Imaging of cold atom clouds in atom interferometry is a key application of this new type of imaging device where enhanced light collection, high depth of field, and 3D tomographic reconstruction can provide new handles to characterize the atom clouds.
Harnessing Artificial Intelligence to Infer Novel Spatial Biomarkers for the Diagnosis of Eosinophilic Esophagitis
May 26, 2022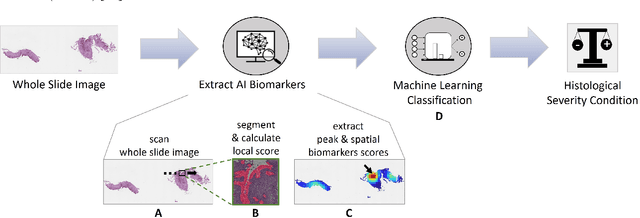
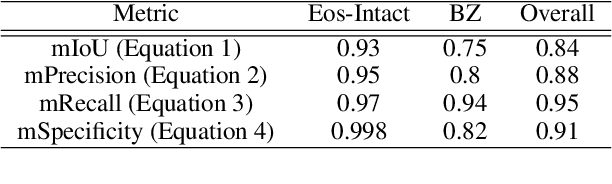
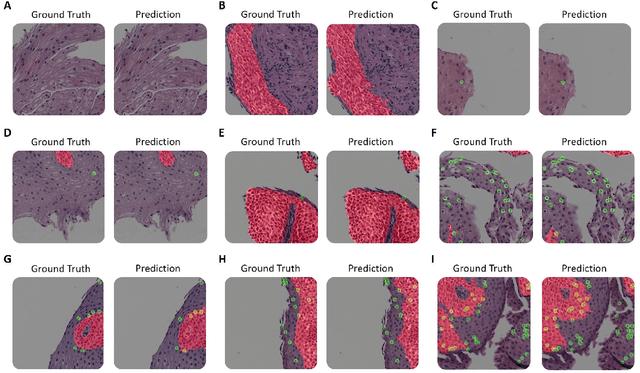

Eosinophilic esophagitis (EoE) is a chronic allergic inflammatory condition of the esophagus associated with elevated esophageal eosinophils. Second only to gastroesophageal reflux disease, EoE is one of the leading causes of chronic refractory dysphagia in adults and children. EoE diagnosis requires enumerating the density of esophageal eosinophils in esophageal biopsies, a somewhat subjective task that is time-consuming, thus reducing the ability to process the complex tissue structure. Previous artificial intelligence (AI) approaches that aimed to improve histology-based diagnosis focused on recapitulating identification and quantification of the area of maximal eosinophil density. However, this metric does not account for the distribution of eosinophils or other histological features, over the whole slide image. Here, we developed an artificial intelligence platform that infers local and spatial biomarkers based on semantic segmentation of intact eosinophils and basal zone distributions. Besides the maximal density of eosinophils (referred to as Peak Eosinophil Count [PEC]) and a maximal basal zone fraction, we identify two additional metrics that reflect the distribution of eosinophils and basal zone fractions. This approach enables a decision support system that predicts EoE activity and classifies the histological severity of EoE patients. We utilized a cohort that includes 1066 biopsy slides from 400 subjects to validate the system's performance and achieved a histological severity classification accuracy of 86.70%, sensitivity of 84.50%, and specificity of 90.09%. Our approach highlights the importance of systematically analyzing the distribution of biopsy features over the entire slide and paves the way towards a personalized decision support system that will assist not only in counting cells but can also potentially improve diagnosis and provide treatment prediction.
Inception Transformer
May 26, 2022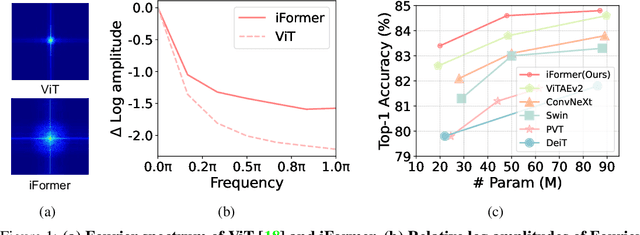
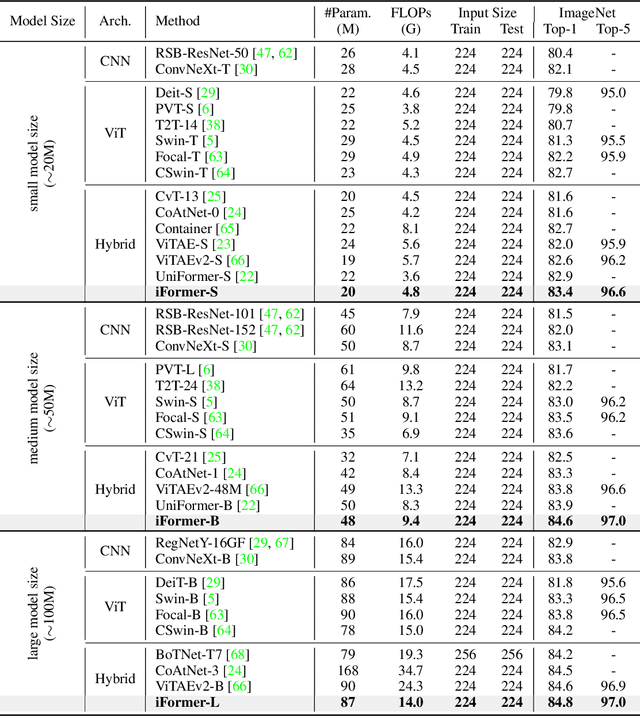
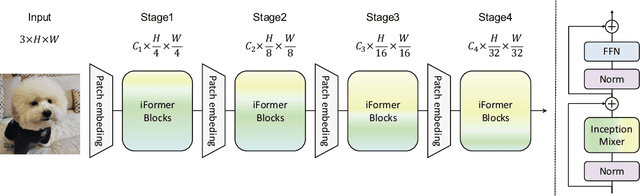
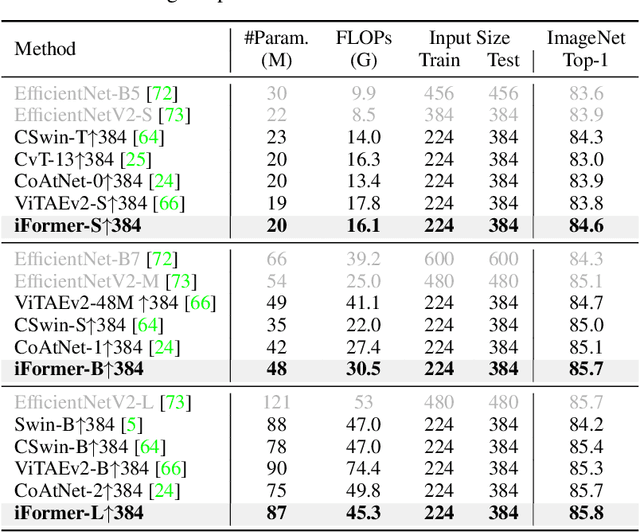
Recent studies show that Transformer has strong capability of building long-range dependencies, yet is incompetent in capturing high frequencies that predominantly convey local information. To tackle this issue, we present a novel and general-purpose Inception Transformer, or iFormer for short, that effectively learns comprehensive features with both high- and low-frequency information in visual data. Specifically, we design an Inception mixer to explicitly graft the advantages of convolution and max-pooling for capturing the high-frequency information to Transformers. Different from recent hybrid frameworks, the Inception mixer brings greater efficiency through a channel splitting mechanism to adopt parallel convolution/max-pooling path and self-attention path as high- and low-frequency mixers, while having the flexibility to model discriminative information scattered within a wide frequency range. Considering that bottom layers play more roles in capturing high-frequency details while top layers more in modeling low-frequency global information, we further introduce a frequency ramp structure, i.e. gradually decreasing the dimensions fed to the high-frequency mixer and increasing those to the low-frequency mixer, which can effectively trade-off high- and low-frequency components across different layers. We benchmark the iFormer on a series of vision tasks, and showcase that it achieves impressive performance on image classification, COCO detection and ADE20K segmentation. For example, our iFormer-S hits the top-1 accuracy of 83.4% on ImageNet-1K, much higher than DeiT-S by 3.6%, and even slightly better than much bigger model Swin-B (83.3%) with only 1/4 parameters and 1/3 FLOPs. Code and models will be released at https://github.com/sail-sg/iFormer.
A System for Image Understanding using Sensemaking and Narrative
Jan 21, 2022
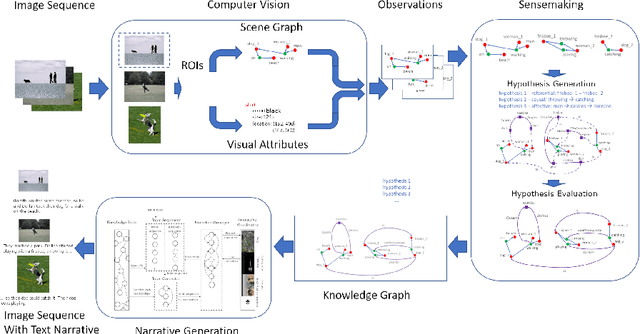
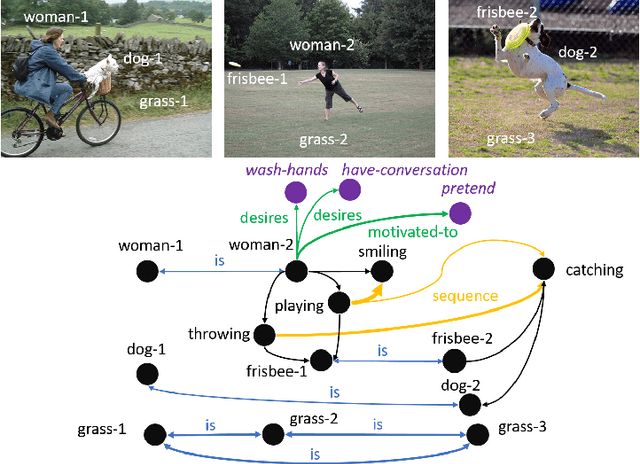
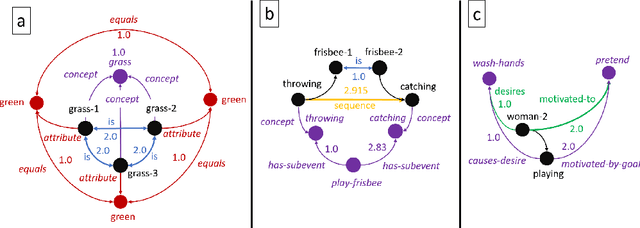
Sensemaking and narrative are two inherently interconnected concepts about how people understand the world around them. Sensemaking is the process by which people structure and interconnect the information they encounter in the world with the knowledge and inferences they have made in the past. Narratives are important constructs that people use sensemaking to create; ones that reflect provide a more holistic account of the world than the information within any given narrative is able to alone. Both are important to how human beings parse the world, and both would be valuable for a computational system attempting to do the same. In this paper, we discuss theories of sensemaking and narrative with respect to how people build an understanding of the world based on the information they encounter, as well as the links between the fields of sensemaking and narrative research. We highlight a specific computational task, visual storytelling, whose solutions we believe can be enhanced by employing a sensemaking and narrative component. We then describe our system for visual storytelling using sensemaking and narrative and discuss examples from its current implementation.
ConvMAE: Masked Convolution Meets Masked Autoencoders
May 08, 2022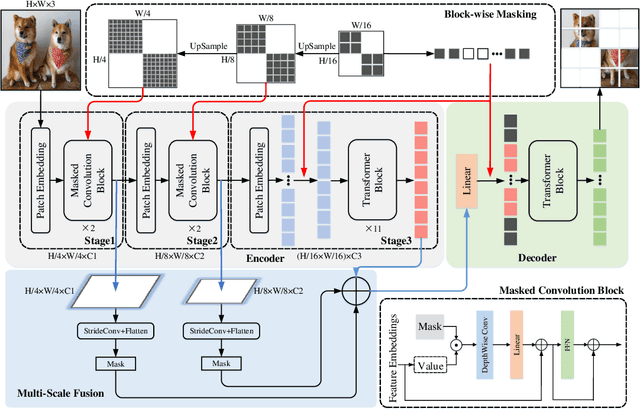
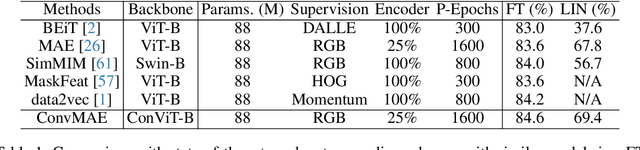
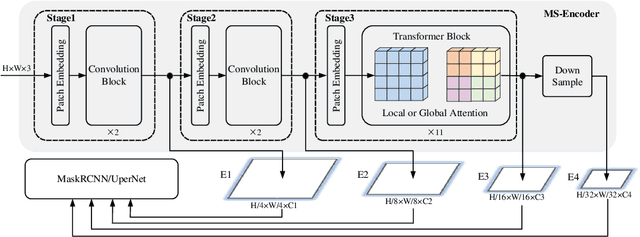
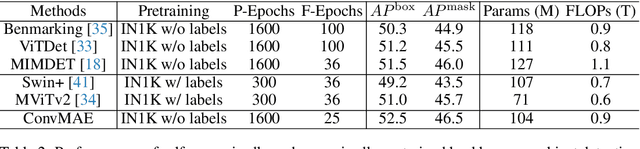
Vision Transformers (ViT) become widely-adopted architectures for various vision tasks. Masked auto-encoding for feature pretraining and multi-scale hybrid convolution-transformer architectures can further unleash the potentials of ViT, leading to state-of-the-art performances on image classification, detection and semantic segmentation. In this paper, our ConvMAE framework demonstrates that multi-scale hybrid convolution-transformer can learn more discriminative representations via the mask auto-encoding scheme. However, directly using the original masking strategy leads to the heavy computational cost and pretraining-finetuning discrepancy. To tackle the issue, we adopt the masked convolution to prevent information leakage in the convolution blocks. A simple block-wise masking strategy is proposed to ensure computational efficiency. We also propose to more directly supervise the multi-scale features of the encoder to boost multi-scale features. Based on our pretrained ConvMAE models, ConvMAE-Base improves ImageNet-1K finetuning accuracy by 1.4% compared with MAE-Base. On object detection, ConvMAE-Base finetuned for only 25 epochs surpasses MAE-Base fined-tuned for 100 epochs by 2.9% box AP and 2.2% mask AP respectively. Code and pretrained models are available at https://github.com/Alpha-VL/ConvMAE.
OSLO: On-the-Sphere Learning for Omnidirectional images and its application to 360-degree image compression
Jul 19, 2021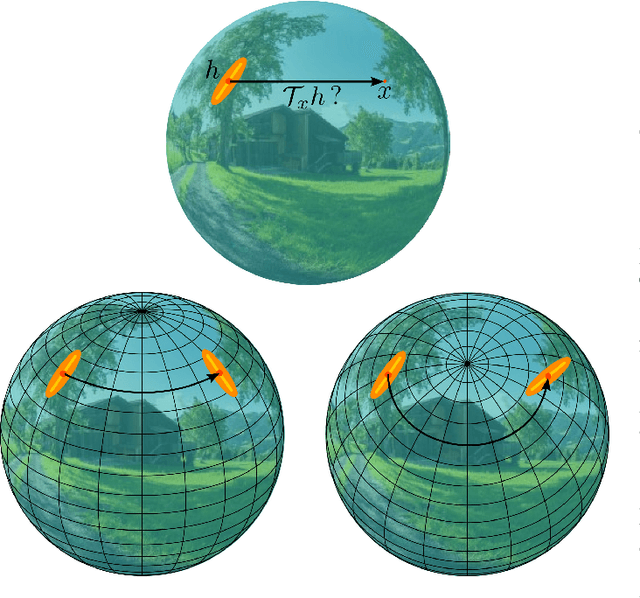
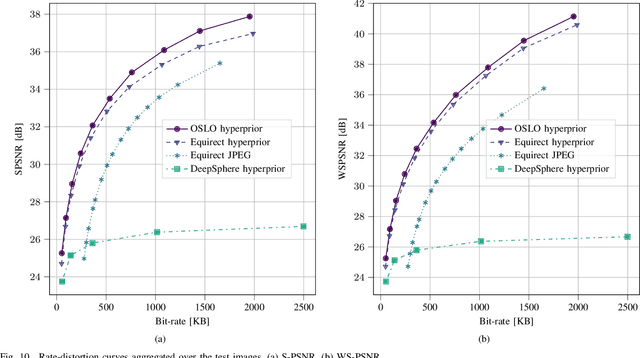
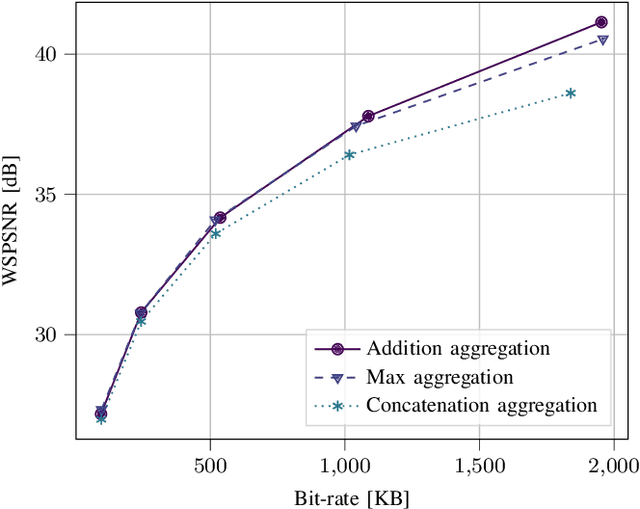
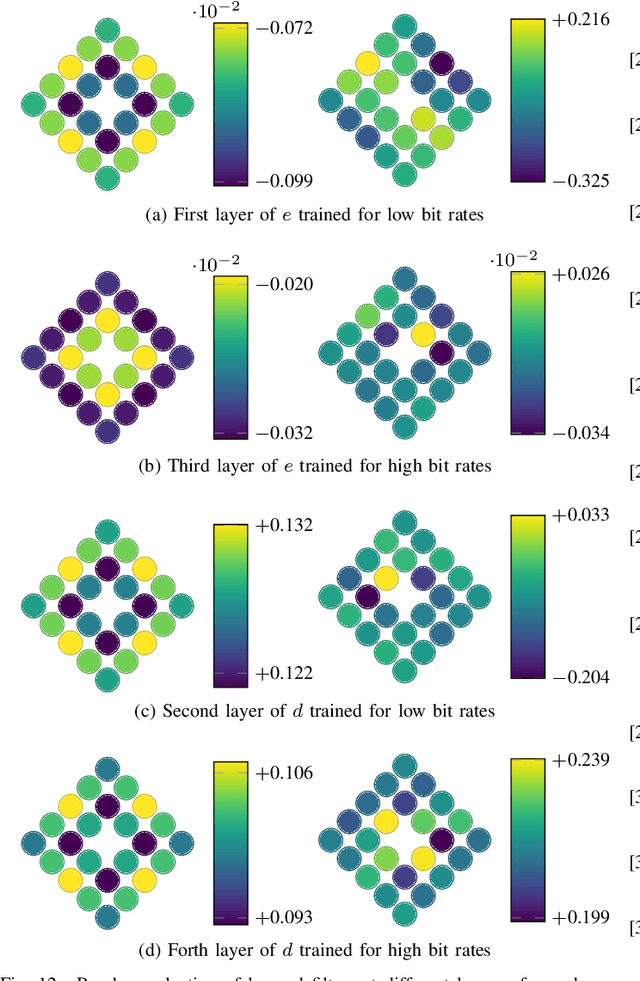
State-of-the-art 2D image compression schemes rely on the power of convolutional neural networks (CNNs). Although CNNs offer promising perspectives for 2D image compression, extending such models to omnidirectional images is not straightforward. First, omnidirectional images have specific spatial and statistical properties that can not be fully captured by current CNN models. Second, basic mathematical operations composing a CNN architecture, e.g., translation and sampling, are not well-defined on the sphere. In this paper, we study the learning of representation models for omnidirectional images and propose to use the properties of HEALPix uniform sampling of the sphere to redefine the mathematical tools used in deep learning models for omnidirectional images. In particular, we: i) propose the definition of a new convolution operation on the sphere that keeps the high expressiveness and the low complexity of a classical 2D convolution; ii) adapt standard CNN techniques such as stride, iterative aggregation, and pixel shuffling to the spherical domain; and then iii) apply our new framework to the task of omnidirectional image compression. Our experiments show that our proposed on-the-sphere solution leads to a better compression gain that can save 13.7% of the bit rate compared to similar learned models applied to equirectangular images. Also, compared to learning models based on graph convolutional networks, our solution supports more expressive filters that can preserve high frequencies and provide a better perceptual quality of the compressed images. Such results demonstrate the efficiency of the proposed framework, which opens new research venues for other omnidirectional vision tasks to be effectively implemented on the sphere manifold.
Non-Deterministic Face Mask Removal Based On 3D Priors
Mar 03, 2022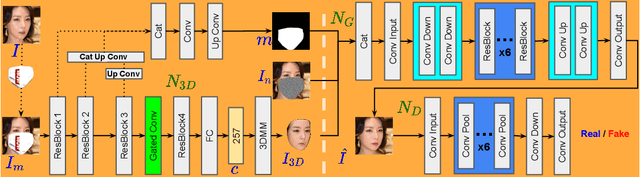

This paper presents a novel image inpainting framework for face mask removal. Although current methods have demonstrated their impressive ability in recovering damaged face images, they suffer from two main problems: the dependence on manually labeled missing regions and the deterministic result corresponding to each input. The proposed approach tackles these problems by integrating a multi-task 3D face reconstruction module with a face inpainting module. Given a masked face image, the former predicts a 3DMM-based reconstructed face together with a binary occlusion map, providing dense geometrical and textural priors that greatly facilitate the inpainting task of the latter. By gradually controlling the 3D shape parameters, our method generates high-quality dynamic inpainting results with different expressions and mouth movements. Qualitative and quantitative experiments verify the effectiveness of the proposed method.
TFill: Image Completion via a Transformer-Based Architecture
Apr 02, 2021
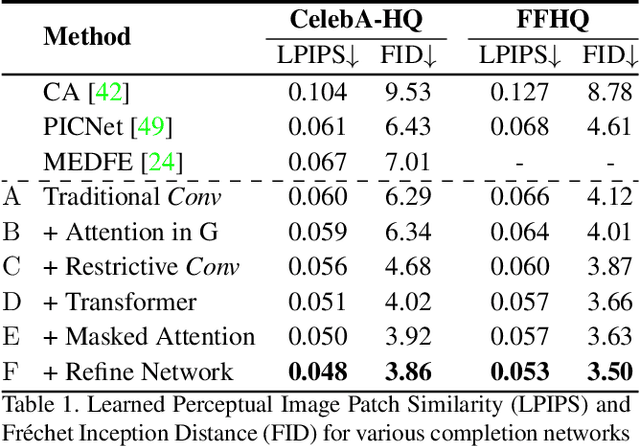
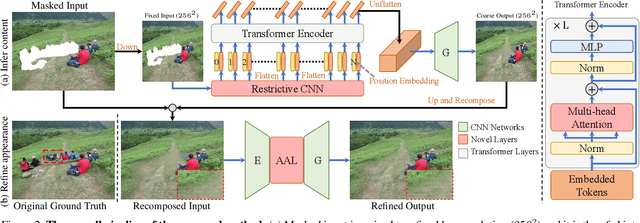
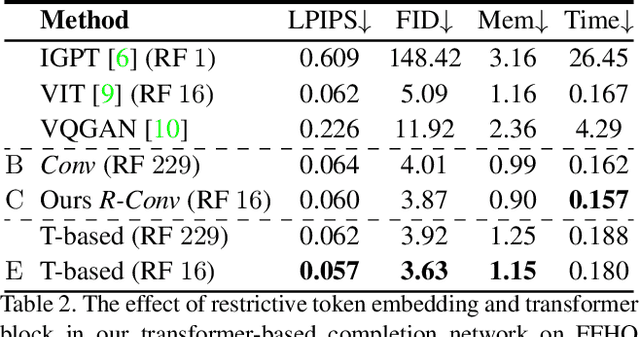
Bridging distant context interactions is important for high quality image completion with large masks. Previous methods attempting this via deep or large receptive field (RF) convolutions cannot escape from the dominance of nearby interactions, which may be inferior. In this paper, we propose treating image completion as a directionless sequence-to-sequence prediction task, and deploy a transformer to directly capture long-range dependence in the encoder in a first phase. Crucially, we employ a restrictive CNN with small and non-overlapping RF for token representation, which allows the transformer to explicitly model the long-range context relations with equal importance in all layers, without implicitly confounding neighboring tokens when larger RFs are used. In a second phase, to improve appearance consistency between visible and generated regions, a novel attention-aware layer (AAL) is introduced to better exploit distantly related features and also avoid the insular effect of standard attention. Overall, extensive experiments demonstrate superior performance compared to state-of-the-art methods on several datasets.
Reproducible Subjective Evaluation
Mar 08, 2022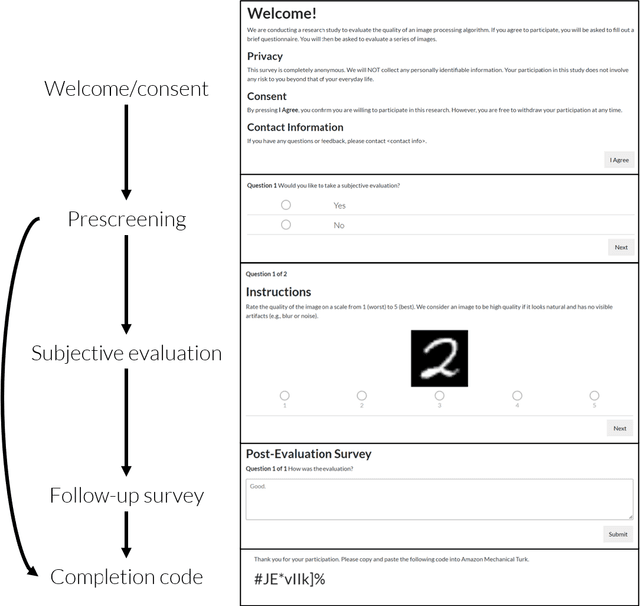

Human perceptual studies are the gold standard for the evaluation of many research tasks in machine learning, linguistics, and psychology. However, these studies require significant time and cost to perform. As a result, many researchers use objective measures that can correlate poorly with human evaluation. When subjective evaluations are performed, they are often not reported with sufficient detail to ensure reproducibility. We propose Reproducible Subjective Evaluation (ReSEval), an open-source framework for quickly deploying crowdsourced subjective evaluations directly from Python. ReSEval lets researchers launch A/B, ABX, Mean Opinion Score (MOS) and MUltiple Stimuli with Hidden Reference and Anchor (MUSHRA) tests on audio, image, text, or video data from a command-line interface or using one line of Python, making it as easy to run as objective evaluation. With ReSEval, researchers can reproduce each other's subjective evaluations by sharing a configuration file and the audio, image, text, or video files.