 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enhancing the Transferability via Feature-Momentum Adversarial Attack
Apr 22, 2022

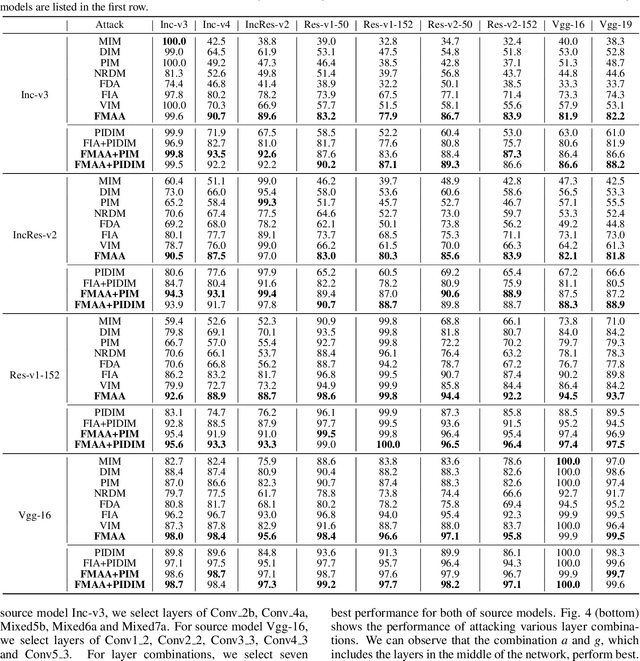
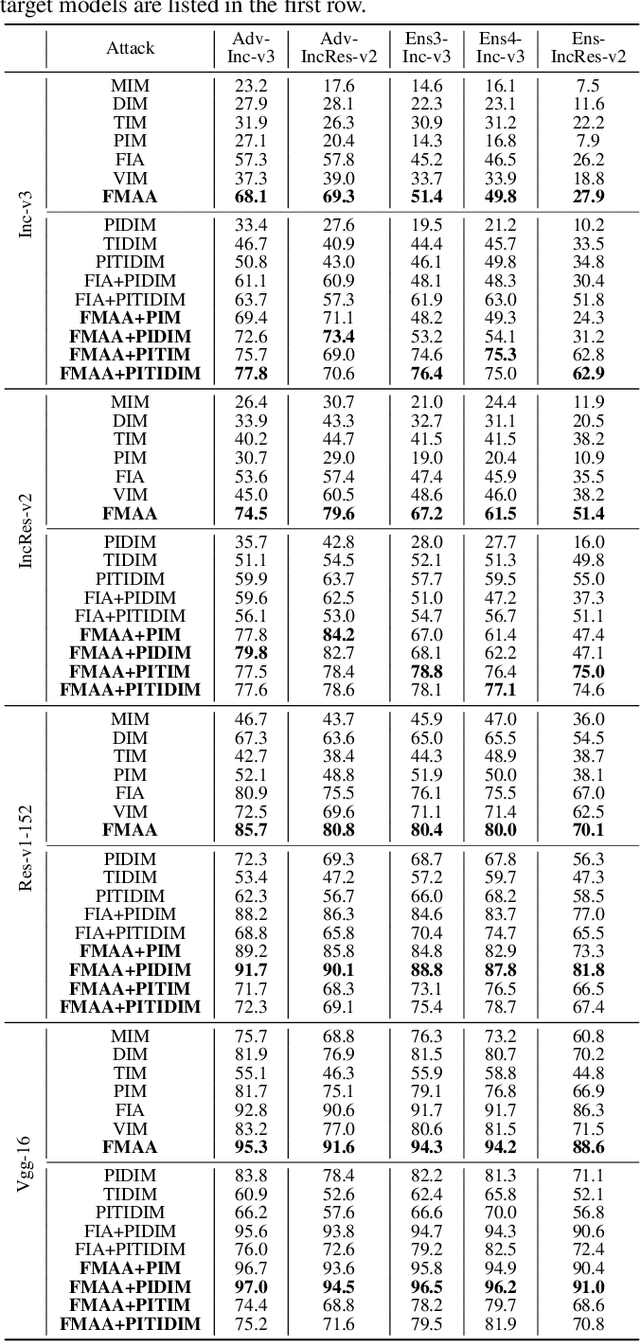
Transferable adversarial attack has drawn increasing attention due to their practical threaten to real-world applications. In particular, the feature-level adversarial attack is one recent branch that can enhance the transferability via disturbing the intermediate features. The existing methods usually create a guidance map for features, where the value indicates the importance of the corresponding feature element and then employs an iterative algorithm to disrupt the features accordingly. However, the guidance map is fixed in existing methods, which can not consistently reflect the behavior of networks as the image is changed during iteration. In this paper, we describe a new method called Feature-Momentum Adversarial Attack (FMAA) to further improve transferability. The key idea of our method is that we estimate a guidance map dynamically at each iteration using momentum to effectively disturb the category-relevant features. Extensive experiments demonstrate that our method significantly outperforms other state-of-the-art methods by a large margin on different target models.
A Framework for Event-based Computer Vision on a Mobile Device
May 13, 2022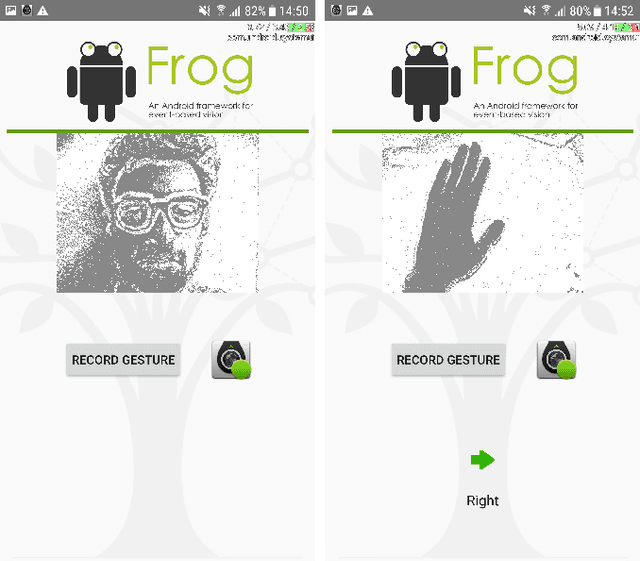
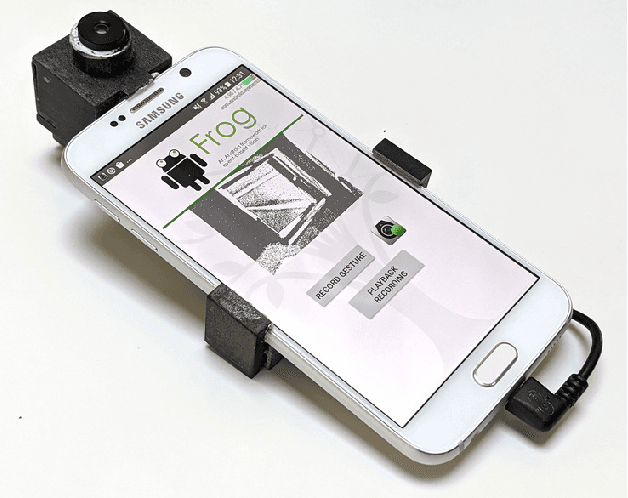
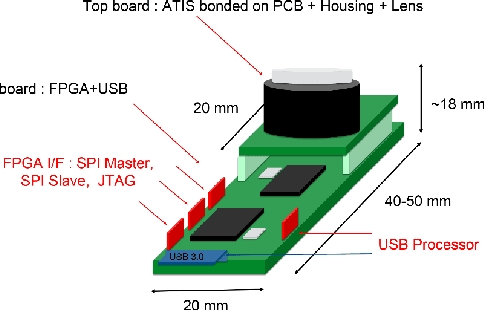
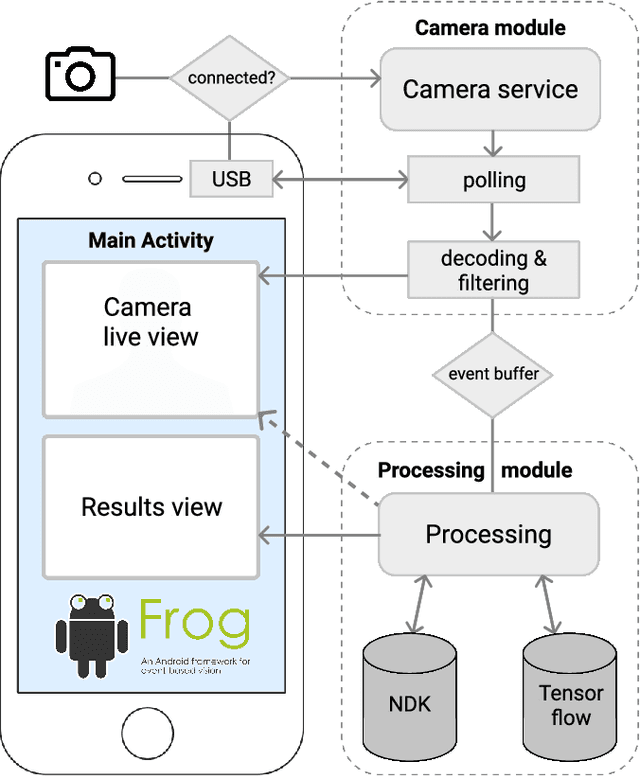
We present the first publicly available Android framework to stream data from an event camera directly to a mobile phone. Today's mobile devices handle a wider range of workloads than ever before and they incorporate a growing gamut of sensors that make devices smarter, more user friendly and secure. Conventional cameras in particular play a central role in such tasks, but they cannot record continuously, as the amount of redundant information recorded is costly to process. Bio-inspired event cameras on the other hand only record changes in a visual scene and have shown promising low-power applications that specifically suit mobile tasks such as face detection, gesture recognition or gaze tracking. Our prototype device is the first step towards embedding such an event camera into a battery-powered handheld device. The mobile framework allows us to stream events in real-time and opens up the possibilities for always-on and on-demand sensing on mobile phones. To liaise the asynchronous event camera output with synchronous von Neumann hardware, we look at how buffering events and processing them in batches can benefit mobile applications. We evaluate our framework in terms of latency and throughput and show examples of computer vision tasks that involve both event-by-event and pre-trained neural network methods for gesture recognition, aperture robust optical flow and grey-level image reconstruction from events. The code is available at https://github.com/neuromorphic-paris/frog
Weakly Supervised Object Localization as Domain Adaption
Mar 14, 2022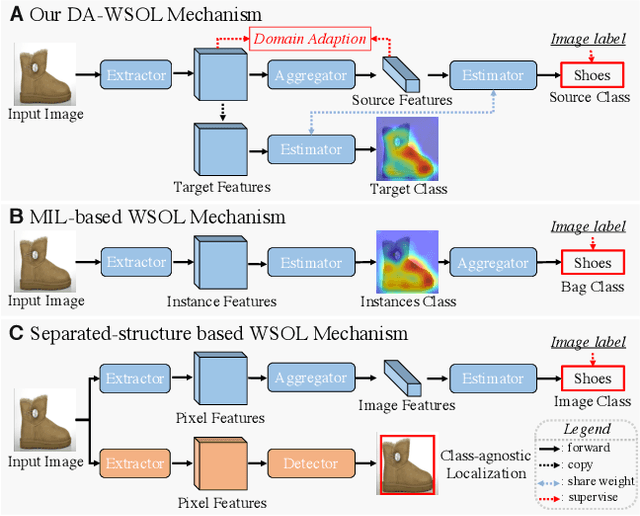
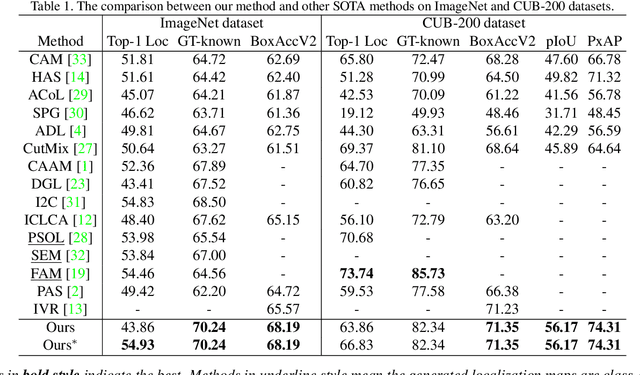
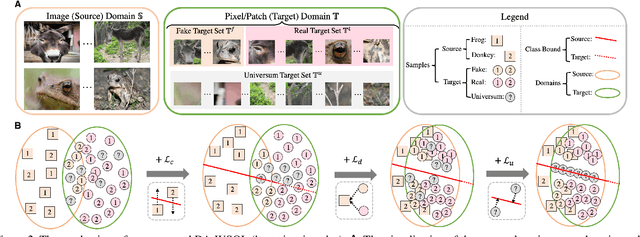
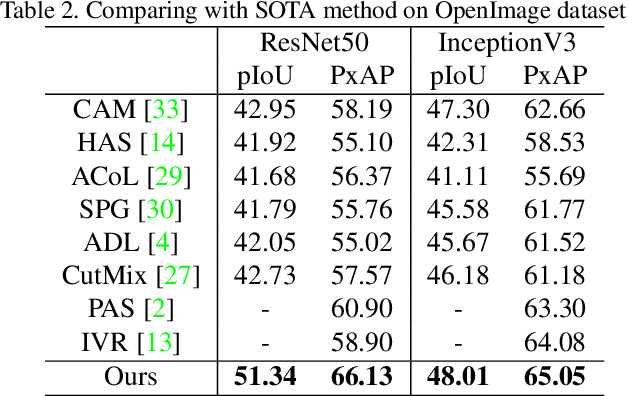
Weakly supervised object localization (WSOL) focuses on localizing objects only with the supervision of image-level classification masks. Most previous WSOL methods follow the classification activation map (CAM) that localizes objects based on the classification structure with the multi-instance learning (MIL) mechanism. However, the MIL mechanism makes CAM only activate discriminative object parts rather than the whole object, weakening its performance for localizing objects. To avoid this problem, this work provides a novel perspective that models WSOL as a domain adaption (DA) task, where the score estimator trained on the source/image domain is tested on the target/pixel domain to locate objects. Under this perspective, a DA-WSOL pipeline is designed to better engage DA approaches into WSOL to enhance localization performance. It utilizes a proposed target sampling strategy to select different types of target samples. Based on these types of target samples, domain adaption localization (DAL) loss is elaborated. It aligns the feature distribution between the two domains by DA and makes the estimator perceive target domain cues by Universum regularization. Experiments show that our pipeline outperforms SOTA methods on multi benchmarks. Code are released at \url{https://github.com/zh460045050/DA-WSOL_CVPR2022}.
TediGAN: Text-Guided Diverse Image Generation and Manipulation
Dec 06, 2020In this work, we propose TediGAN, a novel framework for multi-modal image generation and manipulation with textual descriptions. The proposed method consists of three components: StyleGAN inversion module, visual-linguistic similarity learning, and instance-level optimization. The inversion module is to train an image encoder to map real images to the latent space of a well-trained StyleGAN. The visual-linguistic similarity is to learn the text-image matching by mapping the image and text into a common embedding space. The instance-level optimization is for identity preservation in manipulation. Our model can provide the lowest effect guarantee, and produce diverse and high-quality images with an unprecedented resolution at 1024. Using a control mechanism based on style-mixing, our TediGAN inherently supports image synthesis with multi-modal inputs, such as sketches or semantic labels with or without instance (text or real image) guidance. To facilitate text-guided multi-modal synthesis, we propose the Multi-Modal CelebA-HQ, a large-scale dataset consisting of real face images and corresponding semantic segmentation map, sketch, and textual descriptions. Extensive experiments on the introduced dataset demonstrate the superior performance of our proposed method. Code and data are available at https://github.com/weihaox/TediGAN.
2D Image Relighting with Image-to-Image Translation
Jun 26, 2020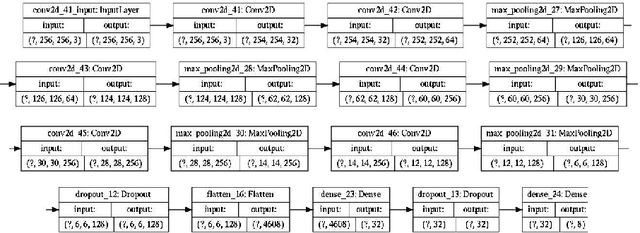
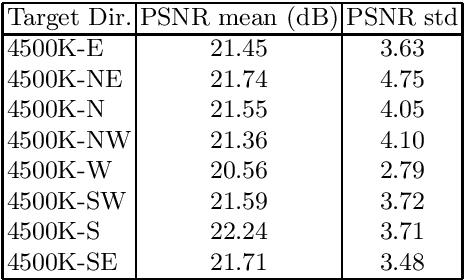
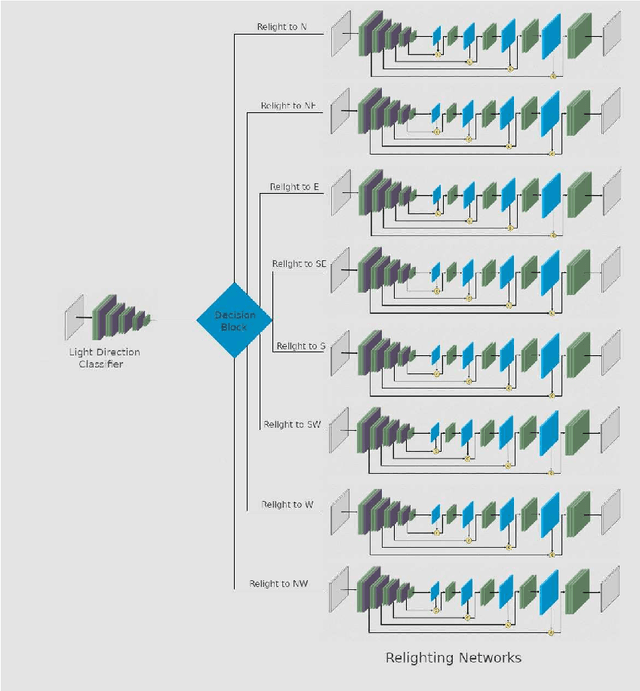
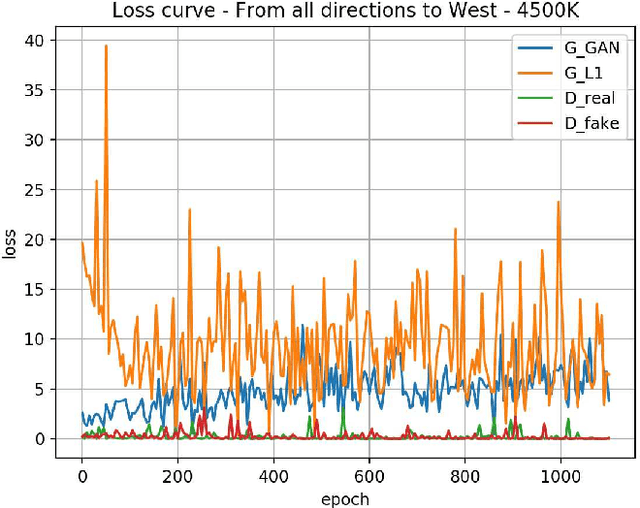
With the advent of Generative Adversarial Networks (GANs), a finer level of control in manipulating various features of an image has become possible. One example of such fine manipulation is changing the position of the light source in a scene. This is fundamentally an ill-posed problem, since it requires understanding the scene geometry to generate proper lighting effects. This problem is not a trivial one and can become even more complicated if we want to change the direction of the light source from any direction to a specific one. Here we provide our attempt to solve this problem using GANs. Specifically, pix2pix [arXiv:1611.07004] trained with the dataset VIDIT [arXiv:2005.05460] which contains images of the same scene with different types of light temperature and 8 different light source positions (N, NE, E, SE, S, SW, W, NW). The results are 8 neural networks trained to be able to change the direction of the light source from any direction to one of the 8 previously mentioned. Additionally, we provide, as a tool, a simple CNN trained to identify the direction of the light source in an image.
Ray Tracing-Guided Design of Plenoptic Cameras
Mar 09, 2022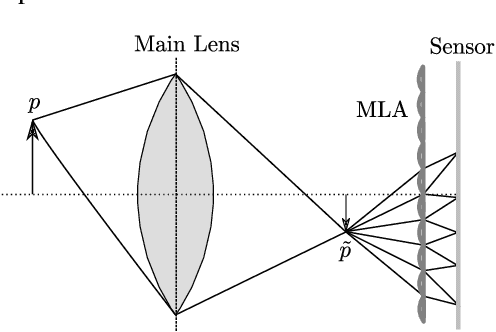


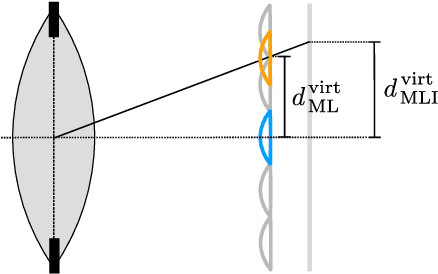
The design of a plenoptic camera requires the combination of two dissimilar optical systems, namely a main lens and an array of microlenses. And while the construction process of a conventional camera is mainly concerned with focusing the image onto a single plane, in the case of plenoptic cameras there can be additional requirements such as a predefined depth of field or a desired range of disparities in neighboring microlens images. Due to this complexity, the manual creation of multiple plenoptic camera setups is often a time-consuming task. In this work we assume a simulation framework as well as the main lens data given and present a method to calculate the remaining aperture, sensor and microlens array parameters under different sets of constraints. Our ray tracing-based approach is shown to result in models outperforming their pendants generated with the commonly used paraxial approximations in terms of image quality, while still meeting the desired constraints. Both the implementation and evaluation setup including 30 plenoptic camera designs are made publicly available.
Computer-aided Recognition and Assessment of a Porous Bioelastomer on Ultrasound Images for Regenerative Medicine Applications
Jan 31, 2022Biodegradable elastic scaffolds have attracted more and more attention in the field of soft tissue repair and tissue engineering. These scaffolds made of porous bioelastomers support tissue ingrowth along with their own degradation. It is necessary to develop a computer-aided analyzing method based on ultrasound images to identify the degradation performance of the scaffold, not only to obviate the need to do destructive testing, but also to monitor the scaffold's degradation and tissue ingrowth over time. It is difficult using a single traditional image processing algorithm to extract continuous and accurate contour of a porous bioelastomer. This paper proposes a joint algorithm for the bioelastomer's contour detection and a texture feature extraction method for monitoring the degradation behavior of the bioelastomer. Mean-shift clustering method is used to obtain the bioelastomer's and native tissue's clustering feature information. Then the OTSU image binarization method automatically selects the optimal threshold value to convert the grayscale ultrasound image into a binary image. The Canny edge detector is used to extract the complete bioelastomer's contour. The first-order and second-order statistical features of texture are extracted. The proposed joint algorithm not only achieves the ideal extraction of the bioelastomer's contours in ultrasound images, but also gives valuable feedback of the degradation behavior of the bioelastomer at the implant site based on the changes of texture characteristics and contour area. The preliminary results of this study suggest that the proposed computer-aided image processing techniques have values and potentials in the non-invasive analysis of tissue scaffolds in vivo based on ultrasound images and may help tissue engineers evaluate the tissue scaffold's degradation and cellular ingrowth progress and improve the scaffold designs.
Event-based Timestamp Image Encoding Network for Human Action Recognition and Anticipation
Apr 12, 2021

Event camera is an asynchronous, high frequencyvision sensor with low power consumption, which is suitable forhuman action understanding task. It is vital to encode the spatial-temporal information of event data properly and use standardcomputer vision tool to learn from the data. In this work, wepropose a timestamp image encoding 2D network, which takes theencoded spatial-temporal images with polarity information of theevent data as input and output the action label. In addition, wepropose a future timestamp image generator to generate futureaction information to aid the model to anticipate the humanaction when the action is not completed. Experiment results showthat our method can achieve the same level of performance asthose RGB-based benchmarks on real world action recognition,and also achieve the state of the art (SOTA) result on gesturerecognition. Our future timestamp image generating model caneffectively improve the prediction accuracy when the action is notcompleted. We also provide insight discussion on the importanceof motion and appearance information in action recognition andanticipation.
Edge-enhanced Feature Distillation Network for Efficient Super-Resolution
Apr 19, 2022
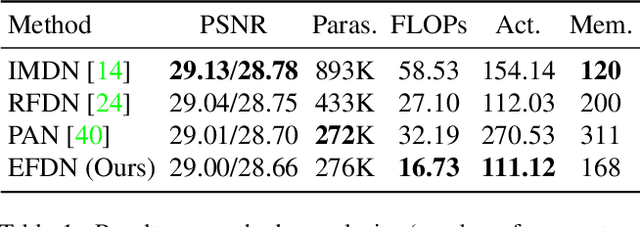
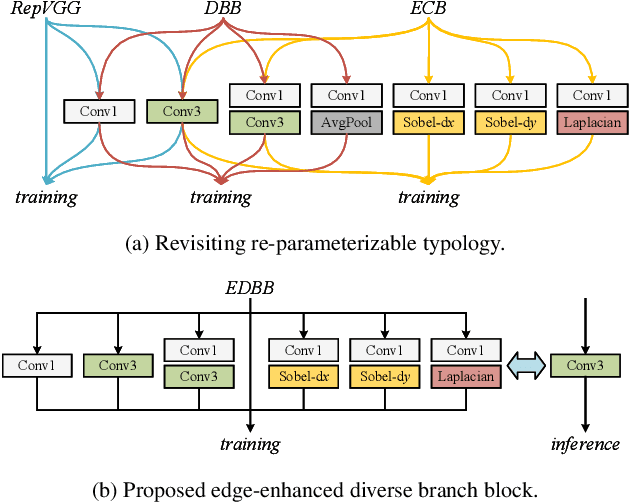

With the recently massive development in convolution neural networks, numerous lightweight CNN-based image super-resolution methods have been proposed for practical deployments on edge devices. However, most existing methods focus on one specific aspect: network or loss design, which leads to the difficulty of minimizing the model size. To address the issue, we conclude block devising, architecture searching, and loss design to obtain a more efficient SR structure. In this paper, we proposed an edge-enhanced feature distillation network, named EFDN, to preserve the high-frequency information under constrained resources. In detail, we build an edge-enhanced convolution block based on the existing reparameterization methods. Meanwhile, we propose edge-enhanced gradient loss to calibrate the reparameterized path training. Experimental results show that our edge-enhanced strategies preserve the edge and significantly improve the final restoration quality. Code is available at https://github.com/icandle/EFDN.
Dynamic Backdoors with Global Average Pooling
Mar 04, 2022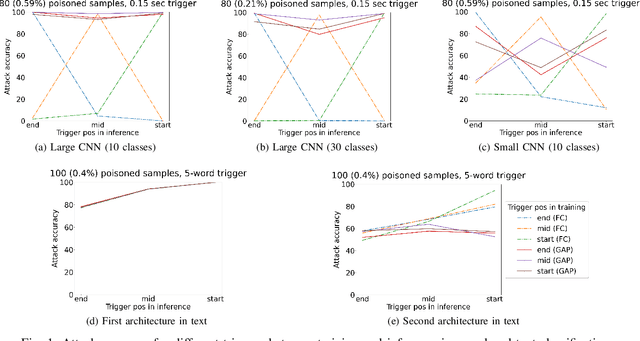
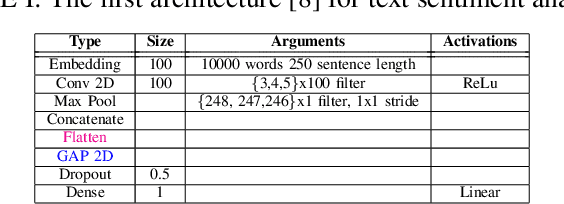
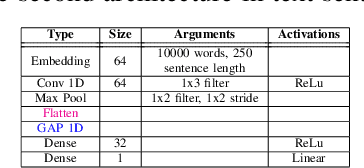
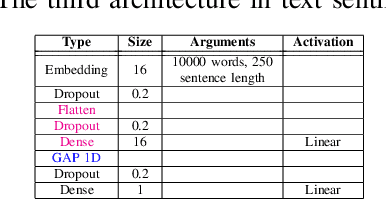
Outsourced training and machine learning as a service have resulted in novel attack vectors like backdoor attacks. Such attacks embed a secret functionality in a neural network activated when the trigger is added to its input. In most works in the literature, the trigger is static, both in terms of location and pattern. The effectiveness of various detection mechanisms depends on this property. It was recently shown that countermeasures in image classification, like Neural Cleanse and ABS, could be bypassed with dynamic triggers that are effective regardless of their pattern and location. Still, such backdoors are demanding as they require a large percentage of poisoned training data. In this work, we are the first to show that dynamic backdoor attacks could happen due to a global average pooling layer without increasing the percentage of the poisoned training data. Nevertheless, our experiments in sound classification, text sentiment analysis, and image classification show this to be very difficult in practice.