 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image/Video Deep Anomaly Detection: A Survey
Mar 02, 2021
The considerable significance of Anomaly Detection (AD) problem has recently drawn the attention of many researchers. Consequently, the number of proposed methods in this research field has been increased steadily. AD strongly correlates with the important computer vision and image processing tasks such as image/video anomaly, irregularity and sudden event detection. More recently, Deep Neural Networks (DNNs) offer a high performance set of solutions, but at the expense of a heavy computational cost. However, there is a noticeable gap between the previously proposed methods and an applicable real-word approach. Regarding the raised concerns about AD as an ongoing challenging problem, notably in images and videos, the time has come to argue over the pitfalls and prospects of methods have attempted to deal with visual AD tasks. Hereupon, in this survey we intend to conduct an in-depth investigation into the images/videos deep learning based AD methods. We also discuss current challenges and future research directions thoroughly.
Iterative Facial Image Inpainting using Cyclic Reverse Generator
Jan 18, 2021
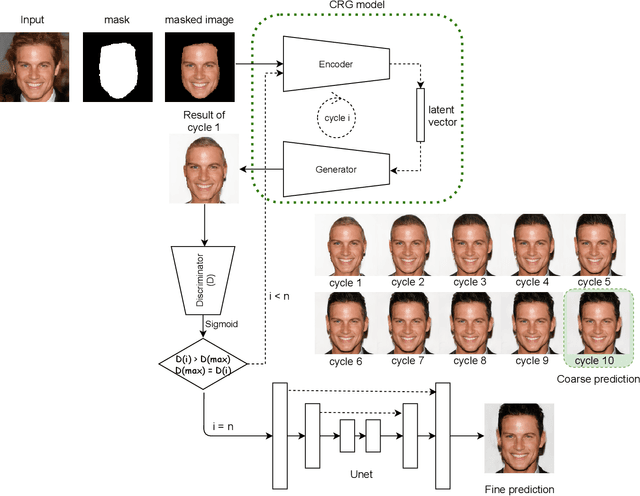

Facial image inpainting is a challenging problem as it requires generating new pixels that include semantic information for masked key components in a face, e.g., eyes and nose. Recently, remarkable methods have been proposed in this field. Most of these approaches use encoder-decoder architectures and have different limitations such as allowing unique results for a given image and a particular mask. Alternatively, some approaches generate promising results using different masks with generator networks. However, these approaches are optimization-based and usually require quite a number of iterations. In this paper, we propose an efficient solution to the facial image painting problem using the Cyclic Reverse Generator (CRG) architecture, which provides an encoder-generator model. We use the encoder to embed a given image to the generator space and incrementally inpaint the masked regions until a plausible image is generated; a discriminator network is utilized to assess the generated images during the iterations. We empirically observed that only a few iterations are sufficient to generate realistic images with the proposed model. After the generation process, for the post processing, we utilize a Unet model that we trained specifically for this task to remedy the artifacts close to the mask boundaries. Our method allows applying sketch-based inpaintings, using variety of mask types, and producing multiple and diverse results. We qualitatively compared our method with the state-of-the-art models and observed that our method can compete with the other models in all mask types; it is particularly better in images where larger masks are utilized.
High-Resolution Deep Image Matting
Sep 14, 2020
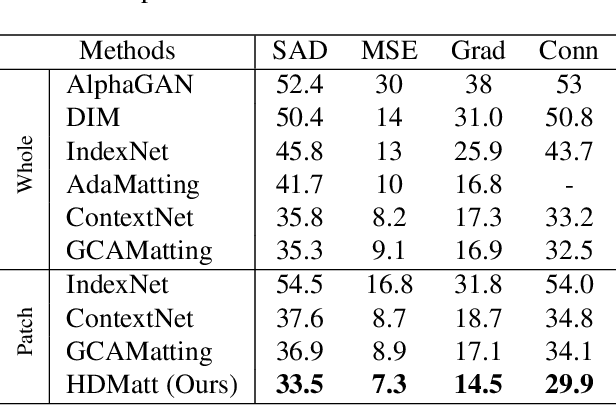
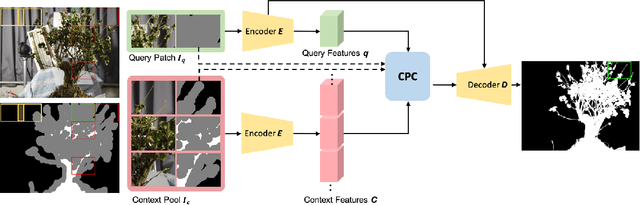
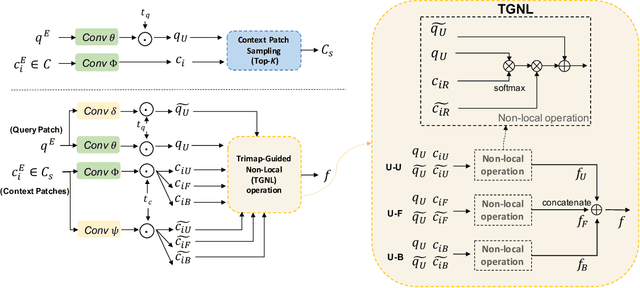
Image matting is a key technique for image and video editing and composition. Conventionally, deep learning approaches take the whole input image and an associated trimap to infer the alpha matte using convolutional neural networks. Such approaches set state-of-the-arts in image matting; however, they may fail in real-world matting applications due to hardware limitations, since real-world input images for matting are mostly of very high resolution. In this paper, we propose HDMatt, a first deep learning based image matting approach for high-resolution inputs. More concretely, HDMatt runs matting in a patch-based crop-and-stitch manner for high-resolution inputs with a novel module design to address the contextual dependency and consistency issues between different patches. Compared with vanilla patch-based inference which computes each patch independently, we explicitly model the cross-patch contextual dependency with a newly-proposed Cross-Patch Contextual module (CPC) guided by the given trimap. Extensive experiments demonstrate the effectiveness of the proposed method and its necessity for high-resolution inputs. Our HDMatt approach also sets new state-of-the-art performance on Adobe Image Matting and AlphaMatting benchmarks and produce impressive visual results on more real-world high-resolution images.
Ray Tracing-Guided Design of Plenoptic Cameras
Mar 09, 2022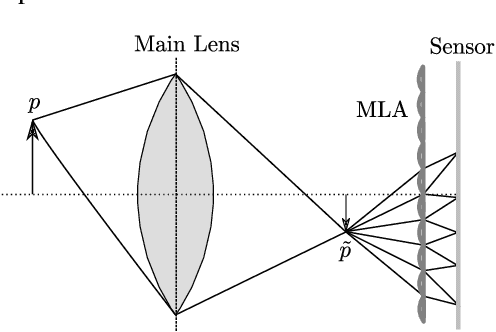


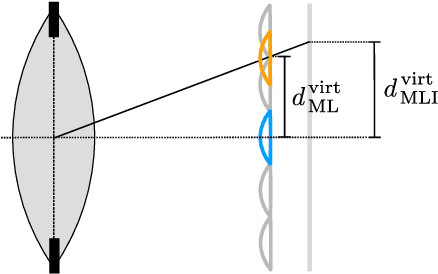
The design of a plenoptic camera requires the combination of two dissimilar optical systems, namely a main lens and an array of microlenses. And while the construction process of a conventional camera is mainly concerned with focusing the image onto a single plane, in the case of plenoptic cameras there can be additional requirements such as a predefined depth of field or a desired range of disparities in neighboring microlens images. Due to this complexity, the manual creation of multiple plenoptic camera setups is often a time-consuming task. In this work we assume a simulation framework as well as the main lens data given and present a method to calculate the remaining aperture, sensor and microlens array parameters under different sets of constraints. Our ray tracing-based approach is shown to result in models outperforming their pendants generated with the commonly used paraxial approximations in terms of image quality, while still meeting the desired constraints. Both the implementation and evaluation setup including 30 plenoptic camera designs are made publicly available.
Lipschitz Regularized CycleGAN for Improving Semantic Robustness in Unpaired Image-to-image Translation
Dec 09, 2020
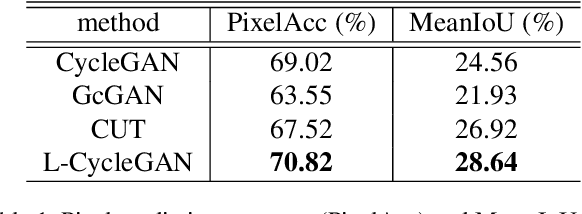

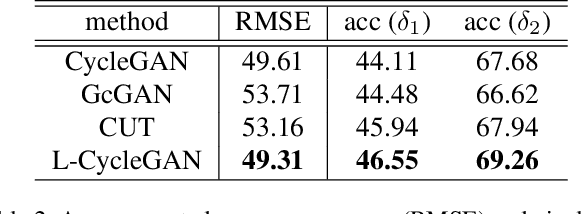
For unpaired image-to-image translation tasks, GAN-based approaches are susceptible to semantic flipping, i.e., contents are not preserved consistently. We argue that this is due to (1) the difference in semantic statistics between source and target domains and (2) the learned generators being non-robust. In this paper, we proposed a novel approach, Lipschitz regularized CycleGAN, for improving semantic robustness and thus alleviating the semantic flipping issue. During training, we add a gradient penalty loss to the generators, which encourages semantically consistent transformations. We evaluate our approach on multiple common datasets and compare with several existing GAN-based methods. Both quantitative and visual results suggest the effectiveness and advantage of our approach in producing robust transformations with fewer semantic flipping.
Planes vs. Chairs: Category-guided 3D shape learning without any 3D cues
Apr 21, 2022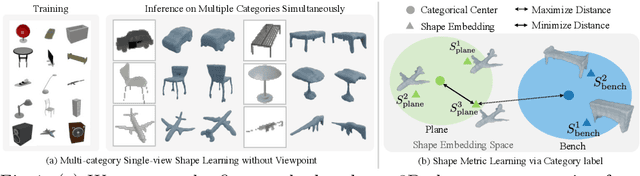

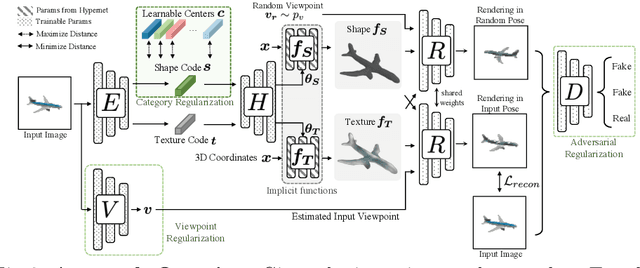
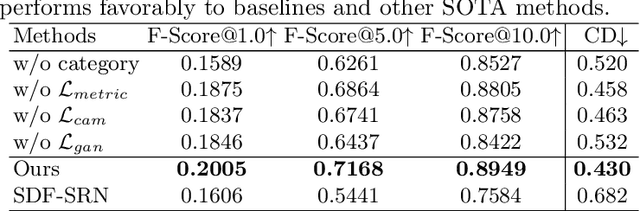
We present a novel 3D shape reconstruction method which learns to predict an implicit 3D shape representation from a single RGB image. Our approach uses a set of single-view images of multiple object categories without viewpoint annotation, forcing the model to learn across multiple object categories without 3D supervision. To facilitate learning with such minimal supervision, we use category labels to guide shape learning with a novel categorical metric learning approach. We also utilize adversarial and viewpoint regularization techniques to further disentangle the effects of viewpoint and shape. We obtain the first results for large-scale (more than 50 categories) single-viewpoint shape prediction using a single model without any 3D cues. We are also the first to examine and quantify the benefit of class information in single-view supervised 3D shape reconstruction. Our method achieves superior performance over state-of-the-art methods on ShapeNet-13, ShapeNet-55 and Pascal3D+.
Towards a Unified Approach to Homography Estimation Using Image Features and Pixel Intensities
Feb 20, 2022
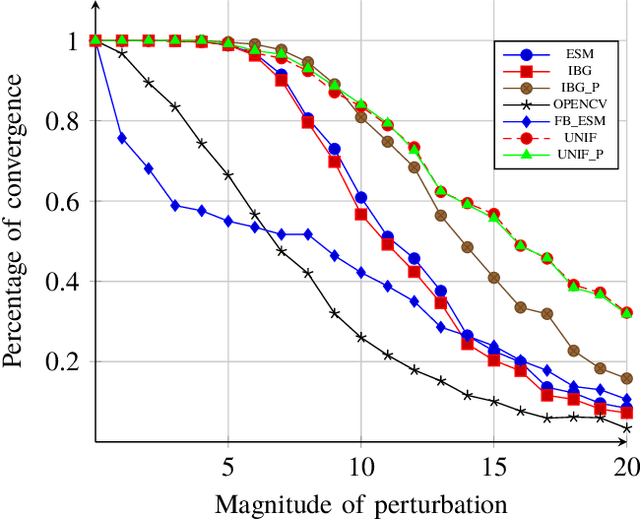
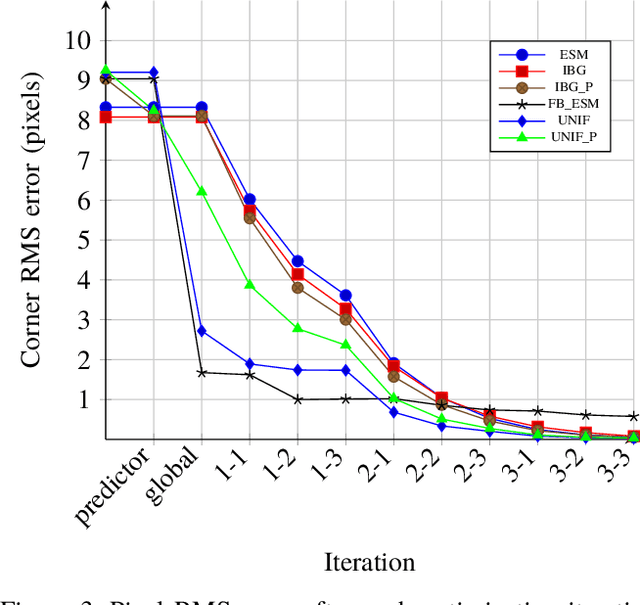
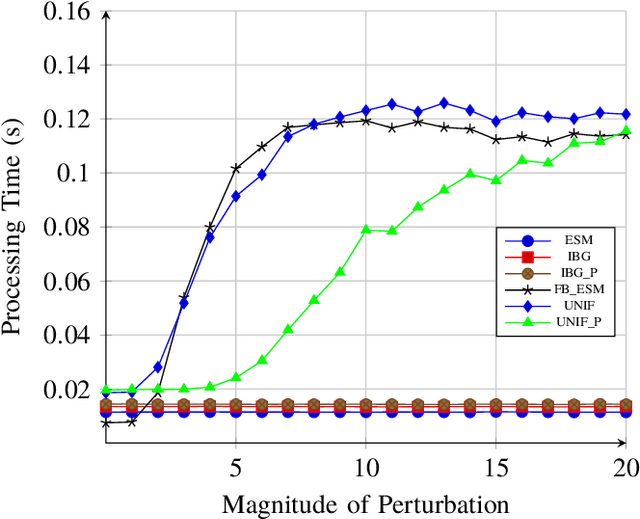
The homography matrix is a key component in various vision-based robotic tasks. Traditionally, homography estimation algorithms are classified into feature- or intensity-based. The main advantages of the latter are their versatility, accuracy, and robustness to arbitrary illumination changes. On the other hand, they have a smaller domain of convergence than the feature-based solutions. Their combination is hence promising, but existing techniques only apply them sequentially. This paper proposes a new hybrid method that unifies both classes into a single nonlinear optimization procedure, applies the same minimization method, and uses the same homography parametrization and warping function. Experimental validation using a classical testing framework shows that the proposed unified approach has improved convergence properties compared to each individual class. These are also demonstrated in a visual tracking application. As a final contribution, our ready-to-use implementation of the algorithm is made publicly available to the research community.
GeoSim: Photorealistic Image Simulation with Geometry-Aware Composition
Jan 16, 2021
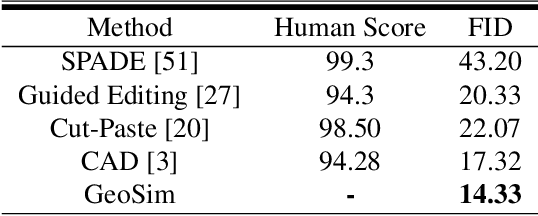
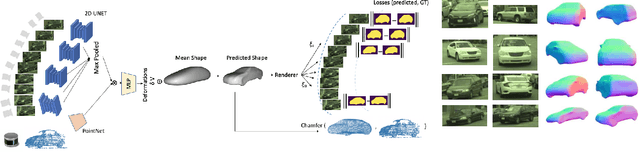

Scalable sensor simulation is an important yet challenging open problem for safety-critical domains such as self-driving. Current work in image simulation either fail to be photorealistic or do not model the 3D environment and the dynamic objects within, losing high-level control and physical realism. In this paper, we present GeoSim, a geometry-aware image composition process that synthesizes novel urban driving scenes by augmenting existing images with dynamic objects extracted from other scenes and rendered at novel poses. Towards this goal, we first build a diverse bank of 3D objects with both realistic geometry and appearance from sensor data. During simulation, we perform a novel geometry-aware simulation-by-composition procedure which 1) proposes plausible and realistic object placements into a given scene, 2) renders novel views of dynamic objects from the asset bank, and 3) composes and blends the rendered image segments. The resulting synthetic images are photorealistic, traffic-aware, and geometrically consistent, allowing image simulation to scale to complex use cases. We demonstrate two such important applications: long-range realistic video simulation across multiple camera sensors, and synthetic data generation for data augmentation on downstream segmentation tasks.
Semantically Video Coding: Instill Static-Dynamic Clues into Structured Bitstream for AI Tasks
Jan 25, 2022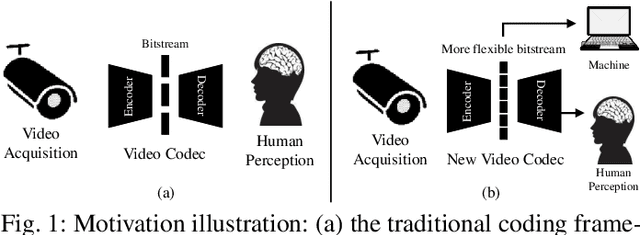
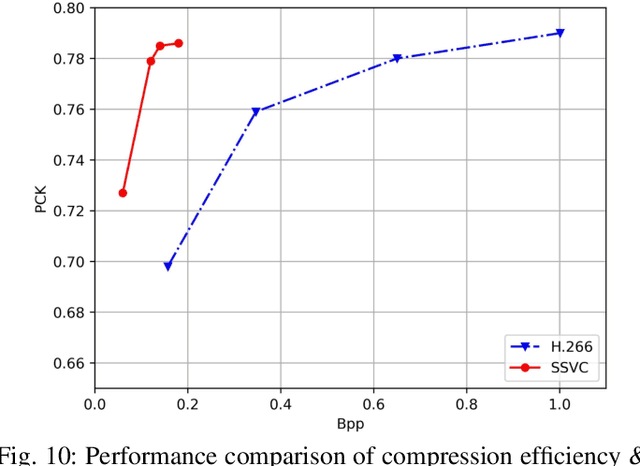
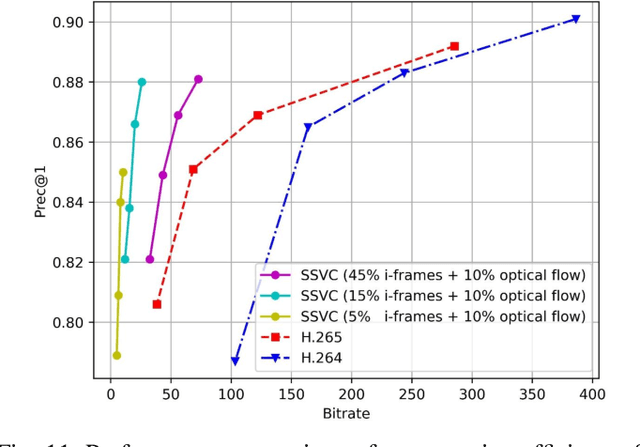
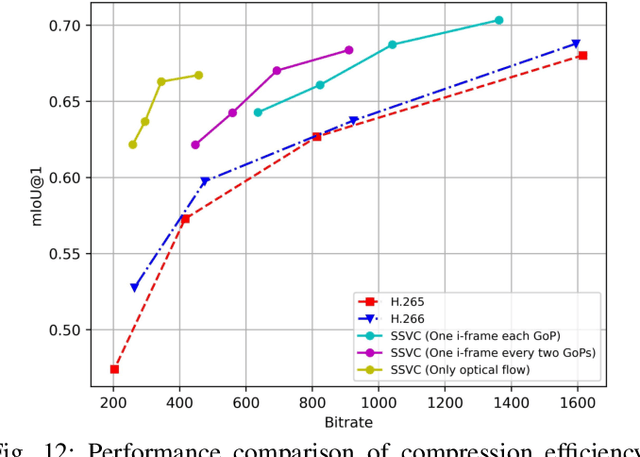
Traditional media coding schemes typically encode image/video into a semantic-unknown binary stream, which fails to directly support downstream intelligent tasks at the bitstream level. Semantically Structured Image Coding (SSIC) framework makes the first attempt to enable decoding-free or partial-decoding image intelligent task analysis via a Semantically Structured Bitstream (SSB). However, the SSIC only considers image coding and its generated SSB only contains the static object information. In this paper, we extend the idea of semantically structured coding from video coding perspective and propose an advanced Semantically Structured Video Coding (SSVC) framework to support heterogeneous intelligent applications. Video signals contain more rich dynamic motion information and exist more redundancy due to the similarity between adjacent frames. Thus, we present a reformulation of semantically structured bitstream (SSB) in SSVC which contains both static object characteristics and dynamic motion clues. Specifically, we introduce optical flow to encode continuous motion information and reduce cross-frame redundancy via a predictive coding architecture, then the optical flow and residual information are reorganized into SSB, which enables the proposed SSVC could better adaptively support video-based downstream intelligent applications. Extensive experiments demonstrate that the proposed SSVC framework could directly support multiple intelligent tasks just depending on a partially decoded bitstream. This avoids the full bitstream decompression and thus significantly saves bitrate/bandwidth consumption for intelligent analytics. We verify this point on the tasks of image object detection, pose estimation, video action recognition, video object segmentation, etc.
Viko 2.0: A Hierarchical Gecko-inspired Adhesive Gripper with Visuotactile Sensor
Apr 21, 2022
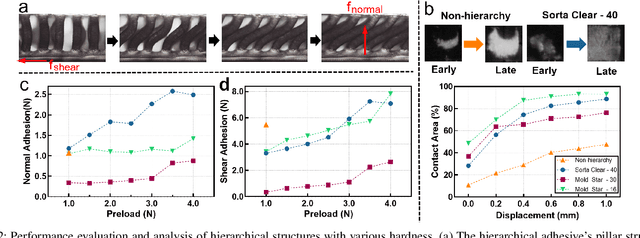
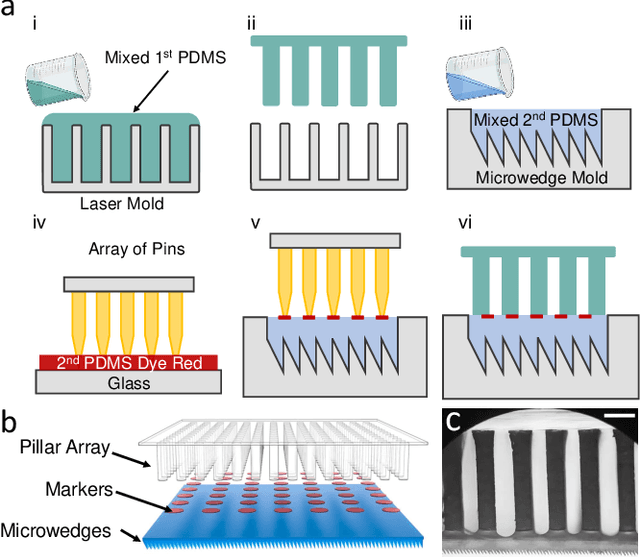
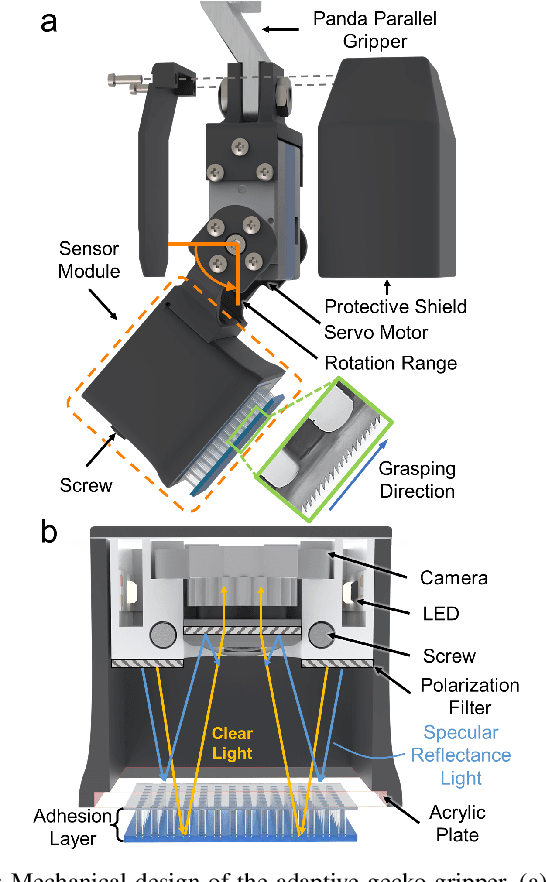
Robotic grippers with visuotactile sensors have access to rich tactile information for grasping tasks but encounter difficulty in partially encompassing large objects with sufficient grip force. While hierarchical gecko-inspired adhesives are a potential technique for bridging performance gaps, they require a large contact area for efficient usage. In this work, we present a new version of an adaptive gecko gripper called Viko 2.0 that effectively combines the advantage of adhesives and visuotactile sensors. Compared with a non-hierarchical structure, a hierarchical structure with a multimaterial design achieves approximately a 1.5 times increase in normal adhesion and double in contact area. The integrated visuotactile sensor captures a deformation image of the hierarchical structure and provides a real-time measurement of contact area, shear force, and incipient slip detection at 24 Hz. The gripper is implemented on a robotic arm to demonstrate an adaptive grasping pose based on contact area, and grasps objects with a wide range of geometries and textures.