 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Meta-Learning Approach for Medical Image Registration
Apr 21, 2021
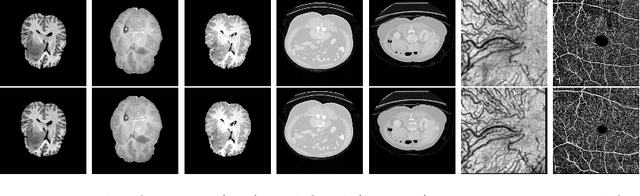
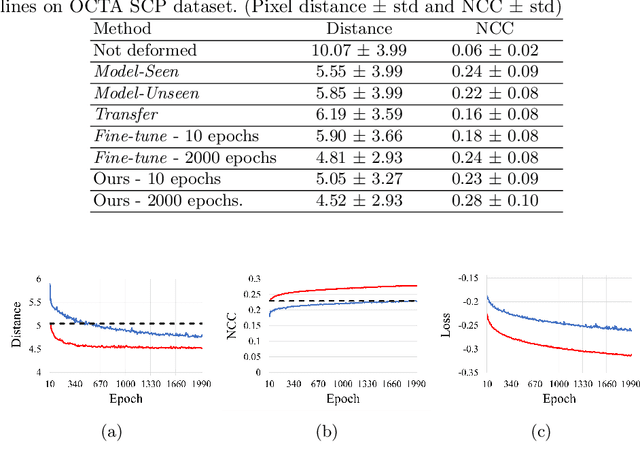
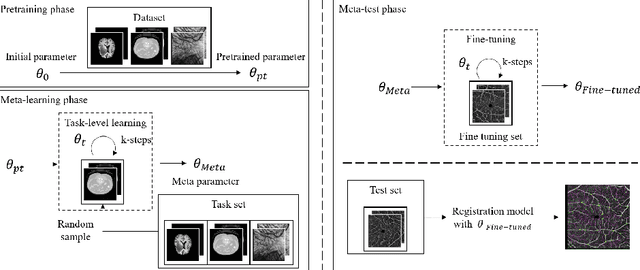
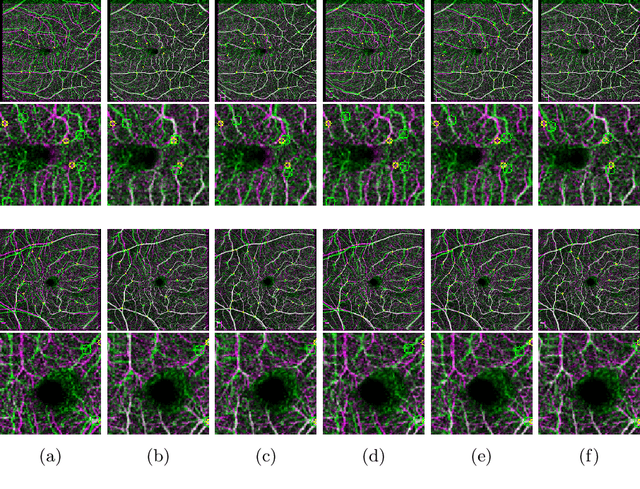
Non-rigid registration is a necessary but challenging task in medical imaging studies. Recently, unsupervised registration models have shown good performance, but they often require a large-scale training dataset and long training times. Therefore, in real world application where only dozens to hundreds of image pairs are available, existing models cannot be practically used. To address these limitations, we propose a novel unsupervised registration model which is integrated with a gradient-based meta learning framework. In particular, we train a meta learner which finds an initialization point of parameters by utilizing a variety of existing registration datasets. To quickly adapt to various tasks, the meta learner was updated to get close to the center of parameters which are fine-tuned for each registration task. Thereby, our model can adapt to unseen domain tasks via a short fine-tuning process and perform accurate registration. To verify the superiority of our model, we train the model for various 2D medical image registration tasks such as retinal choroid Optical Coherence Tomography Angiography (OCTA), CT organs, and brain MRI scans and test on registration of retinal OCTA Superficial Capillary Plexus (SCP). In our experiments, the proposed model obtained significantly improved performance in terms of accuracy and training time compared to other registration models.
Industrial Style Transfer with Large-scale Geometric Warping and Content Preservation
Mar 24, 2022
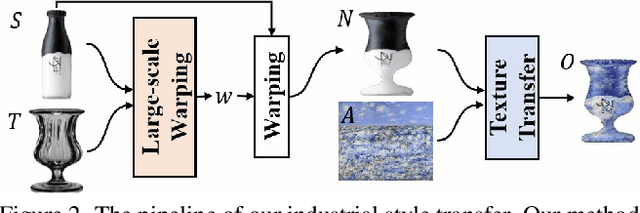
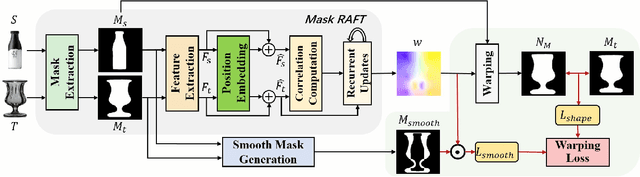
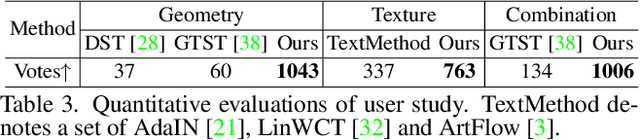
We propose a novel style transfer method to quickly create a new visual product with a nice appearance for industrial designers' reference. Given a source product, a target product, and an art style image, our method produces a neural warping field that warps the source shape to imitate the geometric style of the target and a neural texture transformation network that transfers the artistic style to the warped source product. Our model, Industrial Style Transfer (InST), consists of large-scale geometric warping (LGW) and interest-consistency texture transfer (ICTT). LGW aims to explore an unsupervised transformation between the shape masks of the source and target products for fitting large-scale shape warping. Furthermore, we introduce a mask smoothness regularization term to prevent the abrupt changes of the details of the source product. ICTT introduces an interest regularization term to maintain important contents of the warped product when it is stylized by using the art style image. Extensive experimental results demonstrate that InST achieves state-of-the-art performance on multiple visual product design tasks, e.g., companies' snail logos and classical bottles (please see Fig. 1). To the best of our knowledge, we are the first to extend the neural style transfer method to create industrial product appearances. Project page: \ulr{https://jcyang98.github.io/InST/home.html}. Code available at: \url{https://github.com/jcyang98/InST}.
Template-Free Try-on Image Synthesis via Semantic-guided Optimization
Feb 06, 2021
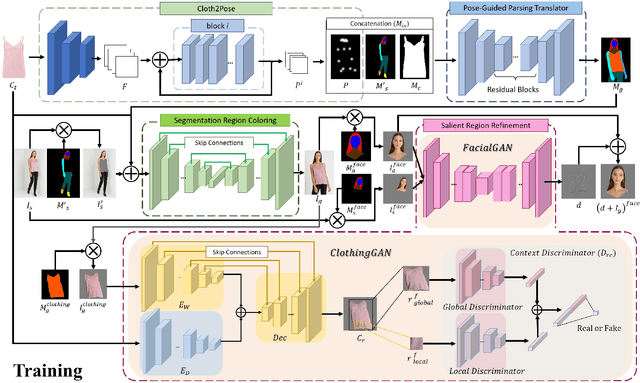


The virtual try-on task is so attractive that it has drawn considerable attention in the field of computer vision. However, presenting the three-dimensional (3D) physical characteristic (e.g., pleat and shadow) based on a 2D image is very challenging. Although there have been several previous studies on 2D-based virtual try-on work, most 1) required user-specified target poses that are not user-friendly and may not be the best for the target clothing, and 2) failed to address some problematic cases, including facial details, clothing wrinkles and body occlusions. To address these two challenges, in this paper, we propose an innovative template-free try-on image synthesis (TF-TIS) network. The TF-TIS first synthesizes the target pose according to the user-specified in-shop clothing. Afterward, given an in-shop clothing image, a user image, and a synthesized pose, we propose a novel model for synthesizing a human try-on image with the target clothing in the best fitting pose. The qualitative and quantitative experiments both indicate that the proposed TF-TIS outperforms the state-of-the-art methods, especially for difficult cases.
A Framework for Event-based Computer Vision on a Mobile Device
May 13, 2022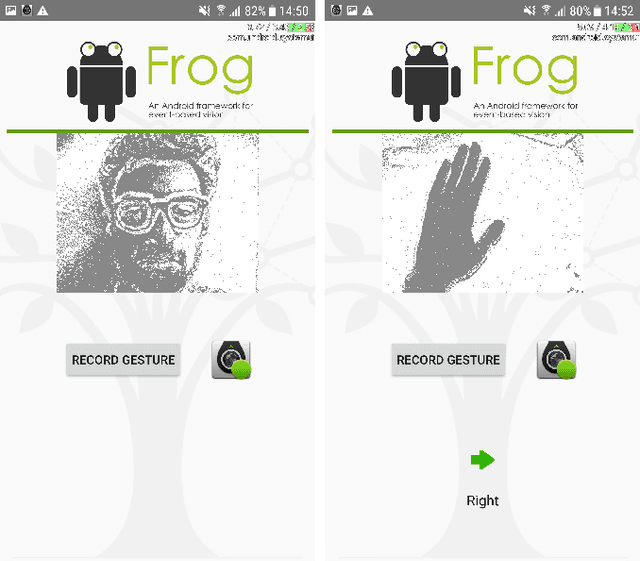
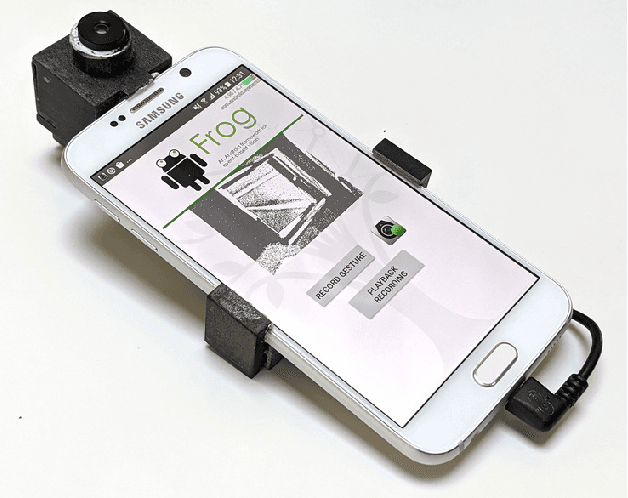
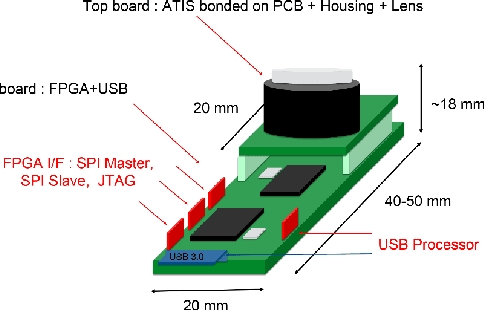
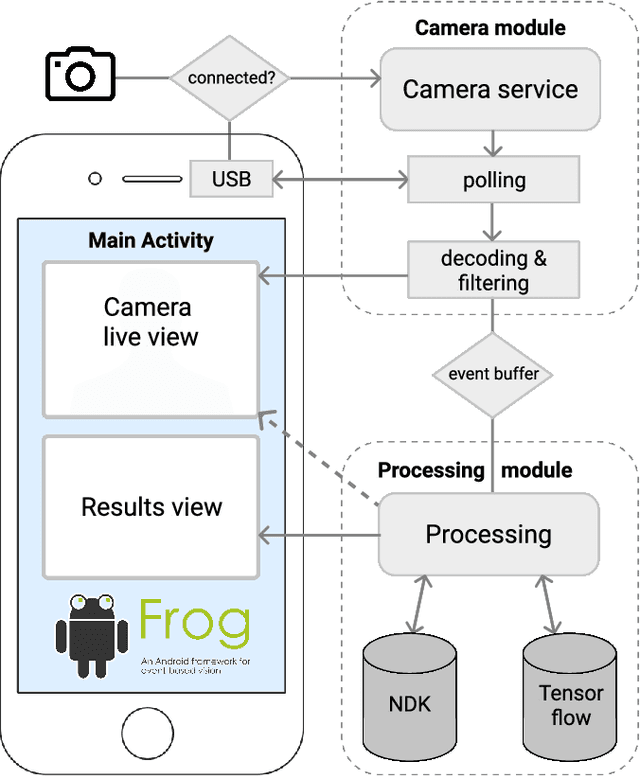
We present the first publicly available Android framework to stream data from an event camera directly to a mobile phone. Today's mobile devices handle a wider range of workloads than ever before and they incorporate a growing gamut of sensors that make devices smarter, more user friendly and secure. Conventional cameras in particular play a central role in such tasks, but they cannot record continuously, as the amount of redundant information recorded is costly to process. Bio-inspired event cameras on the other hand only record changes in a visual scene and have shown promising low-power applications that specifically suit mobile tasks such as face detection, gesture recognition or gaze tracking. Our prototype device is the first step towards embedding such an event camera into a battery-powered handheld device. The mobile framework allows us to stream events in real-time and opens up the possibilities for always-on and on-demand sensing on mobile phones. To liaise the asynchronous event camera output with synchronous von Neumann hardware, we look at how buffering events and processing them in batches can benefit mobile applications. We evaluate our framework in terms of latency and throughput and show examples of computer vision tasks that involve both event-by-event and pre-trained neural network methods for gesture recognition, aperture robust optical flow and grey-level image reconstruction from events. The code is available at https://github.com/neuromorphic-paris/frog
Multi-Domain Multi-Definition Landmark Localization for Small Datasets
Mar 19, 2022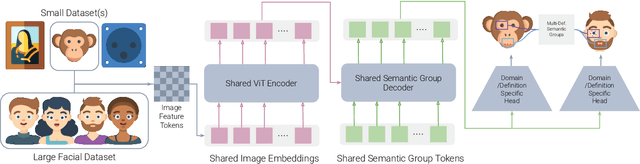
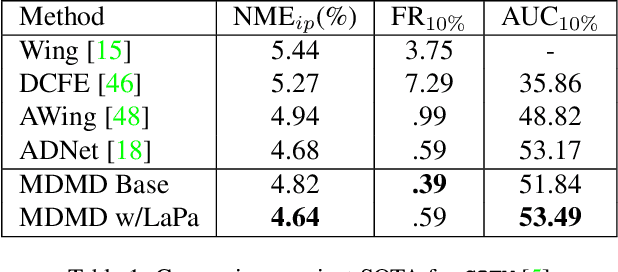

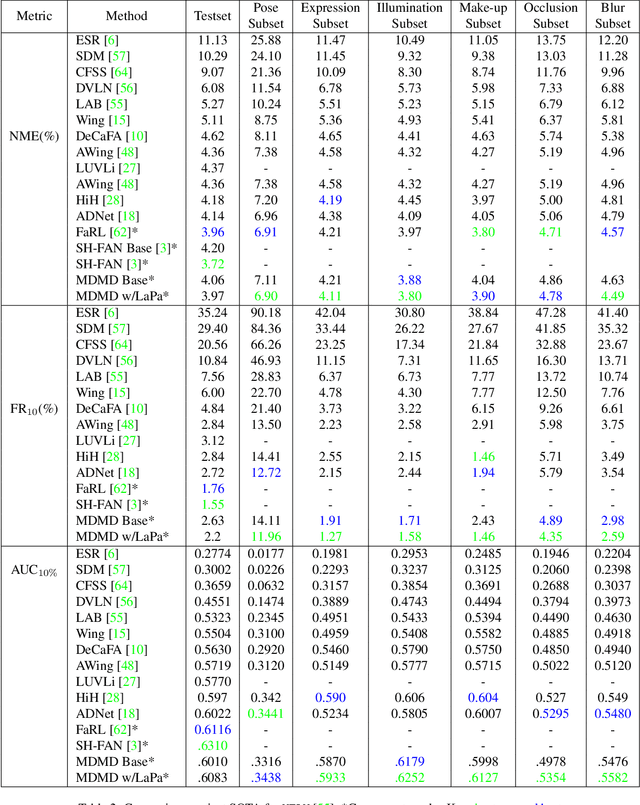
We present a novel method for multi image domain and multi-landmark definition learning for small dataset facial localization. Training a small dataset alongside a large(r) dataset helps with robust learning for the former, and provides a universal mechanism for facial landmark localization for new and/or smaller standard datasets. To this end, we propose a Vision Transformer encoder with a novel decoder with a definition agnostic shared landmark semantic group structured prior, that is learnt, as we train on more than one dataset concurrently. Due to our novel definition agnostic group prior the datasets may vary in landmark definitions and domains. During the decoder stage we use cross- and self-attention, whose output is later fed into domain/definition specific heads that minimize a Laplacian-log-likelihood loss. We achieve state-of-the-art performance on standard landmark localization datasets such as COFW and WFLW, when trained with a bigger dataset. We also show state-of-the-art performance on several varied image domain small datasets for animals, caricatures, and facial portrait paintings. Further, we contribute a small dataset (150 images) of pareidolias to show efficacy of our method. Finally, we provide several analysis and ablation studies to justify our claims.
Robust and Efficient Single-Pixel Image Classificationwith Nonlinear Optics
Jan 27, 2021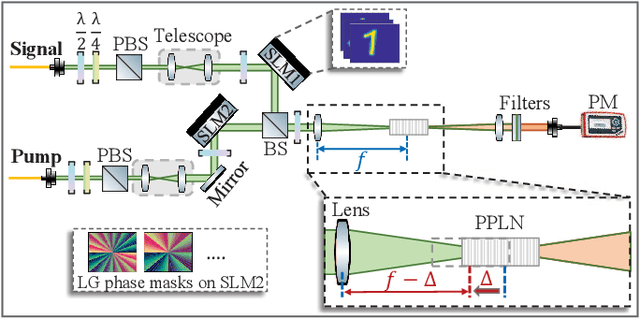
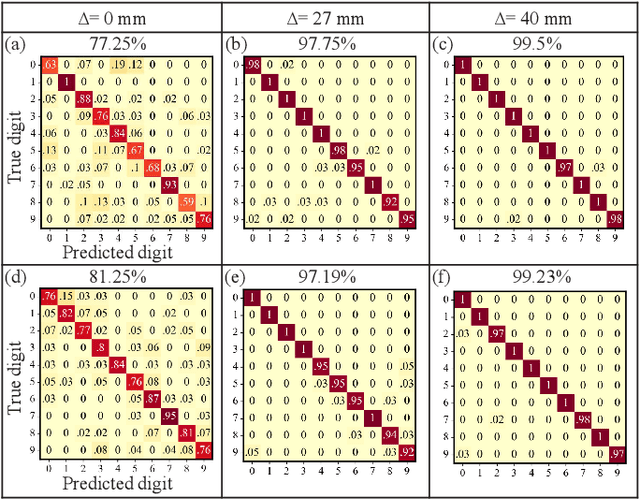
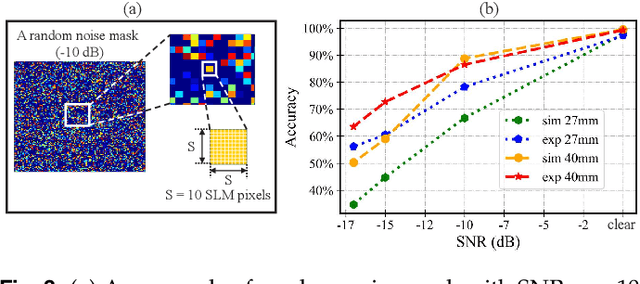
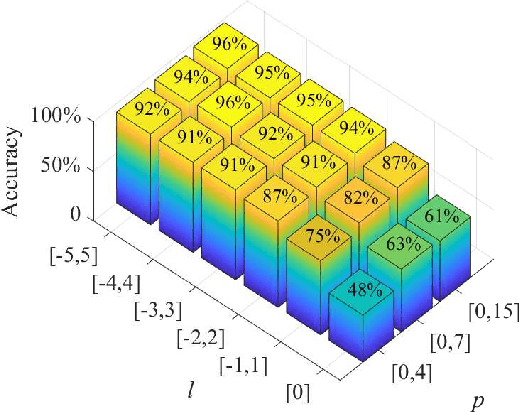
We present a hybrid image classifier by mode-selective image upconversion, single pixel photodetection, and deep learning, aiming at fast processing a large number of pixels. It utilizes partial Fourier transform to extract the signature features of images in both the original and Fourier domains, thereby significantly increasing the classification accuracy and robustness. Tested on the MNIST handwritten digit images, it boosts the accuracy from 81.25% to 99.23%, and achieves an 83% accuracy for highly contaminated images whose signal-to-noise ratio is only -17 dB. Our approach could prove useful for fast lidar data processing, high resolution image recognition, occluded target identification, atmosphere monitoring, and so on.
Federated Learning with Partial Model Personalization
Apr 08, 2022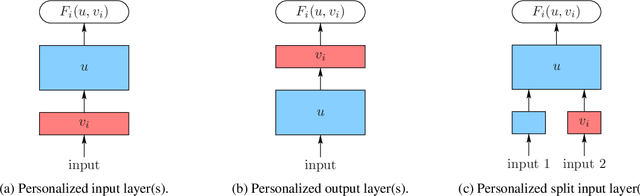

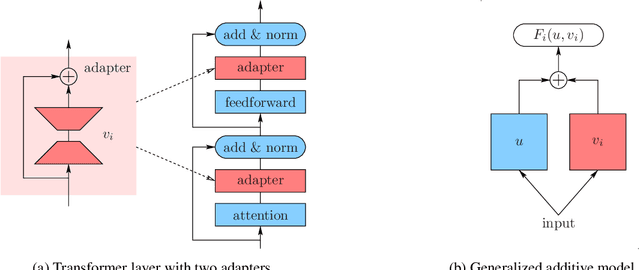

We consider two federated learning algorithms for training partially personalized models, where the shared and personal parameters are updated either simultaneously or alternately on the devices. Both algorithms have been proposed in the literature, but their convergence properties are not fully understood, especially for the alternating variant. We provide convergence analyses of both algorithms in the general nonconvex setting with partial participation and delineate the regime where one dominates the other. Our experiments on real-world image, text, and speech datasets demonstrate that (a) partial personalization can obtain most of the benefits of full model personalization with a small fraction of personal parameters, and, (b) the alternating update algorithm often outperforms the simultaneous update algorithm.
BSRT: Improving Burst Super-Resolution with Swin Transformer and Flow-Guided Deformable Alignment
Apr 22, 2022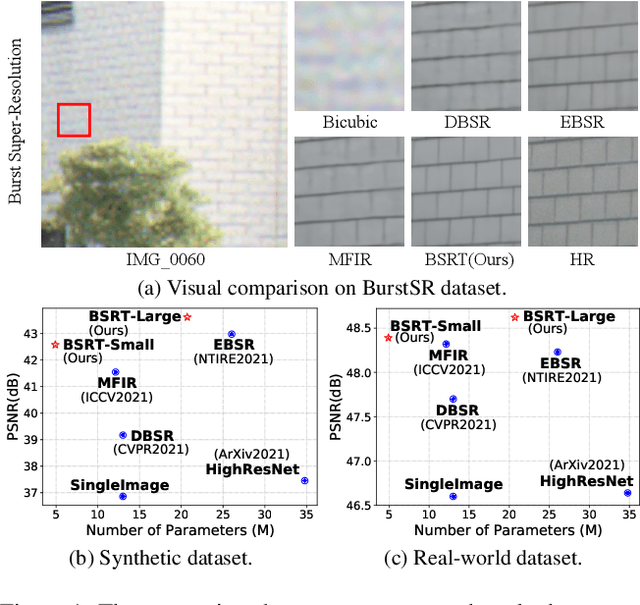
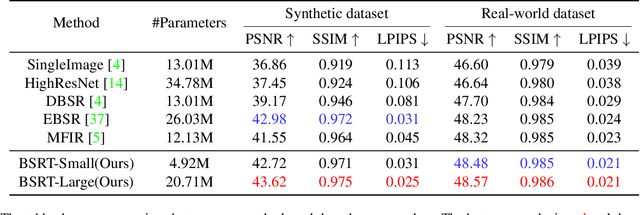
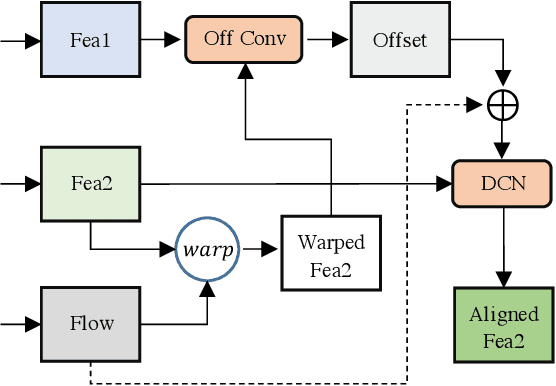
This work addresses the Burst Super-Resolution (BurstSR) task using a new architecture, which requires restoring a high-quality image from a sequence of noisy, misaligned, and low-resolution RAW bursts. To overcome the challenges in BurstSR, we propose a Burst Super-Resolution Transformer (BSRT), which can significantly improve the capability of extracting inter-frame information and reconstruction. To achieve this goal, we propose a Pyramid Flow-Guided Deformable Convolution Network (Pyramid FG-DCN) and incorporate Swin Transformer Blocks and Groups as our main backbone. More specifically, we combine optical flows and deformable convolutions, hence our BSRT can handle misalignment and aggregate the potential texture information in multi-frames more efficiently. In addition, our Transformer-based structure can capture long-range dependency to further improve the performance. The evaluation on both synthetic and real-world tracks demonstrates that our approach achieves a new state-of-the-art in BurstSR task. Further, our BSRT wins the championship in the NTIRE2022 Burst Super-Resolution Challenge.
Data-Folding and Hyperspace Coding for Multi-Dimensonal Time-Series Data Imaging
Mar 10, 2022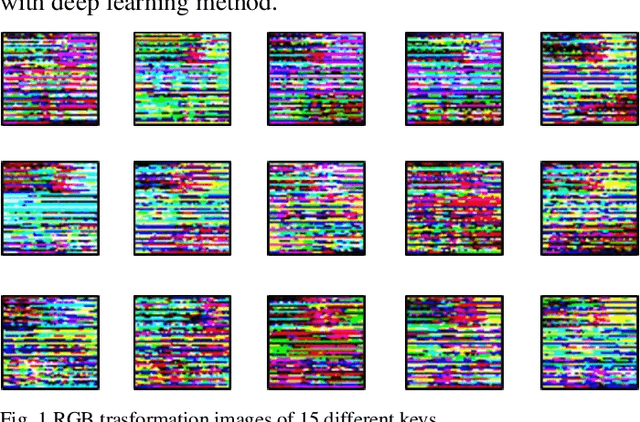
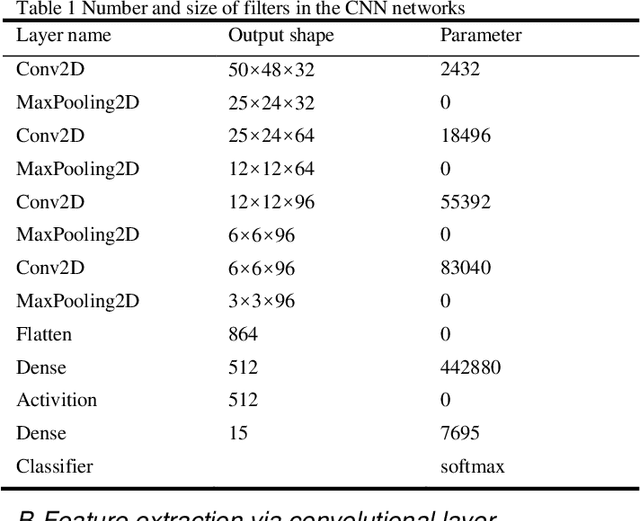
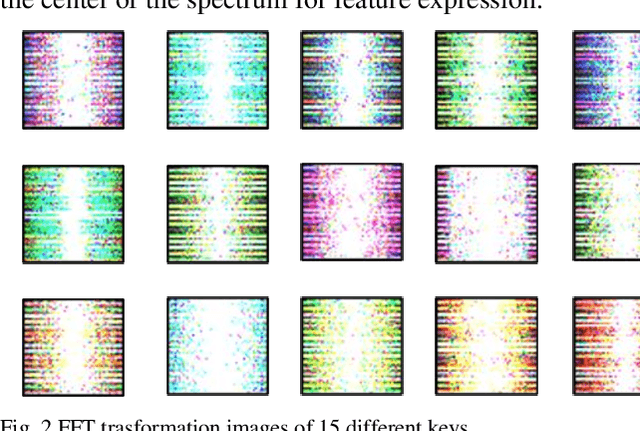
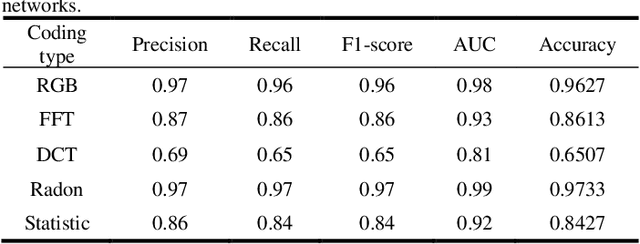
Time-series classification and prediction are widely used in many applications. However, traditional machine learning algorithms, due to their limitations, have difficulty improving the performance of time-series classification and prediction. Inspired by the recent successes of the deep learning technology in computer vision, we develop a new time-series image encoding method for data reconstruction. Featuring data-folding and hyperspace coding this method breaks the barriers between time-series signals and images and establishes a close relationship between them, allowing effective application of the deep learning technology for time-series data. Besides a raw data coding method, we also present other four extended coding methods for other potential applications. For comparison purposes, we present the results of the five different types of image coding methods with our previous keystroke recognition datasets. The results show that our method can achieve an impressive accuracy of 96.27% when RGB coding images are used, and an accuracy of up to 97.33% when using radon coding way. We can expect that this method can also be used and perform well in other classification and prediction applications.
Recognition-free Question Answering on Handwritten Document Collections
Feb 12, 2022In recent years, considerable progress has been made in the research area of Question Answering (QA) on document images. Current QA approaches from the Document Image Analysis community are mainly focusing on machine-printed documents and perform rather limited on handwriting. This is mainly due to the reduced recognition performance on handwritten documents. To tackle this problem, we propose a recognition-free QA approach, especially designed for handwritten document image collections. We present a robust document retrieval method, as well as two QA models. Our approaches outperform the state-of-the-art recognition-free models on the challenging BenthamQA and HW-SQuAD datasets.