 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NDPNet: A novel non-linear data projection network for few-shot fine-grained image classification
Jul 09, 2021
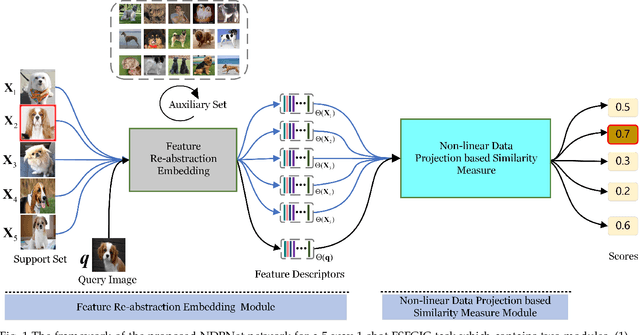
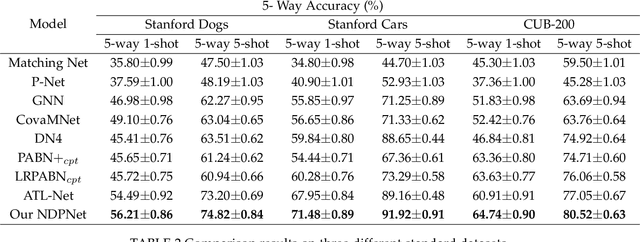
Metric-based few-shot fine-grained image classification (FSFGIC) aims to learn a transferable feature embedding network by estimating the similarities between query images and support classes from very few examples. In this work, we propose, for the first time, to introduce the non-linear data projection concept into the design of FSFGIC architecture in order to address the limited sample problem in few-shot learning and at the same time to increase the discriminability of the model for fine-grained image classification. Specifically, we first design a feature re-abstraction embedding network that has the ability to not only obtain the required semantic features for effective metric learning but also re-enhance such features with finer details from input images. Then the descriptors of the query images and the support classes are projected into different non-linear spaces in our proposed similarity metric learning network to learn discriminative projection factors. This design can effectively operate in the challenging and restricted condition of a FSFGIC task for making the distance between the samples within the same class smaller and the distance between samples from different classes larger and for reducing the coupling relationship between samples from different categories. Furthermore, a novel similarity measure based on the proposed non-linear data project is presented for evaluating the relationships of feature information between a query image and a support set. It is worth to note that our proposed architecture can be easily embedded into any episodic training mechanisms for end-to-end training from scratch. Extensive experiments on FSFGIC tasks demonstrate the superiority of the proposed methods over the state-of-the-art benchmarks.
Multi-Domain Multi-Definition Landmark Localization for Small Datasets
Mar 19, 2022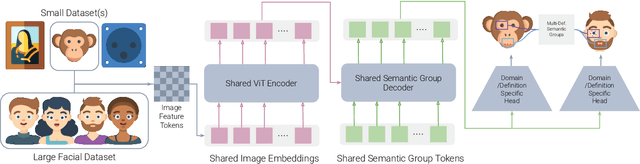
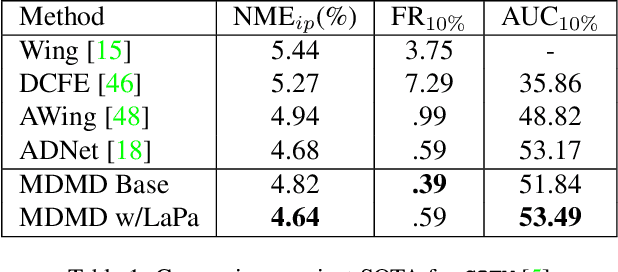

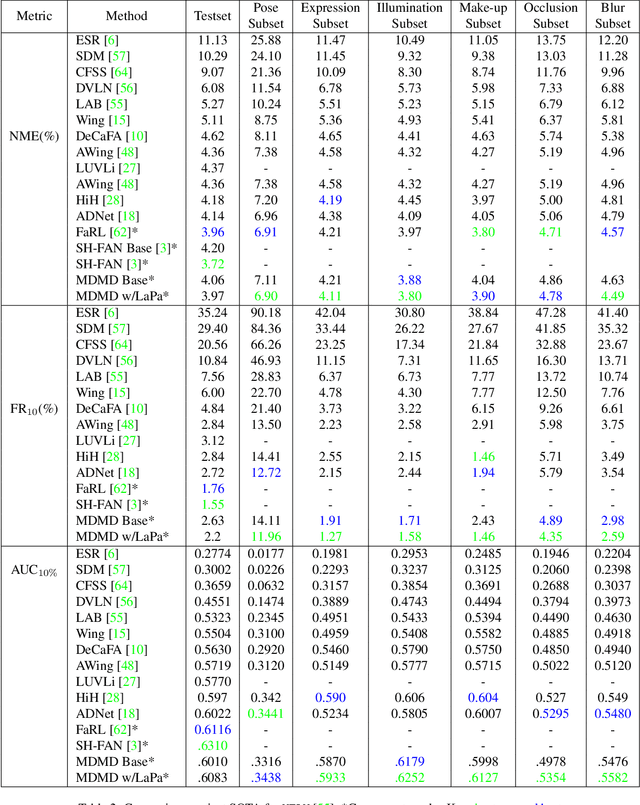
We present a novel method for multi image domain and multi-landmark definition learning for small dataset facial localization. Training a small dataset alongside a large(r) dataset helps with robust learning for the former, and provides a universal mechanism for facial landmark localization for new and/or smaller standard datasets. To this end, we propose a Vision Transformer encoder with a novel decoder with a definition agnostic shared landmark semantic group structured prior, that is learnt, as we train on more than one dataset concurrently. Due to our novel definition agnostic group prior the datasets may vary in landmark definitions and domains. During the decoder stage we use cross- and self-attention, whose output is later fed into domain/definition specific heads that minimize a Laplacian-log-likelihood loss. We achieve state-of-the-art performance on standard landmark localization datasets such as COFW and WFLW, when trained with a bigger dataset. We also show state-of-the-art performance on several varied image domain small datasets for animals, caricatures, and facial portrait paintings. Further, we contribute a small dataset (150 images) of pareidolias to show efficacy of our method. Finally, we provide several analysis and ablation studies to justify our claims.
Medical Image Quality Metrics for Foveated Model Observers
Feb 09, 2021
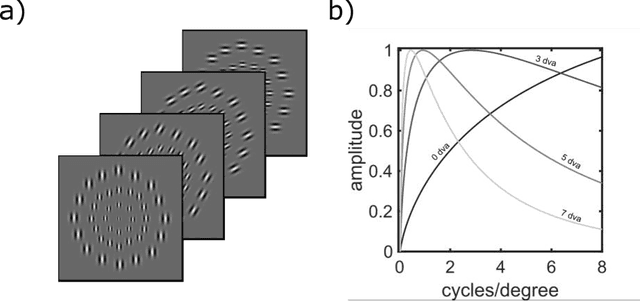

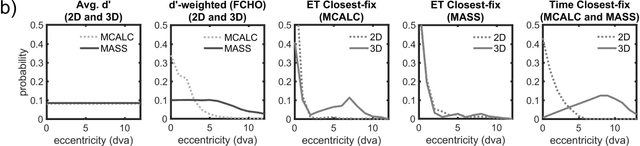
A recently proposed model observer mimics the foveated nature of the human visual system by processing the entire image with varying spatial detail, executing eye movements and scrolling through slices. The model can predict how human search performance changes with signal type and modality (2D vs. 3D), yet its implementation is computationally expensive and time-consuming. Here, we evaluate various image quality metrics using extensions of the classic index of detectability expressions and assess foveated model observers for location-known exactly tasks. We evaluated foveated extensions of a Channelized Hotelling and Non-prewhitening model with an eye filter. The proposed methods involve calculating a model index of detectability (d') for each retinal eccentricity and combining these with a weighting function into a single detectability metric. We assessed different versions of the weighting function that varied in the required measurements of the human observers' search (no measurements, eye movement patterns, and size of the image and median search times). We show that the index of detectability across eccentricities weighted using the eye movement patterns of observers best predicted human performance in 2D vs. 3D search performance for a small microcalcification-like signal and a larger mass-like. The metric with weighting function based on median search times was the second best at predicting human results. The findings provide a set of model observer tools to evaluate image quality in the early stages of imaging system evaluation or design without implementing the more computationally complex foveated search model.
Post-Radiotherapy PET Image Outcome Prediction by Deep Learning under Biological Model Guidance: A Feasibility Study of Oropharyngeal Cancer Application
May 22, 2021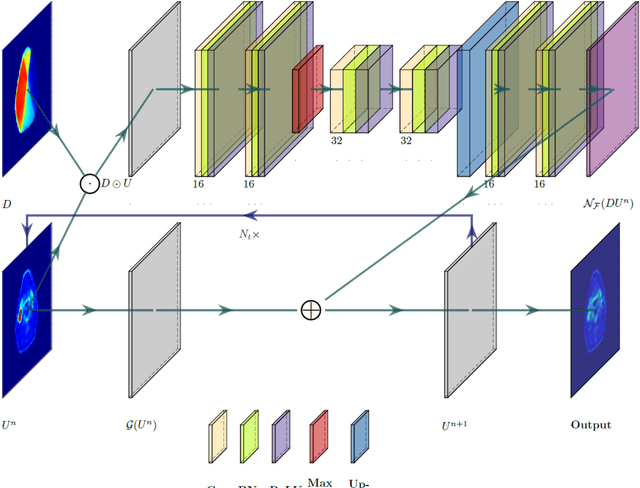
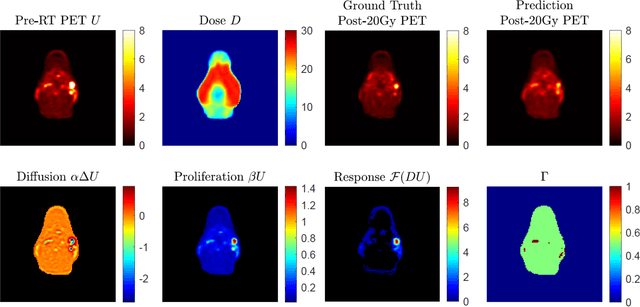
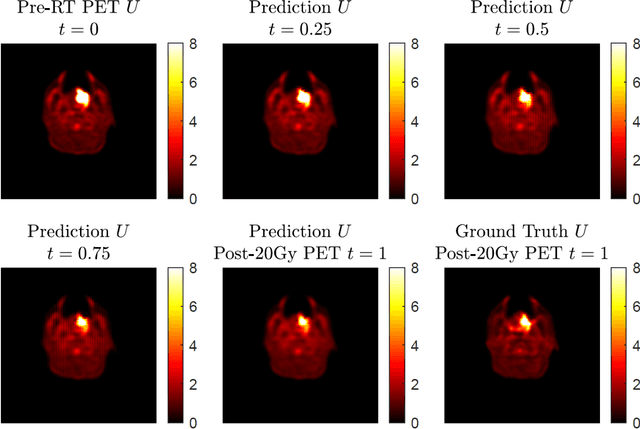
This paper develops a method of biologically guided deep learning for post-radiation FDG-PET image outcome prediction based on pre-radiation images and radiotherapy dose information. Based on the classic reaction-diffusion mechanism, a novel biological model was proposed using a partial differential equation that incorporates spatial radiation dose distribution as a patient-specific treatment information variable. A 7-layer encoder-decoder-based convolutional neural network (CNN) was designed and trained to learn the proposed biological model. As such, the model could generate post-radiation FDG-PET image outcome predictions with possible time-series transition from pre-radiotherapy image states to post-radiotherapy states. The proposed method was developed using 64 oropharyngeal patients with paired FDG-PET studies before and after 20Gy delivery (2Gy/daily fraction) by IMRT. In a two-branch deep learning execution, the proposed CNN learns specific terms in the biological model from paired FDG-PET images and spatial dose distribution as in one branch, and the biological model generates post-20Gy FDG-PET image prediction in the other branch. The proposed method successfully generated post-20Gy FDG-PET image outcome prediction with breakdown illustrations of biological model components. Time-series FDG-PET image predictions were generated to demonstrate the feasibility of disease response rendering. The developed biologically guided deep learning method achieved post-20Gy FDG-PET image outcome predictions in good agreement with ground-truth results. With break-down biological modeling components, the outcome image predictions could be used in adaptive radiotherapy decision-making to optimize personalized plans for the best outcome in the future.
Data--driven Image Restoration with Option--driven Learning for Big and Small Astronomical Image Datasets
Nov 07, 2020
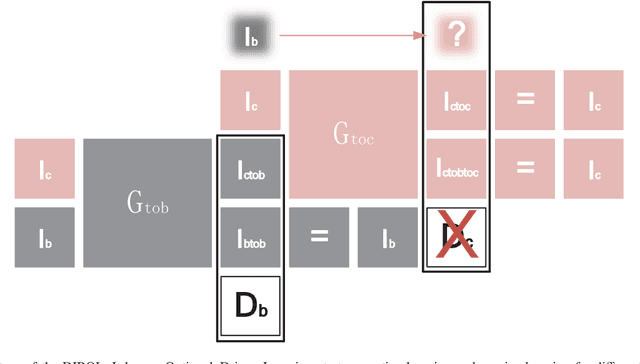
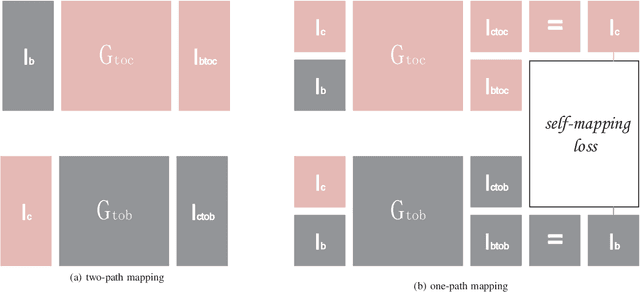

Image restoration methods are commonly used to improve the quality of astronomical images. In recent years, developments of deep neural networks and increments of the number of astronomical images have evoked a lot of data--driven image restoration methods. However, most of these methods belong to supervised learning algorithms, which require paired images either from real observations or simulated data as training set. For some applications, it is hard to get enough paired images from real observations and simulated images are quite different from real observed ones. In this paper, we propose a new data--driven image restoration method based on generative adversarial networks with option--driven learning. Our method uses several high resolution images as references and applies different learning strategies when the number of reference images is different. For sky surveys with variable observation conditions, our method can obtain very stable image restoration results, regardless of the number of reference images.
Bridging Gap between Image Pixels and Semantics via Supervision: A Survey
Jul 29, 2021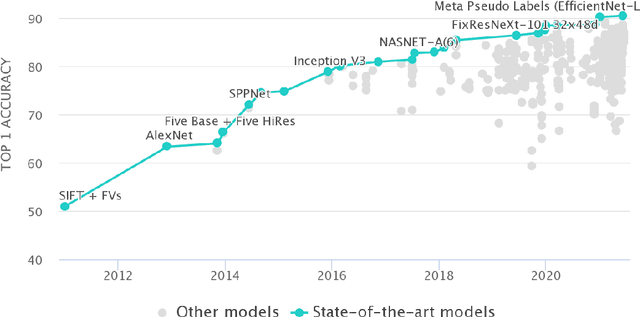
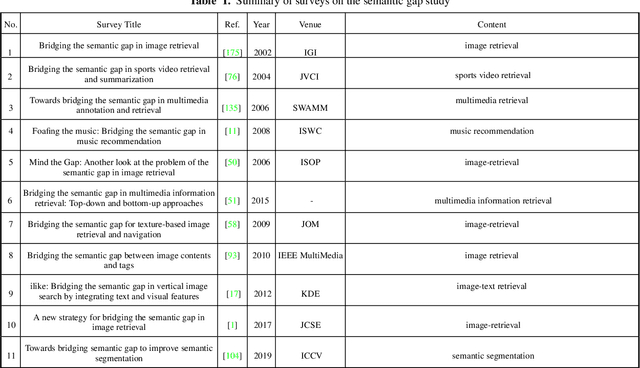

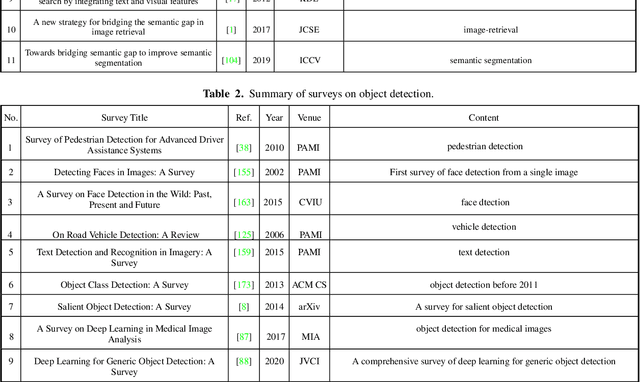
The fact that there exists a gap between low-level features and semantic meanings of images, called the semantic gap, is known for decades. Resolution of the semantic gap is a long standing problem. The semantic gap problem is reviewed and a survey on recent efforts in bridging the gap is made in this work. Most importantly, we claim that the semantic gap is primarily bridged through supervised learning today. Experiences are drawn from two application domains to illustrate this point: 1) object detection and 2) metric learning for content-based image retrieval (CBIR). To begin with, this paper offers a historical retrospective on supervision, makes a gradual transition to the modern data-driven methodology and introduces commonly used datasets. Then, it summarizes various supervision methods to bridge the semantic gap in the context of object detection and metric learning.
Enhancing the Transferability via Feature-Momentum Adversarial Attack
Apr 22, 2022
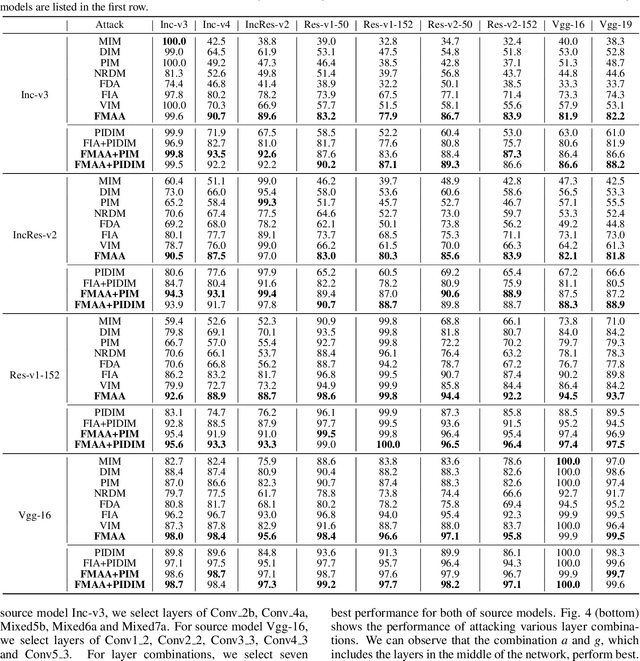
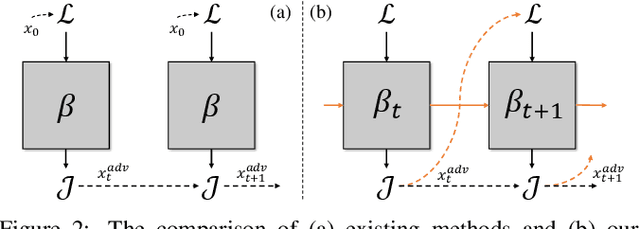
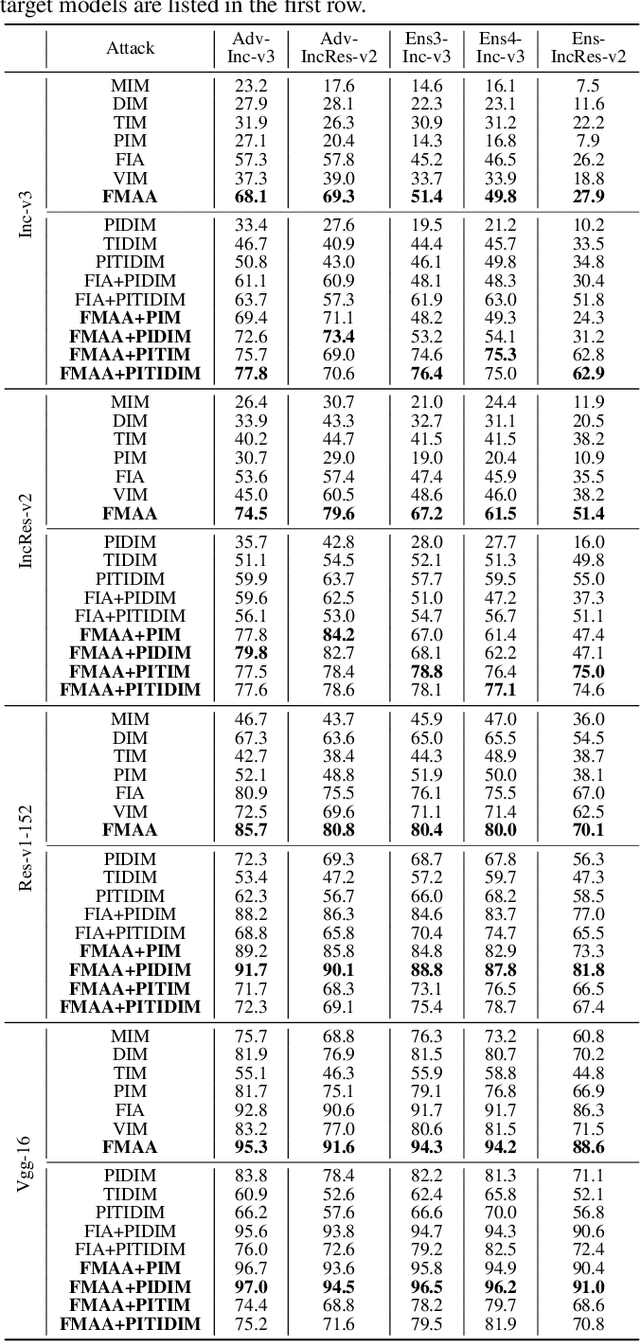
Transferable adversarial attack has drawn increasing attention due to their practical threaten to real-world applications. In particular, the feature-level adversarial attack is one recent branch that can enhance the transferability via disturbing the intermediate features. The existing methods usually create a guidance map for features, where the value indicates the importance of the corresponding feature element and then employs an iterative algorithm to disrupt the features accordingly. However, the guidance map is fixed in existing methods, which can not consistently reflect the behavior of networks as the image is changed during iteration. In this paper, we describe a new method called Feature-Momentum Adversarial Attack (FMAA) to further improve transferability. The key idea of our method is that we estimate a guidance map dynamically at each iteration using momentum to effectively disturb the category-relevant features. Extensive experiments demonstrate that our method significantly outperforms other state-of-the-art methods by a large margin on different target models.
Data-Folding and Hyperspace Coding for Multi-Dimensonal Time-Series Data Imaging
Mar 10, 2022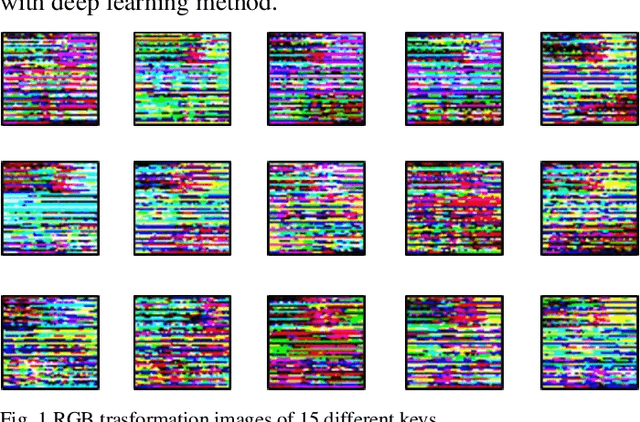
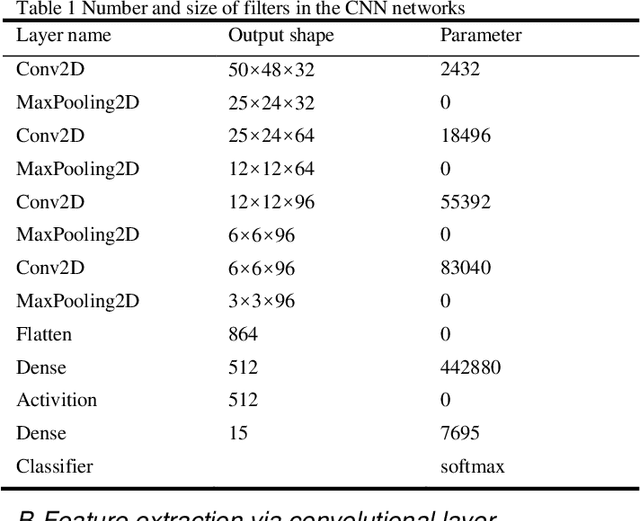
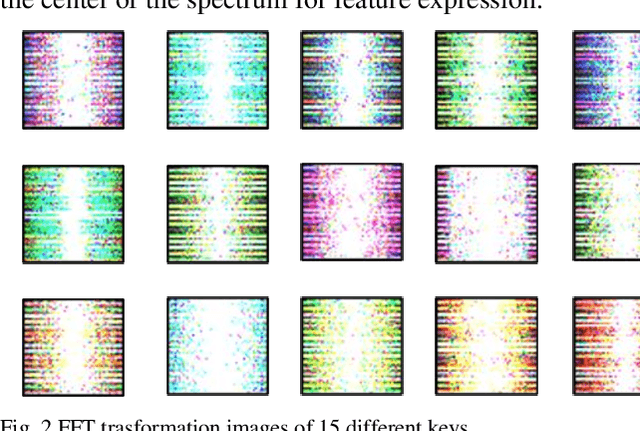
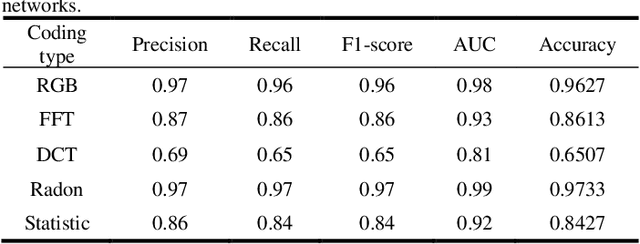
Time-series classification and prediction are widely used in many applications. However, traditional machine learning algorithms, due to their limitations, have difficulty improving the performance of time-series classification and prediction. Inspired by the recent successes of the deep learning technology in computer vision, we develop a new time-series image encoding method for data reconstruction. Featuring data-folding and hyperspace coding this method breaks the barriers between time-series signals and images and establishes a close relationship between them, allowing effective application of the deep learning technology for time-series data. Besides a raw data coding method, we also present other four extended coding methods for other potential applications. For comparison purposes, we present the results of the five different types of image coding methods with our previous keystroke recognition datasets. The results show that our method can achieve an impressive accuracy of 96.27% when RGB coding images are used, and an accuracy of up to 97.33% when using radon coding way. We can expect that this method can also be used and perform well in other classification and prediction applications.
Prediction of stent under-expansion in calcified coronary arteries using machine-learning on intravascular optical coherence tomography
May 16, 2022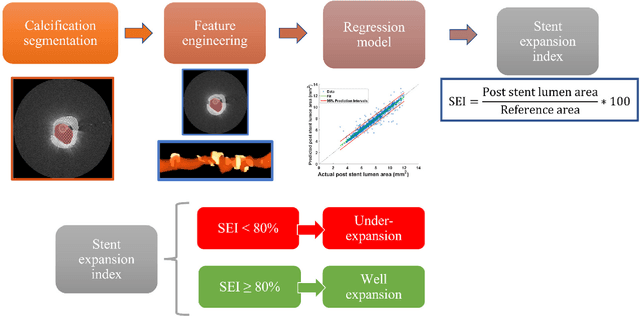
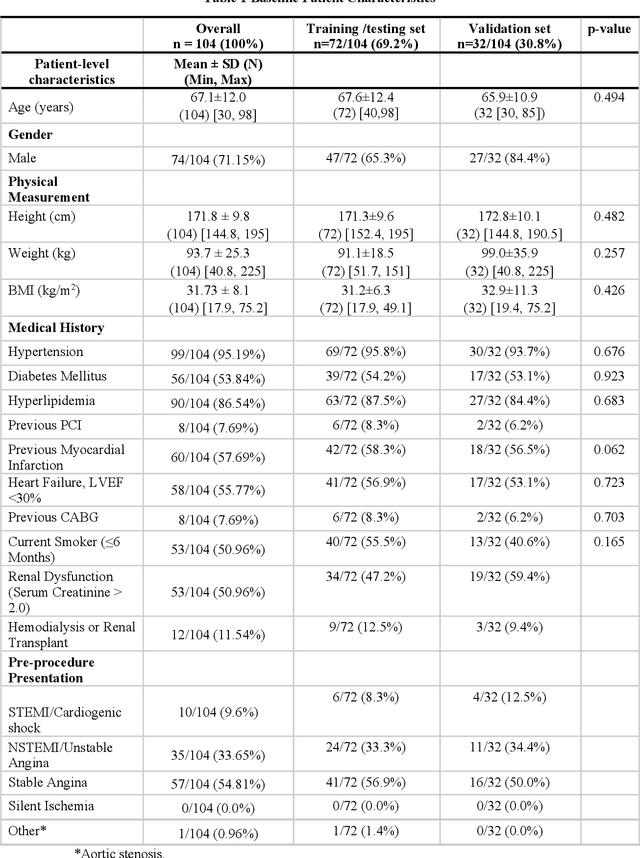
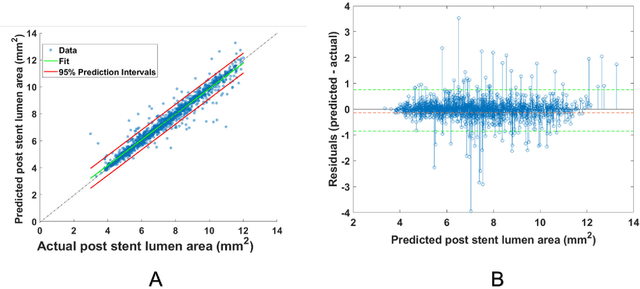
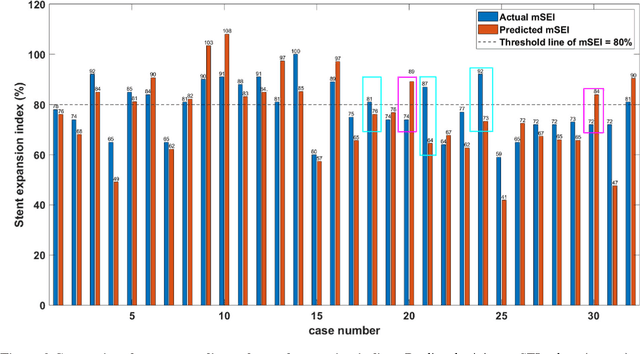
BACKGROUND Careful evaluation of the risk of stent under-expansions before the intervention will aid treatment planning, including the application of a pre-stent plaque modification strategy. OBJECTIVES It remains challenging to achieve a proper stent expansion in the presence of severely calcified coronary lesions. Building on our work in deep learning segmentation, we created an automated machine learning approach that uses lesion attributes to predict stent under-expansion from pre-stent images, suggesting the need for plaque modification. METHODS Pre- and post-stent intravascular optical coherence tomography image data were obtained from 110 coronary lesions. Lumen and calcifications in pre-stent images were segmented using deep learning, and numerous features per lesion were extracted. We analyzed stent expansion along the lesion, enabling frame, segmental, and whole-lesion analyses. We trained regression models to predict the poststent lumen area and then to compute the stent expansion index (SEI). Stents with an SEI < or >/= 80% were classified as "under-expanded" and "well-expanded," respectively. RESULTS Best performance (root-mean-square-error = 0.04+/-0.02 mm2, r = 0.94+/-0.04, p < 0.0001) was achieved when we used features from both the lumen and calcification to train a Gaussian regression model for a segmental analysis over a segment length of 31 frames. Under-expansion classification results (AUC=0.85+/-0.02) were significantly improved over other approaches. CONCLUSIONS We used calcifications and lumen features to identify lesions at risk of stent under-expansion. Results suggest that the use of pre-stent images can inform physicians of the need to apply plaque modification approaches.
Thermal Infrared Image Colorization for Nighttime Driving Scenes with Top-Down Guided Attention
Apr 29, 2021


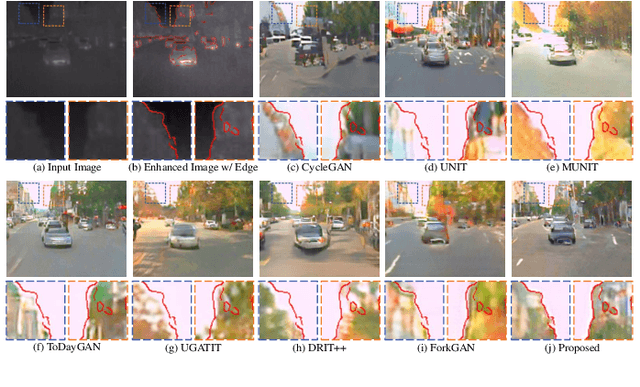
Benefitting from insensitivity to light and high penetration of foggy environments, infrared cameras are widely used for sensing in nighttime traffic scenes. However, the low contrast and lack of chromaticity of thermal infrared (TIR) images hinder the human interpretation and portability of high-level computer vision algorithms. Colorization to translate a nighttime TIR image into a daytime color (NTIR2DC) image may be a promising way to facilitate nighttime scene perception. Despite recent impressive advances in image translation, semantic encoding entanglement and geometric distortion in the NTIR2DC task remain under-addressed. Hence, we propose a toP-down attEntion And gRadient aLignment based GAN, referred to as PearlGAN. A top-down guided attention module and an elaborate attentional loss are first designed to reduce the semantic encoding ambiguity during translation. Then, a structured gradient alignment loss is introduced to encourage edge consistency between the translated and input images. In addition, pixel-level annotation is carried out on a subset of FLIR and KAIST datasets to evaluate the semantic preservation performance of multiple translation methods. Furthermore, a new metric is devised to evaluate the geometric consistency in the translation process. Extensive experiments demonstrate the superiority of the proposed PearlGAN over other image translation methods for the NTIR2DC task. The source code and labeled segmentation masks will be available at \url{https://github.com/FuyaLuo/PearlGAN/}.