 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Space-to-Ground Data Availability for Agriculture Monitoring
May 16, 2022
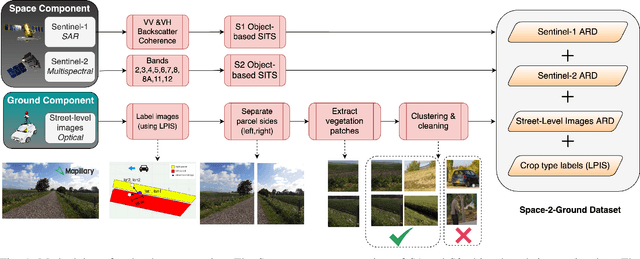
The recent advances in machine learning and the availability of free and open big Earth data (e.g., Sentinel missions), which cover large areas with high spatial and temporal resolution, have enabled many agriculture monitoring applications. One example is the control of subsidy allocations of the Common Agricultural Policy (CAP). Advanced remote sensing systems have been developed towards the large-scale evidence-based monitoring of the CAP. Nevertheless, the spatial resolution of satellite images is not always adequate to make accurate decisions for all fields. In this work, we introduce the notion of space-to-ground data availability, i.e., from the satellite to the field, in an attempt to make the best out of the complementary characteristics of the different sources. We present a space-to-ground dataset that contains Sentinel-1 radar and Sentinel-2 optical image time-series, as well as street-level images from the crowdsourcing platform Mapillary, for grassland fields in the area of Utrecht for 2017. The multifaceted utility of our dataset is showcased through the downstream task of grassland classification. We train machine and deep learning algorithms on these different data domains and highlight the potential of fusion techniques towards increasing the reliability of decisions.
Image Manipulation Detection by Multi-View Multi-Scale Supervision
Apr 14, 2021
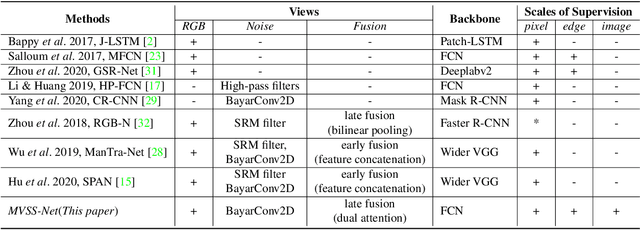
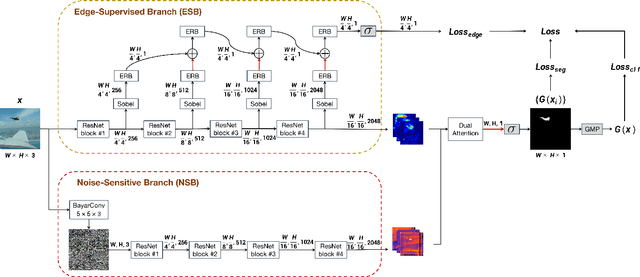
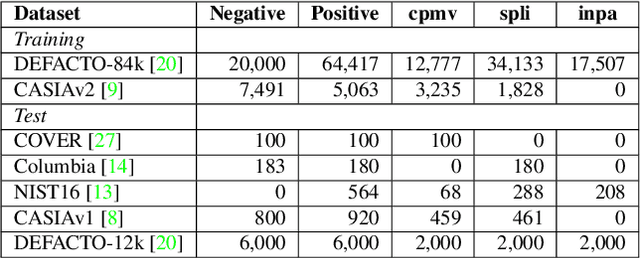
The key challenge of image manipulation detection is how to learn generalizable features that are sensitive to manipulations in novel data, whilst specific to prevent false alarms on authentic images. Current research emphasizes the sensitivity, with the specificity overlooked. In this paper we address both aspects by multi-view feature learning and multi-scale supervision. By exploiting noise distribution and boundary artifact surrounding tampered regions, the former aims to learn semantic-agnostic and thus more generalizable features. The latter allows us to learn from authentic images which are nontrivial to taken into account by current semantic segmentation network based methods. Our thoughts are realized by a new network which we term MVSS-Net. Extensive experiments on five benchmark sets justify the viability of MVSS-Net for both pixel-level and image-level manipulation detection.
Adversarial synthesis based data-augmentation for code-switched spoken language identification
May 30, 2022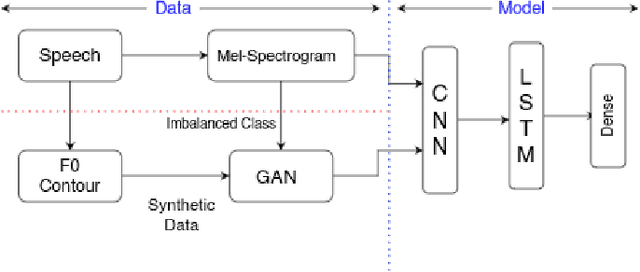
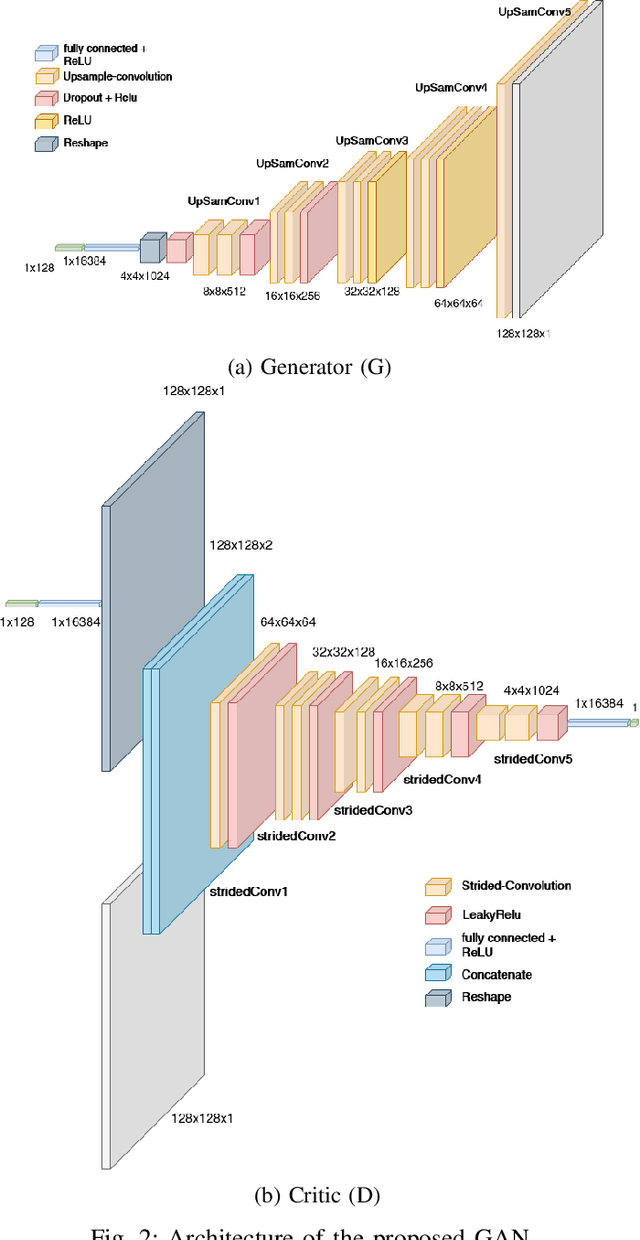
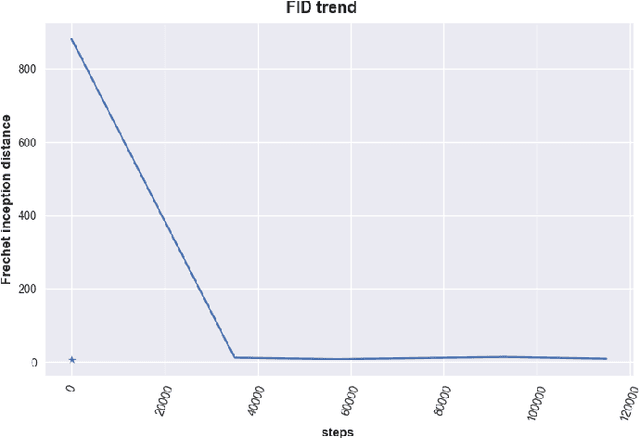
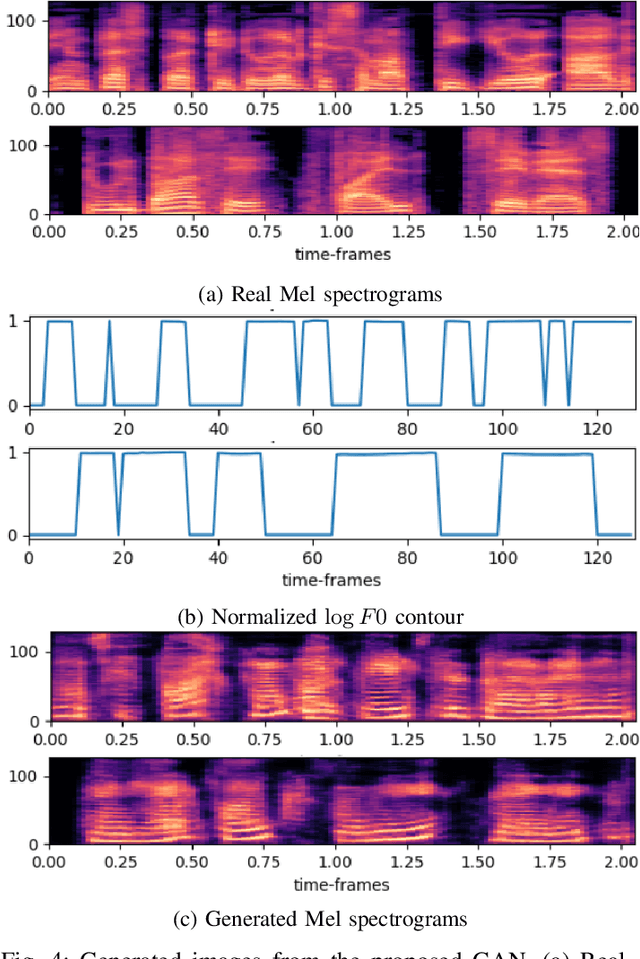
Spoken Language Identification (LID) is an important sub-task of Automatic Speech Recognition(ASR) that is used to classify the language(s) in an audio segment. Automatic LID plays an useful role in multilingual countries. In various countries, identifying a language becomes hard, due to the multilingual scenario where two or more than two languages are mixed together during conversation. Such phenomenon of speech is called as code-mixing or code-switching. This nature is followed not only in India but also in many Asian countries. Such code-mixed data is hard to find, which further reduces the capabilities of the spoken LID. Due to the lack of avalibility of this code-mixed data, it becomes a minority class in LID task. Hence, this work primarily addresses this problem using data augmentation as a solution on the minority code-switched class. This study focuses on Indic language code-mixed with English. Spoken LID is performed on Hindi, code-mixed with English. This research proposes Generative Adversarial Network (GAN) based data augmentation technique performed using Mel spectrograms for audio data. GANs have already been proven to be accurate in representing the real data distribution in the image domain. Proposed research exploits these capabilities of GANs in speech domains such as speech classification, automatic speech recognition,etc. GANs are trained to generate Mel spectrograms of the minority code-mixed class which are then used to augment data for the classifier. Utilizing GANs give an overall improvement on Unweighted Average Recall by an amount of 3.5\% as compared to a Convolutional Recurrent Neural Network (CRNN) classifier used as the baseline reference.
DeepCFL: Deep Contextual Features Learning from a Single Image
Nov 07, 2020
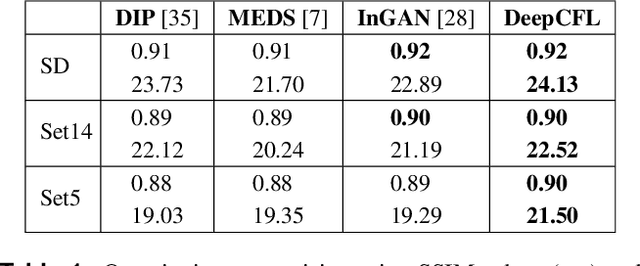
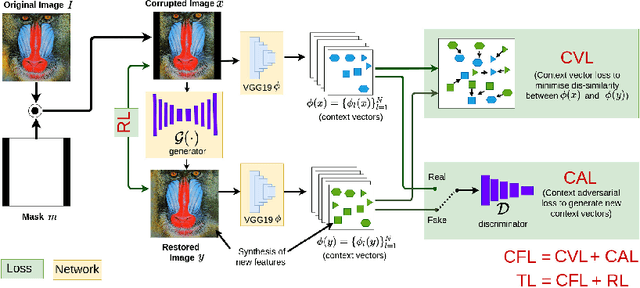
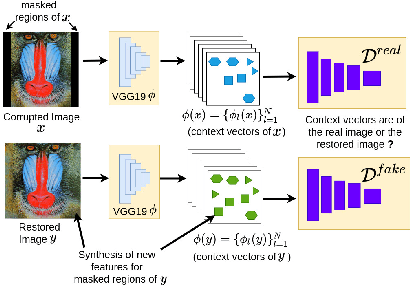
Recently, there is a vast interest in developing image feature learning methods that are independent of the training data, such as deep image prior, InGAN, SinGAN, and DCIL. These methods are unsupervised and are used to perform low-level vision tasks such as image restoration, image editing, and image synthesis. In this work, we proposed a new training data-independent framework, called Deep Contextual Features Learning (DeepCFL), to perform image synthesis and image restoration based on the semantics of the input image. The contextual features are simply the high dimensional vectors representing the semantics of the given image. DeepCFL is a single image GAN framework that learns the distribution of the context vectors from the input image. We show the performance of contextual learning in various challenging scenarios: outpainting, inpainting, and restoration of randomly removed pixels. DeepCFL is applicable when the input source image and the generated target image are not aligned. We illustrate image synthesis using DeepCFL for the task of image resizing.
Continual BatchNorm Adaptation (CBNA) for Semantic Segmentation
Mar 02, 2022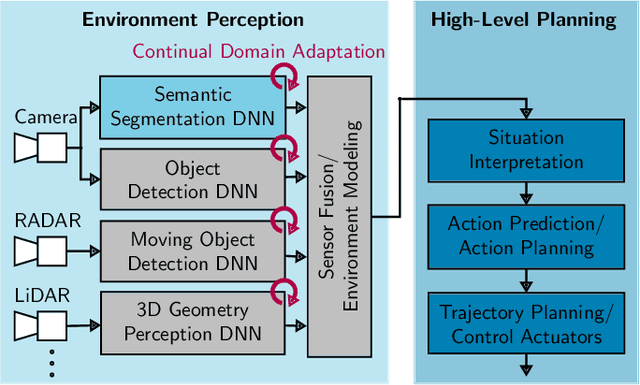
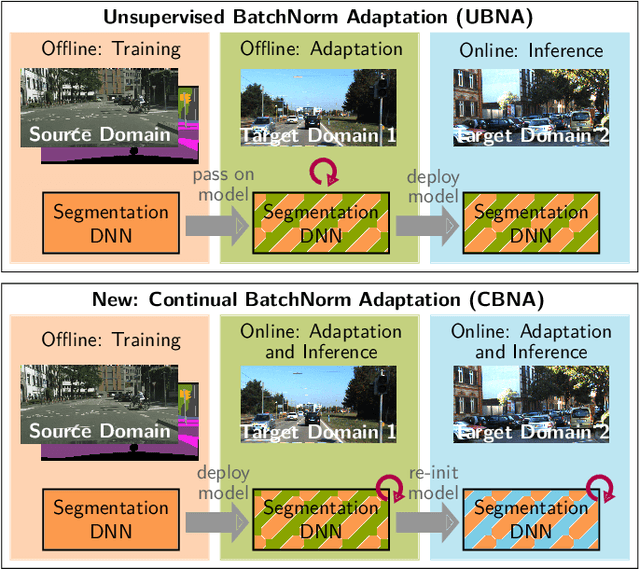
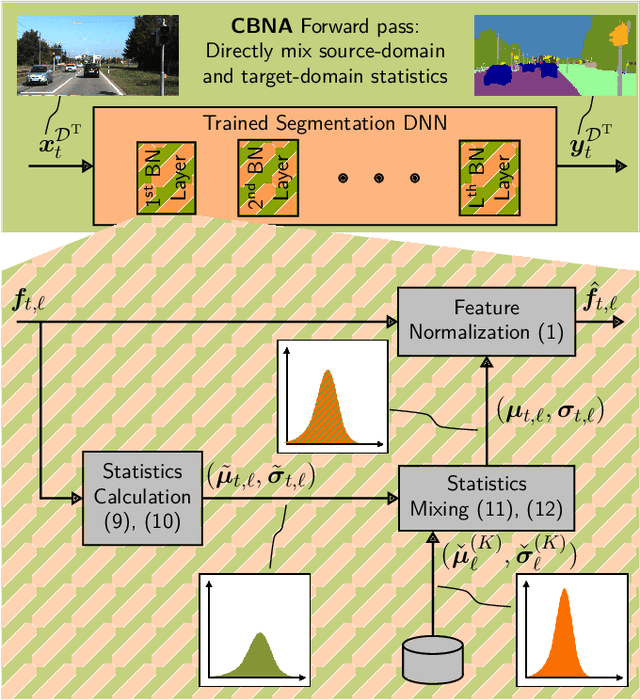
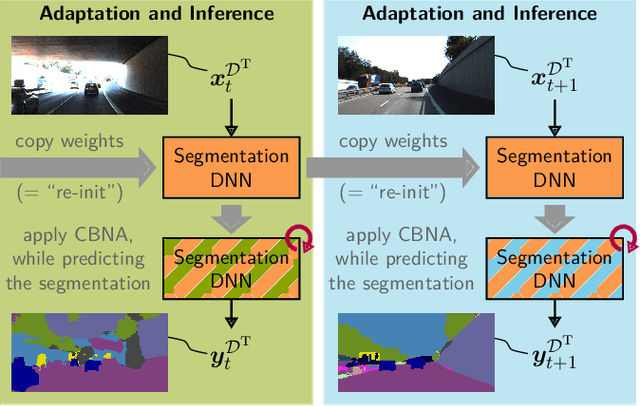
Environment perception in autonomous driving vehicles often heavily relies on deep neural networks (DNNs), which are subject to domain shifts, leading to a significantly decreased performance during DNN deployment. Usually, this problem is addressed by unsupervised domain adaptation (UDA) approaches trained either simultaneously on source and target domain datasets or even source-free only on target data in an offline fashion. In this work, we further expand a source-free UDA approach to a continual and therefore online-capable UDA on a single-image basis for semantic segmentation. Accordingly, our method only requires the pre-trained model from the supplier (trained in the source domain) and the current (unlabeled target domain) camera image. Our method Continual BatchNorm Adaptation (CBNA) modifies the source domain statistics in the batch normalization layers, using target domain images in an unsupervised fashion, which yields consistent performance improvements during inference. Thereby, in contrast to existing works, our approach can be applied to improve a DNN continuously on a single-image basis during deployment without access to source data, without algorithmic delay, and nearly without computational overhead. We show the consistent effectiveness of our method across a wide variety of source/target domain settings for semantic segmentation. As part of this work, our code will be made publicly available.
Reversible data hiding with dual pixel-value-ordering and1minimum prediction error expansion
Feb 12, 2022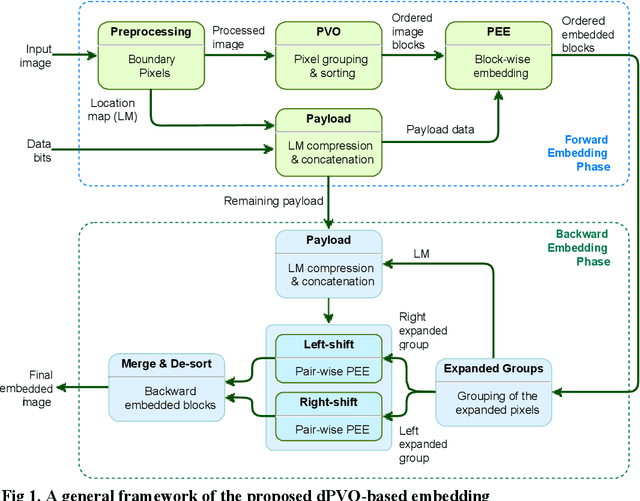
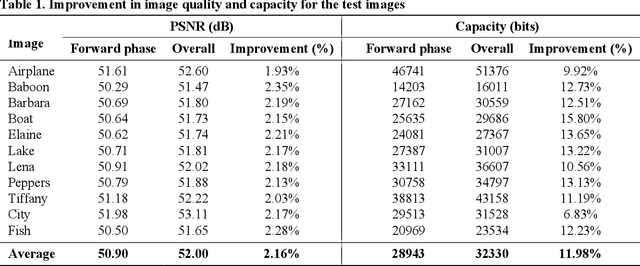
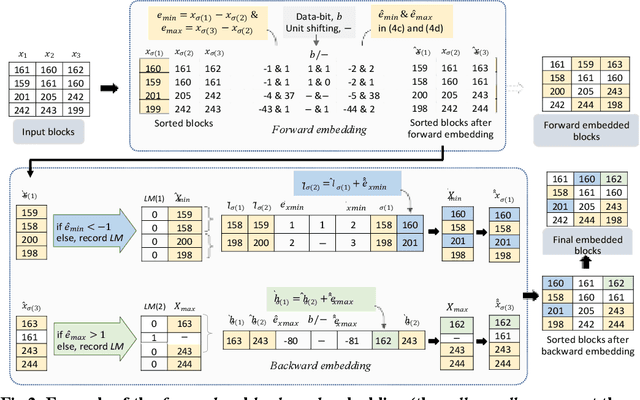
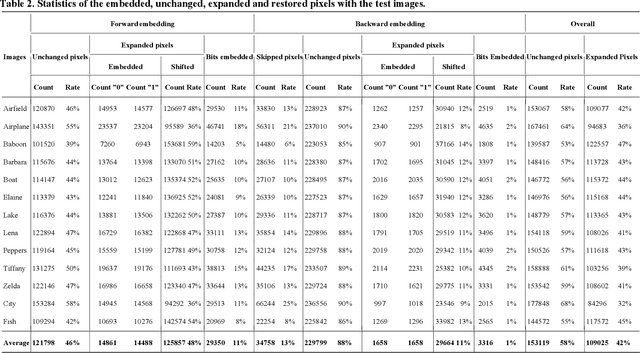
Pixel Value Ordering (PVO) holds an impressive property for high fidelity Reversible Data Hiding (RDH). In this paper, we introduce a dual-PVO (dPVO) for Prediction Error Expansion(PEE), and thereby develop a new RDH scheme to offer a better rate-distortion performance. Particularly, we propose to embed in two phases: forward and backward. In the forward phase, PVO with classic PEE is applied to every non-overlapping image block of size 1x3. In the backward phase,minimum-set and maximum-set of pixels are determined from the pixels predicted in the forward phase. The minimum set only contains the lowest predicted pixels and the maximum set contains the largest predicted pixels of each image block. Proposed dPVO withPEE is then applied to both sets, so that the pixel values of the minimum set are increased and that of the maximum set are decreased by a unit value. Thereby, the pixels predicted in the forward embedding can partially be restored to their original values resulting in both better-embedded image quality and a higher embedding rate. Experimental results have recorded a promising rate-distortion performance of our scheme with a significant improvement of embedded image quality at higher embedding rates compared to the popular and state-of-the-art PVO-based RDHschemes.
A Survey of Hand Crafted and Deep Learning Methods for Image Aesthetic Assessment
Mar 22, 2021
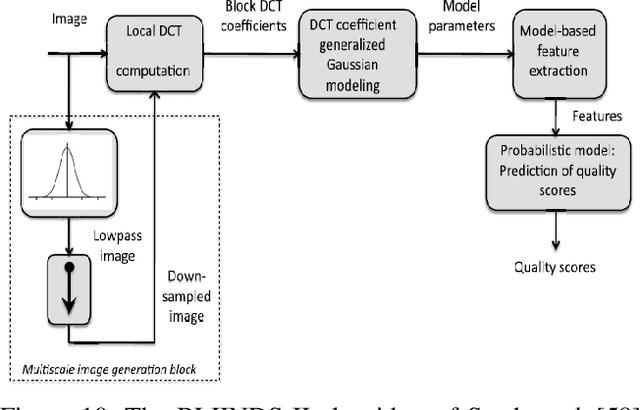
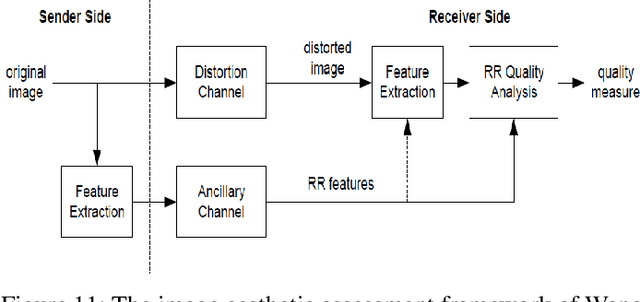
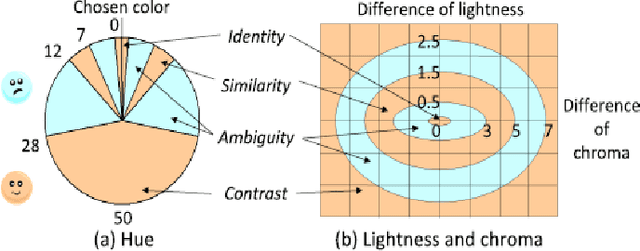
Automatic image aesthetics assessment is a computer vision problem that deals with the categorization of images into different aesthetic levels. The categorization is usually done by analyzing an input image and computing some measure of the degree to which the image adhere to the key principles of photography (balance, rhythm, harmony, contrast, unity, look, feel, tone and texture). Owing to its diverse applications in many areas, automatic image aesthetic assessment has gained significant research attention in recent years. This paper presents a literature review of the recent techniques of automatic image aesthetics assessment. A large number of traditional hand crafted and deep learning based approaches are reviewed. Key problem aspects are discussed such as why some features or models perform better than others and what are the limitations. A comparison of the quantitative results of different methods is also provided at the end.
Underwater image filtering: methods, datasets and evaluation
Dec 22, 2020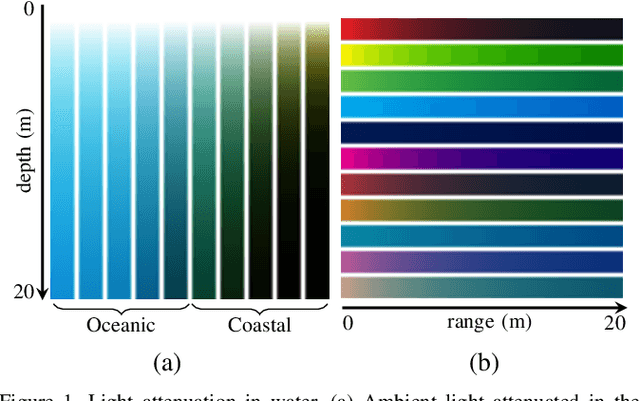
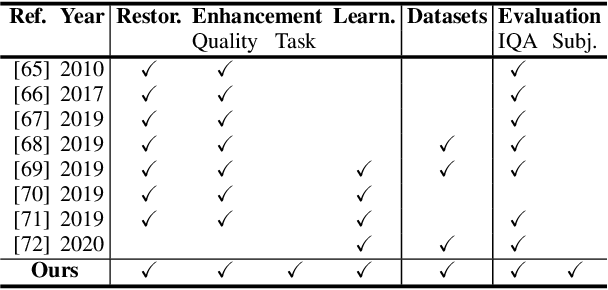

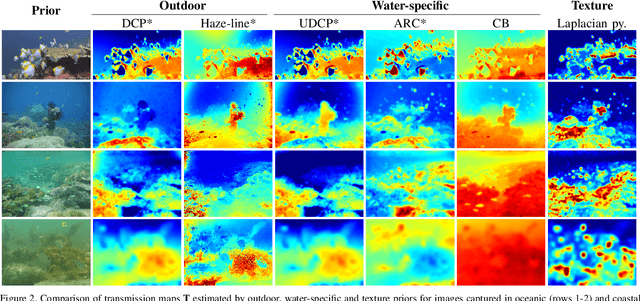
Underwater images are degraded by the selective attenuation of light that distorts colours and reduces contrast. The degradation extent depends on the water type, the distance between an object and the camera, and the depth under the water surface the object is at. Underwater image filtering aims to restore or to enhance the appearance of objects captured in an underwater image. Restoration methods compensate for the actual degradation, whereas enhancement methods improve either the perceived image quality or the performance of computer vision algorithms. The growing interest in underwater image filtering methods--including learning-based approaches used for both restoration and enhancement--and the associated challenges call for a comprehensive review of the state of the art. In this paper, we review the design principles of filtering methods and revisit the oceanology background that is fundamental to identify the degradation causes. We discuss image formation models and the results of restoration methods in various water types. Furthermore, we present task-dependent enhancement methods and categorise datasets for training neural networks and for method evaluation. Finally, we discuss evaluation strategies, including subjective tests and quality assessment measures. We complement this survey with a platform ( https://puiqe.eecs.qmul.ac.uk/ ), which hosts state-of-the-art underwater filtering methods and facilitates comparisons.
An Adaptive Structural Learning of Deep Belief Network for Image-based Crack Detection in Concrete Structures Using SDNET2018
Oct 25, 2021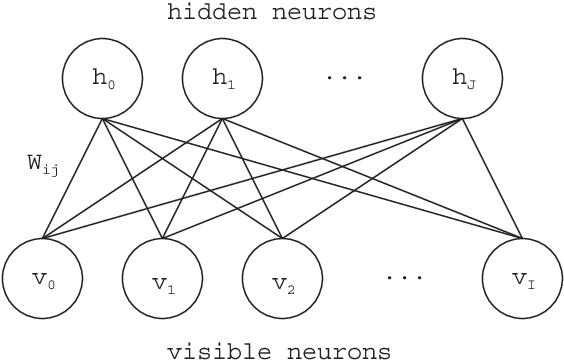

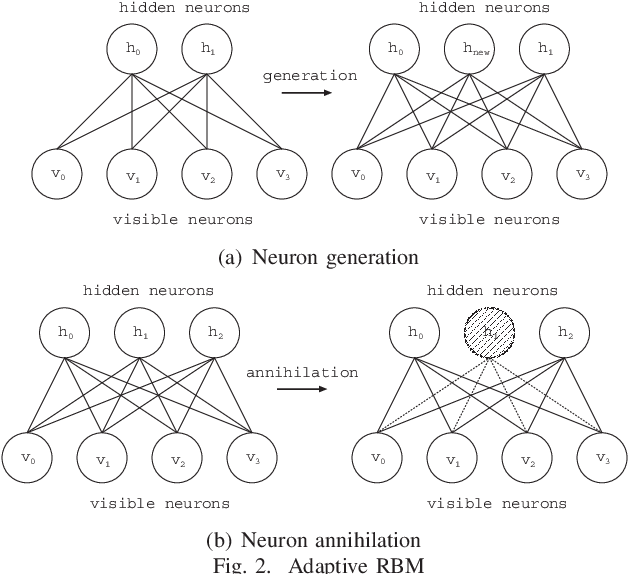
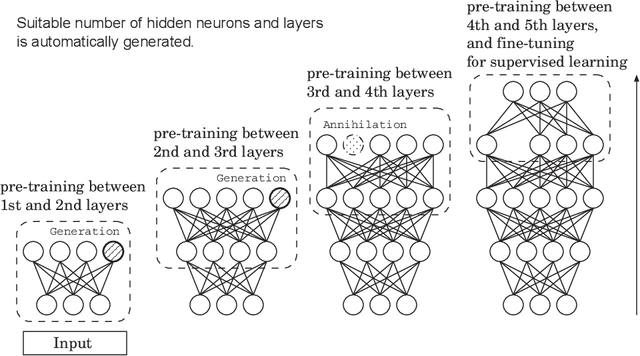
We have developed an adaptive structural Deep Belief Network (Adaptive DBN) that finds an optimal network structure in a self-organizing manner during learning. The Adaptive DBN is the hierarchical architecture where each layer employs Adaptive Restricted Boltzmann Machine (Adaptive RBM). The Adaptive RBM can find the appropriate number of hidden neurons during learning. The proposed method was applied to a concrete image benchmark data set SDNET2018 for crack detection. The dataset contains about 56,000 crack images for three types of concrete structures: bridge decks, walls, and paved roads. The fine-tuning method of the Adaptive DBN can show 99.7%, 99.7%, and 99.4% classification accuracy for three types of structures. However, we found the database included some wrong annotated data which cannot be judged from images by human experts. This paper discusses consideration that purses the major factor for the wrong cases and the removal of the adversarial examples from the dataset.
Ensuring accurate stain reproduction in deep generative networks for virtual immunohistochemistry
Apr 14, 2022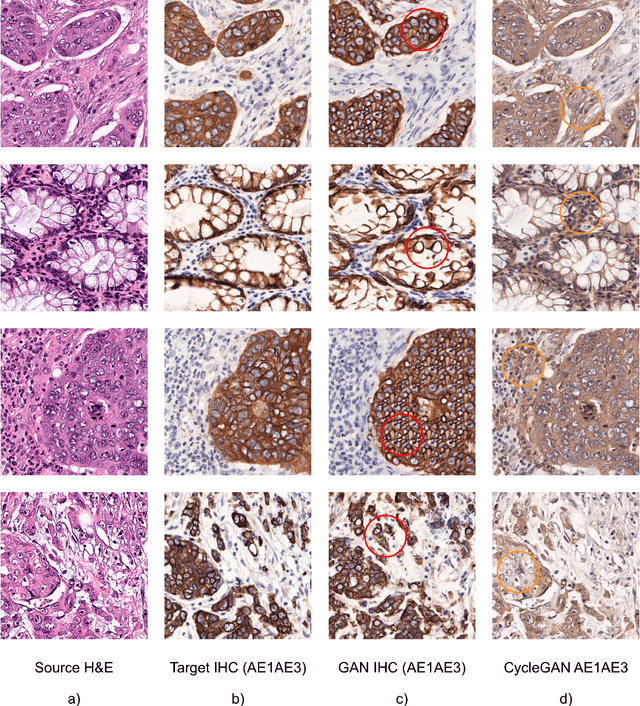
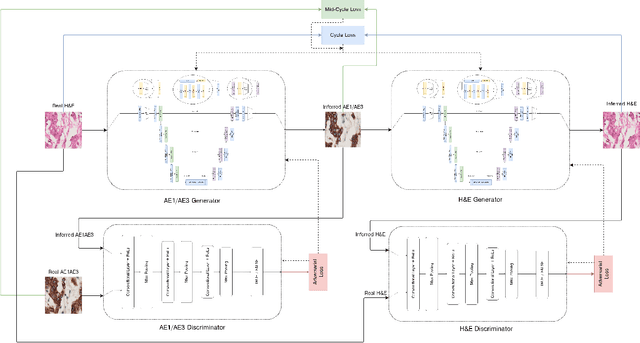
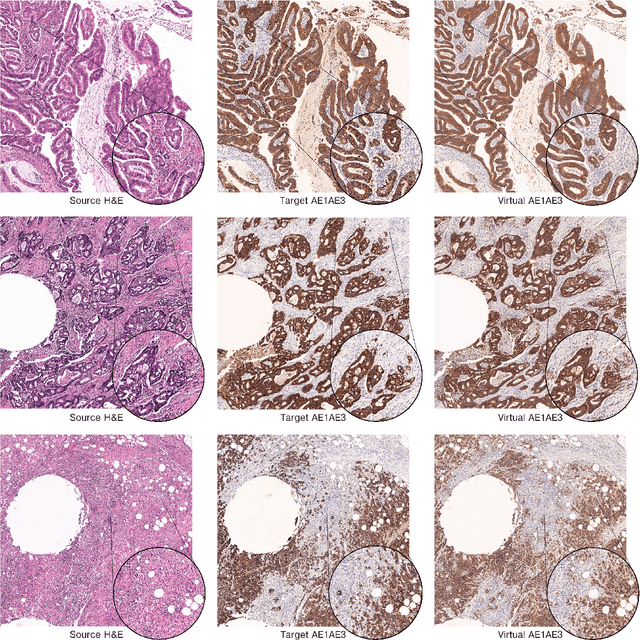
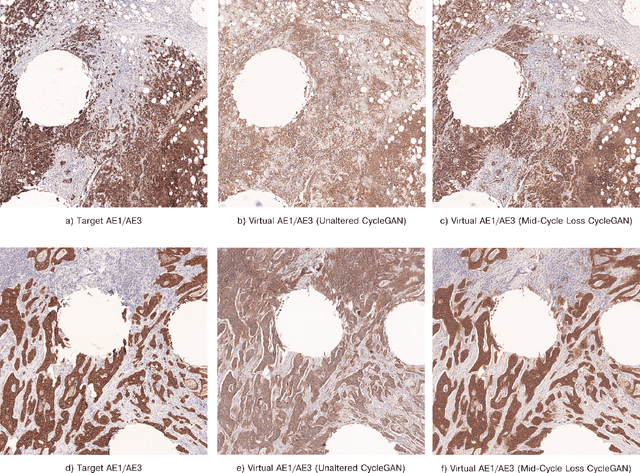
Immunohistochemistry is a valuable diagnostic tool for cancer pathology. However, it requires specialist labs and equipment, is time-intensive, and is difficult to reproduce. Consequently, a long term aim is to provide a digital method of recreating physical immunohistochemical stains. Generative Adversarial Networks have become exceedingly advanced at mapping one image type to another and have shown promise at inferring immunostains from haematoxylin and eosin. However, they have a substantial weakness when used with pathology images as they can fabricate structures that are not present in the original data. CycleGANs can mitigate invented tissue structures in pathology image mapping but have a related disposition to generate areas of inaccurate staining. In this paper, we describe a modification to the loss function of a CycleGAN to improve its mapping ability for pathology images by enforcing realistic stain replication while retaining tissue structure. Our approach improves upon others by considering structure and staining during model training. We evaluated our network using the Fr\'echet Inception distance, coupled with a new technique that we propose to appraise the accuracy of virtual immunohistochemistry. This assesses the overlap between each stain component in the inferred and ground truth images through colour deconvolution, thresholding and the Sorensen-Dice coefficient. Our modified loss function resulted in a Dice coefficient for the virtual stain of 0.78 compared with the real AE1/AE3 slide. This was superior to the unaltered CycleGAN's score of 0.74. Additionally, our loss function improved the Fr\'echet Inception distance for the reconstruction to 74.54 from 76.47. We, therefore, describe an advance in virtual restaining that can extend to other immunostains and tumour types and deliver reproducible, fast and readily accessible immunohistochemistry worldwide.