 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Searching Intrinsic Dimensions of Vision Transformers
Apr 16, 2022
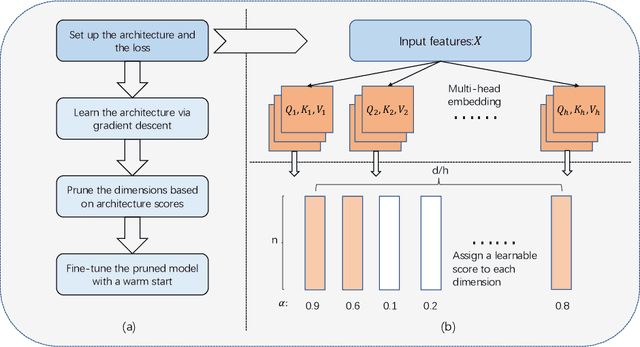
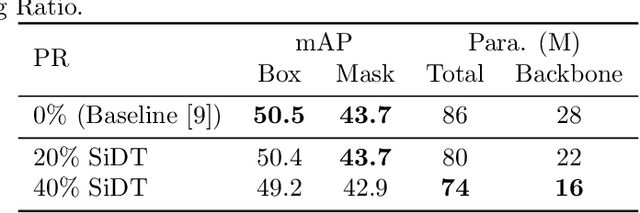
It has been shown by many researchers that transformers perform as well as convolutional neural networks in many computer vision tasks. Meanwhile, the large computational costs of its attention module hinder further studies and applications on edge devices. Some pruning methods have been developed to construct efficient vision transformers, but most of them have considered image classification tasks only. Inspired by these results, we propose SiDT, a method for pruning vision transformer backbones on more complicated vision tasks like object detection, based on the search of transformer dimensions. Experiments on CIFAR-100 and COCO datasets show that the backbones with 20\% or 40\% dimensions/parameters pruned can have similar or even better performance than the unpruned models. Moreover, we have also provided the complexity analysis and comparisons with the previous pruning methods.
3D endoscopic depth estimation using 3D surface-aware constraints
Mar 04, 2022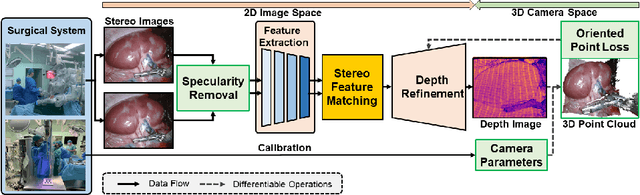
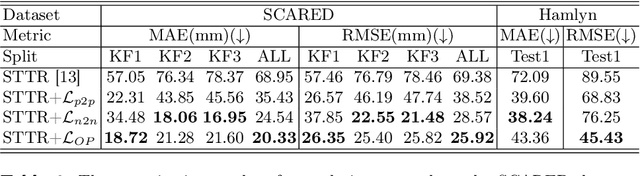
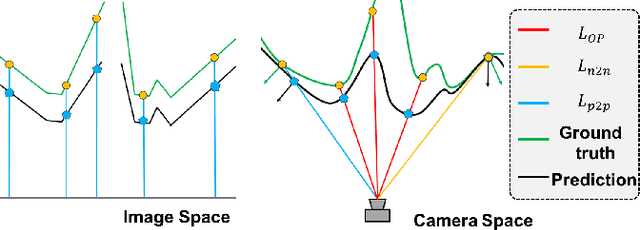

Robotic-assisted surgery allows surgeons to conduct precise surgical operations with stereo vision and flexible motor control. However, the lack of 3D spatial perception limits situational awareness during procedures and hinders mastering surgical skills in the narrow abdominal space. Depth estimation, as a representative perception task, is typically defined as an image reconstruction problem. In this work, we show that depth estimation can be reformed from a 3D surface perspective. We propose a loss function for depth estimation that integrates the surface-aware constraints, leading to a faster and better convergence with the valid information from spatial information. In addition, camera parameters are incorporated into the training pipeline to increase the control and transparency of the depth estimation. We also integrate a specularity removal module to recover more buried image information. Quantitative experimental results on endoscopic datasets and user studies with medical professionals demonstrate the effectiveness of our method.
Iterative Facial Image Inpainting using Cyclic Reverse Generator
Jan 18, 2021
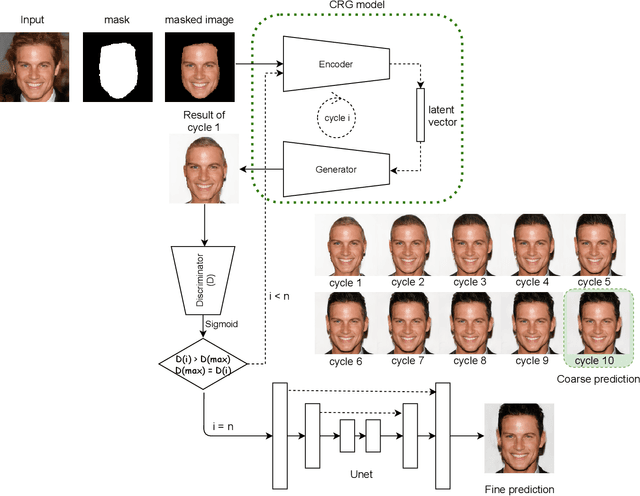

Facial image inpainting is a challenging problem as it requires generating new pixels that include semantic information for masked key components in a face, e.g., eyes and nose. Recently, remarkable methods have been proposed in this field. Most of these approaches use encoder-decoder architectures and have different limitations such as allowing unique results for a given image and a particular mask. Alternatively, some approaches generate promising results using different masks with generator networks. However, these approaches are optimization-based and usually require quite a number of iterations. In this paper, we propose an efficient solution to the facial image painting problem using the Cyclic Reverse Generator (CRG) architecture, which provides an encoder-generator model. We use the encoder to embed a given image to the generator space and incrementally inpaint the masked regions until a plausible image is generated; a discriminator network is utilized to assess the generated images during the iterations. We empirically observed that only a few iterations are sufficient to generate realistic images with the proposed model. After the generation process, for the post processing, we utilize a Unet model that we trained specifically for this task to remedy the artifacts close to the mask boundaries. Our method allows applying sketch-based inpaintings, using variety of mask types, and producing multiple and diverse results. We qualitatively compared our method with the state-of-the-art models and observed that our method can compete with the other models in all mask types; it is particularly better in images where larger masks are utilized.
Bridging Gap between Image Pixels and Semantics via Supervision: A Survey
Jul 29, 2021
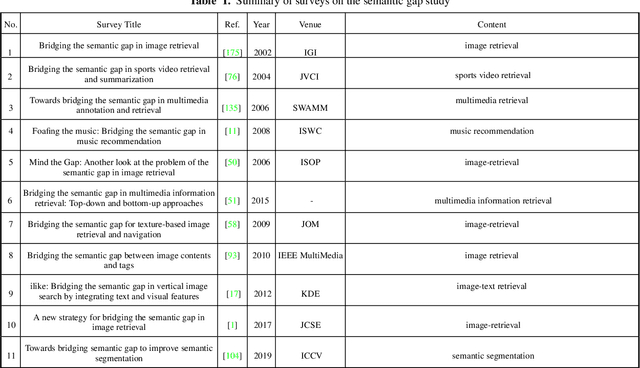

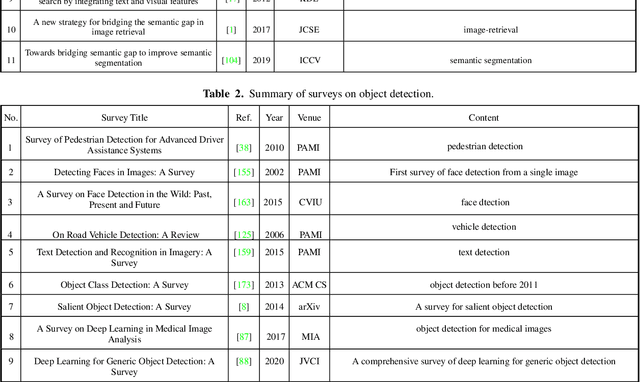
The fact that there exists a gap between low-level features and semantic meanings of images, called the semantic gap, is known for decades. Resolution of the semantic gap is a long standing problem. The semantic gap problem is reviewed and a survey on recent efforts in bridging the gap is made in this work. Most importantly, we claim that the semantic gap is primarily bridged through supervised learning today. Experiences are drawn from two application domains to illustrate this point: 1) object detection and 2) metric learning for content-based image retrieval (CBIR). To begin with, this paper offers a historical retrospective on supervision, makes a gradual transition to the modern data-driven methodology and introduces commonly used datasets. Then, it summarizes various supervision methods to bridge the semantic gap in the context of object detection and metric learning.
Reliable Detection of Doppelgängers based on Deep Face Representations
Jan 21, 2022
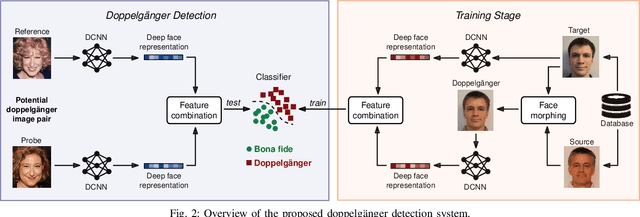


Doppelg\"angers (or lookalikes) usually yield an increased probability of false matches in a facial recognition system, as opposed to random face image pairs selected for non-mated comparison trials. In this work, we assess the impact of doppelg\"angers on the HDA Doppelg\"anger and Disguised Faces in The Wild databases using a state-of-the-art face recognition system. It is found that doppelg\"anger image pairs yield very high similarity scores resulting in a significant increase of false match rates. Further, we propose a doppelg\"anger detection method which distinguishes doppelg\"angers from mated comparison trials by analysing differences in deep representations obtained from face image pairs. The proposed detection system employs a machine learning-based classifier, which is trained with generated doppelg\"anger image pairs utilising face morphing techniques. Experimental evaluations conducted on the HDA Doppelg\"anger and Look-Alike Face databases reveal a detection equal error rate of approximately 2.7% for the task of separating mated authentication attempts from doppelg\"angers.
Lipschitz Regularized CycleGAN for Improving Semantic Robustness in Unpaired Image-to-image Translation
Dec 09, 2020
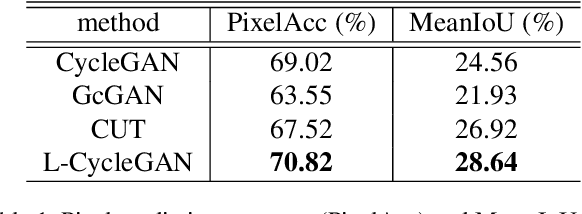

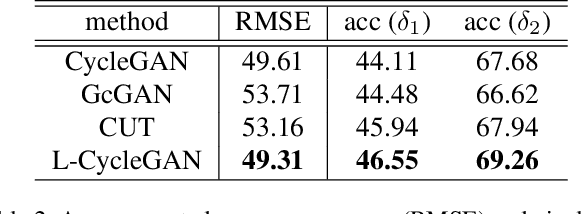
For unpaired image-to-image translation tasks, GAN-based approaches are susceptible to semantic flipping, i.e., contents are not preserved consistently. We argue that this is due to (1) the difference in semantic statistics between source and target domains and (2) the learned generators being non-robust. In this paper, we proposed a novel approach, Lipschitz regularized CycleGAN, for improving semantic robustness and thus alleviating the semantic flipping issue. During training, we add a gradient penalty loss to the generators, which encourages semantically consistent transformations. We evaluate our approach on multiple common datasets and compare with several existing GAN-based methods. Both quantitative and visual results suggest the effectiveness and advantage of our approach in producing robust transformations with fewer semantic flipping.
Semi-supervised Meta-learning with Disentanglement for Domain-generalised Medical Image Segmentation
Jun 24, 2021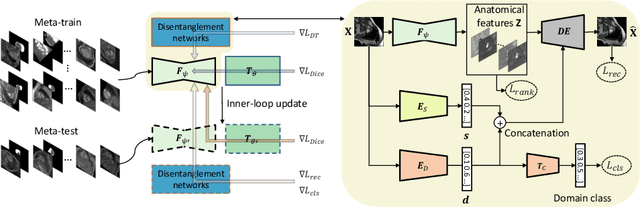
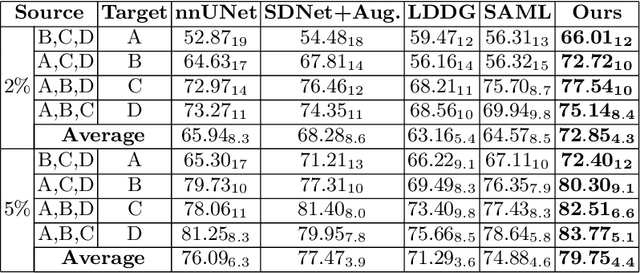
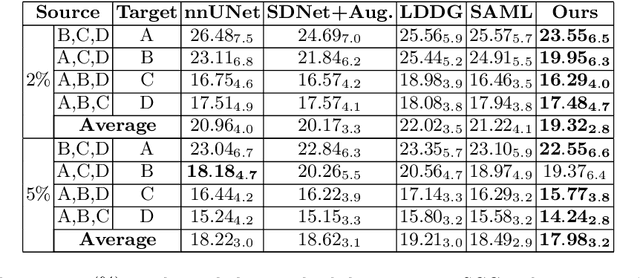
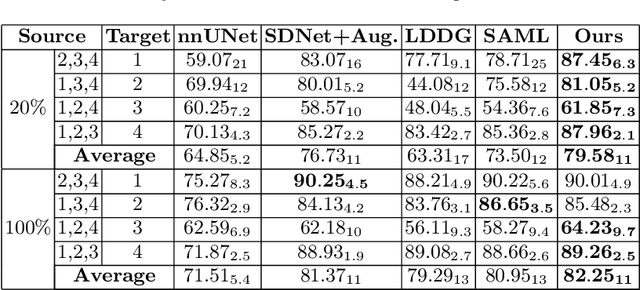
Generalising deep models to new data from new centres (termed here domains) remains a challenge. This is largely attributed to shifts in data statistics (domain shifts) between source and unseen domains. Recently, gradient-based meta-learning approaches where the training data are split into meta-train and meta-test sets to simulate and handle the domain shifts during training have shown improved generalisation performance. However, the current fully supervised meta-learning approaches are not scalable for medical image segmentation, where large effort is required to create pixel-wise annotations. Meanwhile, in a low data regime, the simulated domain shifts may not approximate the true domain shifts well across source and unseen domains. To address this problem, we propose a novel semi-supervised meta-learning framework with disentanglement. We explicitly model the representations related to domain shifts. Disentangling the representations and combining them to reconstruct the input image allows unlabeled data to be used to better approximate the true domain shifts for meta-learning. Hence, the model can achieve better generalisation performance, especially when there is a limited amount of labeled data. Experiments show that the proposed method is robust on different segmentation tasks and achieves state-of-the-art generalisation performance on two public benchmarks.
Fast and Structured Block-Term Tensor Decomposition For Hyperspectral Unmixing
May 08, 2022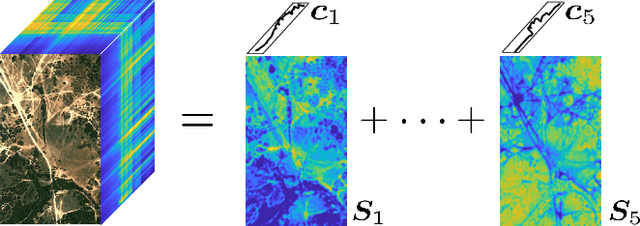
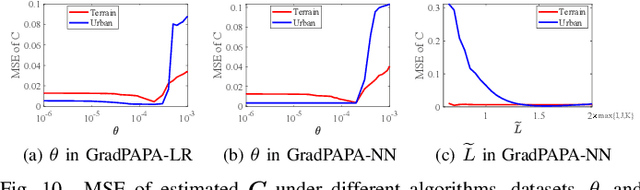
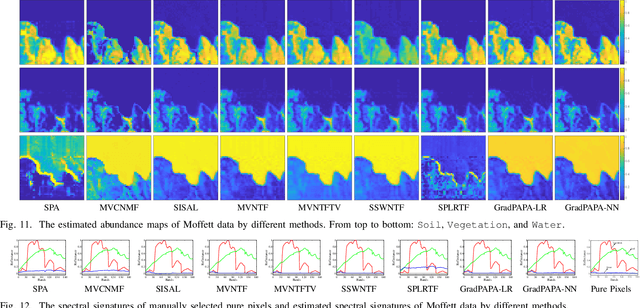
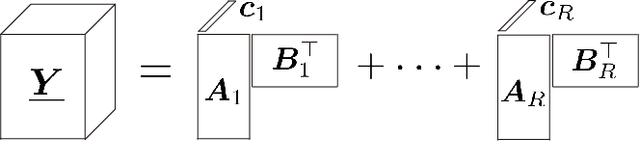
The block-term tensor decomposition model with multilinear rank-$(L_r,L_r,1)$ terms (or, the "LL1 tensor decomposition" in short) offers a valuable alternative for hyperspectral unmixing (HU) under the linear mixture model. Particularly, the LL1 decomposition ensures the endmember/abundance identifiability in scenarios where such guarantees are not supported by the classic matrix factorization (MF) approaches. However, existing LL1-based HU algorithms use a three-factor parameterization of the tensor (i.e., the hyperspectral image cube), which leads to a number of challenges including high per-iteration complexity, slow convergence, and difficulties in incorporating structural prior information. This work puts forth an LL1 tensor decomposition-based HU algorithm that uses a constrained two-factor re-parameterization of the tensor data. As a consequence, a two-block alternating gradient projection (GP)-based LL1 algorithm is proposed for HU. With carefully designed projection solvers, the GP algorithm enjoys a relatively low per-iteration complexity. Like in MF-based HU, the factors under our parameterization correspond to the endmembers and abundances. Thus, the proposed framework is natural to incorporate physics-motivated priors that arise in HU. The proposed algorithm often attains orders-of-magnitude speedup and substantial HU performance gains compared to the existing three-factor parameterization-based HU algorithms.
Analysis of Visual Reasoning on One-Stage Object Detection
Feb 26, 2022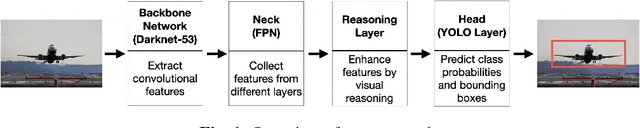
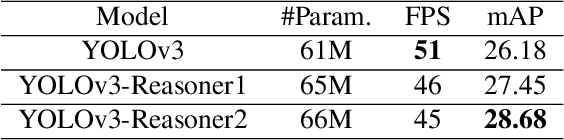
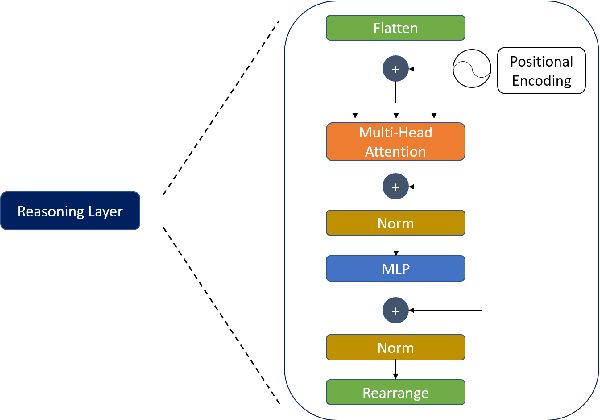
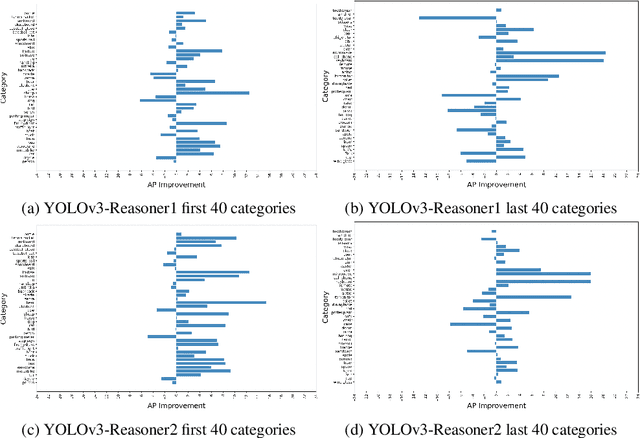
Current state-of-the-art one-stage object detectors are limited by treating each image region separately without considering possible relations of the objects. This causes dependency solely on high-quality convolutional feature representations for detecting objects successfully. However, this may not be possible sometimes due to some challenging conditions. In this paper, the usage of reasoning features on one-stage object detection is analyzed. We attempted different architectures that reason the relations of the image regions by using self-attention. YOLOv3-Reasoner2 model spatially and semantically enhances features in the reasoning layer and fuses them with the original convolutional features to improve performance. The YOLOv3-Reasoner2 model achieves around 2.5% absolute improvement with respect to baseline YOLOv3 on COCO in terms of mAP while still running in real-time.
Unpaired Single-Image Depth Synthesis with cycle-consistent Wasserstein GANs
Mar 31, 2021
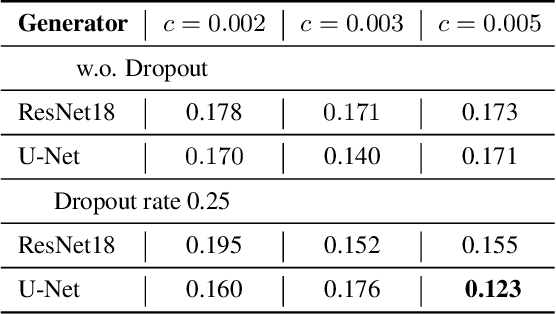
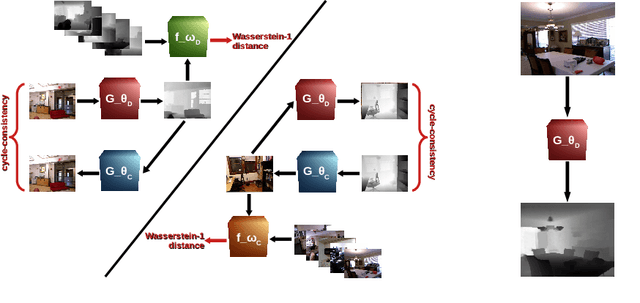
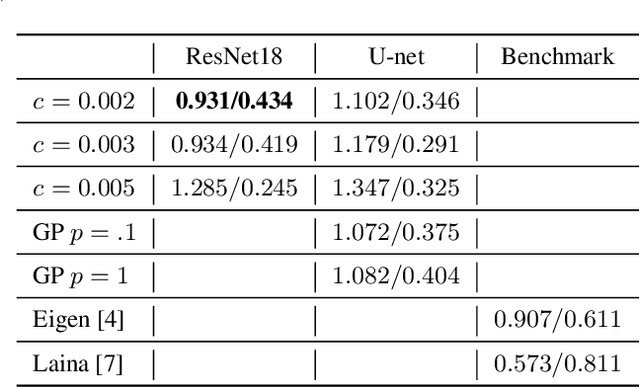
Real-time estimation of actual environment depth is an essential module for various autonomous system tasks such as localization, obstacle detection and pose estimation. During the last decade of machine learning, extensive deployment of deep learning methods to computer vision tasks yielded successful approaches for realistic depth synthesis out of a simple RGB modality. While most of these models rest on paired depth data or availability of video sequences and stereo images, there is a lack of methods facing single-image depth synthesis in an unsupervised manner. Therefore, in this study, latest advancements in the field of generative neural networks are leveraged to fully unsupervised single-image depth synthesis. To be more exact, two cycle-consistent generators for RGB-to-depth and depth-to-RGB transfer are implemented and simultaneously optimized using the Wasserstein-1 distance. To ensure plausibility of the proposed method, we apply the models to a self acquised industrial data set as well as to the renown NYU Depth v2 data set, which allows comparison with existing approaches. The observed success in this study suggests high potential for unpaired single-image depth estimation in real world applications.