 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EDTER: Edge Detection with Transformer
Mar 16, 2022
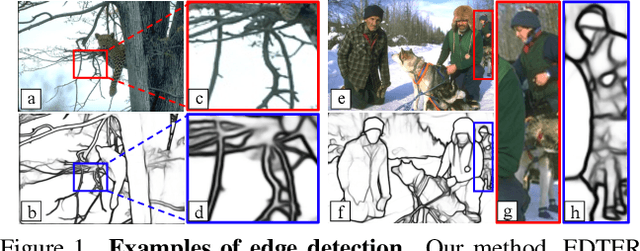

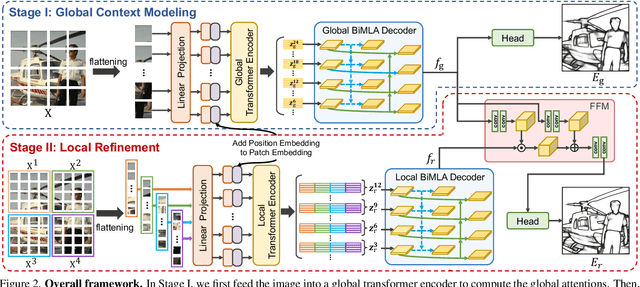
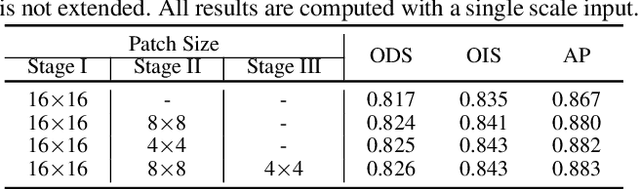
Convolutional neural networks have made significant progresses in edge detection by progressively exploring the context and semantic features. However, local details are gradually suppressed with the enlarging of receptive fields. Recently, vision transformer has shown excellent capability in capturing long-range dependencies. Inspired by this, we propose a novel transformer-based edge detector, \emph{Edge Detection TransformER (EDTER)}, to extract clear and crisp object boundaries and meaningful edges by exploiting the full image context information and detailed local cues simultaneously. EDTER works in two stages. In Stage I, a global transformer encoder is used to capture long-range global context on coarse-grained image patches. Then in Stage II, a local transformer encoder works on fine-grained patches to excavate the short-range local cues. Each transformer encoder is followed by an elaborately designed Bi-directional Multi-Level Aggregation decoder to achieve high-resolution features. Finally, the global context and local cues are combined by a Feature Fusion Module and fed into a decision head for edge prediction. Extensive experiments on BSDS500, NYUDv2, and Multicue demonstrate the superiority of EDTER in comparison with state-of-the-arts.
Analysis of Visual Reasoning on One-Stage Object Detection
Feb 26, 2022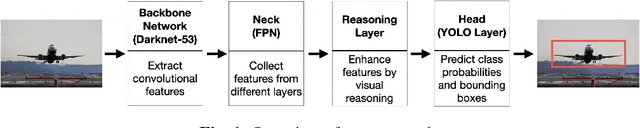
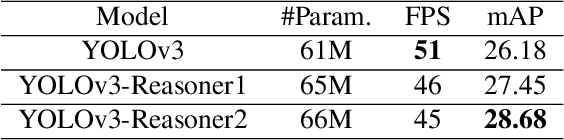
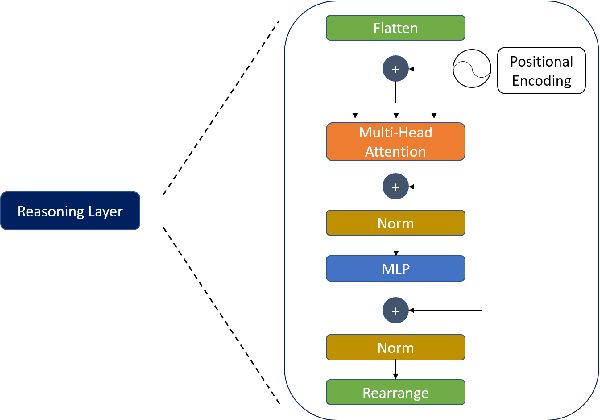
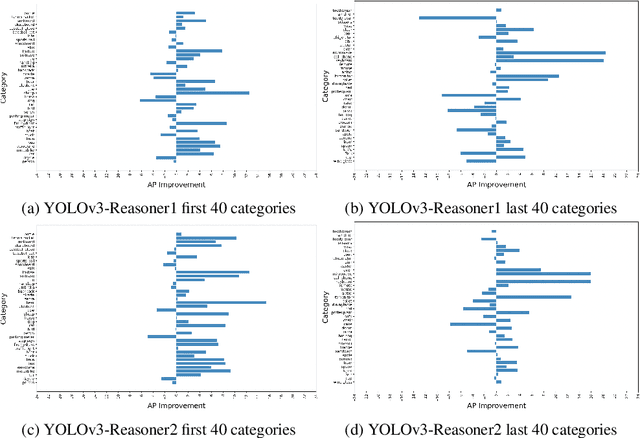
Current state-of-the-art one-stage object detectors are limited by treating each image region separately without considering possible relations of the objects. This causes dependency solely on high-quality convolutional feature representations for detecting objects successfully. However, this may not be possible sometimes due to some challenging conditions. In this paper, the usage of reasoning features on one-stage object detection is analyzed. We attempted different architectures that reason the relations of the image regions by using self-attention. YOLOv3-Reasoner2 model spatially and semantically enhances features in the reasoning layer and fuses them with the original convolutional features to improve performance. The YOLOv3-Reasoner2 model achieves around 2.5% absolute improvement with respect to baseline YOLOv3 on COCO in terms of mAP while still running in real-time.
Unsupervised Single-Image Reflection Separation Using Perceptual Deep Image Priors
Sep 01, 2020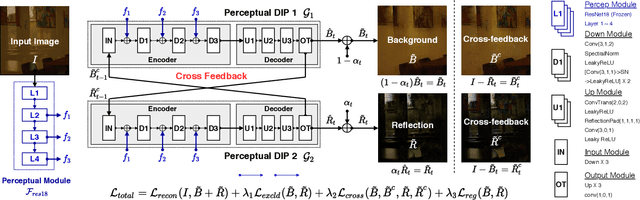
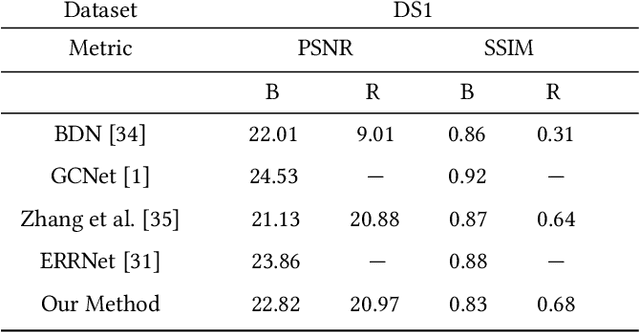

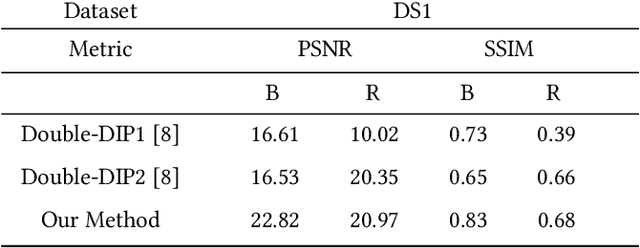
Reflections often degrade the quality of the image by obstructing the background scene. This is not desirable for everyday users, and it negatively impacts the performance of multimedia applications that process images with reflections. Most current methods for removing reflections utilize supervised-learning models. However, these models require an extensive number of image pairs to perform well, especially on natural images with reflection, which is difficult to achieve in practice. In this paper, we propose a novel unsupervised framework for single-image reflection separation. Instead of learning from a large dataset, we optimize the parameters of two cross-coupled deep convolutional networks on a target image to generate two exclusive background and reflection layers. In particular, we design a new architecture of the network to embed semantic features extracted from a pre-trained deep classification network, which gives more meaningful separation similar to human perception. Quantitative and qualitative results on commonly used datasets in the literature show that our method's performance is at least on par with the state-of-the-art supervised methods and, occasionally, better without requiring large training datasets. Our results also show that our method significantly outperforms the closest unsupervised method in the literature for removing reflections from single images.
Towards Bundle Adjustment for Satellite Imaging via Quantum Machine Learning
Apr 23, 2022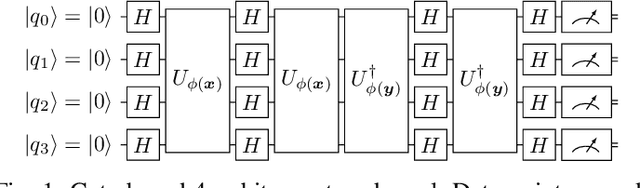
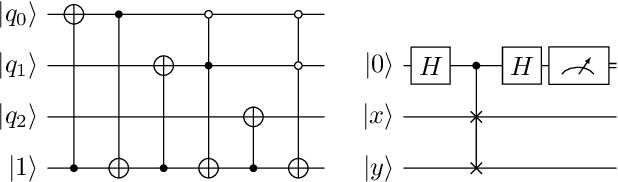


Given is a set of images, where all images show views of the same area at different points in time and from different viewpoints. The task is the alignment of all images such that relevant information, e.g., poses, changes, and terrain, can be extracted from the fused image. In this work, we focus on quantum methods for keypoint extraction and feature matching, due to the demanding computational complexity of these sub-tasks. To this end, k-medoids clustering, kernel density clustering, nearest neighbor search, and kernel methods are investigated and it is explained how these methods can be re-formulated for quantum annealers and gate-based quantum computers. Experimental results obtained on digital quantum emulation hardware, quantum annealers, and quantum gate computers show that classical systems still deliver superior results. However, the proposed methods are ready for the current and upcoming generations of quantum computing devices which have the potential to outperform classical systems in the near future.
Proximal PanNet: A Model-Based Deep Network for Pansharpening
Feb 12, 2022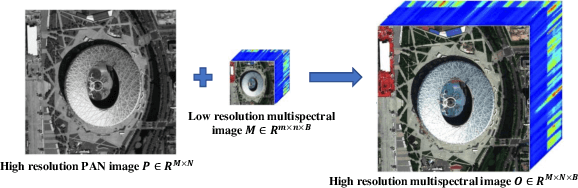
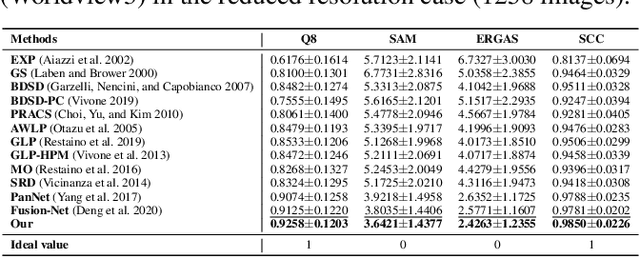
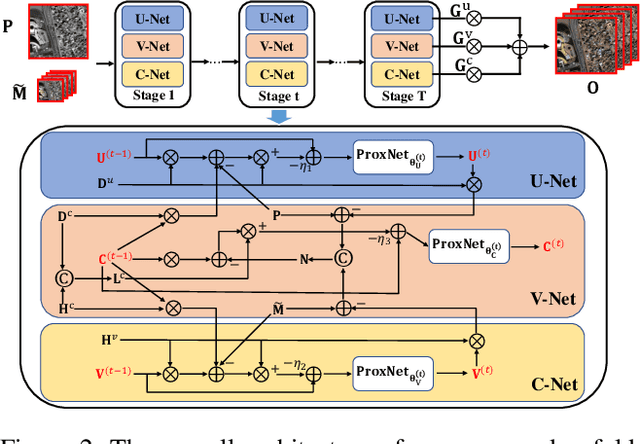
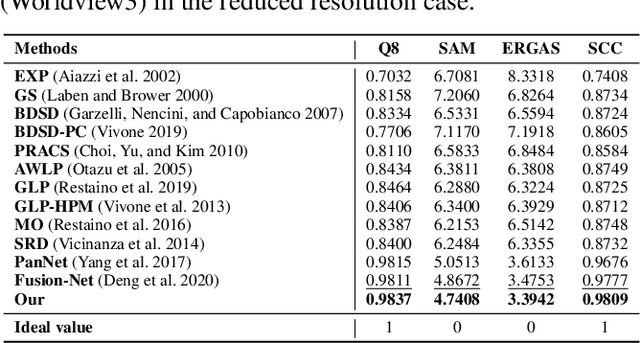
Recently, deep learning techniques have been extensively studied for pansharpening, which aims to generate a high resolution multispectral (HRMS) image by fusing a low resolution multispectral (LRMS) image with a high resolution panchromatic (PAN) image. However, existing deep learning-based pansharpening methods directly learn the mapping from LRMS and PAN to HRMS. These network architectures always lack sufficient interpretability, which limits further performance improvements. To alleviate this issue, we propose a novel deep network for pansharpening by combining the model-based methodology with the deep learning method. Firstly, we build an observation model for pansharpening using the convolutional sparse coding (CSC) technique and design a proximal gradient algorithm to solve this model. Secondly, we unfold the iterative algorithm into a deep network, dubbed as Proximal PanNet, by learning the proximal operators using convolutional neural networks. Finally, all the learnable modules can be automatically learned in an end-to-end manner. Experimental results on some benchmark datasets show that our network performs better than other advanced methods both quantitatively and qualitatively.
Multi-modal curb detection and filtering
May 14, 2022



Reliable knowledge of road boundaries is critical for autonomous vehicle navigation. We propose a robust curb detection and filtering technique based on the fusion of camera semantics and dense lidar point clouds. The lidar point clouds are collected by fusing multiple lidars for robust feature detection. The camera semantics are based on a modified EfficientNet architecture which is trained with labeled data collected from onboard fisheye cameras. The point clouds are associated with the closest curb segment with $L_2$-norm analysis after projecting into the image space with the fisheye model projection. Next, the selected points are clustered using unsupervised density-based spatial clustering to detect different curb regions. As new curb points are detected in consecutive frames they are associated with the existing curb clusters using temporal reachability constraints. If no reachability constraints are found a new curb cluster is formed from these new points. This ensures we can detect multiple curbs present in road segments consisting of multiple lanes if they are in the sensors' field of view. Finally, Delaunay filtering is applied for outlier removal and its performance is compared to traditional RANSAC-based filtering. An objective evaluation of the proposed solution is done using a high-definition map containing ground truth curb points obtained from a commercial map supplier. The proposed system has proven capable of detecting curbs of any orientation in complex urban road scenarios comprising straight roads, curved roads, and intersections with traffic isles.
FasterVideo: Efficient Online Joint Object Detection And Tracking
Apr 15, 2022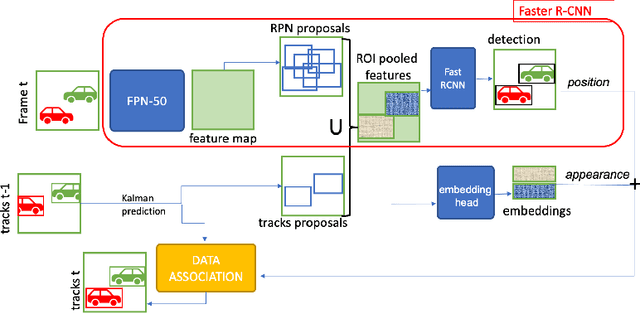

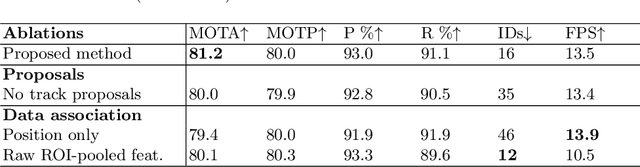
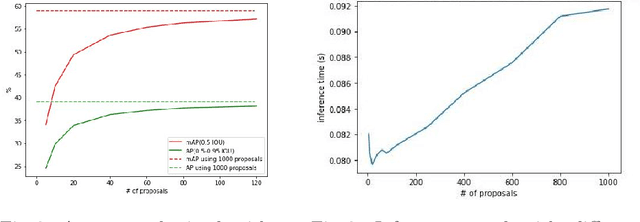
Object detection and tracking in videos represent essential and computationally demanding building blocks for current and future visual perception systems. In order to reduce the efficiency gap between available methods and computational requirements of real-world applications, we propose to re-think one of the most successful methods for image object detection, Faster R-CNN, and extend it to the video domain. Specifically, we extend the detection framework to learn instance-level embeddings which prove beneficial for data association and re-identification purposes. Focusing on the computational aspects of detection and tracking, our proposed method reaches a very high computational efficiency necessary for relevant applications, while still managing to compete with recent and state-of-the-art methods as shown in the experiments we conduct on standard object tracking benchmarks
Closing the Loop: Joint Rain Generation and Removal via Disentangled Image Translation
Mar 25, 2021
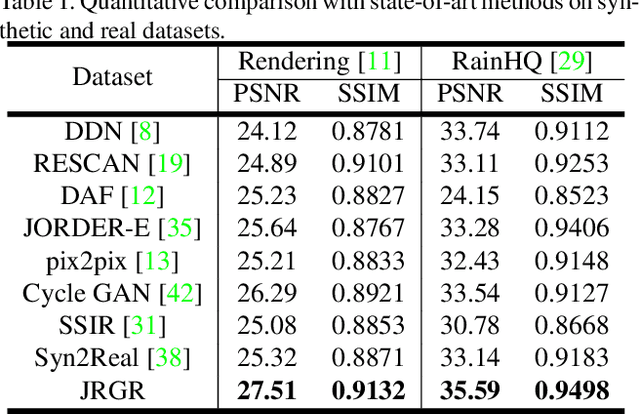
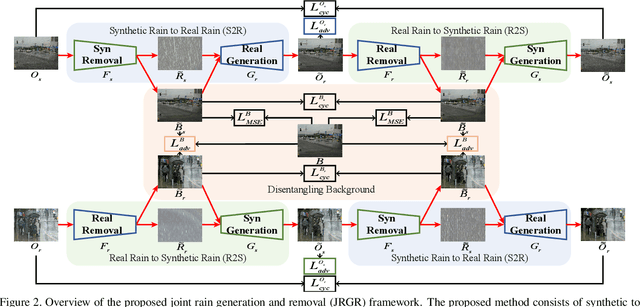
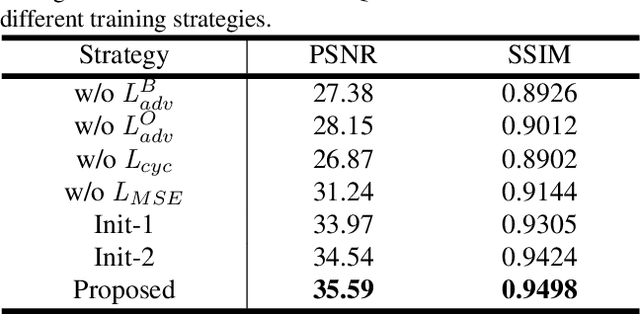
Existing deep learning-based image deraining methods have achieved promising performance for synthetic rainy images, typically rely on the pairs of sharp images and simulated rainy counterparts. However, these methods suffer from significant performance drop when facing the real rain, because of the huge gap between the simplified synthetic rain and the complex real rain. In this work, we argue that the rain generation and removal are the two sides of the same coin and should be tightly coupled. To close the loop, we propose to jointly learn real rain generation and removal procedure within a unified disentangled image translation framework. Specifically, we propose a bidirectional disentangled translation network, in which each unidirectional network contains two loops of joint rain generation and removal for both the real and synthetic rain image, respectively. Meanwhile, we enforce the disentanglement strategy by decomposing the rainy image into a clean background and rain layer (rain removal), in order to better preserve the identity background via both the cycle-consistency loss and adversarial loss, and ease the rain layer translating between the real and synthetic rainy image. A counterpart composition with the entanglement strategy is symmetrically applied for rain generation. Extensive experiments on synthetic and real-world rain datasets show the superiority of proposed method compared to state-of-the-arts.
Neural Optimal Transport
Jan 28, 2022

We present a novel neural-networks-based algorithm to compute optimal transport maps and plans for strong and weak transport costs. To justify the usage of neural networks, we prove that they are universal approximators of transport plans between probability distributions. We evaluate the performance of our optimal transport algorithm on toy examples and on the unpaired image-to-image style translation task.
Towards Unsupervised Deep Image Enhancement with Generative Adversarial Network
Dec 30, 2020


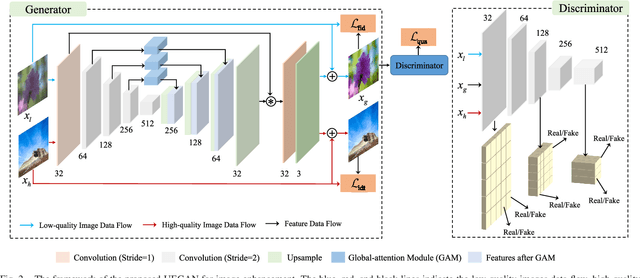
Improving the aesthetic quality of images is challenging and eager for the public. To address this problem, most existing algorithms are based on supervised learning methods to learn an automatic photo enhancer for paired data, which consists of low-quality photos and corresponding expert-retouched versions. However, the style and characteristics of photos retouched by experts may not meet the needs or preferences of general users. In this paper, we present an unsupervised image enhancement generative adversarial network (UEGAN), which learns the corresponding image-to-image mapping from a set of images with desired characteristics in an unsupervised manner, rather than learning on a large number of paired images. The proposed model is based on single deep GAN which embeds the modulation and attention mechanisms to capture richer global and local features. Based on the proposed model, we introduce two losses to deal with the unsupervised image enhancement: (1) fidelity loss, which is defined as a L2 regularization in the feature domain of a pre-trained VGG network to ensure the content between the enhanced image and the input image is the same, and (2) quality loss that is formulated as a relativistic hinge adversarial loss to endow the input image the desired characteristics. Both quantitative and qualitative results show that the proposed model effectively improves the aesthetic quality of images. Our code is available at: https://github.com/eezkni/UEGAN.