 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enabling Multimodal Generation on CLIP via Vision-Language Knowledge Distillation
Mar 12, 2022
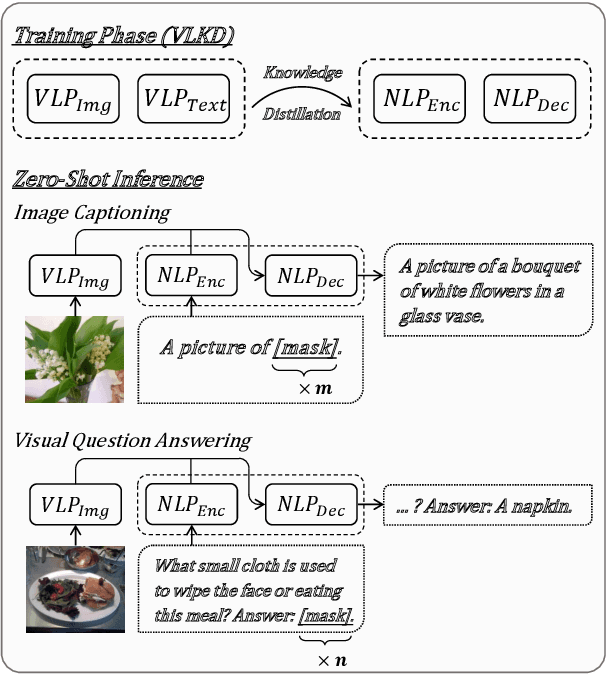
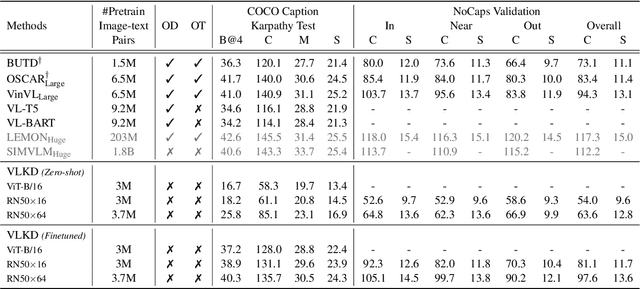
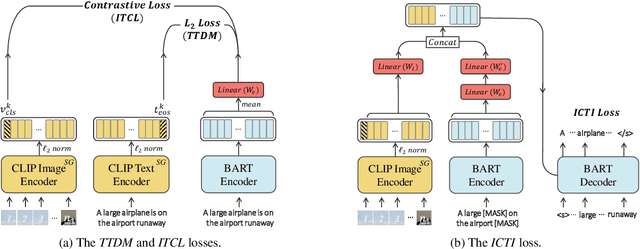
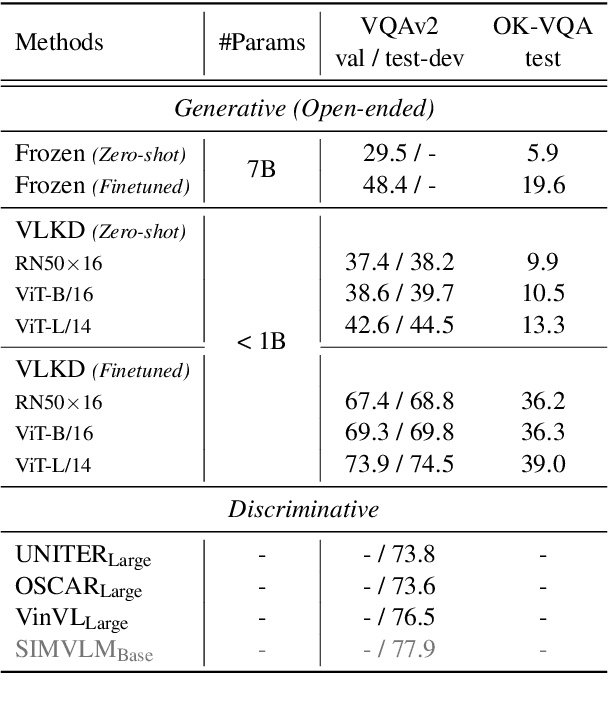
The recent large-scale vision-language pre-training (VLP) of dual-stream architectures (e.g., CLIP) with a tremendous amount of image-text pair data, has shown its superiority on various multimodal alignment tasks. Despite its success, the resulting models are not capable of multimodal generative tasks due to the weak text encoder. To tackle this problem, we propose to augment the dual-stream VLP model with a textual pre-trained language model (PLM) via vision-language knowledge distillation (VLKD), enabling the capability for multimodal generation. VLKD is pretty data- and computation-efficient compared to the pre-training from scratch. Experimental results show that the resulting model has strong zero-shot performance on multimodal generation tasks, such as open-ended visual question answering and image captioning. For example, it achieves 44.5% zero-shot accuracy on the VQAv2 dataset, surpassing the previous state-of-the-art zero-shot model with $7\times$ fewer parameters. Furthermore, the original textual language understanding and generation ability of the PLM is maintained after VLKD, which makes our model versatile for both multimodal and unimodal tasks.
Robust and Efficient Single-Pixel Image Classificationwith Nonlinear Optics
Jan 27, 2021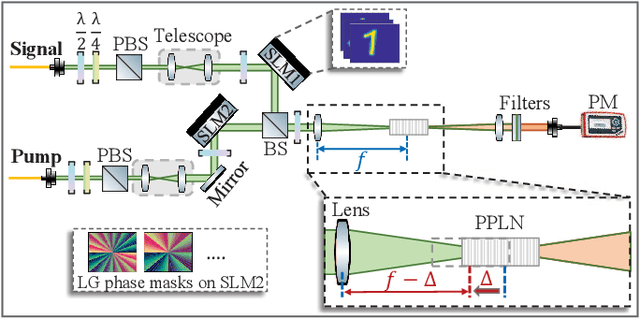
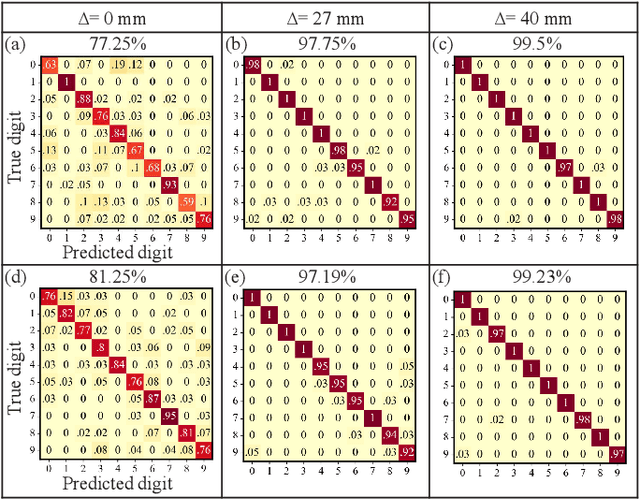
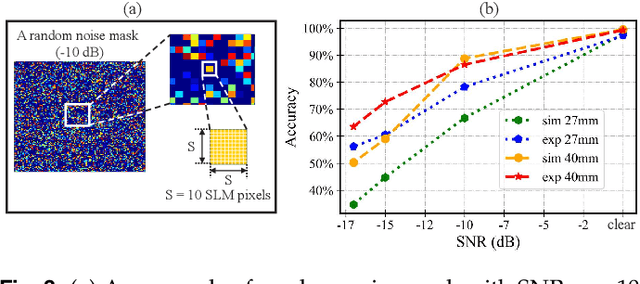
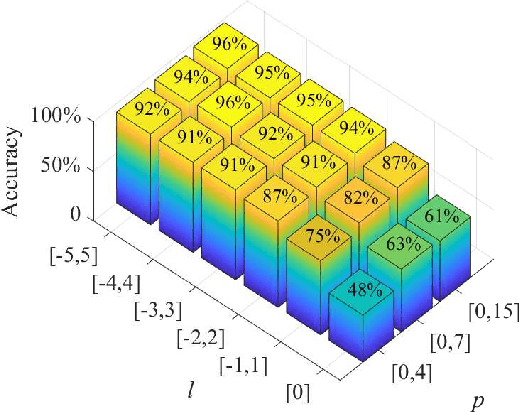
We present a hybrid image classifier by mode-selective image upconversion, single pixel photodetection, and deep learning, aiming at fast processing a large number of pixels. It utilizes partial Fourier transform to extract the signature features of images in both the original and Fourier domains, thereby significantly increasing the classification accuracy and robustness. Tested on the MNIST handwritten digit images, it boosts the accuracy from 81.25% to 99.23%, and achieves an 83% accuracy for highly contaminated images whose signal-to-noise ratio is only -17 dB. Our approach could prove useful for fast lidar data processing, high resolution image recognition, occluded target identification, atmosphere monitoring, and so on.
High-Resolution Deep Image Matting
Sep 14, 2020
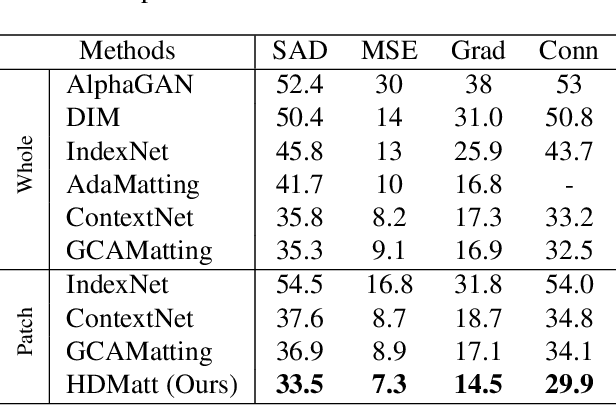
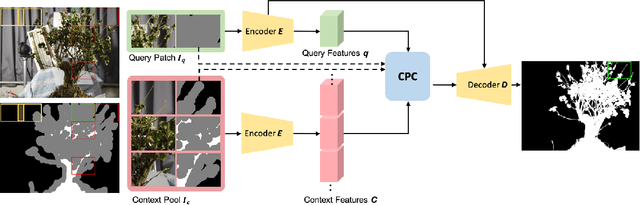
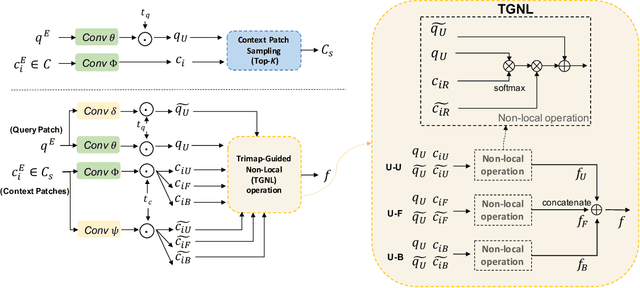
Image matting is a key technique for image and video editing and composition. Conventionally, deep learning approaches take the whole input image and an associated trimap to infer the alpha matte using convolutional neural networks. Such approaches set state-of-the-arts in image matting; however, they may fail in real-world matting applications due to hardware limitations, since real-world input images for matting are mostly of very high resolution. In this paper, we propose HDMatt, a first deep learning based image matting approach for high-resolution inputs. More concretely, HDMatt runs matting in a patch-based crop-and-stitch manner for high-resolution inputs with a novel module design to address the contextual dependency and consistency issues between different patches. Compared with vanilla patch-based inference which computes each patch independently, we explicitly model the cross-patch contextual dependency with a newly-proposed Cross-Patch Contextual module (CPC) guided by the given trimap. Extensive experiments demonstrate the effectiveness of the proposed method and its necessity for high-resolution inputs. Our HDMatt approach also sets new state-of-the-art performance on Adobe Image Matting and AlphaMatting benchmarks and produce impressive visual results on more real-world high-resolution images.
Identifying outliers in astronomical images with unsupervised machine learning
May 19, 2022
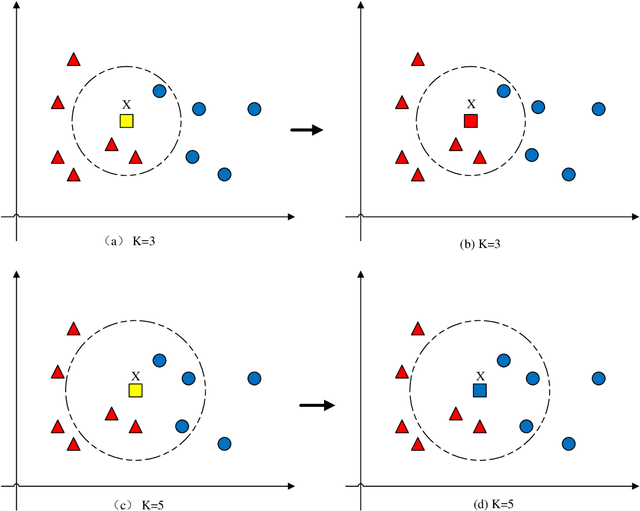
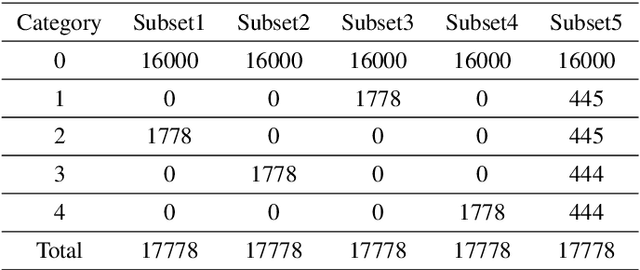
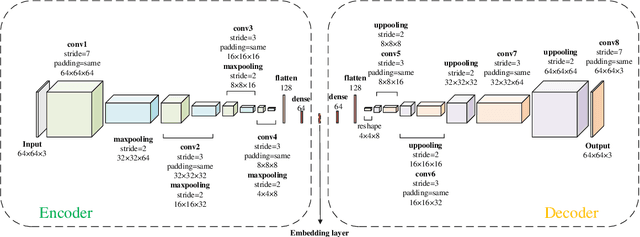
Astronomical outliers, such as unusual, rare or unknown types of astronomical objects or phenomena, constantly lead to the discovery of genuinely unforeseen knowledge in astronomy. More unpredictable outliers will be uncovered in principle with the increment of the coverage and quality of upcoming survey data. However, it is a severe challenge to mine rare and unexpected targets from enormous data with human inspection due to a significant workload. Supervised learning is also unsuitable for this purpose since designing proper training sets for unanticipated signals is unworkable. Motivated by these challenges, we adopt unsupervised machine learning approaches to identify outliers in the data of galaxy images to explore the paths for detecting astronomical outliers. For comparison, we construct three methods, which are built upon the k-nearest neighbors (KNN), Convolutional Auto-Encoder (CAE)+ KNN, and CAE + KNN + Attention Mechanism (attCAE KNN) separately. Testing sets are created based on the Galaxy Zoo image data published online to evaluate the performance of the above methods. Results show that attCAE KNN achieves the best recall (78%), which is 53% higher than the classical KNN method and 22% higher than CAE+KNN. The efficiency of attCAE KNN (10 minutes) is also superior to KNN (4 hours) and equal to CAE+KNN(10 minutes) for accomplishing the same task. Thus, we believe it is feasible to detect astronomical outliers in the data of galaxy images in an unsupervised manner. Next, we will apply attCAE KNN to available survey datasets to assess its applicability and reliability.
Structured light dark-field microscope
Feb 10, 2022A resolution-enhanced dark-field microscope by structured light illumination is proposed to improve resolution and contrast. A set of phase-shifted fringes are projected to the sample plane at large angle to capture modulated dark-field images, from which resolution- and contrast-enhanced dark-field image, as well as sectioned dark-field image, can be obtained. Human tissue samples are tested to demonstrate the resolution and contrast enhancement. The system can be implemented in transmission-mode and reflectance-mode, with potential applications ranging from defect detection to biomedical imaging.
Topology-Preserving 3D Image Segmentation Based On Hyperelastic Regularization
Mar 31, 2021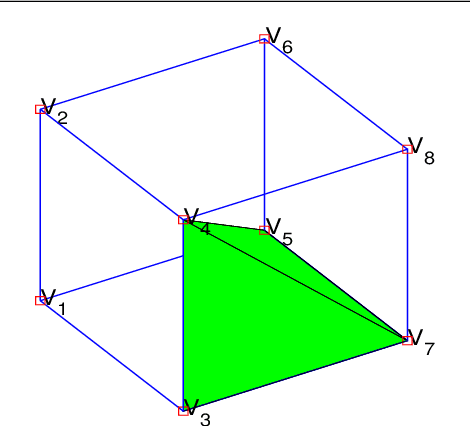
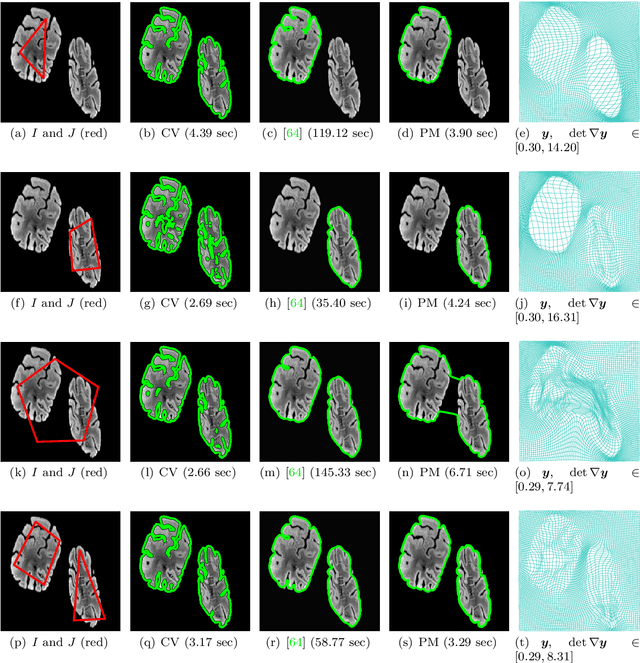
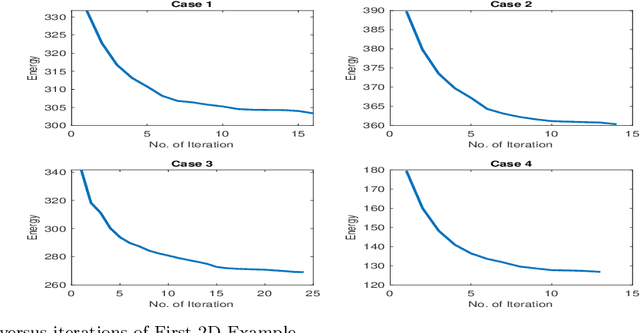
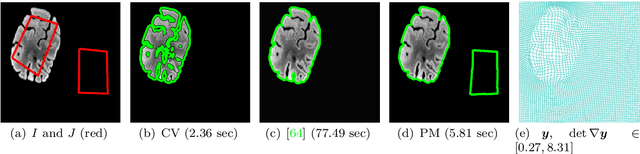
Image segmentation is to extract meaningful objects from a given image. For degraded images due to occlusions, obscurities or noises, the accuracy of the segmentation result can be severely affected. To alleviate this problem, prior information about the target object is usually introduced. In [10], a topology-preserving registration-based segmentation model was proposed, which is restricted to segment 2D images only. In this paper, we propose a novel 3D topology-preserving registration-based segmentation model with the hyperelastic regularization, which can handle both 2D and 3D images. The existence of the solution of the proposed model is established. We also propose a converging iterative scheme to solve the proposed model. Numerical experiments have been carried out on the synthetic and real images, which demonstrate the effectiveness of our proposed model.
Deep Aesthetic Assessment and Retrieval of Breast Cancer Treatment Outcomes
May 25, 2022Treatments for breast cancer have continued to evolve and improve in recent years, resulting in a substantial increase in survival rates, with approximately 80\% of patients having a 10-year survival period. Given the serious impact that breast cancer treatments can have on a patient's body image, consequently affecting her self-confidence and sexual and intimate relationships, it is paramount to ensure that women receive the treatment that optimizes both survival and aesthetic outcomes. Currently, there is no gold standard for evaluating the aesthetic outcome of breast cancer treatment. In addition, there is no standard way to show patients the potential outcome of surgery. The presentation of similar cases from the past would be extremely important to manage women's expectations of the possible outcome. In this work, we propose a deep neural network to perform the aesthetic evaluation. As a proof-of-concept, we focus on a binary aesthetic evaluation. Besides its use for classification, this deep neural network can also be used to find the most similar past cases by searching for nearest neighbours in the highly semantic space before classification. We performed the experiments on a dataset consisting of 143 photos of women after conservative treatment for breast cancer. The results for accuracy and balanced accuracy showed the superior performance of our proposed model compared to the state of the art in aesthetic evaluation of breast cancer treatments. In addition, the model showed a good ability to retrieve similar previous cases, with the retrieved cases having the same or adjacent class (in the 4-class setting) and having similar types of asymmetry. Finally, a qualitative interpretability assessment was also performed to analyse the robustness and trustworthiness of the model.
Transformers in 3D Point Clouds: A Survey
May 16, 2022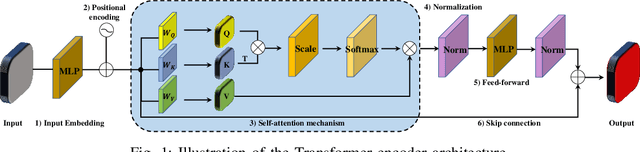
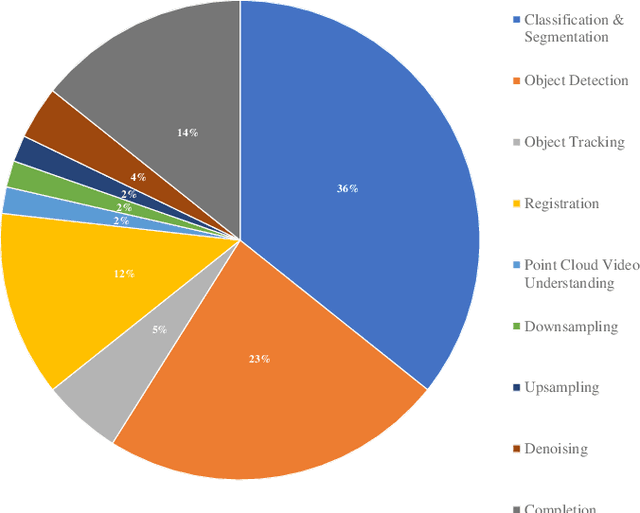
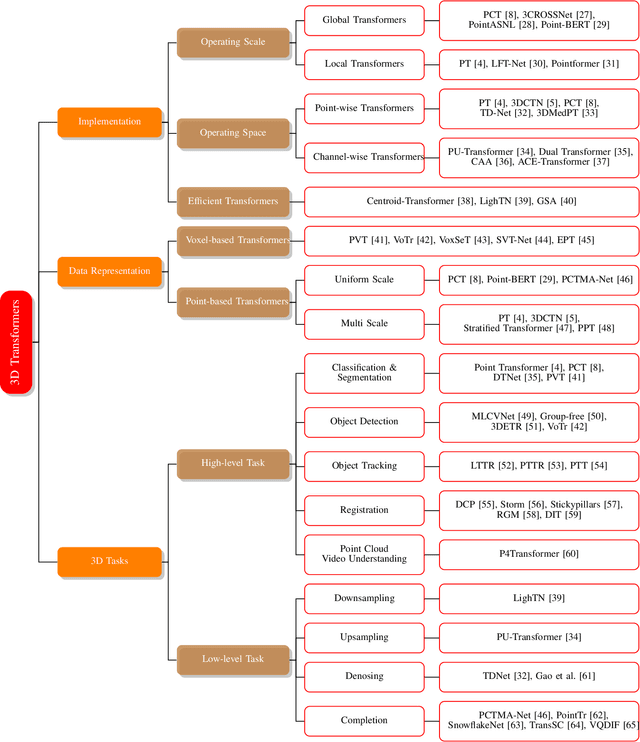
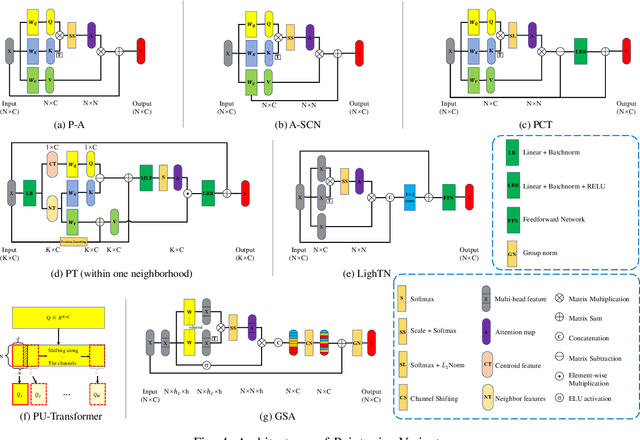
In recent years, Transformer models have been proven to have the remarkable ability of long-range dependencies modeling. They have achieved satisfactory results both in Natural Language Processing (NLP) and image processing. This significant achievement sparks great interest among researchers in 3D point cloud processing to apply them to various 3D tasks. Due to the inherent permutation invariance and strong global feature learning ability, 3D Transformers are well suited for point cloud processing and analysis. They have achieved competitive or even better performance compared to the state-of-the-art non-Transformer algorithms. This survey aims to provide a comprehensive overview of 3D Transformers designed for various tasks (e.g. point cloud classification, segmentation, object detection, and so on). We start by introducing the fundamental components of the general Transformer and providing a brief description of its application in 2D and 3D fields. Then, we present three different taxonomies (i.e., Transformer implementation-based taxonomy, data representation-based taxonomy, and task-based taxonomy) for method classification, which allows us to analyze involved methods from multiple perspectives. Furthermore, we also conduct an investigation of 3D self-attention mechanism variants designed for performance improvement. To demonstrate the superiority of 3D Transformers, we compare the performance of Transformer-based algorithms in terms of point cloud classification, segmentation, and object detection. Finally, we point out three potential future research directions, expecting to provide some benefit references for the development of 3D Transformers.
Disentangled3D: Learning a 3D Generative Model with Disentangled Geometry and Appearance from Monocular Images
Mar 29, 2022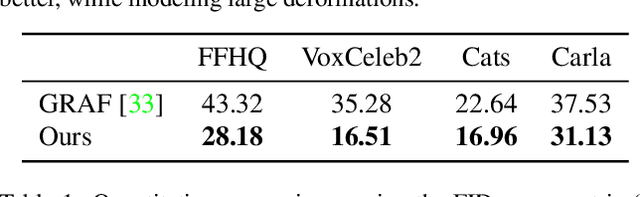
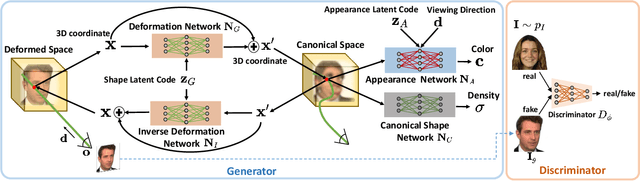


Learning 3D generative models from a dataset of monocular images enables self-supervised 3D reasoning and controllable synthesis. State-of-the-art 3D generative models are GANs which use neural 3D volumetric representations for synthesis. Images are synthesized by rendering the volumes from a given camera. These models can disentangle the 3D scene from the camera viewpoint in any generated image. However, most models do not disentangle other factors of image formation, such as geometry and appearance. In this paper, we design a 3D GAN which can learn a disentangled model of objects, just from monocular observations. Our model can disentangle the geometry and appearance variations in the scene, i.e., we can independently sample from the geometry and appearance spaces of the generative model. This is achieved using a novel non-rigid deformable scene formulation. A 3D volume which represents an object instance is computed as a non-rigidly deformed canonical 3D volume. Our method learns the canonical volume, as well as its deformations, jointly during training. This formulation also helps us improve the disentanglement between the 3D scene and the camera viewpoints using a novel pose regularization loss defined on the 3D deformation field. In addition, we further model the inverse deformations, enabling the computation of dense correspondences between images generated by our model. Finally, we design an approach to embed real images into the latent space of our disentangled generative model, enabling editing of real images.
Why-So-Deep: Towards Boosting Previously Trained Models for Visual Place Recognition
Jan 10, 2022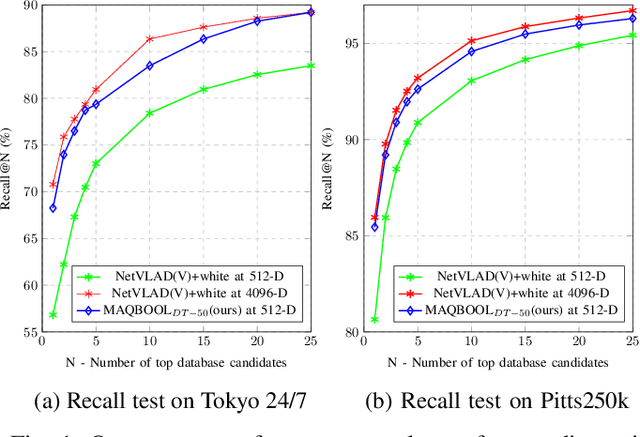

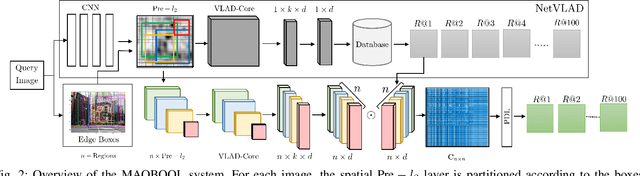

Deep learning-based image retrieval techniques for the loop closure detection demonstrate satisfactory performance. However, it is still challenging to achieve high-level performance based on previously trained models in different geographical regions. This paper addresses the problem of their deployment with simultaneous localization and mapping (SLAM) systems in the new environment. The general baseline approach uses additional information, such as GPS, sequential keyframes tracking, and re-training the whole environment to enhance the recall rate. We propose a novel approach for improving image retrieval based on previously trained models. We present an intelligent method, MAQBOOL, to amplify the power of pre-trained models for better image recall and its application to real-time multiagent SLAM systems. We achieve comparable image retrieval results at a low descriptor dimension (512-D), compared to the high descriptor dimension (4096-D) of state-of-the-art methods. We use spatial information to improve the recall rate in image retrieval on pre-trained models.