 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast and Structured Block-Term Tensor Decomposition For Hyperspectral Unmixing
May 08, 2022
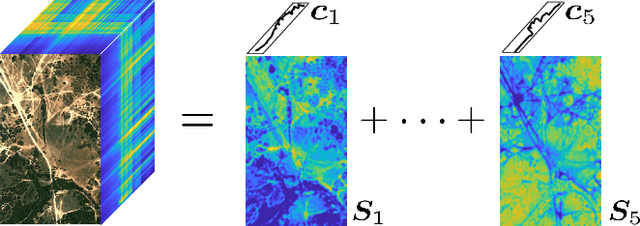
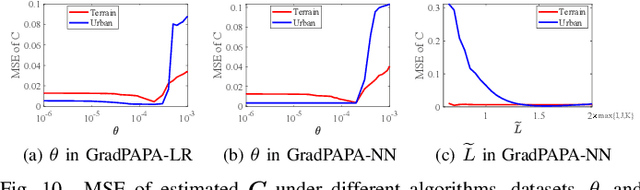
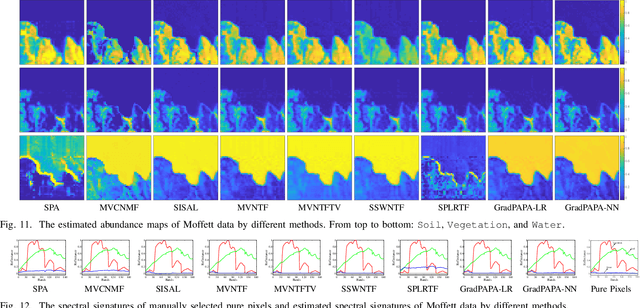
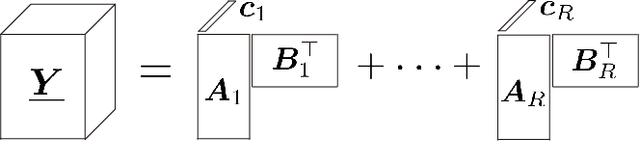
The block-term tensor decomposition model with multilinear rank-$(L_r,L_r,1)$ terms (or, the "LL1 tensor decomposition" in short) offers a valuable alternative for hyperspectral unmixing (HU) under the linear mixture model. Particularly, the LL1 decomposition ensures the endmember/abundance identifiability in scenarios where such guarantees are not supported by the classic matrix factorization (MF) approaches. However, existing LL1-based HU algorithms use a three-factor parameterization of the tensor (i.e., the hyperspectral image cube), which leads to a number of challenges including high per-iteration complexity, slow convergence, and difficulties in incorporating structural prior information. This work puts forth an LL1 tensor decomposition-based HU algorithm that uses a constrained two-factor re-parameterization of the tensor data. As a consequence, a two-block alternating gradient projection (GP)-based LL1 algorithm is proposed for HU. With carefully designed projection solvers, the GP algorithm enjoys a relatively low per-iteration complexity. Like in MF-based HU, the factors under our parameterization correspond to the endmembers and abundances. Thus, the proposed framework is natural to incorporate physics-motivated priors that arise in HU. The proposed algorithm often attains orders-of-magnitude speedup and substantial HU performance gains compared to the existing three-factor parameterization-based HU algorithms.
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
Feb 14, 2022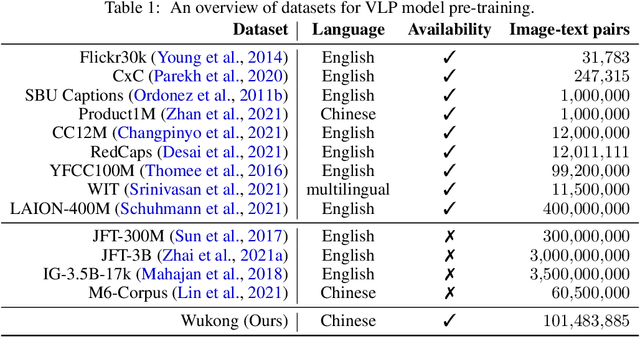
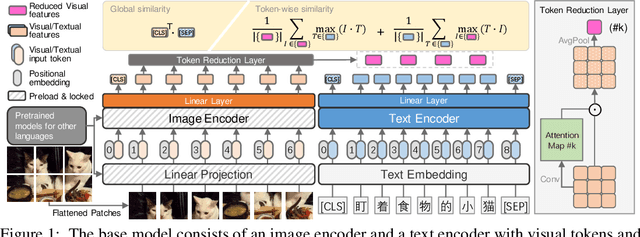


This paper presents a large-scale Chinese cross-modal dataset for benchmarking different multi-modal pre-training methods to facilitate the Vision-Language Pre-training (VLP) research and community development. Recent dual-stream VLP models like CLIP, ALIGN and FILIP have shown remarkable performance on various downstream tasks as well as their remarkable zero-shot ability in the open domain tasks. However, their success heavily relies on the scale of pre-trained datasets. Though there have been both small-scale vision-language English datasets like Flickr30k, CC12M as well as large-scale LAION-400M, the current community lacks large-scale Vision-Language benchmarks in Chinese, hindering the development of broader multilingual applications. On the other hand, there is very rare publicly available large-scale Chinese cross-modal pre-training dataset that has been released, making it hard to use pre-trained models as services for downstream tasks. In this work, we release a Large-Scale Chinese Cross-modal dataset named Wukong, containing 100 million Chinese image-text pairs from the web. Furthermore, we release a group of big models pre-trained with advanced image encoders (ResNet/ViT/SwinT) and different pre-training methods (CLIP/FILIP/LiT). We provide extensive experiments, a deep benchmarking of different downstream tasks, and some exciting findings. Experiments show that Wukong can serve as a promising Chinese pre-training dataset and benchmark for different cross-modal learning methods, which gives superior performance on various downstream tasks such as zero-shot image classification and image-text retrieval benchmarks. More information can refer to https://wukong-dataset.github.io/wukong-dataset/.
A Systematic Review on Computer Vision-Based Parking Lot Management Applied on Public Datasets
Mar 12, 2022
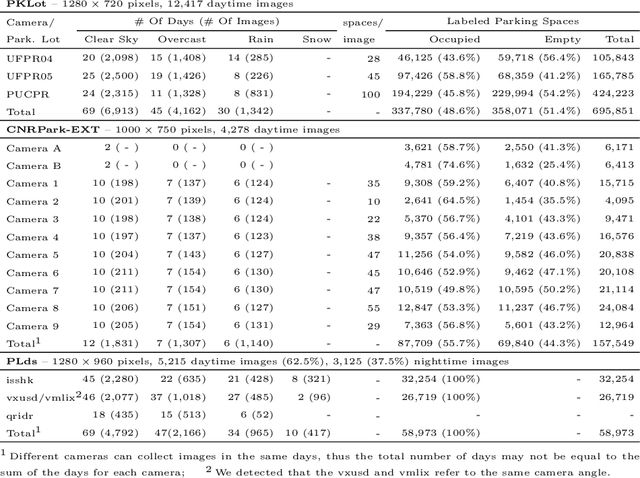

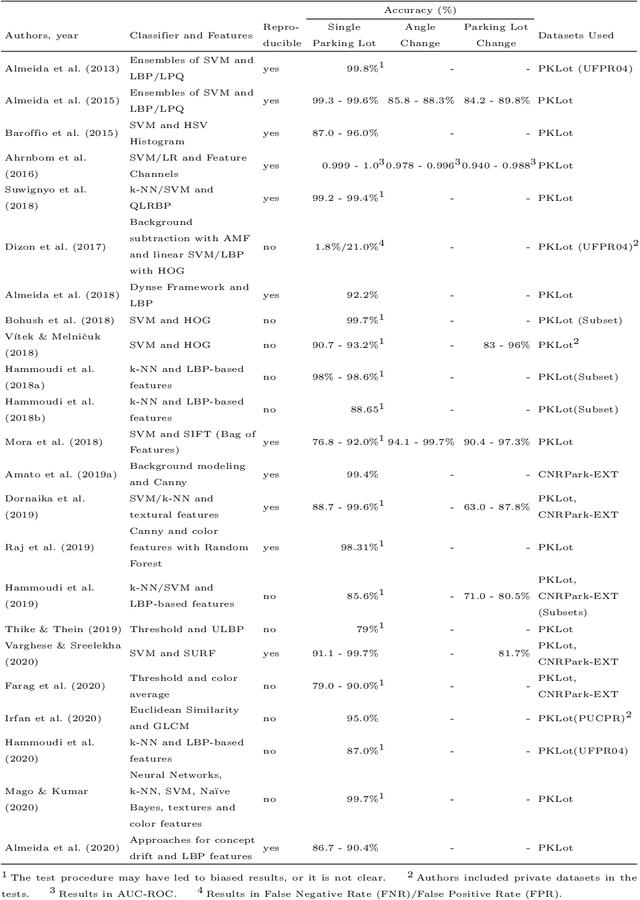
Computer vision-based parking lot management methods have been extensively researched upon owing to their flexibility and cost-effectiveness. To evaluate such methods authors often employ publicly available parking lot image datasets. In this study, we surveyed and compared robust publicly available image datasets specifically crafted to test computer vision-based methods for parking lot management approaches and consequently present a systematic and comprehensive review of existing works that employ such datasets. The literature review identified relevant gaps that require further research, such as the requirement of dataset-independent approaches and methods suitable for autonomous detection of position of parking spaces. In addition, we have noticed that several important factors such as the presence of the same cars across consecutive images, have been neglected in most studies, thereby rendering unrealistic assessment protocols. Furthermore, the analysis of the datasets also revealed that certain features that should be present when developing new benchmarks, such as the availability of video sequences and images taken in more diverse conditions, including nighttime and snow, have not been incorporated.
A Thin Format Vision-Based Tactile Sensor with A Micro Lens Array (MLA)
Apr 19, 2022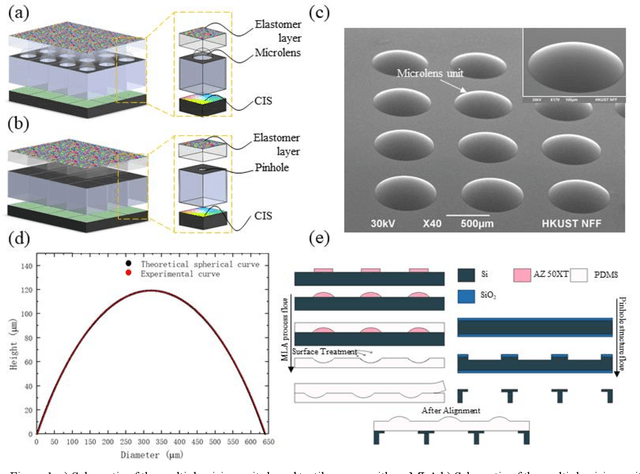
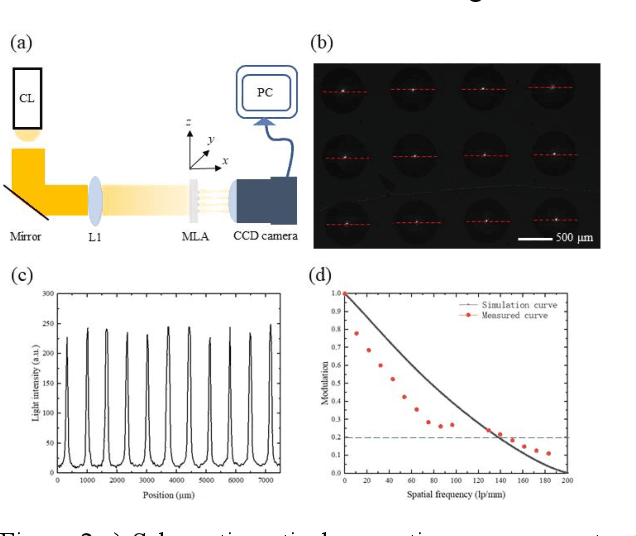
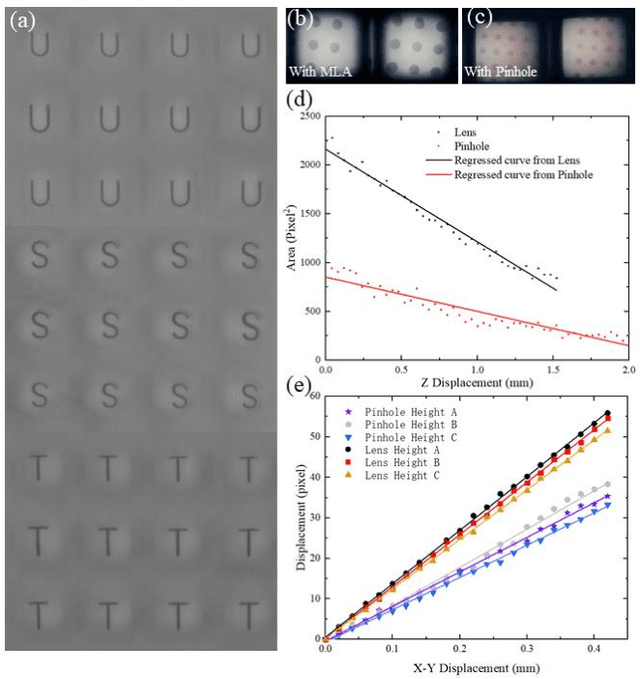
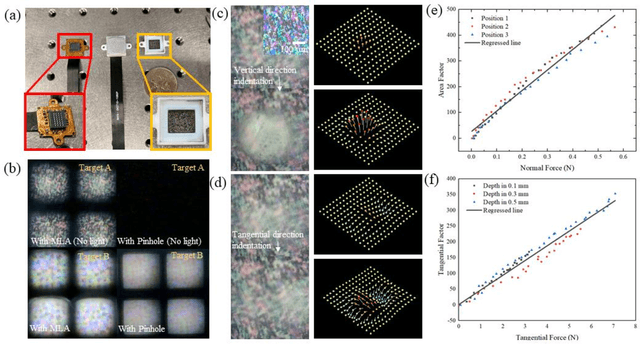
Vision-based tactile sensors have been widely studied in the robotics field for high spatial resolution and compatibility with machine learning algorithms. However, the currently employed sensor's imaging system is bulky limiting its further application. Here we present a micro lens array (MLA) based vison system to achieve a low thickness format of the sensor package with high tactile sensing performance. Multiple micromachined micro lens units cover the whole elastic touching layer and provide a stitched clear tactile image, enabling high spatial resolution with a thin thickness of 5 mm. The thermal reflow and soft lithography method ensure the uniform spherical profile and smooth surface of micro lens. Both optical and mechanical characterization demonstrated the sensor's stable imaging and excellent tactile sensing, enabling precise 3D tactile information, such as displacement mapping and force distribution with an ultra compact-thin structure.
Benchmarking Image Retrieval for Visual Localization
Dec 01, 2020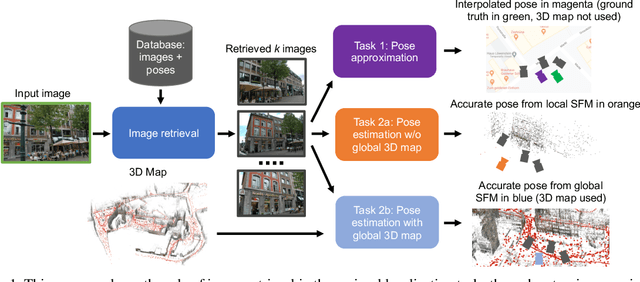
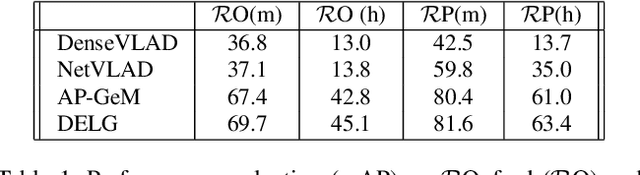
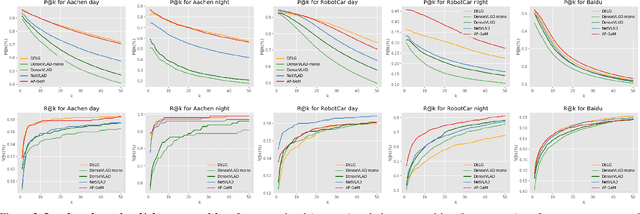
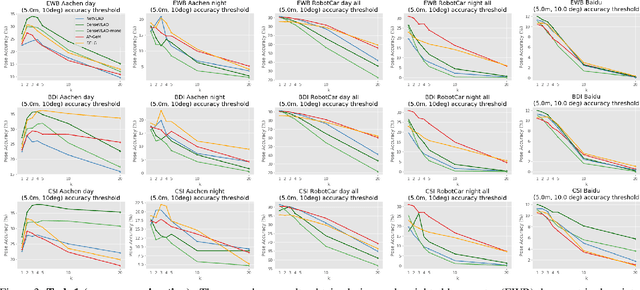
Visual localization, i.e., camera pose estimation in a known scene, is a core component of technologies such as autonomous driving and augmented reality. State-of-the-art localization approaches often rely on image retrieval techniques for one of two tasks: (1) provide an approximate pose estimate or (2) determine which parts of the scene are potentially visible in a given query image. It is common practice to use state-of-the-art image retrieval algorithms for these tasks. These algorithms are often trained for the goal of retrieving the same landmark under a large range of viewpoint changes. However, robustness to viewpoint changes is not necessarily desirable in the context of visual localization. This paper focuses on understanding the role of image retrieval for multiple visual localization tasks. We introduce a benchmark setup and compare state-of-the-art retrieval representations on multiple datasets. We show that retrieval performance on classical landmark retrieval/recognition tasks correlates only for some but not all tasks to localization performance. This indicates a need for retrieval approaches specifically designed for localization tasks. Our benchmark and evaluation protocols are available at https://github.com/naver/kapture-localization.
Semi-Cycled Generative Adversarial Networks for Real-World Face Super-Resolution
May 08, 2022
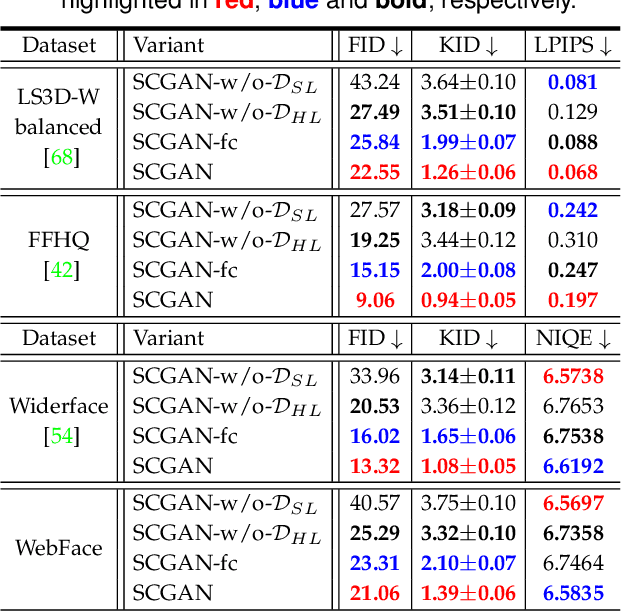


Real-world face super-resolution (SR) is a highly ill-posed image restoration task. The fully-cycled Cycle-GAN architecture is widely employed to achieve promising performance on face SR, but prone to produce artifacts upon challenging cases in real-world scenarios, since joint participation in the same degradation branch will impact final performance due to huge domain gap between real-world and synthetic LR ones obtained by generators. To better exploit the powerful generative capability of GAN for real-world face SR, in this paper, we establish two independent degradation branches in the forward and backward cycle-consistent reconstruction processes, respectively, while the two processes share the same restoration branch. Our Semi-Cycled Generative Adversarial Networks (SCGAN) is able to alleviate the adverse effects of the domain gap between the real-world LR face images and the synthetic LR ones, and to achieve accurate and robust face SR performance by the shared restoration branch regularized by both the forward and backward cycle-consistent learning processes. Experiments on two synthetic and two real-world datasets demonstrate that, our SCGAN outperforms the state-of-the-art methods on recovering the face structures/details and quantitative metrics for real-world face SR. The code will be publicly released at https://github.com/HaoHou-98/SCGAN.
Disentangled3D: Learning a 3D Generative Model with Disentangled Geometry and Appearance from Monocular Images
Mar 29, 2022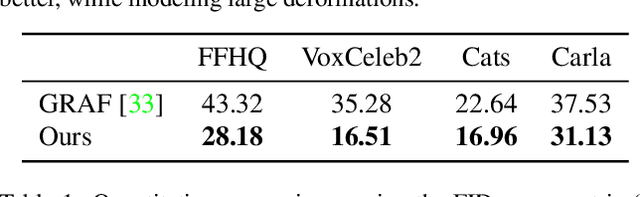
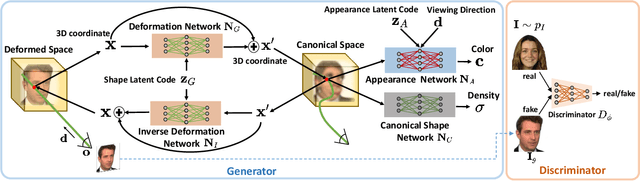


Learning 3D generative models from a dataset of monocular images enables self-supervised 3D reasoning and controllable synthesis. State-of-the-art 3D generative models are GANs which use neural 3D volumetric representations for synthesis. Images are synthesized by rendering the volumes from a given camera. These models can disentangle the 3D scene from the camera viewpoint in any generated image. However, most models do not disentangle other factors of image formation, such as geometry and appearance. In this paper, we design a 3D GAN which can learn a disentangled model of objects, just from monocular observations. Our model can disentangle the geometry and appearance variations in the scene, i.e., we can independently sample from the geometry and appearance spaces of the generative model. This is achieved using a novel non-rigid deformable scene formulation. A 3D volume which represents an object instance is computed as a non-rigidly deformed canonical 3D volume. Our method learns the canonical volume, as well as its deformations, jointly during training. This formulation also helps us improve the disentanglement between the 3D scene and the camera viewpoints using a novel pose regularization loss defined on the 3D deformation field. In addition, we further model the inverse deformations, enabling the computation of dense correspondences between images generated by our model. Finally, we design an approach to embed real images into the latent space of our disentangled generative model, enabling editing of real images.
Spatially-Adaptive Pixelwise Networks for Fast Image Translation
Dec 05, 2020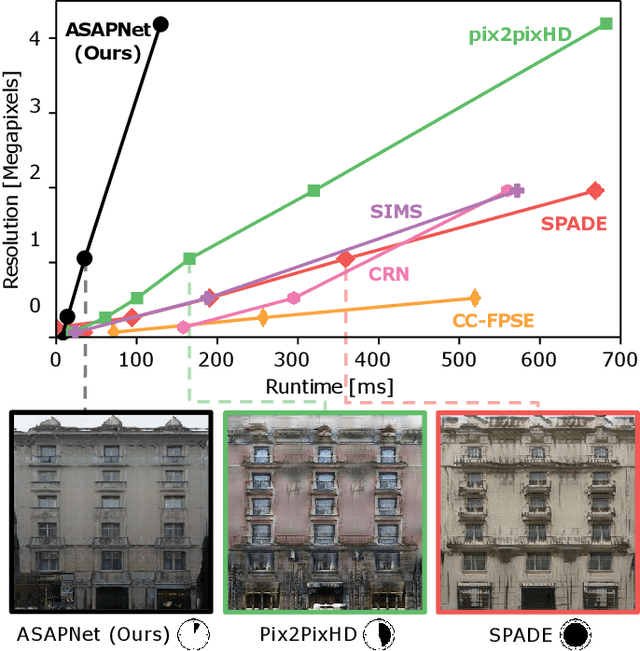

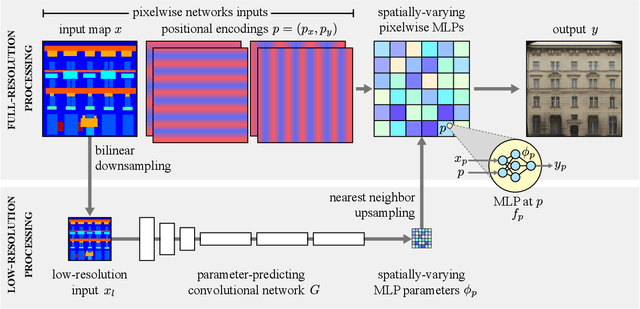
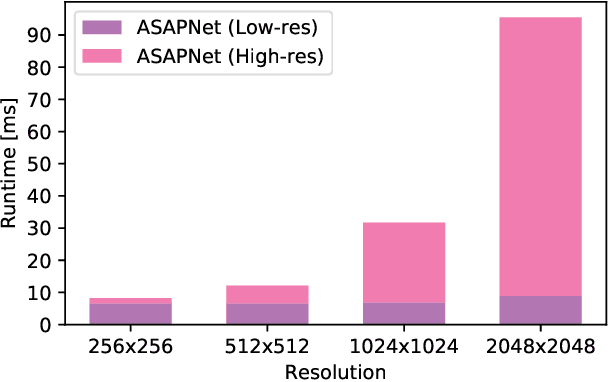
We introduce a new generator architecture, aimed at fast and efficient high-resolution image-to-image translation. We design the generator to be an extremely lightweight function of the full-resolution image. In fact, we use pixel-wise networks; that is, each pixel is processed independently of others, through a composition of simple affine transformations and nonlinearities. We take three important steps to equip such a seemingly simple function with adequate expressivity. First, the parameters of the pixel-wise networks are spatially varying so they can represent a broader function class than simple 1x1 convolutions. Second, these parameters are predicted by a fast convolutional network that processes an aggressively low-resolution representation of the input; Third, we augment the input image with a sinusoidal encoding of spatial coordinates, which provides an effective inductive bias for generating realistic novel high-frequency image content. As a result, our model is up to 18x faster than state-of-the-art baselines. We achieve this speedup while generating comparable visual quality across different image resolutions and translation domains.
Searching Intrinsic Dimensions of Vision Transformers
Apr 16, 2022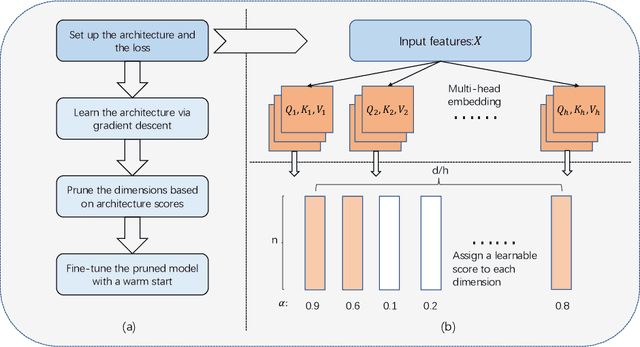
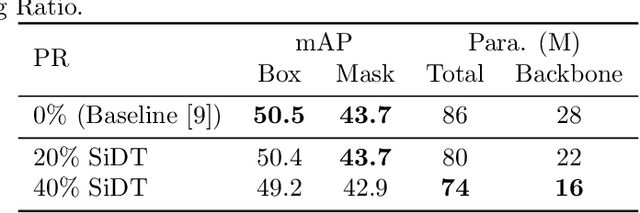
It has been shown by many researchers that transformers perform as well as convolutional neural networks in many computer vision tasks. Meanwhile, the large computational costs of its attention module hinder further studies and applications on edge devices. Some pruning methods have been developed to construct efficient vision transformers, but most of them have considered image classification tasks only. Inspired by these results, we propose SiDT, a method for pruning vision transformer backbones on more complicated vision tasks like object detection, based on the search of transformer dimensions. Experiments on CIFAR-100 and COCO datasets show that the backbones with 20\% or 40\% dimensions/parameters pruned can have similar or even better performance than the unpruned models. Moreover, we have also provided the complexity analysis and comparisons with the previous pruning methods.
Signature and Log-signature for the Study of Empirical Distributions Generated with GANs
Mar 07, 2022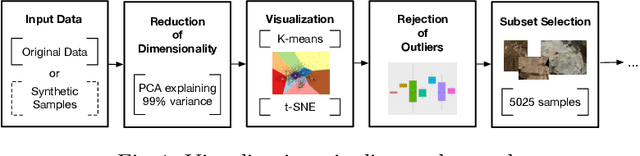


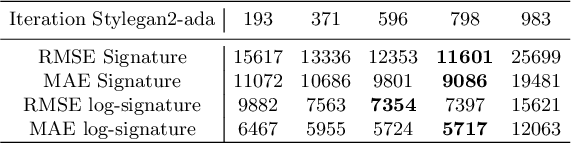
In this paper, we develop a new and systematic method to explore and analyze samples taken by NASA Perseverance on the surface of the planet Mars. A novel in this context PCA adaptive t-SNE is proposed, as well as the introduction of statistical measures to study the goodness of fit of the sample distribution. We go beyond visualization by generating synthetic imagery using Stylegan2-ADA that resemble the original terrain distribution. We also conduct synthetic image generation using the recently introduced Scored-based Generative Modeling. We bring forward the use of the recently developed Signature Transform as a way to measure the similarity between image distributions and provide detailed acquaintance and extensive evaluations. We are the first to pioneer RMSE and MAE Signature and log-signature as an alternative to measure GAN convergence. Insights on state-of-the-art instance segmentation of the samples by the use of a model DeepLabv3 are also given.