 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Time-multiplexed Neural Holography: A flexible framework for holographic near-eye displays with fast heavily-quantized spatial light modulators
May 05, 2022


Holographic near-eye displays offer unprecedented capabilities for virtual and augmented reality systems, including perceptually important focus cues. Although artificial intelligence--driven algorithms for computer-generated holography (CGH) have recently made much progress in improving the image quality and synthesis efficiency of holograms, these algorithms are not directly applicable to emerging phase-only spatial light modulators (SLM) that are extremely fast but offer phase control with very limited precision. The speed of these SLMs offers time multiplexing capabilities, essentially enabling partially-coherent holographic display modes. Here we report advances in camera-calibrated wave propagation models for these types of holographic near-eye displays and we develop a CGH framework that robustly optimizes the heavily quantized phase patterns of fast SLMs. Our framework is flexible in supporting runtime supervision with different types of content, including 2D and 2.5D RGBD images, 3D focal stacks, and 4D light fields. Using our framework, we demonstrate state-of-the-art results for all of these scenarios in simulation and experiment.
Coupled Iterative Refinement for 6D Multi-Object Pose Estimation
Apr 26, 2022
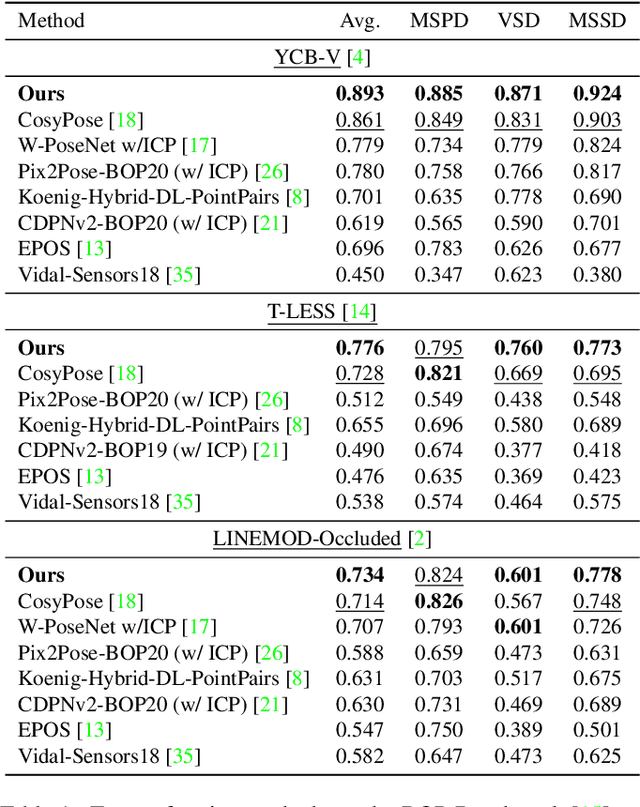
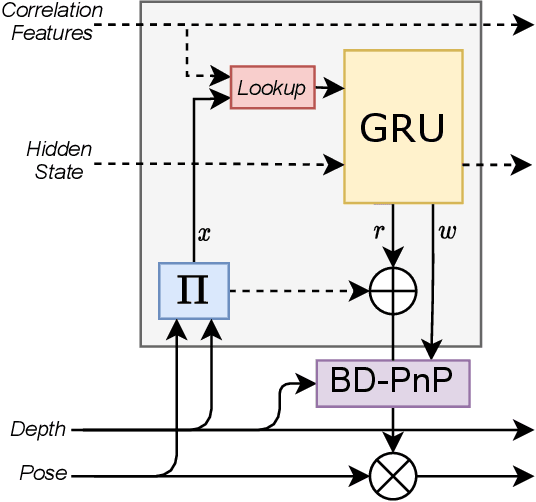
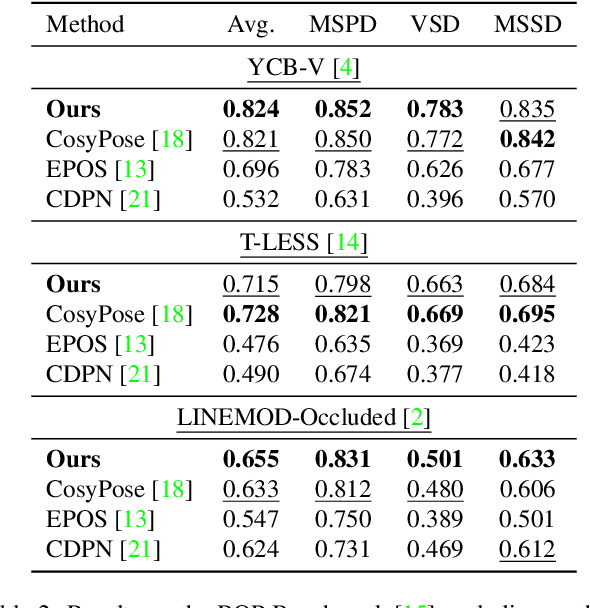
We address the task of 6D multi-object pose: given a set of known 3D objects and an RGB or RGB-D input image, we detect and estimate the 6D pose of each object. We propose a new approach to 6D object pose estimation which consists of an end-to-end differentiable architecture that makes use of geometric knowledge. Our approach iteratively refines both pose and correspondence in a tightly coupled manner, allowing us to dynamically remove outliers to improve accuracy. We use a novel differentiable layer to perform pose refinement by solving an optimization problem we refer to as Bidirectional Depth-Augmented Perspective-N-Point (BD-PnP). Our method achieves state-of-the-art accuracy on standard 6D Object Pose benchmarks. Code is available at https://github.com/princeton-vl/Coupled-Iterative-Refinement.
Rethinking Coarse-to-Fine Approach in Single Image Deblurring
Aug 11, 2021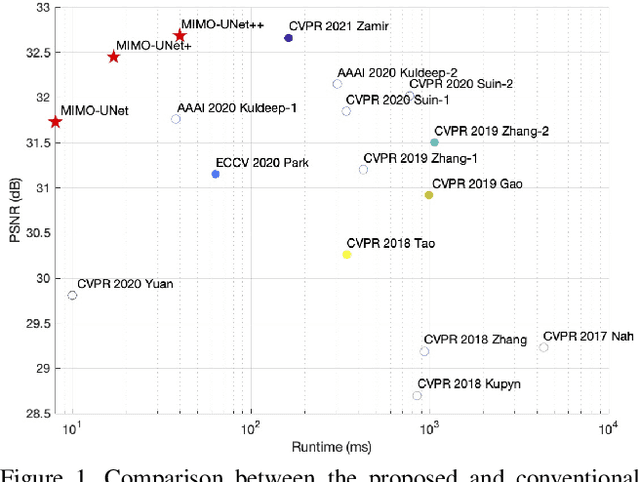
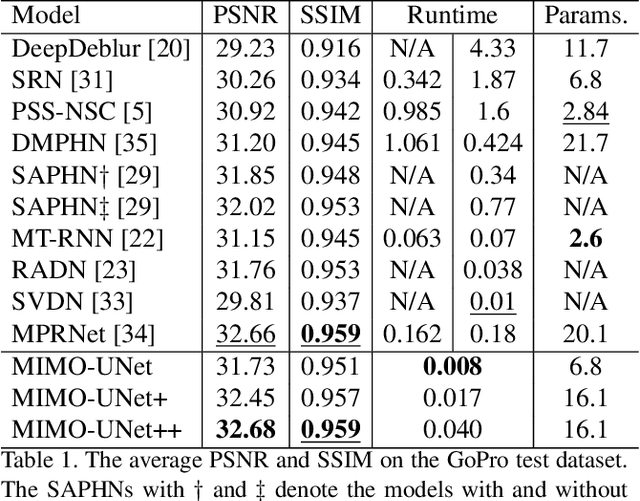
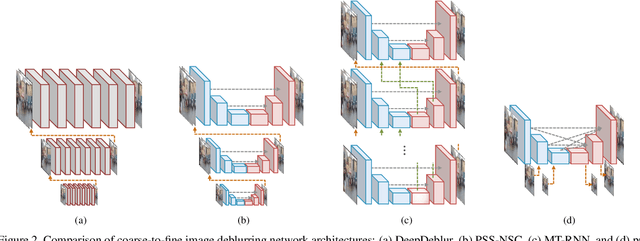
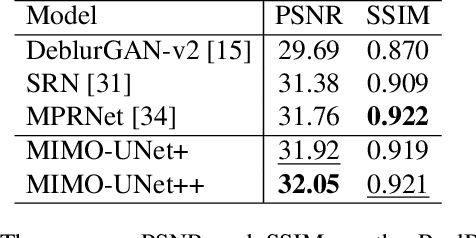
Coarse-to-fine strategies have been extensively used for the architecture design of single image deblurring networks. Conventional methods typically stack sub-networks with multi-scale input images and gradually improve sharpness of images from the bottom sub-network to the top sub-network, yielding inevitably high computational costs. Toward a fast and accurate deblurring network design, we revisit the coarse-to-fine strategy and present a multi-input multi-output U-net (MIMO-UNet). The MIMO-UNet has three distinct features. First, the single encoder of the MIMO-UNet takes multi-scale input images to ease the difficulty of training. Second, the single decoder of the MIMO-UNet outputs multiple deblurred images with different scales to mimic multi-cascaded U-nets using a single U-shaped network. Last, asymmetric feature fusion is introduced to merge multi-scale features in an efficient manner. Extensive experiments on the GoPro and RealBlur datasets demonstrate that the proposed network outperforms the state-of-the-art methods in terms of both accuracy and computational complexity. Source code is available for research purposes at https://github.com/chosj95/MIMO-UNet.
One-Shot Adaptation of GAN in Just One CLIP
Mar 23, 2022


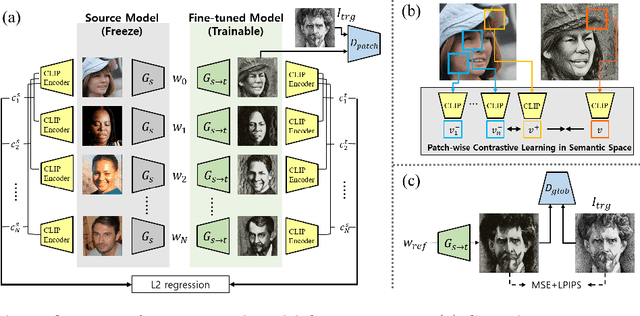
There are many recent research efforts to fine-tune a pre-trained generator with a few target images to generate images of a novel domain. Unfortunately, these methods often suffer from overfitting or under-fitting when fine-tuned with a single target image. To address this, here we present a novel single-shot GAN adaptation method through unified CLIP space manipulations. Specifically, our model employs a two-step training strategy: reference image search in the source generator using a CLIP-guided latent optimization, followed by generator fine-tuning with a novel loss function that imposes CLIP space consistency between the source and adapted generators. To further improve the adapted model to produce spatially consistent samples with respect to the source generator, we also propose contrastive regularization for patchwise relationships in the CLIP space. Experimental results show that our model generates diverse outputs with the target texture and outperforms the baseline models both qualitatively and quantitatively. Furthermore, we show that our CLIP space manipulation strategy allows more effective attribute editing.
Test-Time Training for Deformable Multi-Scale Image Registration
Mar 25, 2021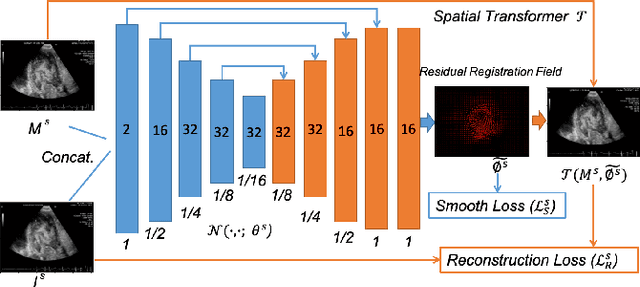
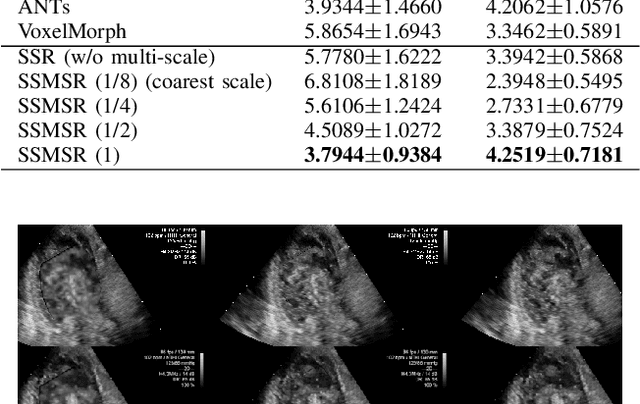
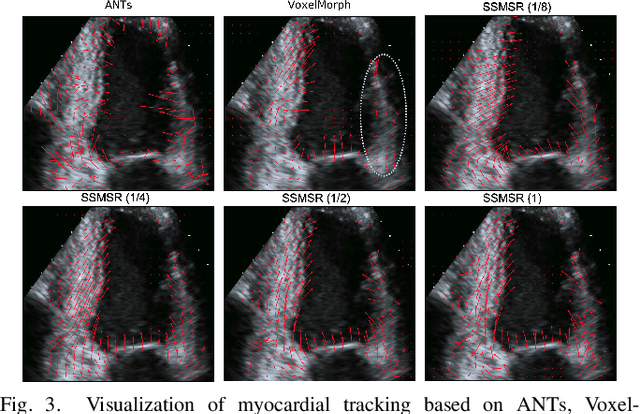
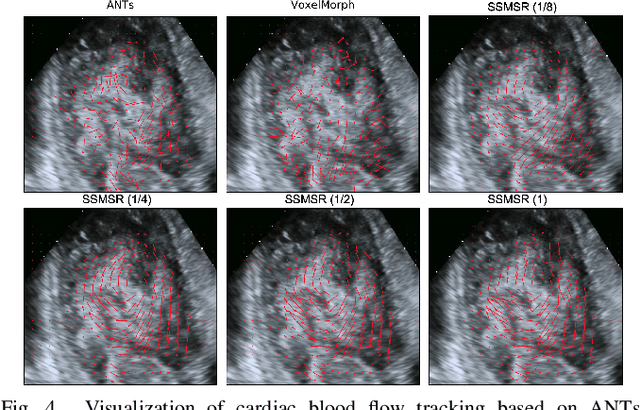
Registration is a fundamental task in medical robotics and is often a crucial step for many downstream tasks such as motion analysis, intra-operative tracking and image segmentation. Popular registration methods such as ANTs and NiftyReg optimize objective functions for each pair of images from scratch, which are time-consuming for 3D and sequential images with complex deformations. Recently, deep learning-based registration approaches such as VoxelMorph have been emerging and achieve competitive performance. In this work, we construct a test-time training for deep deformable image registration to improve the generalization ability of conventional learning-based registration model. We design multi-scale deep networks to consecutively model the residual deformations, which is effective for high variational deformations. Extensive experiments validate the effectiveness of multi-scale deep registration with test-time training based on Dice coefficient for image segmentation and mean square error (MSE), normalized local cross-correlation (NLCC) for tissue dense tracking tasks. Two videos are in https://www.youtube.com/watch?v=NvLrCaqCiAE and https://www.youtube.com/watch?v=pEA6ZmtTNuQ
* ICRA 2021; 8 pages, 4 figures, 2 big tables
Soft then Hard: Rethinking the Quantization in Neural Image Compression
Apr 12, 2021


Quantization is one of the core components in lossy image compression. For neural image compression, end-to-end optimization requires differentiable approximations of quantization, which can generally be grouped into three categories: additive uniform noise, straight-through estimator and soft-to-hard annealing. Training with additive uniform noise approximates the quantization error variationally but suffers from the train-test mismatch. The other two methods do not encounter this mismatch but, as shown in this paper, hurt the rate-distortion performance since the latent representation ability is weakened. We thus propose a novel soft-then-hard quantization strategy for neural image compression that first learns an expressive latent space softly, then eliminates the train-test mismatch with hard quantization. In addition, beyond the fixed integer quantization, we apply scaled additive uniform noise to adaptively control the quantization granularity by deriving a new variational upper bound on actual rate. Experiments demonstrate that our proposed methods are easy to adopt, stable to train, and highly effective especially on complex compression models.
Non-local Channel Aggregation Network for Single Image Rain Removal
Mar 03, 2021



Rain streaks showing in images or videos would severely degrade the performance of computer vision applications. Thus, it is of vital importance to remove rain streaks and facilitate our vision systems. While recent convolutinal neural network based methods have shown promising results in single image rain removal (SIRR), they fail to effectively capture long-range location dependencies or aggregate convolutional channel information simultaneously. However, as SIRR is a highly illposed problem, these spatial and channel information are very important clues to solve SIRR. First, spatial information could help our model to understand the image context by gathering long-range dependency location information hidden in the image. Second, aggregating channels could help our model to concentrate on channels more related to image background instead of rain streaks. In this paper, we propose a non-local channel aggregation network (NCANet) to address the SIRR problem. NCANet models 2D rainy images as sequences of vectors in three directions, namely vertical direction, transverse direction and channel direction. Recurrently aggregating information from all three directions enables our model to capture the long-range dependencies in both channels and spaitials locations. Extensive experiments on both heavy and light rain image data sets demonstrate the effectiveness of the proposed NCANet model.
A Topology-Attention ConvLSTM Network and Its Application to EM Images
Feb 07, 2022
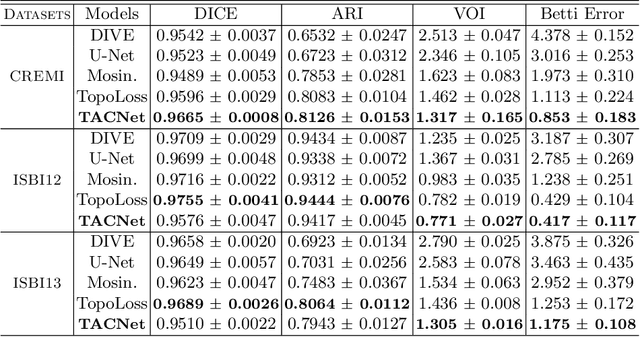
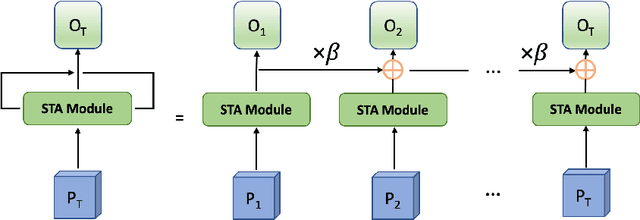
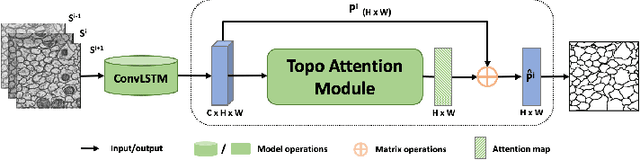
Structural accuracy of segmentation is important for finescale structures in biomedical images. We propose a novel TopologyAttention ConvLSTM Network (TACNet) for 3D image segmentation in order to achieve high structural accuracy for 3D segmentation tasks. Specifically, we propose a Spatial Topology-Attention (STA) module to process a 3D image as a stack of 2D image slices and adopt ConvLSTM to leverage contextual structure information from adjacent slices. In order to effectively transfer topology-critical information across slices, we propose an Iterative-Topology Attention (ITA) module that provides a more stable topology-critical map for segmentation. Quantitative and qualitative results show that our proposed method outperforms various baselines in terms of topology-aware evaluation metrics.
Utilizing variational autoencoders in the Bayesian inverse problem of photoacoustic tomography
Apr 13, 2022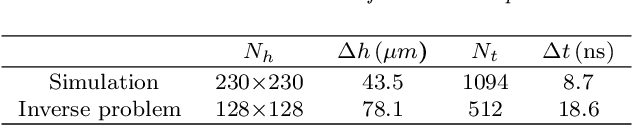
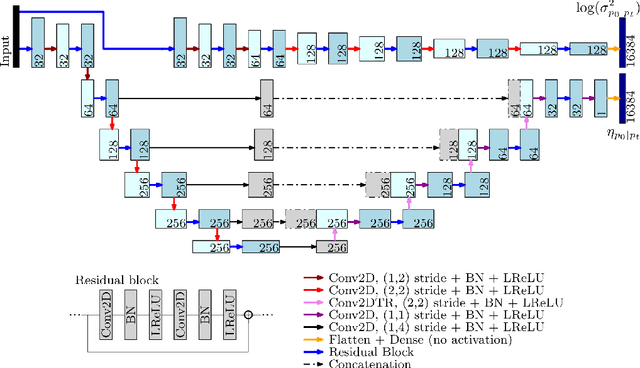
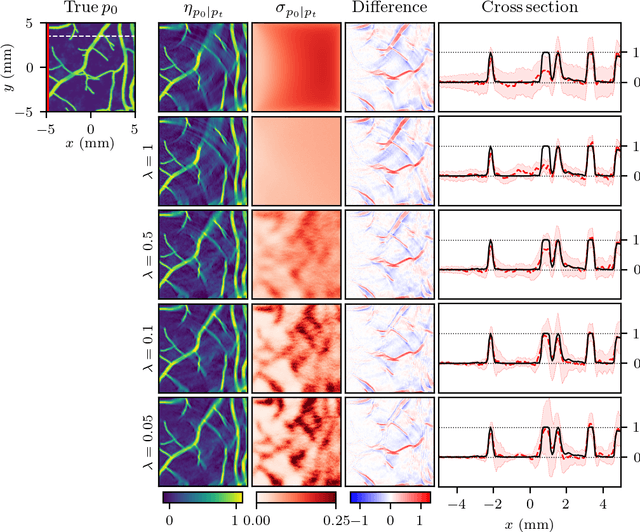
There has been an increasing interest in utilizing machine learning methods in inverse problems and imaging. Most of the work has, however, concentrated on image reconstruction problems, and the number of studies regarding the full solution of the inverse problem is limited. In this work, we study a machine learning based approach for the Bayesian inverse problem of photoacoustic tomography. We develop an approach for estimating the posterior distribution in photoacoustic tomography using an approach based on the variational autoencoder. The approach is evaluated with numerical simulations and compared to the solution of the inverse problem using a Bayesian approach.
Dynamic Dual-Output Diffusion Models
Mar 08, 2022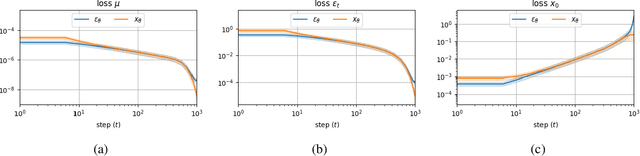
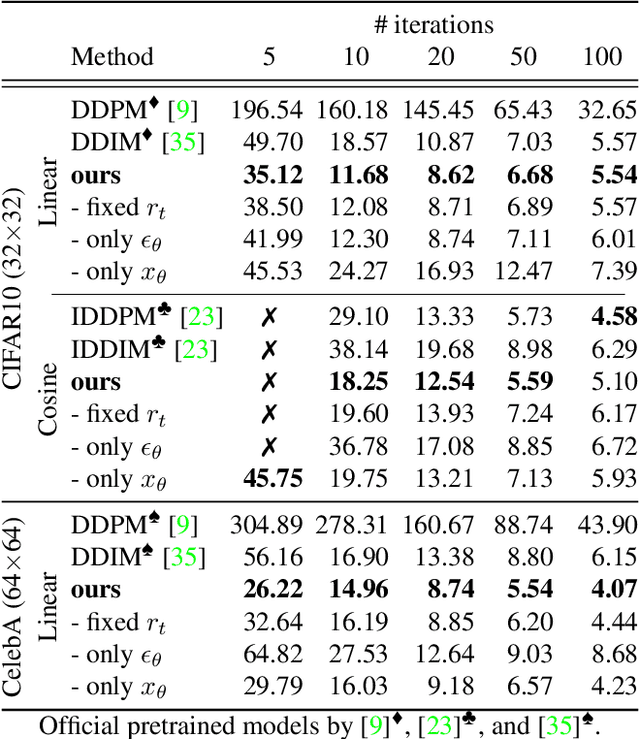
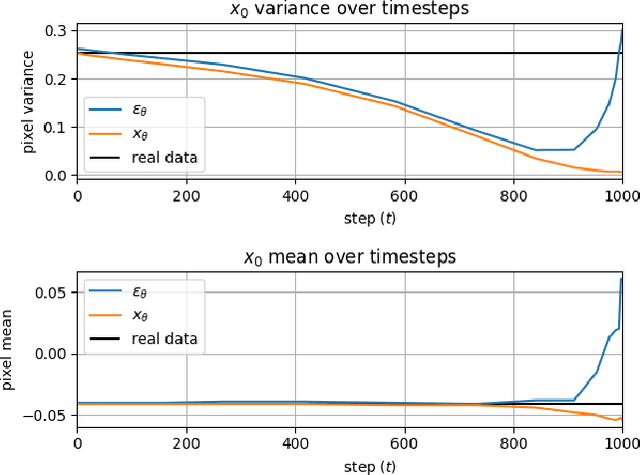
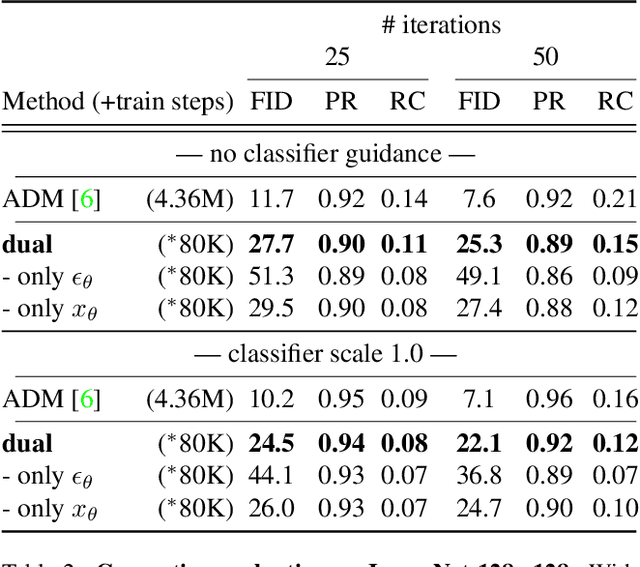
Iterative denoising-based generation, also known as denoising diffusion models, has recently been shown to be comparable in quality to other classes of generative models, and even surpass them. Including, in particular, Generative Adversarial Networks, which are currently the state of the art in many sub-tasks of image generation. However, a major drawback of this method is that it requires hundreds of iterations to produce a competitive result. Recent works have proposed solutions that allow for faster generation with fewer iterations, but the image quality gradually deteriorates with increasingly fewer iterations being applied during generation. In this paper, we reveal some of the causes that affect the generation quality of diffusion models, especially when sampling with few iterations, and come up with a simple, yet effective, solution to mitigate them. We consider two opposite equations for the iterative denoising, the first predicts the applied noise, and the second predicts the image directly. Our solution takes the two options and learns to dynamically alternate between them through the denoising process. Our proposed solution is general and can be applied to any existing diffusion model. As we show, when applied to various SOTA architectures, our solution immediately improves their generation quality, with negligible added complexity and parameters. We experiment on multiple datasets and configurations and run an extensive ablation study to support these findings.