 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
If a Human Can See It, So Should Your System: Reliability Requirements for Machine Vision Components
Feb 08, 2022

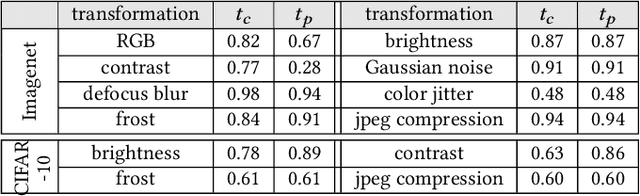
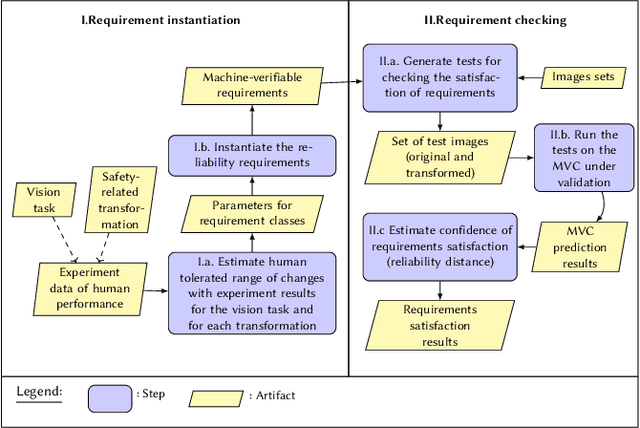
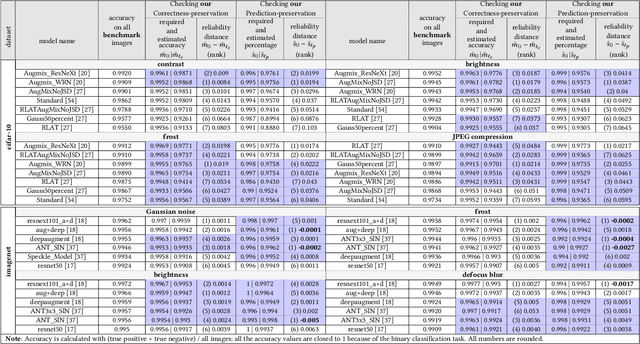
Machine Vision Components (MVC) are becoming safety-critical. Assuring their quality, including safety, is essential for their successful deployment. Assurance relies on the availability of precisely specified and, ideally, machine-verifiable requirements. MVCs with state-of-the-art performance rely on machine learning (ML) and training data but largely lack such requirements. In this paper, we address the need for defining machine-verifiable reliability requirements for MVCs against transformations that simulate the full range of realistic and safety-critical changes in the environment. Using human performance as a baseline, we define reliability requirements as: 'if the changes in an image do not affect a human's decision, neither should they affect the MVC's.' To this end, we provide: (1) a class of safety-related image transformations; (2) reliability requirement classes to specify correctness-preservation and prediction-preservation for MVCs; (3) a method to instantiate machine-verifiable requirements from these requirements classes using human performance experiment data; (4) human performance experiment data for image recognition involving eight commonly used transformations, from about 2000 human participants; and (5) a method for automatically checking whether an MVC satisfies our requirements. Further, we show that our reliability requirements are feasible and reusable by evaluating our methods on 13 state-of-the-art pre-trained image classification models. Finally, we demonstrate that our approach detects reliability gaps in MVCs that other existing methods are unable to detect.
StyleT2F: Generating Human Faces from Textual Description Using StyleGAN2
Apr 17, 2022
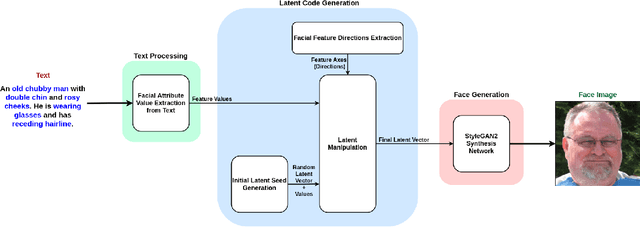
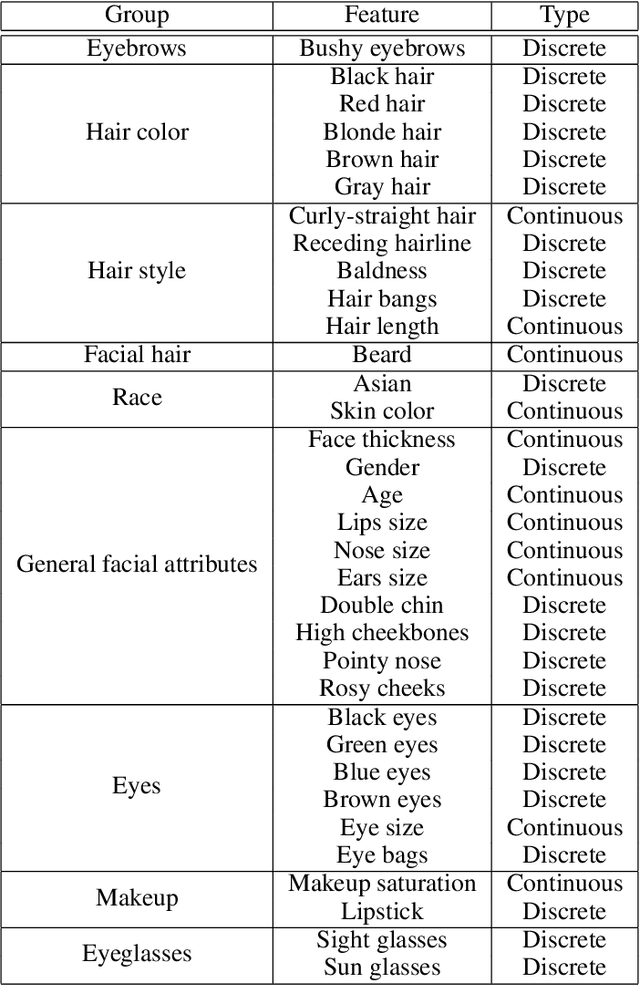
AI-driven image generation has improved significantly in recent years. Generative adversarial networks (GANs), like StyleGAN, are able to generate high-quality realistic data and have artistic control over the output, as well. In this work, we present StyleT2F, a method of controlling the output of StyleGAN2 using text, in order to be able to generate a detailed human face from textual description. We utilize StyleGAN's latent space to manipulate different facial features and conditionally sample the required latent code, which embeds the facial features mentioned in the input text. Our method proves to capture the required features correctly and shows consistency between the input text and the output images. Moreover, our method guarantees disentanglement on manipulating a wide range of facial features that sufficiently describes a human face.
NPU-BOLT: A Dataset for Bolt Object Detection in Natural Scene Images
May 25, 2022



Bolt joints are very common and important in engineering structures. Due to extreme service environment and load factors, bolts often get loose or even disengaged. To real-time or timely detect the loosed or disengaged bolts is an urgent need in practical engineering, which is critical to keep structural safety and service life. In recent years, many bolt loosening detection methods using deep learning and machine learning techniques have been proposed and are attracting more and more attention. However, most of these studies use bolt images captured in laboratory for deep leaning model training. The images are obtained in a well-controlled light, distance, and view angle conditions. Also, the bolted structures are well designed experimental structures with brand new bolts and the bolts are exposed without any shelter nearby. It is noted that in practical engineering, the above well controlled lab conditions are not easy realized and the real bolt images often have blur edges, oblique perspective, partial occlusion and indistinguishable colors etc., which make the trained models obtained in laboratory conditions loss their accuracy or fails. Therefore, the aim of this study is to develop a dataset named NPU-BOLT for bolt object detection in natural scene images and open it to researchers for public use and further development. In the first version of the dataset, it contains 337 samples of bolt joints images mainly in the natural environment, with image data sizes ranging from 400*400 to 6000*4000, totaling approximately 1275 bolt targets. The bolt targets are annotated into four categories named blur bolt, bolt head, bolt nut and bolt side. The dataset is tested with advanced object detection models including yolov5, Faster-RCNN and CenterNet. The effectiveness of the dataset is validated.
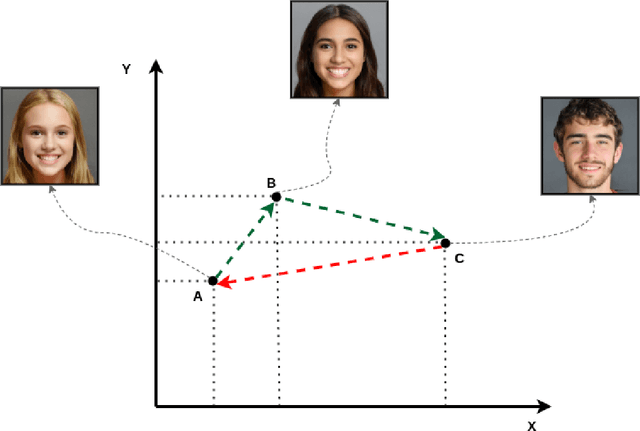
Do Deep Networks Transfer Invariances Across Classes?
Mar 18, 2022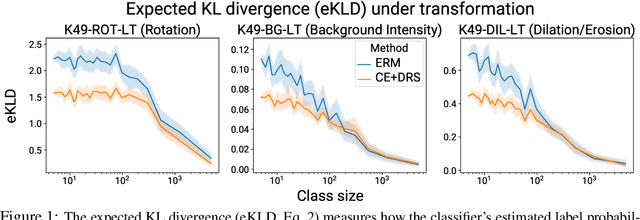
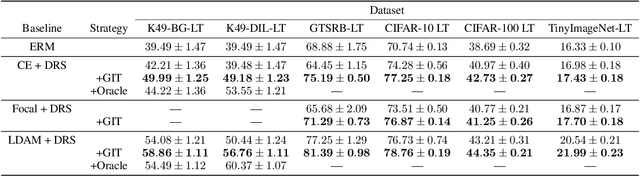
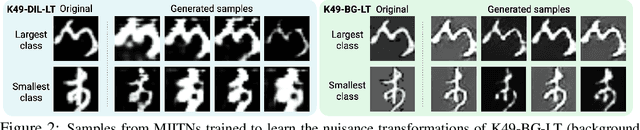
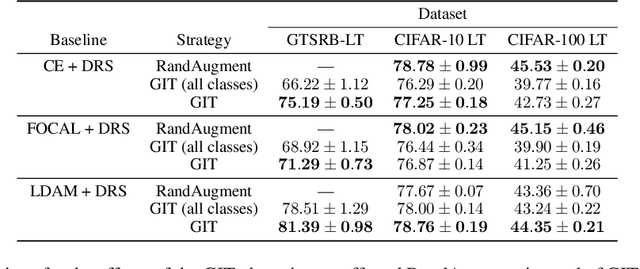
To generalize well, classifiers must learn to be invariant to nuisance transformations that do not alter an input's class. Many problems have "class-agnostic" nuisance transformations that apply similarly to all classes, such as lighting and background changes for image classification. Neural networks can learn these invariances given sufficient data, but many real-world datasets are heavily class imbalanced and contain only a few examples for most of the classes. We therefore pose the question: how well do neural networks transfer class-agnostic invariances learned from the large classes to the small ones? Through careful experimentation, we observe that invariance to class-agnostic transformations is still heavily dependent on class size, with the networks being much less invariant on smaller classes. This result holds even when using data balancing techniques, and suggests poor invariance transfer across classes. Our results provide one explanation for why classifiers generalize poorly on unbalanced and long-tailed distributions. Based on this analysis, we show how a generative approach for learning the nuisance transformations can help transfer invariances across classes and improve performance on a set of imbalanced image classification benchmarks. Source code for our experiments is available at https://github.com/AllanYangZhou/generative-invariance-transfer.
VITA: A Multi-Source Vicinal Transfer Augmentation Method for Out-of-Distribution Generalization
Apr 25, 2022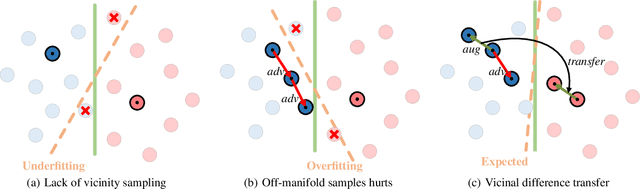
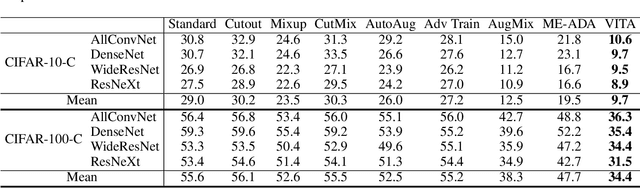
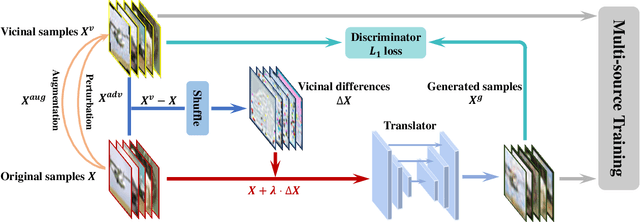
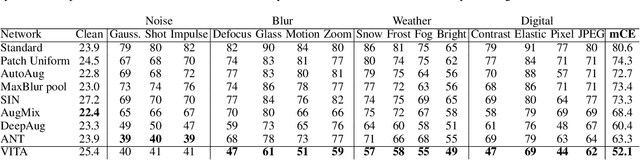
Invariance to diverse types of image corruption, such as noise, blurring, or colour shifts, is essential to establish robust models in computer vision. Data augmentation has been the major approach in improving the robustness against common corruptions. However, the samples produced by popular augmentation strategies deviate significantly from the underlying data manifold. As a result, performance is skewed toward certain types of corruption. To address this issue, we propose a multi-source vicinal transfer augmentation (VITA) method for generating diverse on-manifold samples. The proposed VITA consists of two complementary parts: tangent transfer and integration of multi-source vicinal samples. The tangent transfer creates initial augmented samples for improving corruption robustness. The integration employs a generative model to characterize the underlying manifold built by vicinal samples, facilitating the generation of on-manifold samples. Our proposed VITA significantly outperforms the current state-of-the-art augmentation methods, demonstrated in extensive experiments on corruption benchmarks.
Joint Estimation of Image Representations and their Lie Invariants
Dec 08, 2020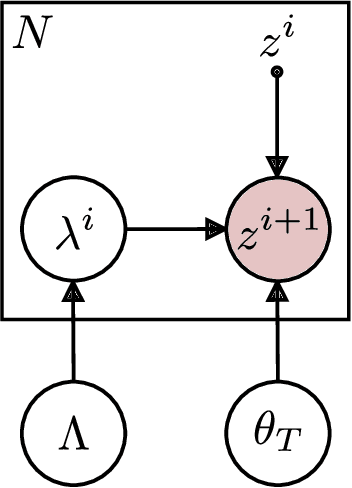
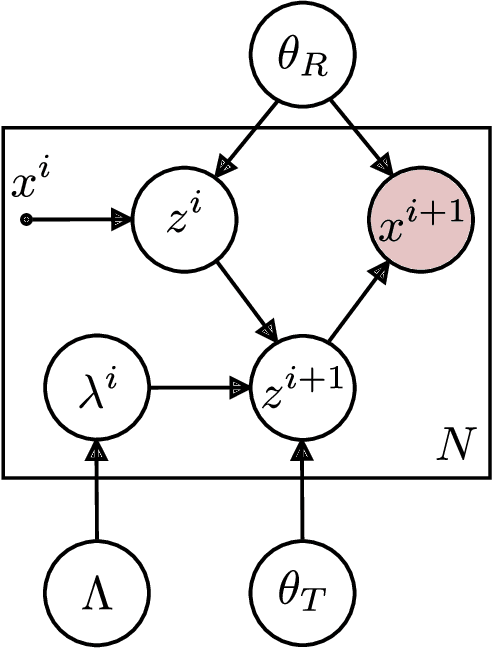
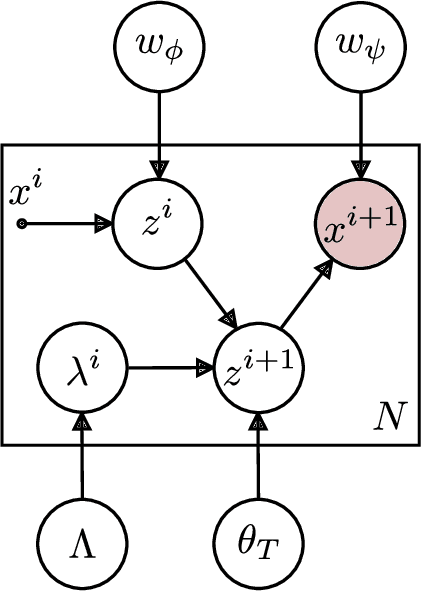
Images encode both the state of the world and its content. The former is useful for tasks such as planning and control, and the latter for classification. The automatic extraction of this information is challenging because of the high-dimensionality and entangled encoding inherent to the image representation. This article introduces two theoretical approaches aimed at the resolution of these challenges. The approaches allow for the interpolation and extrapolation of images from an image sequence by joint estimation of the image representation and the generators of the sequence dynamics. In the first approach, the image representations are learned using probabilistic PCA \cite{tipping1999probabilistic}. The linear-Gaussian conditional distributions allow for a closed form analytical description of the latent distributions but assumes the underlying image manifold is a linear subspace. In the second approach, the image representations are learned using probabilistic nonlinear PCA which relieves the linear manifold assumption at the cost of requiring a variational approximation of the latent distributions. In both approaches, the underlying dynamics of the image sequence are modelled explicitly to disentangle them from the image representations. The dynamics themselves are modelled with Lie group structure which enforces the desirable properties of smoothness and composability of inter-image transformations.
Evolving SimGANs to Improve Abnormal Electrocardiogram Classification
May 12, 2022

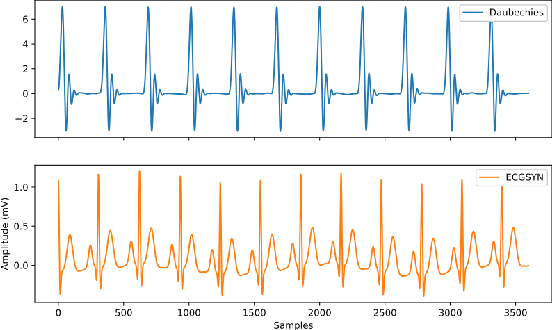
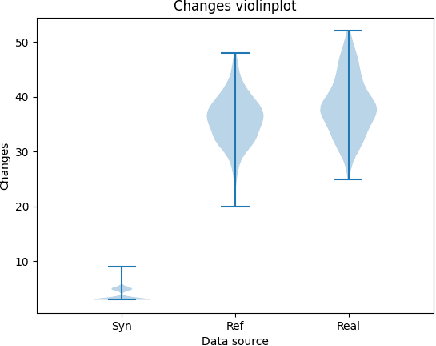
Machine Learning models are used in a wide variety of domains. However, machine learning methods often require a large amount of data in order to be successful. This is especially troublesome in domains where collecting real-world data is difficult and/or expensive. Data simulators do exist for many of these domains, but they do not sufficiently reflect the real world data due to factors such as a lack of real-world noise. Recently generative adversarial networks (GANs) have been modified to refine simulated image data into data that better fits the real world distribution, using the SimGAN method. While evolutionary computing has been used for GAN evolution, there are currently no frameworks that can evolve a SimGAN. In this paper we (1) extend the SimGAN method to refine one-dimensional data, (2) modify Easy Cartesian Genetic Programming (ezCGP), an evolutionary computing framework, to create SimGANs that more accurately refine simulated data, and (3) create new feature-based quantitative metrics to evaluate refined data. We also use our framework to augment an electrocardiogram (ECG) dataset, a domain that suffers from the issues previously mentioned. In particular, while healthy ECGs can be simulated there are no current simulators of abnormal ECGs. We show that by using an evolved SimGAN to refine simulated healthy ECG data to mimic real-world abnormal ECGs, we can improve the accuracy of abnormal ECG classifiers.
Energy-Efficient Classification at the Wireless Edge with Reliability Guarantees
Apr 25, 2022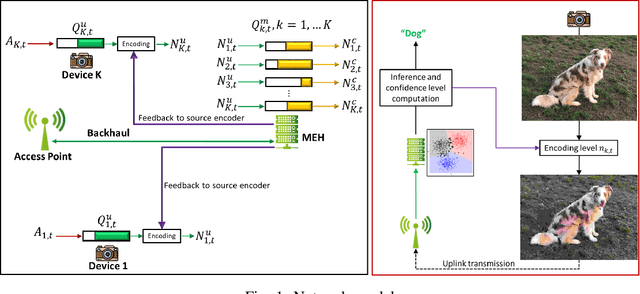
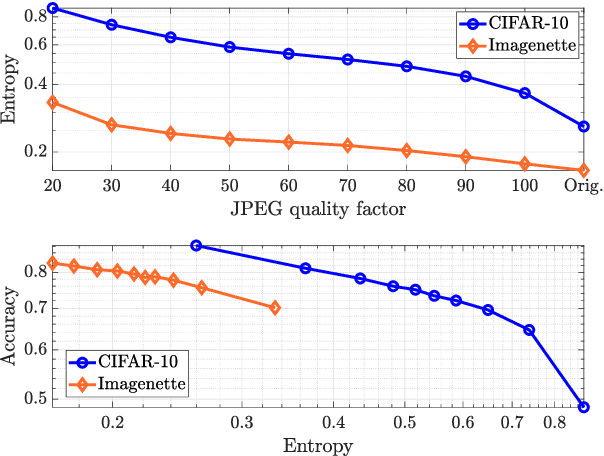
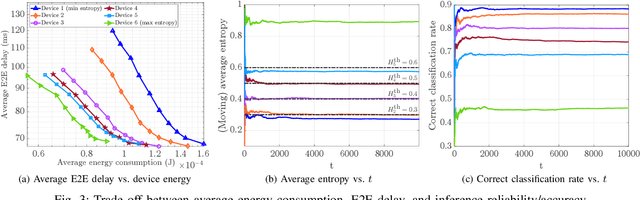
Learning at the edge is a challenging task from several perspectives, since data must be collected by end devices (e.g. sensors), possibly pre-processed (e.g. data compression), and finally processed remotely to output the result of training and/or inference phases. This involves heterogeneous resources, such as radio, computing and learning related parameters. In this context, we propose an algorithm that dynamically selects data encoding scheme, local computing resources, uplink radio parameters, and remote computing resources, to perform a classification task with the minimum average end devices' energy consumption, under E2E delay and inference reliability constraints. Our method does not assume any prior knowledge of the statistics of time varying context parameters, while it only requires the solution of low complexity per-slot deterministic optimization problems, based on instantaneous observations of these parameters and that of properly defined state variables. Numerical results on convolutional neural network based image classification illustrate the effectiveness of our method in striking the best trade-off between energy, delay and inference reliability.
Discriminability-Transferability Trade-Off: An Information-Theoretic Perspective
Mar 08, 2022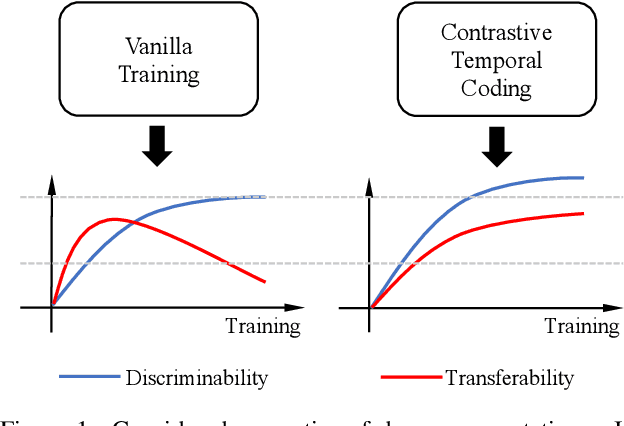

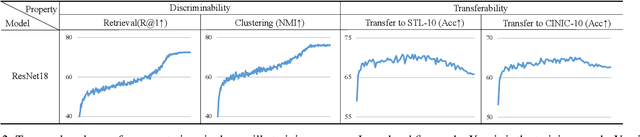

This work simultaneously considers the discriminability and transferability properties of deep representations in the typical supervised learning task, i.e., image classification. By a comprehensive temporal analysis, we observe a trade-off between these two properties. The discriminability keeps increasing with the training progressing while the transferability intensely diminishes in the later training period. From the perspective of information-bottleneck theory, we reveal that the incompatibility between discriminability and transferability is attributed to the over-compression of input information. More importantly, we investigate why and how the InfoNCE loss can alleviate the over-compression, and further present a learning framework, named contrastive temporal coding~(CTC), to counteract the over-compression and alleviate the incompatibility. Extensive experiments validate that CTC successfully mitigates the incompatibility, yielding discriminative and transferable representations. Noticeable improvements are achieved on the image classification task and challenging transfer learning tasks. We hope that this work will raise the significance of the transferability property in the conventional supervised learning setting. Code will be publicly available.
DivergentNets: Medical Image Segmentation by Network Ensemble
Jul 01, 2021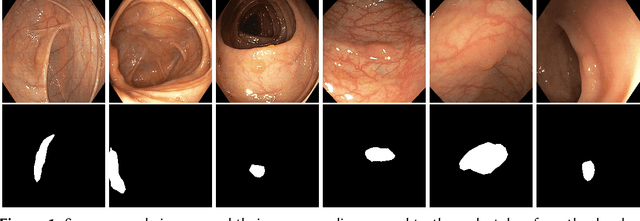
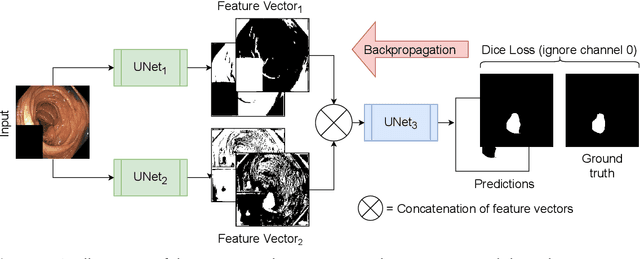
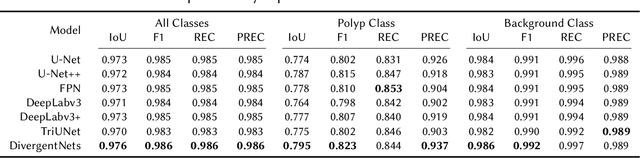
Detection of colon polyps has become a trending topic in the intersecting fields of machine learning and gastrointestinal endoscopy. The focus has mainly been on per-frame classification. More recently, polyp segmentation has gained attention in the medical community. Segmentation has the advantage of being more accurate than per-frame classification or object detection as it can show the affected area in greater detail. For our contribution to the EndoCV 2021 segmentation challenge, we propose two separate approaches. First, a segmentation model named TriUNet composed of three separate UNet models. Second, we combine TriUNet with an ensemble of well-known segmentation models, namely UNet++, FPN, DeepLabv3, and DeepLabv3+, into a model called DivergentNets to produce more generalizable medical image segmentation masks. In addition, we propose a modified Dice loss that calculates loss only for a single class when performing multiclass segmentation, forcing the model to focus on what is most important. Overall, the proposed methods achieved the best average scores for each respective round in the challenge, with TriUNet being the winning model in Round I and DivergentNets being the winning model in Round II of the segmentation generalization challenge at EndoCV 2021. The implementation of our approach is made publicly available on GitHub.
* the winning model of the segmentation generalization challenge at EndoCV 2021