 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention in Attention Network for Image Super-Resolution
Apr 19, 2021
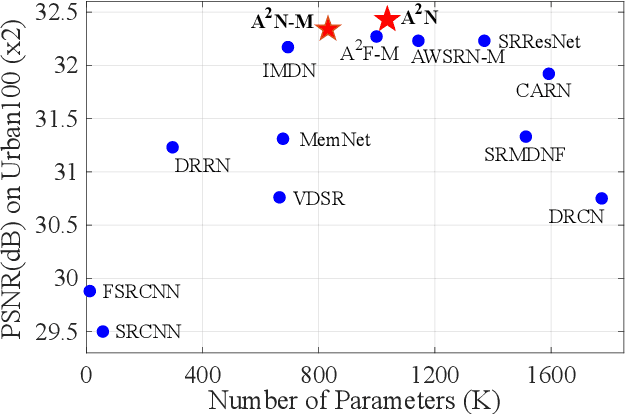

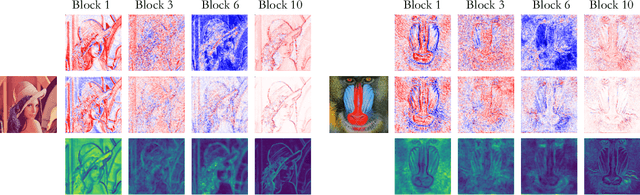

Convolutional neural networks have allowed remarkable advances in single image super-resolution (SISR) over the last decade. Among recent advances in SISR, attention mechanisms are crucial for high performance SR models. However, few works really discuss why attention works and how it works. In this work, we attempt to quantify and visualize the static attention mechanisms and show that not all attention modules are equally beneficial. We then propose attention in attention network (A$^2$N) for highly accurate image SR. Specifically, our A$^2$N consists of a non-attention branch and a coupling attention branch. Attention dropout module is proposed to generate dynamic attention weights for these two branches based on input features that can suppress unwanted attention adjustments. This allows attention modules to specialize to beneficial examples without otherwise penalties and thus greatly improve the capacity of the attention network with little parameter overhead. Experiments have demonstrated that our model could achieve superior trade-off performances comparing with state-of-the-art lightweight networks. Experiments on local attribution maps also prove attention in attention (A$^2$) structure can extract features from a wider range.
Energy-Efficient Classification at the Wireless Edge with Reliability Guarantees
Apr 25, 2022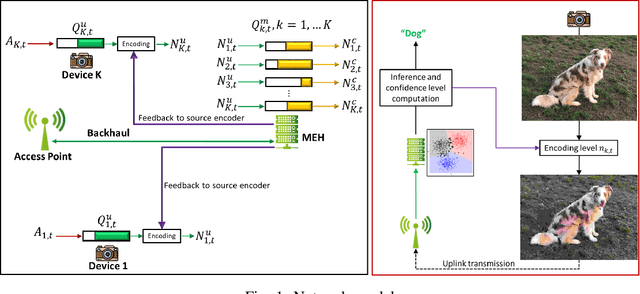
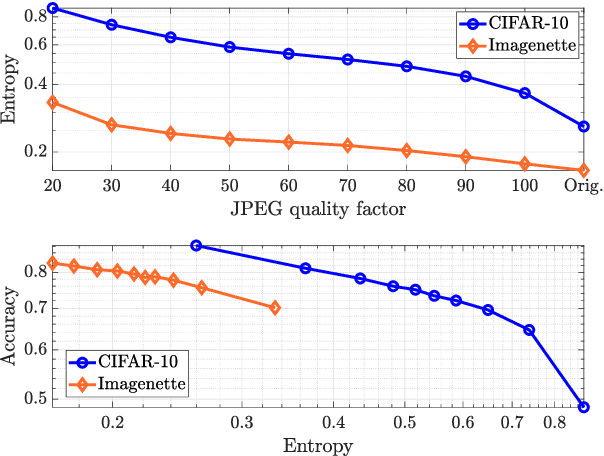
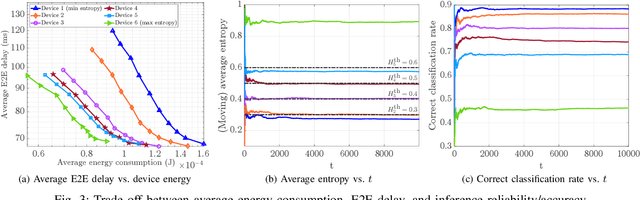
Learning at the edge is a challenging task from several perspectives, since data must be collected by end devices (e.g. sensors), possibly pre-processed (e.g. data compression), and finally processed remotely to output the result of training and/or inference phases. This involves heterogeneous resources, such as radio, computing and learning related parameters. In this context, we propose an algorithm that dynamically selects data encoding scheme, local computing resources, uplink radio parameters, and remote computing resources, to perform a classification task with the minimum average end devices' energy consumption, under E2E delay and inference reliability constraints. Our method does not assume any prior knowledge of the statistics of time varying context parameters, while it only requires the solution of low complexity per-slot deterministic optimization problems, based on instantaneous observations of these parameters and that of properly defined state variables. Numerical results on convolutional neural network based image classification illustrate the effectiveness of our method in striking the best trade-off between energy, delay and inference reliability.
Identifying outliers in astronomical images with unsupervised machine learning
May 19, 2022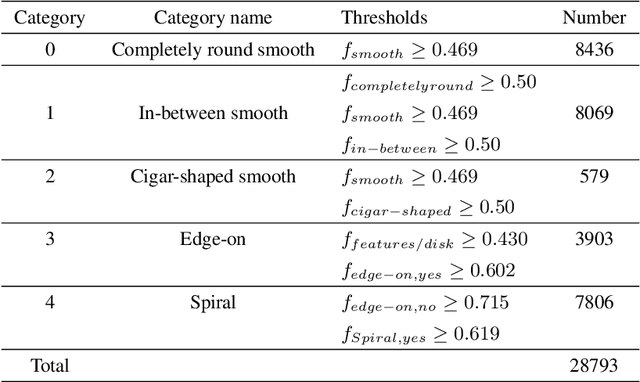
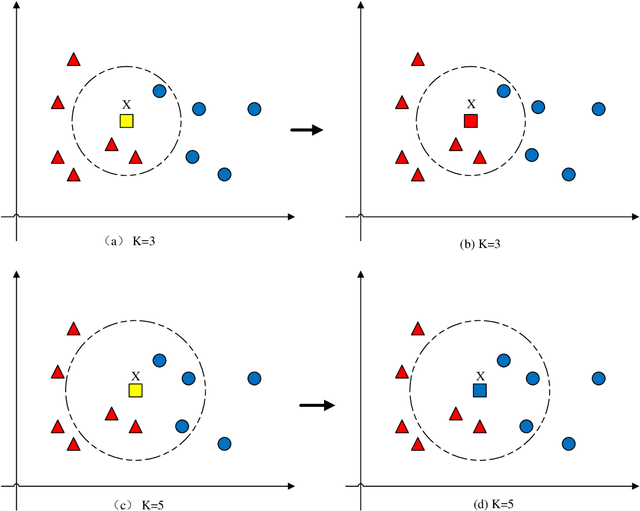
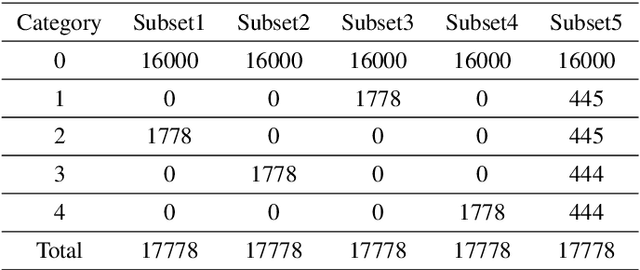
Astronomical outliers, such as unusual, rare or unknown types of astronomical objects or phenomena, constantly lead to the discovery of genuinely unforeseen knowledge in astronomy. More unpredictable outliers will be uncovered in principle with the increment of the coverage and quality of upcoming survey data. However, it is a severe challenge to mine rare and unexpected targets from enormous data with human inspection due to a significant workload. Supervised learning is also unsuitable for this purpose since designing proper training sets for unanticipated signals is unworkable. Motivated by these challenges, we adopt unsupervised machine learning approaches to identify outliers in the data of galaxy images to explore the paths for detecting astronomical outliers. For comparison, we construct three methods, which are built upon the k-nearest neighbors (KNN), Convolutional Auto-Encoder (CAE)+ KNN, and CAE + KNN + Attention Mechanism (attCAE KNN) separately. Testing sets are created based on the Galaxy Zoo image data published online to evaluate the performance of the above methods. Results show that attCAE KNN achieves the best recall (78%), which is 53% higher than the classical KNN method and 22% higher than CAE+KNN. The efficiency of attCAE KNN (10 minutes) is also superior to KNN (4 hours) and equal to CAE+KNN(10 minutes) for accomplishing the same task. Thus, we believe it is feasible to detect astronomical outliers in the data of galaxy images in an unsupervised manner. Next, we will apply attCAE KNN to available survey datasets to assess its applicability and reliability.
Contextual Attention Network: Transformer Meets U-Net
Mar 02, 2022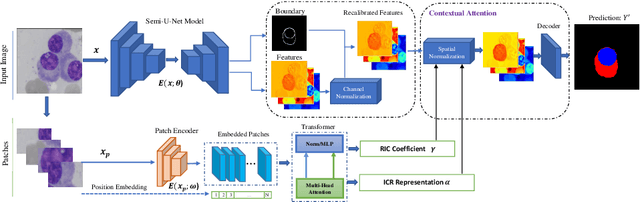
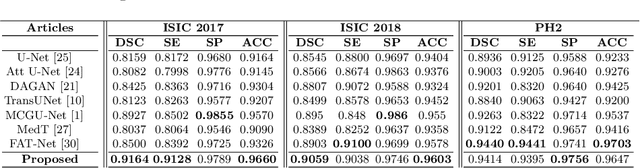


Currently, convolutional neural networks (CNN) (e.g., U-Net) have become the de facto standard and attained immense success in medical image segmentation. However, as a downside, CNN based methods are a double-edged sword as they fail to build long-range dependencies and global context connections due to the limited receptive field that stems from the intrinsic characteristics of the convolution operation. Hence, recent articles have exploited Transformer variants for medical image segmentation tasks which open up great opportunities due to their innate capability of capturing long-range correlations through the attention mechanism. Although being feasibly designed, most of the cohort studies incur prohibitive performance in capturing local information, thereby resulting in less lucidness of boundary areas. In this paper, we propose a contextual attention network to tackle the aforementioned limitations. The proposed method uses the strength of the Transformer module to model the long-range contextual dependency. Simultaneously, it utilizes the CNN encoder to capture local semantic information. In addition, an object-level representation is included to model the regional interaction map. The extracted hierarchical features are then fed to the contextual attention module to adaptively recalibrate the representation space using the local information. Then, they emphasize the informative regions while taking into account the long-range contextual dependency derived by the Transformer module. We validate our method on several large-scale public medical image segmentation datasets and achieve state-of-the-art performance. We have provided the implementation code in https://github.com/rezazad68/TMUnet.
Crossing-Domain Generative Adversarial Networks for Unsupervised Multi-Domain Image-to-Image Translation
Aug 27, 2020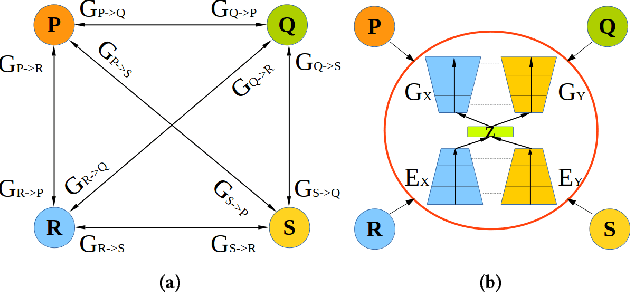
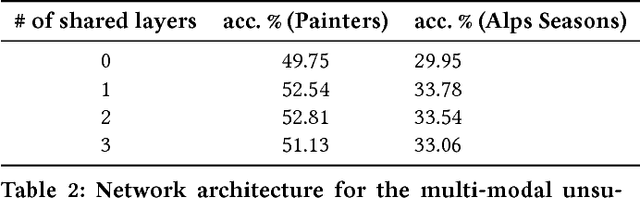
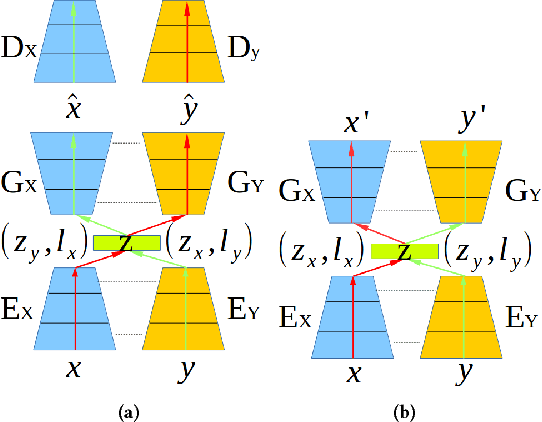
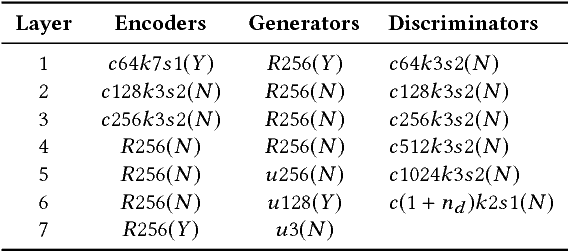
State-of-the-art techniques in Generative Adversarial Networks (GANs) have shown remarkable success in image-to-image translation from peer domain X to domain Y using paired image data. However, obtaining abundant paired data is a non-trivial and expensive process in the majority of applications. When there is a need to translate images across n domains, if the training is performed between every two domains, the complexity of the training will increase quadratically. Moreover, training with data from two domains only at a time cannot benefit from data of other domains, which prevents the extraction of more useful features and hinders the progress of this research area. In this work, we propose a general framework for unsupervised image-to-image translation across multiple domains, which can translate images from domain X to any a domain without requiring direct training between the two domains involved in image translation. A byproduct of the framework is the reduction of computing time and computing resources, since it needs less time than training the domains in pairs as is done in state-of-the-art works. Our proposed framework consists of a pair of encoders along with a pair of GANs which learns high-level features across different domains to generate diverse and realistic samples from. Our framework shows competing results on many image-to-image tasks compared with state-of-the-art techniques.
Do Deep Networks Transfer Invariances Across Classes?
Mar 18, 2022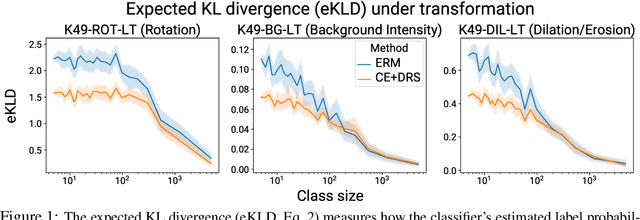
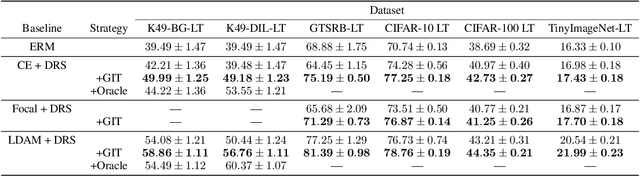
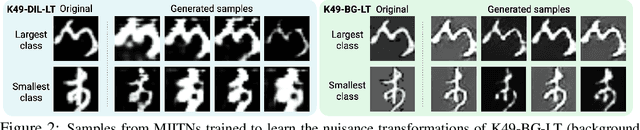
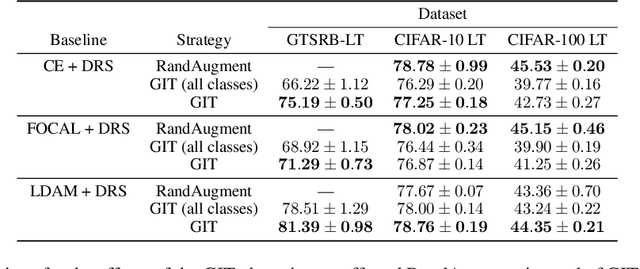
To generalize well, classifiers must learn to be invariant to nuisance transformations that do not alter an input's class. Many problems have "class-agnostic" nuisance transformations that apply similarly to all classes, such as lighting and background changes for image classification. Neural networks can learn these invariances given sufficient data, but many real-world datasets are heavily class imbalanced and contain only a few examples for most of the classes. We therefore pose the question: how well do neural networks transfer class-agnostic invariances learned from the large classes to the small ones? Through careful experimentation, we observe that invariance to class-agnostic transformations is still heavily dependent on class size, with the networks being much less invariant on smaller classes. This result holds even when using data balancing techniques, and suggests poor invariance transfer across classes. Our results provide one explanation for why classifiers generalize poorly on unbalanced and long-tailed distributions. Based on this analysis, we show how a generative approach for learning the nuisance transformations can help transfer invariances across classes and improve performance on a set of imbalanced image classification benchmarks. Source code for our experiments is available at https://github.com/AllanYangZhou/generative-invariance-transfer.
Contrastive Registration for Unsupervised Medical Image Segmentation
Nov 17, 2020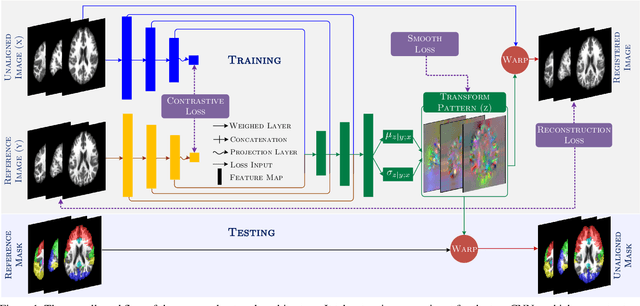

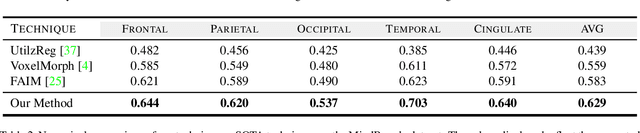
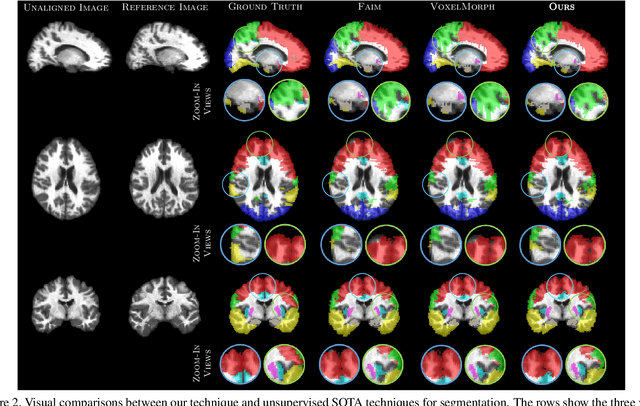
Medical image segmentation is a relevant task as it serves as the first step for several diagnosis processes, thus it is indispensable in clinical usage. Whilst major success has been reported using supervised techniques, they assume a large and well-representative labelled set. This is a strong assumption in the medical domain where annotations are expensive, time-consuming, and inherent to human bias. To address this problem, unsupervised techniques have been proposed in the literature yet it is still an open problem due to the difficulty of learning any transformation pattern. In this work, we present a novel optimisation model framed into a new CNN-based contrastive registration architecture for unsupervised medical image segmentation. The core of our approach is to exploit image-level registration and feature-level from a contrastive learning mechanism, to perform registration-based segmentation. Firstly, we propose an architecture to capture the image-to-image transformation pattern via registration for unsupervised medical image segmentation. Secondly, we embed a contrastive learning mechanism into the registration architecture to enhance the discriminating capacity of the network in the feature-level. We show that our proposed technique mitigates the major drawbacks of existing unsupervised techniques. We demonstrate, through numerical and visual experiments, that our technique substantially outperforms the current state-of-the-art unsupervised segmentation methods on two major medical image datasets.
Progressively Complementary Network for Fisheye Image Rectification Using Appearance Flow
Mar 31, 2021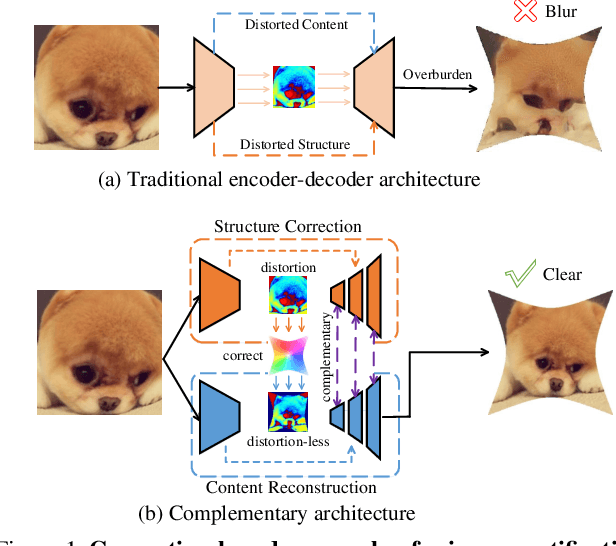
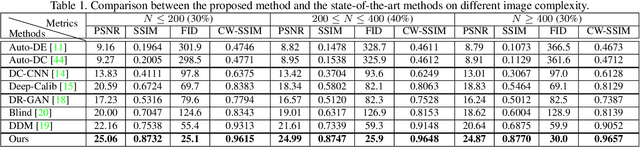
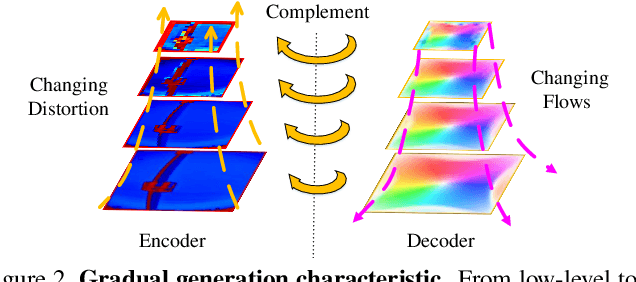
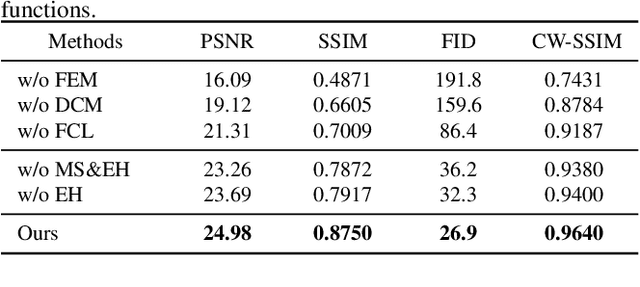
Distortion rectification is often required for fisheye images. The generation-based method is one mainstream solution due to its label-free property, but its naive skip-connection and overburdened decoder will cause blur and incomplete correction. First, the skip-connection directly transfers the image features, which may introduce distortion and cause incomplete correction. Second, the decoder is overburdened during simultaneously reconstructing the content and structure of the image, resulting in vague performance. To solve these two problems, in this paper, we focus on the interpretable correction mechanism of the distortion rectification network and propose a feature-level correction scheme. We embed a correction layer in skip-connection and leverage the appearance flows in different layers to pre-correct the image features. Consequently, the decoder can easily reconstruct a plausible result with the remaining distortion-less information. In addition, we propose a parallel complementary structure. It effectively reduces the burden of the decoder by separating content reconstruction and structure correction. Subjective and objective experiment results on different datasets demonstrate the superiority of our method.
Transformers in 3D Point Clouds: A Survey
May 16, 2022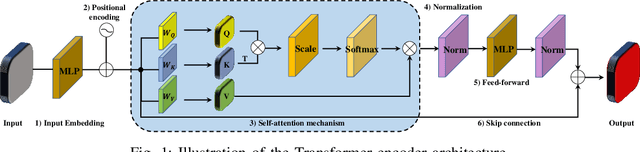
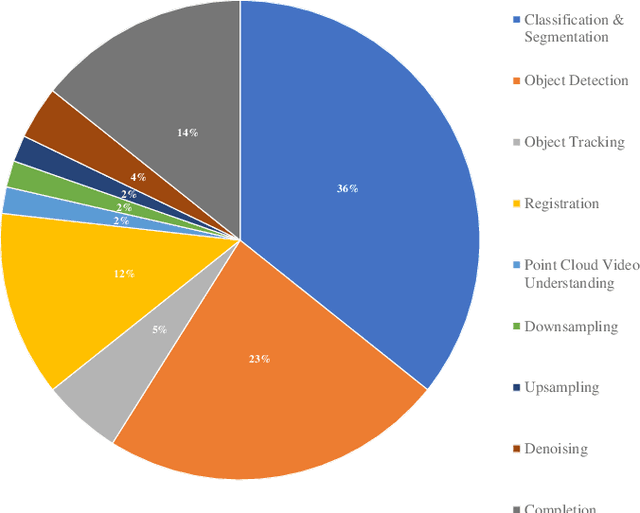
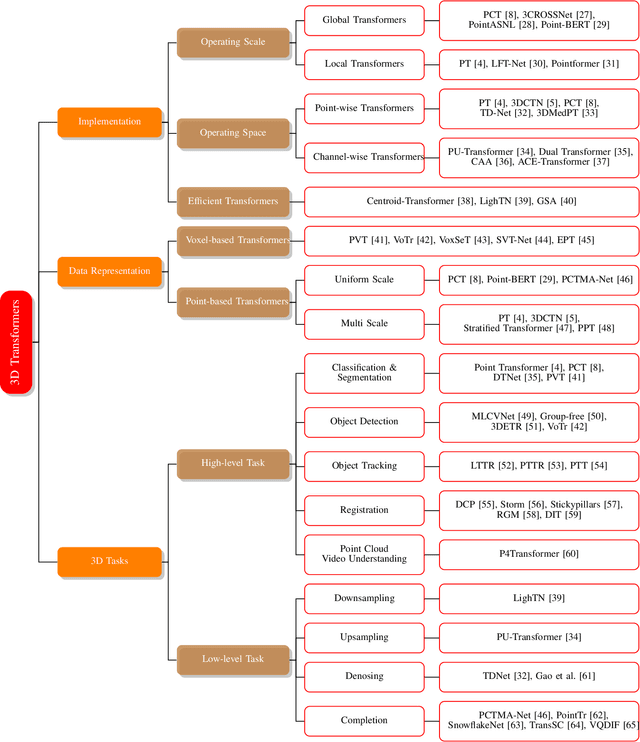
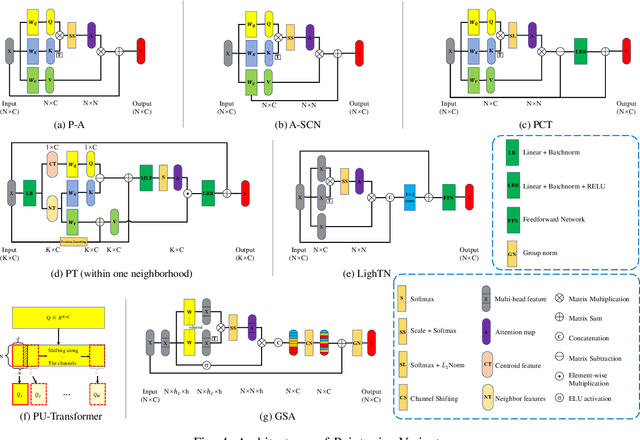
In recent years, Transformer models have been proven to have the remarkable ability of long-range dependencies modeling. They have achieved satisfactory results both in Natural Language Processing (NLP) and image processing. This significant achievement sparks great interest among researchers in 3D point cloud processing to apply them to various 3D tasks. Due to the inherent permutation invariance and strong global feature learning ability, 3D Transformers are well suited for point cloud processing and analysis. They have achieved competitive or even better performance compared to the state-of-the-art non-Transformer algorithms. This survey aims to provide a comprehensive overview of 3D Transformers designed for various tasks (e.g. point cloud classification, segmentation, object detection, and so on). We start by introducing the fundamental components of the general Transformer and providing a brief description of its application in 2D and 3D fields. Then, we present three different taxonomies (i.e., Transformer implementation-based taxonomy, data representation-based taxonomy, and task-based taxonomy) for method classification, which allows us to analyze involved methods from multiple perspectives. Furthermore, we also conduct an investigation of 3D self-attention mechanism variants designed for performance improvement. To demonstrate the superiority of 3D Transformers, we compare the performance of Transformer-based algorithms in terms of point cloud classification, segmentation, and object detection. Finally, we point out three potential future research directions, expecting to provide some benefit references for the development of 3D Transformers.
If a Human Can See It, So Should Your System: Reliability Requirements for Machine Vision Components
Feb 08, 2022
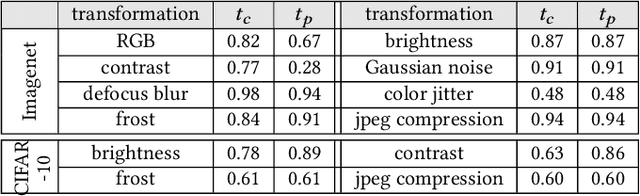
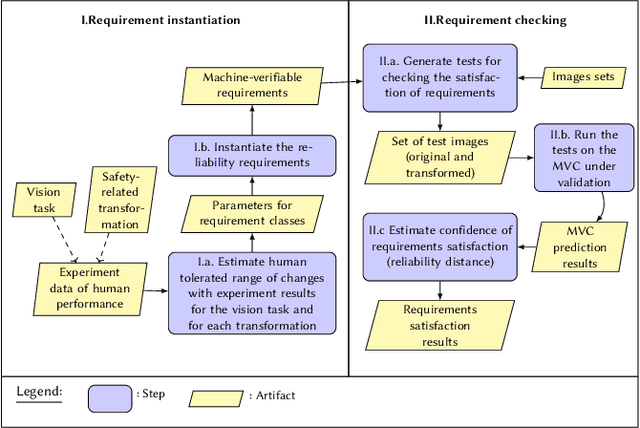
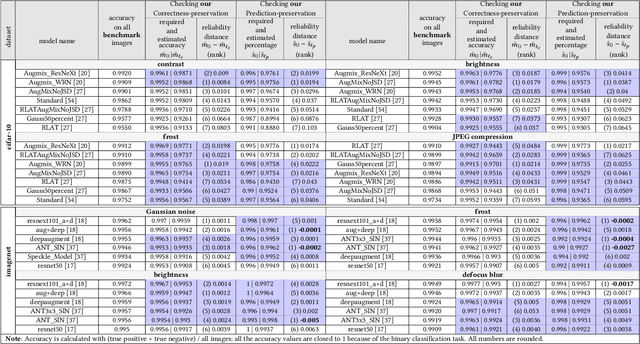
Machine Vision Components (MVC) are becoming safety-critical. Assuring their quality, including safety, is essential for their successful deployment. Assurance relies on the availability of precisely specified and, ideally, machine-verifiable requirements. MVCs with state-of-the-art performance rely on machine learning (ML) and training data but largely lack such requirements. In this paper, we address the need for defining machine-verifiable reliability requirements for MVCs against transformations that simulate the full range of realistic and safety-critical changes in the environment. Using human performance as a baseline, we define reliability requirements as: 'if the changes in an image do not affect a human's decision, neither should they affect the MVC's.' To this end, we provide: (1) a class of safety-related image transformations; (2) reliability requirement classes to specify correctness-preservation and prediction-preservation for MVCs; (3) a method to instantiate machine-verifiable requirements from these requirements classes using human performance experiment data; (4) human performance experiment data for image recognition involving eight commonly used transformations, from about 2000 human participants; and (5) a method for automatically checking whether an MVC satisfies our requirements. Further, we show that our reliability requirements are feasible and reusable by evaluating our methods on 13 state-of-the-art pre-trained image classification models. Finally, we demonstrate that our approach detects reliability gaps in MVCs that other existing methods are unable to detect.