 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VNT-Net: Rotational Invariant Vector Neuron Transformers
May 19, 2022

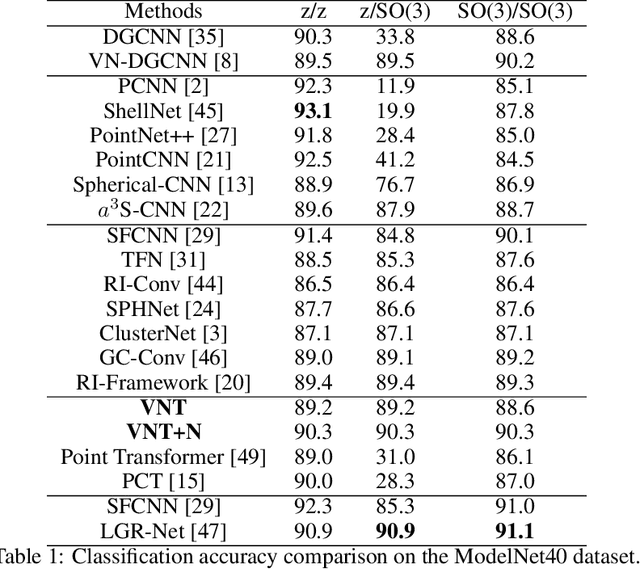
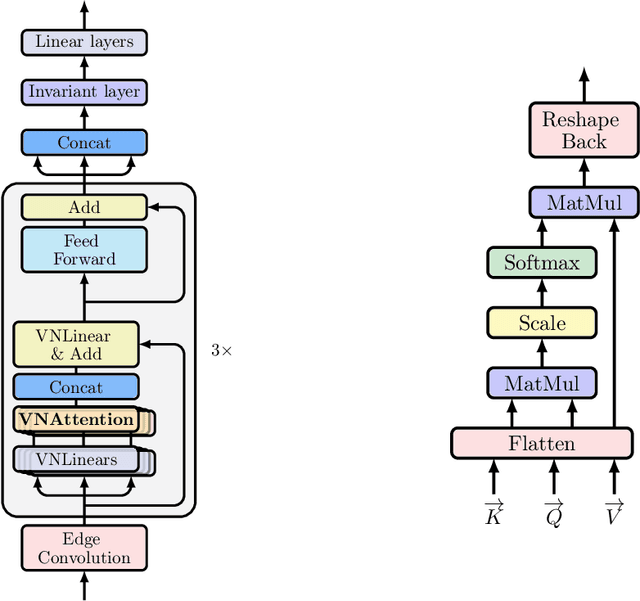
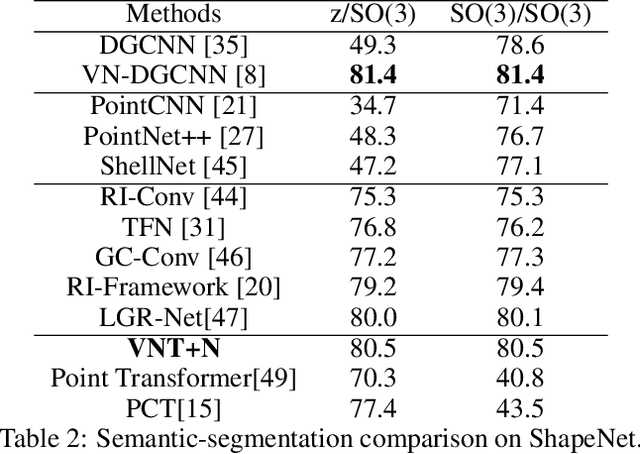
Learning 3D point sets with rotational invariance is an important and challenging problem in machine learning. Through rotational invariant architectures, 3D point cloud neural networks are relieved from requiring a canonical global pose and from exhaustive data augmentation with all possible rotations. In this work, we introduce a rotational invariant neural network by combining recently introduced vector neurons with self-attention layers to build a point cloud vector neuron transformer network (VNT-Net). Vector neurons are known for their simplicity and versatility in representing SO(3) actions and are thereby incorporated in common neural operations. Similarly, Transformer architectures have gained popularity and recently were shown successful for images by applying directly on sequences of image patches and achieving superior performance and convergence. In order to benefit from both worlds, we combine the two structures by mainly showing how to adapt the multi-headed attention layers to comply with vector neurons operations. Through this adaptation attention layers become SO(3) and the overall network becomes rotational invariant. Experiments demonstrate that our network efficiently handles 3D point cloud objects in arbitrary poses. We also show that our network achieves higher accuracy when compared to related state-of-the-art methods and requires less training due to a smaller number of hyperparameters in common classification and segmentation tasks.
Wireless Transmission of Images With The Assistance of Multi-level Semantic Information
Feb 08, 2022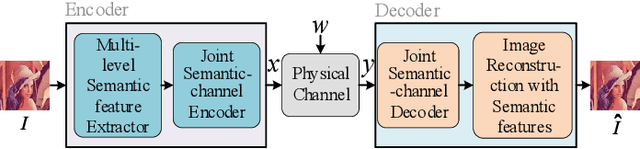
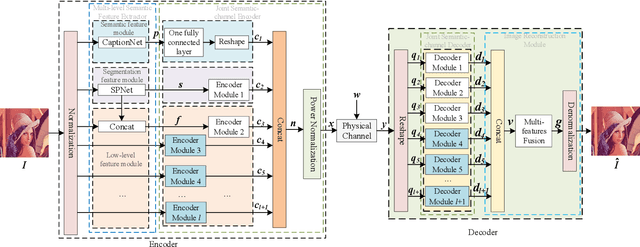
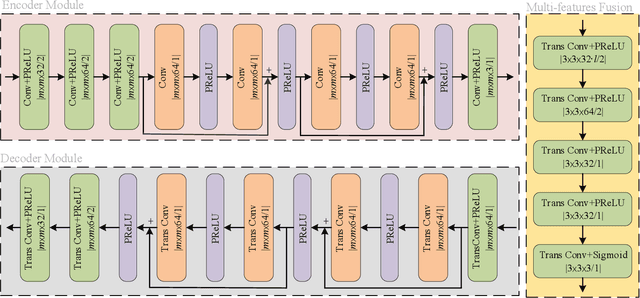
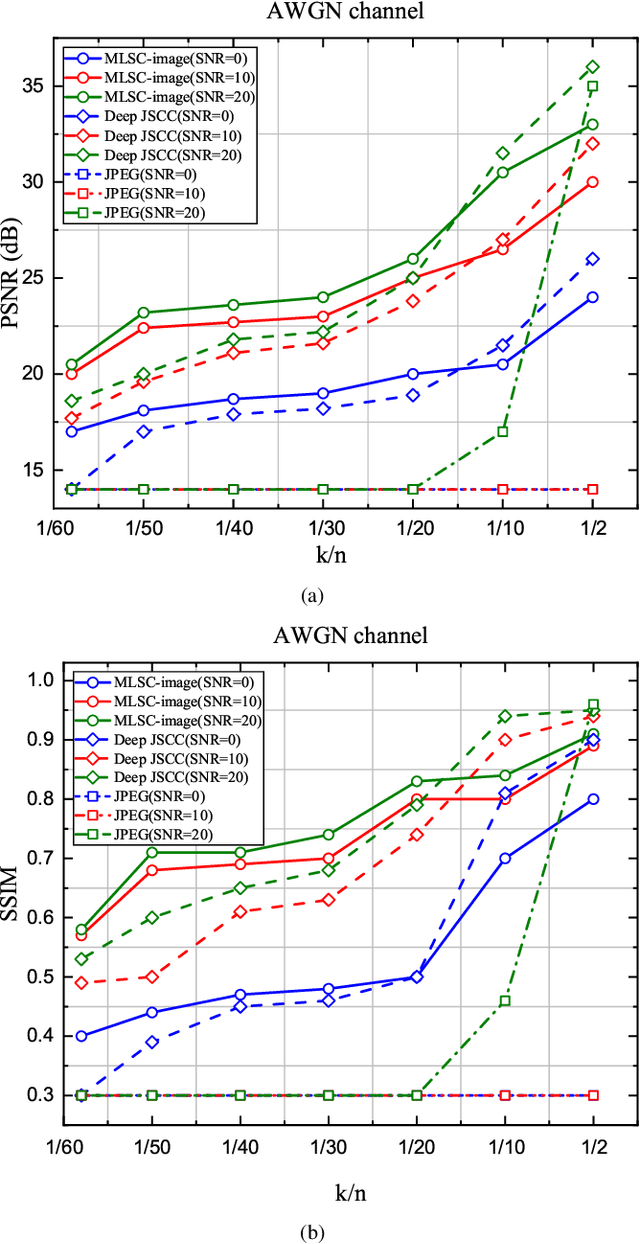
Semantic-oriented communication has been considered as a promising to boost the bandwidth efficiency by only transmitting the semantics of the data. In this paper, we propose a multi-level semantic aware communication system for wireless image transmission, named MLSC-image, which is based on the deep learning techniques and trained in an end to end manner. In particular, the proposed model includes a multilevel semantic feature extractor, that extracts both the highlevel semantic information, such as the text semantics and the segmentation semantics, and the low-level semantic information, such as local spatial details of the images. We employ a pretrained image caption to capture the text semantics and a pretrained image segmentation model to obtain the segmentation semantics. These high-level and low-level semantic features are then combined and encoded by a joint semantic and channel encoder into symbols to transmit over the physical channel. The numerical results validate the effectiveness and efficiency of the proposed semantic communication system, especially under the limited bandwidth condition, which indicates the advantages of the high-level semantics in the compression of images.
NeRD: Neural Representation of Distribution for Medical Image Segmentation
Mar 06, 2021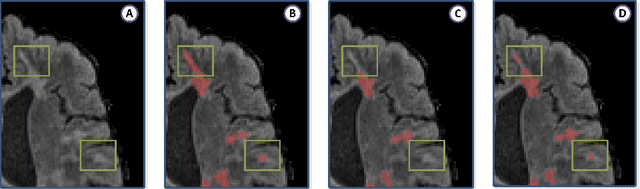
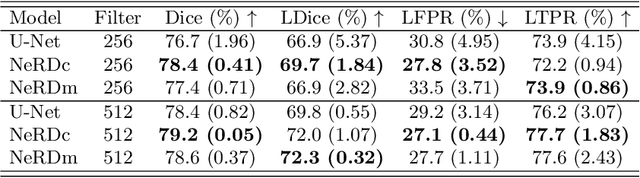
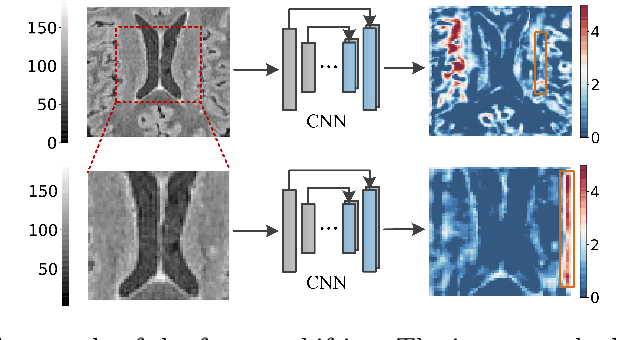
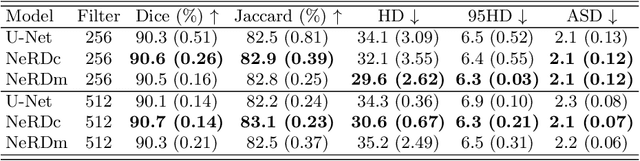
We introduce Neural Representation of Distribution (NeRD) technique, a module for convolutional neural networks (CNNs) that can estimate the feature distribution by optimizing an underlying function mapping image coordinates to the feature distribution. Using NeRD, we propose an end-to-end deep learning model for medical image segmentation that can compensate the negative impact of feature distribution shifting issue caused by commonly used network operations such as padding and pooling. An implicit function is used to represent the parameter space of the feature distribution by querying the image coordinate. With NeRD, the impact of issues such as over-segmenting and missing have been reduced, and experimental results on the challenging white matter lesion segmentation and left atrial segmentation verify the effectiveness of the proposed method. The code is available via https://github.com/tinymilky/NeRD.
Interactive Multi-Class Tiny-Object Detection
Mar 29, 2022

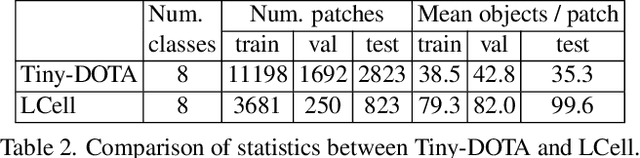
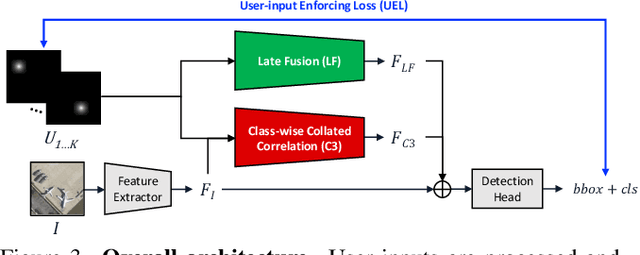
Annotating tens or hundreds of tiny objects in a given image is laborious yet crucial for a multitude of Computer Vision tasks. Such imagery typically contains objects from various categories, yet the multi-class interactive annotation setting for the detection task has thus far been unexplored. To address these needs, we propose a novel interactive annotation method for multiple instances of tiny objects from multiple classes, based on a few point-based user inputs. Our approach, C3Det, relates the full image context with annotator inputs in a local and global manner via late-fusion and feature-correlation, respectively. We perform experiments on the Tiny-DOTA and LCell datasets using both two-stage and one-stage object detection architectures to verify the efficacy of our approach. Our approach outperforms existing approaches in interactive annotation, achieving higher mAP with fewer clicks. Furthermore, we validate the annotation efficiency of our approach in a user study where it is shown to be 2.85x faster and yield only 0.36x task load (NASA-TLX, lower is better) compared to manual annotation. The code is available at https://github.com/ChungYi347/Interactive-Multi-Class-Tiny-Object-Detection.
Self-Adversarial Training incorporating Forgery Attention for Image Forgery Localization
Jul 06, 2021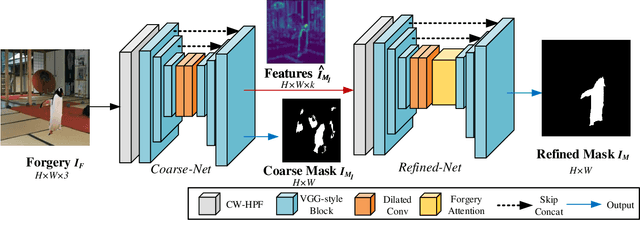
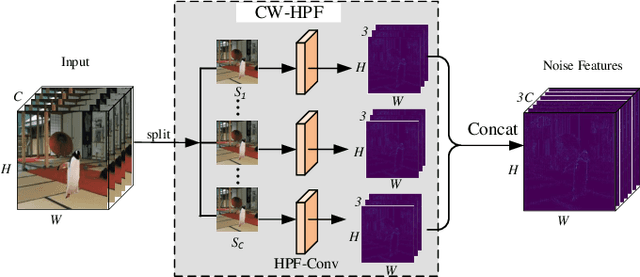
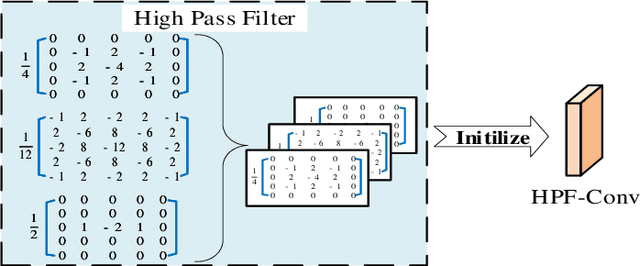
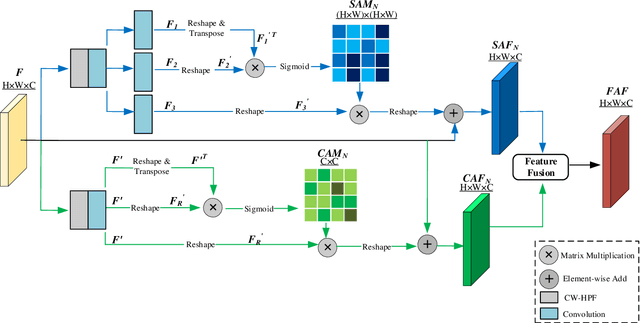
Image editing techniques enable people to modify the content of an image without leaving visual traces and thus may cause serious security risks. Hence the detection and localization of these forgeries become quite necessary and challenging. Furthermore, unlike other tasks with extensive data, there is usually a lack of annotated forged images for training due to annotation difficulties. In this paper, we propose a self-adversarial training strategy and a reliable coarse-to-fine network that utilizes a self-attention mechanism to localize forged regions in forgery images. The self-attention module is based on a Channel-Wise High Pass Filter block (CW-HPF). CW-HPF leverages inter-channel relationships of features and extracts noise features by high pass filters. Based on the CW-HPF, a self-attention mechanism, called forgery attention, is proposed to capture rich contextual dependencies of intrinsic inconsistency extracted from tampered regions. Specifically, we append two types of attention modules on top of CW-HPF respectively to model internal interdependencies in spatial dimension and external dependencies among channels. We exploit a coarse-to-fine network to enhance the noise inconsistency between original and tampered regions. More importantly, to address the issue of insufficient training data, we design a self-adversarial training strategy that expands training data dynamically to achieve more robust performance. Specifically, in each training iteration, we perform adversarial attacks against our network to generate adversarial examples and train our model on them. Extensive experimental results demonstrate that our proposed algorithm steadily outperforms state-of-the-art methods by a clear margin in different benchmark datasets.
TRT-ViT: TensorRT-oriented Vision Transformer
May 19, 2022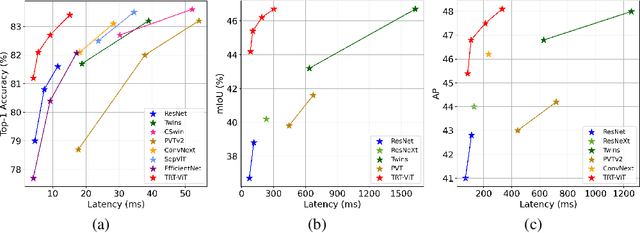
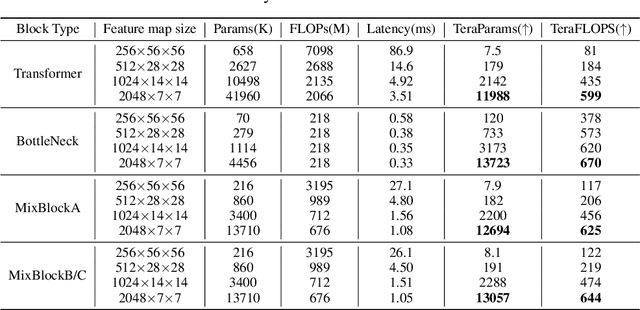
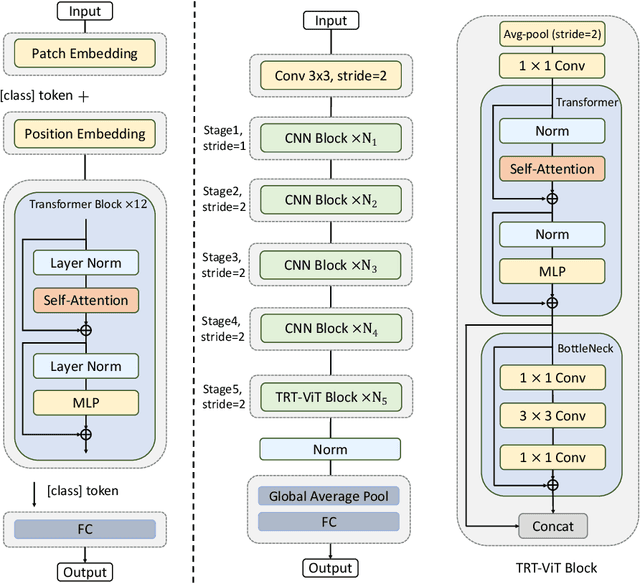
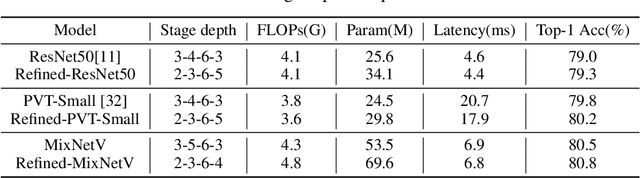
We revisit the existing excellent Transformers from the perspective of practical application. Most of them are not even as efficient as the basic ResNets series and deviate from the realistic deployment scenario. It may be due to the current criterion to measure computation efficiency, such as FLOPs or parameters is one-sided, sub-optimal, and hardware-insensitive. Thus, this paper directly treats the TensorRT latency on the specific hardware as an efficiency metric, which provides more comprehensive feedback involving computational capacity, memory cost, and bandwidth. Based on a series of controlled experiments, this work derives four practical guidelines for TensorRT-oriented and deployment-friendly network design, e.g., early CNN and late Transformer at stage-level, early Transformer and late CNN at block-level. Accordingly, a family of TensortRT-oriented Transformers is presented, abbreviated as TRT-ViT. Extensive experiments demonstrate that TRT-ViT significantly outperforms existing ConvNets and vision Transformers with respect to the latency/accuracy trade-off across diverse visual tasks, e.g., image classification, object detection and semantic segmentation. For example, at 82.7% ImageNet-1k top-1 accuracy, TRT-ViT is 2.7$\times$ faster than CSWin and 2.0$\times$ faster than Twins. On the MS-COCO object detection task, TRT-ViT achieves comparable performance with Twins, while the inference speed is increased by 2.8$\times$.
Accelerating Diffusion Models via Early Stop of the Diffusion Process
May 30, 2022

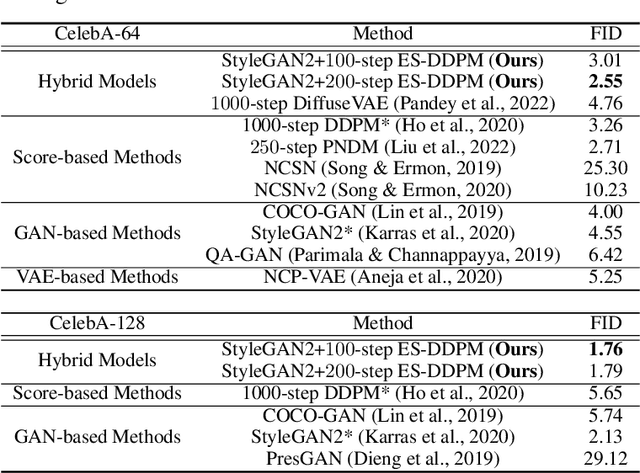
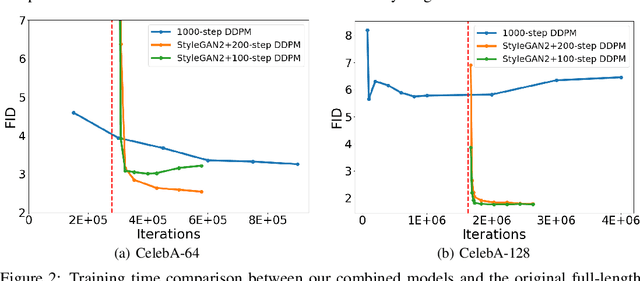
Denoising Diffusion Probabilistic Models (DDPMs) have achieved impressive performance on various generation tasks. By modeling the reverse process of gradually diffusing the data distribution into a Gaussian distribution, generating a sample in DDPMs can be regarded as iteratively denoising a randomly sampled Gaussian noise. However, in practice DDPMs often need hundreds even thousands of denoising steps to obtain a high-quality sample from the Gaussian noise, leading to extremely low inference efficiency. In this work, we propose a principled acceleration strategy, referred to as Early-Stopped DDPM (ES-DDPM), for DDPMs. The key idea is to stop the diffusion process early where only the few initial diffusing steps are considered and the reverse denoising process starts from a non-Gaussian distribution. By further adopting a powerful pre-trained generative model, such as GAN and VAE, in ES-DDPM, sampling from the target non-Gaussian distribution can be efficiently achieved by diffusing samples obtained from the pre-trained generative model. In this way, the number of required denoising steps is significantly reduced. In the meantime, the sample quality of ES-DDPM also improves substantially, outperforming both the vanilla DDPM and the adopted pre-trained generative model. On extensive experiments across CIFAR-10, CelebA, ImageNet, LSUN-Bedroom and LSUN-Cat, ES-DDPM obtains promising acceleration effect and performance improvement over representative baseline methods. Moreover, ES-DDPM also demonstrates several attractive properties, including being orthogonal to existing acceleration methods, as well as simultaneously enabling both global semantic and local pixel-level control in image generation.
4Weed Dataset: Annotated Imagery Weeds Dataset
Mar 29, 2022

Weeds are a major threat to crops and are responsible for reducing crop yield worldwide. To mitigate their negative effect, it is advantageous to accurately identify them early in the season to prevent their spread throughout the field. Traditionally, farmers rely on manually scouting fields and applying herbicides for different weeds. However, it is easy to confuse between crops with weeds during the early growth stages. Recently, deep learning-based weed identification has become popular as deep learning relies on convolutional neural networks that are capable of learning important distinguishable features between weeds and crops. However, training robust deep learning models requires access to large imagery datasets. Therefore, an early-season weeds dataset was acquired under field conditions. The dataset consists of 159 Cocklebur images, 139 Foxtail images, 170 Redroot Pigweed images and 150 Giant Ragweed images corresponding to four common weed species found in corn and soybean production systems.. Bounding box annotations were created for each image to prepare the dataset for training both image classification and object detection deep learning networks capable of accurately locating and identifying weeds within corn and soybean fields. (https://osf.io/w9v3j/)
End-to-End Attention-based Image Captioning
Apr 30, 2021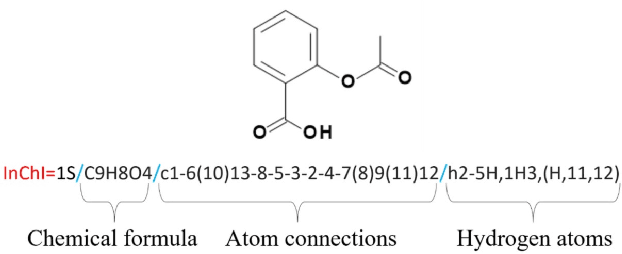
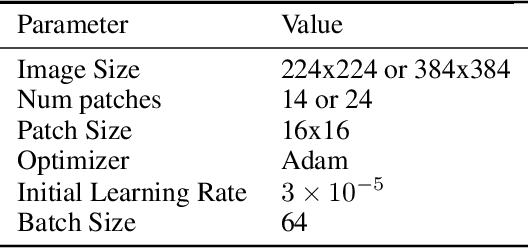
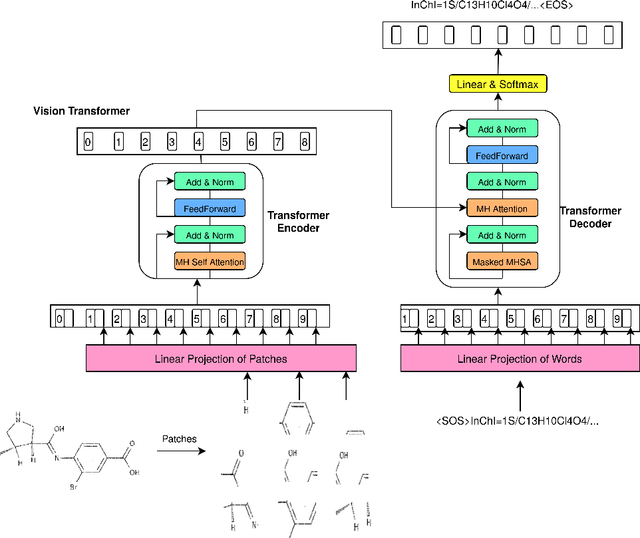
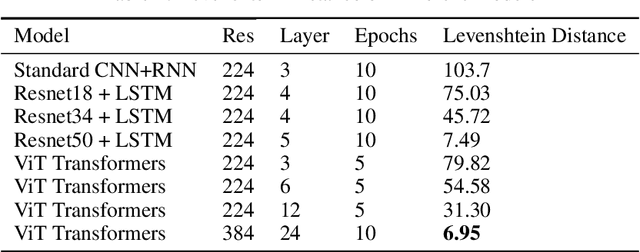
In this paper, we address the problem of image captioning specifically for molecular translation where the result would be a predicted chemical notation in InChI format for a given molecular structure. Current approaches mainly follow rule-based or CNN+RNN based methodology. However, they seem to underperform on noisy images and images with small number of distinguishable features. To overcome this, we propose an end-to-end transformer model. When compared to attention-based techniques, our proposed model outperforms on molecular datasets.
PointDistiller: Structured Knowledge Distillation Towards Efficient and Compact 3D Detection
May 23, 2022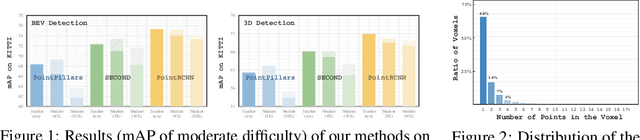
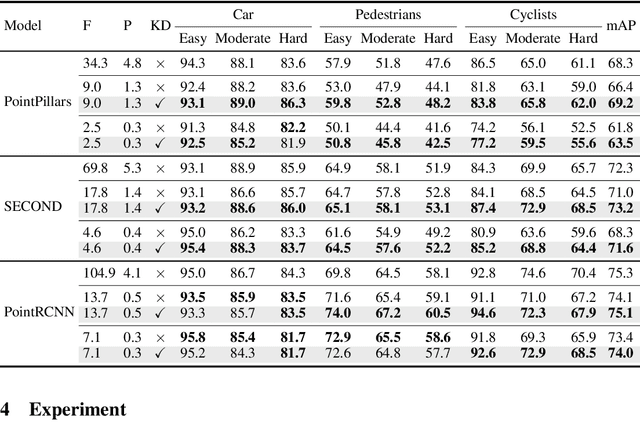
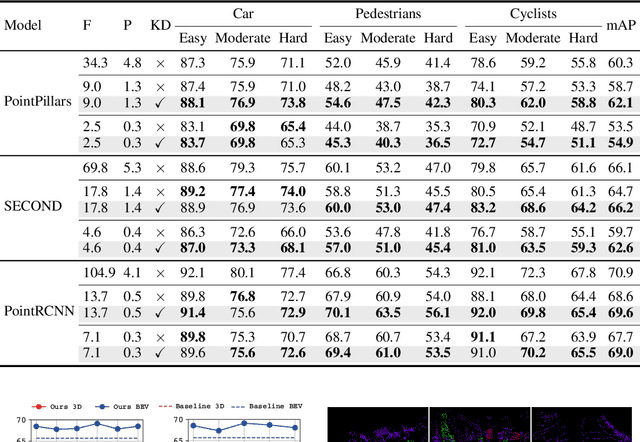
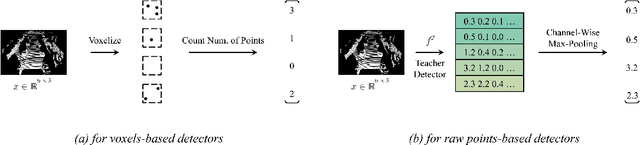
The remarkable breakthroughs in point cloud representation learning have boosted their usage in real-world applications such as self-driving cars and virtual reality. However, these applications usually have an urgent requirement for not only accurate but also efficient 3D object detection. Recently, knowledge distillation has been proposed as an effective model compression technique, which transfers the knowledge from an over-parameterized teacher to a lightweight student and achieves consistent effectiveness in 2D vision. However, due to point clouds' sparsity and irregularity, directly applying previous image-based knowledge distillation methods to point cloud detectors usually leads to unsatisfactory performance. To fill the gap, this paper proposes PointDistiller, a structured knowledge distillation framework for point clouds-based 3D detection. Concretely, PointDistiller includes local distillation which extracts and distills the local geometric structure of point clouds with dynamic graph convolution and reweighted learning strategy, which highlights student learning on the crucial points or voxels to improve knowledge distillation efficiency. Extensive experiments on both voxels-based and raw points-based detectors have demonstrated the effectiveness of our method over seven previous knowledge distillation methods. For instance, our 4X compressed PointPillars student achieves 2.8 and 3.4 mAP improvements on BEV and 3D object detection, outperforming its teacher by 0.9 and 1.8 mAP, respectively. Codes have been released at https://github.com/RunpeiDong/PointDistiller.