 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Visual Navigation Perspective for Category-Level Object Pose Estimation
Mar 25, 2022
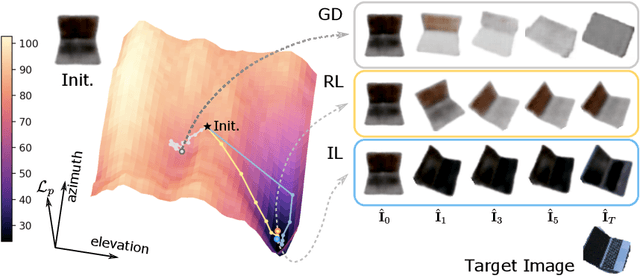
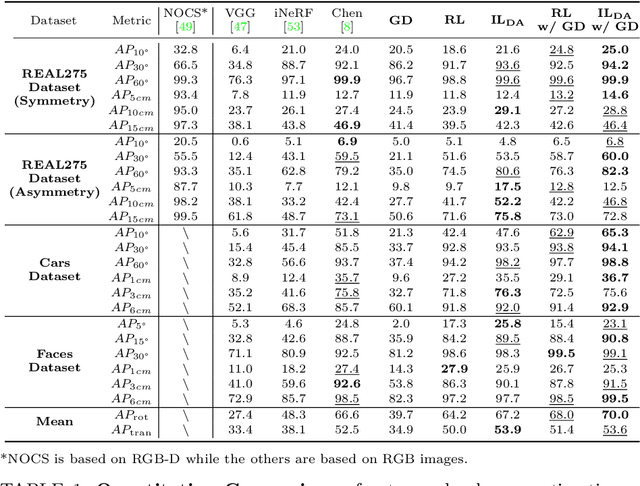
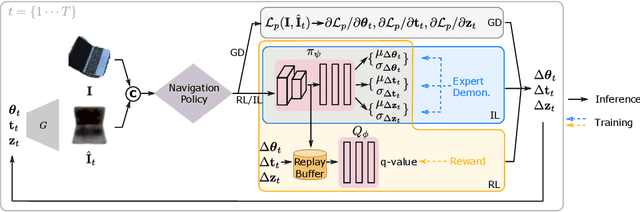
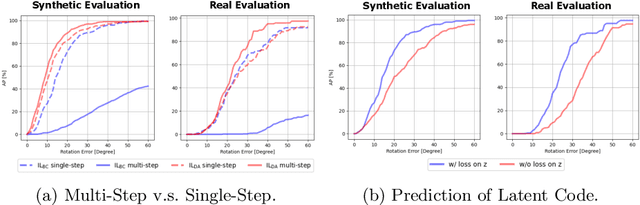
This paper studies category-level object pose estimation based on a single monocular image. Recent advances in pose-aware generative models have paved the way for addressing this challenging task using analysis-by-synthesis. The idea is to sequentially update a set of latent variables, e.g., pose, shape, and appearance, of the generative model until the generated image best agrees with the observation. However, convergence and efficiency are two challenges of this inference procedure. In this paper, we take a deeper look at the inference of analysis-by-synthesis from the perspective of visual navigation, and investigate what is a good navigation policy for this specific task. We evaluate three different strategies, including gradient descent, reinforcement learning and imitation learning, via thorough comparisons in terms of convergence, robustness and efficiency. Moreover, we show that a simple hybrid approach leads to an effective and efficient solution. We further compare these strategies to state-of-the-art methods, and demonstrate superior performance on synthetic and real-world datasets leveraging off-the-shelf pose-aware generative models.
Single Image Cloud Detection via Multi-Image Fusion
Jul 29, 2020
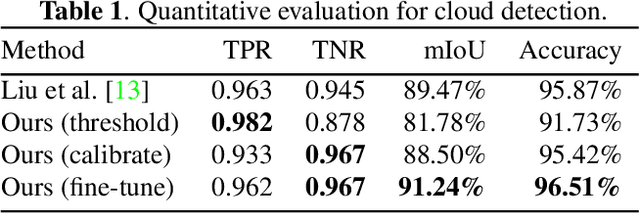
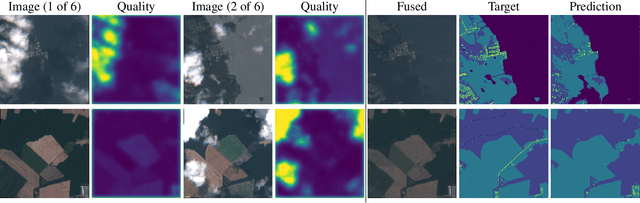
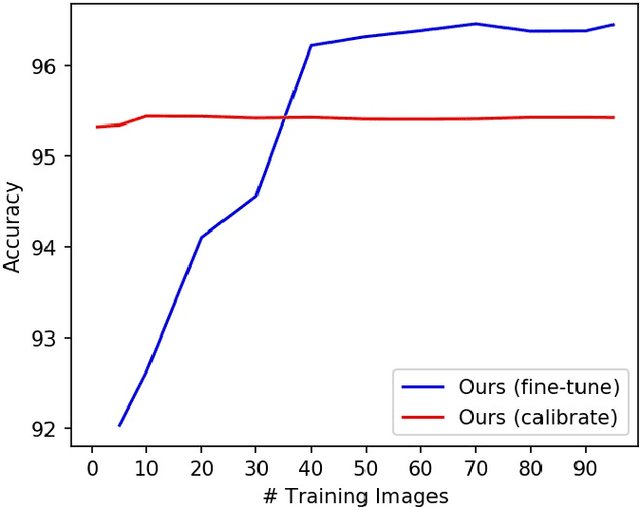
Artifacts in imagery captured by remote sensing, such as clouds, snow, and shadows, present challenges for various tasks, including semantic segmentation and object detection. A primary challenge in developing algorithms for identifying such artifacts is the cost of collecting annotated training data. In this work, we explore how recent advances in multi-image fusion can be leveraged to bootstrap single image cloud detection. We demonstrate that a network optimized to estimate image quality also implicitly learns to detect clouds. To support the training and evaluation of our approach, we collect a large dataset of Sentinel-2 images along with a per-pixel semantic labelling for land cover. Through various experiments, we demonstrate that our method reduces the need for annotated training data and improves cloud detection performance.
iWave3D: End-to-end Brain Image Compression with Trainable 3-D Wavelet Transform
Sep 18, 2021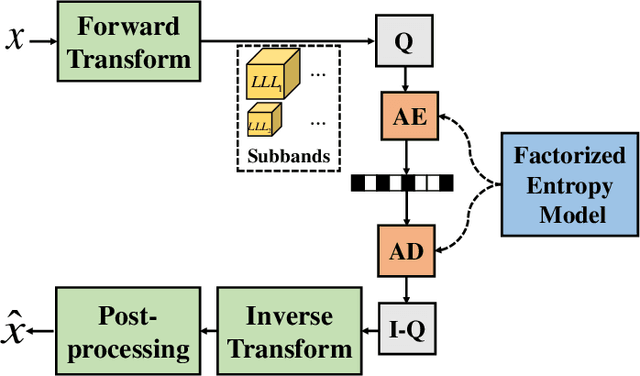
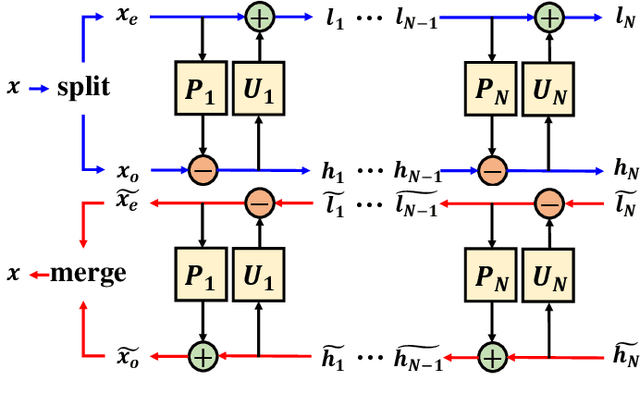
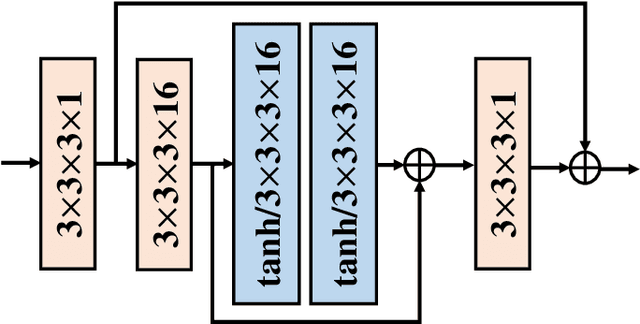
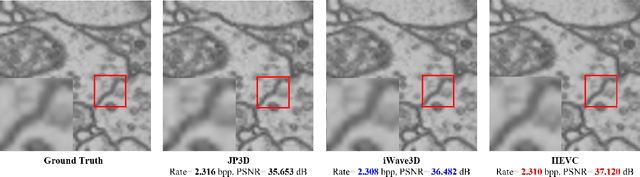
With the rapid development of whole brain imaging technology, a large number of brain images have been produced, which puts forward a great demand for efficient brain image compression methods. At present, the most commonly used compression methods are all based on 3-D wavelet transform, such as JP3D. However, traditional 3-D wavelet transforms are designed manually with certain assumptions on the signal, but brain images are not as ideal as assumed. What's more, they are not directly optimized for compression task. In order to solve these problems, we propose a trainable 3-D wavelet transform based on the lifting scheme, in which the predict and update steps are replaced by 3-D convolutional neural networks. Then the proposed transform is embedded into an end-to-end compression scheme called iWave3D, which is trained with a large amount of brain images to directly minimize the rate-distortion loss. Experimental results demonstrate that our method outperforms JP3D significantly by 2.012 dB in terms of average BD-PSNR.
DistillAdapt: Source-Free Active Visual Domain Adaptation
May 24, 2022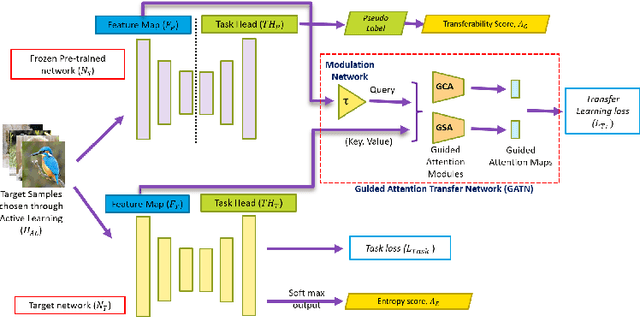

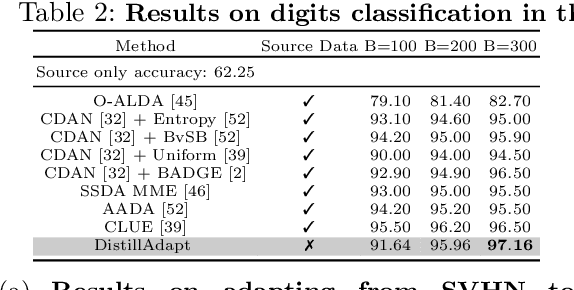
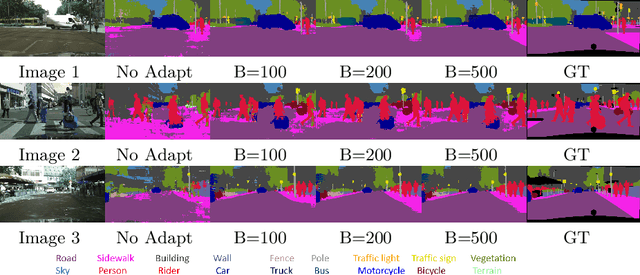
We present a novel method, DistillAdapt, for the challenging problem of Source-Free Active Domain Adaptation (SF-ADA). The problem requires adapting a pretrained source domain network to a target domain, within a provided budget for acquiring labels in the target domain, while assuming that the source data is not available for adaptation due to privacy concerns or otherwise. DistillAdapt is one of the first approaches for SF-ADA, and holistically addresses the challenges of SF-ADA via a novel Guided Attention Transfer Network (GATN) and an active learning heuristic, H_AL. The GATN enables selective distillation of features from the pre-trained network to the target network using a small subset of annotated target samples mined by H_AL. H_AL acquires samples at batch-level and balances transfer-ability from the pre-trained network and uncertainty of the target network. DistillAdapt is task-agnostic, and can be applied across visual tasks such as classification, segmentation and detection. Moreover, DistillAdapt can handle shifts in output label space. We conduct experiments and extensive ablation studies across 3 visual tasks, viz. digits classification (MNIST, SVHN), synthetic (GTA5) to real (CityScapes) image segmentation, and document layout detection (PubLayNet to DSSE). We show that our source-free approach, DistillAdapt, results in an improvement of 0.5% - 31.3% (across datasets and tasks) over prior adaptation methods that assume access to large amounts of annotated source data for adaptation.
M^2BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Birds-Eye View Representation
Apr 11, 2022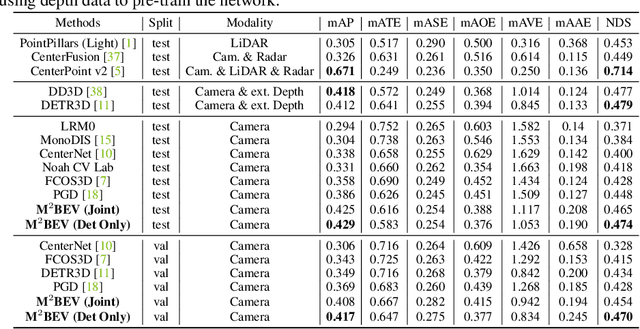
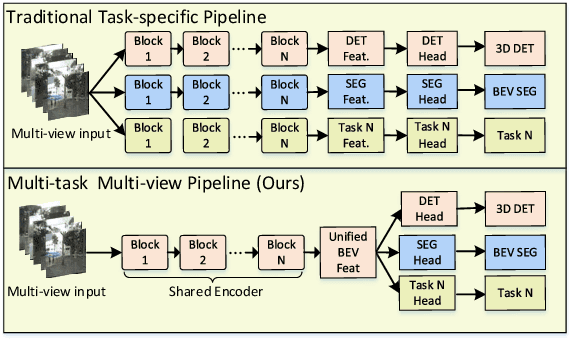
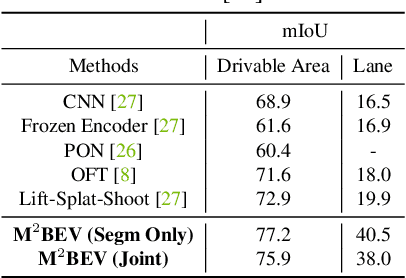
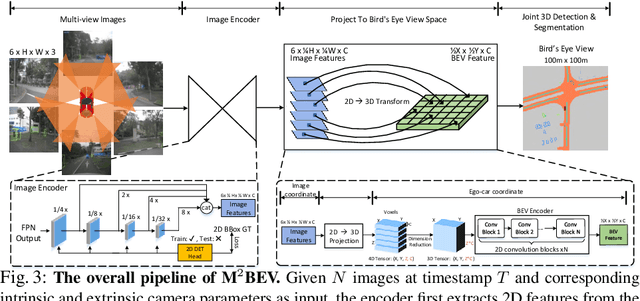
In this paper, we propose M$^2$BEV, a unified framework that jointly performs 3D object detection and map segmentation in the Birds Eye View~(BEV) space with multi-camera image inputs. Unlike the majority of previous works which separately process detection and segmentation, M$^2$BEV infers both tasks with a unified model and improves efficiency. M$^2$BEV efficiently transforms multi-view 2D image features into the 3D BEV feature in ego-car coordinates. Such BEV representation is important as it enables different tasks to share a single encoder. Our framework further contains four important designs that benefit both accuracy and efficiency: (1) An efficient BEV encoder design that reduces the spatial dimension of a voxel feature map. (2) A dynamic box assignment strategy that uses learning-to-match to assign ground-truth 3D boxes with anchors. (3) A BEV centerness re-weighting that reinforces with larger weights for more distant predictions, and (4) Large-scale 2D detection pre-training and auxiliary supervision. We show that these designs significantly benefit the ill-posed camera-based 3D perception tasks where depth information is missing. M$^2$BEV is memory efficient, allowing significantly higher resolution images as input, with faster inference speed. Experiments on nuScenes show that M$^2$BEV achieves state-of-the-art results in both 3D object detection and BEV segmentation, with the best single model achieving 42.5 mAP and 57.0 mIoU in these two tasks, respectively.
Controlling Memorability of Face Images
Feb 24, 2022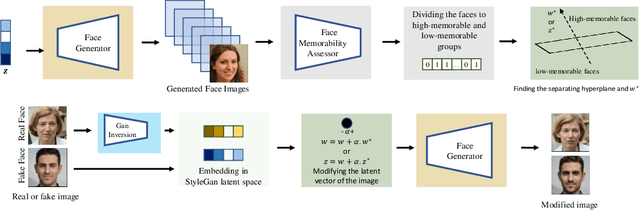


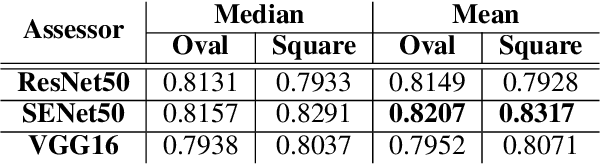
Everyday, we are bombarded with many photographs of faces, whether on social media, television, or smartphones. From an evolutionary perspective, faces are intended to be remembered, mainly due to survival and personal relevance. However, all these faces do not have the equal opportunity to stick in our minds. It has been shown that memorability is an intrinsic feature of an image but yet, it is largely unknown what attributes make an image more memorable. In this work, we aimed to address this question by proposing a fast approach to modify and control the memorability of face images. In our proposed method, we first found a hyperplane in the latent space of StyleGAN to separate high and low memorable images. We then modified the image memorability (while maintaining the identity and other facial features such as age, emotion, etc.) by moving in the positive or negative direction of this hyperplane normal vector. We further analyzed how different layers of the StyleGAN augmented latent space contribute to face memorability. These analyses showed how each individual face attribute makes an image more or less memorable. Most importantly, we evaluated our proposed method for both real and synthesized face images. The proposed method successfully modifies and controls the memorability of real human faces as well as unreal synthesized faces. Our proposed method can be employed in photograph editing applications for social media, learning aids, or advertisement purposes.
DTFD-MIL: Double-Tier Feature Distillation Multiple Instance Learning for Histopathology Whole Slide Image Classification
Mar 22, 2022
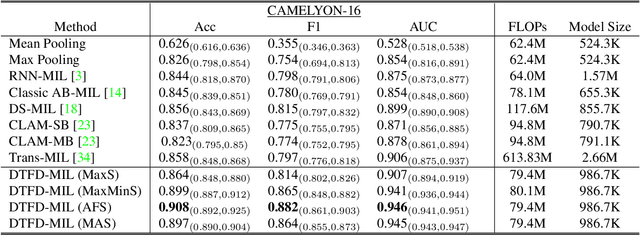

Multiple instance learning (MIL) has been increasingly used in the classification of histopathology whole slide images (WSIs). However, MIL approaches for this specific classification problem still face unique challenges, particularly those related to small sample cohorts. In these, there are limited number of WSI slides (bags), while the resolution of a single WSI is huge, which leads to a large number of patches (instances) cropped from this slide. To address this issue, we propose to virtually enlarge the number of bags by introducing the concept of pseudo-bags, on which a double-tier MIL framework is built to effectively use the intrinsic features. Besides, we also contribute to deriving the instance probability under the framework of attention-based MIL, and utilize the derivation to help construct and analyze the proposed framework. The proposed method outperforms other latest methods on the CAMELYON-16 by substantially large margins, and is also better in performance on the TCGA lung cancer dataset. The proposed framework is ready to be extended for wider MIL applications. The code is available at: https://github.com/hrzhang1123/DTFD-MIL
Do learned representations respect causal relationships?
Apr 07, 2022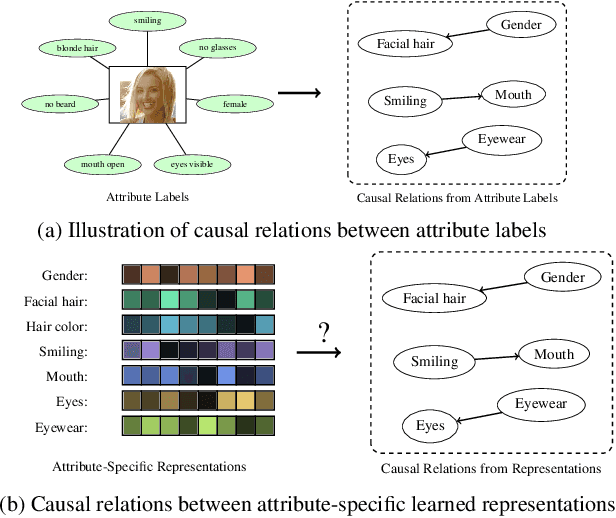
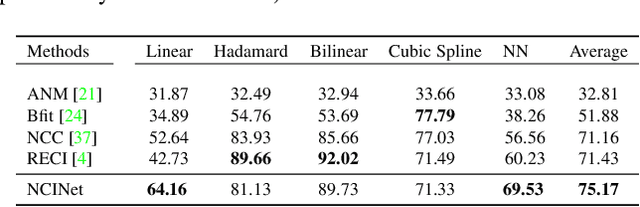


Data often has many semantic attributes that are causally associated with each other. But do attribute-specific learned representations of data also respect the same causal relations? We answer this question in three steps. First, we introduce NCINet, an approach for observational causal discovery from high-dimensional data. It is trained purely on synthetically generated representations and can be applied to real representations, and is specifically designed to mitigate the domain gap between the two. Second, we apply NCINet to identify the causal relations between image representations of different pairs of attributes with known and unknown causal relations between the labels. For this purpose, we consider image representations learned for predicting attributes on the 3D Shapes, CelebA, and the CASIA-WebFace datasets, which we annotate with multiple multi-class attributes. Third, we analyze the effect on the underlying causal relation between learned representations induced by various design choices in representation learning. Our experiments indicate that (1) NCINet significantly outperforms existing observational causal discovery approaches for estimating the causal relation between pairs of random samples, both in the presence and absence of an unobserved confounder, (2) under controlled scenarios, learned representations can indeed satisfy the underlying causal relations between their respective labels, and (3) the causal relations are positively correlated with the predictive capability of the representations.
Binarizing by Classification: Is soft function really necessary?
May 16, 2022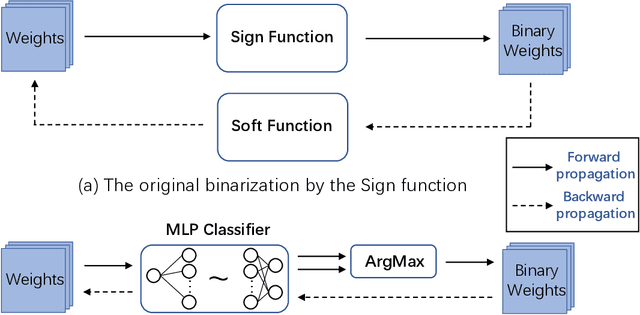

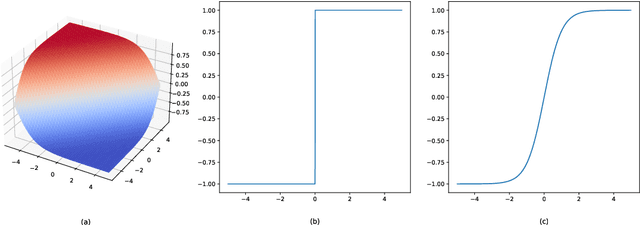
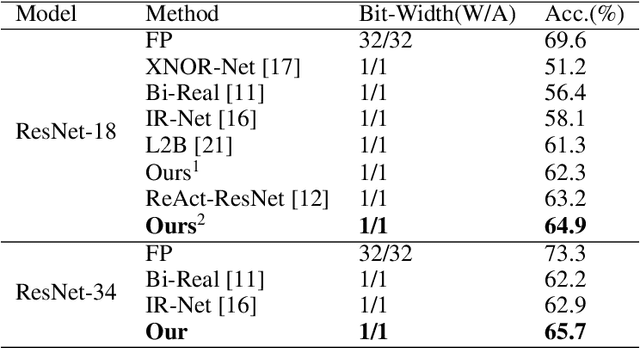
Binary neural network leverages the $Sign$ function to binarize real values, and its non-derivative property inevitably brings huge gradient errors during backpropagation. Although many hand-designed soft functions have been proposed to approximate gradients, their mechanism is not clear and there are still huge performance gaps between binary models and their full-precision counterparts. To address this, we propose to tackle network binarization as a binary classification problem and use a multi-layer perceptron (MLP) as the classifier. The MLP-based classifier can fit any continuous function theoretically and is adaptively learned to binarize networks and backpropagate gradients without any specific soft function. With this view, we further prove experimentally that even a simple linear function can outperform previous complex soft functions. Extensive experiments demonstrate that the proposed method yields surprising performance both in image classification and human pose estimation tasks. Specifically, we achieve 65.7% top-1 accuracy of ResNet-34 on ImageNet dataset, with an absolute improvement of 2.8%. When evaluating on the challenging Microsoft COCO keypoint dataset, the proposed method enables binary networks to achieve a mAP of 60.6 for the first time, on par with some full-precision methods.
A Note on the Regularity of Images Generated by Convolutional Neural Networks
Apr 22, 2022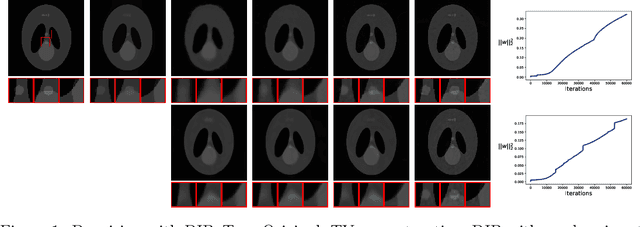
The regularity of images generated by convolutional neural networks, such as the U-net, generative adversarial networks, or the deep image prior, is analyzed. In a resolution-independent, infinite dimensional setting, it is shown that such images, represented as functions, are always continuous and, in some circumstances, even continuously differentiable, contradicting the widely accepted modeling of sharp edges in images via jump discontinuities. While such statements require an infinite dimensional setting, the connection to (discretized) neural networks used in practice is made by considering the limit as the resolution approaches infinity. As practical consequence, the results of this paper suggest to refrain from basic L2 regularization of network weights in case of images being the network output.