 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
InsCon:Instance Consistency Feature Representation via Self-Supervised Learning
Mar 15, 2022
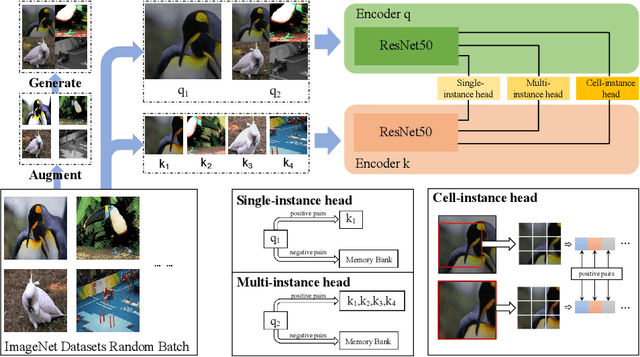
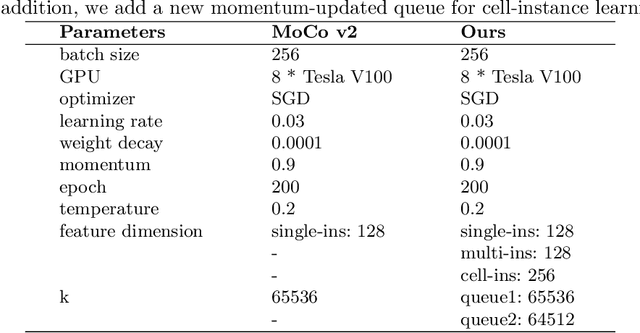
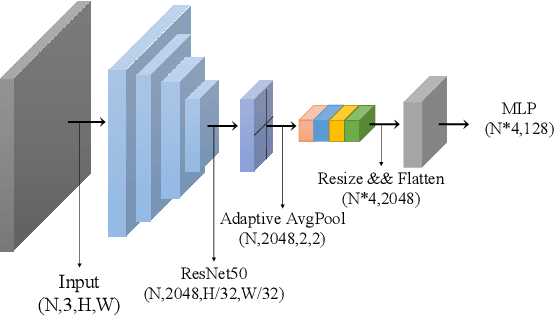
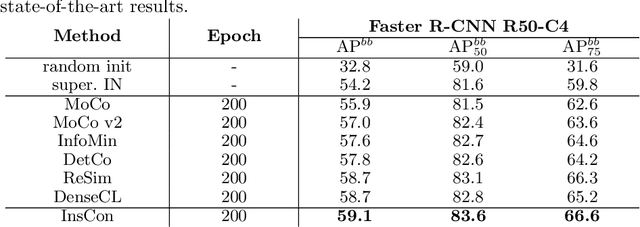
Feature representation via self-supervised learning has reached remarkable success in image-level contrastive learning, which brings impressive performances on image classification tasks. While image-level feature representation mainly focuses on contrastive learning in single instance, it ignores the objective differences between pretext and downstream prediction tasks such as object detection and instance segmentation. In order to fully unleash the power of feature representation on downstream prediction tasks, we propose a new end-to-end self-supervised framework called InsCon, which is devoted to capturing multi-instance information and extracting cell-instance features for object recognition and localization. On the one hand, InsCon builds a targeted learning paradigm that applies multi-instance images as input, aligning the learned feature between corresponding instance views, which makes it more appropriate for multi-instance recognition tasks. On the other hand, InsCon introduces the pull and push of cell-instance, which utilizes cell consistency to enhance fine-grained feature representation for precise boundary localization. As a result, InsCon learns multi-instance consistency on semantic feature representation and cell-instance consistency on spatial feature representation. Experiments demonstrate the method we proposed surpasses MoCo v2 by 1.1% AP^{bb} on COCO object detection and 1.0% AP^{mk} on COCO instance segmentation using Mask R-CNN R50-FPN network structure with 90k iterations, 2.1% APbb on PASCAL VOC objection detection using Faster R-CNN R50-C4 network structure with 24k iterations.
Advances on image interpolation based on ant colony algorithm
Apr 12, 2021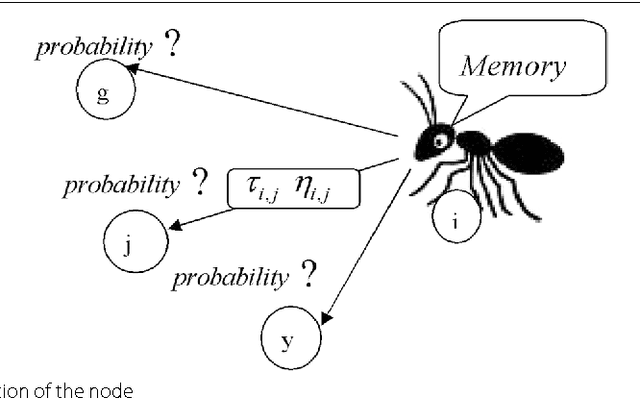

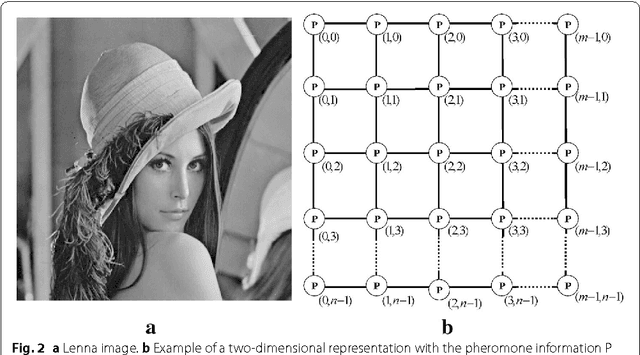

This paper presents an advance on image interpolation based on ant colony algorithm (AACA) for high-resolution image scaling. The difference between the proposed algorithm and the previously proposed optimization of bilinear interpolation based on ant colony algorithm (OBACA) is that AACA uses global weighting, whereas OBACA uses a local weighting scheme. The strength of the proposed global weighting of the AACA algorithm depends on employing solely the pheromone matrix information present on any group of four adjacent pixels to decide which case deserves a maximum global weight value or not. Experimental results are further provided to show the higher performance of the proposed AACA algorithm with reference to the algorithms mentioned in this paper.
* 17 pages, 14 figures, 3 tables
Efficient-VDVAE: Less is more
Mar 25, 2022


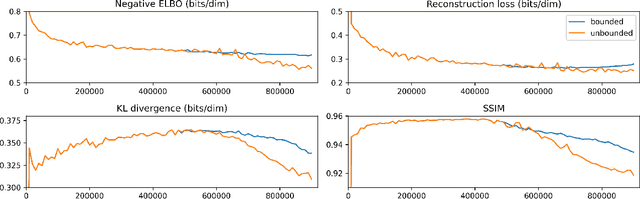
Hierarchical VAEs have emerged in recent years as a reliable option for maximum likelihood estimation. However, instability issues and demanding computational requirements have hindered research progress in the area. We present simple modifications to the Very Deep VAE to make it converge up to $2.6\times$ faster, save up to $20\times$ in memory load and improve stability during training. Despite these changes, our models achieve comparable or better negative log-likelihood performance than current state-of-the-art models on all $7$ commonly used image datasets we evaluated on. We also make an argument against using 5-bit benchmarks as a way to measure hierarchical VAE's performance due to undesirable biases caused by the 5-bit quantization. Additionally, we empirically demonstrate that roughly $3\%$ of the hierarchical VAE's latent space dimensions is sufficient to encode most of the image information, without loss of performance, opening up the doors to efficiently leverage the hierarchical VAEs' latent space in downstream tasks. We release our source code and models at https://github.com/Rayhane-mamah/Efficient-VDVAE .
Beyond Categorical Label Representations for Image Classification
Apr 06, 2021We find that the way we choose to represent data labels can have a profound effect on the quality of trained models. For example, training an image classifier to regress audio labels rather than traditional categorical probabilities produces a more reliable classification. This result is surprising, considering that audio labels are more complex than simpler numerical probabilities or text. We hypothesize that high dimensional, high entropy label representations are generally more useful because they provide a stronger error signal. We support this hypothesis with evidence from various label representations including constant matrices, spectrograms, shuffled spectrograms, Gaussian mixtures, and uniform random matrices of various dimensionalities. Our experiments reveal that high dimensional, high entropy labels achieve comparable accuracy to text (categorical) labels on the standard image classification task, but features learned through our label representations exhibit more robustness under various adversarial attacks and better effectiveness with a limited amount of training data. These results suggest that label representation may play a more important role than previously thought. The project website is at \url{https://www.creativemachineslab.com/label-representation.html}.
LiDAR-guided Stereo Matching with a Spatial Consistency Constraint
Feb 24, 2022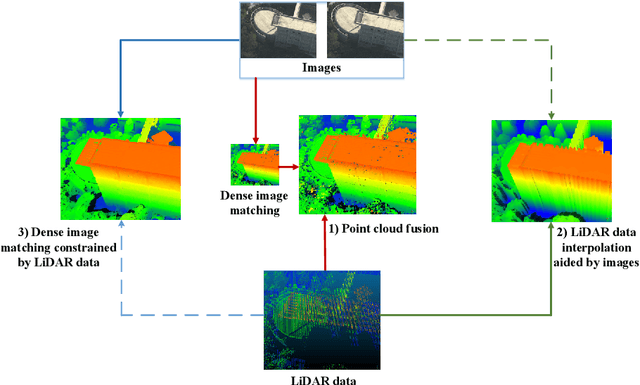
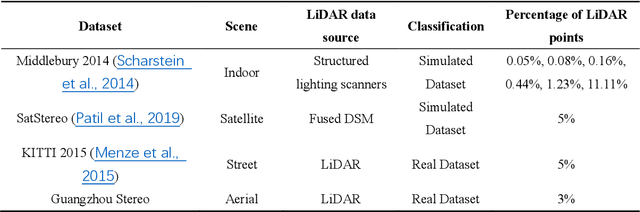
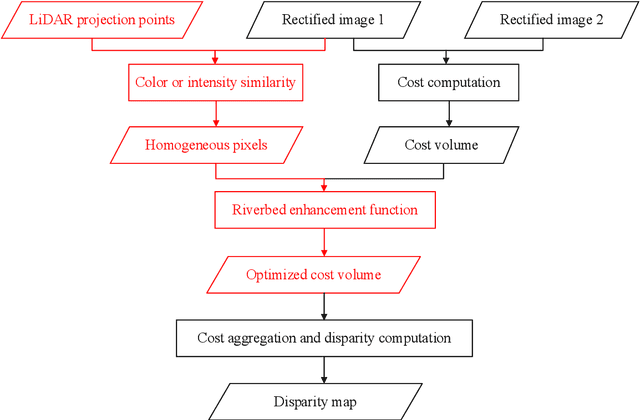
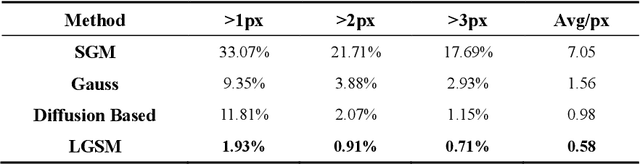
The complementary fusion of light detection and ranging (LiDAR) data and image data is a promising but challenging task for generating high-precision and high-density point clouds. This study proposes an innovative LiDAR-guided stereo matching approach called LiDAR-guided stereo matching (LGSM), which considers the spatial consistency represented by continuous disparity or depth changes in the homogeneous region of an image. The LGSM first detects the homogeneous pixels of each LiDAR projection point based on their color or intensity similarity. Next, we propose a riverbed enhancement function to optimize the cost volume of the LiDAR projection points and their homogeneous pixels to improve the matching robustness. Our formulation expands the constraint scopes of sparse LiDAR projection points with the guidance of image information to optimize the cost volume of pixels as much as possible. We applied LGSM to semi-global matching and AD-Census on both simulated and real datasets. When the percentage of LiDAR points in the simulated datasets was 0.16%, the matching accuracy of our method achieved a subpixel level, while that of the original stereo matching algorithm was 3.4 pixels. The experimental results show that LGSM is suitable for indoor, street, aerial, and satellite image datasets and provides good transferability across semi-global matching and AD-Census. Furthermore, the qualitative and quantitative evaluations demonstrate that LGSM is superior to two state-of-the-art optimizing cost volume methods, especially in reducing mismatches in difficult matching areas and refining the boundaries of objects.
* we replace an article because of the addition of journal reference, DOI, and report number information
A Data Augmentation Method for Fully Automatic Brain Tumor Segmentation
Feb 13, 2022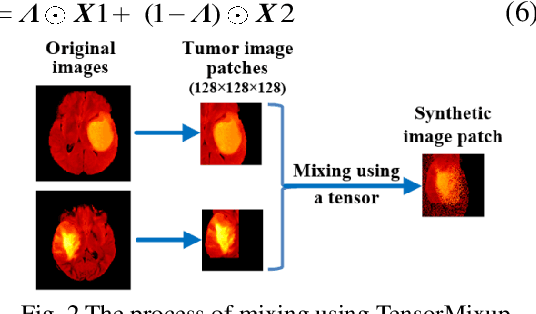

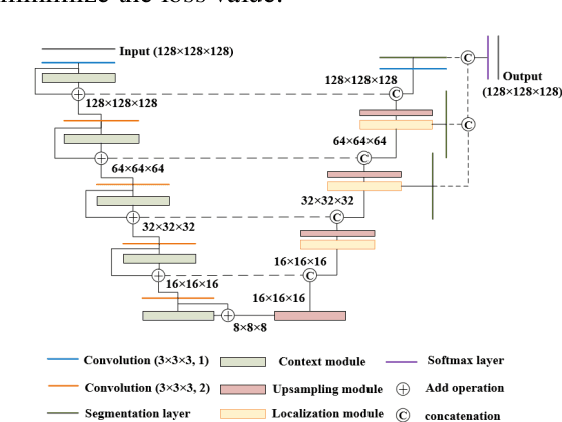
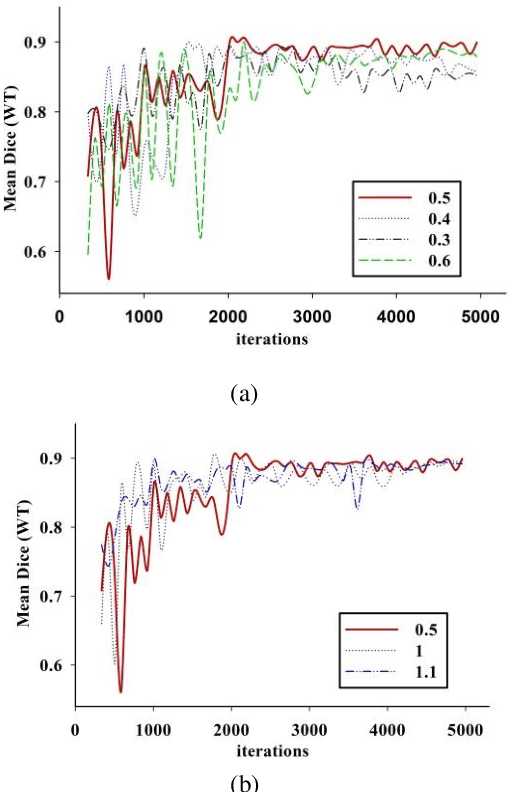
Automatic segmentation of glioma and its subregions is of great significance for diagnosis, treatment and monitoring of disease. In this paper, an augmentation method, called TensorMixup, was proposed and applied to the three dimensional U-Net architecture for brain tumor segmentation. The main ideas included that first, two image patches with size of 128 in three dimensions were selected according to glioma information of ground truth labels from the magnetic resonance imaging data of any two patients with the same modality. Next, a tensor in which all elements were independently sampled from Beta distribution was used to mix the image patches. Then the tensor was mapped to a matrix which was used to mix the one-hot encoded labels of the above image patches. Therefore, a new image and its one-hot encoded label were synthesized. Finally, the new data was used to train the model which could be used to segment glioma. The experimental results show that the mean accuracy of Dice scores are 91.32%, 85.67%, and 82.20% respectively on the whole tumor, tumor core, and enhancing tumor segmentation, which proves that the proposed TensorMixup is feasible and effective for brain tumor segmentation.
LF-YOLO: A Lighter and Faster YOLO for Weld Defect Detection of X-ray Image
Oct 28, 2021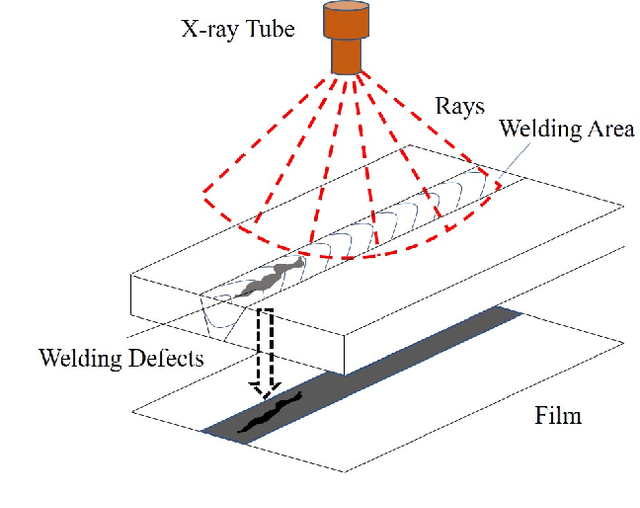

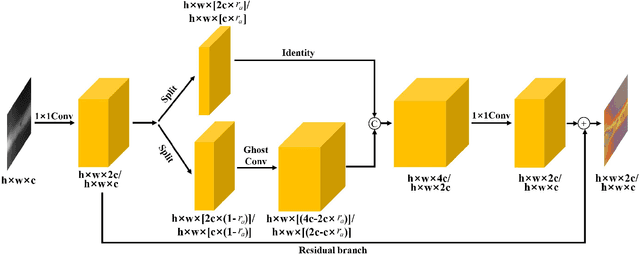
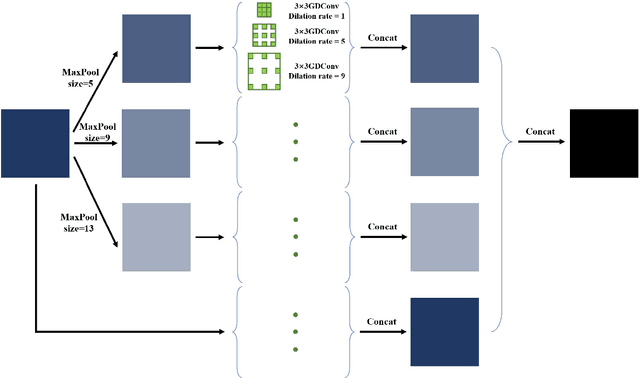
X-ray image plays an important role in manufacturing for quality assurance, because it can reflect the internal condition of weld region. However, the shape and scale of different defect types vary greatly, which makes it challenging for model to detect weld defects. In this paper, we propose a weld defect detection method based on convolution neural network (CNN), namely Lighter and Faster YOLO (LF-YOLO). In particularly, an enhanced multiscale feature (EMF) module is designed to implement both parameter-based and parameter-free multi-scale information extracting operation. EMF enables the extracted feature map capable to represent more plentiful information, which is achieved by superior hierarchical fusion structure. To improve the performance of detection network, we propose an efficient feature extraction (EFE) module. EFE processes input data with extremely low consumption, and improve the practicability of whole network in actual industry. Experimental results show that our weld defect network achieves satisfactory balance between performance and consumption, and reaches 92.9 mAP50 with 61.5 FPS. To further prove the ability of our method, we test it on public dataset MS COCO, and the results show that our LF-YOLO has a outstanding versatility detection performance. The code is available at https://github.com/lmomoy/LF-YOLO.
Decision boundaries and convex hulls in the feature space that deep learning functions learn from images
Feb 05, 2022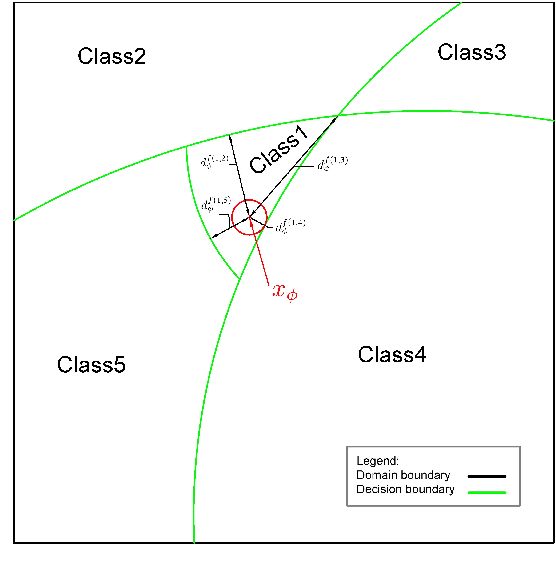
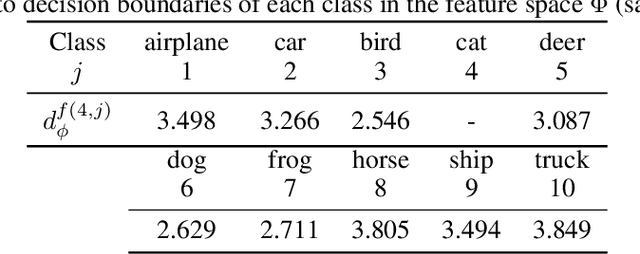
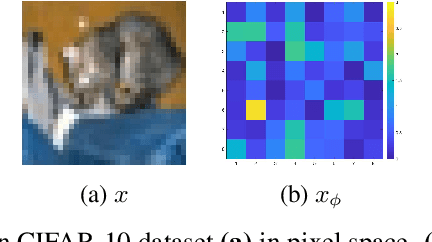
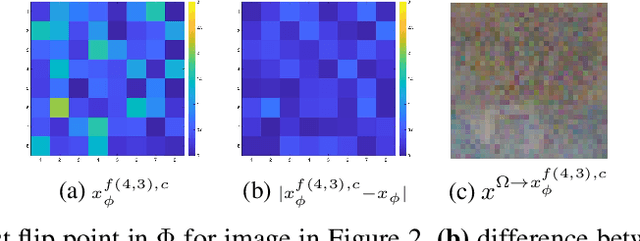
The success of deep neural networks in image classification and learning can be partly attributed to the features they extract from images. It is often speculated about the properties of a low-dimensional manifold that models extract and learn from images. However, there is not sufficient understanding about this low-dimensional space based on theory or empirical evidence. For image classification models, their last hidden layer is the one where images of each class is separated from other classes and it also has the least number of features. Here, we develop methods and formulations to study that feature space for any model. We study the partitioning of the domain in feature space, identify regions guaranteed to have certain classifications, and investigate its implications for the pixel space. We observe that geometric arrangements of decision boundaries in feature space is significantly different compared to pixel space, providing insights about adversarial vulnerabilities, image morphing, extrapolation, ambiguity in classification, and the mathematical understanding of image classification models.
Understanding Gender and Racial Disparities in Image Recognition Models
Jul 20, 2021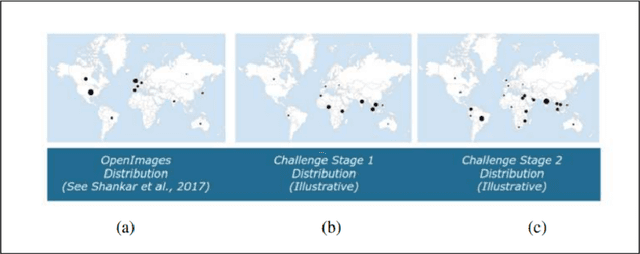
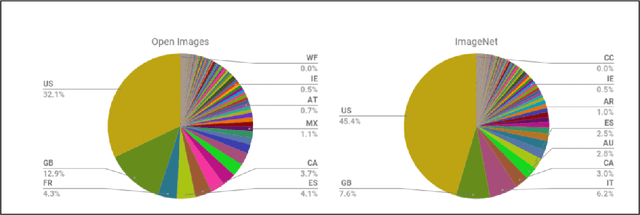


Large scale image classification models trained on top of popular datasets such as Imagenet have shown to have a distributional skew which leads to disparities in prediction accuracies across different subsections of population demographics. A lot of approaches have been made to solve for this distributional skew using methods that alter the model pre, post and during training. We investigate one such approach - which uses a multi-label softmax loss with cross-entropy as the loss function instead of a binary cross-entropy on a multi-label classification problem on the Inclusive Images dataset which is a subset of the OpenImages V6 dataset. We use the MR2 dataset, which contains images of people with self-identified gender and race attributes to evaluate the fairness in the model outcomes and try to interpret the mistakes by looking at model activations and suggest possible fixes.
Fast Eye Detector Using Metric Learning for Iris on The Move
Feb 22, 2022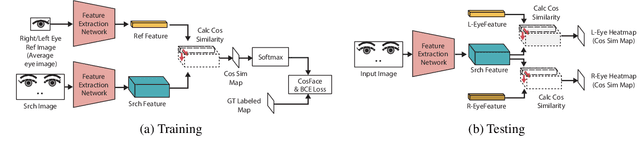


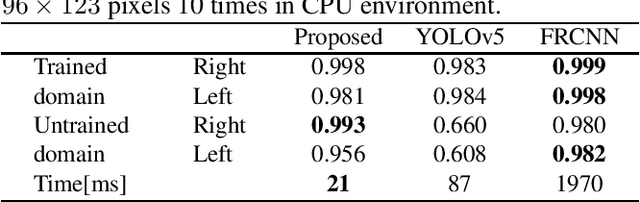
This paper proposes a fast eye detection method based on fully-convolutional Siamese networks for iris recognition. The iris on the move system requires to capture high resolution iris images from a moving subject for iris recognition. Therefore, capturing images contains both eyes at high-frame-rate increases the chance of iris imaging. In order to output the authentication result in real time, the system requires a fast eye detector extracting the left and right eye regions from the image. Our method extracts features of a partial face image and a reference eye image using Siamese network frameworks. Similarity heat maps of both eyes are created by calculating the spatial cosine similarity between extracted features. Besides, we use CosFace as a loss function for training to discriminate the left and right eyes with high accuracy even with a shallow network. Experimental results show that our method trained by CosFace is fast and accurate compared with conventional generic object detection methods.