 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sketches image analysis: Web image search engine usingLSH index and DNN InceptionV3
May 03, 2021
The adoption of an appropriate approximate similarity search method is an essential prereq-uisite for developing a fast and efficient CBIR system, especially when dealing with large amount ofdata. In this study we implement a web image search engine on top of a Locality Sensitive Hashing(LSH) Index to allow fast similarity search on deep features. Specifically, we exploit transfer learningfor deep features extraction from images. Firstly, we adopt InceptionV3 pretrained on ImageNet asfeatures extractor, secondly, we try out several CNNs built on top of InceptionV3 as convolutionalbase fine-tuned on our dataset. In both of the previous cases we index the features extracted within ourLSH index implementation so as to compare the retrieval performances with and without fine-tuning.In our approach we try out two different LSH implementations: the first one working with real numberfeature vectors and the second one with the binary transposed version of those vectors. Interestingly,we obtain the best performances when using the binary LSH, reaching almost the same result, in termsof mean average precision, obtained by performing sequential scan of the features, thus avoiding thebias introduced by the LSH index. Lastly, we carry out a performance analysis class by class in terms ofrecall againstmAPhighlighting, as expected, a strong positive correlation between the two.
Metric Learning based Interactive Modulation for Real-World Super-Resolution
May 10, 2022
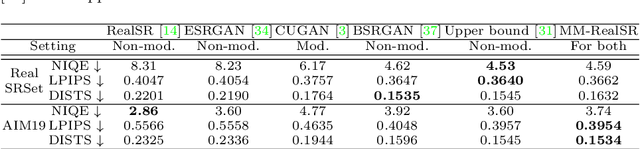
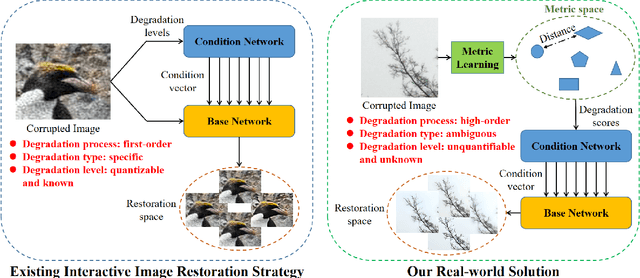

Interactive image restoration aims to restore images by adjusting several controlling coefficients, which determine the restoration strength. Existing methods are restricted in learning the controllable functions under the supervision of known degradation types and levels. They usually suffer from a severe performance drop when the real degradation is different from their assumptions. Such a limitation is due to the complexity of real-world degradations, which can not provide explicit supervision to the interactive modulation during training. However, how to realize the interactive modulation in real-world super-resolution has not yet been studied. In this work, we present a Metric Learning based Interactive Modulation for Real-World Super-Resolution (MM-RealSR). Specifically, we propose an unsupervised degradation estimation strategy to estimate the degradation level in real-world scenarios. Instead of using known degradation levels as explicit supervision to the interactive mechanism, we propose a metric learning strategy to map the unquantifiable degradation levels in real-world scenarios to a metric space, which is trained in an unsupervised manner. Moreover, we introduce an anchor point strategy in the metric learning process to normalize the distribution of metric space. Extensive experiments demonstrate that the proposed MM-RealSR achieves excellent modulation and restoration performance in real-world super-resolution. Codes are available at https://github.com/TencentARC/MM-RealSR.
Cancer image classification based on DenseNet model
Nov 23, 2020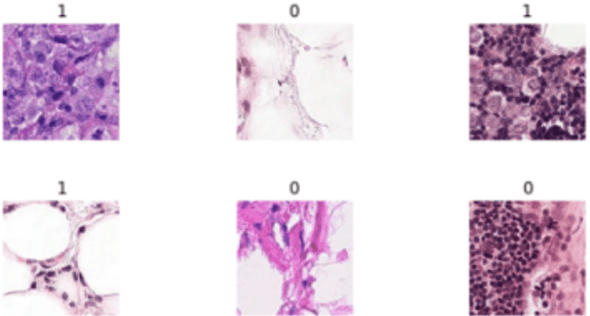
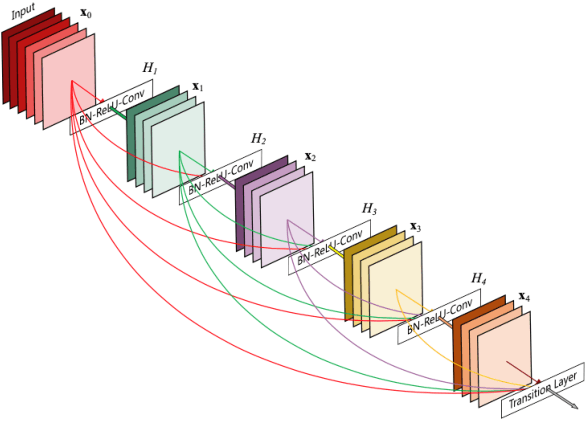
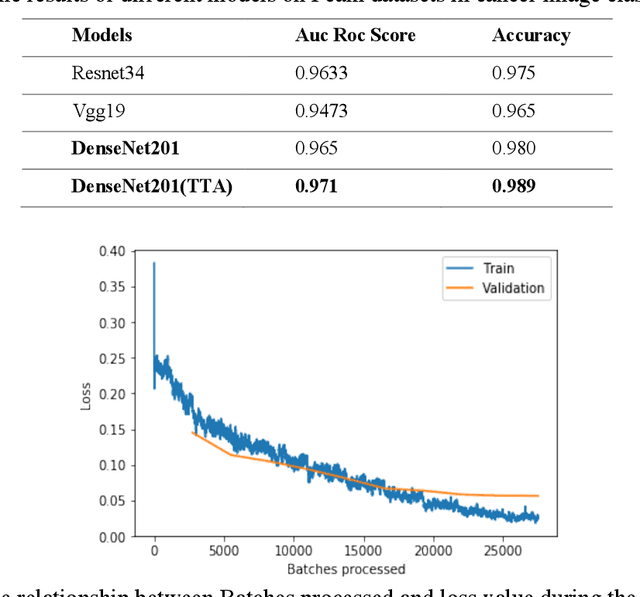
Computer-aided diagnosis establishes methods for robust assessment of medical image-based examination. Image processing introduced a promising strategy to facilitate disease classification and detection while diminishing unnecessary expenses. In this paper, we propose a novel metastatic cancer image classification model based on DenseNet Block, which can effectively identify metastatic cancer in small image patches taken from larger digital pathology scans. We evaluate the proposed approach to the slightly modified version of the PatchCamelyon (PCam) benchmark dataset. The dataset is the slightly modified version of the PatchCamelyon (PCam) benchmark dataset provided by Kaggle competition, which packs the clinically-relevant task of metastasis detection into a straight-forward binary image classification task. The experiments indicated that our model outperformed other classical methods like Resnet34, Vgg19. Moreover, we also conducted data augmentation experiment and study the relationship between Batches processed and loss value during the training and validation process.
CUAB: Convolutional Uncertainty Attention Block Enhanced the Chest X-ray Image Analysis
May 05, 2021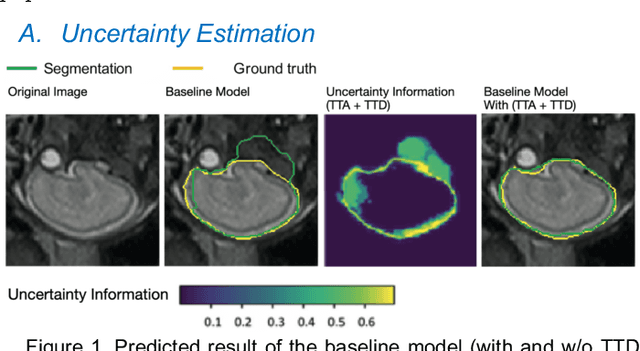
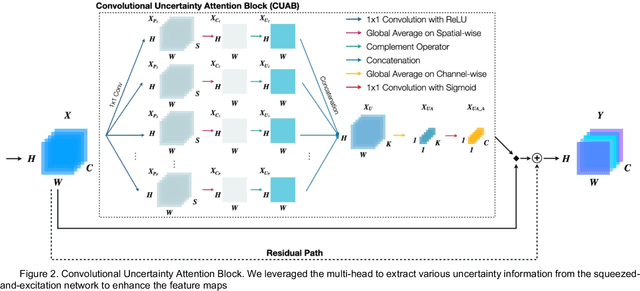
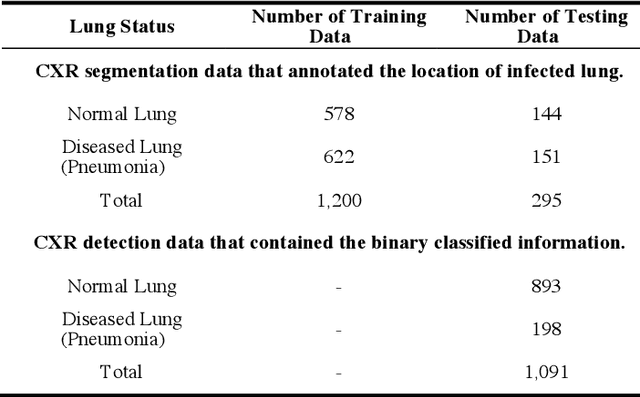
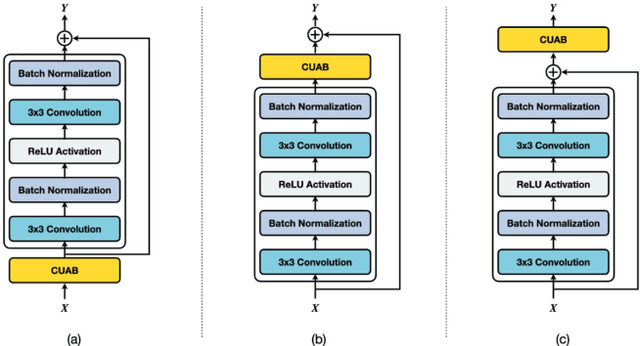
In recent years, convolutional neural networks (CNNs) have been successfully implemented to various image recognition applications, such as medical image analysis, object detection, and image segmentation. Many studies and applications have been working on improving the performance of CNN algorithms and models. The strategies that aim to improve the performance of CNNs can be grouped into three major approaches: (1) deeper and wider network architecture, (2) automatic architecture search, and (3) convolutional attention block. Unlike approaches (1) and (2), the convolutional attention block approach is more flexible with lower cost. It enhances the CNN performance by extracting more efficient features. However, the existing attention blocks focus on enhancing the significant features, which lose some potential features in the uncertainty information. Inspired by the test time augmentation and test-time dropout approaches, we developed a novel convolutional uncertainty attention block (CUAB) that can leverage the uncertainty information to improve CNN-based models. The proposed module discovers potential information from the uncertain regions on feature maps in computer vision tasks. It is a flexible functional attention block that can be applied to any position in the convolutional block in CNN models. We evaluated the CUAB with notable backbone models, ResNet and ResNeXt, on a medical image segmentation task. The CUAB achieved a dice score of 73% and 84% in pneumonia and pneumothorax segmentation, respectively, thereby outperforming the original model and other notable attention approaches. The results demonstrated that the CUAB can efficiently utilize the uncertainty information to improve the model performance.
Image Classifiers for Network Intrusions
Mar 13, 2021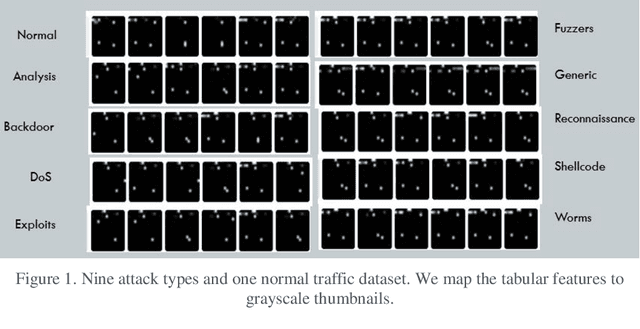
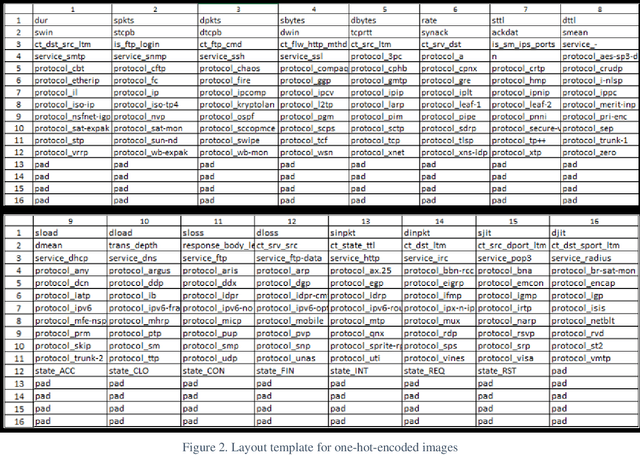
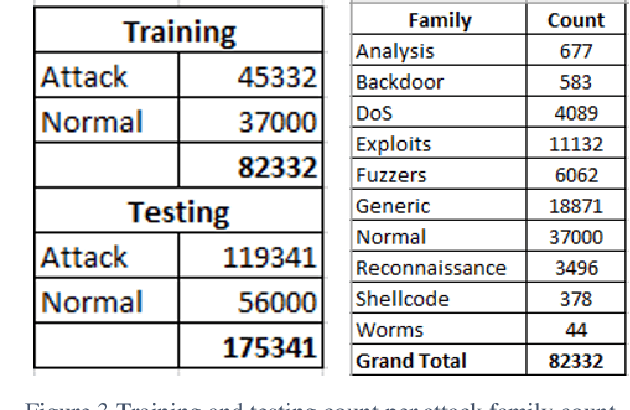
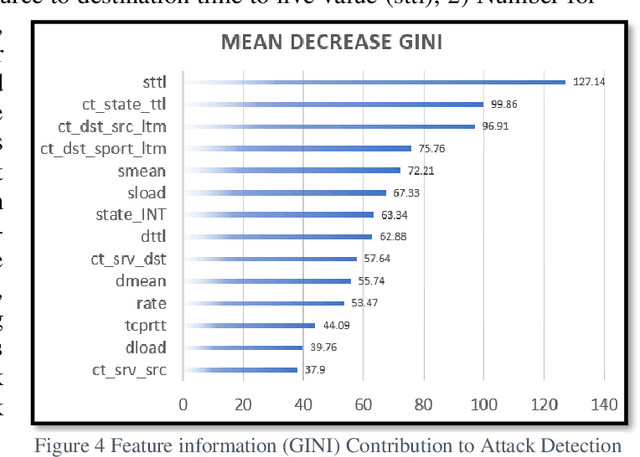
This research recasts the network attack dataset from UNSW-NB15 as an intrusion detection problem in image space. Using one-hot-encodings, the resulting grayscale thumbnails provide a quarter-million examples for deep learning algorithms. Applying the MobileNetV2's convolutional neural network architecture, the work demonstrates a 97% accuracy in distinguishing normal and attack traffic. Further class refinements to 9 individual attack families (exploits, worms, shellcodes) show an overall 56% accuracy. Using feature importance rank, a random forest solution on subsets show the most important source-destination factors and the least important ones as mainly obscure protocols. The dataset is available on Kaggle.
Is Geometry Enough for Matching in Visual Localization?
Mar 24, 2022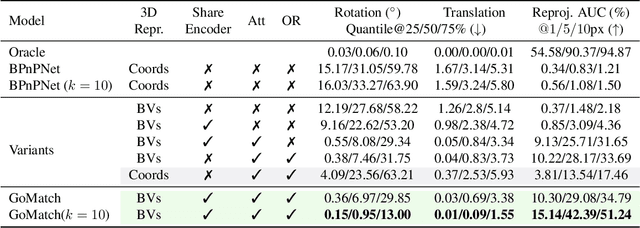
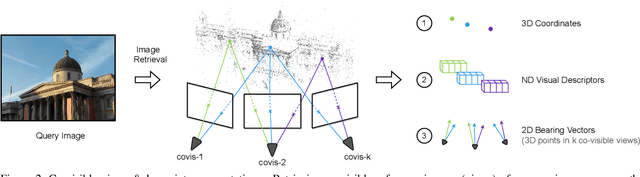
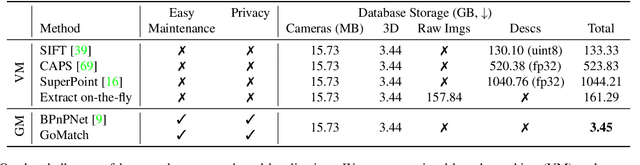
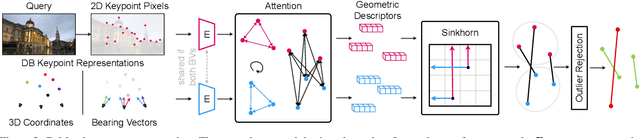
In this paper, we propose to go beyond the well-established approach to vision-based localization that relies on visual descriptor matching between a query image and a 3D point cloud. While matching keypoints via visual descriptors makes localization highly accurate, it has significant storage demands, raises privacy concerns and increases map maintenance complexity. To elegantly address those practical challenges for large-scale localization, we present GoMatch, an alternative to visual-based matching that solely relies on geometric information for matching image keypoints to maps, represented as sets of bearing vectors. Our novel bearing vectors representation of 3D points, significantly relieves the cross-domain challenge in geometric-based matching that prevented prior work to tackle localization in a realistic environment. With additional careful architecture design, GoMatch improves over prior geometric-based matching work with a reduction of ($10.67m, 95.7^{\circ}$) and ($1.43m$, $34.7^{\circ}$) in average median pose errors on Cambridge Landmarks and 7-Scenes, while requiring as little as $1.5/1.7\%$ of storage capacity in comparison to the best visual-based matching methods. This confirms its potential and feasibility for real-world localization and opens the door to future efforts in advancing city-scale visual localization methods that do not require storing visual descriptors.
Improving the Energy Efficiency and Robustness of tinyML Computer Vision using Log-Gradient Input Images
Mar 04, 2022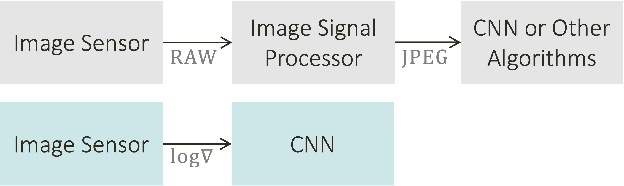
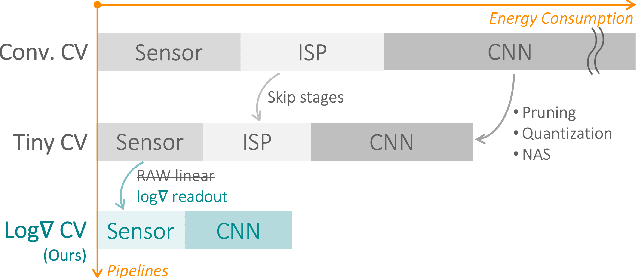
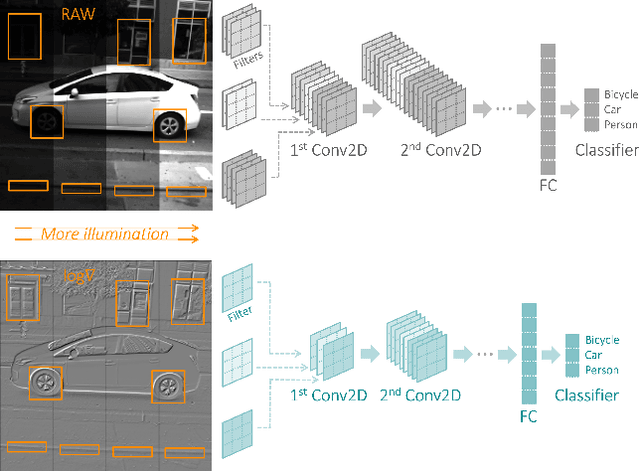

This paper studies the merits of applying log-gradient input images to convolutional neural networks (CNNs) for tinyML computer vision (CV). We show that log gradients enable: (i) aggressive 1.5-bit quantization of first-layer inputs, (ii) potential CNN resource reductions, and (iii) inherent robustness to illumination changes (1.7% accuracy loss across 1/32...8 brightness variation vs. up to 10% for JPEG). We establish these results using the PASCAL RAW image data set and through a combination of experiments using neural architecture search and a fixed three-layer network. The latter reveal that training on log-gradient images leads to higher filter similarity, making the CNN more prunable. The combined benefits of aggressive first-layer quantization, CNN resource reductions, and operation without tight exposure control and image signal processing (ISP) are helpful for pushing tinyML CV toward its ultimate efficiency limits.
Application of machine learning methods to detect and classify Core images using GAN and texture recognition
Apr 21, 2022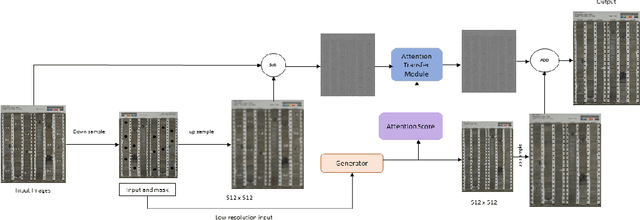

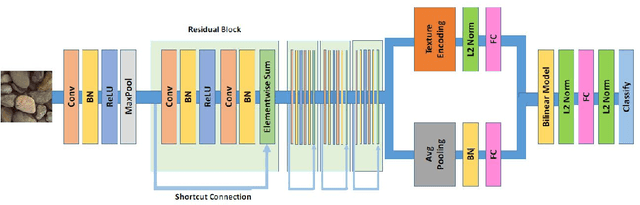
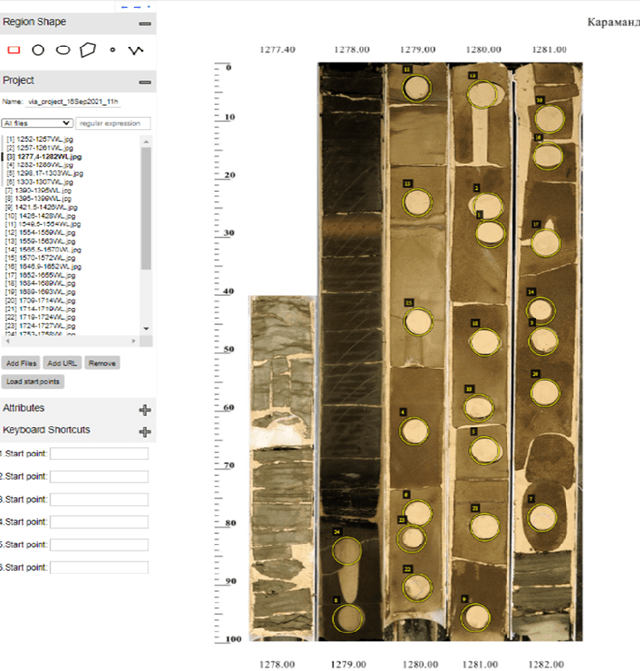
During exploration campaigns, oil companies rely heavily on drill core samples as they provide valuable geological information that helps them find important oil deposits. Traditional core logging techniques are laborious and subjective. Core imaging, a new technique in the oil industry, is used to supplement analysis by rapidly characterising large quantities of drill cores in a nondestructive and noninvasive manner. In this paper, we will present the problem of core detection and classification. The first problem is detecting the cores and segmenting the holes in images by using Faster RCNN and Mask RCNN models respectively. The second problem is filling the hole in the core image by applying the Generative adversarial network(GAN) technique and using Contextual Residual Aggregation(CRA) which creates high frequency residual for missing contents in images. And finally applying Texture recognition models for the classification of core images.
AIM 2020 Challenge on Image Extreme Inpainting
Oct 02, 2020
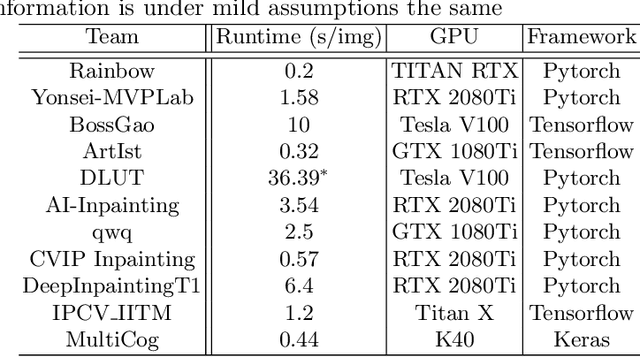
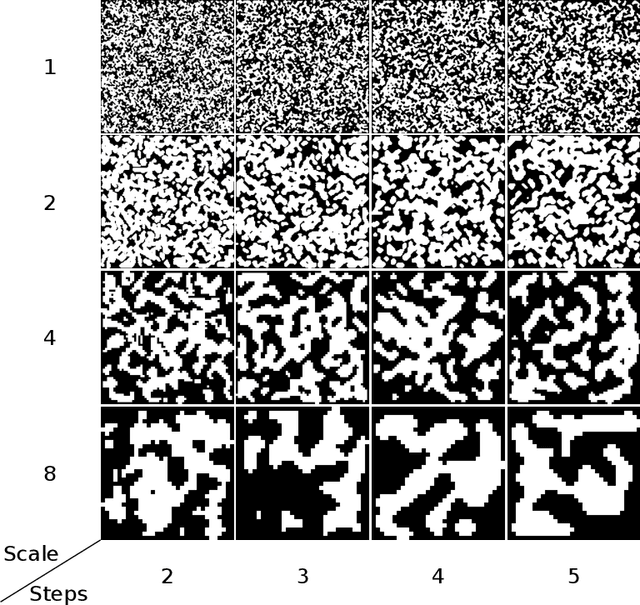
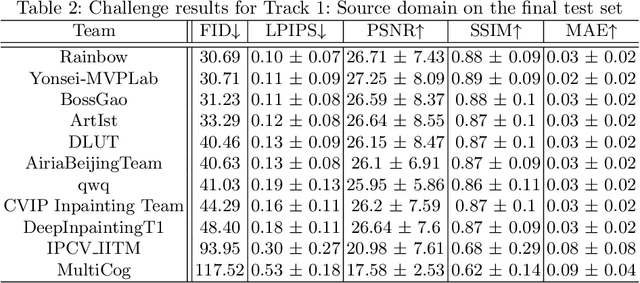
This paper reviews the AIM 2020 challenge on extreme image inpainting. This report focuses on proposed solutions and results for two different tracks on extreme image inpainting: classical image inpainting and semantically guided image inpainting. The goal of track 1 is to inpaint considerably large part of the image using no supervision but the context. Similarly, the goal of track 2 is to inpaint the image by having access to the entire semantic segmentation map of the image to inpaint. The challenge had 88 and 74 participants, respectively. 11 and 6 teams competed in the final phase of the challenge, respectively. This report gauges current solutions and set a benchmark for future extreme image inpainting methods.
CrossPoint: Self-Supervised Cross-Modal Contrastive Learning for 3D Point Cloud Understanding
Mar 24, 2022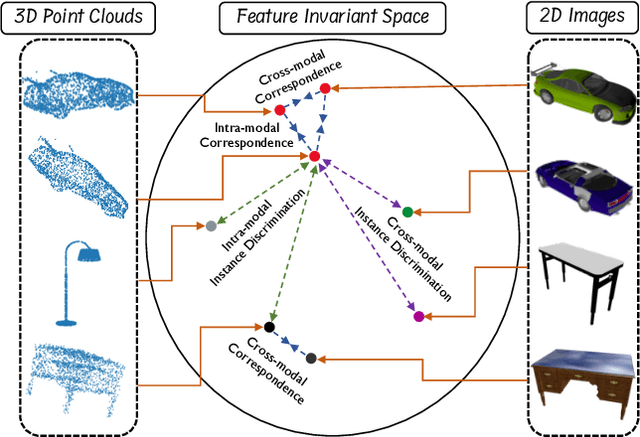
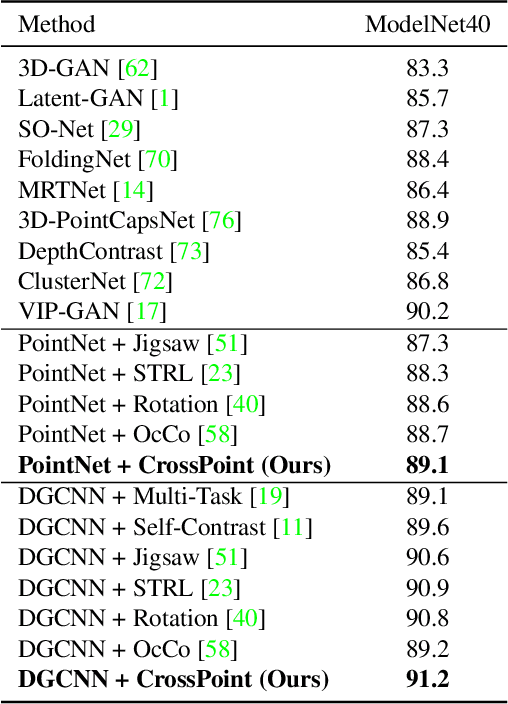
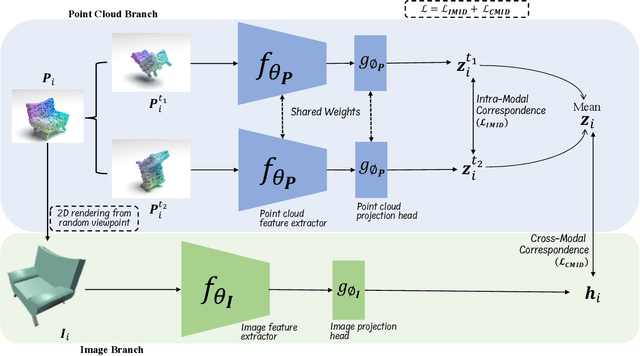
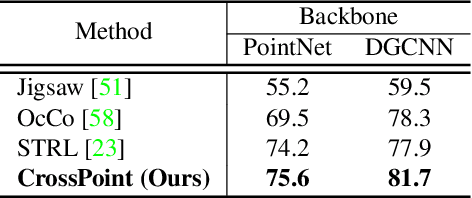
Manual annotation of large-scale point cloud dataset for varying tasks such as 3D object classification, segmentation and detection is often laborious owing to the irregular structure of point clouds. Self-supervised learning, which operates without any human labeling, is a promising approach to address this issue. We observe in the real world that humans are capable of mapping the visual concepts learnt from 2D images to understand the 3D world. Encouraged by this insight, we propose CrossPoint, a simple cross-modal contrastive learning approach to learn transferable 3D point cloud representations. It enables a 3D-2D correspondence of objects by maximizing agreement between point clouds and the corresponding rendered 2D image in the invariant space, while encouraging invariance to transformations in the point cloud modality. Our joint training objective combines the feature correspondences within and across modalities, thus ensembles a rich learning signal from both 3D point cloud and 2D image modalities in a self-supervised fashion. Experimental results show that our approach outperforms the previous unsupervised learning methods on a diverse range of downstream tasks including 3D object classification and segmentation. Further, the ablation studies validate the potency of our approach for a better point cloud understanding. Code and pretrained models are available at http://github.com/MohamedAfham/CrossPoint.