 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
QAIR: Practical Query-efficient Black-Box Attacks for Image Retrieval
Mar 23, 2021
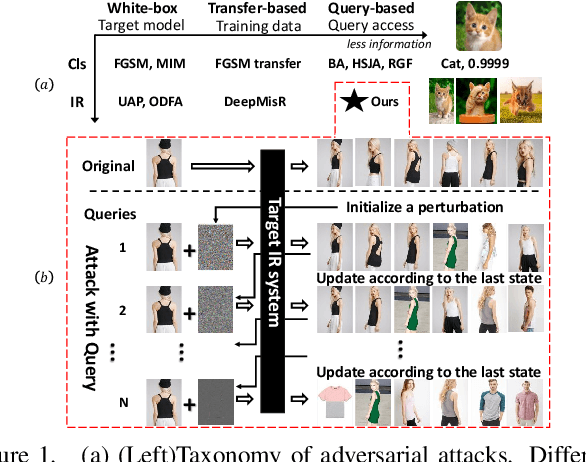
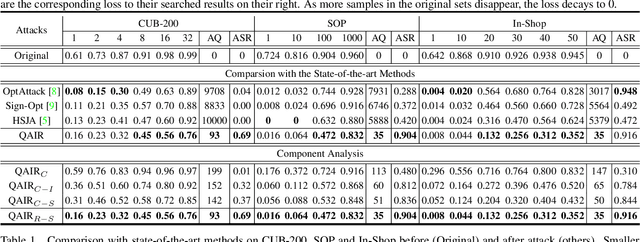
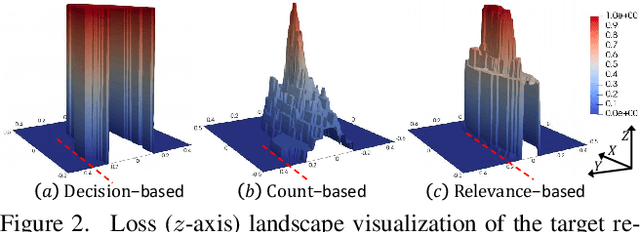
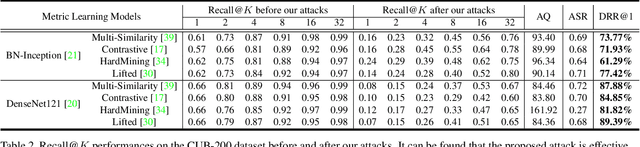
We study the query-based attack against image retrieval to evaluate its robustness against adversarial examples under the black-box setting, where the adversary only has query access to the top-k ranked unlabeled images from the database. Compared with query attacks in image classification, which produce adversaries according to the returned labels or confidence score, the challenge becomes even more prominent due to the difficulty in quantifying the attack effectiveness on the partial retrieved list. In this paper, we make the first attempt in Query-based Attack against Image Retrieval (QAIR), to completely subvert the top-k retrieval results. Specifically, a new relevance-based loss is designed to quantify the attack effects by measuring the set similarity on the top-k retrieval results before and after attacks and guide the gradient optimization. To further boost the attack efficiency, a recursive model stealing method is proposed to acquire transferable priors on the target model and generate the prior-guided gradients. Comprehensive experiments show that the proposed attack achieves a high attack success rate with few queries against the image retrieval systems under the black-box setting. The attack evaluations on the real-world visual search engine show that it successfully deceives a commercial system such as Bing Visual Search with 98% attack success rate by only 33 queries on average.
BBBD: Bounding Box Based Detector for Occlusion Detection and Order Recovery
Apr 27, 2022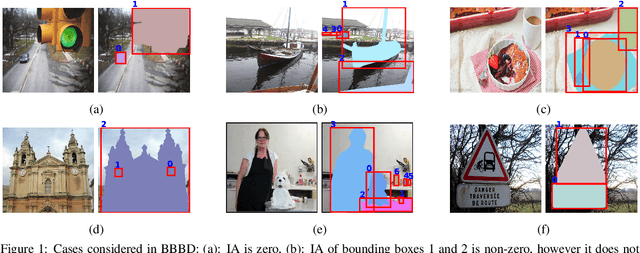
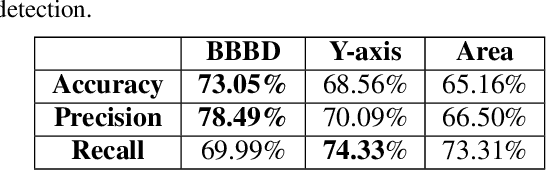
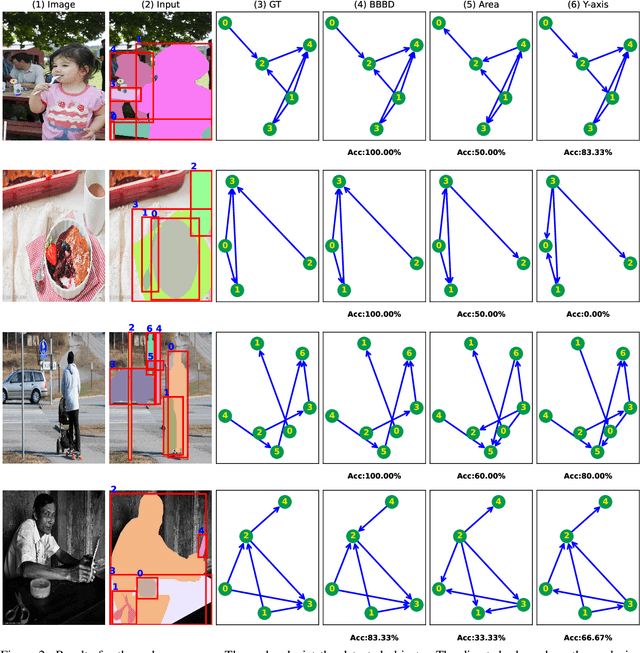
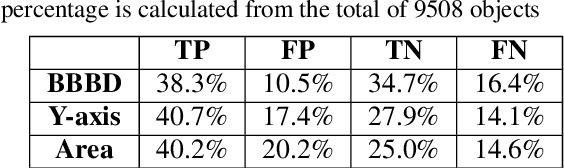
Occlusion handling is one of the challenges of object detection and segmentation, and scene understanding. Because objects appear differently when they are occluded in varying degree, angle, and locations. Therefore, determining the existence of occlusion between objects and their order in a scene is a fundamental requirement for semantic understanding. Existing works mostly use deep learning based models to retrieve the order of the instances in an image or for occlusion detection. This requires labelled occluded data and it is time consuming. In this paper, we propose a simpler and faster method that can perform both operations without any training and only requires the modal segmentation masks. For occlusion detection, instead of scanning the two objects entirely, we only focus on the intersected area between their bounding boxes. Similarly, we use the segmentation mask inside the same area to recover the depth-ordering. When tested on COCOA dataset, our method achieves +8% and +5% more accuracy than the baselines in order recovery and occlusion detection respectively.
* 7 pages, 4 figures
Adversarial Image Composition with Auxiliary Illumination
Sep 17, 2020
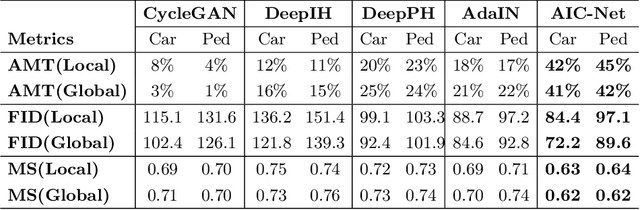
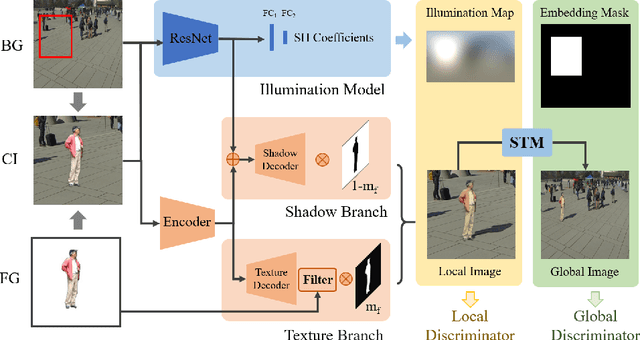
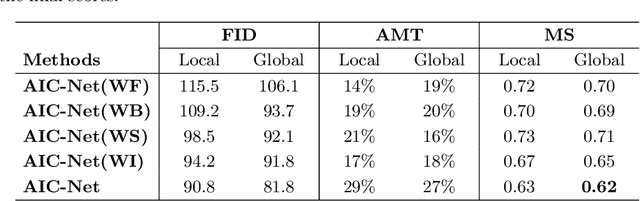
Dealing with the inconsistency between a foreground object and a background image is a challenging task in high-fidelity image composition. State-of-the-art methods strive to harmonize the composed image by adapting the style of foreground objects to be compatible with the background image, whereas the potential shadow of foreground objects within the composed image which is critical to the composition realism is largely neglected. In this paper, we propose an Adversarial Image Composition Net (AIC-Net) that achieves realistic image composition by considering potential shadows that the foreground object projects in the composed image. A novel branched generation mechanism is proposed, which disentangles the generation of shadows and the transfer of foreground styles for optimal accomplishment of the two tasks simultaneously. A differentiable spatial transformation module is designed which bridges the local harmonization and the global harmonization to achieve their joint optimization effectively. Extensive experiments on pedestrian and car composition tasks show that the proposed AIC-Net achieves superior composition performance qualitatively and quantitatively.
A Dempster-Shafer approach to trustworthy AI with application to fetal brain MRI segmentation
Apr 05, 2022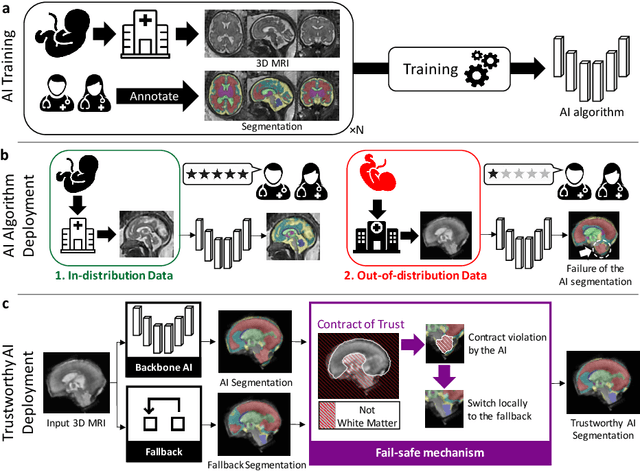
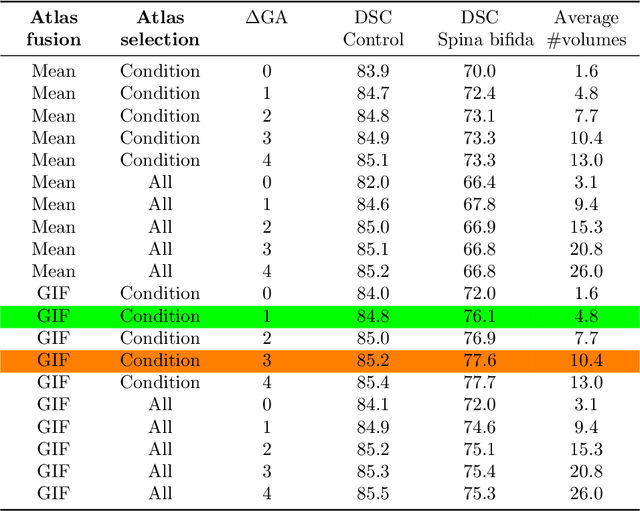
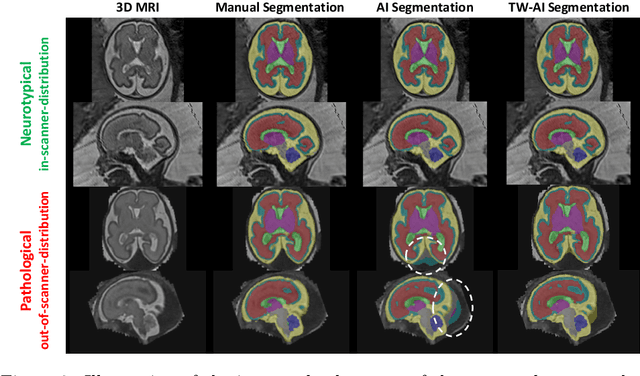
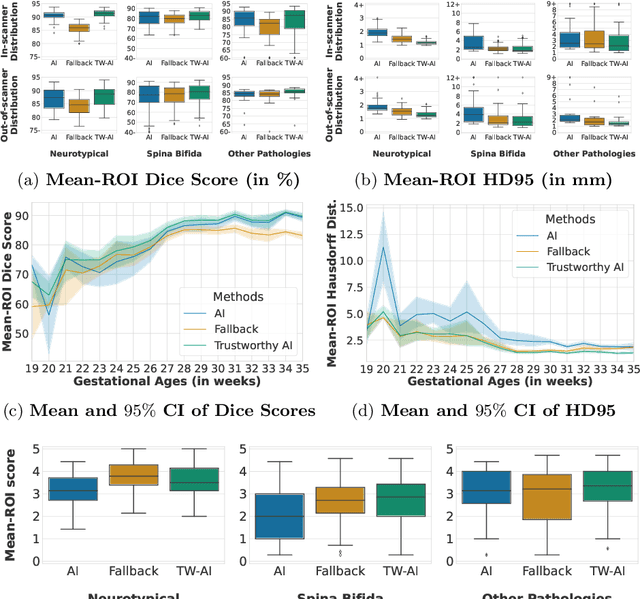
Deep learning models for medical image segmentation can fail unexpectedly and spectacularly for pathological cases and for images acquired at different centers than those used for training, with labeling errors that violate expert knowledge about the anatomy and the intensity distribution of the regions to be segmented. Such errors undermine the trustworthiness of deep learning models developed for medical image segmentation. Mechanisms with a fallback method for detecting and correcting such failures are essential for safely translating this technology into clinics and are likely to be a requirement of future regulations on artificial intelligence (AI). Here, we propose a principled trustworthy AI theoretical framework and a practical system that can augment any backbone AI system using a fallback method and a fail-safe mechanism based on Dempster-Shafer theory. Our approach relies on an actionable definition of trustworthy AI. Our method automatically discards the voxel-level labeling predicted by the backbone AI that are likely to violate expert knowledge and relies on a fallback atlas-based segmentation method for those voxels. We demonstrate the effectiveness of the proposed trustworthy AI approach on the largest reported annotated dataset of fetal T2w MRI consisting of 540 manually annotated fetal brain 3D MRIs with neurotypical or abnormal brain development and acquired from 13 sources of data across 6 countries. We show that our trustworthy AI method improves the robustness of a state-of-the-art backbone AI for fetal brain MRI segmentation on MRIs acquired across various centers and for fetuses with various brain abnormalities.
Image deblurring based on lightweight multi-information fusion network
Jan 14, 2021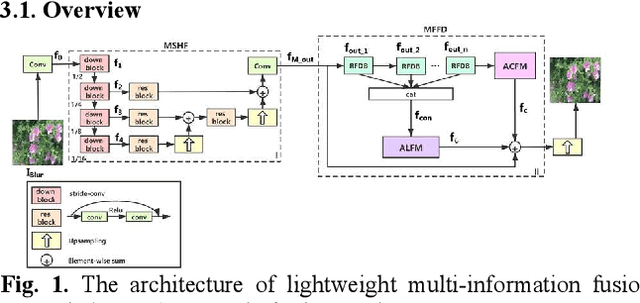
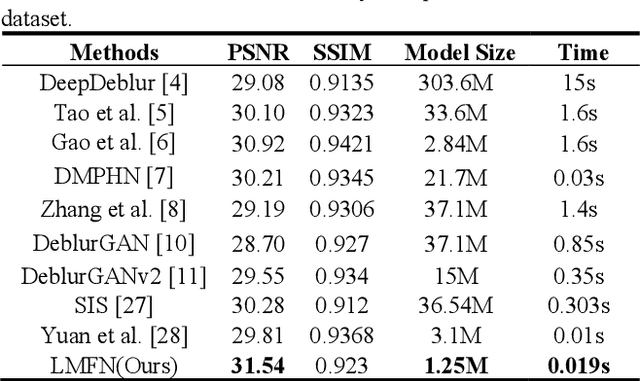
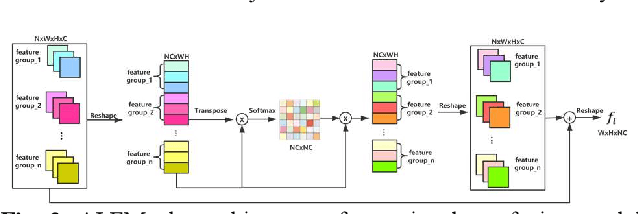

Recently, deep learning based image deblurring has been well developed. However, exploiting the detailed image features in a deep learning framework always requires a mass of parameters, which inevitably makes the network suffer from high computational burden. To solve this problem, we propose a lightweight multiinformation fusion network (LMFN) for image deblurring. The proposed LMFN is designed as an encoder-decoder architecture. In the encoding stage, the image feature is reduced to various smallscale spaces for multi-scale information extraction and fusion without a large amount of information loss. Then, a distillation network is used in the decoding stage, which allows the network benefit the most from residual learning while remaining sufficiently lightweight. Meanwhile, an information fusion strategy between distillation modules and feature channels is also carried out by attention mechanism. Through fusing different information in the proposed approach, our network can achieve state-of-the-art image deblurring result with smaller number of parameters and outperforms existing methods in model complexity.
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Feb 08, 2021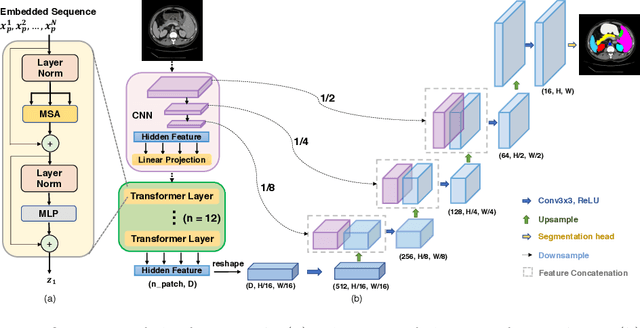
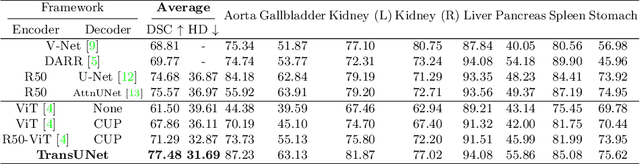
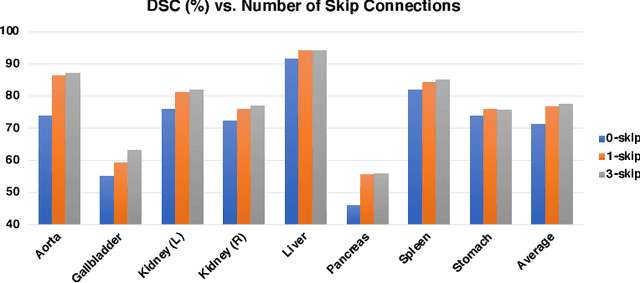

Medical image segmentation is an essential prerequisite for developing healthcare systems, especially for disease diagnosis and treatment planning. On various medical image segmentation tasks, the u-shaped architecture, also known as U-Net, has become the de-facto standard and achieved tremendous success. However, due to the intrinsic locality of convolution operations, U-Net generally demonstrates limitations in explicitly modeling long-range dependency. Transformers, designed for sequence-to-sequence prediction, have emerged as alternative architectures with innate global self-attention mechanisms, but can result in limited localization abilities due to insufficient low-level details. In this paper, we propose TransUNet, which merits both Transformers and U-Net, as a strong alternative for medical image segmentation. On one hand, the Transformer encodes tokenized image patches from a convolution neural network (CNN) feature map as the input sequence for extracting global contexts. On the other hand, the decoder upsamples the encoded features which are then combined with the high-resolution CNN feature maps to enable precise localization. We argue that Transformers can serve as strong encoders for medical image segmentation tasks, with the combination of U-Net to enhance finer details by recovering localized spatial information. TransUNet achieves superior performances to various competing methods on different medical applications including multi-organ segmentation and cardiac segmentation. Code and models are available at https://github.com/Beckschen/TransUNet.
RSINet: Inpainting Remotely Sensed Images Using Triple GAN Framework
Feb 12, 2022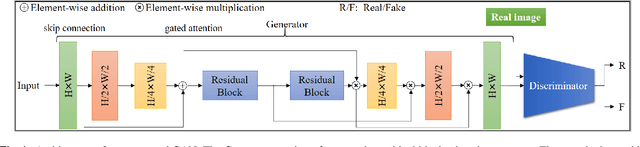
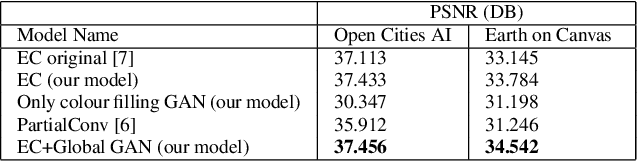
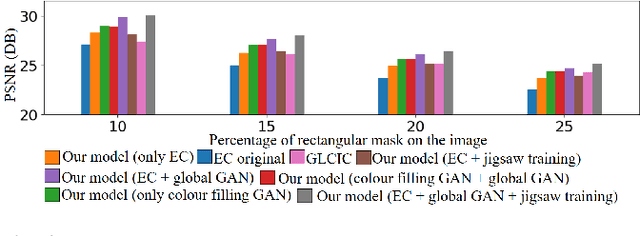

We tackle the problem of image inpainting in the remote sensing domain. Remote sensing images possess high resolution and geographical variations, that render the conventional inpainting methods less effective. This further entails the requirement of models with high complexity to sufficiently capture the spectral, spatial and textural nuances within an image, emerging from its high spatial variability. To this end, we propose a novel inpainting method that individually focuses on each aspect of an image such as edges, colour and texture using a task specific GAN. Moreover, each individual GAN also incorporates the attention mechanism that explicitly extracts the spectral and spatial features. To ensure consistent gradient flow, the model uses residual learning paradigm, thus simultaneously working with high and low level features. We evaluate our model, alongwith previous state of the art models, on the two well known remote sensing datasets, Open Cities AI and Earth on Canvas, and achieve competitive performance.
Case-based similar image retrieval for weakly annotated large histopathological images of malignant lymphoma using deep metric learning
Jul 08, 2021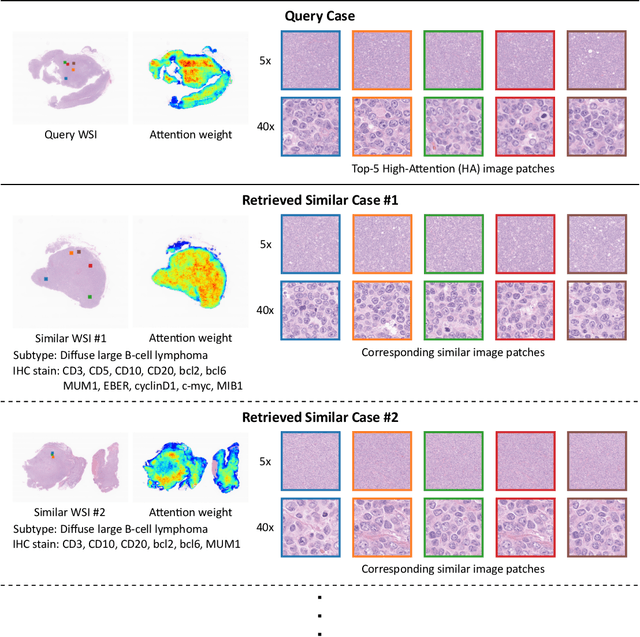
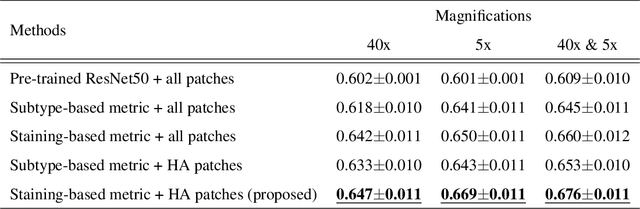
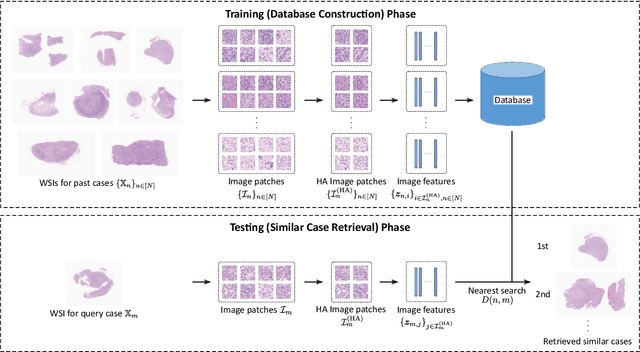
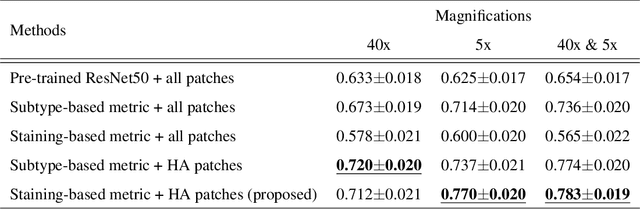
In the present study, we propose a novel case-based similar image retrieval (SIR) method for hematoxylin and eosin (H&E)-stained histopathological images of malignant lymphoma. When a whole slide image (WSI) is used as an input query, it is desirable to be able to retrieve similar cases by focusing on image patches in pathologically important regions such as tumor cells. To address this problem, we employ attention-based multiple instance learning, which enables us to focus on tumor-specific regions when the similarity between cases is computed. Moreover, we employ contrastive distance metric learning to incorporate immunohistochemical (IHC) staining patterns as useful supervised information for defining appropriate similarity between heterogeneous malignant lymphoma cases. In the experiment with 249 malignant lymphoma patients, we confirmed that the proposed method exhibited higher evaluation measures than the baseline case-based SIR methods. Furthermore, the subjective evaluation by pathologists revealed that our similarity measure using IHC staining patterns is appropriate for representing the similarity of H&E-stained tissue images for malignant lymphoma.
Multitask AET with Orthogonal Tangent Regularity for Dark Object Detection
May 06, 2022

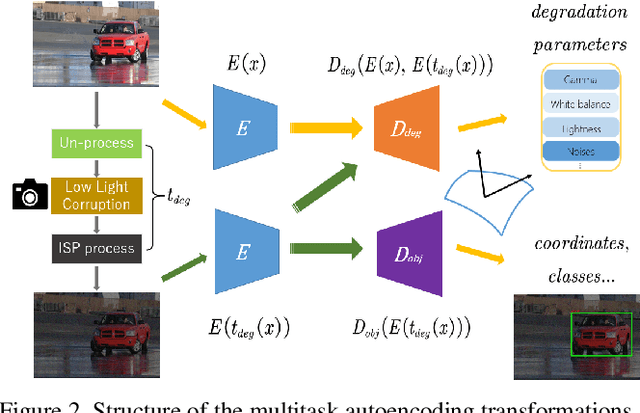

Dark environment becomes a challenge for computer vision algorithms owing to insufficient photons and undesirable noise. To enhance object detection in a dark environment, we propose a novel multitask auto encoding transformation (MAET) model which is able to explore the intrinsic pattern behind illumination translation. In a self-supervision manner, the MAET learns the intrinsic visual structure by encoding and decoding the realistic illumination-degrading transformation considering the physical noise model and image signal processing (ISP). Based on this representation, we achieve the object detection task by decoding the bounding box coordinates and classes. To avoid the over-entanglement of two tasks, our MAET disentangles the object and degrading features by imposing an orthogonal tangent regularity. This forms a parametric manifold along which multitask predictions can be geometrically formulated by maximizing the orthogonality between the tangents along the outputs of respective tasks. Our framework can be implemented based on the mainstream object detection architecture and directly trained end-to-end using normal target detection datasets, such as VOC and COCO. We have achieved the state-of-the-art performance using synthetic and real-world datasets. Code is available at https://github.com/cuiziteng/MAET.
Sketches image analysis: Web image search engine usingLSH index and DNN InceptionV3
May 03, 2021The adoption of an appropriate approximate similarity search method is an essential prereq-uisite for developing a fast and efficient CBIR system, especially when dealing with large amount ofdata. In this study we implement a web image search engine on top of a Locality Sensitive Hashing(LSH) Index to allow fast similarity search on deep features. Specifically, we exploit transfer learningfor deep features extraction from images. Firstly, we adopt InceptionV3 pretrained on ImageNet asfeatures extractor, secondly, we try out several CNNs built on top of InceptionV3 as convolutionalbase fine-tuned on our dataset. In both of the previous cases we index the features extracted within ourLSH index implementation so as to compare the retrieval performances with and without fine-tuning.In our approach we try out two different LSH implementations: the first one working with real numberfeature vectors and the second one with the binary transposed version of those vectors. Interestingly,we obtain the best performances when using the binary LSH, reaching almost the same result, in termsof mean average precision, obtained by performing sequential scan of the features, thus avoiding thebias introduced by the LSH index. Lastly, we carry out a performance analysis class by class in terms ofrecall againstmAPhighlighting, as expected, a strong positive correlation between the two.