 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Location-free Human Pose Estimation
May 25, 2022
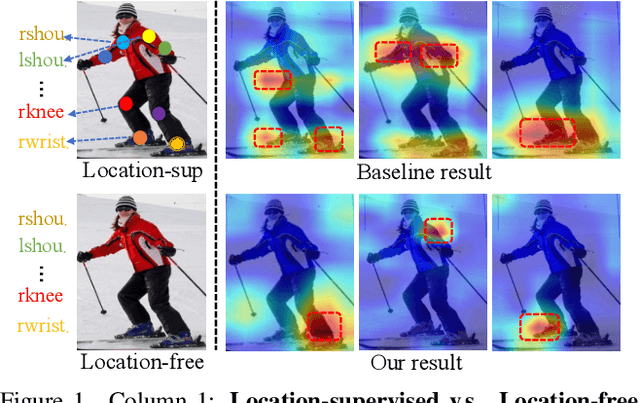
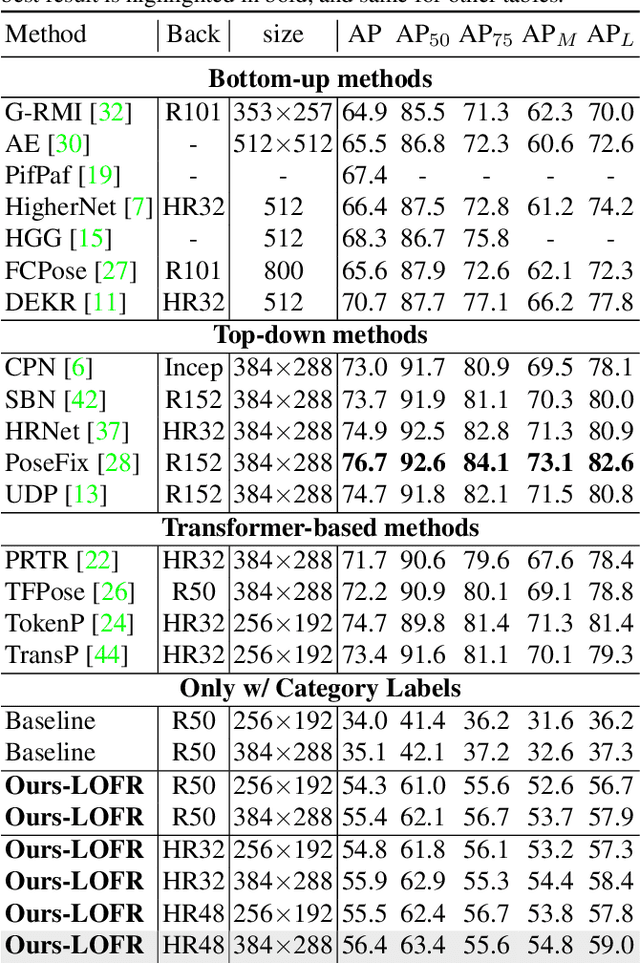
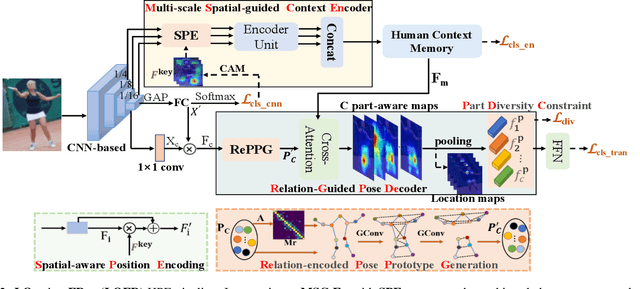
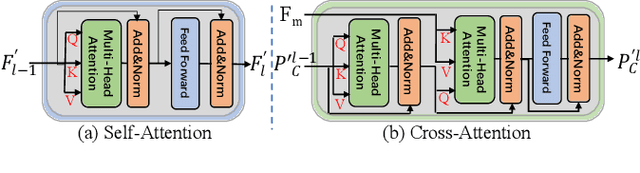
Human pose estimation (HPE) usually requires large-scale training data to reach high performance. However, it is rather time-consuming to collect high-quality and fine-grained annotations for human body. To alleviate this issue, we revisit HPE and propose a location-free framework without supervision of keypoint locations. We reformulate the regression-based HPE from the perspective of classification. Inspired by the CAM-based weakly-supervised object localization, we observe that the coarse keypoint locations can be acquired through the part-aware CAMs but unsatisfactory due to the gap between the fine-grained HPE and the object-level localization. To this end, we propose a customized transformer framework to mine the fine-grained representation of human context, equipped with the structural relation to capture subtle differences among keypoints. Concretely, we design a Multi-scale Spatial-guided Context Encoder to fully capture the global human context while focusing on the part-aware regions and a Relation-encoded Pose Prototype Generation module to encode the structural relations. All these works together for strengthening the weak supervision from image-level category labels on locations. Our model achieves competitive performance on three datasets when only supervised at a category-level and importantly, it can achieve comparable results with fully-supervised methods with only 25\% location labels on MS-COCO and MPII.
A Novel Framework for Characterization of Tumor-Immune Spatial Relationships in Tumor Microenvironment
Apr 27, 2022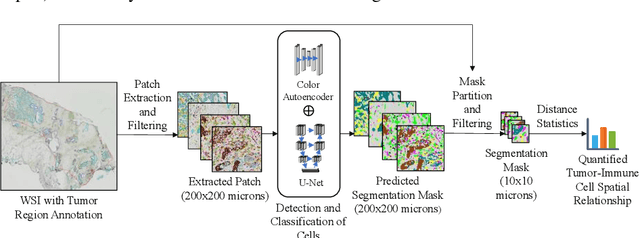

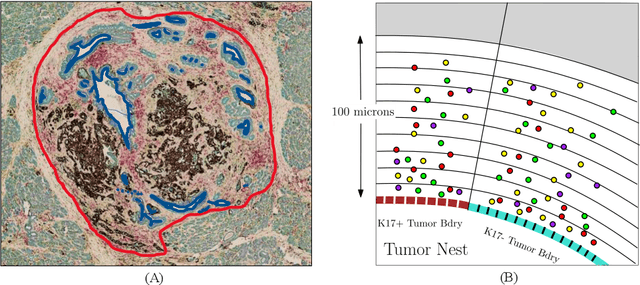
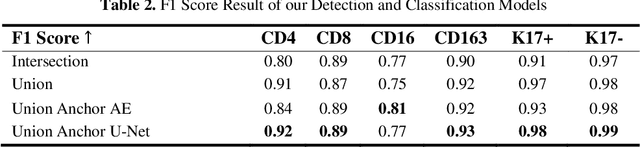
Understanding the impact of tumor biology on the composition of nearby cells often requires characterizing the impact of biologically distinct tumor regions. Biomarkers have been developed to label biologically distinct tumor regions, but challenges arise because of differences in the spatial extent and distribution of differentially labeled regions. In this work, we present a framework for systematically investigating the impact of distinct tumor regions on cells near the tumor borders, accounting their cross spatial distributions. We apply the framework to multiplex immunohistochemistry (mIHC) studies of pancreatic cancer and show its efficacy in demonstrating how biologically different tumor regions impact the immune response in the tumor microenvironment. Furthermore, we show that the proposed framework can be extended to largescale whole slide image analysis.
Behavioral Economics Approach to Interpretable Deep Image Classification. Rationally Inattentive Utility Maximization Explains Deep Image Classification
Feb 09, 2021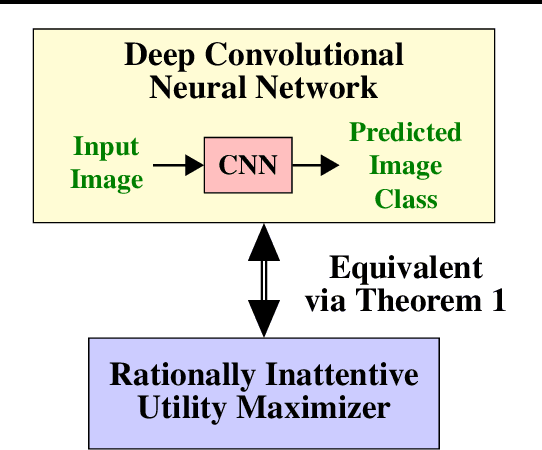

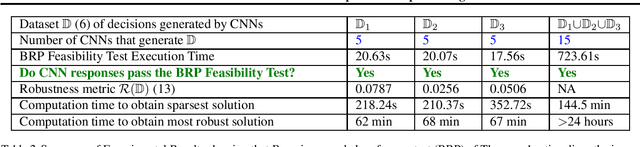
Are deep convolutional neural networks (CNNs) for image classification consistent with utility maximization behavior with information acquisition costs? This paper demonstrates the remarkable result that a deep CNN behaves equivalently (in terms of necessary and sufficient conditions) to a rationally inattentive utility maximizer, a model extensively used in behavioral economics to explain human decision making. This implies that a deep CNN has a parsimonious representation in terms of simple intuitive human-like decision parameters, namely, a utility function and an information acquisition cost. Also the reconstructed utility function that rationalizes the decisions of the deep CNNs, yields a useful preference order amongst the image classes (hypotheses).
Deep Image Harmonization by Bridging the Reality Gap
Mar 31, 2021
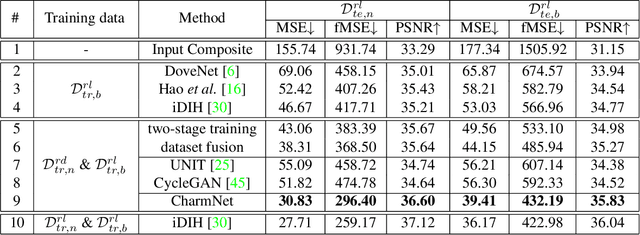
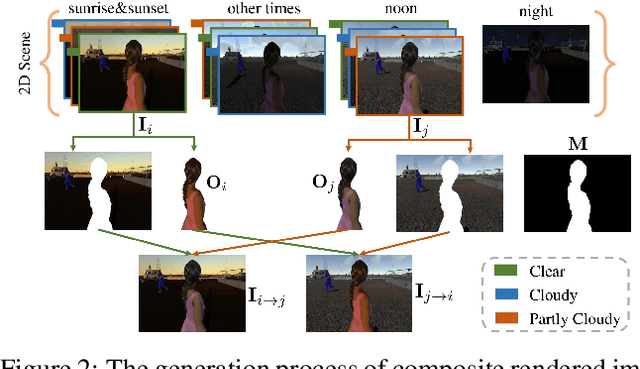
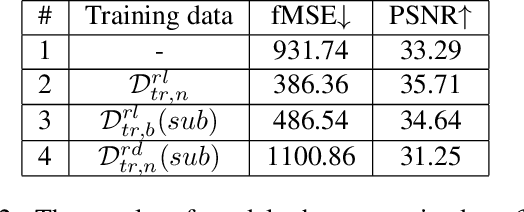
Image harmonization has been significantly advanced with large-scale harmonization dataset. However, the current way to build dataset is still labor-intensive, which adversely affects the extendability of dataset. To address this problem, we propose to construct a large-scale rendered harmonization dataset RHHarmony with fewer human efforts to augment the existing real-world dataset. To leverage both real-world images and rendered images, we propose a cross-domain harmonization network CharmNet to bridge the domain gap between two domains. Moreover, we also employ well-designed style classifiers and losses to facilitate cross-domain knowledge transfer. Extensive experiments demonstrate the potential of using rendered images for image harmonization and the effectiveness of our proposed network. Our dataset and code are available at https://github.com/bcmi/Rendered_Image_Harmonization_Datasets.
Can Open Domain Question Answering Systems Answer Visual Knowledge Questions?
Feb 09, 2022
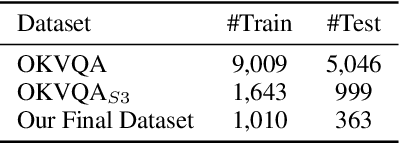

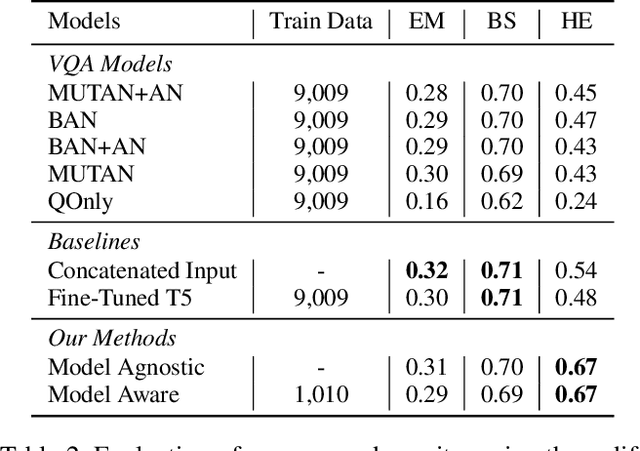
The task of Outside Knowledge Visual Question Answering (OKVQA) requires an automatic system to answer natural language questions about pictures and images using external knowledge. We observe that many visual questions, which contain deictic referential phrases referring to entities in the image, can be rewritten as "non-grounded" questions and can be answered by existing text-based question answering systems. This allows for the reuse of existing text-based Open Domain Question Answering (QA) Systems for visual question answering. In this work, we propose a potentially data-efficient approach that reuses existing systems for (a) image analysis, (b) question rewriting, and (c) text-based question answering to answer such visual questions. Given an image and a question pertaining to that image (a visual question), we first extract the entities present in the image using pre-trained object and scene classifiers. Using these detected entities, the visual questions can be rewritten so as to be answerable by open domain QA systems. We explore two rewriting strategies: (1) an unsupervised method using BERT for masking and rewriting, and (2) a weakly supervised approach that combines adaptive rewriting and reinforcement learning techniques to use the implicit feedback from the QA system. We test our strategies on the publicly available OKVQA dataset and obtain a competitive performance with state-of-the-art models while using only 10% of the training data.
OCR Synthetic Benchmark Dataset for Indic Languages
May 05, 2022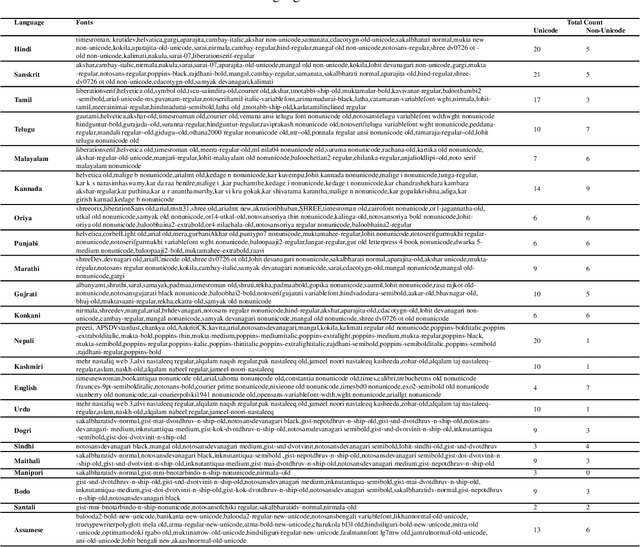
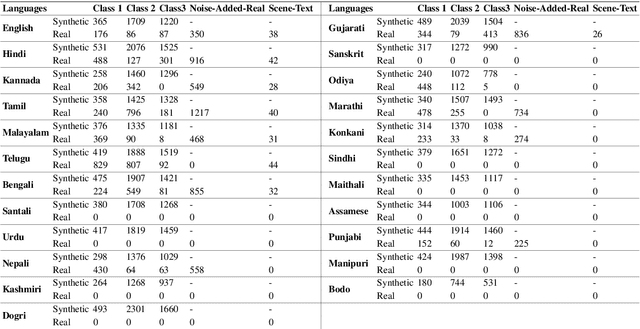
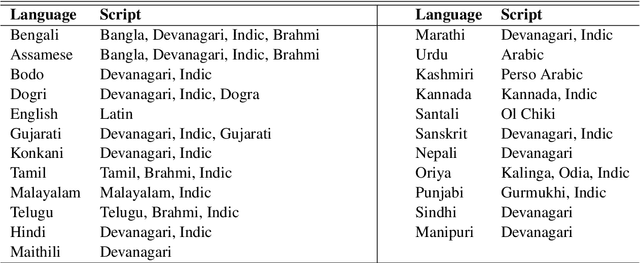
We present the largest publicly available synthetic OCR benchmark dataset for Indic languages. The collection contains a total of 90k images and their ground truth for 23 Indic languages. OCR model validation in Indic languages require a good amount of diverse data to be processed in order to create a robust and reliable model. Generating such a huge amount of data would be difficult otherwise but with synthetic data, it becomes far easier. It can be of great importance to fields like Computer Vision or Image Processing where once an initial synthetic data is developed, model creation becomes easier. Generating synthetic data comes with the flexibility to adjust its nature and environment as and when required in order to improve the performance of the model. Accuracy for labeled real-time data is sometimes quite expensive while accuracy for synthetic data can be easily achieved with a good score.
Repairing Group-Level Errors for DNNs Using Weighted Regularization
Apr 04, 2022
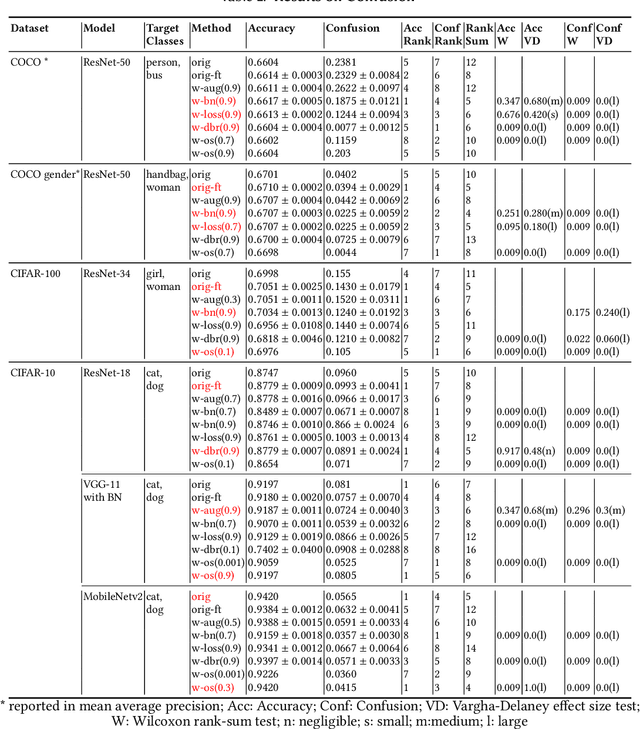
Deep Neural Networks (DNNs) have been widely used in software making decisions impacting people's lives. However, they have been found to exhibit severe erroneous behaviors that may lead to unfortunate outcomes. Previous work shows that such misbehaviors often occur due to class property violations rather than errors on a single image. Although methods for detecting such errors have been proposed, fixing them has not been studied so far. Here, we propose a generic method called Weighted Regularization (WR) consisting of five concrete methods targeting the error-producing classes to fix the DNNs. In particular, it can repair confusion error and bias error of DNN models for both single-label and multi-label image classifications. A confusion error happens when a given DNN model tends to confuse between two classes. Each method in WR assigns more weights at a stage of DNN retraining or inference to mitigate the confusion between target pair. A bias error can be fixed similarly. We evaluate and compare the proposed methods along with baselines on six widely-used datasets and architecture combinations. The results suggest that WR methods have different trade-offs but under each setting at least one WR method can greatly reduce confusion/bias errors at a very limited cost of the overall performance.
Reconstruction of Perceived Images from fMRI Patterns and Semantic Brain Exploration using Instance-Conditioned GANs
Feb 25, 2022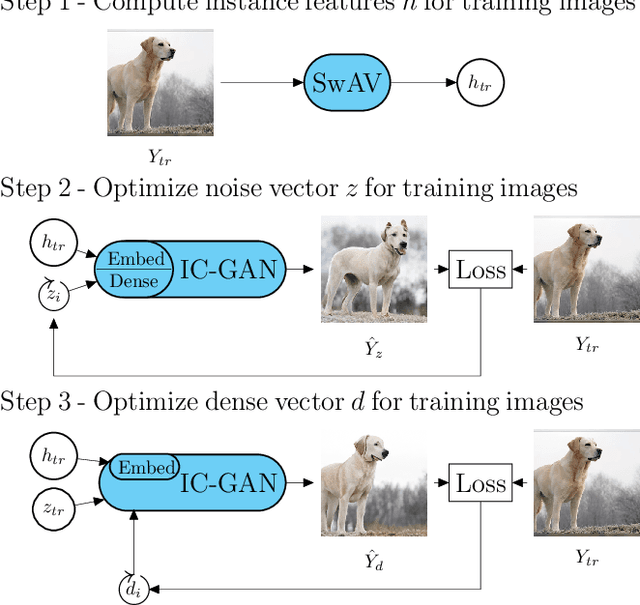
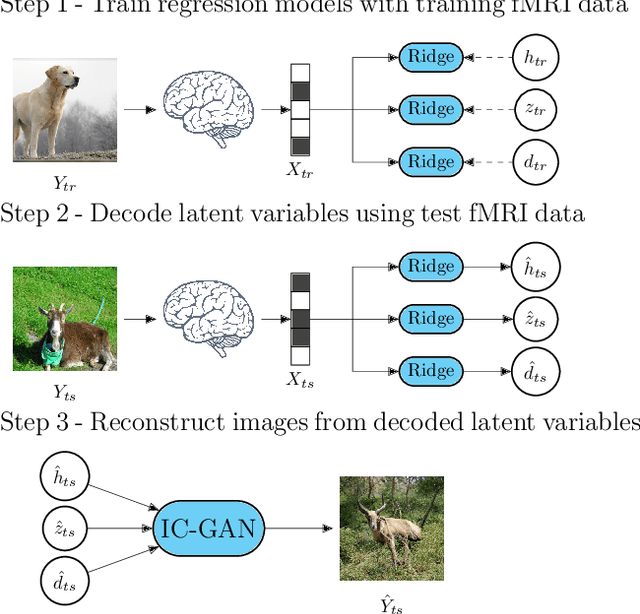
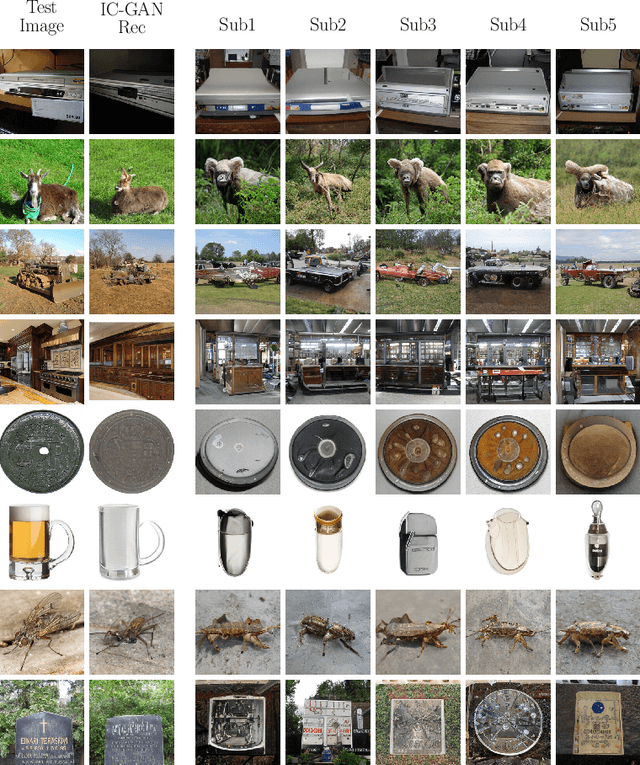

Reconstructing perceived natural images from fMRI signals is one of the most engaging topics of neural decoding research. Prior studies had success in reconstructing either the low-level image features or the semantic/high-level aspects, but rarely both. In this study, we utilized an Instance-Conditioned GAN (IC-GAN) model to reconstruct images from fMRI patterns with both accurate semantic attributes and preserved low-level details. The IC-GAN model takes as input a 119-dim noise vector and a 2048-dim instance feature vector extracted from a target image via a self-supervised learning model (SwAV ResNet-50); these instance features act as a conditioning for IC-GAN image generation, while the noise vector introduces variability between samples. We trained ridge regression models to predict instance features, noise vectors, and dense vectors (the output of the first dense layer of the IC-GAN generator) of stimuli from corresponding fMRI patterns. Then, we used the IC-GAN generator to reconstruct novel test images based on these fMRI-predicted variables. The generated images presented state-of-the-art results in terms of capturing the semantic attributes of the original test images while remaining relatively faithful to low-level image details. Finally, we use the learned regression model and the IC-GAN generator to systematically explore and visualize the semantic features that maximally drive each of several regions-of-interest in the human brain.
Image Classification in the Dark using Quanta Image Sensors
Jun 03, 2020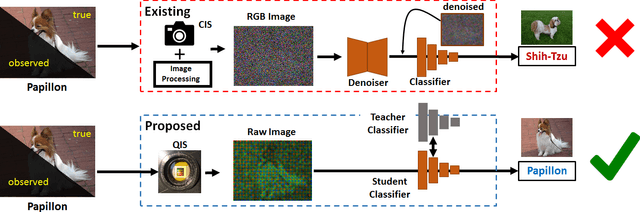
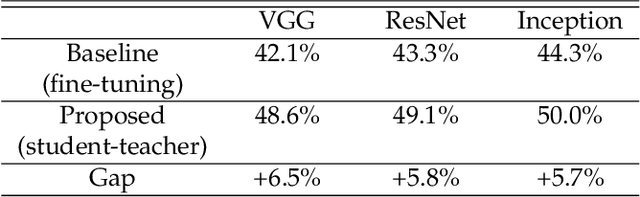

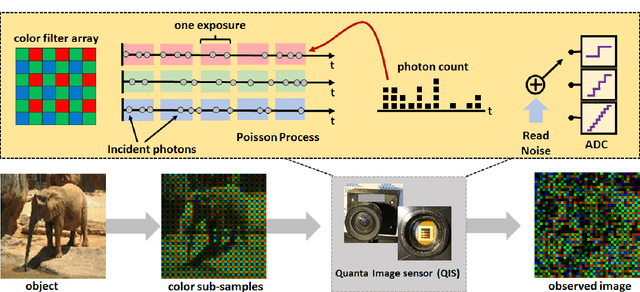
State-of-the-art image classifiers are trained and tested using well-illuminated images. These images are typically captured by CMOS image sensors with at least tens of photons per pixel. However, in dark environments when the photon flux is low, image classification becomes difficult because the measured signal is suppressed by noise. In this paper, we present a new low-light image classification solution using Quanta Image Sensors (QIS). QIS are a new type of image sensors that possess photon counting ability without compromising on pixel size and spatial resolution. Numerous studies over the past decade have demonstrated the feasibility of QIS for low-light imaging, but their usage for image classification has not been studied. This paper fills the gap by presenting a student-teacher learning scheme which allows us to classify the noisy QIS raw data. We show that with student-teacher learning, we are able to achieve image classification at a photon level of one photon per pixel or lower. Experimental results verify the effectiveness of the proposed method compared to existing solutions.
The Group Loss++: A deeper look into group loss for deep metric learning
Apr 04, 2022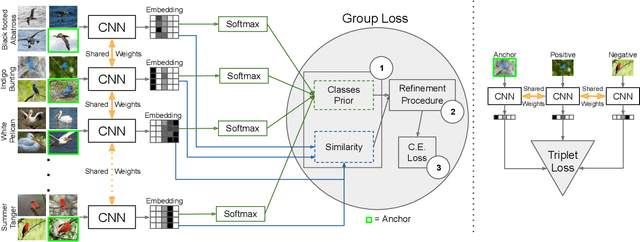
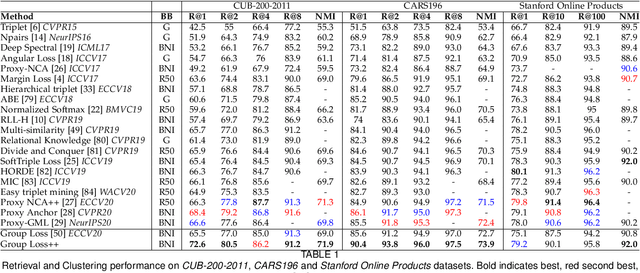
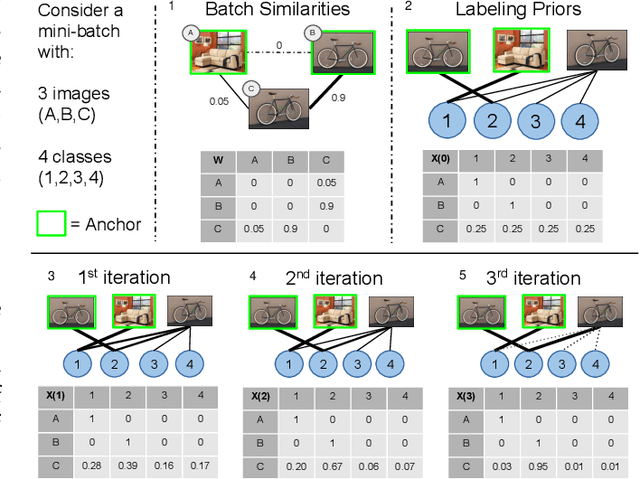
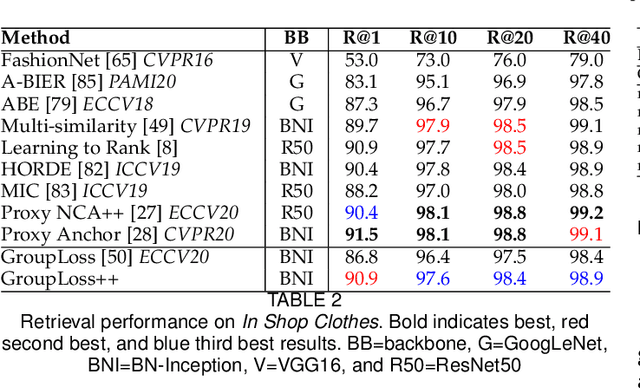
Deep metric learning has yielded impressive results in tasks such as clustering and image retrieval by leveraging neural networks to obtain highly discriminative feature embeddings, which can be used to group samples into different classes. Much research has been devoted to the design of smart loss functions or data mining strategies for training such networks. Most methods consider only pairs or triplets of samples within a mini-batch to compute the loss function, which is commonly based on the distance between embeddings. We propose Group Loss, a loss function based on a differentiable label-propagation method that enforces embedding similarity across all samples of a group while promoting, at the same time, low-density regions amongst data points belonging to different groups. Guided by the smoothness assumption that "similar objects should belong to the same group", the proposed loss trains the neural network for a classification task, enforcing a consistent labelling amongst samples within a class. We design a set of inference strategies tailored towards our algorithm, named Group Loss++ that further improve the results of our model. We show state-of-the-art results on clustering and image retrieval on four retrieval datasets, and present competitive results on two person re-identification datasets, providing a unified framework for retrieval and re-identification.