 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning to Deblur Polarized Images
Feb 28, 2024
A polarization camera can capture four polarized images with different polarizer angles in a single shot, which is useful in polarization-based vision applications since the degree of polarization (DoP) and the angle of polarization (AoP) can be directly computed from the captured polarized images. However, since the on-chip micro-polarizers block part of the light so that the sensor often requires a longer exposure time, the captured polarized images are prone to motion blur caused by camera shakes, leading to noticeable degradation in the computed DoP and AoP. Deblurring methods for conventional images often show degenerated performance when handling the polarized images since they only focus on deblurring without considering the polarization constrains. In this paper, we propose a polarized image deblurring pipeline to solve the problem in a polarization-aware manner by adopting a divide-and-conquer strategy to explicitly decompose the problem into two less ill-posed sub-problems, and design a two-stage neural network to handle the two sub-problems respectively. Experimental results show that our method achieves state-of-the-art performance on both synthetic and real-world images, and can improve the performance of polarization-based vision applications such as image dehazing and reflection removal.
Understanding the Role of Pathways in a Deep Neural Network
Feb 28, 2024Deep neural networks have demonstrated superior performance in artificial intelligence applications, but the opaqueness of their inner working mechanism is one major drawback in their application. The prevailing unit-based interpretation is a statistical observation of stimulus-response data, which fails to show a detailed internal process of inherent mechanisms of neural networks. In this work, we analyze a convolutional neural network (CNN) trained in the classification task and present an algorithm to extract the diffusion pathways of individual pixels to identify the locations of pixels in an input image associated with object classes. The pathways allow us to test the causal components which are important for classification and the pathway-based representations are clearly distinguishable between categories. We find that the few largest pathways of an individual pixel from an image tend to cross the feature maps in each layer that is important for classification. And the large pathways of images of the same category are more consistent in their trends than those of different categories. We also apply the pathways to understanding adversarial attacks, object completion, and movement perception. Further, the total number of pathways on feature maps in all layers can clearly discriminate the original, deformed, and target samples.
A Modular System for Enhanced Robustness of Multimedia Understanding Networks via Deep Parametric Estimation
Feb 29, 2024In multimedia understanding tasks, corrupted samples pose a critical challenge, because when fed to machine learning models they lead to performance degradation. In the past, three groups of approaches have been proposed to handle noisy data: i) enhancer and denoiser modules to improve the quality of the noisy data, ii) data augmentation approaches, and iii) domain adaptation strategies. All the aforementioned approaches come with drawbacks that limit their applicability; the first has high computational costs and requires pairs of clean-corrupted data for training, while the others only allow deployment of the same task/network they were trained on (\ie, when upstream and downstream task/network are the same). In this paper, we propose SyMPIE to solve these shortcomings. To this end, we design a small, modular, and efficient (just 2GFLOPs to process a Full HD image) system to enhance input data for robust downstream multimedia understanding with minimal computational cost. Our SyMPIE is pre-trained on an upstream task/network that should not match the downstream ones and does not need paired clean-corrupted samples. Our key insight is that most input corruptions found in real-world tasks can be modeled through global operations on color channels of images or spatial filters with small kernels. We validate our approach on multiple datasets and tasks, such as image classification (on ImageNetC, ImageNetC-Bar, VizWiz, and a newly proposed mixed corruption benchmark named ImageNetC-mixed) and semantic segmentation (on Cityscapes, ACDC, and DarkZurich) with consistent improvements of about 5\% relative accuracy gain across the board. The code of our approach and the new ImageNetC-mixed benchmark will be made available upon publication.
G4G:A Generic Framework for High Fidelity Talking Face Generation with Fine-grained Intra-modal Alignment
Mar 02, 2024Despite numerous completed studies, achieving high fidelity talking face generation with highly synchronized lip movements corresponding to arbitrary audio remains a significant challenge in the field. The shortcomings of published studies continue to confuse many researchers. This paper introduces G4G, a generic framework for high fidelity talking face generation with fine-grained intra-modal alignment. G4G can reenact the high fidelity of original video while producing highly synchronized lip movements regardless of given audio tones or volumes. The key to G4G's success is the use of a diagonal matrix to enhance the ordinary alignment of audio-image intra-modal features, which significantly increases the comparative learning between positive and negative samples. Additionally, a multi-scaled supervision module is introduced to comprehensively reenact the perceptional fidelity of original video across the facial region while emphasizing the synchronization of lip movements and the input audio. A fusion network is then used to further fuse the facial region and the rest. Our experimental results demonstrate significant achievements in reenactment of original video quality as well as highly synchronized talking lips. G4G is an outperforming generic framework that can produce talking videos competitively closer to ground truth level than current state-of-the-art methods.
DISORF: A Distributed Online NeRF Training and Rendering Framework for Mobile Robots
Mar 01, 2024

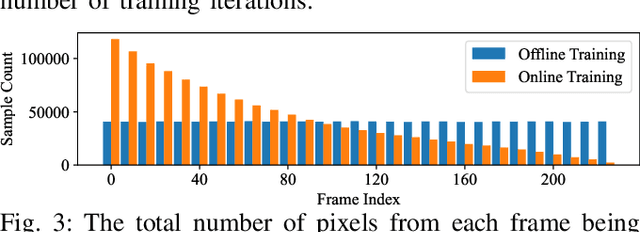
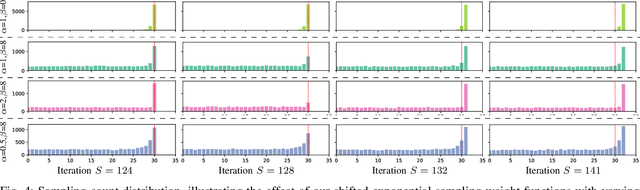
We present a framework, DISORF, to enable online 3D reconstruction and visualization of scenes captured by resource-constrained mobile robots and edge devices. To address the limited compute capabilities of edge devices and potentially limited network availability, we design a framework that efficiently distributes computation between the edge device and remote server. We leverage on-device SLAM systems to generate posed keyframes and transmit them to remote servers that can perform high quality 3D reconstruction and visualization at runtime by leveraging NeRF models. We identify a key challenge with online NeRF training where naive image sampling strategies can lead to significant degradation in rendering quality. We propose a novel shifted exponential frame sampling method that addresses this challenge for online NeRF training. We demonstrate the effectiveness of our framework in enabling high-quality real-time reconstruction and visualization of unknown scenes as they are captured and streamed from cameras in mobile robots and edge devices.
Phase retrieval beyond the homogeneous object assumption for X-ray in-line holographic imaging
Mar 01, 2024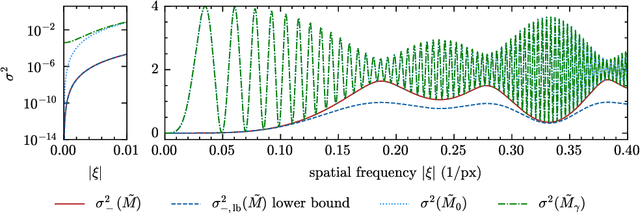



X-ray near field holography has proven to be a powerful 2D and 3D imaging technique with applications ranging from biomedical research to material sciences. To reconstruct meaningful and quantitative images from the measurement intensities, however, it relies on computational phase retrieval which in many cases assumes the phase-shift and attenuation coefficient of the sample to be proportional. Here, we demonstrate an efficient phase retrieval algorithm that does not rely on this homogeneous-object assumption and is a generalization of the well-established contrast-transfer-function (CTF) approach. We then investigate its stability and present an experimental study comparing the proposed algorithm with established methods. The algorithm shows superior reconstruction quality compared to the established CTF-based method at similar computational cost. Our analysis provides a deeper fundamental understanding of the homogeneous object assumption and the proposed algorithm will help improve the image quality for near-field holography in biomedical applications
Fine-Tuning Text-To-Image Diffusion Models for Class-Wise Spurious Feature Generation
Feb 13, 2024

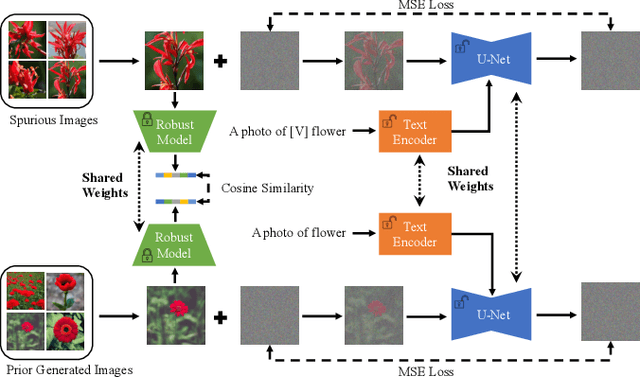
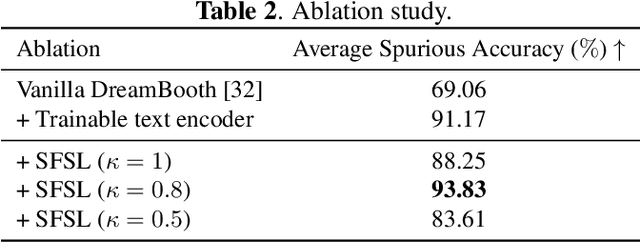
We propose a method for generating spurious features by leveraging large-scale text-to-image diffusion models. Although the previous work detects spurious features in a large-scale dataset like ImageNet and introduces Spurious ImageNet, we found that not all spurious images are spurious across different classifiers. Although spurious images help measure the reliance of a classifier, filtering many images from the Internet to find more spurious features is time-consuming. To this end, we utilize an existing approach of personalizing large-scale text-to-image diffusion models with available discovered spurious images and propose a new spurious feature similarity loss based on neural features of an adversarially robust model. Precisely, we fine-tune Stable Diffusion with several reference images from Spurious ImageNet with a modified objective incorporating the proposed spurious-feature similarity loss. Experiment results show that our method can generate spurious images that are consistently spurious across different classifiers. Moreover, the generated spurious images are visually similar to reference images from Spurious ImageNet.
Region-Aware Exposure Consistency Network for Mixed Exposure Correction
Feb 28, 2024Exposure correction aims to enhance images suffering from improper exposure to achieve satisfactory visual effects. Despite recent progress, existing methods generally mitigate either overexposure or underexposure in input images, and they still struggle to handle images with mixed exposure, i.e., one image incorporates both overexposed and underexposed regions. The mixed exposure distribution is non-uniform and leads to varying representation, which makes it challenging to address in a unified process. In this paper, we introduce an effective Region-aware Exposure Correction Network (RECNet) that can handle mixed exposure by adaptively learning and bridging different regional exposure representations. Specifically, to address the challenge posed by mixed exposure disparities, we develop a region-aware de-exposure module that effectively translates regional features of mixed exposure scenarios into an exposure-invariant feature space. Simultaneously, as de-exposure operation inevitably reduces discriminative information, we introduce a mixed-scale restoration unit that integrates exposure-invariant features and unprocessed features to recover local information. To further achieve a uniform exposure distribution in the global image, we propose an exposure contrastive regularization strategy under the constraints of intra-regional exposure consistency and inter-regional exposure continuity. Extensive experiments are conducted on various datasets, and the experimental results demonstrate the superiority and generalization of our proposed method. The code is released at: https://github.com/kravrolens/RECNet.
ClickSAM: Fine-tuning Segment Anything Model using click prompts for ultrasound image segmentation
Feb 14, 2024The newly released Segment Anything Model (SAM) is a popular tool used in image processing due to its superior segmentation accuracy, variety of input prompts, training capabilities, and efficient model design. However, its current model is trained on a diverse dataset not tailored to medical images, particularly ultrasound images. Ultrasound images tend to have a lot of noise, making it difficult to segment out important structures. In this project, we developed ClickSAM, which fine-tunes the Segment Anything Model using click prompts for ultrasound images. ClickSAM has two stages of training: the first stage is trained on single-click prompts centered in the ground-truth contours, and the second stage focuses on improving the model performance through additional positive and negative click prompts. By comparing the first stage predictions to the ground-truth masks, true positive, false positive, and false negative segments are calculated. Positive clicks are generated using the true positive and false negative segments, and negative clicks are generated using the false positive segments. The Centroidal Voronoi Tessellation algorithm is then employed to collect positive and negative click prompts in each segment that are used to enhance the model performance during the second stage of training. With click-train methods, ClickSAM exhibits superior performance compared to other existing models for ultrasound image segmentation.
Hand Shape and Gesture Recognition using Multiscale Template Matching, Background Subtraction and Binary Image Analysis
Feb 15, 2024This paper presents a hand shape classification approach employing multiscale template matching. The integration of background subtraction is utilized to derive a binary image of the hand object, enabling the extraction of key features such as centroid and bounding box. The methodology, while simple, demonstrates effectiveness in basic hand shape classification tasks, laying the foundation for potential applications in straightforward human-computer interaction scenarios. Experimental results highlight the system's capability in controlled environments.