 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Crossing-Domain Generative Adversarial Networks for Unsupervised Multi-Domain Image-to-Image Translation
Aug 27, 2020
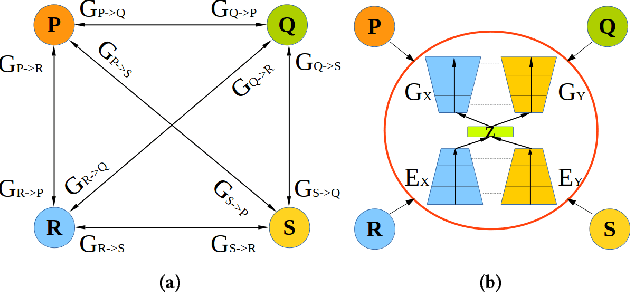
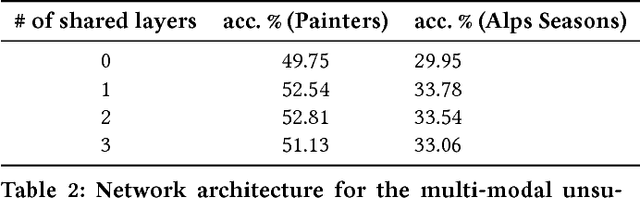
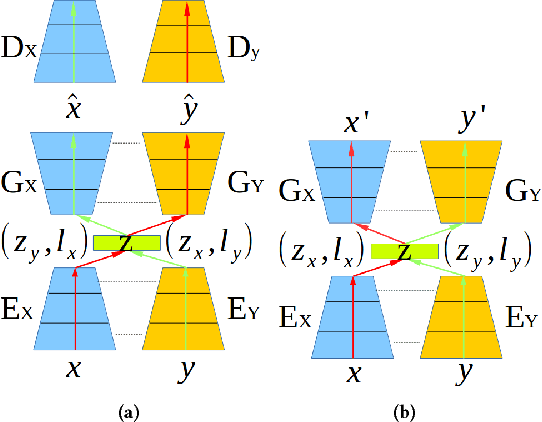
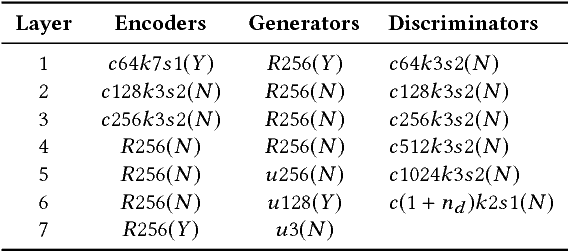
State-of-the-art techniques in Generative Adversarial Networks (GANs) have shown remarkable success in image-to-image translation from peer domain X to domain Y using paired image data. However, obtaining abundant paired data is a non-trivial and expensive process in the majority of applications. When there is a need to translate images across n domains, if the training is performed between every two domains, the complexity of the training will increase quadratically. Moreover, training with data from two domains only at a time cannot benefit from data of other domains, which prevents the extraction of more useful features and hinders the progress of this research area. In this work, we propose a general framework for unsupervised image-to-image translation across multiple domains, which can translate images from domain X to any a domain without requiring direct training between the two domains involved in image translation. A byproduct of the framework is the reduction of computing time and computing resources, since it needs less time than training the domains in pairs as is done in state-of-the-art works. Our proposed framework consists of a pair of encoders along with a pair of GANs which learns high-level features across different domains to generate diverse and realistic samples from. Our framework shows competing results on many image-to-image tasks compared with state-of-the-art techniques.
Time-series image denoising of pressure-sensitive paint data by projected multivariate singular spectrum analysis
Mar 15, 2022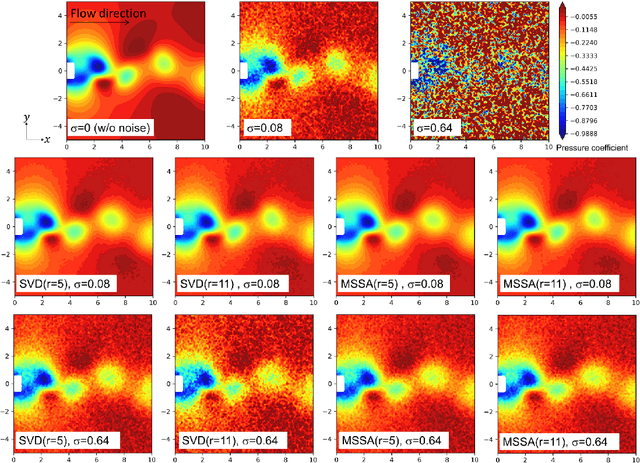
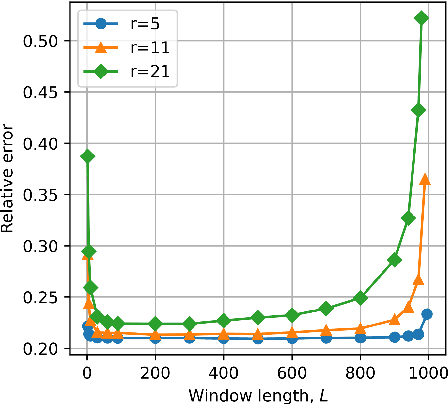
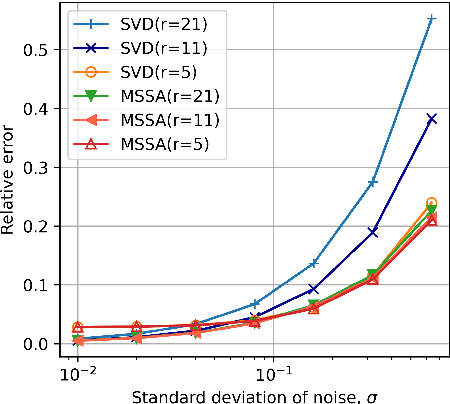
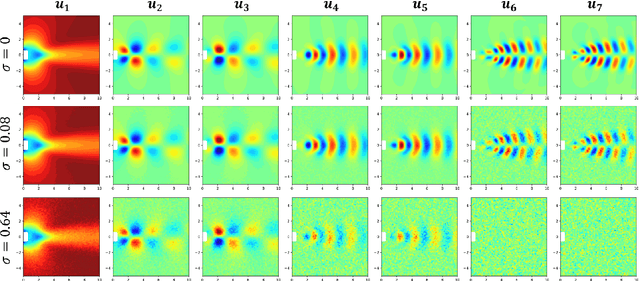
Time-series data, such as unsteady pressure-sensitive paint (PSP) measurement data, may contain a significant amount of random noise. Thus, in this study, we investigated a noise-reduction method that combines multivariate singular spectrum analysis (MSSA) with low-dimensional data representation. MSSA is a state-space reconstruction technique that utilizes time-delay embedding, and the low-dimensional representation is achieved by projecting data onto the singular value decomposition (SVD) basis. The noise-reduction performance of the proposed method for unsteady PSP data, i.e., the projected MSSA, is compared with that of the truncated SVD method, one of the most employed noise-reduction methods. The result shows that the projected MSSA exhibits better performance in reducing random noise than the truncated SVD method. Additionally, in contrast to that of the truncated SVD method, the performance of the projected MSSA is less sensitive to the truncation rank. Furthermore, the projected MSSA achieves denoising effectively by extracting smooth trajectories in a state space from noisy input data. Expectedly, the projected MSSA will be effective for reducing random noise in not only PSP measurement data, but also various high-dimensional time-series data.
A Novel Local Binary Pattern Based Blind Feature Image Steganography
Jan 16, 2021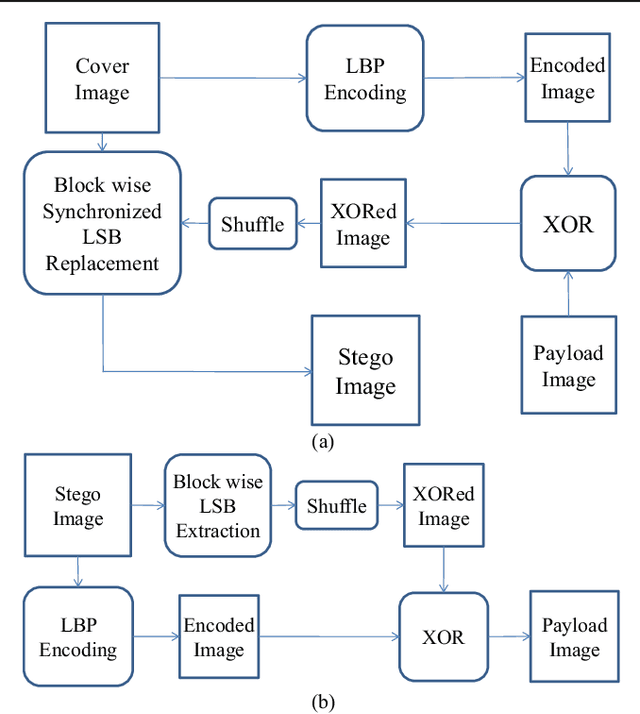
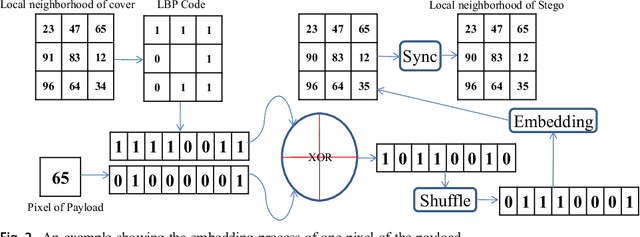
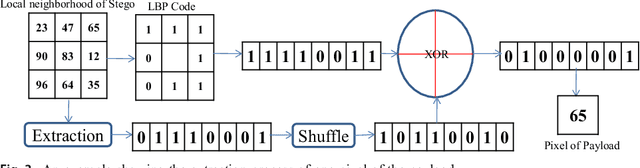
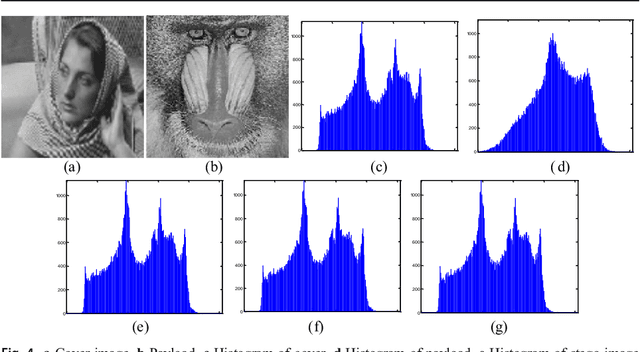
Steganography methods in general terms tend to embed more and more secret bits in the cover images. Most of these methods are designed to embed secret information in such a way that the change in the visual quality of the resulting stego image is not detectable. There exists some methods which preserve the global structure of the cover after embedding. However, the embedding capacity of these methods is very less. In this paper a novel feature based blind image steganography technique is proposed, which preserves the LBP (Local binary pattern) feature of the cover with comparable embedding rates. Local binary pattern is a well known image descriptor used for image representation. The proposed scheme computes the local binary pattern to hide the bits of the secret image in such a way that the local relationship that exists in the cover are preserved in the resulting stego image. The performance of the proposed steganography method has been tested on several images of different types to show the robustness. State of the art LSB based steganography methods are compared with the proposed method to show the effectiveness of feature based image steganography
Signature and Log-signature for the Study of Empirical Distributions Generated with GANs
Mar 12, 2022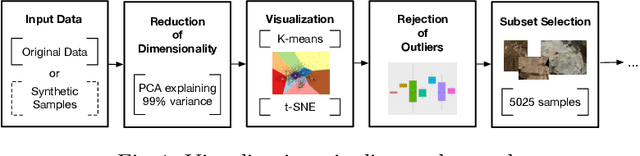


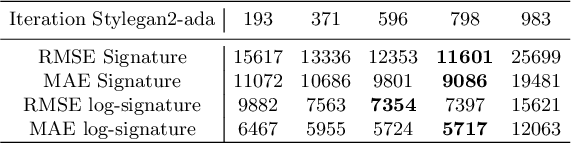
In this paper, we develop a new and systematic method to explore and analyze samples taken by NASA Perseverance on the surface of the planet Mars. A novel in this context PCA adaptive t-SNE is proposed, as well as the introduction of statistical measures to study the goodness of fit of the sample distribution. We go beyond visualization by generating synthetic imagery using Stylegan2-ADA that resemble the original terrain distribution. We also conduct synthetic image generation using the recently introduced Scored-based Generative Modeling. We bring forward the use of the recently developed Signature Transform as a way to measure the similarity between image distributions and provide detailed acquaintance and extensive evaluations. We are the first to pioneer RMSE and MAE Signature and log-signature as an alternative to measure GAN convergence. Insights on state-of-the-art instance segmentation of the samples by the use of a model DeepLabv3 are also given.
Image Classifiers for Network Intrusions
Mar 13, 2021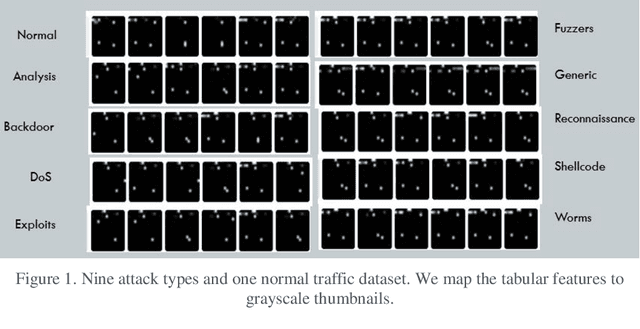
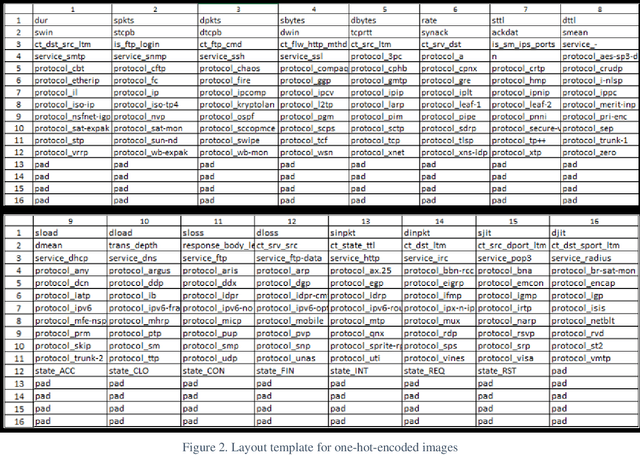
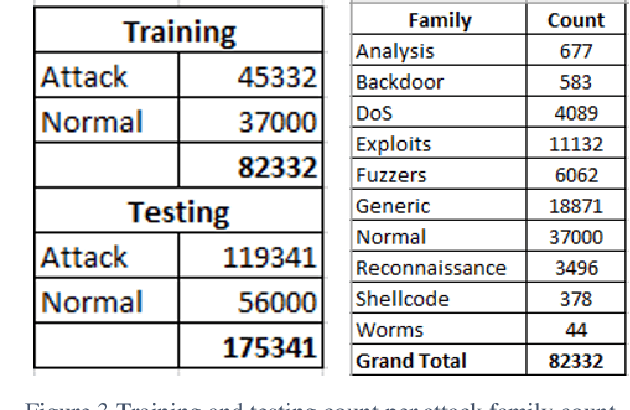
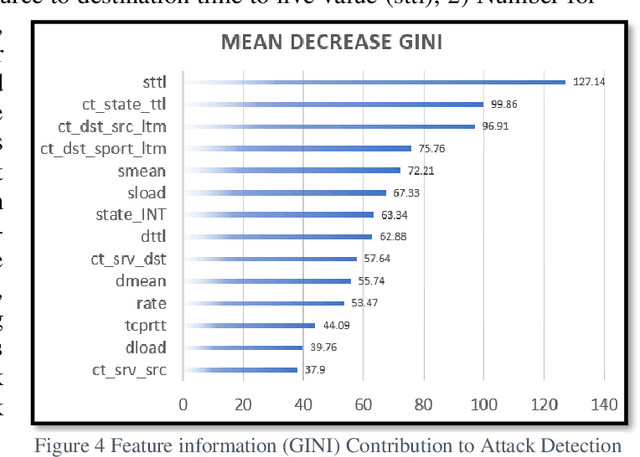
This research recasts the network attack dataset from UNSW-NB15 as an intrusion detection problem in image space. Using one-hot-encodings, the resulting grayscale thumbnails provide a quarter-million examples for deep learning algorithms. Applying the MobileNetV2's convolutional neural network architecture, the work demonstrates a 97% accuracy in distinguishing normal and attack traffic. Further class refinements to 9 individual attack families (exploits, worms, shellcodes) show an overall 56% accuracy. Using feature importance rank, a random forest solution on subsets show the most important source-destination factors and the least important ones as mainly obscure protocols. The dataset is available on Kaggle.
Accelerating the creation of instance segmentation training sets through bounding box annotation
May 23, 2022



Collecting image annotations remains a significant burden when deploying CNN in a specific applicative context. This is especially the case when the annotation consists in binary masks covering object instances. Our work proposes to delineate instances in three steps, based on a semi-automatic approach: (1) the extreme points of an object (left-most, right-most, top, bottom pixels) are manually defined, thereby providing the object bounding-box, (2) a universal automatic segmentation tool like Deep Extreme Cut is used to turn the bounded object into a segmentation mask that matches the extreme points; and (3) the predicted mask is manually corrected. Various strategies are then investigated to balance the human manual annotation resources between bounding-box definition and mask correction, including when the correction of instance masks is prioritized based on their overlap with other instance bounding-boxes, or the outcome of an instance segmentation model trained on a partially annotated dataset. Our experimental study considers a teamsport player segmentation task, and measures how the accuracy of the Panoptic-Deeplab instance segmentation model depends on the human annotation resources allocation strategy. It reveals that the sole definition of extreme points results in a model accuracy that would require up to 10 times more resources if the masks were defined through fully manual delineation of instances. When targeting higher accuracies, prioritizing the mask correction among the training set instances is also shown to save up to 80\% of correction annotation resources compared to a systematic frame by frame correction of instances, for a same trained instance segmentation model accuracy.
CUAB: Convolutional Uncertainty Attention Block Enhanced the Chest X-ray Image Analysis
May 05, 2021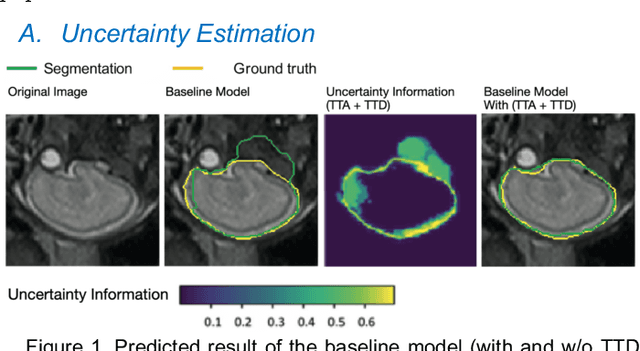
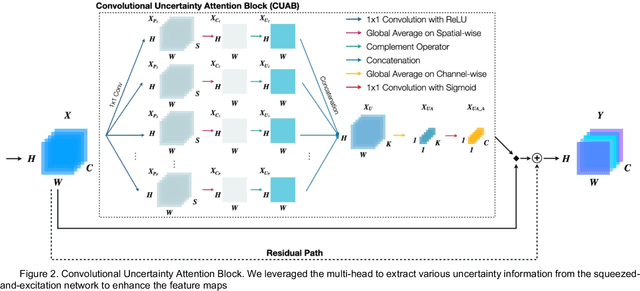
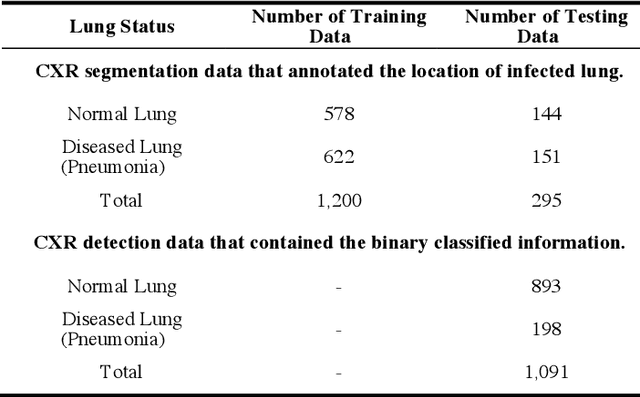
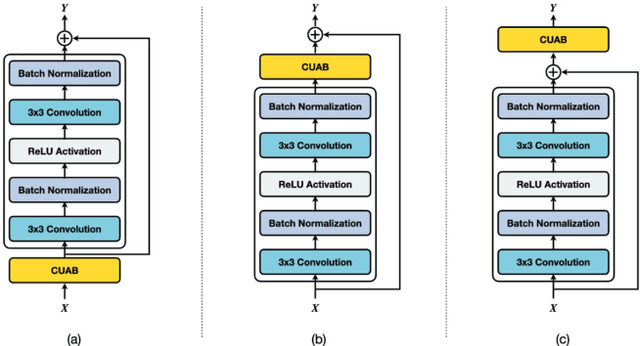
In recent years, convolutional neural networks (CNNs) have been successfully implemented to various image recognition applications, such as medical image analysis, object detection, and image segmentation. Many studies and applications have been working on improving the performance of CNN algorithms and models. The strategies that aim to improve the performance of CNNs can be grouped into three major approaches: (1) deeper and wider network architecture, (2) automatic architecture search, and (3) convolutional attention block. Unlike approaches (1) and (2), the convolutional attention block approach is more flexible with lower cost. It enhances the CNN performance by extracting more efficient features. However, the existing attention blocks focus on enhancing the significant features, which lose some potential features in the uncertainty information. Inspired by the test time augmentation and test-time dropout approaches, we developed a novel convolutional uncertainty attention block (CUAB) that can leverage the uncertainty information to improve CNN-based models. The proposed module discovers potential information from the uncertain regions on feature maps in computer vision tasks. It is a flexible functional attention block that can be applied to any position in the convolutional block in CNN models. We evaluated the CUAB with notable backbone models, ResNet and ResNeXt, on a medical image segmentation task. The CUAB achieved a dice score of 73% and 84% in pneumonia and pneumothorax segmentation, respectively, thereby outperforming the original model and other notable attention approaches. The results demonstrated that the CUAB can efficiently utilize the uncertainty information to improve the model performance.
Novel Light Field Imaging Device with Enhanced Light Collection for Cold Atom Clouds
May 23, 2022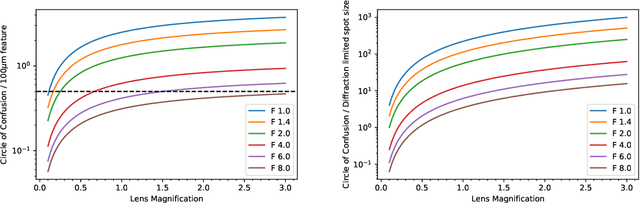
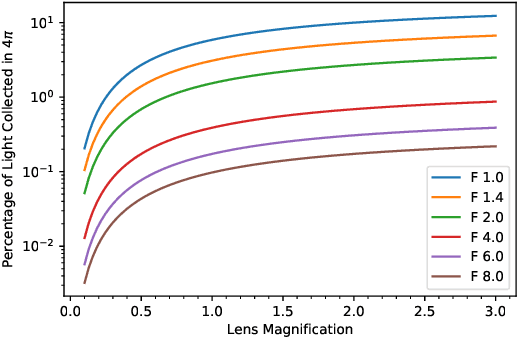
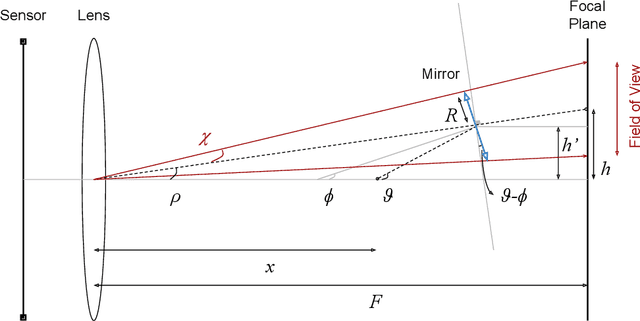
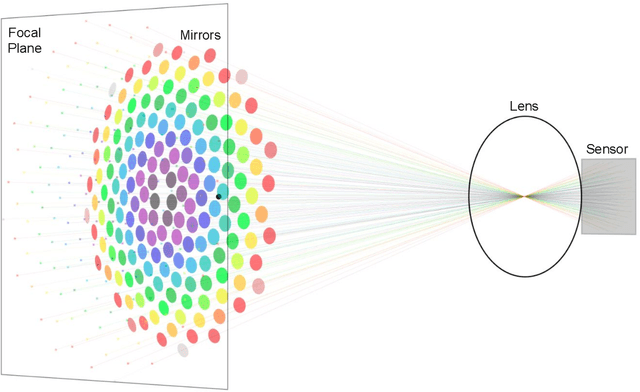
We present a light field imaging system that captures multiple views of an object with a single shot. The system is designed to maximize the total light collection by accepting a larger solid angle of light than a conventional lens with equivalent depth of field. This is achieved by populating a plane of virtual objects using mirrors and fully utilizing the available field of view and depth of field. Simulation results demonstrate that this design is capable of single-shot tomography of objects of size $\mathcal{O}$(1 mm$^3$), reconstructing the 3-dimensional (3D) distribution and features not accessible from any single view angle in isolation. In particular, for atom clouds used in atom interferometry experiments, the system can reconstruct 3D fringe patterns with size $\mathcal{O}$(100 $\mu$m). We also demonstrate this system with a 3D-printed prototype. The prototype is used to take images of $\mathcal{O}$(1 mm$^{3}$) sized objects, and 3D reconstruction algorithms running on a single-shot image successfully reconstruct $\mathcal{O}$(100 $\mu$m) internal features. The prototype also shows that the system can be built with 3D printing technology and hence can be deployed quickly and cost-effectively in experiments with needs for enhanced light collection or 3D reconstruction. Imaging of cold atom clouds in atom interferometry is a key application of this new type of imaging device where enhanced light collection, high depth of field, and 3D tomographic reconstruction can provide new handles to characterize the atom clouds.
SDD-FIQA: Unsupervised Face Image Quality Assessment with Similarity Distribution Distance
Mar 10, 2021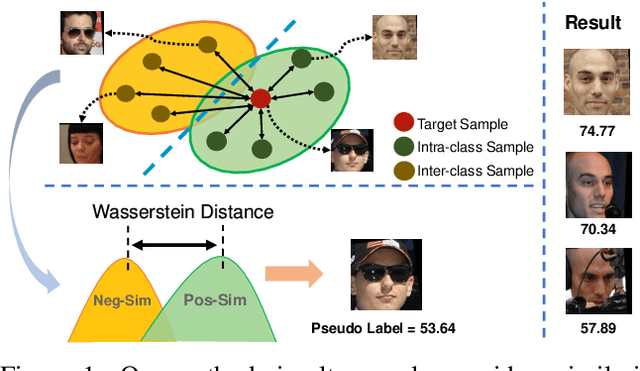
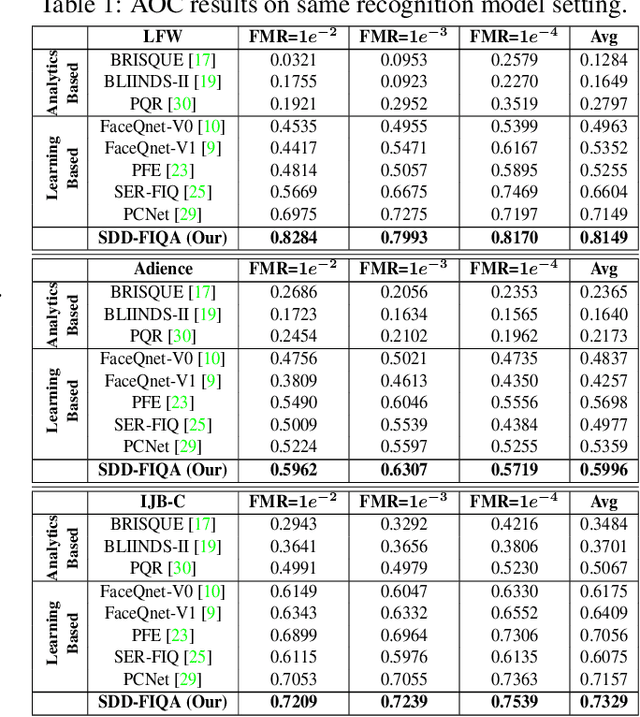
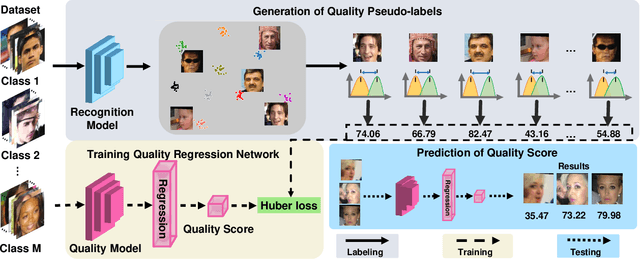
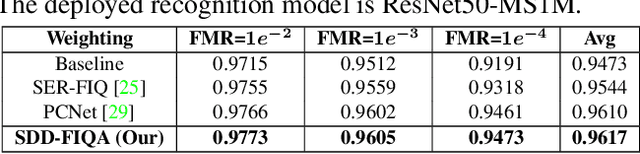
In recent years, Face Image Quality Assessment (FIQA) has become an indispensable part of the face recognition system to guarantee the stability and reliability of recognition performance in an unconstrained scenario. For this purpose, the FIQA method should consider both the intrinsic property and the recognizability of the face image. Most previous works aim to estimate the sample-wise embedding uncertainty or pair-wise similarity as the quality score, which only considers the information from partial intra-class. However, these methods ignore the valuable information from the inter-class, which is for estimating to the recognizability of face image. In this work, we argue that a high-quality face image should be similar to its intra-class samples and dissimilar to its inter-class samples. Thus, we propose a novel unsupervised FIQA method that incorporates Similarity Distribution Distance for Face Image Quality Assessment (SDD-FIQA). Our method generates quality pseudo-labels by calculating the Wasserstein Distance (WD) between the intra-class similarity distributions and inter-class similarity distributions. With these quality pseudo-labels, we are capable of training a regression network for quality prediction. Extensive experiments on benchmark datasets demonstrate that the proposed SDD-FIQA surpasses the state-of-the-arts by an impressive margin. Meanwhile, our method shows good generalization across different recognition systems.
Scene Clustering Based Pseudo-labeling Strategy for Multi-modal Aerial View Object Classification
May 04, 2022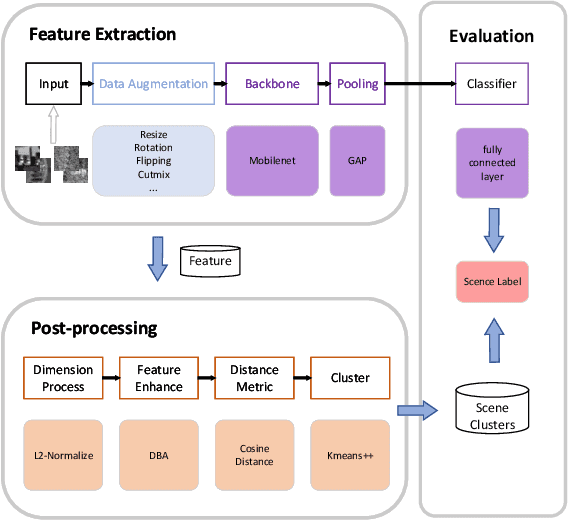
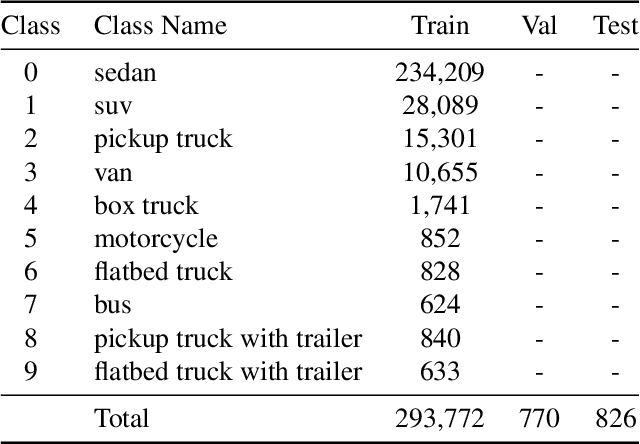
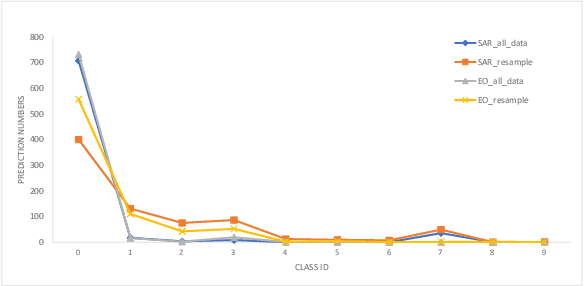
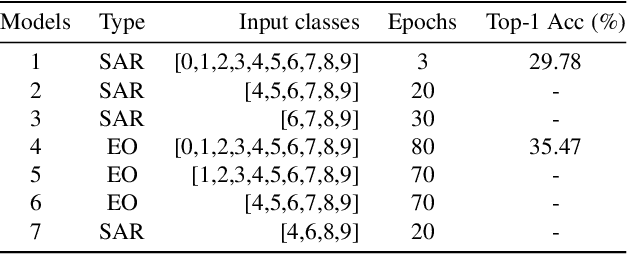
Multi-modal aerial view object classification (MAVOC) in Automatic target recognition (ATR), although an important and challenging problem, has been under studied. This paper firstly finds that fine-grained data, class imbalance and various shooting conditions preclude the representational ability of general image classification. Moreover, the MAVOC dataset has scene aggregation characteristics. By exploiting these properties, we propose Scene Clustering Based Pseudo-labeling Strategy (SCP-Label), a simple yet effective method to employ in post-processing. The SCP-Label brings greater accuracy by assigning the same label to objects within the same scene while also mitigating bias and confusion with model ensembles. Its performance surpasses the official baseline by a large margin of +20.57% Accuracy on Track 1 (SAR), and +31.86% Accuracy on Track 2 (SAR+EO), demonstrating the potential of SCP-Label as post-processing. Finally, we win the championship both on Track1 and Track2 in the CVPR 2022 Perception Beyond the Visible Spectrum (PBVS) Workshop MAVOC Challenge. Our code is available at https://github.com/HowieChangchn/SCP-Label.