 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Classification in the Dark using Quanta Image Sensors
Jun 03, 2020
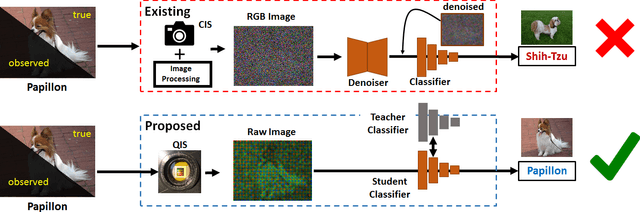
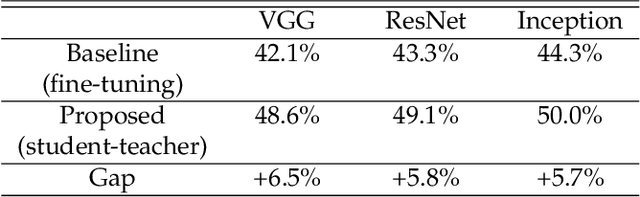

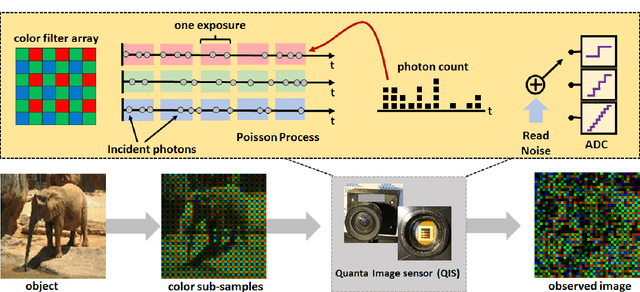
State-of-the-art image classifiers are trained and tested using well-illuminated images. These images are typically captured by CMOS image sensors with at least tens of photons per pixel. However, in dark environments when the photon flux is low, image classification becomes difficult because the measured signal is suppressed by noise. In this paper, we present a new low-light image classification solution using Quanta Image Sensors (QIS). QIS are a new type of image sensors that possess photon counting ability without compromising on pixel size and spatial resolution. Numerous studies over the past decade have demonstrated the feasibility of QIS for low-light imaging, but their usage for image classification has not been studied. This paper fills the gap by presenting a student-teacher learning scheme which allows us to classify the noisy QIS raw data. We show that with student-teacher learning, we are able to achieve image classification at a photon level of one photon per pixel or lower. Experimental results verify the effectiveness of the proposed method compared to existing solutions.
BSRA: Block-based Super Resolution Accelerator with Hardware Efficient Pixel Attention
May 02, 2022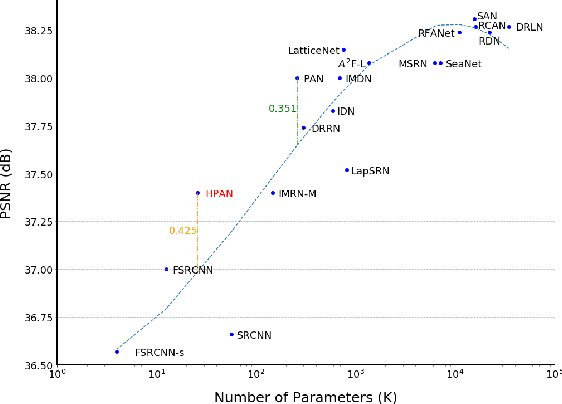
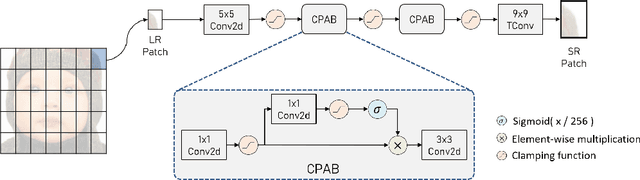
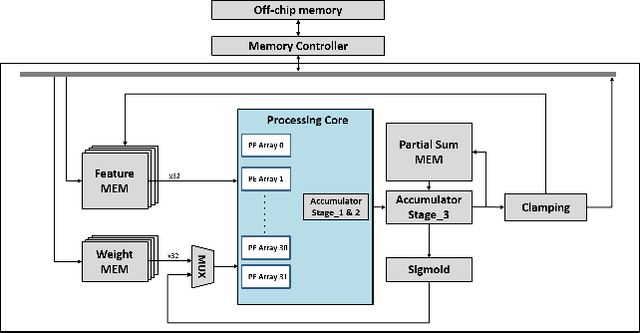
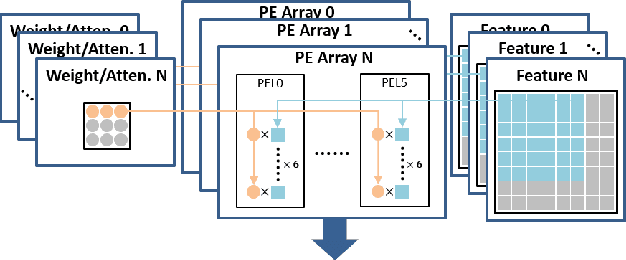
Increasingly, convolution neural network (CNN) based super resolution models have been proposed for better reconstruction results, but their large model size and complicated structure inhibit their real-time hardware implementation. Current hardware designs are limited to a plain network and suffer from lower quality and high memory bandwidth requirements. This paper proposes a super resolution hardware accelerator with hardware efficient pixel attention that just needs 25.9K parameters and simple structure but achieves 0.38dB better reconstruction images than the widely used FSRCNN. The accelerator adopts full model block wise convolution for full model layer fusion to reduce external memory access to model input and output only. In addition, CNN and pixel attention are well supported by PE arrays with distributed weights. The final implementation can support full HD image reconstruction at 30 frames per second with TSMC 40nm CMOS process.
Unsupervised Segmentation of Hyperspectral Remote Sensing Images with Superpixels
Apr 26, 2022
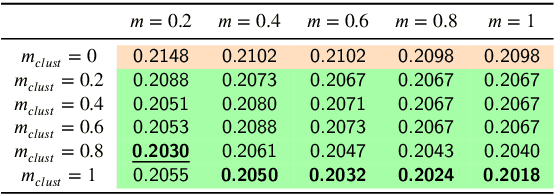
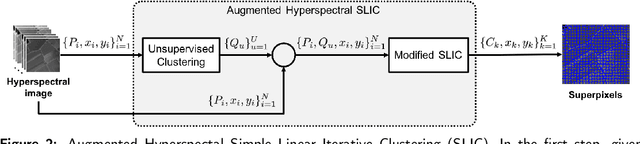
In this paper, we propose an unsupervised method for hyperspectral remote sensing image segmentation. The method exploits the mean-shift clustering algorithm that takes as input a preliminary hyperspectral superpixels segmentation together with the spectral pixel information. The proposed method does not require the number of segmentation classes as input parameter, and it does not exploit any a-priori knowledge about the type of land-cover or land-use to be segmented (e.g. water, vegetation, building etc.). Experiments on Salinas, SalinasA, Pavia Center and Pavia University datasets are carried out. Performance are measured in terms of normalized mutual information, adjusted Rand index and F1-score. Results demonstrate the validity of the proposed method in comparison with the state of the art.
SETGAN: Scale and Energy Trade-off GANs for Image Applications on Mobile Platforms
Mar 23, 2021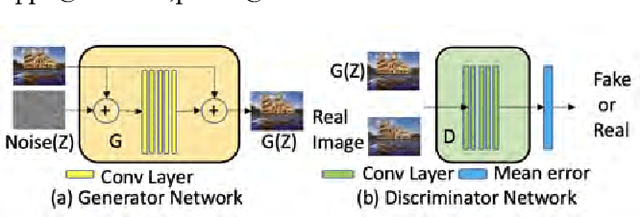

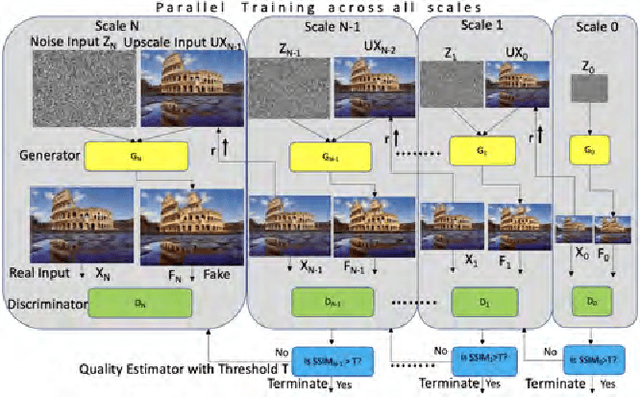
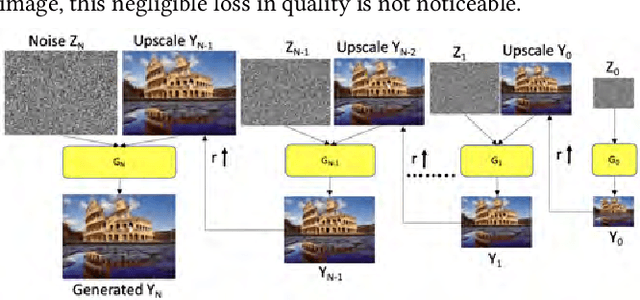
We consider the task of photo-realistic unconditional image generation (generate high quality, diverse samples that carry the same visual content as the image) on mobile platforms using Generative Adversarial Networks (GANs). In this paper, we propose a novel approach to trade-off image generation accuracy of a GAN for the energy consumed (compute) at run-time called Scale-Energy Tradeoff GAN (SETGAN). GANs usually take a long time to train and consume a huge memory hence making it difficult to run on edge devices. The key idea behind SETGAN for an image generation task is for a given input image, we train a GAN on a remote server and use the trained model on edge devices. We use SinGAN, a single image unconditional generative model, that contains a pyramid of fully convolutional GANs, each responsible for learning the patch distribution at a different scale of the image. During the training process, we determine the optimal number of scales for a given input image and the energy constraint from the target edge device. Results show that with SETGAN's unique client-server-based architecture, we were able to achieve a 56% gain in energy for a loss of 3% to 12% SSIM accuracy. Also, with the parallel multi-scale training, we obtain around 4x gain in training time on the server.
A Petri Dish for Histopathology Image Analysis
Jan 29, 2021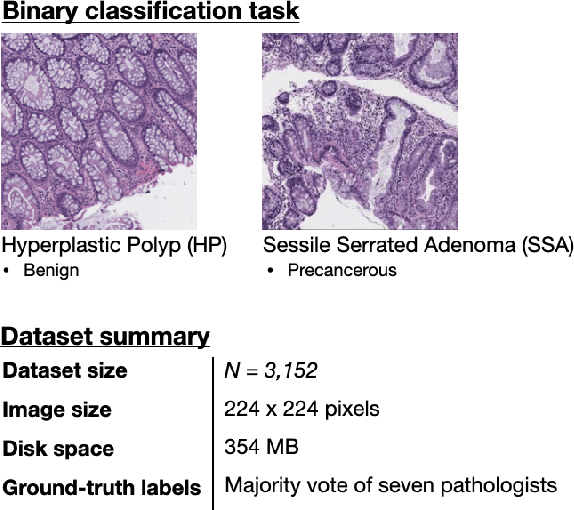
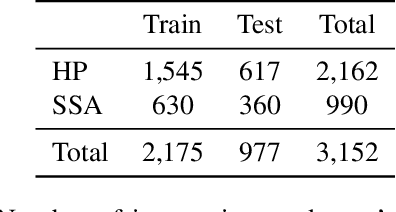
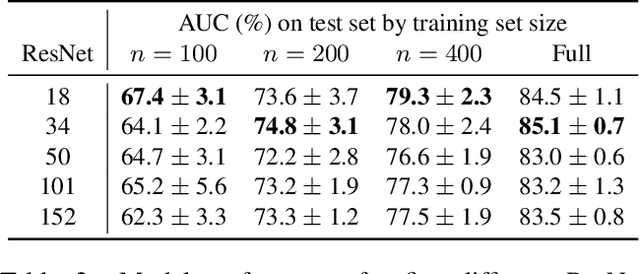
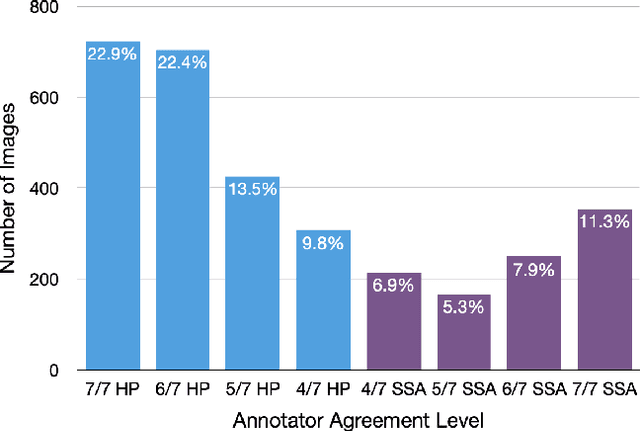
With the rise of deep learning, there has been increased interest in using neural networks for histopathology image analysis, a field that investigates the properties of biopsy or resected specimens that are traditionally manually examined under a microscope by pathologists. In histopathology image analysis, however, challenges such as limited data, costly annotation, and processing high-resolution and variable-size images create a high barrier of entry and make it difficult to quickly iterate over model designs. Throughout scientific history, many significant research directions have leveraged small-scale experimental setups as petri dishes to efficiently evaluate exploratory ideas, which are then validated in large-scale applications. For instance, the Drosophila fruit fly in genetics and MNIST in computer vision are well-known petri dishes. In this paper, we introduce a minimalist histopathology image analysis dataset (MHIST), an analogous petri dish for histopathology image analysis. MHIST is a binary classification dataset of 3,152 fixed-size images of colorectal polyps, each with a gold-standard label determined by the majority vote of seven board-certified gastrointestinal pathologists and annotator agreement level. MHIST occupies less than 400 MB of disk space, and a ResNet-18 baseline can be trained to convergence on MHIST in just 6 minutes using 3.5 GB of memory on a NVIDIA RTX 3090. As example use cases, we use MHIST to study natural questions such as how dataset size, network depth, transfer learning, and high-disagreement examples affect model performance. By introducing MHIST, we hope to not only help facilitate the work of current histopathology imaging researchers, but also make histopathology image analysis more accessible to the general computer vision community. Our dataset is available at https://bmirds.github.io/MHIST.
Identification of chicken egg fertility using SVM classifier based on first-order statistical feature extraction
Jan 10, 2022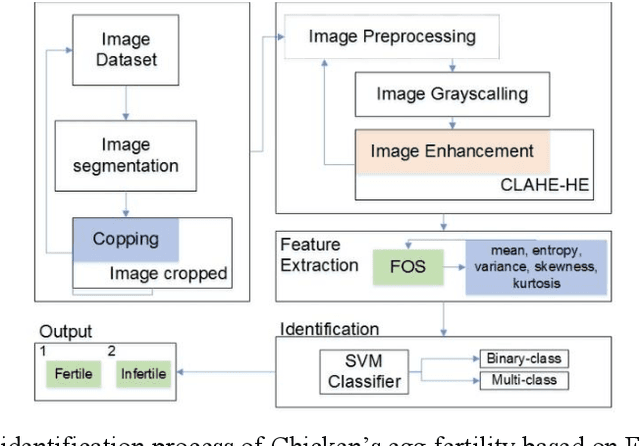
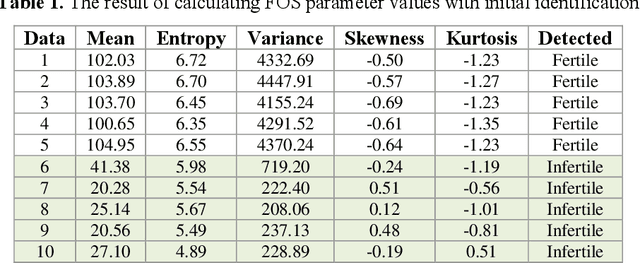

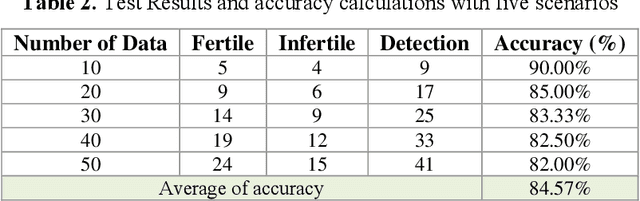
This study aims to identify chicken eggs fertility using the support vector machine (SVM) classifier method. The classification basis used the first-order statistical (FOS) parameters as feature extraction in the identification process. This research was developed based on the process's identification process, which is still manual (conventional). Although currently there are many technologies in the identification process, they still need development. Thus, this research is one of the developments in the field of image processing technology. The sample data uses datasets from previous studies with a total of 100 egg images. The egg object in the image is a single object. From these data, the classification of each fertile and infertile egg is 50 image data. Chicken egg image data became input in image processing, with the initial process is segmentation. This initial segmentation aims to get the cropped image according to the object. The cropped image is repaired using image preprocessing with grayscaling and image enhancement methods. This method (image enhancement) used two combination methods: contrast limited adaptive histogram equalization (CLAHE) and histogram equalization (HE). The improved image becomes the input for feature extraction using the FOS method. The FOS uses five parameters, namely mean, entropy, variance, skewness, and kurtosis. The five parameters entered into the SVM classifier method to identify the fertility of chicken eggs. The results of these experiments, the method proposed in the identification process has a success percentage of 84.57%. Thus, the implementation of this method can be used as a reference for future research improvements. In addition, it may be possible to use a second-order feature extraction method to improve its accuracy and improve supervised learning for classification.
* 9 Pages, 5 Figures, 2 Tables
Aligning Silhouette Topology for Self-Adaptive 3D Human Pose Recovery
Apr 04, 2022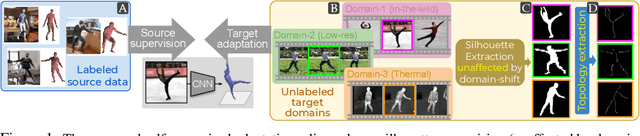
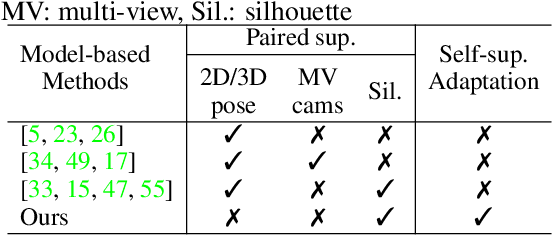
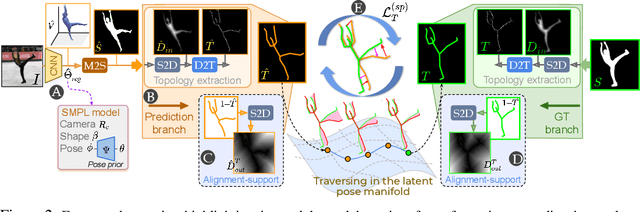
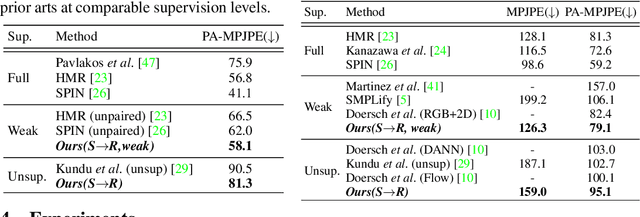
Articulation-centric 2D/3D pose supervision forms the core training objective in most existing 3D human pose estimation techniques. Except for synthetic source environments, acquiring such rich supervision for each real target domain at deployment is highly inconvenient. However, we realize that standard foreground silhouette estimation techniques (on static camera feeds) remain unaffected by domain-shifts. Motivated by this, we propose a novel target adaptation framework that relies only on silhouette supervision to adapt a source-trained model-based regressor. However, in the absence of any auxiliary cue (multi-view, depth, or 2D pose), an isolated silhouette loss fails to provide a reliable pose-specific gradient and requires to be employed in tandem with a topology-centric loss. To this end, we develop a series of convolution-friendly spatial transformations in order to disentangle a topological-skeleton representation from the raw silhouette. Such a design paves the way to devise a Chamfer-inspired spatial topological-alignment loss via distance field computation, while effectively avoiding any gradient hindering spatial-to-pointset mapping. Experimental results demonstrate our superiority against prior-arts in self-adapting a source trained model to diverse unlabeled target domains, such as a) in-the-wild datasets, b) low-resolution image domains, and c) adversarially perturbed image domains (via UAP).
Enabling faster and more reliable sonographic assessment of gestational age through machine learning
Mar 22, 2022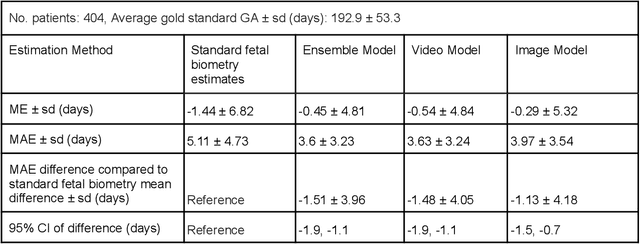
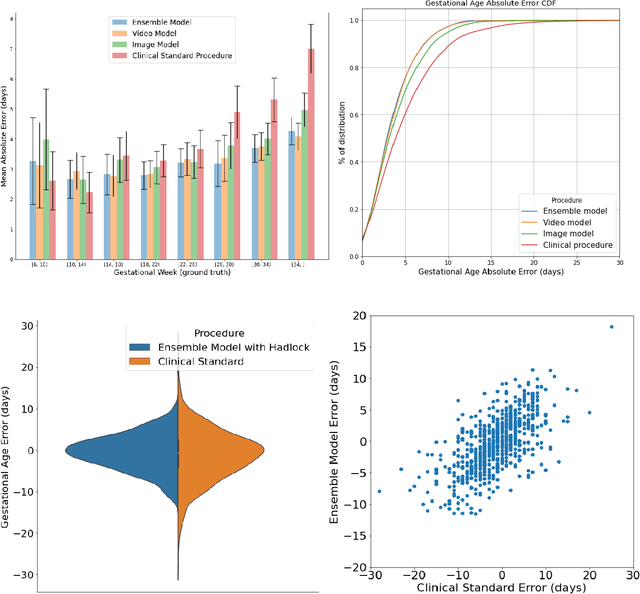
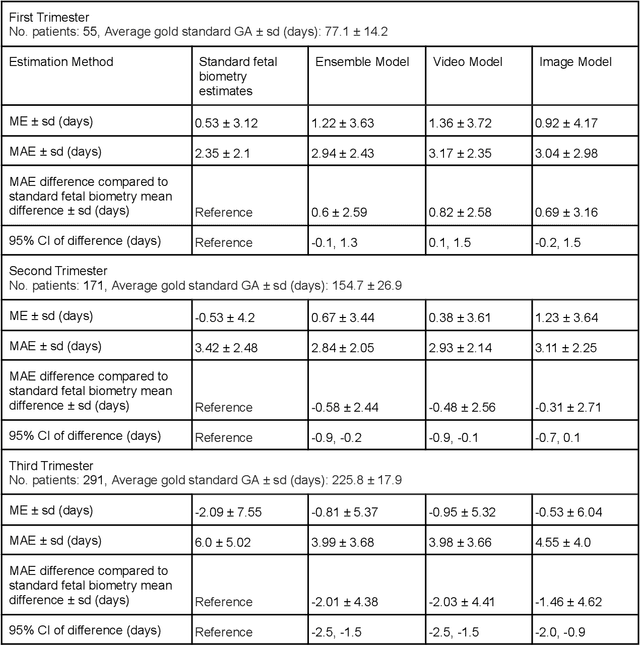
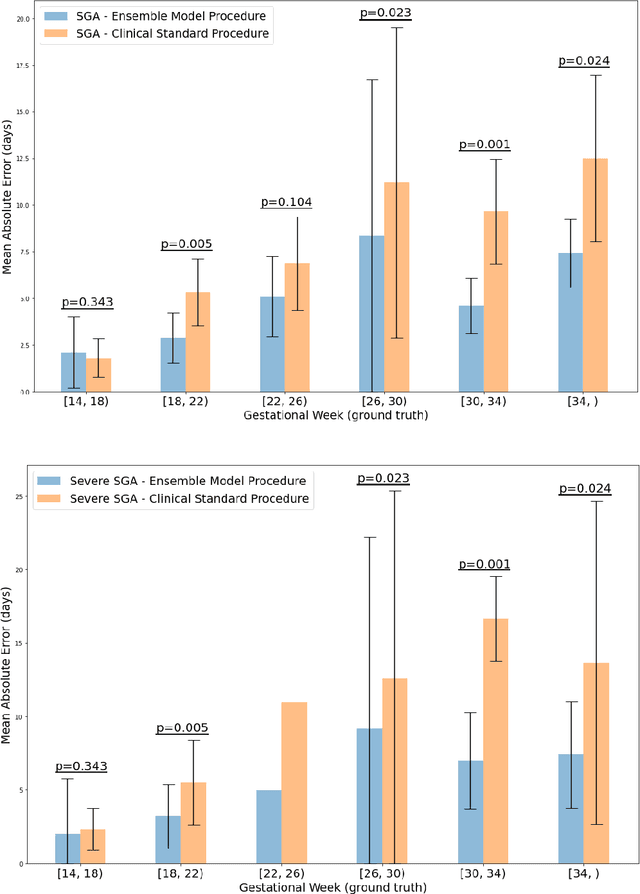
Fetal ultrasounds are an essential part of prenatal care and can be used to estimate gestational age (GA). Accurate GA assessment is important for providing appropriate prenatal care throughout pregnancy and identifying complications such as fetal growth disorders. Since derivation of GA from manual fetal biometry measurements (head, abdomen, femur) are operator-dependent and time-consuming, there have been a number of research efforts focused on using artificial intelligence (AI) models to estimate GA using standard biometry images, but there is still room to improve the accuracy and reliability of these AI systems for widescale adoption. To improve GA estimates, without significant change to provider workflows, we leverage AI to interpret standard plane ultrasound images as well as 'fly-to' ultrasound videos, which are 5-10s videos automatically recorded as part of the standard of care before the still image is captured. We developed and validated three AI models: an image model using standard plane images, a video model using fly-to videos, and an ensemble model (combining both image and video). All three were statistically superior to standard fetal biometry-based GA estimates derived by expert sonographers, the ensemble model has the lowest mean absolute error (MAE) compared to the clinical standard fetal biometry (mean difference: -1.51 $\pm$ 3.96 days, 95% CI [-1.9, -1.1]) on a test set that consisted of 404 participants. We showed that our models outperform standard biometry by a more substantial margin on fetuses that were small for GA. Our AI models have the potential to empower trained operators to estimate GA with higher accuracy while reducing the amount of time required and user variability in measurement acquisition.
BatchFormerV2: Exploring Sample Relationships for Dense Representation Learning
Apr 04, 2022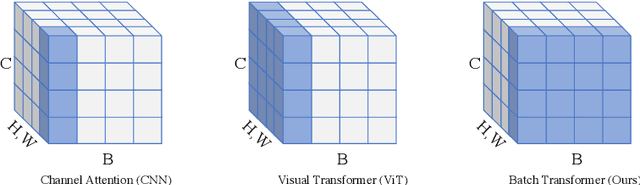
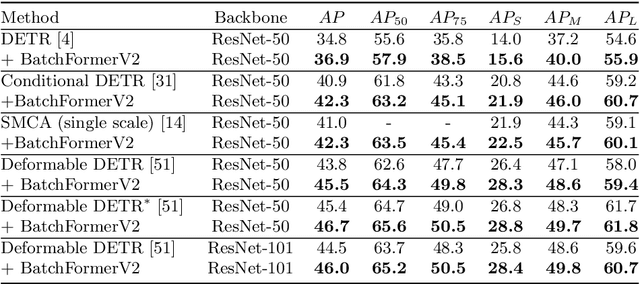
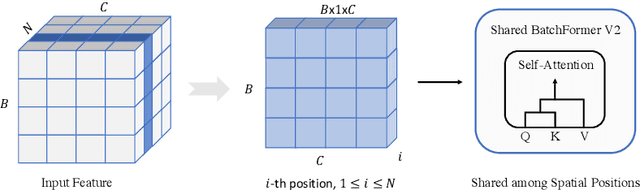

Attention mechanisms have been very popular in deep neural networks, where the Transformer architecture has achieved great success in not only natural language processing but also visual recognition applications. Recently, a new Transformer module, applying on batch dimension rather than spatial/channel dimension, i.e., BatchFormer [18], has been introduced to explore sample relationships for overcoming data scarcity challenges. However, it only works with image-level representations for classification. In this paper, we devise a more general batch Transformer module, BatchFormerV2, which further enables exploring sample relationships for dense representation learning. Specifically, when applying the proposed module, it employs a two-stream pipeline during training, i.e., either with or without a BatchFormerV2 module, where the batchformer stream can be removed for testing. Therefore, the proposed method is a plug-and-play module and can be easily integrated into different vision Transformers without any extra inference cost. Without bells and whistles, we show the effectiveness of the proposed method for a variety of popular visual recognition tasks, including image classification and two important dense prediction tasks: object detection and panoptic segmentation. Particularly, BatchFormerV2 consistently improves current DETR-based detection methods (e.g., DETR, Deformable-DETR, Conditional DETR, and SMCA) by over 1.3%. Code will be made publicly available.
Uncertainty in Minimum Cost Multicuts for Image and Motion Segmentation
May 16, 2021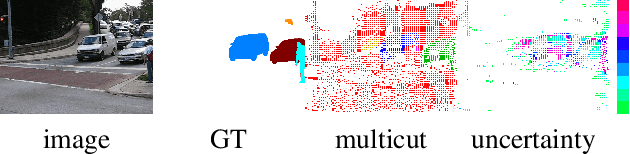

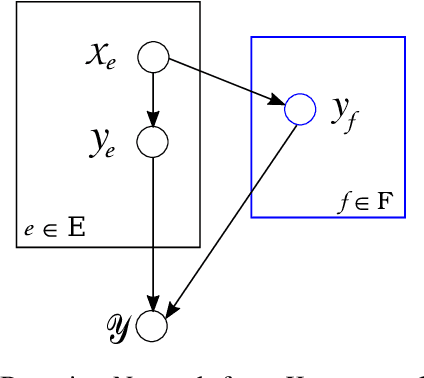

The minimum cost lifted multicut approach has proven practically good performance in a wide range of applications such as image decomposition, mesh segmentation, multiple object tracking, and motion segmentation. It addresses such problems in a graph-based model, where real-valued costs are assigned to the edges between entities such that the minimum cut decomposes the graph into an optimal number of segments. Driven by a probabilistic formulation of minimum cost multicuts, we provide a measure for the uncertainties of the decisions made during the optimization. We argue that access to such uncertainties is crucial for many practical applications and conduct an evaluation by means of sparsifications on three different, widely used datasets in the context of image decomposition (BSDS-500) and motion segmentation (DAVIS2016 and FBMS59) in terms of variation of information (VI) and Rand index (RI).