 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MaxViT: Multi-Axis Vision Transformer
Apr 04, 2022
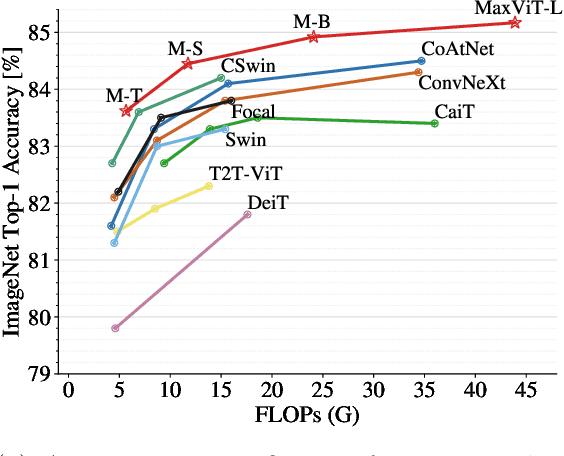

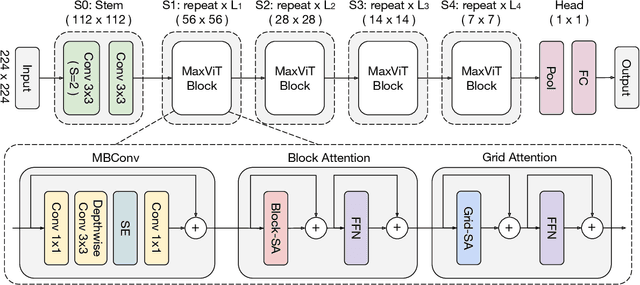
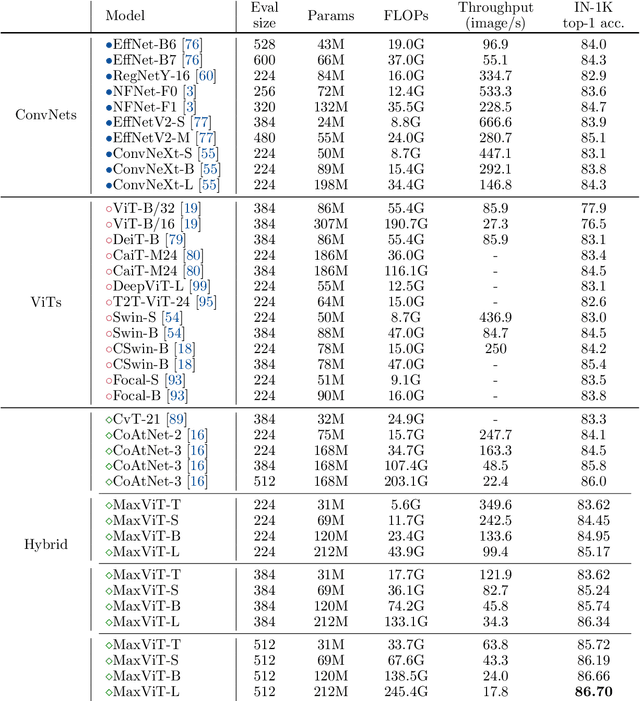
Transformers have recently gained significant attention in the computer vision community. However, the lack of scalability of self-attention mechanisms with respect to image size has limited their wide adoption in state-of-the-art vision backbones. In this paper we introduce an efficient and scalable attention model we call multi-axis attention, which consists of two aspects: blocked local and dilated global attention. These design choices allow global-local spatial interactions on arbitrary input resolutions with only linear complexity. We also present a new architectural element by effectively blending our proposed attention model with convolutions, and accordingly propose a simple hierarchical vision backbone, dubbed MaxViT, by simply repeating the basic building block over multiple stages. Notably, MaxViT is able to "see" globally throughout the entire network, even in earlier, high-resolution stages. We demonstrate the effectiveness of our model on a broad spectrum of vision tasks. On image classification, MaxViT achieves state-of-the-art performance under various settings: without extra data, MaxViT attains 86.5\% ImageNet-1K top-1 accuracy; with ImageNet-21K pre-training, our model achieves 88.7\% top-1 accuracy. For downstream tasks, MaxViT as a backbone delivers favorable performance on object detection as well as visual aesthetic assessment. We also show that our proposed model expresses strong generative modeling capability on ImageNet, demonstrating the superior potential of MaxViT blocks as a universal vision module. We will make the code and models publicly available.
Image Manipulation Detection by Multi-View Multi-Scale Supervision
Apr 14, 2021
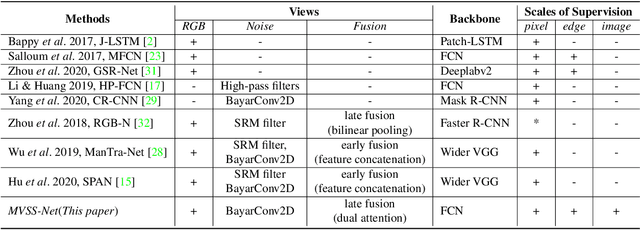
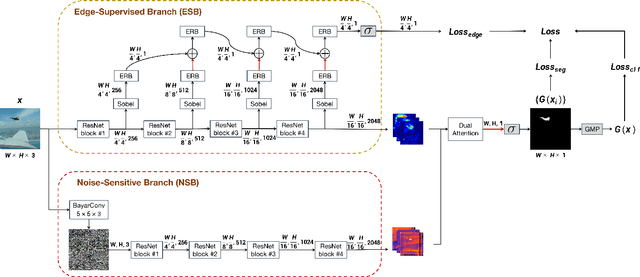
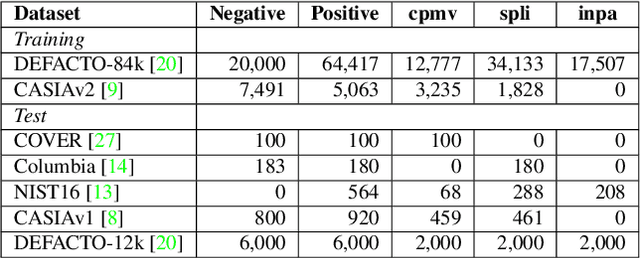
The key challenge of image manipulation detection is how to learn generalizable features that are sensitive to manipulations in novel data, whilst specific to prevent false alarms on authentic images. Current research emphasizes the sensitivity, with the specificity overlooked. In this paper we address both aspects by multi-view feature learning and multi-scale supervision. By exploiting noise distribution and boundary artifact surrounding tampered regions, the former aims to learn semantic-agnostic and thus more generalizable features. The latter allows us to learn from authentic images which are nontrivial to taken into account by current semantic segmentation network based methods. Our thoughts are realized by a new network which we term MVSS-Net. Extensive experiments on five benchmark sets justify the viability of MVSS-Net for both pixel-level and image-level manipulation detection.
Neural Estimation of the Rate-Distortion Function With Applications to Operational Source Coding
Apr 04, 2022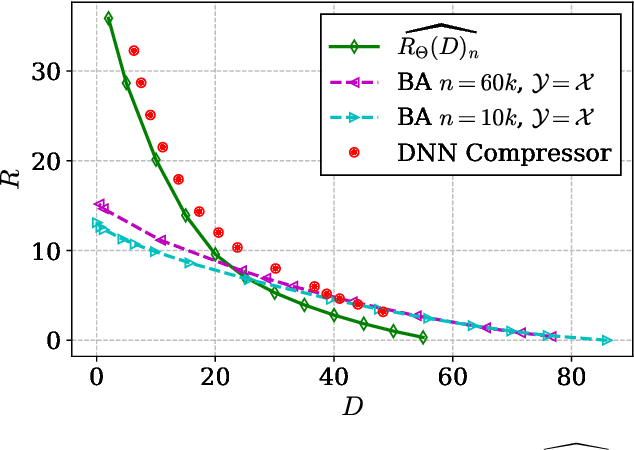
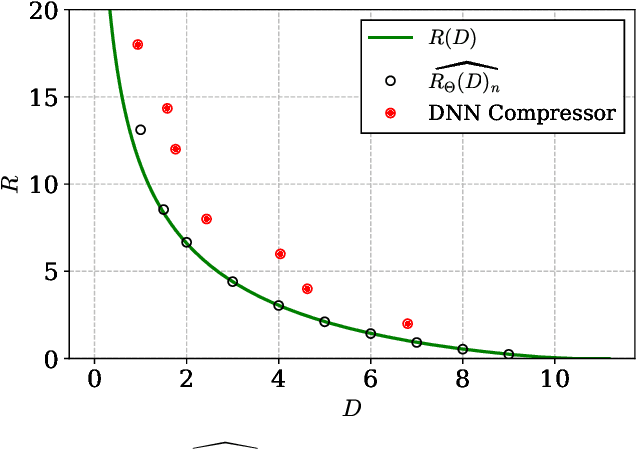
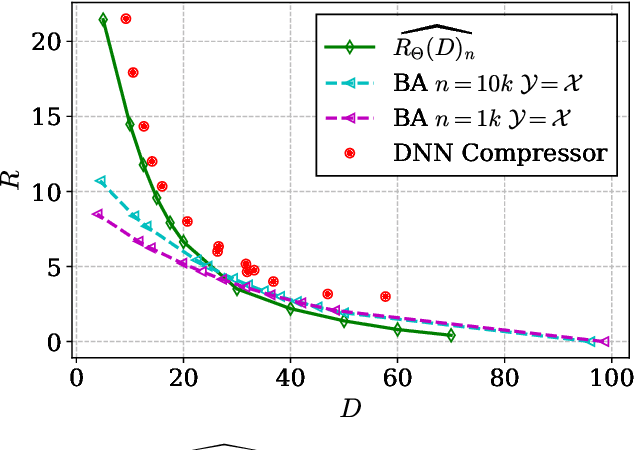

A fundamental question in designing lossy data compression schemes is how well one can do in comparison with the rate-distortion function, which describes the known theoretical limits of lossy compression. Motivated by the empirical success of deep neural network (DNN) compressors on large, real-world data, we investigate methods to estimate the rate-distortion function on such data, which would allow comparison of DNN compressors with optimality. While one could use the empirical distribution of the data and apply the Blahut-Arimoto algorithm, this approach presents several computational challenges and inaccuracies when the datasets are large and high-dimensional, such as the case of modern image datasets. Instead, we re-formulate the rate-distortion objective, and solve the resulting functional optimization problem using neural networks. We apply the resulting rate-distortion estimator, called NERD, on popular image datasets, and provide evidence that NERD can accurately estimate the rate-distortion function. Using our estimate, we show that the rate-distortion achievable by DNN compressors are within several bits of the rate-distortion function for real-world datasets. Additionally, NERD provides access to the rate-distortion achieving channel, as well as samples from its output marginal. Therefore, using recent results in reverse channel coding, we describe how NERD can be used to construct an operational one-shot lossy compression scheme with guarantees on the achievable rate and distortion. Experimental results demonstrate competitive performance with DNN compressors.
ObjectMix: Data Augmentation by Copy-Pasting Objects in Videos for Action Recognition
Apr 01, 2022
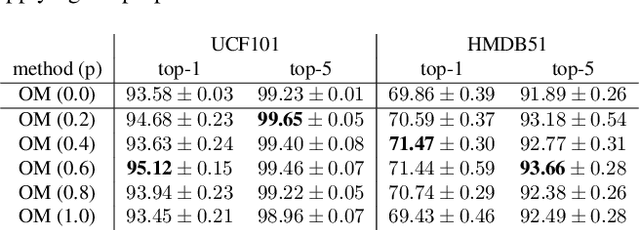

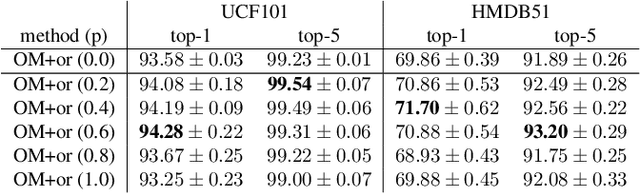
In this paper, we propose a data augmentation method for action recognition using instance segmentation. Although many data augmentation methods have been proposed for image recognition, few methods have been proposed for action recognition. Our proposed method, ObjectMix, extracts each object region from two videos using instance segmentation and combines them to create new videos. Experiments on two action recognition datasets, UCF101 and HMDB51, demonstrate the effectiveness of the proposed method and show its superiority over VideoMix, a prior work.
GOSS: Towards Generalized Open-set Semantic Segmentation
Mar 23, 2022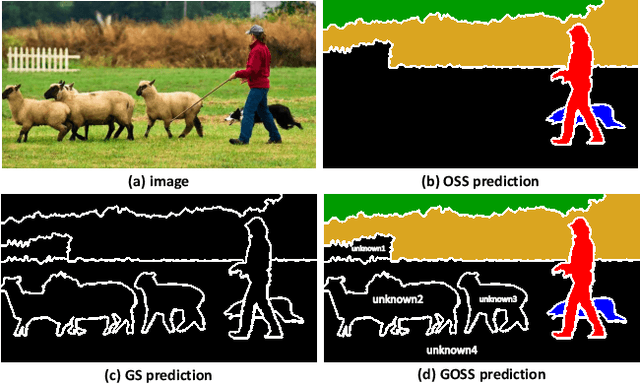

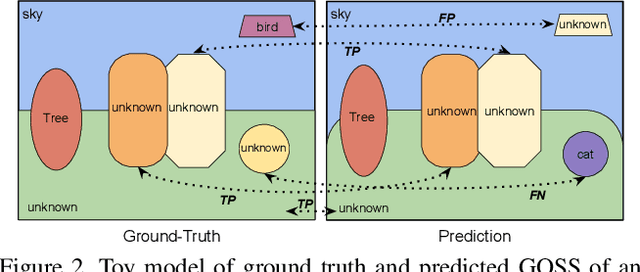

In this paper, we present and study a new image segmentation task, called Generalized Open-set Semantic Segmentation (GOSS). Previously, with the well-known open-set semantic segmentation (OSS), the intelligent agent only detects the unknown regions without further processing, limiting their perception of the environment. It stands to reason that a further analysis of the detected unknown pixels would be beneficial. Therefore, we propose GOSS, which unifies the abilities of two well-defined segmentation tasks, OSS and generic segmentation (GS), in a holistic way. Specifically, GOSS classifies pixels as belonging to known classes, and clusters (or groups) of pixels of unknown class are labelled as such. To evaluate this new expanded task, we further propose a metric which balances the pixel classification and clustering aspects. Moreover, we build benchmark tests on top of existing datasets and propose a simple neural architecture as a baseline, which jointly predicts pixel classification and clustering under open-set settings. Our experiments on multiple benchmarks demonstrate the effectiveness of our baseline. We believe our new GOSS task can produce an expressive image understanding for future research. Code will be made available.
Towards Robust 2D Convolution for Reliable Visual Recognition
Mar 18, 2022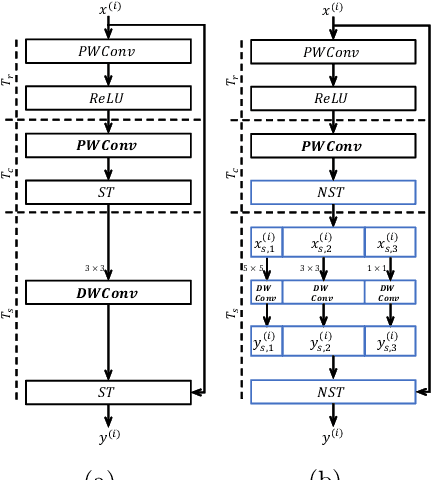

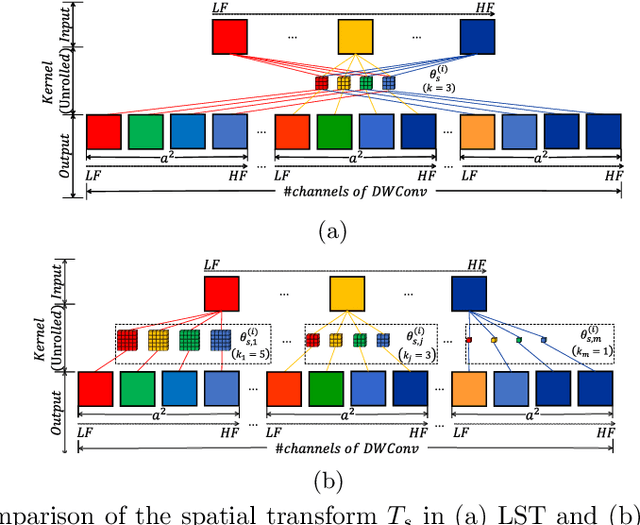
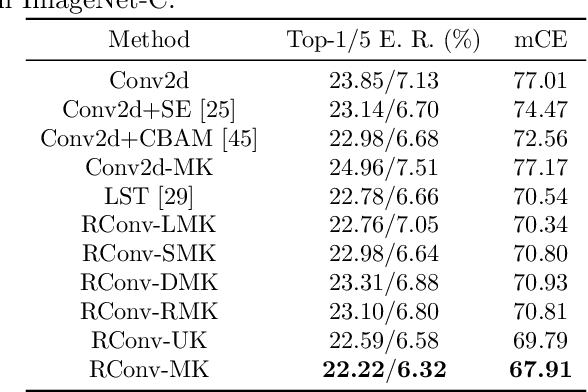
2D convolution (Conv2d), which is responsible for extracting features from the input image, is one of the key modules of a convolutional neural network (CNN). However, Conv2d is vulnerable to image corruptions and adversarial samples. It is an important yet rarely investigated problem that whether we can design a more robust alternative of Conv2d for more reliable feature extraction. In this paper, inspired by the recently developed learnable sparse transform that learns to convert the CNN features into a compact and sparse latent space, we design a novel building block, denoted by RConv-MK, to strengthen the robustness of extracted convolutional features. Our method leverages a set of learnable kernels of different sizes to extract features at different frequencies and employs a normalized soft thresholding operator to adaptively remove noises and trivial features at different corruption levels. Extensive experiments on clean images, corrupted images as well as adversarial samples validate the effectiveness of the proposed robust module for reliable visual recognition. The source codes are enclosed in the submission.
Accelerating the creation of instance segmentation training sets through bounding box annotation
May 23, 2022



Collecting image annotations remains a significant burden when deploying CNN in a specific applicative context. This is especially the case when the annotation consists in binary masks covering object instances. Our work proposes to delineate instances in three steps, based on a semi-automatic approach: (1) the extreme points of an object (left-most, right-most, top, bottom pixels) are manually defined, thereby providing the object bounding-box, (2) a universal automatic segmentation tool like Deep Extreme Cut is used to turn the bounded object into a segmentation mask that matches the extreme points; and (3) the predicted mask is manually corrected. Various strategies are then investigated to balance the human manual annotation resources between bounding-box definition and mask correction, including when the correction of instance masks is prioritized based on their overlap with other instance bounding-boxes, or the outcome of an instance segmentation model trained on a partially annotated dataset. Our experimental study considers a teamsport player segmentation task, and measures how the accuracy of the Panoptic-Deeplab instance segmentation model depends on the human annotation resources allocation strategy. It reveals that the sole definition of extreme points results in a model accuracy that would require up to 10 times more resources if the masks were defined through fully manual delineation of instances. When targeting higher accuracies, prioritizing the mask correction among the training set instances is also shown to save up to 80\% of correction annotation resources compared to a systematic frame by frame correction of instances, for a same trained instance segmentation model accuracy.
DeepOIS: Gyroscope-Guided Deep Optical Image Stabilizer Compensation
Jan 27, 2021

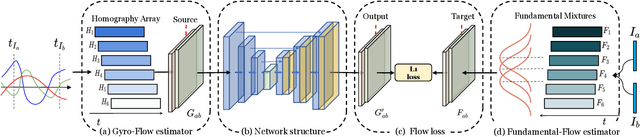
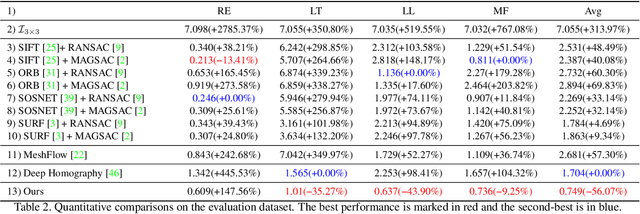
Mobile captured images can be aligned using their gyroscope sensors. Optical image stabilizer (OIS) terminates this possibility by adjusting the images during the capturing. In this work, we propose a deep network that compensates the motions caused by the OIS, such that the gyroscopes can be used for image alignment on the OIS cameras. To achieve this, first, we record both videos and gyroscopes with an OIS camera as training data. Then, we convert gyroscope readings into motion fields. Second, we propose a Fundamental Mixtures motion model for rolling shutter cameras, where an array of rotations within a frame are extracted as the ground-truth guidance. Third, we train a convolutional neural network with gyroscope motions as input to compensate for the OIS motion. Once finished, the compensation network can be applied for other scenes, where the image alignment is purely based on gyroscopes with no need for images contents, delivering strong robustness. Experiments show that our results are comparable with that of non-OIS cameras, and outperform image-based alignment results with a relatively large margin.
Harnessing Artificial Intelligence to Infer Novel Spatial Biomarkers for the Diagnosis of Eosinophilic Esophagitis
May 26, 2022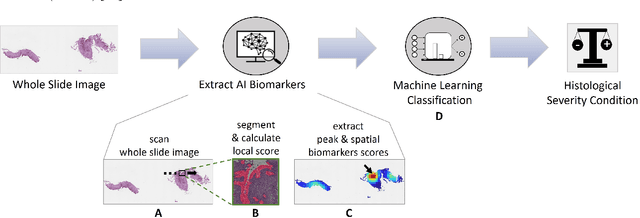
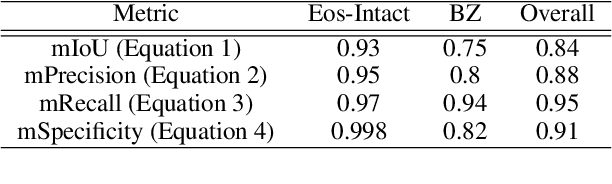
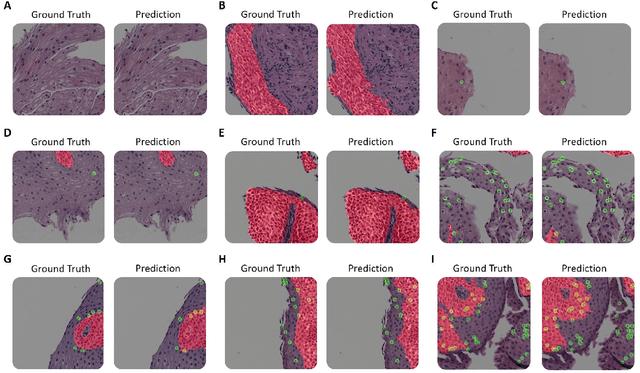

Eosinophilic esophagitis (EoE) is a chronic allergic inflammatory condition of the esophagus associated with elevated esophageal eosinophils. Second only to gastroesophageal reflux disease, EoE is one of the leading causes of chronic refractory dysphagia in adults and children. EoE diagnosis requires enumerating the density of esophageal eosinophils in esophageal biopsies, a somewhat subjective task that is time-consuming, thus reducing the ability to process the complex tissue structure. Previous artificial intelligence (AI) approaches that aimed to improve histology-based diagnosis focused on recapitulating identification and quantification of the area of maximal eosinophil density. However, this metric does not account for the distribution of eosinophils or other histological features, over the whole slide image. Here, we developed an artificial intelligence platform that infers local and spatial biomarkers based on semantic segmentation of intact eosinophils and basal zone distributions. Besides the maximal density of eosinophils (referred to as Peak Eosinophil Count [PEC]) and a maximal basal zone fraction, we identify two additional metrics that reflect the distribution of eosinophils and basal zone fractions. This approach enables a decision support system that predicts EoE activity and classifies the histological severity of EoE patients. We utilized a cohort that includes 1066 biopsy slides from 400 subjects to validate the system's performance and achieved a histological severity classification accuracy of 86.70%, sensitivity of 84.50%, and specificity of 90.09%. Our approach highlights the importance of systematically analyzing the distribution of biopsy features over the entire slide and paves the way towards a personalized decision support system that will assist not only in counting cells but can also potentially improve diagnosis and provide treatment prediction.
Structurally Adaptive Multi-Derivative Regularization for Image Recovery from Sparse Fourier Samples
Jun 10, 2021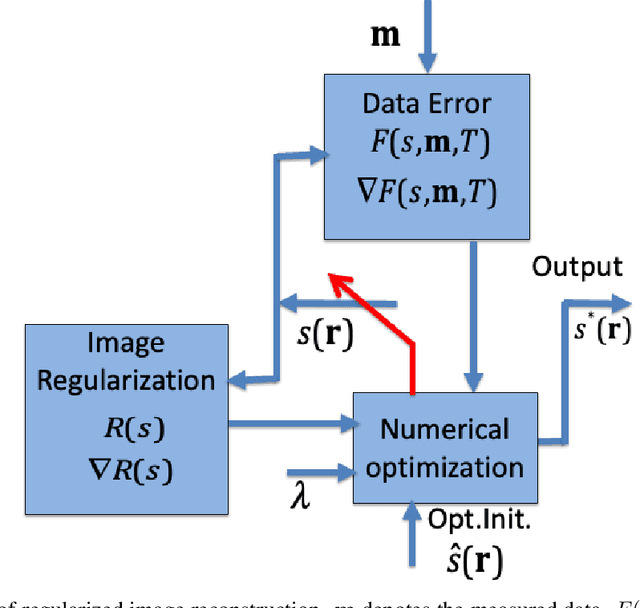
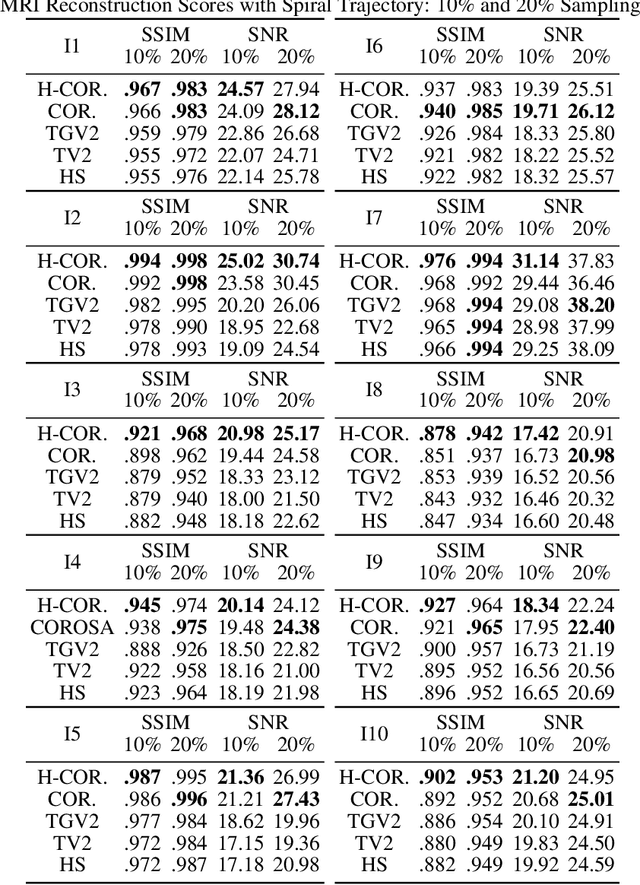
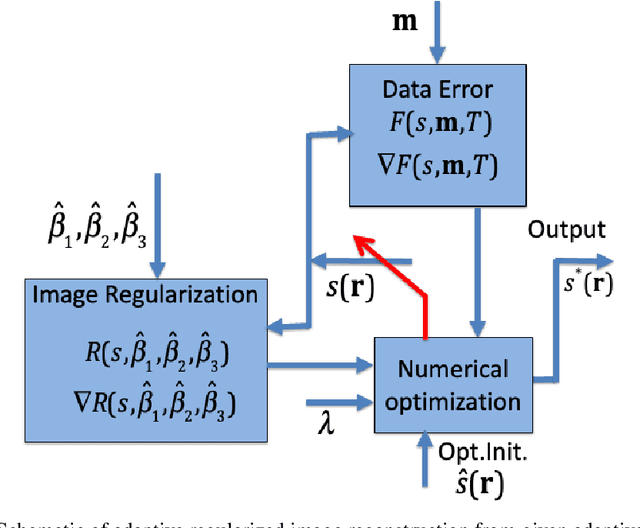
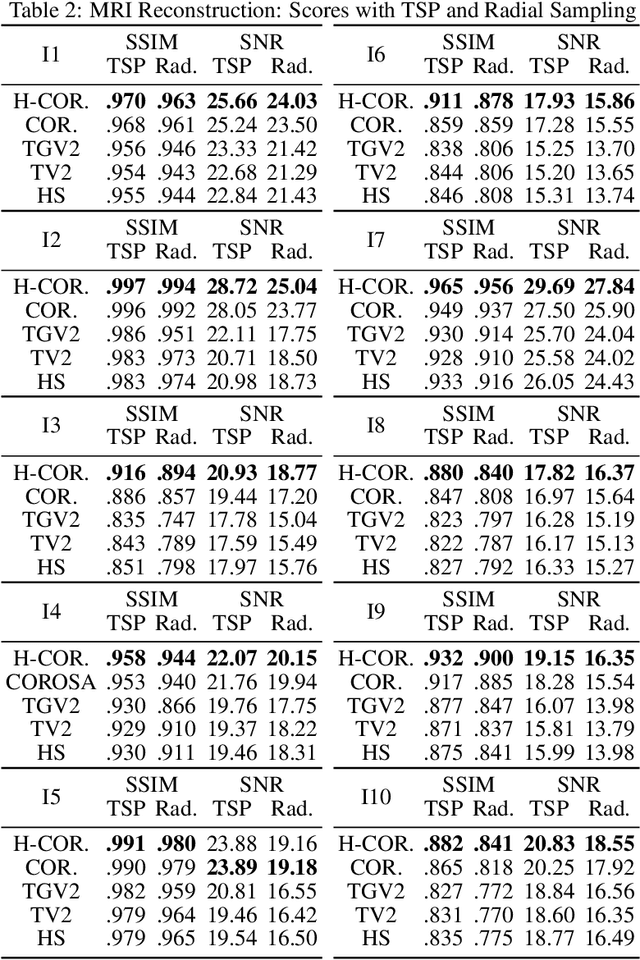
The importance of regularization has been well established in image reconstruction -- which is the computational inversion of imaging forward model -- with applications including deconvolution for microscopy, tomographic reconstruction, magnetic resonance imaging, and so on. Originally, the primary role of the regularization was to stabilize the computational inversion of the imaging forward model against noise. However, a recent framework pioneered by Donoho and others, known as compressive sensing, brought the role of regularization beyond the stabilization of inversion. It established a possibility that regularization can recover full images from highly undersampled measurements. However, it was observed that the quality of reconstruction yielded by compressive sensing methods falls abruptly when the under-sampling and/or measurement noise goes beyond a certain threshold. Recently developed learning-based methods are believed to outperform the compressive sensing methods without a steep drop in the reconstruction quality under such imaging conditions. However, the need for training data limits their applicability. In this paper, we develop a regularization method that outperforms compressive sensing methods as well as selected learning-based methods, without any need for training data. The regularization is constructed as a spatially varying weighted sum of first- and canonical second-order derivatives, with the weights determined to be adaptive to the image structure; the weights are determined such that the attenuation of sharp image features -- which is inevitable with the use of any regularization -- is significantly reduced. We demonstrate the effectiveness of the proposed method by performing reconstruction on sparse Fourier samples simulated from a variety of MRI images.