 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
YOLOPose: Transformer-based Multi-Object 6D Pose Estimation using Keypoint Regression
May 05, 2022
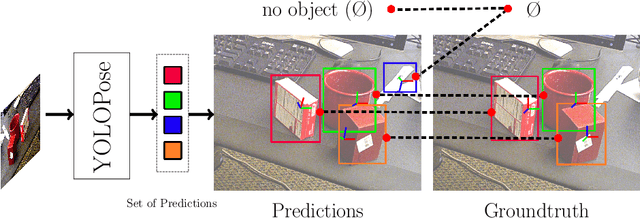
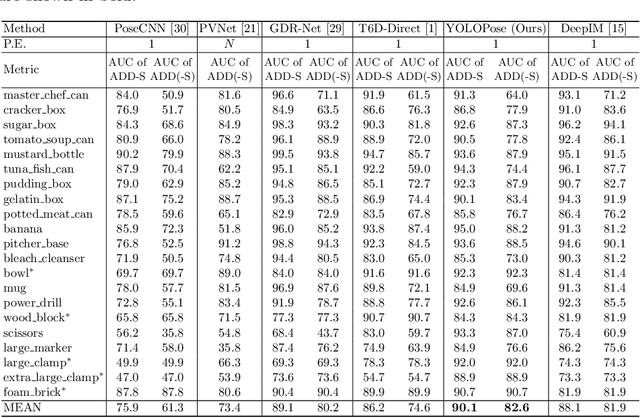
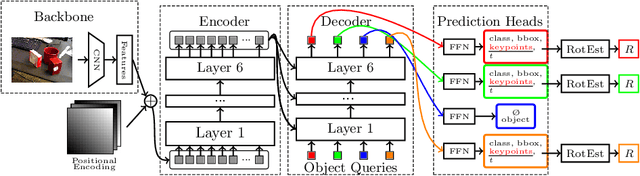
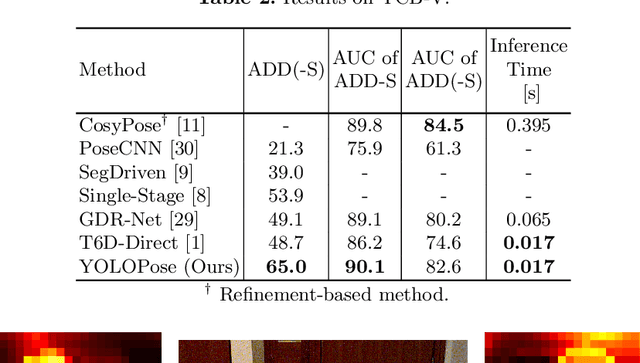
6D object pose estimation is a crucial prerequisite for autonomous robot manipulation applications. The state-of-the-art models for pose estimation are convolutional neural network (CNN)-based. Lately, Transformers, an architecture originally proposed for natural language processing, is achieving state-of-the-art results in many computer vision tasks as well. Equipped with the multi-head self-attention mechanism, Transformers enable simple single-stage end-to-end architectures for learning object detection and 6D object pose estimation jointly. In this work, we propose YOLOPose (short form for You Only Look Once Pose estimation), a Transformer-based multi-object 6D pose estimation method based on keypoint regression. In contrast to the standard heatmaps for predicting keypoints in an image, we directly regress the keypoints. Additionally, we employ a learnable orientation estimation module to predict the orientation from the keypoints. Along with a separate translation estimation module, our model is end-to-end differentiable. Our method is suitable for real-time applications and achieves results comparable to state-of-the-art methods.
RestainNet: a self-supervised digital re-stainer for stain normalization
Feb 28, 2022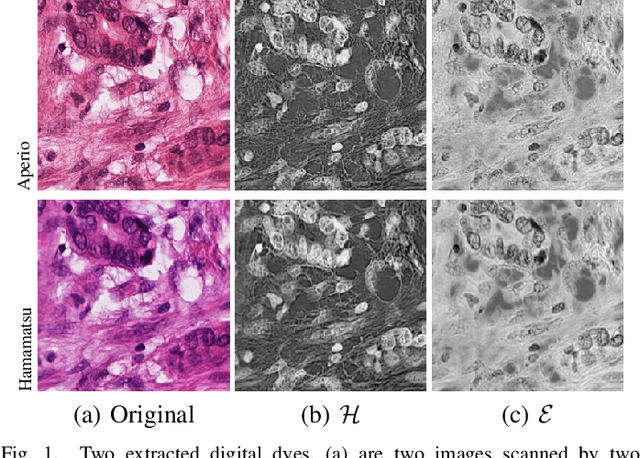
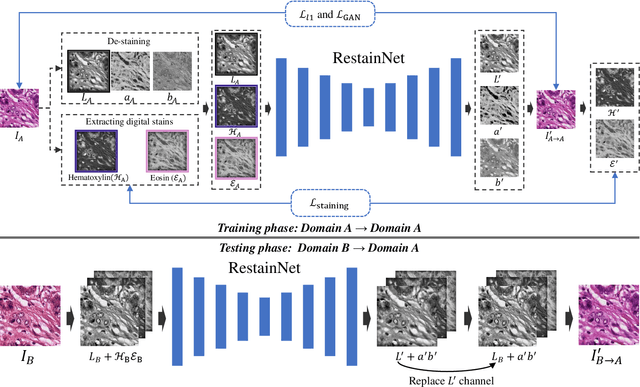
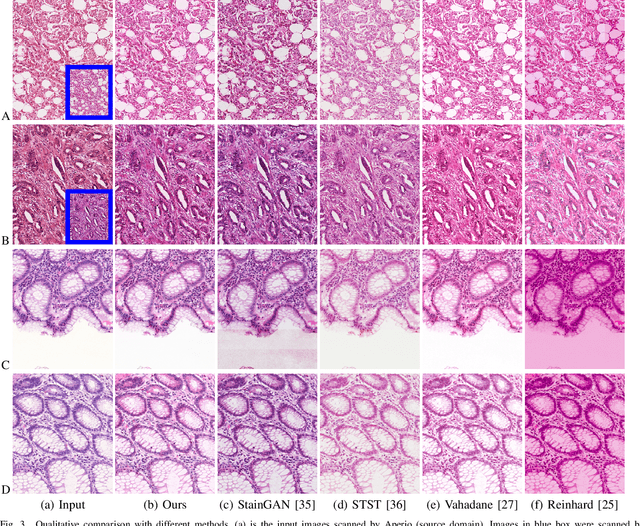
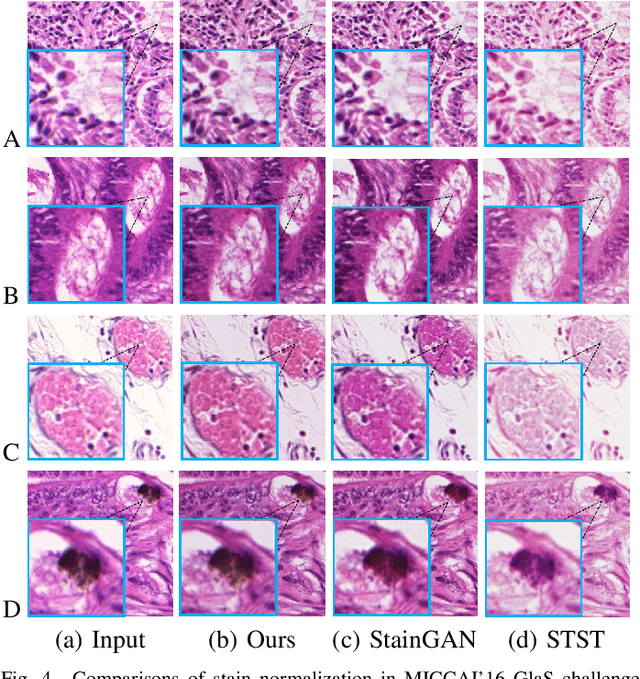
Color inconsistency is an inevitable challenge in computational pathology, which generally happens because of stain intensity variations or sections scanned by different scanners. It harms the pathological image analysis methods, especially the learning-based models. A series of approaches have been proposed for stain normalization. However, most of them are lack flexibility in practice. In this paper, we formulated stain normalization as a digital re-staining process and proposed a self-supervised learning model, which is called RestainNet. Our network is regarded as a digital restainer which learns how to re-stain an unstained (grayscale) image. Two digital stains, Hematoxylin (H) and Eosin (E) were extracted from the original image by Beer-Lambert's Law. We proposed a staining loss to maintain the correctness of stain intensity during the restaining process. Thanks to the self-supervised nature, paired training samples are no longer necessary, which demonstrates great flexibility in practical usage. Our RestainNet outperforms existing approaches and achieves state-of-the-art performance with regard to color correctness and structure preservation. We further conducted experiments on the segmentation and classification tasks and the proposed RestainNet achieved outstanding performance compared with SOTA methods. The self-supervised design allows the network to learn any staining style with no extra effort.
Interventional Multi-Instance Learning with Deconfounded Instance-Level Prediction
Apr 22, 2022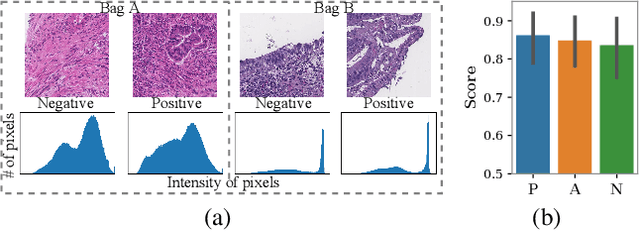
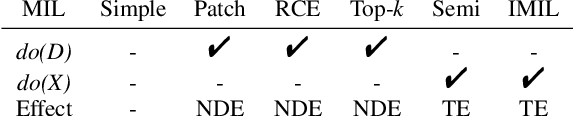
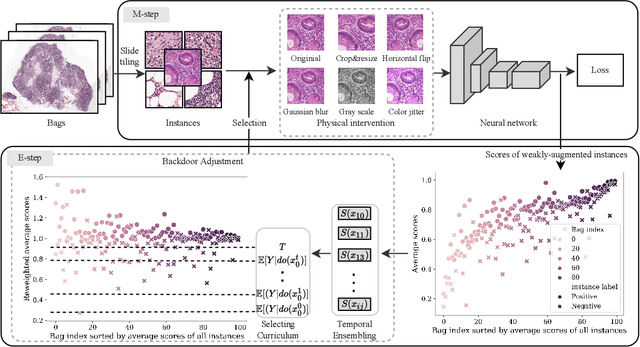
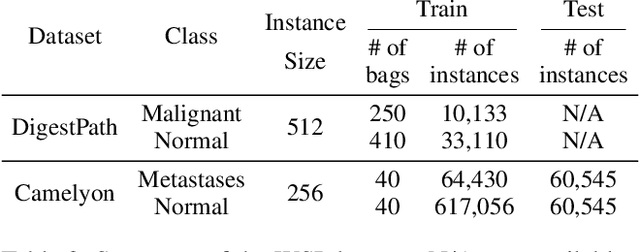
When applying multi-instance learning (MIL) to make predictions for bags of instances, the prediction accuracy of an instance often depends on not only the instance itself but also its context in the corresponding bag. From the viewpoint of causal inference, such bag contextual prior works as a confounder and may result in model robustness and interpretability issues. Focusing on this problem, we propose a novel interventional multi-instance learning (IMIL) framework to achieve deconfounded instance-level prediction. Unlike traditional likelihood-based strategies, we design an Expectation-Maximization (EM) algorithm based on causal intervention, providing a robust instance selection in the training phase and suppressing the bias caused by the bag contextual prior. Experiments on pathological image analysis demonstrate that our IMIL method substantially reduces false positives and outperforms state-of-the-art MIL methods.
Holistic Image Manipulation Detection using Pixel Co-occurrence Matrices
Apr 12, 2021

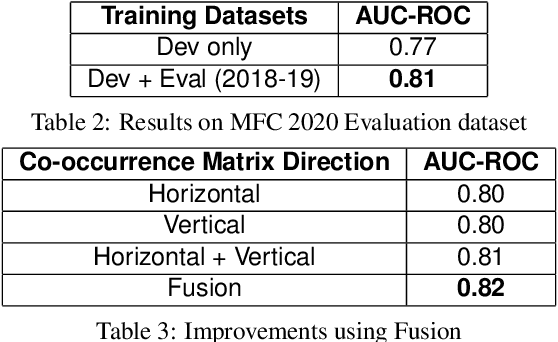
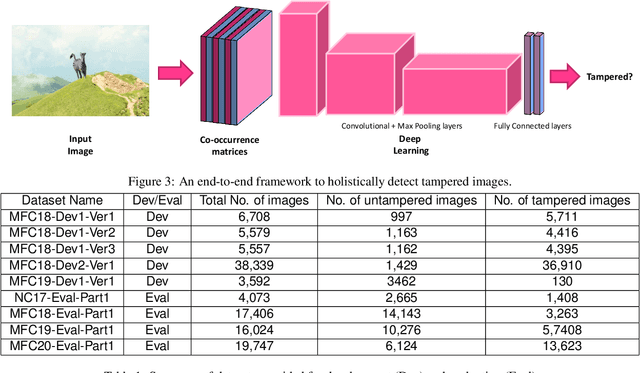
Digital image forensics aims to detect images that have been digitally manipulated. Realistic image forgeries involve a combination of splicing, resampling, region removal, smoothing and other manipulation methods. While most detection methods in literature focus on detecting a particular type of manipulation, it is challenging to identify doctored images that involve a host of manipulations. In this paper, we propose a novel approach to holistically detect tampered images using a combination of pixel co-occurrence matrices and deep learning. We extract horizontal and vertical co-occurrence matrices on three color channels in the pixel domain and train a model using a deep convolutional neural network (CNN) framework. Our method is agnostic to the type of manipulation and classifies an image as tampered or untampered. We train and validate our model on a dataset of more than 86,000 images. Experimental results show that our approach is promising and achieves more than 0.99 area under the curve (AUC) evaluation metric on the training and validation subsets. Further, our approach also generalizes well and achieves around 0.81 AUC on an unseen test dataset comprising more than 19,740 images released as part of the Media Forensics Challenge (MFC) 2020. Our score was highest among all other teams that participated in the challenge, at the time of announcement of the challenge results.
Determining Chess Game State From an Image
Apr 30, 2021

Identifying the configuration of chess pieces from an image of a chessboard is a problem in computer vision that has not yet been solved accurately. However, it is important for helping amateur chess players improve their games by facilitating automatic computer analysis without the overhead of manually entering the pieces. Current approaches are limited by the lack of large datasets and are not designed to adapt to unseen chess sets. This paper puts forth a new dataset synthesised from a 3D model that is an order of magnitude larger than existing ones. Trained on this dataset, a novel end-to-end chess recognition system is presented that combines traditional computer vision techniques with deep learning. It localises the chessboard using a RANSAC-based algorithm that computes a projective transformation of the board onto a regular grid. Using two convolutional neural networks, it then predicts an occupancy mask for the squares in the warped image and finally classifies the pieces. The described system achieves an error rate of 0.23% per square on the test set, 28 times better than the current state of the art. Further, a few-shot transfer learning approach is developed that is able to adapt the inference system to a previously unseen chess set using just two photos of the starting position, obtaining a per-square accuracy of 99.83% on images of that new chess set. The dataset is released publicly; code and trained models are available at https://github.com/georgw777/chesscog.
Face identification by means of a neural net classifier
Apr 01, 2022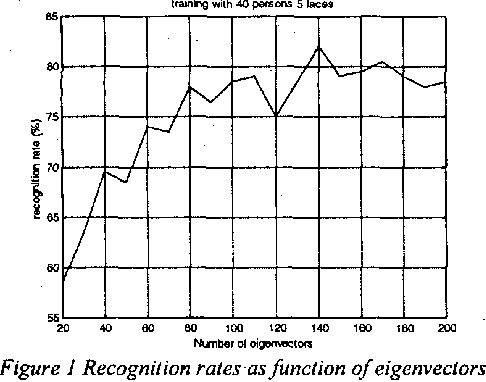
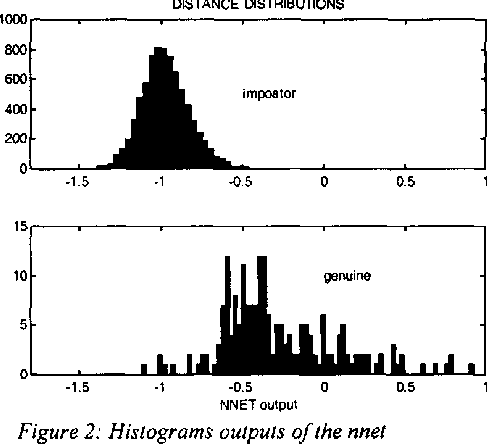
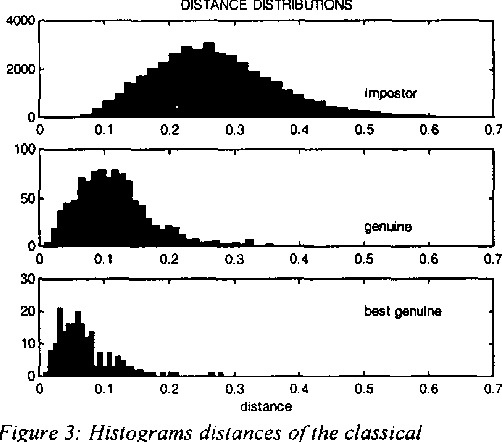
This paper describes a novel face identification method that combines the eigenfaces theory with the Neural Nets. We use the eigenfaces methodology in order to reduce the dimensionality of the input image, and a neural net classifier that performs the identification process. The method presented recognizes faces in the presence of variations in facial expression, facial details and lighting conditions. A recognition rate of more than 87% has been achieved, while the classical method of Turk and Pentland achieves a 75.5%.
* 5 pages, published in Proceedings IEEE 33rd Annual 1999 International Carnahan Conference on Security Technology (Cat. No.99CH36303) Madrid (Spain)
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
May 09, 2022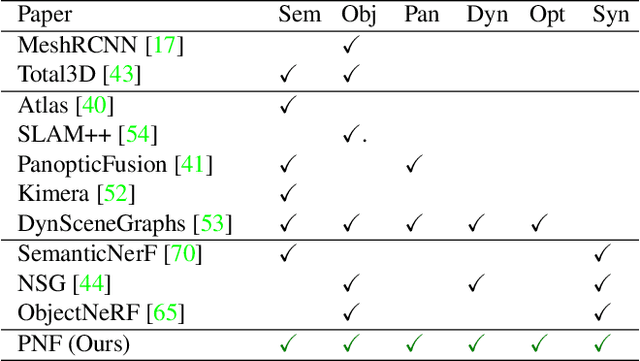
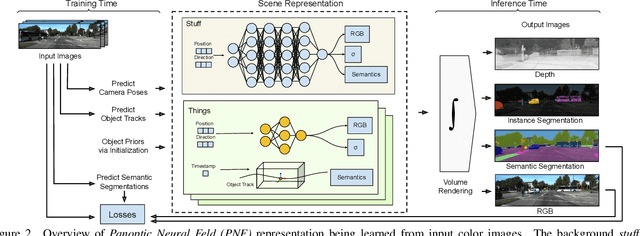
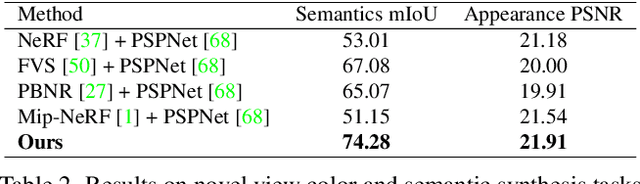
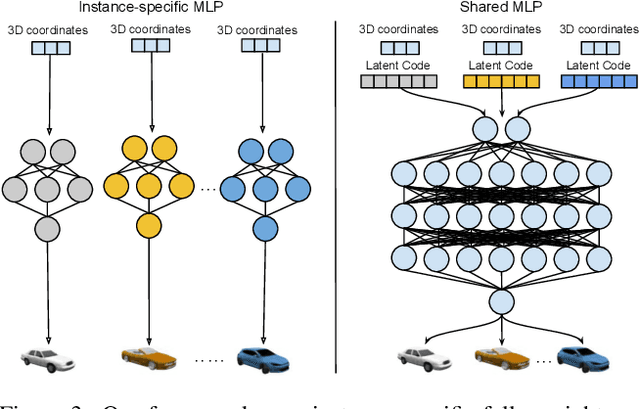
We present Panoptic Neural Fields (PNF), an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). Each object is represented by an oriented 3D bounding box and a multi-layer perceptron (MLP) that takes position, direction, and time and outputs density and radiance. The background stuff is represented by a similar MLP that additionally outputs semantic labels. Each object MLPs are instance-specific and thus can be smaller and faster than previous object-aware approaches, while still leveraging category-specific priors incorporated via meta-learned initialization. Our model builds a panoptic radiance field representation of any scene from just color images. We use off-the-shelf algorithms to predict camera poses, object tracks, and 2D image semantic segmentations. Then we jointly optimize the MLP weights and bounding box parameters using analysis-by-synthesis with self-supervision from color images and pseudo-supervision from predicted semantic segmentations. During experiments with real-world dynamic scenes, we find that our model can be used effectively for several tasks like novel view synthesis, 2D panoptic segmentation, 3D scene editing, and multiview depth prediction.
NeuralEF: Deconstructing Kernels by Deep Neural Networks
Apr 30, 2022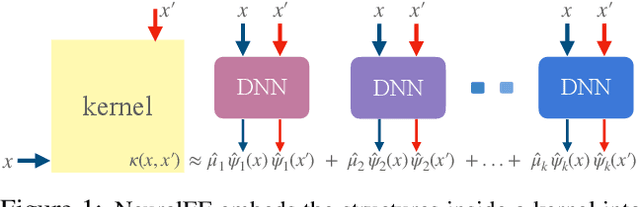

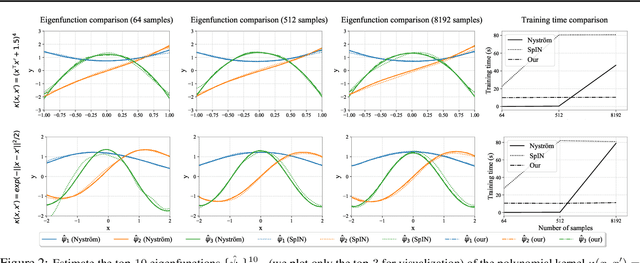
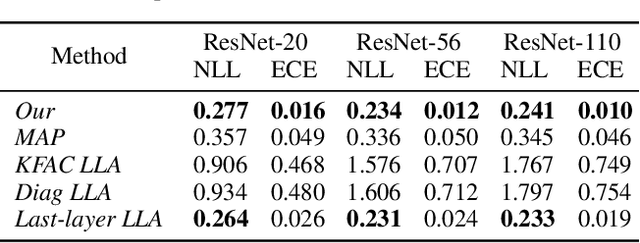
Learning the principal eigenfunctions of an integral operator defined by a kernel and a data distribution is at the core of many machine learning problems. Traditional nonparametric solutions based on the Nystr{\"o}m formula suffer from scalability issues. Recent work has resorted to a parametric approach, i.e., training neural networks to approximate the eigenfunctions. However, the existing method relies on an expensive orthogonalization step and is difficult to implement. We show that these problems can be fixed by using a new series of objective functions that generalizes the EigenGame~\citep{gemp2020eigengame} to function space. We test our method on a variety of supervised and unsupervised learning problems and show it provides accurate approximations to the eigenfunctions of polynomial, radial basis, neural network Gaussian process, and neural tangent kernels. Finally, we demonstrate our method can scale up linearised Laplace approximation of deep neural networks to modern image classification datasets through approximating the Gauss-Newton matrix.
ObjectMix: Data Augmentation by Copy-Pasting Objects in Videos for Action Recognition
Apr 01, 2022
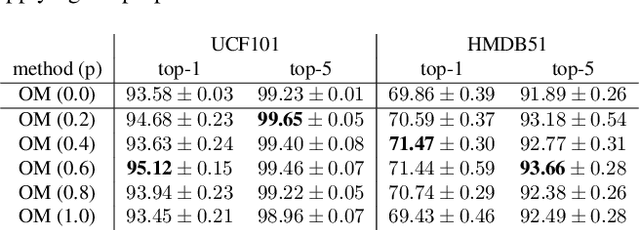

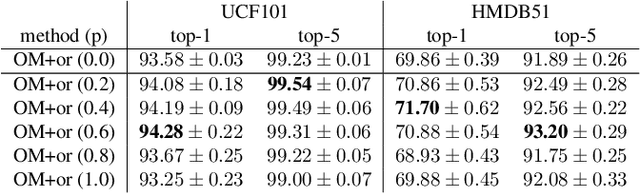
In this paper, we propose a data augmentation method for action recognition using instance segmentation. Although many data augmentation methods have been proposed for image recognition, few methods have been proposed for action recognition. Our proposed method, ObjectMix, extracts each object region from two videos using instance segmentation and combines them to create new videos. Experiments on two action recognition datasets, UCF101 and HMDB51, demonstrate the effectiveness of the proposed method and show its superiority over VideoMix, a prior work.
Image Manipulation Detection by Multi-View Multi-Scale Supervision
Apr 14, 2021
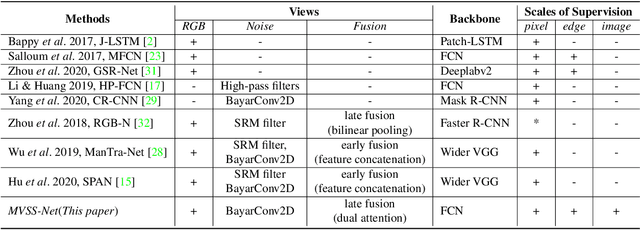
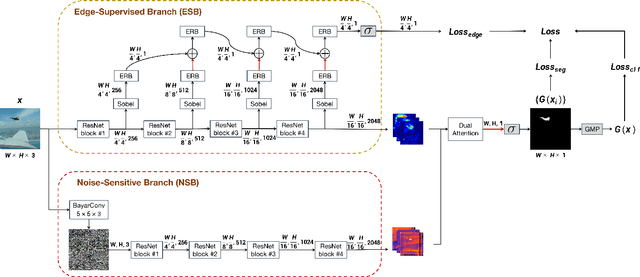
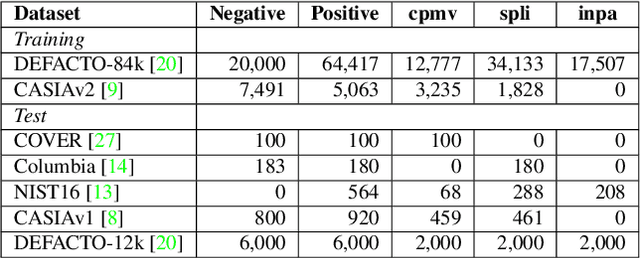
The key challenge of image manipulation detection is how to learn generalizable features that are sensitive to manipulations in novel data, whilst specific to prevent false alarms on authentic images. Current research emphasizes the sensitivity, with the specificity overlooked. In this paper we address both aspects by multi-view feature learning and multi-scale supervision. By exploiting noise distribution and boundary artifact surrounding tampered regions, the former aims to learn semantic-agnostic and thus more generalizable features. The latter allows us to learn from authentic images which are nontrivial to taken into account by current semantic segmentation network based methods. Our thoughts are realized by a new network which we term MVSS-Net. Extensive experiments on five benchmark sets justify the viability of MVSS-Net for both pixel-level and image-level manipulation detection.