 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Region of Interest focused MRI to Synthetic CT Translation using Regression and Classification Multi-task Network
Mar 30, 2022
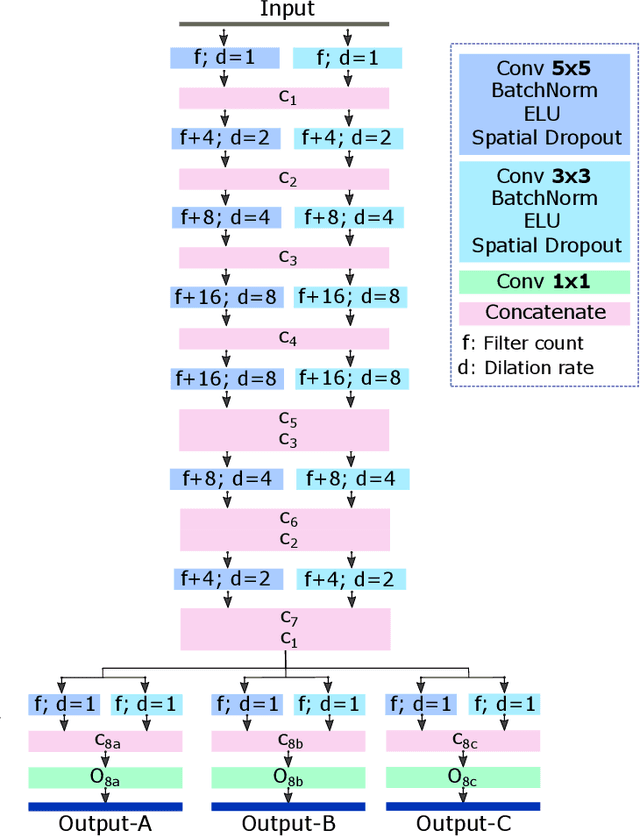
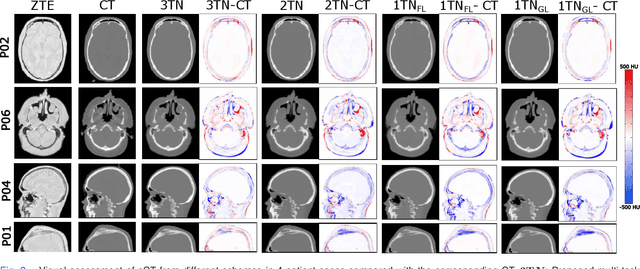
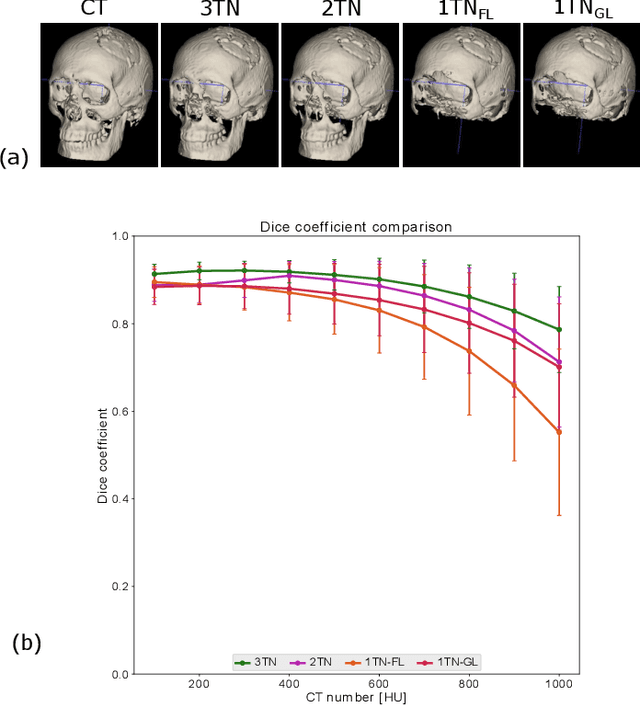
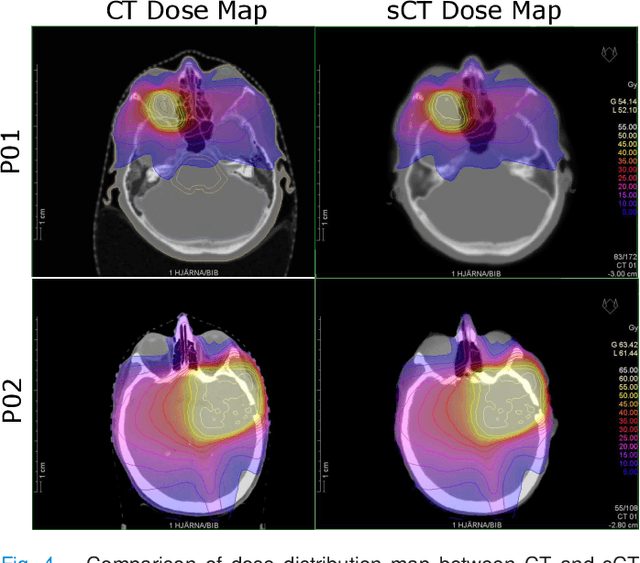
In this work, we present a method for synthetic CT (sCT) generation from zero-echo-time (ZTE) MRI aimed at structural and quantitative accuracies of the image, with a particular focus on the accurate bone density value prediction. We propose a loss function that favors a spatially sparse region in the image. We harness the ability of a multi-task network to produce correlated outputs as a framework to enable localisation of region of interest (RoI) via classification, emphasize regression of values within RoI and still retain the overall accuracy via global regression. The network is optimized by a composite loss function that combines a dedicated loss from each task. We demonstrate how the multi-task network with RoI focused loss offers an advantage over other configurations of the network to achieve higher accuracy of performance. This is relevant to sCT where failure to accurately estimate high Hounsfield Unit values of bone could lead to impaired accuracy in clinical applications. We compare the dose calculation maps from the proposed sCT and the real CT in a radiation therapy treatment planning setup.
QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation
Mar 16, 2022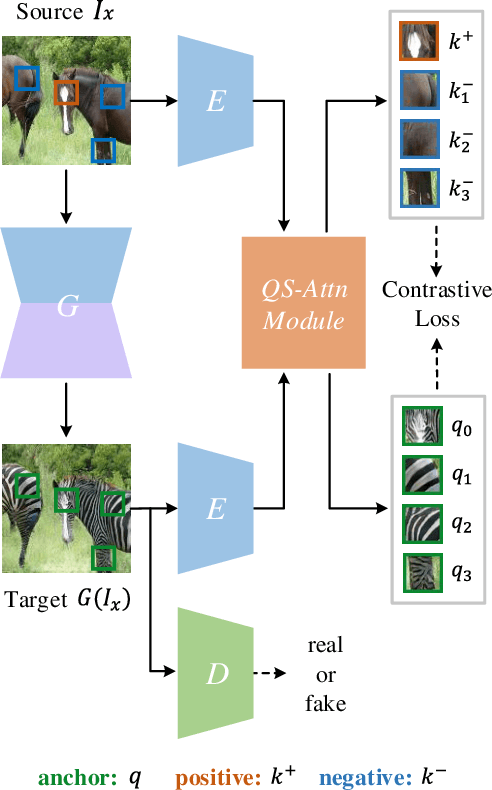
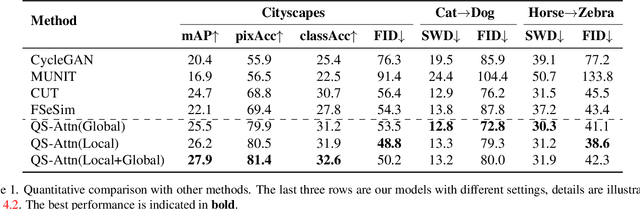

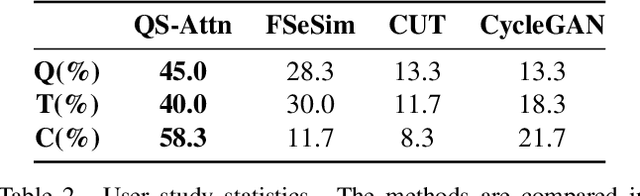
Unpaired image-to-image (I2I) translation often requires to maximize the mutual information between the source and the translated images across different domains, which is critical for the generator to keep the source content and prevent it from unnecessary modifications. The self-supervised contrastive learning has already been successfully applied in the I2I. By constraining features from the same location to be closer than those from different ones, it implicitly ensures the result to take content from the source. However, previous work uses the features from random locations to impose the constraint, which may not be appropriate since some locations contain less information of source domain. Moreover, the feature itself does not reflect the relation with others. This paper deals with these problems by intentionally selecting significant anchor points for contrastive learning. We design a query-selected attention (QS-Attn) module, which compares feature distances in the source domain, giving an attention matrix with a probability distribution in each row. Then we select queries according to their measurement of significance, computed from the distribution. The selected ones are regarded as anchors for contrastive loss. At the same time, the reduced attention matrix is employed to route features in both domains, so that source relations maintain in the synthesis. We validate our proposed method in three different I2I datasets, showing that it increases the image quality without adding learnable parameters.
Give Me Your Attention: Dot-Product Attention Considered Harmful for Adversarial Patch Robustness
Mar 25, 2022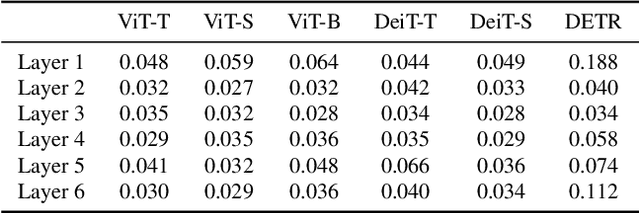
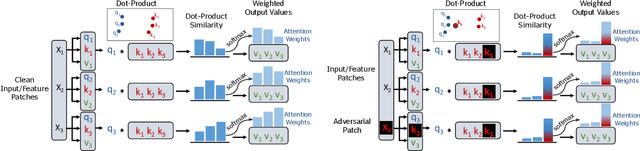
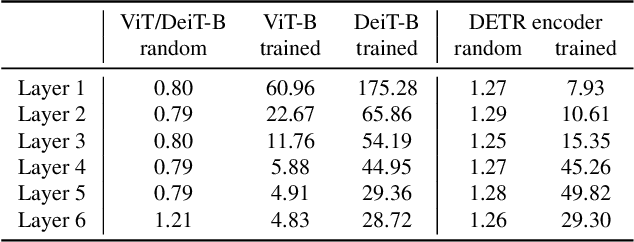
Neural architectures based on attention such as vision transformers are revolutionizing image recognition. Their main benefit is that attention allows reasoning about all parts of a scene jointly. In this paper, we show how the global reasoning of (scaled) dot-product attention can be the source of a major vulnerability when confronted with adversarial patch attacks. We provide a theoretical understanding of this vulnerability and relate it to an adversary's ability to misdirect the attention of all queries to a single key token under the control of the adversarial patch. We propose novel adversarial objectives for crafting adversarial patches which target this vulnerability explicitly. We show the effectiveness of the proposed patch attacks on popular image classification (ViTs and DeiTs) and object detection models (DETR). We find that adversarial patches occupying 0.5% of the input can lead to robust accuracies as low as 0% for ViT on ImageNet, and reduce the mAP of DETR on MS COCO to less than 3%.
QLEVR: A Diagnostic Dataset for Quantificational Language and Elementary Visual Reasoning
May 06, 2022
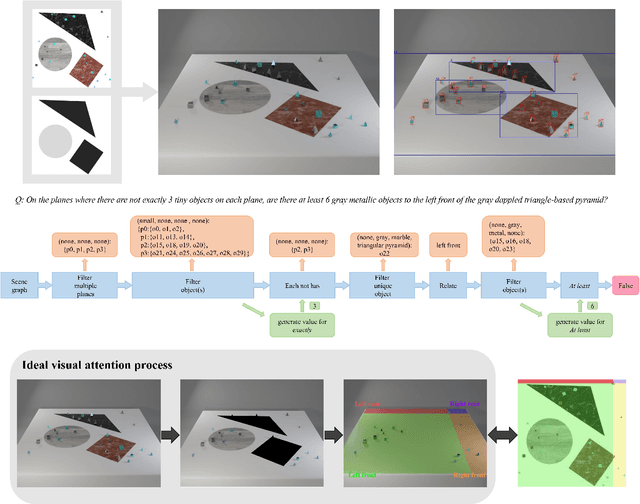
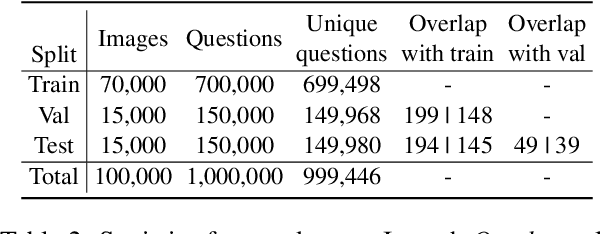

Synthetic datasets have successfully been used to probe visual question-answering datasets for their reasoning abilities. CLEVR (johnson2017clevr), for example, tests a range of visual reasoning abilities. The questions in CLEVR focus on comparisons of shapes, colors, and sizes, numerical reasoning, and existence claims. This paper introduces a minimally biased, diagnostic visual question-answering dataset, QLEVR, that goes beyond existential and numerical quantification and focus on more complex quantifiers and their combinations, e.g., asking whether there are more than two red balls that are smaller than at least three blue balls in an image. We describe how the dataset was created and present a first evaluation of state-of-the-art visual question-answering models, showing that QLEVR presents a formidable challenge to our current models. Code and Dataset are available at https://github.com/zechenli03/QLEVR
UAMD-Net: A Unified Adaptive Multimodal Neural Network for Dense Depth Completion
Apr 16, 2022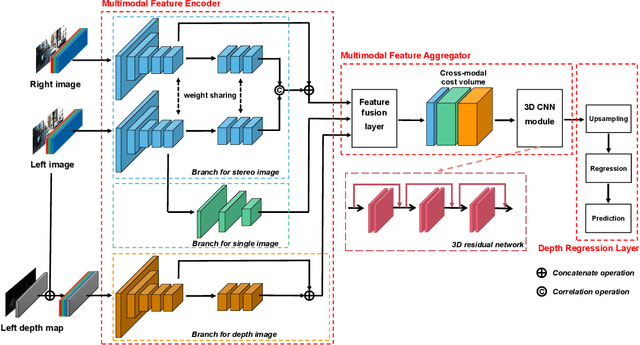
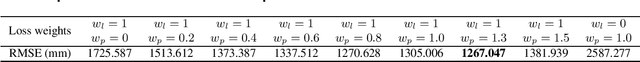
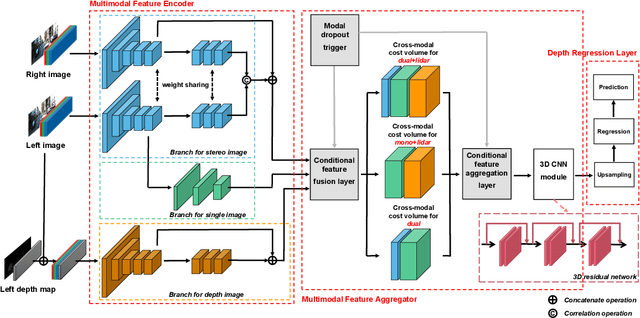
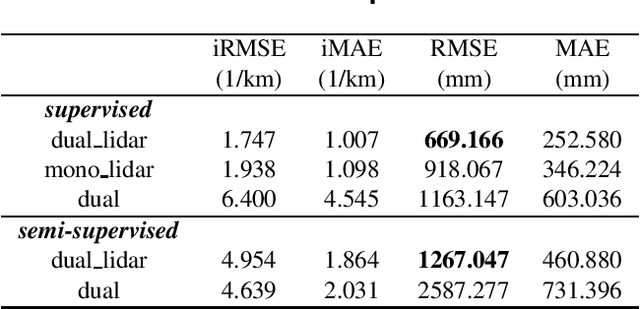
Depth prediction is a critical problem in robotics applications especially autonomous driving. Generally, depth prediction based on binocular stereo matching and fusion of monocular image and laser point cloud are two mainstream methods. However, the former usually suffers from overfitting while building cost volume, and the latter has a limited generalization due to the lack of geometric constraint. To solve these problems, we propose a novel multimodal neural network, namely UAMD-Net, for dense depth completion based on fusion of binocular stereo matching and the weak constrain from the sparse point clouds. Specifically, the sparse point clouds are converted to sparse depth map and sent to the multimodal feature encoder (MFE) with binocular image, constructing a cross-modal cost volume. Then, it will be further processed by the multimodal feature aggregator (MFA) and the depth regression layer. Furthermore, the existing multimodal methods ignore the problem of modal dependence, that is, the network will not work when a certain modal input has a problem. Therefore, we propose a new training strategy called Modal-dropout which enables the network to be adaptively trained with multiple modal inputs and inference with specific modal inputs. Benefiting from the flexible network structure and adaptive training method, our proposed network can realize unified training under various modal input conditions. Comprehensive experiments conducted on KITTI depth completion benchmark demonstrate that our method produces robust results and outperforms other state-of-the-art methods.
Checkerboard Context Model for Efficient Learned Image Compression
Apr 01, 2021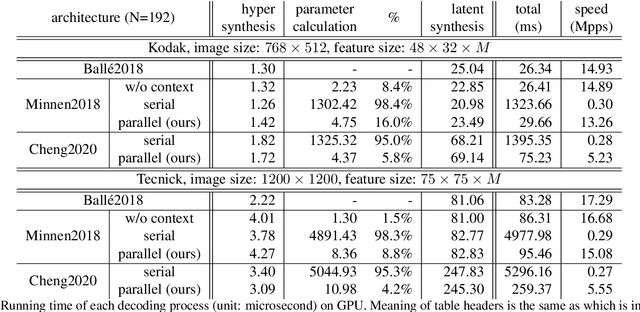

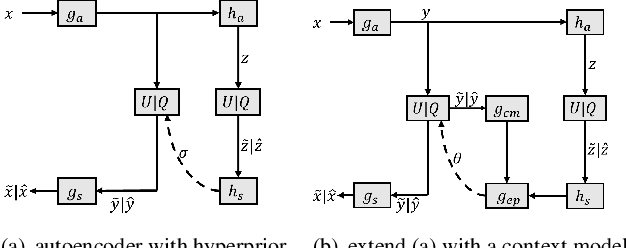

For learned image compression, the autoregressive context model is proved effective in improving the rate-distortion (RD) performance. Because it helps remove spatial redundancies among latent representations. However, the decoding process must be done in a strict scan order, which breaks the parallelization. We propose a parallelizable checkerboard context model (CCM) to solve the problem. Our two-pass checkerboard context calculation eliminates such limitations on spatial locations by re-organizing the decoding order. Speeding up the decoding process more than 40 times in our experiments, it achieves significantly improved computational efficiency with almost the same rate-distortion performance. To the best of our knowledge, this is the first exploration on parallelization-friendly spatial context model for learned image compression.
High-dimensional Assisted Generative Model for Color Image Restoration
Aug 14, 2021


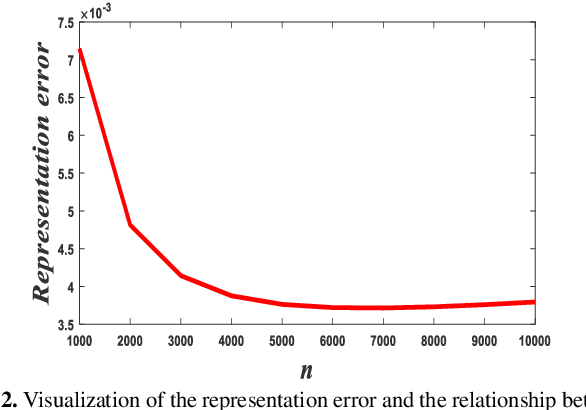
This work presents an unsupervised deep learning scheme that exploiting high-dimensional assisted score-based generative model for color image restoration tasks. Considering that the sample number and internal dimension in score-based generative model have key influence on estimating the gradients of data distribution, two different high-dimensional ways are proposed: The channel-copy transformation increases the sample number and the pixel-scale transformation decreases feasible space dimension. Subsequently, a set of high-dimensional tensors represented by these transformations are used to train the network through denoising score matching. Then, sampling is performed by annealing Langevin dynamics and alternative data-consistency update. Furthermore, to alleviate the difficulty of learning high-dimensional representation, a progressive strategy is proposed to leverage the performance. The proposed unsupervised learning and iterative restoration algo-rithm, which involves a pre-trained generative network to obtain prior, has transparent and clear interpretation compared to other data-driven approaches. Experimental results on demosaicking and inpainting conveyed the remarkable performance and diversity of our proposed method.
Rabbit, toad, and the Moon: Can machine categorize them into one class?
Mar 30, 2022
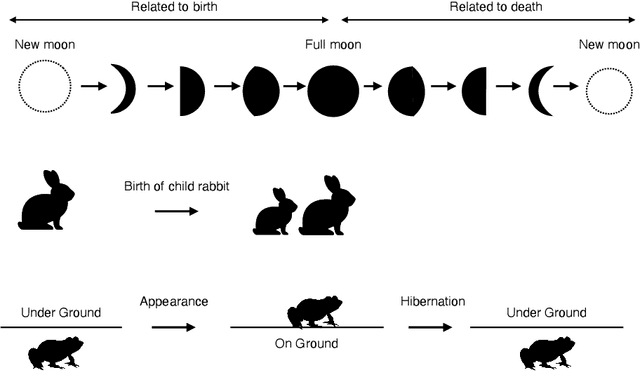
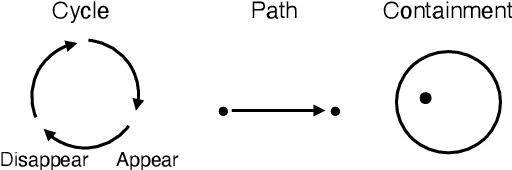
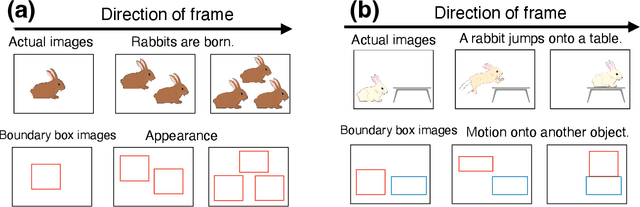
Recent machine learning algorithms such as neural networks can classify objects and actions in video frames with high accuracy. Here, I discuss a classification of objects based on basal dynamic patterns referencing one tradition, the link between rabbit, toad, and the Moon, which can be seen in several cultures. In order for them to be classified into one class, a basic pattern of behavior (cyclic appearance and disappearance) works as a feature point. A static character such as the shape and time scale of the behavior are not essential for this classification. In cognitive semantics, image schemas are introduced to describe basal patterns of events. If learning of these image schemas is attained, a machine may be able to categorize rabbit, toad, and the Moon as the same class. For learning, video frames that show boundary boxes or segmentation may be helpful. Although this discussion is preliminary and many tasks remain to be solved, the classification based on basal behaviors can be an important topic for cognitive processes and computer science.
Hierarchical entropy and domain interaction to understand the structure in an image
Apr 20, 2021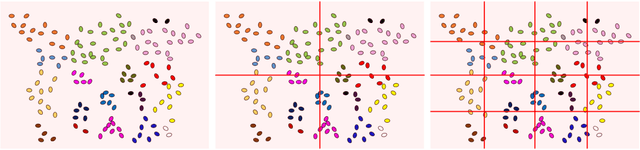
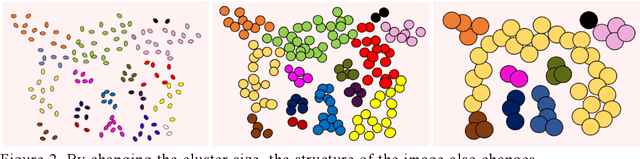
In this study, we devise a model that introduces two hierarchies into information entropy. The two hierarchies are the size of the region for which entropy is calculated and the size of the component that determines whether the structures in the image are integrated or not. And this model uses two indicators, hierarchical entropy and domain interaction. Both indicators increase or decrease due to the integration or fragmentation of the structure in the image. It aims to help people interpret and explain what the structure in an image looks like from two indicators that change with the size of the region and the component. First, we conduct experiments using images and qualitatively evaluate how the two indicators change. Next, we explain the relationship with the hidden structure of Vermeer's girl with a pearl earring using the change of hierarchical entropy. Finally, we clarify the relationship between the change of domain interaction and the appropriate segment result of the image by an experiment using a questionnaire.
CD$^2$-pFed: Cyclic Distillation-guided Channel Decoupling for Model Personalization in Federated Learning
Apr 08, 2022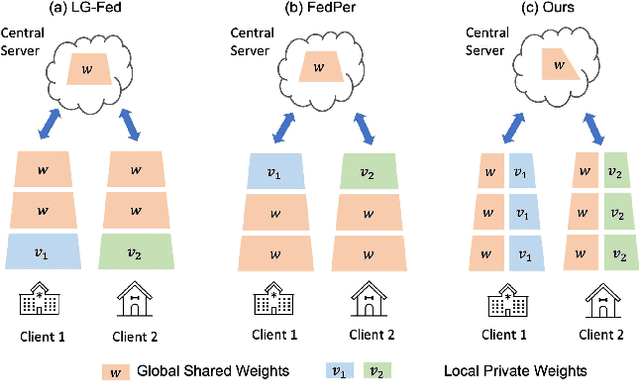
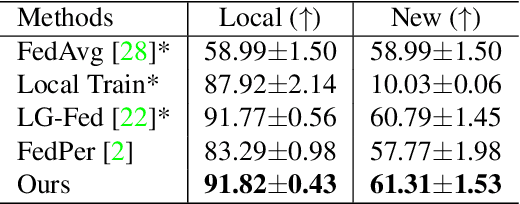
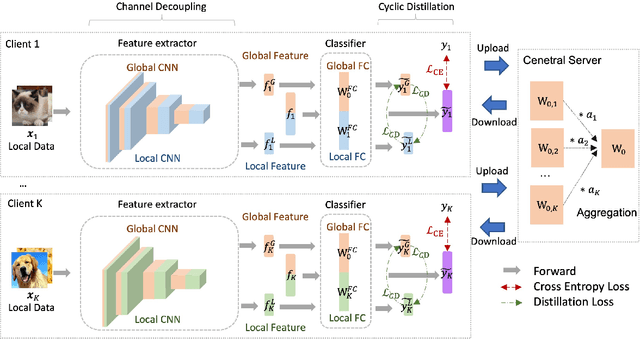
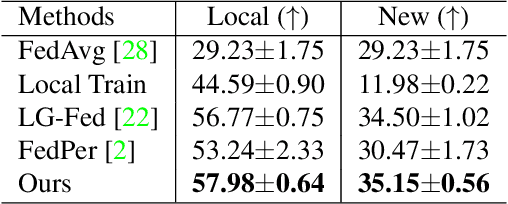
Federated learning (FL) is a distributed learning paradigm that enables multiple clients to collaboratively learn a shared global model. Despite the recent progress, it remains challenging to deal with heterogeneous data clients, as the discrepant data distributions usually prevent the global model from delivering good generalization ability on each participating client. In this paper, we propose CD^2-pFed, a novel Cyclic Distillation-guided Channel Decoupling framework, to personalize the global model in FL, under various settings of data heterogeneity. Different from previous works which establish layer-wise personalization to overcome the non-IID data across different clients, we make the first attempt at channel-wise assignment for model personalization, referred to as channel decoupling. To further facilitate the collaboration between private and shared weights, we propose a novel cyclic distillation scheme to impose a consistent regularization between the local and global model representations during the federation. Guided by the cyclical distillation, our channel decoupling framework can deliver more accurate and generalized results for different kinds of heterogeneity, such as feature skew, label distribution skew, and concept shift. Comprehensive experiments on four benchmarks, including natural image and medical image analysis tasks, demonstrate the consistent effectiveness of our method on both local and external validations.