 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Behavioral Economics Approach to Interpretable Deep Image Classification. Rationally Inattentive Utility Maximization Explains Deep Image Classification
Feb 16, 2021
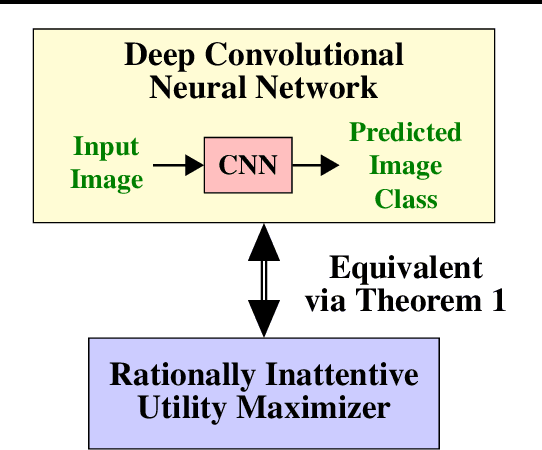

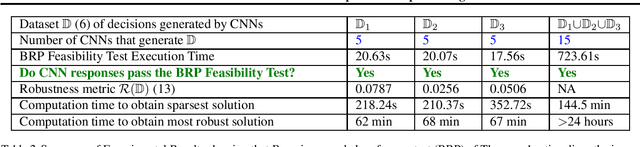
Are deep convolutional neural networks (CNNs) for image classification consistent with utility maximization behavior with information acquisition costs? This paper demonstrates the remarkable result that a deep CNN behaves equivalently (in terms of necessary and sufficient conditions) to a rationally inattentive utility maximizer, a model extensively used in behavioral economics to explain human decision making. This implies that a deep CNN has a parsimonious representation in terms of simple intuitive human-like decision parameters, namely, a utility function and an information acquisition cost. Also the reconstructed utility function that rationalizes the decisions of the deep CNNs, yields a useful preference order amongst the image classes (hypotheses).
QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation
Mar 16, 2022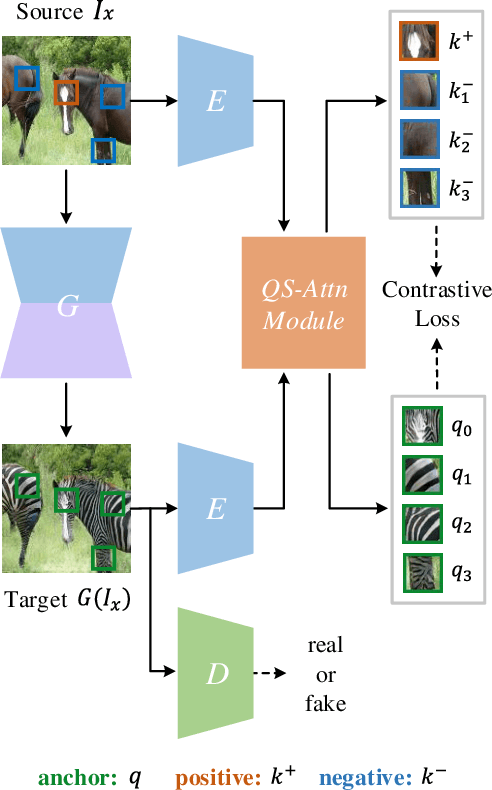
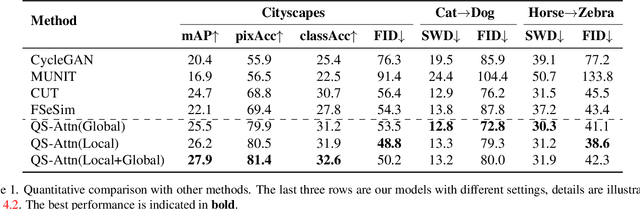

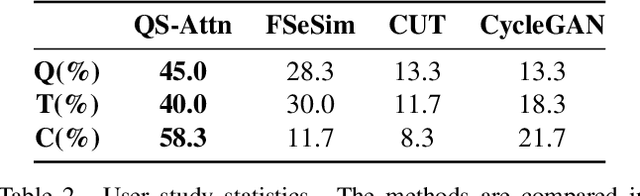
Unpaired image-to-image (I2I) translation often requires to maximize the mutual information between the source and the translated images across different domains, which is critical for the generator to keep the source content and prevent it from unnecessary modifications. The self-supervised contrastive learning has already been successfully applied in the I2I. By constraining features from the same location to be closer than those from different ones, it implicitly ensures the result to take content from the source. However, previous work uses the features from random locations to impose the constraint, which may not be appropriate since some locations contain less information of source domain. Moreover, the feature itself does not reflect the relation with others. This paper deals with these problems by intentionally selecting significant anchor points for contrastive learning. We design a query-selected attention (QS-Attn) module, which compares feature distances in the source domain, giving an attention matrix with a probability distribution in each row. Then we select queries according to their measurement of significance, computed from the distribution. The selected ones are regarded as anchors for contrastive loss. At the same time, the reduced attention matrix is employed to route features in both domains, so that source relations maintain in the synthesis. We validate our proposed method in three different I2I datasets, showing that it increases the image quality without adding learnable parameters.
Cross-Modality Multi-Atlas Segmentation Using Deep Neural Networks
Feb 04, 2022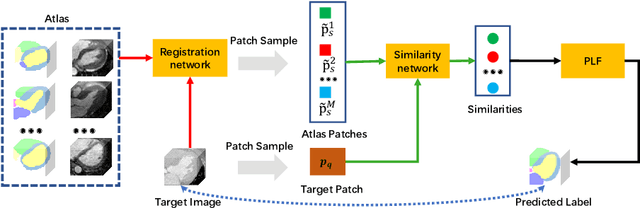
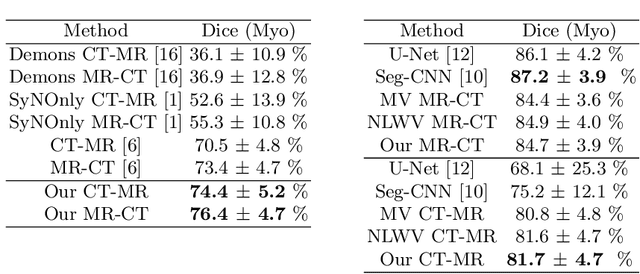
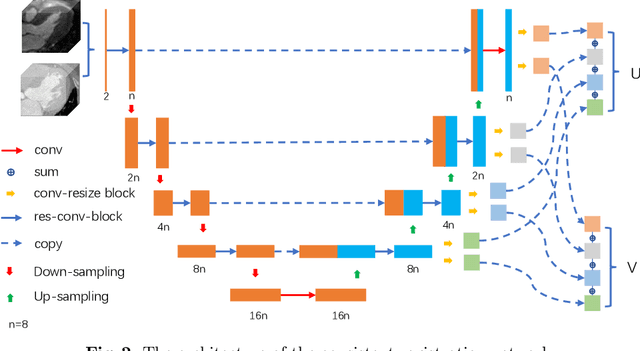
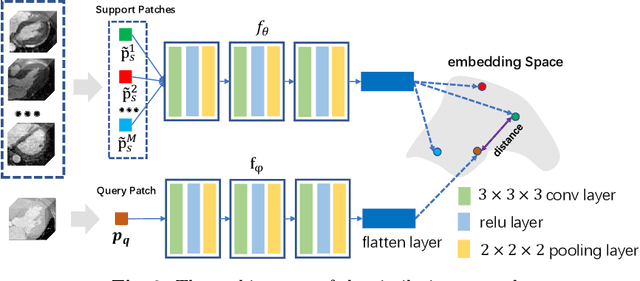
Multi-atlas segmentation (MAS) is a promising framework for medical image segmentation. Generally, MAS methods register multiple atlases, i.e., medical images with corresponding labels, to a target image; and the transformed atlas labels can be combined to generate target segmentation via label fusion schemes. Many conventional MAS methods employed the atlases from the same modality as the target image. However, the number of atlases with the same modality may be limited or even missing in many clinical applications. Besides, conventional MAS methods suffer from the computational burden of registration or label fusion procedures. In this work, we design a novel cross-modality MAS framework, which uses available atlases from a certain modality to segment a target image from another modality. To boost the computational efficiency of the framework, both the image registration and label fusion are achieved by well-designed deep neural networks. For the atlas-to-target image registration, we propose a bi-directional registration network (BiRegNet), which can efficiently align images from different modalities. For the label fusion, we design a similarity estimation network (SimNet), which estimates the fusion weight of each atlas by measuring its similarity to the target image. SimNet can learn multi-scale information for similarity estimation to improve the performance of label fusion. The proposed framework was evaluated by the left ventricle and liver segmentation tasks on the MM-WHS and CHAOS datasets, respectively. Results have shown that the framework is effective for cross-modality MAS in both registration and label fusion. The code will be released publicly on \url{https://github.com/NanYoMy/cmmas} once the manuscript is accepted.
High-resolution Coastline Extraction in SAR Images via MISP-GGD Superpixel Segmentation
Mar 05, 2022


High accuracy coastline/shoreline extraction from SAR imagery is a crucial step in a number of maritime and coastal monitoring applications. We present a method based on image segmentation using the Generalised Gamma Mixture Model superpixel algorithm (MISP-GGD). MISP-GGD produces superpixels adhering with great accuracy to object edges in the image, such as the coastline. Unsupervised clustering of the generated superpixels according to textural and radiometric features allows for generation of a land/water mask from which a highly accurate coastline can be extracted. We present results of our proposed method on a number of SAR images of varying characteristics.
UAMD-Net: A Unified Adaptive Multimodal Neural Network for Dense Depth Completion
Apr 16, 2022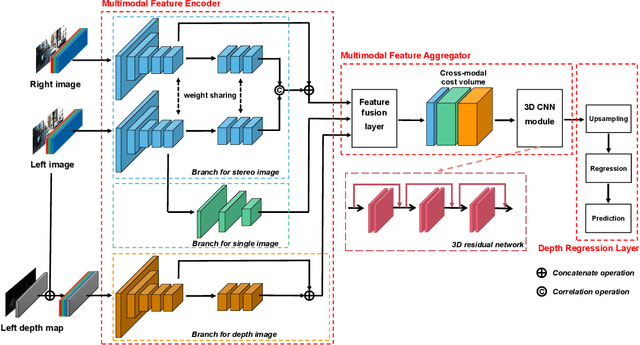
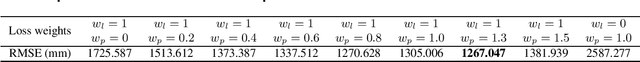
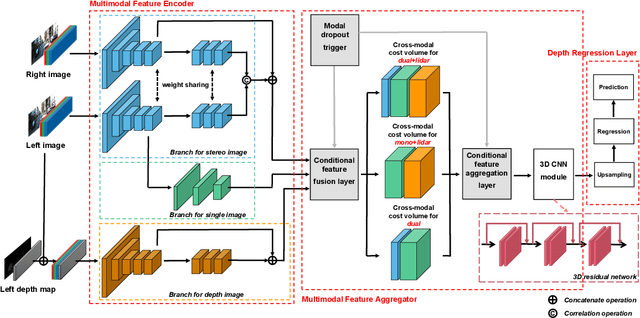
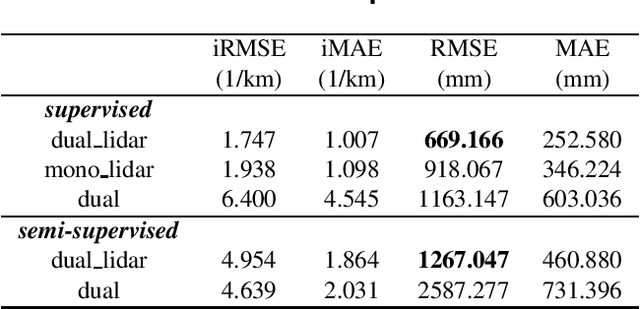
Depth prediction is a critical problem in robotics applications especially autonomous driving. Generally, depth prediction based on binocular stereo matching and fusion of monocular image and laser point cloud are two mainstream methods. However, the former usually suffers from overfitting while building cost volume, and the latter has a limited generalization due to the lack of geometric constraint. To solve these problems, we propose a novel multimodal neural network, namely UAMD-Net, for dense depth completion based on fusion of binocular stereo matching and the weak constrain from the sparse point clouds. Specifically, the sparse point clouds are converted to sparse depth map and sent to the multimodal feature encoder (MFE) with binocular image, constructing a cross-modal cost volume. Then, it will be further processed by the multimodal feature aggregator (MFA) and the depth regression layer. Furthermore, the existing multimodal methods ignore the problem of modal dependence, that is, the network will not work when a certain modal input has a problem. Therefore, we propose a new training strategy called Modal-dropout which enables the network to be adaptively trained with multiple modal inputs and inference with specific modal inputs. Benefiting from the flexible network structure and adaptive training method, our proposed network can realize unified training under various modal input conditions. Comprehensive experiments conducted on KITTI depth completion benchmark demonstrate that our method produces robust results and outperforms other state-of-the-art methods.
SeqNetVLAD vs PointNetVLAD: Image Sequence vs 3D Point Clouds for Day-Night Place Recognition
Jun 22, 2021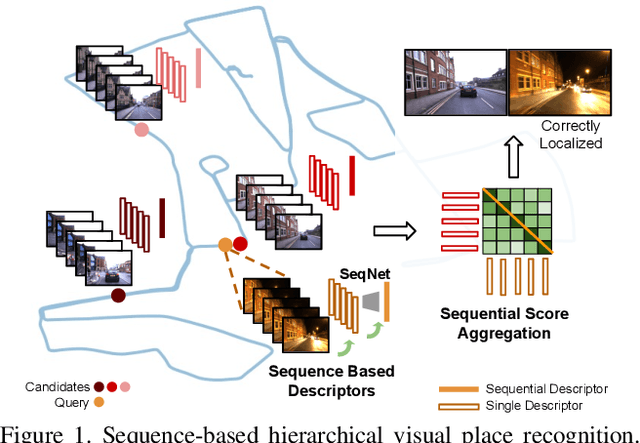
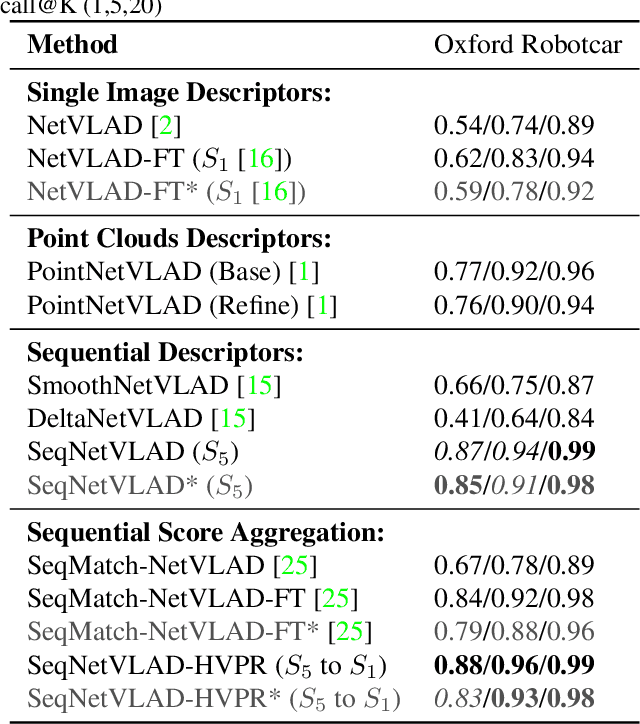
Place Recognition is a crucial capability for mobile robot localization and navigation. Image-based or Visual Place Recognition (VPR) is a challenging problem as scene appearance and camera viewpoint can change significantly when places are revisited. Recent VPR methods based on ``sequential representations'' have shown promising results as compared to traditional sequence score aggregation or single image based techniques. In parallel to these endeavors, 3D point clouds based place recognition is also being explored following the advances in deep learning based point cloud processing. However, a key question remains: is an explicit 3D structure based place representation always superior to an implicit ``spatial'' representation based on sequence of RGB images which can inherently learn scene structure. In this extended abstract, we attempt to compare these two types of methods by considering a similar ``metric span'' to represent places. We compare a 3D point cloud based method (PointNetVLAD) with image sequence based methods (SeqNet and others) and showcase that image sequence based techniques approach, and can even surpass, the performance achieved by point cloud based methods for a given metric span. These performance variations can be attributed to differences in data richness of input sensors as well as data accumulation strategies for a mobile robot. While a perfect apple-to-apple comparison may not be feasible for these two different modalities, the presented comparison takes a step in the direction of answering deeper questions regarding spatial representations, relevant to several applications like Autonomous Driving and Augmented/Virtual Reality. Source code available publicly https://github.com/oravus/seqNet.
Discrete-continuous Action Space Policy Gradient-based Attention for Image-Text Matching
Apr 21, 2021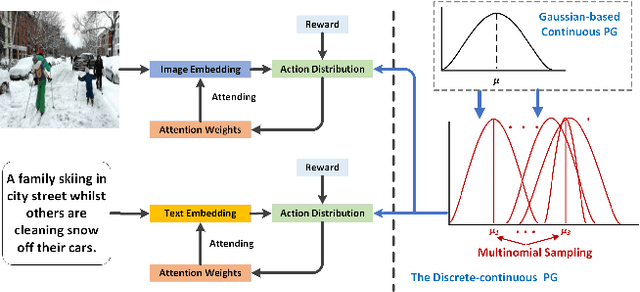
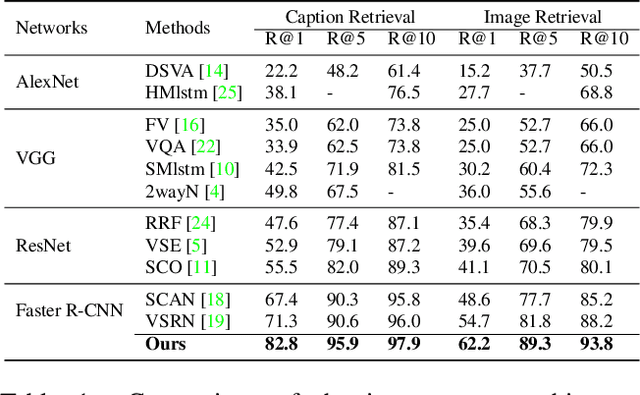
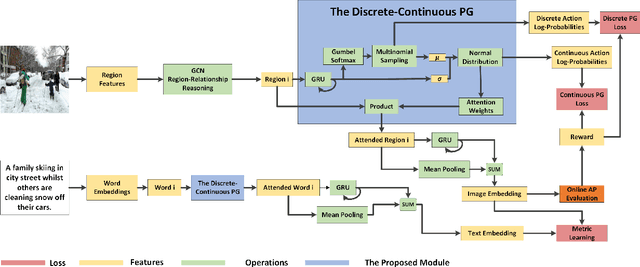
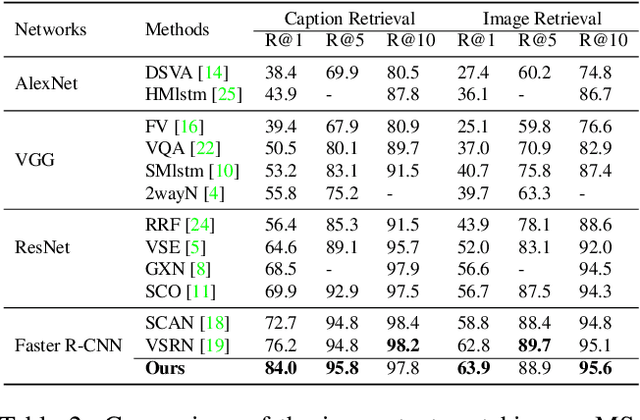
Image-text matching is an important multi-modal task with massive applications. It tries to match the image and the text with similar semantic information. Existing approaches do not explicitly transform the different modalities into a common space. Meanwhile, the attention mechanism which is widely used in image-text matching models does not have supervision. We propose a novel attention scheme which projects the image and text embedding into a common space and optimises the attention weights directly towards the evaluation metrics. The proposed attention scheme can be considered as a kind of supervised attention and requiring no additional annotations. It is trained via a novel Discrete-continuous action space policy gradient algorithm, which is more effective in modelling complex action space than previous continuous action space policy gradient. We evaluate the proposed methods on two widely-used benchmark datasets: Flickr30k and MS-COCO, outperforming the previous approaches by a large margin.
Toward Zero-Shot Unsupervised Image-to-Image Translation
Jul 28, 2020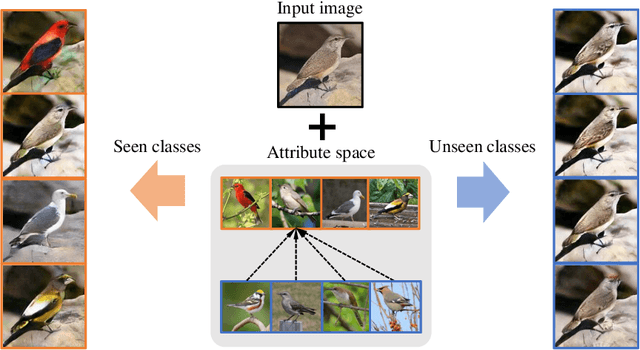
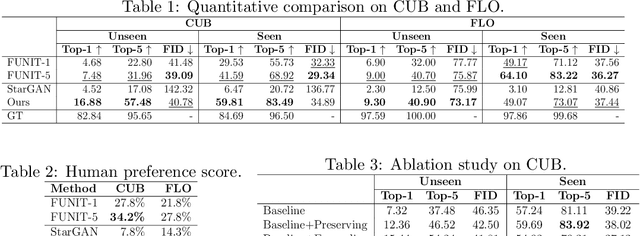
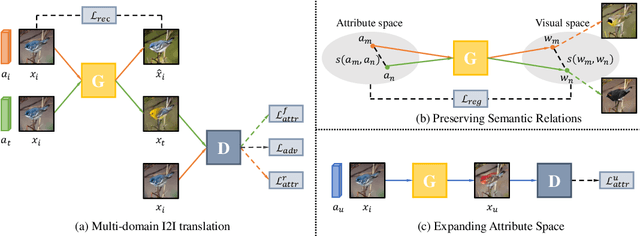

Recent studies have shown remarkable success in unsupervised image-to-image translation. However, if there has no access to enough images in target classes, learning a mapping from source classes to the target classes always suffers from mode collapse, which limits the application of the existing methods. In this work, we propose a zero-shot unsupervised image-to-image translation framework to address this limitation, by associating categories with their side information like attributes. To generalize the translator to previous unseen classes, we introduce two strategies for exploiting the space spanned by the semantic attributes. Specifically, we propose to preserve semantic relations to the visual space and expand attribute space by utilizing attribute vectors of unseen classes, thus encourage the translator to explore the modes of unseen classes. Quantitative and qualitative results on different datasets demonstrate the effectiveness of our proposed approach. Moreover, we demonstrate that our framework can be applied to many tasks, such as zero-shot classification and fashion design.
Give Me Your Attention: Dot-Product Attention Considered Harmful for Adversarial Patch Robustness
Mar 25, 2022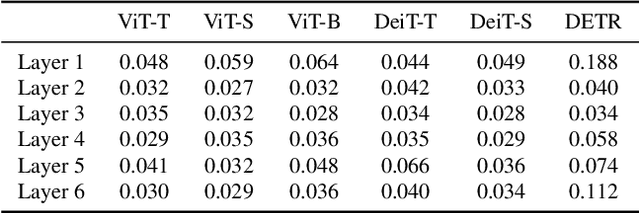
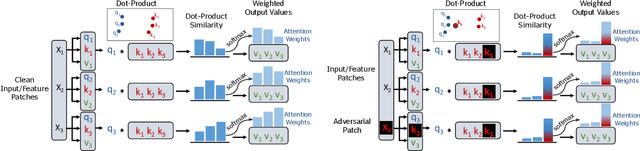
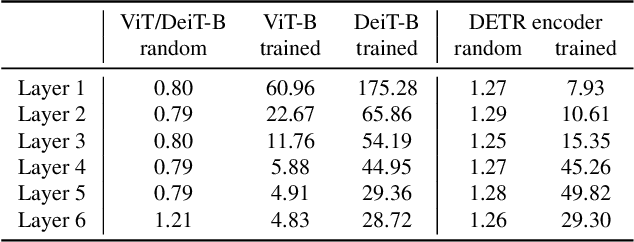
Neural architectures based on attention such as vision transformers are revolutionizing image recognition. Their main benefit is that attention allows reasoning about all parts of a scene jointly. In this paper, we show how the global reasoning of (scaled) dot-product attention can be the source of a major vulnerability when confronted with adversarial patch attacks. We provide a theoretical understanding of this vulnerability and relate it to an adversary's ability to misdirect the attention of all queries to a single key token under the control of the adversarial patch. We propose novel adversarial objectives for crafting adversarial patches which target this vulnerability explicitly. We show the effectiveness of the proposed patch attacks on popular image classification (ViTs and DeiTs) and object detection models (DETR). We find that adversarial patches occupying 0.5% of the input can lead to robust accuracies as low as 0% for ViT on ImageNet, and reduce the mAP of DETR on MS COCO to less than 3%.
Learned Block-based Hybrid Image Compression
Jan 18, 2021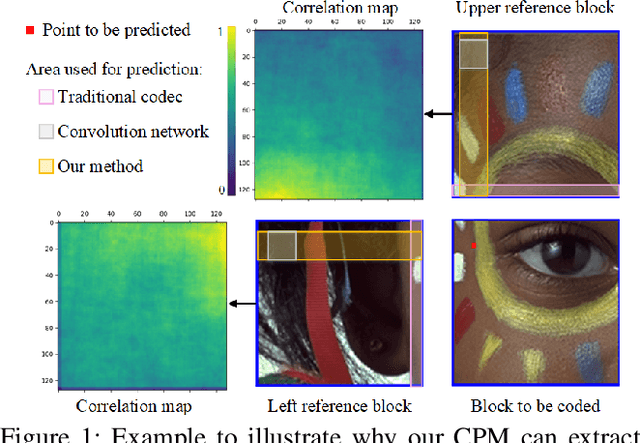
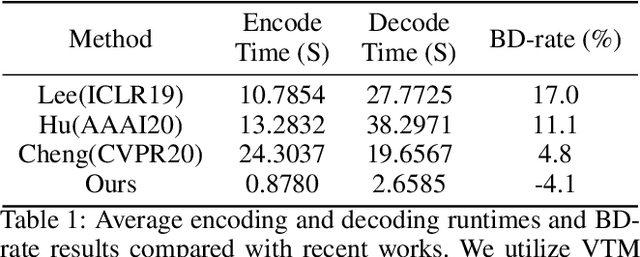
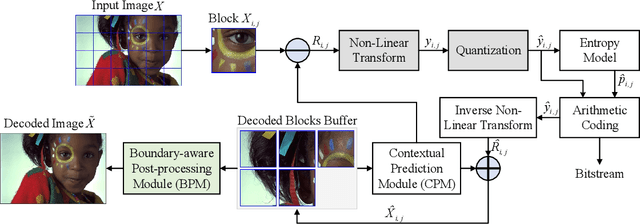
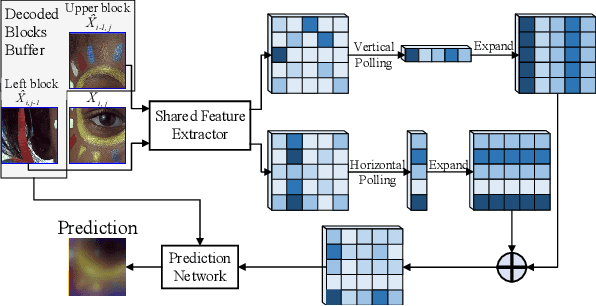
Recent works on learned image compression perform encoding and decoding processes in a full-resolution manner, resulting in two problems when deployed for practical applications. First, parallel acceleration of the autoregressive entropy model cannot be achieved due to serial decoding. Second, full-resolution inference often causes the out-of-memory(OOM) problem with limited GPU resources, especially for high-resolution images. Block partition is a good design choice to handle the above issues, but it brings about new challenges in reducing the redundancy between blocks and eliminating block effects. To tackle the above challenges, this paper provides a learned block-based hybrid image compression (LBHIC) framework. Specifically, we introduce explicit intra prediction into a learned image compression framework to utilize the relation among adjacent blocks. Superior to context modeling by linear weighting of neighbor pixels in traditional codecs, we propose a contextual prediction module (CPM) to better capture long-range correlations by utilizing the strip pooling to extract the most relevant information in neighboring latent space, thus achieving effective information prediction. Moreover, to alleviate blocking artifacts, we further propose a boundary-aware postprocessing module (BPM) with the edge importance taken into account. Extensive experiments demonstrate that the proposed LBHIC codec outperforms the VVC, with a bit-rate conservation of 4.1%, and reduces the decoding time by approximately 86.7% compared with that of state-of-the-art learned image compression methods.