 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Captioning through Image Transformer
Apr 29, 2020

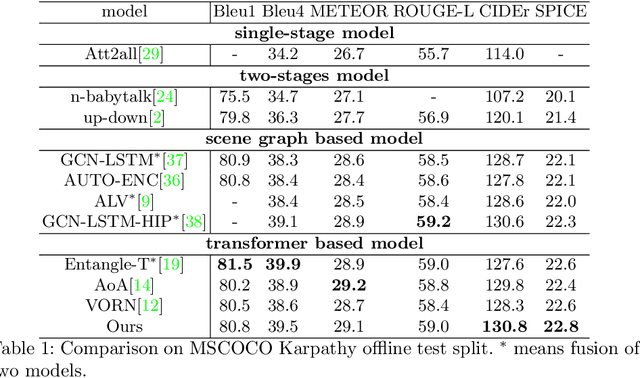
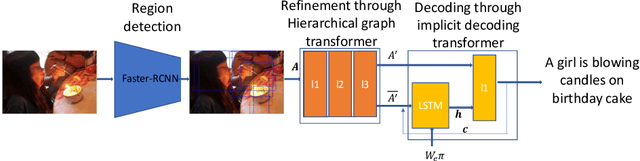
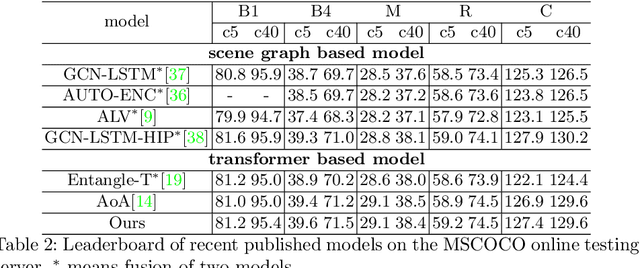
Automatic captioning of images is a task that combines the challenges of image analysis and text generation. One important aspect in captioning is the notion of attention: How to decide what to describe and in which order. Inspired by the successes in text analysis and translation, previous work have proposed the \textit{transformer} architecture for image captioning. However, the structure between the \textit{semantic units} in images (usually the detected regions from object detection model) and sentences (each single word) is different. Limited work has been done to adapt the transformer's internal architecture to images. In this work, we introduce the \textbf{\textit{image transformer}}, which consists of a modified encoding transformer and an implicit decoding transformer, motivated by the relative spatial relationship between image regions. Our design widen the original transformer layer's inner architecture to adapt to the structure of images. With only regions feature as inputs, our model achieves new state-of-the-art performance on both MSCOCO offline and online testing benchmarks.
Source-Free Domain Adaptive Fundus Image Segmentation with Denoised Pseudo-Labeling
Sep 19, 2021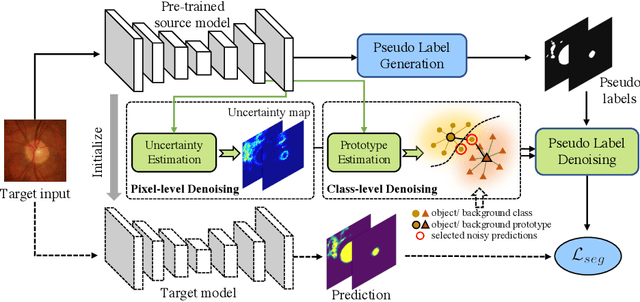
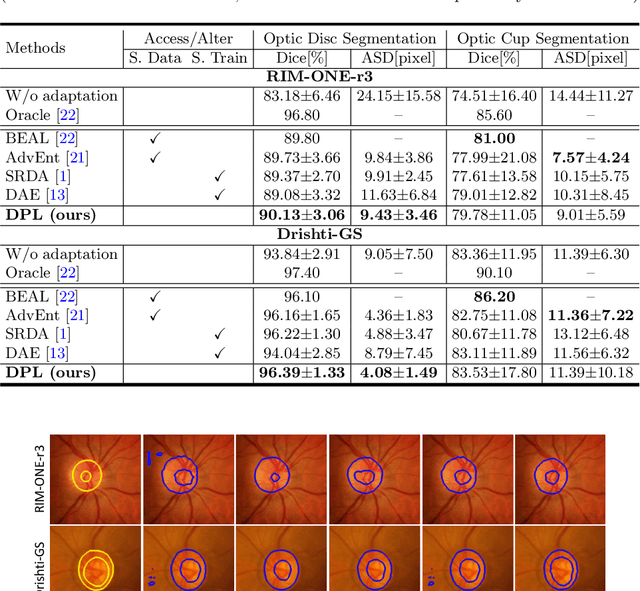

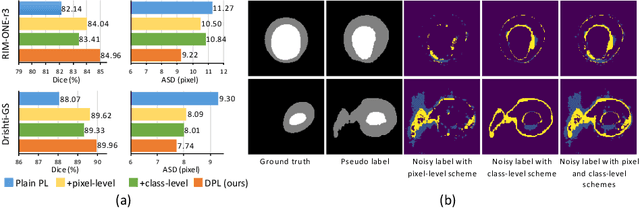
Domain adaptation typically requires to access source domain data to utilize their distribution information for domain alignment with the target data. However, in many real-world scenarios, the source data may not be accessible during the model adaptation in the target domain due to privacy issue. This paper studies the practical yet challenging source-free unsupervised domain adaptation problem, in which only an existing source model and the unlabeled target data are available for model adaptation. We present a novel denoised pseudo-labeling method for this problem, which effectively makes use of the source model and unlabeled target data to promote model self-adaptation from pseudo labels. Importantly, considering that the pseudo labels generated from source model are inevitably noisy due to domain shift, we further introduce two complementary pixel-level and class-level denoising schemes with uncertainty estimation and prototype estimation to reduce noisy pseudo labels and select reliable ones to enhance the pseudo-labeling efficacy. Experimental results on cross-domain fundus image segmentation show that without using any source images or altering source training, our approach achieves comparable or even higher performance than state-of-the-art source-dependent unsupervised domain adaptation methods.
Transparency strategy-based data augmentation for BI-RADS classification of mammograms
Mar 20, 2022

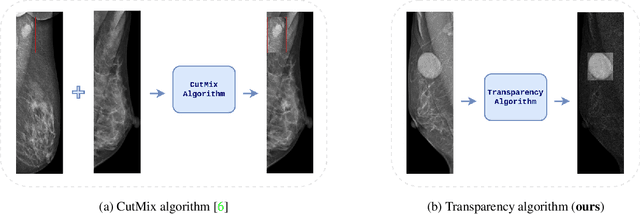
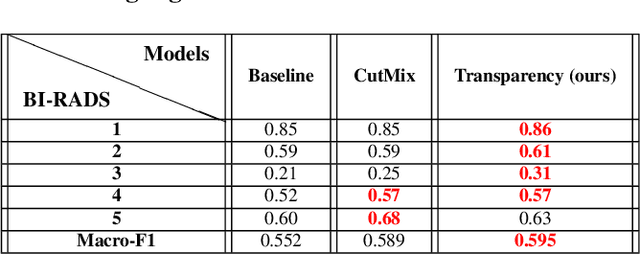
Image augmentation techniques have been widely investigated to improve the performance of deep learning (DL) algorithms on mammography classification tasks. Recent methods have proved the efficiency of image augmentation on data deficiency or data imbalance issues. In this paper, we propose a novel transparency strategy to boost the Breast Imaging Reporting and Data System (BI-RADS) scores of mammograms classifier. The proposed approach utilizes the Region of Interest (ROI) information to generate more high-risk training examples from original images. Our extensive experiments were conducted on our benchmark mammography dataset. The experiment results show that the proposed approach surpasses current state-of-the-art data augmentation techniques such as Upsampling or CutMix. The study highlights that the transparency method is more effective than other augmentation strategies for BI-RADS classification and can be widely applied for our computer vision tasks.
AS2T: Arbitrary Source-To-Target Adversarial Attack on Speaker Recognition Systems
Jun 07, 2022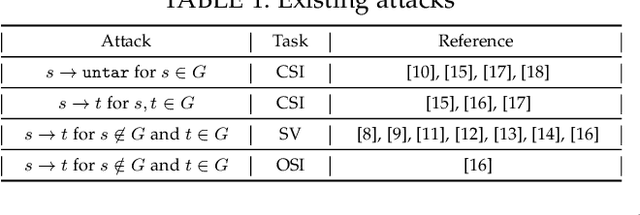
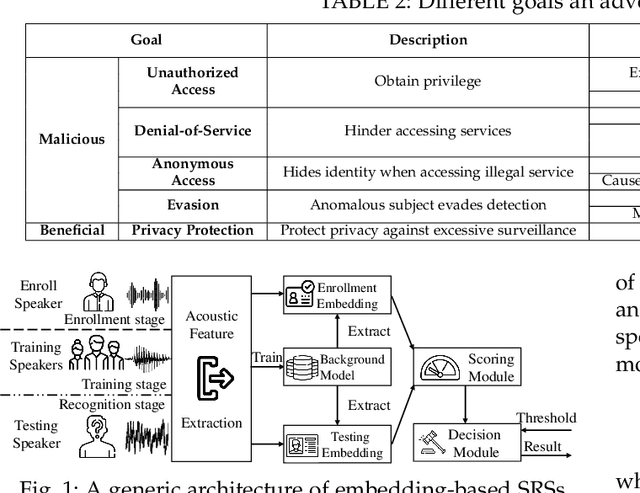
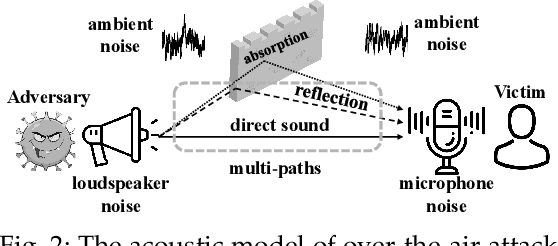
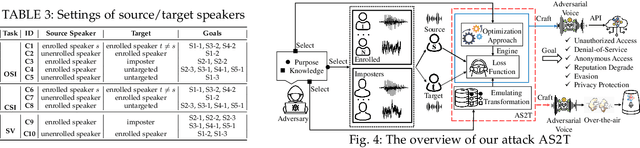
Recent work has illuminated the vulnerability of speaker recognition systems (SRSs) against adversarial attacks, raising significant security concerns in deploying SRSs. However, they considered only a few settings (e.g., some combinations of source and target speakers), leaving many interesting and important settings in real-world attack scenarios alone. In this work, we present AS2T, the first attack in this domain which covers all the settings, thus allows the adversary to craft adversarial voices using arbitrary source and target speakers for any of three main recognition tasks. Since none of the existing loss functions can be applied to all the settings, we explore many candidate loss functions for each setting including the existing and newly designed ones. We thoroughly evaluate their efficacy and find that some existing loss functions are suboptimal. Then, to improve the robustness of AS2T towards practical over-the-air attack, we study the possible distortions occurred in over-the-air transmission, utilize different transformation functions with different parameters to model those distortions, and incorporate them into the generation of adversarial voices. Our simulated over-the-air evaluation validates the effectiveness of our solution in producing robust adversarial voices which remain effective under various hardware devices and various acoustic environments with different reverberation, ambient noises, and noise levels. Finally, we leverage AS2T to perform thus far the largest-scale evaluation to understand transferability among 14 diverse SRSs. The transferability analysis provides many interesting and useful insights which challenge several findings and conclusion drawn in previous works in the image domain. Our study also sheds light on future directions of adversarial attacks in the speaker recognition domain.
Image Translation via Fine-grained Knowledge Transfer
Dec 21, 2020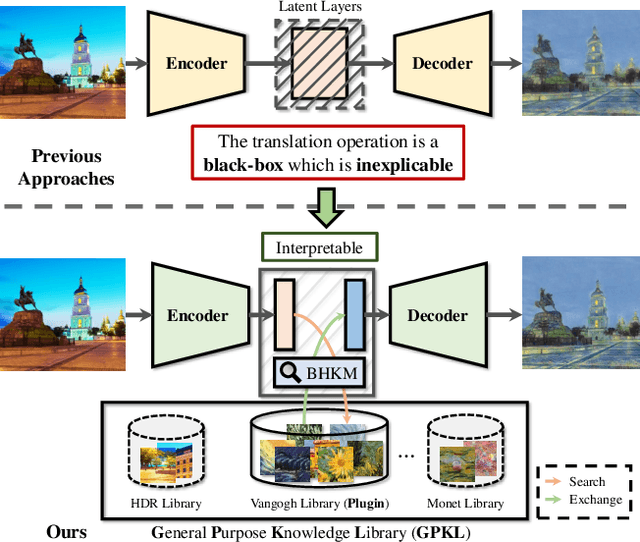



Prevailing image-translation frameworks mostly seek to process images via the end-to-end style, which has achieved convincing results. Nonetheless, these methods lack interpretability and are not scalable on different image-translation tasks (e.g., style transfer, HDR, etc.). In this paper, we propose an interpretable knowledge-based image-translation framework, which realizes the image-translation through knowledge retrieval and transfer. In details, the framework constructs a plug-and-play and model-agnostic general purpose knowledge library, remembering task-specific styles, tones, texture patterns, etc. Furthermore, we present a fast ANN searching approach, Bandpass Hierarchical K-Means (BHKM), to cope with the difficulty of searching in the enormous knowledge library. Extensive experiments well demonstrate the effectiveness and feasibility of our framework in different image-translation tasks. In particular, backtracking experiments verify the interpretability of our method. Our code soon will be available at https://github.com/AceSix/Knowledge_Transfer.
Learning image quality assessment by reinforcing task amenable data selection
Feb 15, 2021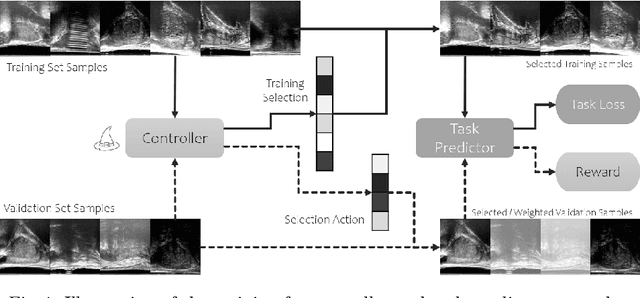

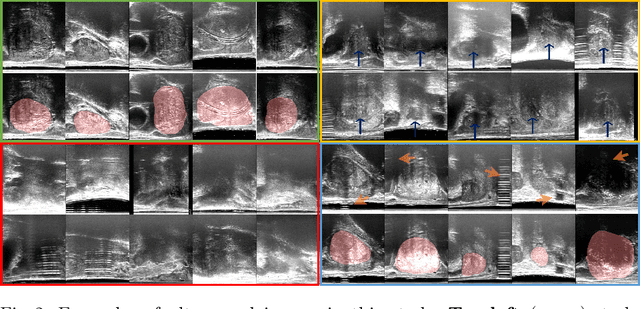
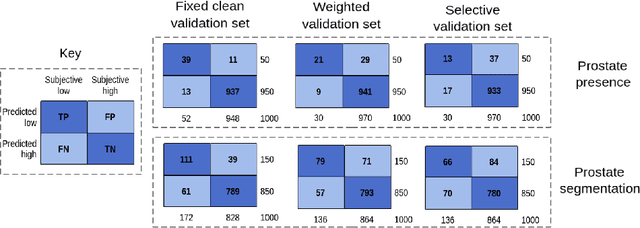
In this paper, we consider a type of image quality assessment as a task-specific measurement, which can be used to select images that are more amenable to a given target task, such as image classification or segmentation. We propose to train simultaneously two neural networks for image selection and a target task using reinforcement learning. A controller network learns an image selection policy by maximising an accumulated reward based on the target task performance on the controller-selected validation set, whilst the target task predictor is optimised using the training set. The trained controller is therefore able to reject those images that lead to poor accuracy in the target task. In this work, we show that the controller-predicted image quality can be significantly different from the task-specific image quality labels that are manually defined by humans. Furthermore, we demonstrate that it is possible to learn effective image quality assessment without using a ``clean'' validation set, thereby avoiding the requirement for human labelling of images with respect to their amenability for the task. Using $6712$, labelled and segmented, clinical ultrasound images from $259$ patients, experimental results on holdout data show that the proposed image quality assessment achieved a mean classification accuracy of $0.94\pm0.01$ and a mean segmentation Dice of $0.89\pm0.02$, by discarding $5\%$ and $15\%$ of the acquired images, respectively. The significantly improved performance was observed for both tested tasks, compared with the respective $0.90\pm0.01$ and $0.82\pm0.02$ from networks without considering task amenability. This enables image quality feedback during real-time ultrasound acquisition among many other medical imaging applications.
Diverse Single Image Generation with Controllable Global Structure through Self-Attention
Feb 15, 2021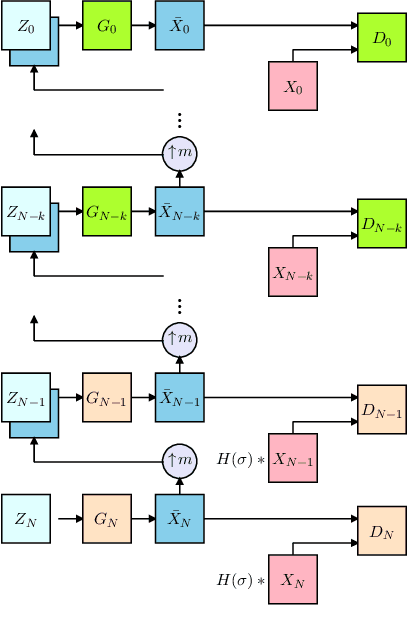

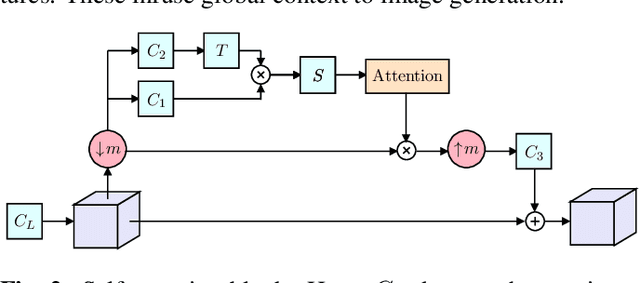
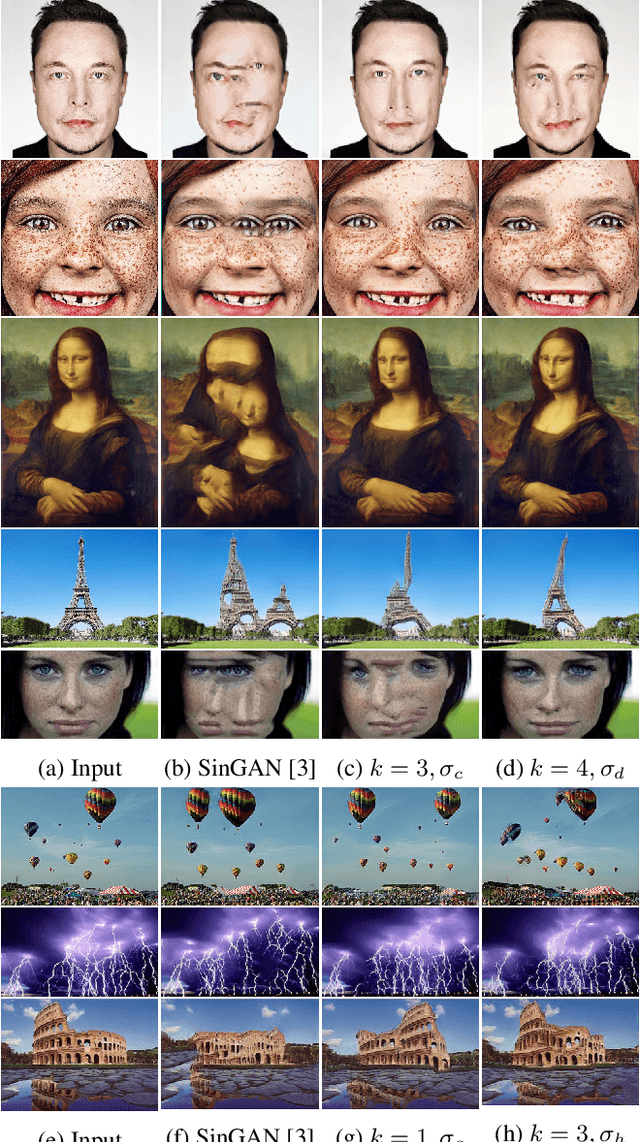
Image generation from a single image using generative adversarial networks is quite interesting due to the realism of generated images. However, recent approaches need improvement for such realistic and diverse image generation, when the global context of the image is important such as in face, animal, and architectural image generation. This is mainly due to the use of fewer convolutional layers for mainly capturing the patch statistics and, thereby, not being able to capture global statistics very well. We solve this problem by using attention blocks at selected scales and feeding a random Gaussian blurred image to the discriminator for training. Our results are visually better than the state-of-the-art particularly in generating images that require global context. The diversity of our image generation, measured using the average standard deviation of pixels, is also better.
GPU Acceleration for Synthetic Aperture Sonar Image Reconstruction
Jan 14, 2021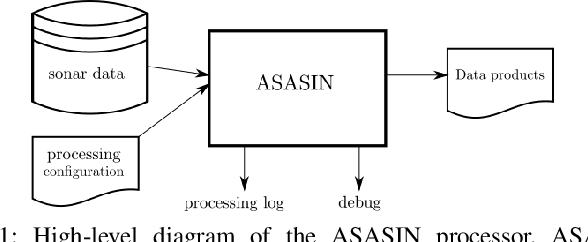
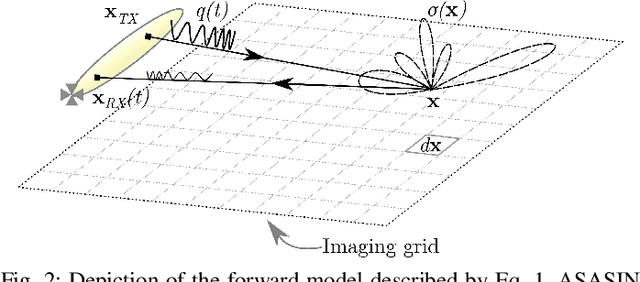
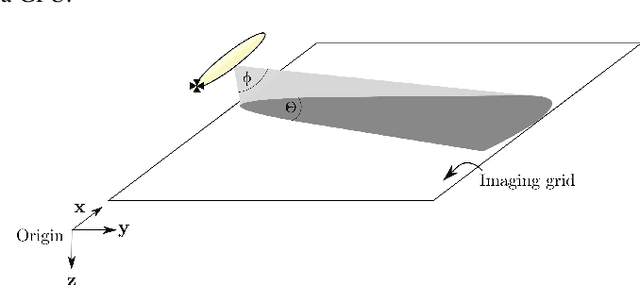
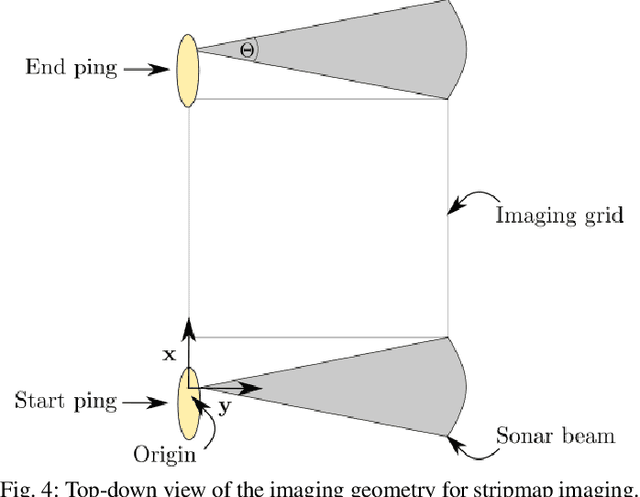
Synthetic aperture sonar (SAS) image reconstruction, or beamforming as it is often referred to within the SAS community, comprises a class of computationally intensive algorithms for creating coherent high-resolution imagery from successive spatially varying sonar pings. Image reconstruction is usually performed topside because of the large compute burden necessitated by the procedure. Historically, image reconstruction required significant assumptions in order to produce real-time imagery within an unmanned underwater vehicle's (UUV's) size, weight, and power (SWaP) constraints. However, these assumptions result in reduced image quality. In this work, we describe ASASIN, the Advanced Synthetic Aperture Sonar Imagining eNgine. ASASIN is a time domain backprojection image reconstruction suite utilizing graphics processing units (GPUs) allowing real-time operation on UUVs without sacrificing image quality. We describe several speedups employed in ASASIN allowing us to achieve this objective. Furthermore, ASASIN's signal processing chain is capable of producing 2D and 3D SAS imagery as we will demonstrate. Finally, we measure ASASIN's performance on a variety of GPUs and create a model capable of predicting performance. We demonstrate our model's usefulness in predicting run-time performance on desktop and embedded GPU hardware.
Contributor-Aware Defenses Against Adversarial Backdoor Attacks
May 28, 2022
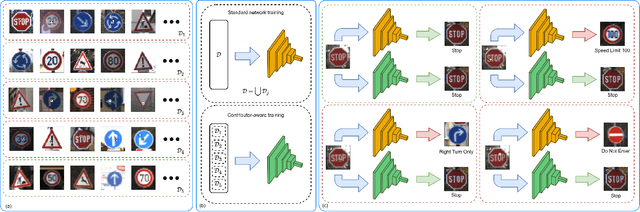
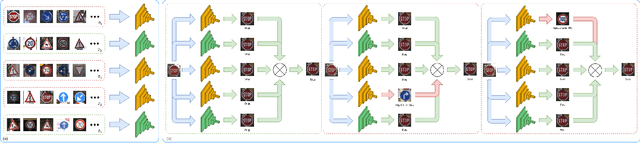
Deep neural networks for image classification are well-known to be vulnerable to adversarial attacks. One such attack that has garnered recent attention is the adversarial backdoor attack, which has demonstrated the capability to perform targeted misclassification of specific examples. In particular, backdoor attacks attempt to force a model to learn spurious relations between backdoor trigger patterns and false labels. In response to this threat, numerous defensive measures have been proposed; however, defenses against backdoor attacks focus on backdoor pattern detection, which may be unreliable against novel or unexpected types of backdoor pattern designs. We introduce a novel re-contextualization of the adversarial setting, where the presence of an adversary implicitly admits the existence of multiple database contributors. Then, under the mild assumption of contributor awareness, it becomes possible to exploit this knowledge to defend against backdoor attacks by destroying the false label associations. We propose a contributor-aware universal defensive framework for learning in the presence of multiple, potentially adversarial data sources that utilizes semi-supervised ensembles and learning from crowds to filter the false labels produced by adversarial triggers. Importantly, this defensive strategy is agnostic to backdoor pattern design, as it functions without needing -- or even attempting -- to perform either adversary identification or backdoor pattern detection during either training or inference. Our empirical studies demonstrate the robustness of the proposed framework against adversarial backdoor attacks from multiple simultaneous adversaries.
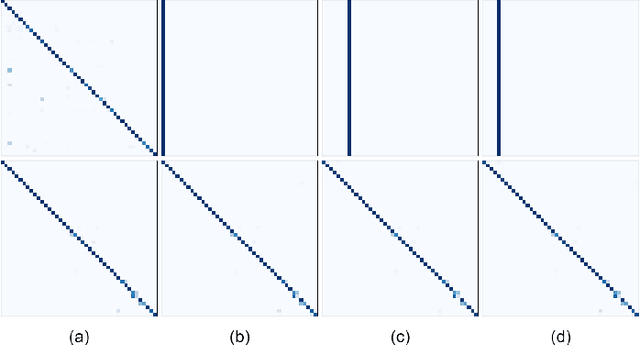
FisheyeHDK: Hyperbolic Deformable Kernel Learning for Ultra-Wide Field-of-View Image Recognition
Mar 14, 2022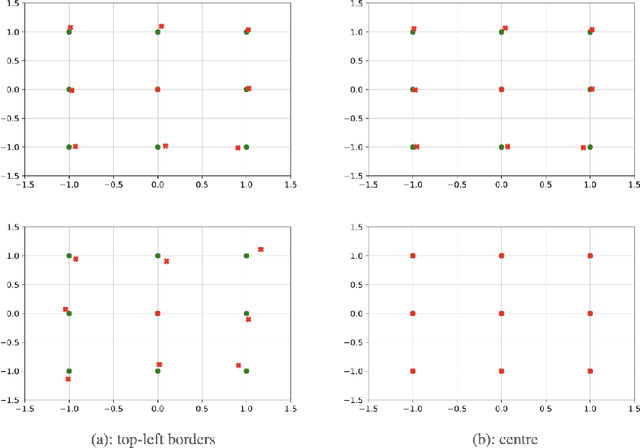

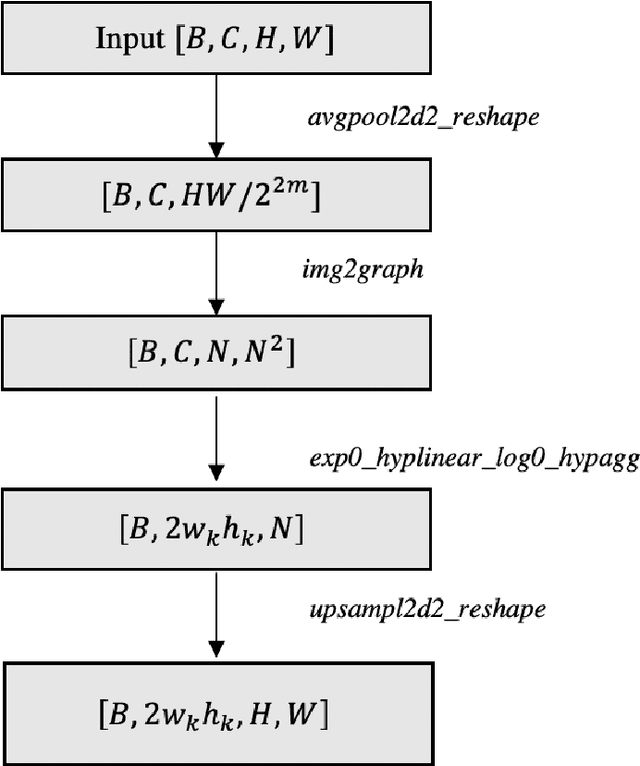
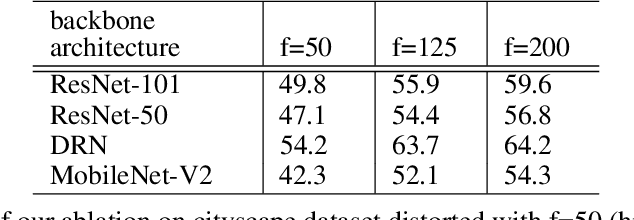
Conventional convolution neural networks (CNNs) trained on narrow Field-of-View (FoV) images are the state-of-the-art approaches for object recognition tasks. Some methods proposed the adaptation of CNNs to ultra-wide FoV images by learning deformable kernels. However, they are limited by the Euclidean geometry and their accuracy degrades under strong distortions caused by fisheye projections. In this work, we demonstrate that learning the shape of convolution kernels in non-Euclidean spaces is better than existing deformable kernel methods. In particular, we propose a new approach that learns deformable kernel parameters (positions) in hyperbolic space. FisheyeHDK is a hybrid CNN architecture combining hyperbolic and Euclidean convolution layers for positions and features learning. First, we provide an intuition of hyperbolic space for wide FoV images. Using synthetic distortion profiles, we demonstrate the effectiveness of our approach. We select two datasets - Cityscapes and BDD100K 2020 - of perspective images which we transform to fisheye equivalents at different scaling factors (analog to focal lengths). Finally, we provide an experiment on data collected by a real fisheye camera. Validations and experiments show that our approach improves existing deformable kernel methods for CNN adaptation on fisheye images.