 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fixed Point Iterations for SURE-based PSF Estimation for Image Deconvolution
Feb 26, 2022


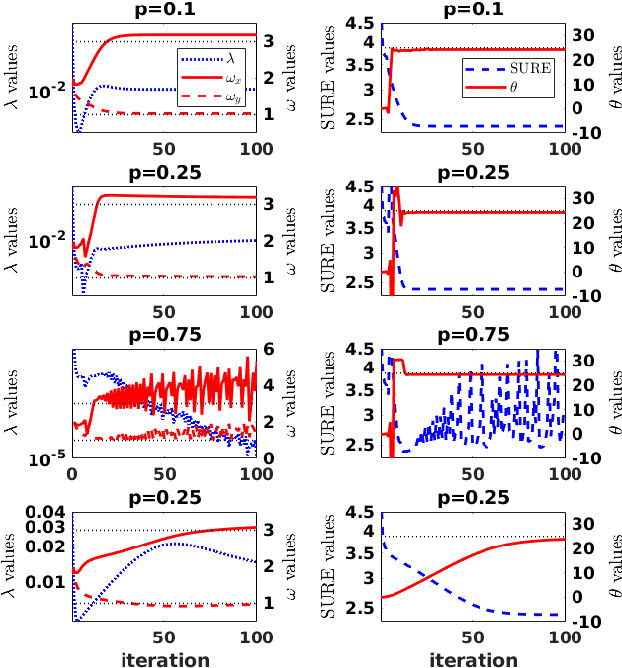
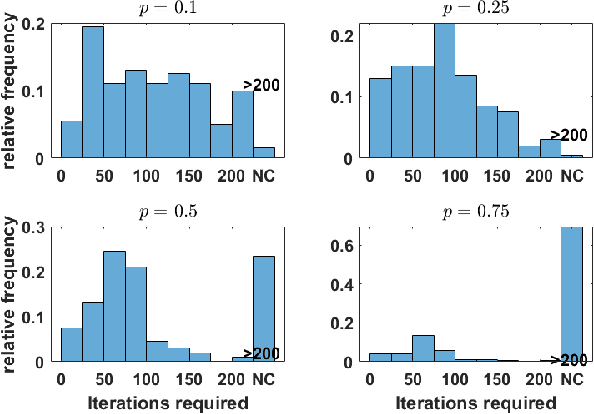
Stein's unbiased risk estimator (SURE) has been shown to be an effective metric for determining optimal parameters for many applications. The topic of this article is focused on the use of SURE for determining parameters for blind deconvolution. The parameters include those that define the shape of the point spread function (PSF), as well as regularization parameters in the deconvolution formulas. Within this context, the optimal parameters are typically determined via a brute for search over the feasible parameter space. When multiple parameters are involved, this parameter search is prohibitively costly due to the curse of dimensionality. In this work, novel fixed point iterations are proposed for optimizing these parameters, which allows for rapid estimation of a relatively large number of parameters. We demonstrate that with some mild tuning of the optimization parameters, these fixed point methods typically converge to the ideal PSF parameters in relatively few iterations, e.g. 50-100, with each iteration requiring very low computational cost.
Evolving GAN Formulations for Higher Quality Image Synthesis
Feb 17, 2021

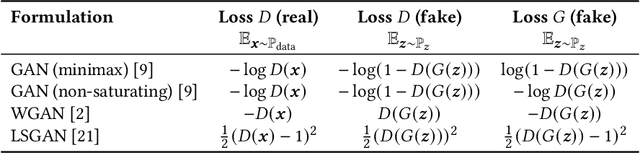
Generative Adversarial Networks (GANs) have extended deep learning to complex generation and translation tasks across different data modalities. However, GANs are notoriously difficult to train: Mode collapse and other instabilities in the training process often degrade the quality of the generated results, such as images. This paper presents a new technique called TaylorGAN for improving GANs by discovering customized loss functions for each of its two networks. The loss functions are parameterized as Taylor expansions and optimized through multiobjective evolution. On an image-to-image translation benchmark task, this approach qualitatively improves generated image quality and quantitatively improves two independent GAN performance metrics. It therefore forms a promising approach for applying GANs to more challenging tasks in the future.
A Linear Comb Filter for Event Flicker Removal
May 17, 2022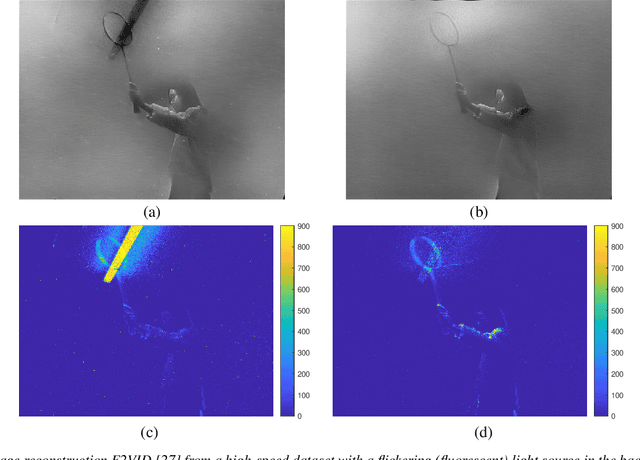
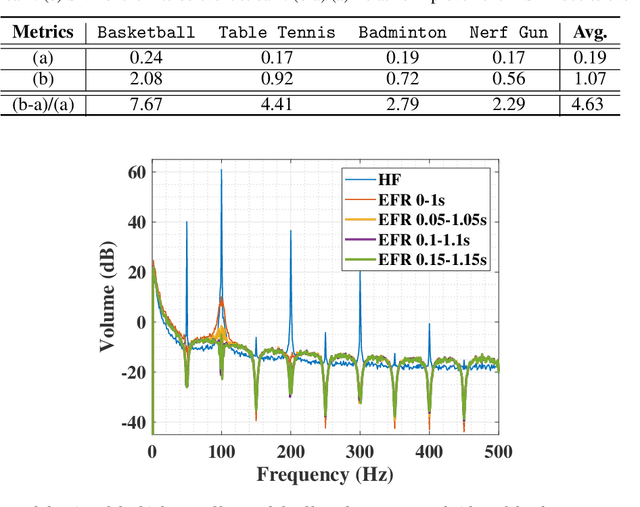
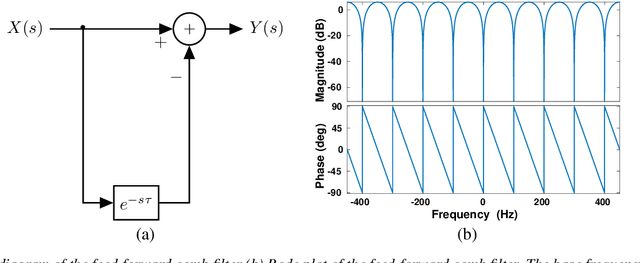
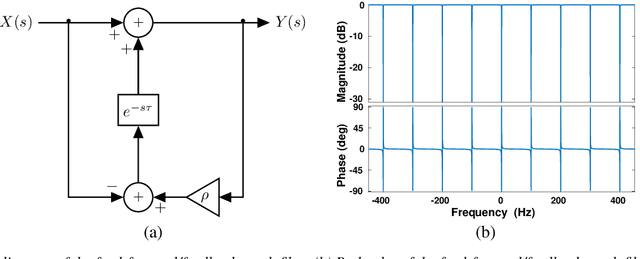
Event cameras are bio-inspired sensors that capture per-pixel asynchronous intensity change rather than the synchronous absolute intensity frames captured by a classical camera sensor. Such cameras are ideal for robotics applications since they have high temporal resolution, high dynamic range and low latency. However, due to their high temporal resolution, event cameras are particularly sensitive to flicker such as from fluorescent or LED lights. During every cycle from bright to dark, pixels that image a flickering light source generate many events that provide little or no useful information for a robot, swamping the useful data in the scene. In this paper, we propose a novel linear filter to preprocess event data to remove unwanted flicker events from an event stream. The proposed algorithm achieves over 4.6 times relative improvement in the signal-to-noise ratio when compared to the raw event stream due to the effective removal of flicker from fluorescent lighting. Thus, it is ideally suited to robotics applications that operate in indoor settings or scenes illuminated by flickering light sources.
Global Contrast Masked Autoencoders Are Powerful Pathological Representation Learners
May 21, 2022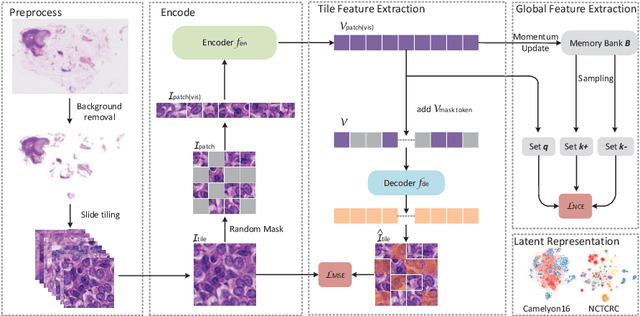
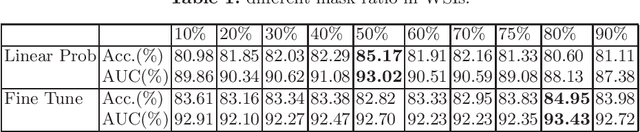

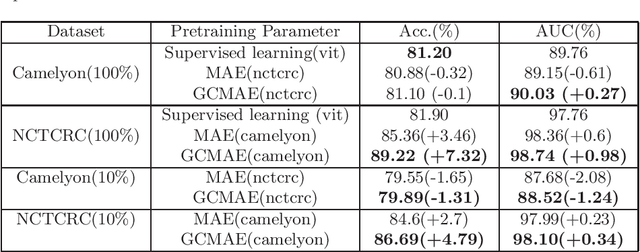
Based on digital whole slide scanning technique, artificial intelligence algorithms represented by deep learning have achieved remarkable results in the field of computational pathology. Compared with other medical images such as Computed Tomography (CT) or Magnetic Resonance Imaging (MRI), pathological images are more difficult to annotate, thus there is an extreme lack of data sets that can be used for supervised learning. In this study, a self-supervised learning (SSL) model, Global Contrast Masked Autoencoders (GCMAE), is proposed, which has the ability to represent both global and local domain-specific features of whole slide image (WSI), as well as excellent cross-data transfer ability. The Camelyon16 and NCTCRC datasets are used to evaluate the performance of our model. When dealing with transfer learning tasks with different data sets, the experimental results show that GCMAE has better linear classification accuracy than MAE, which can reach 81.10% and 89.22% respectively. Our method outperforms the previous state-of-the-art algorithm and even surpass supervised learning (improved by 3.86% on NCTCRC data sets). The source code of this paper is publicly available at https://github.com/StarUniversus/gcmae
Image Translation via Fine-grained Knowledge Transfer
Dec 21, 2020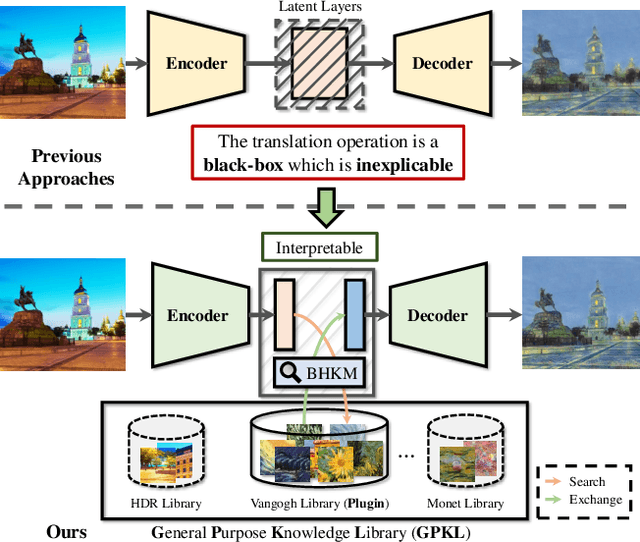



Prevailing image-translation frameworks mostly seek to process images via the end-to-end style, which has achieved convincing results. Nonetheless, these methods lack interpretability and are not scalable on different image-translation tasks (e.g., style transfer, HDR, etc.). In this paper, we propose an interpretable knowledge-based image-translation framework, which realizes the image-translation through knowledge retrieval and transfer. In details, the framework constructs a plug-and-play and model-agnostic general purpose knowledge library, remembering task-specific styles, tones, texture patterns, etc. Furthermore, we present a fast ANN searching approach, Bandpass Hierarchical K-Means (BHKM), to cope with the difficulty of searching in the enormous knowledge library. Extensive experiments well demonstrate the effectiveness and feasibility of our framework in different image-translation tasks. In particular, backtracking experiments verify the interpretability of our method. Our code soon will be available at https://github.com/AceSix/Knowledge_Transfer.
Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment
Mar 31, 2022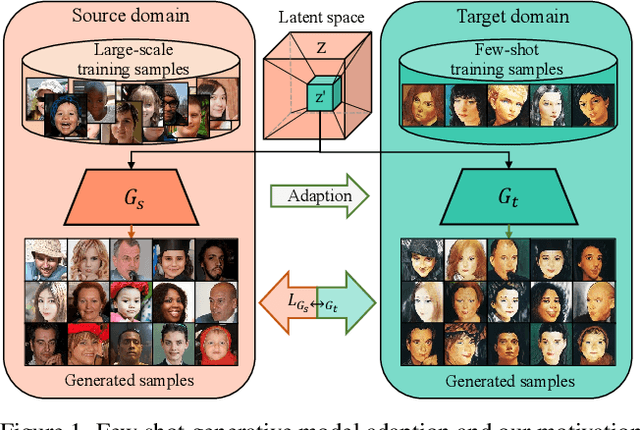
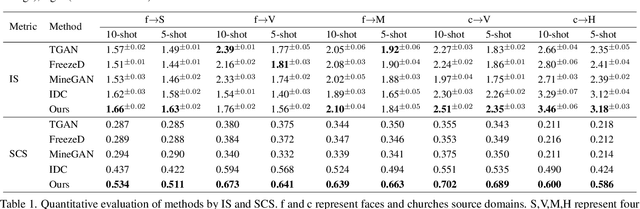
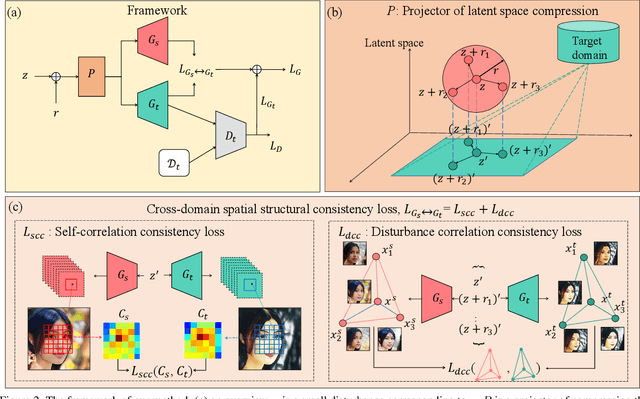

Training a generative adversarial network (GAN) with limited data has been a challenging task. A feasible solution is to start with a GAN well-trained on a large scale source domain and adapt it to the target domain with a few samples, termed as few shot generative model adaption. However, existing methods are prone to model overfitting and collapse in extremely few shot setting (less than 10). To solve this problem, we propose a relaxed spatial structural alignment method to calibrate the target generative models during the adaption. We design a cross-domain spatial structural consistency loss comprising the self-correlation and disturbance correlation consistency loss. It helps align the spatial structural information between the synthesis image pairs of the source and target domains. To relax the cross-domain alignment, we compress the original latent space of generative models to a subspace. Image pairs generated from the subspace are pulled closer. Qualitative and quantitative experiments show that our method consistently surpasses the state-of-the-art methods in few shot setting.
Region-wise Loss for Biomedical Image Segmentation
Aug 03, 2021


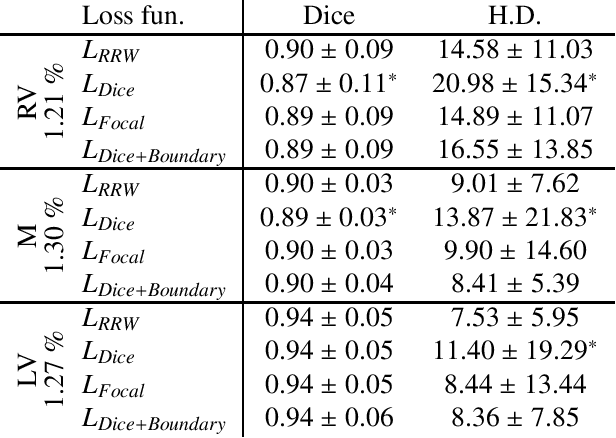
We propose Region-wise (RW) loss for biomedical image segmentation. Region-wise loss is versatile, can simultaneously account for class imbalance and pixel importance, and it can be easily implemented as the pixel-wise multiplication between the softmax output and a RW map. We show that, under the proposed Region-wise loss framework, certain loss functions, such as Active Contour and Boundary loss, can be reformulated similarly with appropriate RW maps, thus revealing their underlying similarities and a new perspective to understand these loss functions. We investigate the observed optimization instability caused by certain RW maps, such as Boundary loss distance maps, and we introduce a mathematically-grounded principle to avoid such instability. This principle provides excellent adaptability to any dataset and practically ensures convergence without extra regularization terms or optimization tricks. Following this principle, we propose a simple version of boundary distance maps called rectified RW maps that, as we demonstrate in our experiments, achieve state-of-the-art performance with similar or better Dice coefficients and Hausdorff distances than Dice, Focal, and Boundary losses in three distinct segmentation tasks. We quantify the optimization instability provided by Boundary loss distance maps, and we empirically show that our rectified RW maps are stable to optimize. The code to run all our experiments is publicly available at: https://github.com/jmlipman/RegionWiseLoss.
Learning image quality assessment by reinforcing task amenable data selection
Feb 15, 2021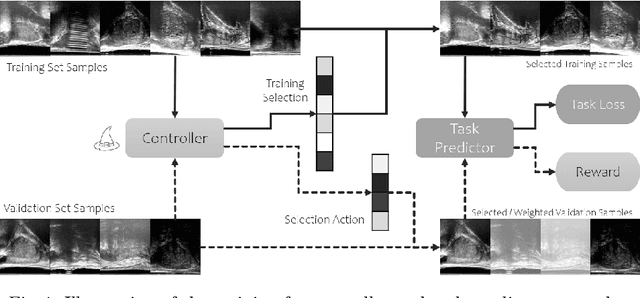

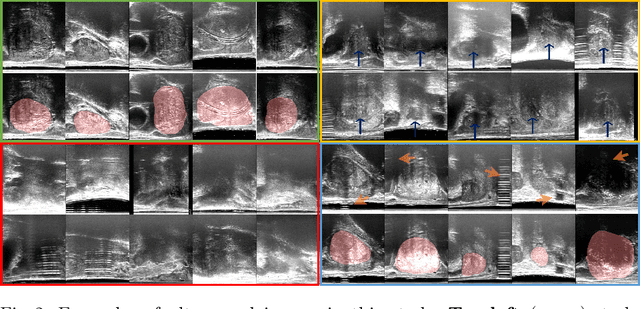
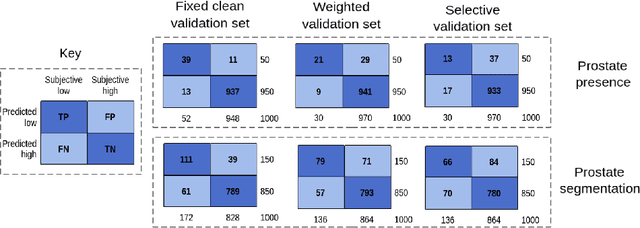
In this paper, we consider a type of image quality assessment as a task-specific measurement, which can be used to select images that are more amenable to a given target task, such as image classification or segmentation. We propose to train simultaneously two neural networks for image selection and a target task using reinforcement learning. A controller network learns an image selection policy by maximising an accumulated reward based on the target task performance on the controller-selected validation set, whilst the target task predictor is optimised using the training set. The trained controller is therefore able to reject those images that lead to poor accuracy in the target task. In this work, we show that the controller-predicted image quality can be significantly different from the task-specific image quality labels that are manually defined by humans. Furthermore, we demonstrate that it is possible to learn effective image quality assessment without using a ``clean'' validation set, thereby avoiding the requirement for human labelling of images with respect to their amenability for the task. Using $6712$, labelled and segmented, clinical ultrasound images from $259$ patients, experimental results on holdout data show that the proposed image quality assessment achieved a mean classification accuracy of $0.94\pm0.01$ and a mean segmentation Dice of $0.89\pm0.02$, by discarding $5\%$ and $15\%$ of the acquired images, respectively. The significantly improved performance was observed for both tested tasks, compared with the respective $0.90\pm0.01$ and $0.82\pm0.02$ from networks without considering task amenability. This enables image quality feedback during real-time ultrasound acquisition among many other medical imaging applications.
VNT-Net: Rotational Invariant Vector Neuron Transformers
May 25, 2022
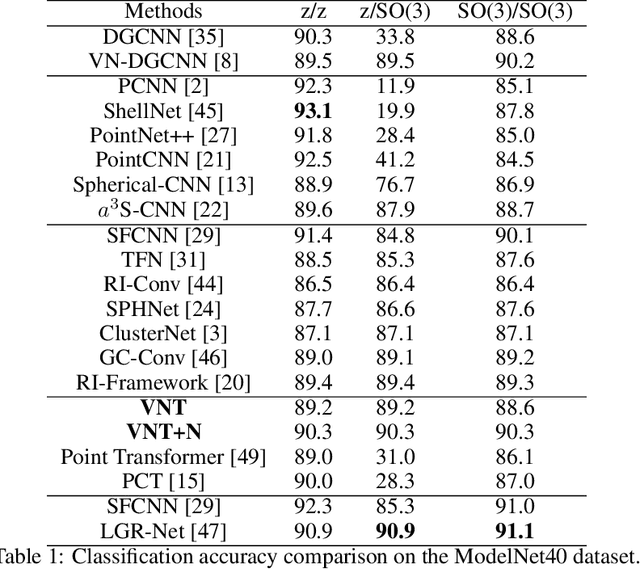
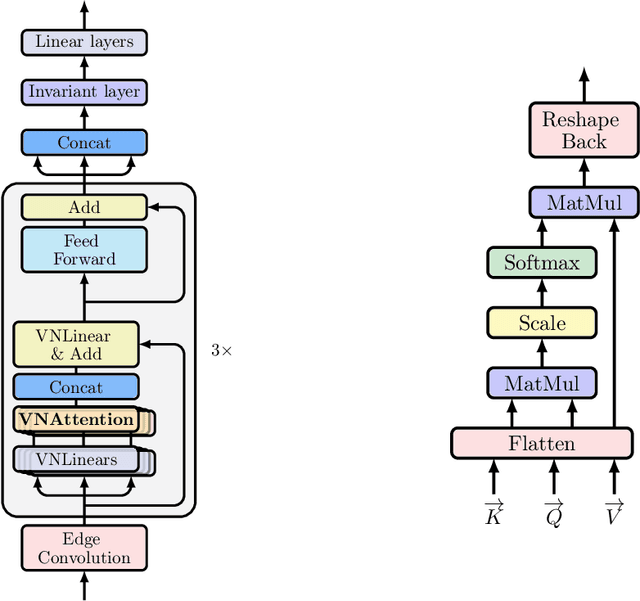
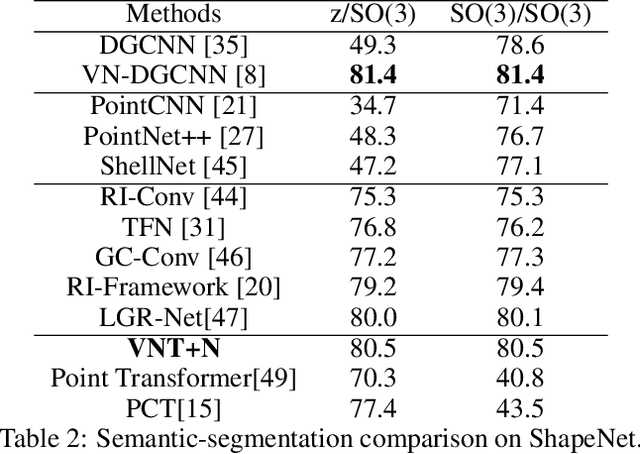
Learning 3D point sets with rotational invariance is an important and challenging problem in machine learning. Through rotational invariant architectures, 3D point cloud neural networks are relieved from requiring a canonical global pose and from exhaustive data augmentation with all possible rotations. In this work, we introduce a rotational invariant neural network by combining recently introduced vector neurons with self-attention layers to build a point cloud vector neuron transformer network (VNT-Net). Vector neurons are known for their simplicity and versatility in representing SO(3) actions and are thereby incorporated in common neural operations. Similarly, Transformer architectures have gained popularity and recently were shown successful for images by applying directly on sequences of image patches and achieving superior performance and convergence. In order to benefit from both worlds, we combine the two structures by mainly showing how to adapt the multi-headed attention layers to comply with vector neurons operations. Through this adaptation attention layers become SO(3) and the overall network becomes rotational invariant. Experiments demonstrate that our network efficiently handles 3D point cloud objects in arbitrary poses. We also show that our network achieves higher accuracy when compared to related state-of-the-art methods and requires less training due to a smaller number of hyperparameters in common classification and segmentation tasks.
Diverse Single Image Generation with Controllable Global Structure through Self-Attention
Feb 15, 2021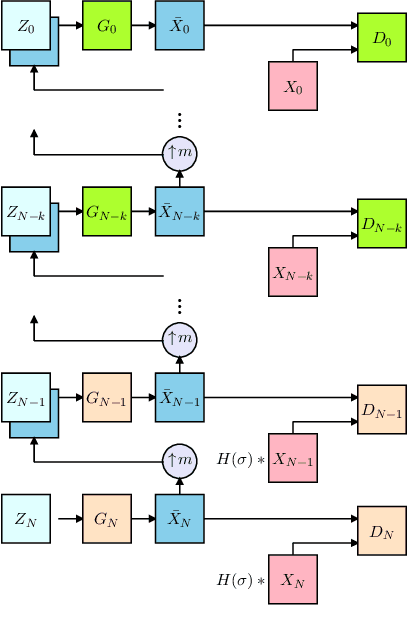

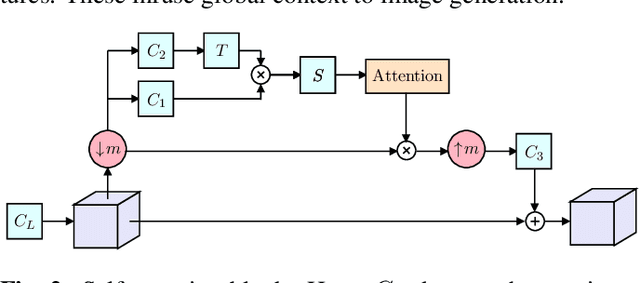
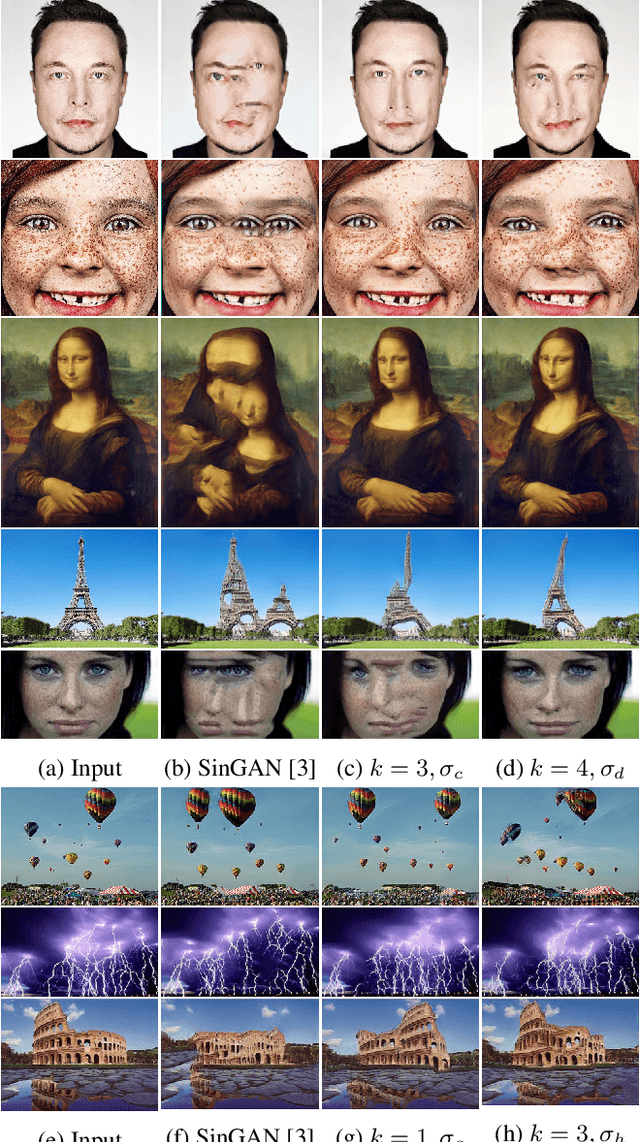
Image generation from a single image using generative adversarial networks is quite interesting due to the realism of generated images. However, recent approaches need improvement for such realistic and diverse image generation, when the global context of the image is important such as in face, animal, and architectural image generation. This is mainly due to the use of fewer convolutional layers for mainly capturing the patch statistics and, thereby, not being able to capture global statistics very well. We solve this problem by using attention blocks at selected scales and feeding a random Gaussian blurred image to the discriminator for training. Our results are visually better than the state-of-the-art particularly in generating images that require global context. The diversity of our image generation, measured using the average standard deviation of pixels, is also better.