 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Physics-guided Terahertz Computational Imaging
Apr 30, 2022
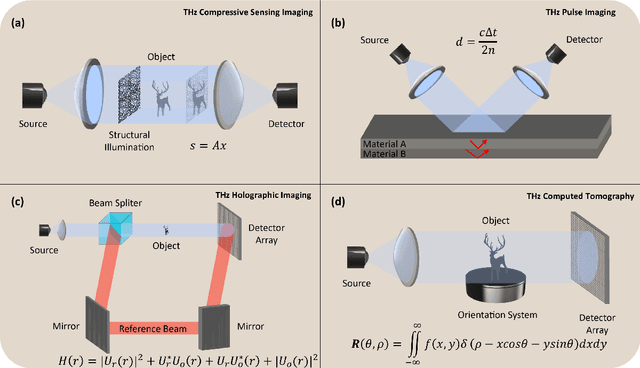
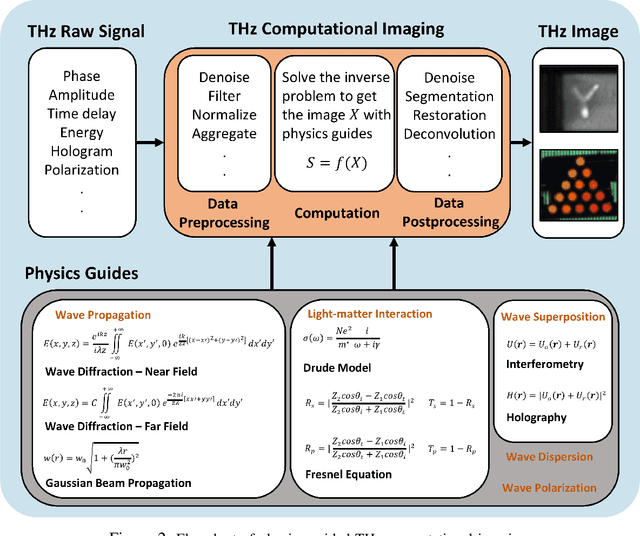
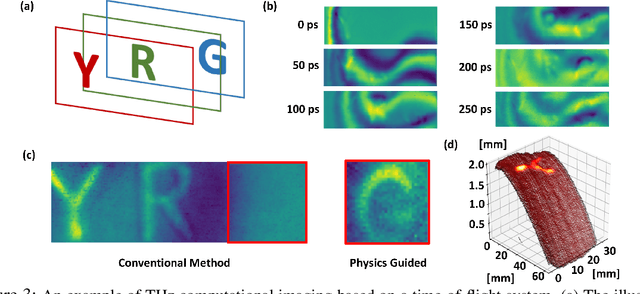
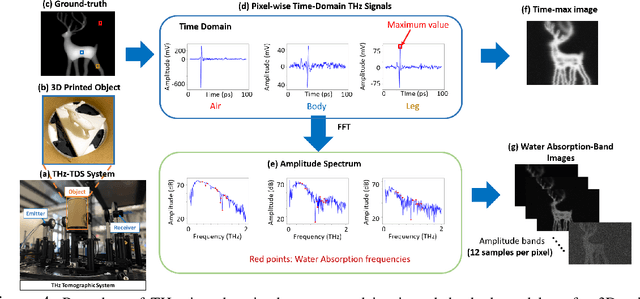
Visualizing information inside objects is an ever-lasting need to bridge the world from physics, chemistry, biology to computation. Among all tomographic techniques, terahertz (THz) computational imaging has demonstrated its unique sensing features to digitalize multi-dimensional object information in a non-destructive, non-ionizing, and non-invasive way. Applying modern signal processing and physics-guided modalities, THz computational imaging systems are now launched in various application fields in industrial inspection, security screening, chemical inspection and non-destructive evaluation. In this article, we overview recent advances in THz computational imaging modalities in the aspects of system configuration, wave propagation and interaction models, physics-guided algorithm for digitalizing interior information of imaged objects. Several image restoration and reconstruction issues based on multi-dimensional THz signals are further discussed, which provides a crosslink between material digitalization, functional property extraction, and multi-dimensional imager utilization from a signal processing perspective.
FALCON: Fast Visual Concept Learning by Integrating Images, Linguistic descriptions, and Conceptual Relations
Mar 30, 2022
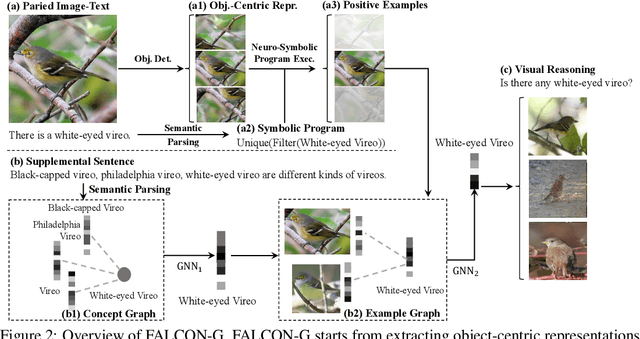
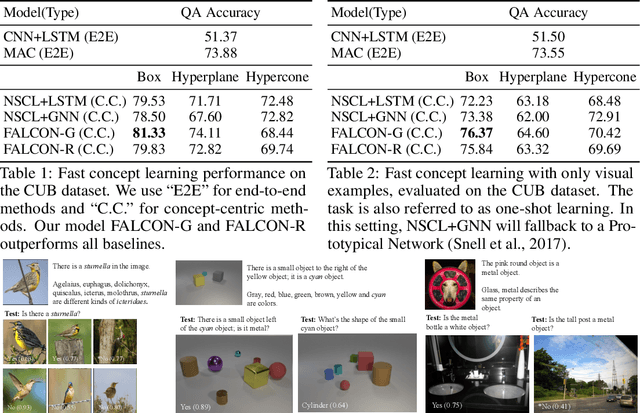
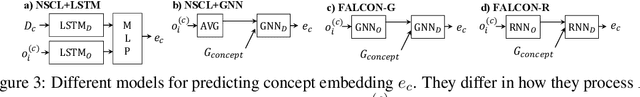
We present a meta-learning framework for learning new visual concepts quickly, from just one or a few examples, guided by multiple naturally occurring data streams: simultaneously looking at images, reading sentences that describe the objects in the scene, and interpreting supplemental sentences that relate the novel concept with other concepts. The learned concepts support downstream applications, such as answering questions by reasoning about unseen images. Our model, namely FALCON, represents individual visual concepts, such as colors and shapes, as axis-aligned boxes in a high-dimensional space (the "box embedding space"). Given an input image and its paired sentence, our model first resolves the referential expression in the sentence and associates the novel concept with particular objects in the scene. Next, our model interprets supplemental sentences to relate the novel concept with other known concepts, such as "X has property Y" or "X is a kind of Y". Finally, it infers an optimal box embedding for the novel concept that jointly 1) maximizes the likelihood of the observed instances in the image, and 2) satisfies the relationships between the novel concepts and the known ones. We demonstrate the effectiveness of our model on both synthetic and real-world datasets.
Text-DIAE: Degradation Invariant Autoencoders for Text Recognition and Document Enhancement
Mar 16, 2022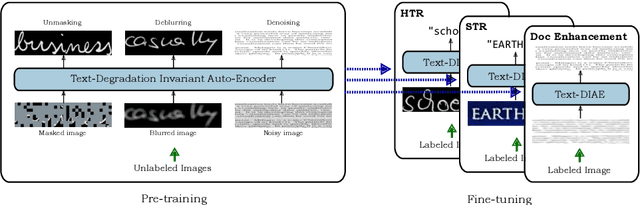
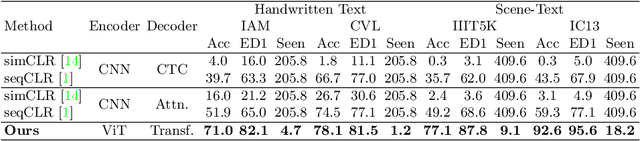
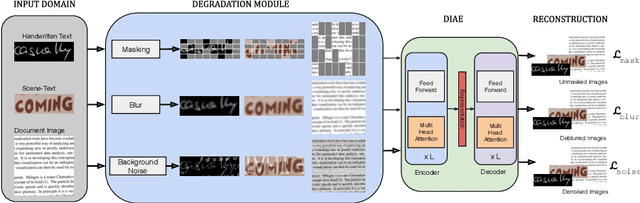
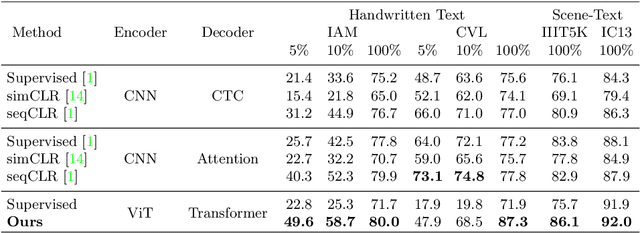
In this work, we propose Text-Degradation Invariant Auto Encoder (Text-DIAE) aimed to solve two tasks, text recognition (handwritten or scene-text) and document image enhancement. We define three pretext tasks as learning objectives to be optimized during pre-training without the usage of labelled data. Each of the pre-text objectives is specifically tailored for the final downstream tasks. We conduct several ablation experiments that show the importance of each degradation for a specific domain. Exhaustive experimentation shows that our method does not have limitations of previous state-of-the-art based on contrastive losses while at the same time requiring essentially fewer data samples to converge. Finally, we demonstrate that our method surpasses the state-of-the-art significantly in existing supervised and self-supervised settings in handwritten and scene text recognition and document image enhancement. Our code and trained models will be made publicly available at~\url{ http://Upon_Acceptance}.
Fast improvement of TEM image with low-dose electrons by deep learning
Jun 03, 2021
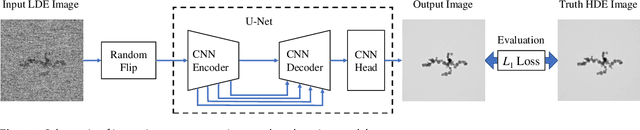
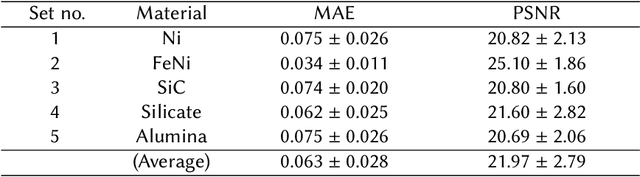
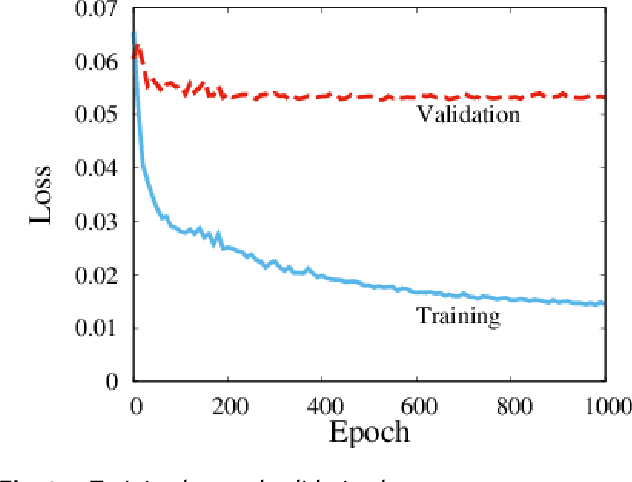
Low-electron-dose observation is indispensable for observing various samples using a transmission electron microscope; consequently, image processing has been used to improve transmission electron microscopy (TEM) images. To apply such image processing to in situ observations, we here apply a convolutional neural network to TEM imaging. Using a dataset that includes short-exposure images and long-exposure images, we develop a pipeline for processed short-exposure images, based on end-to-end training. The quality of images acquired with a total dose of approximately 5 e- per pixel becomes comparable to that of images acquired with a total dose of approximately 1000 e- per pixel. Because the conversion time is approximately 8 ms, in situ observation at 125 fps is possible. This imaging technique enables in situ observation of electron-beam-sensitive specimens.
Attention-guided Image Compression by Deep Reconstruction of Compressive Sensed Saliency Skeleton
Mar 29, 2021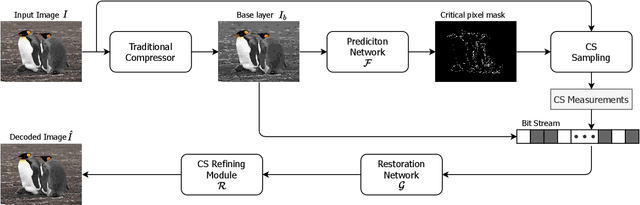
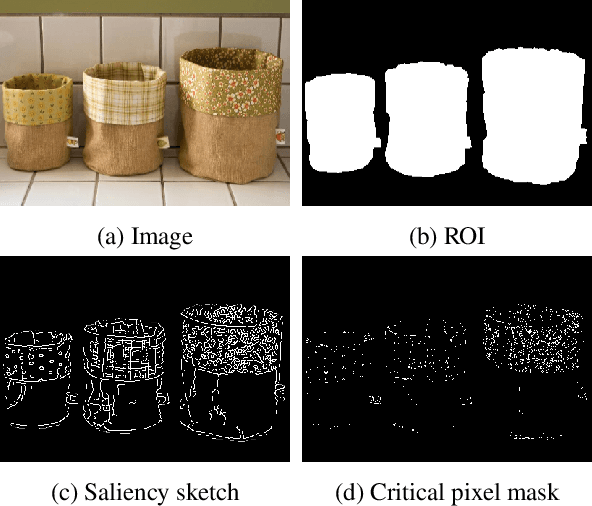
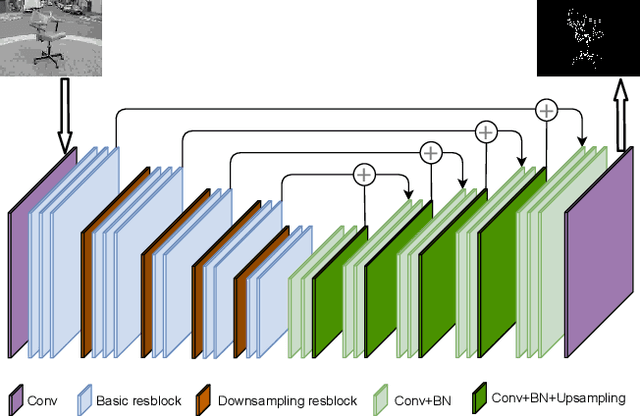
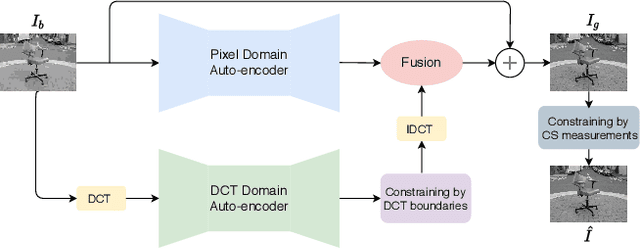
We propose a deep learning system for attention-guided dual-layer image compression (AGDL). In the AGDL compression system, an image is encoded into two layers, a base layer and an attention-guided refinement layer. Unlike the existing ROI image compression methods that spend an extra bit budget equally on all pixels in ROI, AGDL employs a CNN module to predict those pixels on and near a saliency sketch within ROI that are critical to perceptual quality. Only the critical pixels are further sampled by compressive sensing (CS) to form a very compact refinement layer. Another novel CNN method is developed to jointly decode the two compression layers for a much refined reconstruction, while strictly satisfying the transmitted CS constraints on perceptually critical pixels. Extensive experiments demonstrate that the proposed AGDL system advances the state of the art in perception-aware image compression.
How to Guide Adaptive Depth Sampling?
May 20, 2022
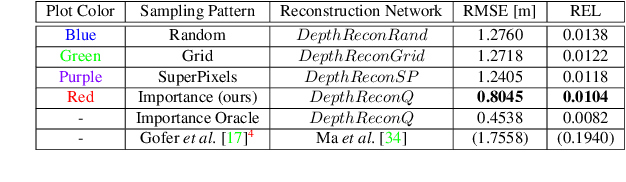
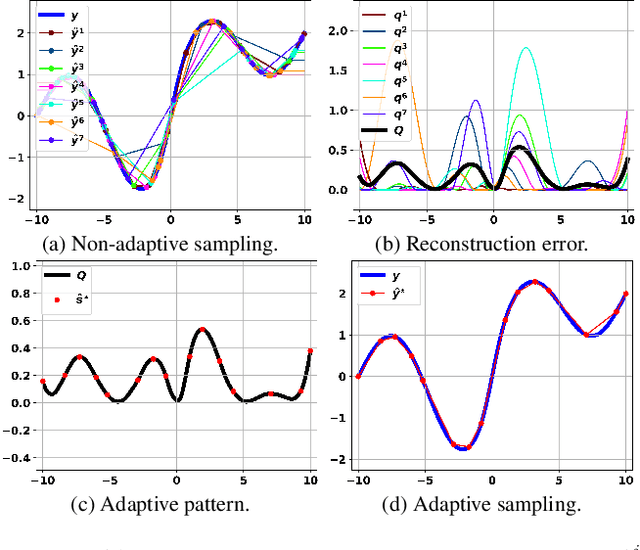

Recent advances in depth sensing technologies allow fast electronic maneuvering of the laser beam, as opposed to fixed mechanical rotations. This will enable future sensors, in principle, to vary in real-time the sampling pattern. We examine here the abstract problem of whether adapting the sampling pattern for a given frame can reduce the reconstruction error or allow a sparser pattern. We propose a constructive generic method to guide adaptive depth sampling algorithms. Given a sampling budget B, a depth predictor P and a desired quality measure M, we propose an Importance Map that highlights important sampling locations. This map is defined for a given frame as the per-pixel expected value of M produced by the predictor P, given a pattern of B random samples. This map can be well estimated in a training phase. We show that a neural network can learn to produce a highly faithful Importance Map, given an RGB image. We then suggest an algorithm to produce a sampling pattern for the scene, which is denser in regions that are harder to reconstruct. The sampling strategy of our modular framework can be adjusted according to hardware limitations, type of depth predictor, and any custom reconstruction error measure that should be minimized. We validate through simulations that our approach outperforms grid and random sampling patterns as well as recent state-of-the-art adaptive algorithms.
TorchEsegeta: Framework for Interpretability and Explainability of Image-based Deep Learning Models
Oct 16, 2021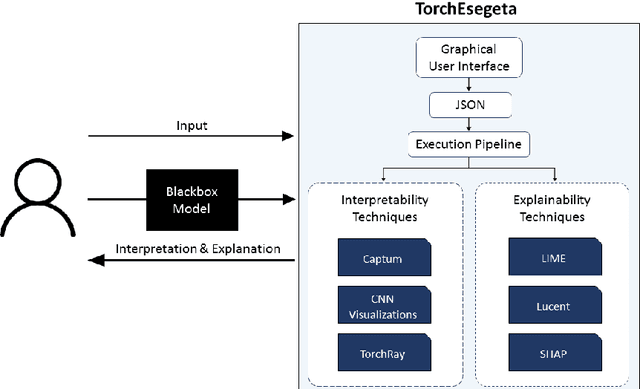
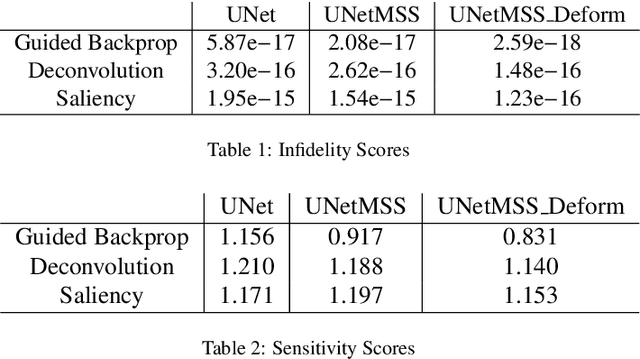
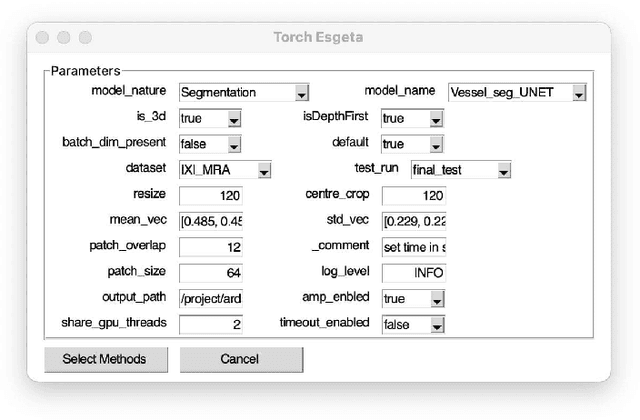
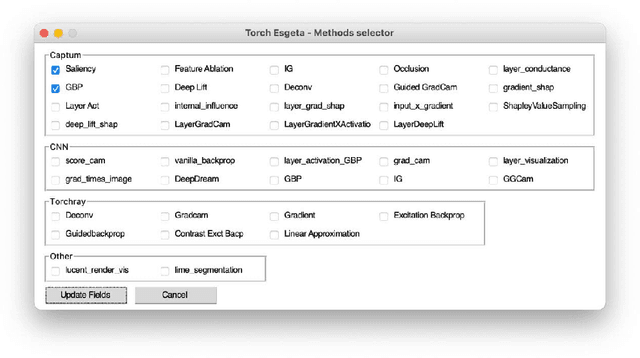
Clinicians are often very sceptical about applying automatic image processing approaches, especially deep learning based methods, in practice. One main reason for this is the black-box nature of these approaches and the inherent problem of missing insights of the automatically derived decisions. In order to increase trust in these methods, this paper presents approaches that help to interpret and explain the results of deep learning algorithms by depicting the anatomical areas which influence the decision of the algorithm most. Moreover, this research presents a unified framework, TorchEsegeta, for applying various interpretability and explainability techniques for deep learning models and generate visual interpretations and explanations for clinicians to corroborate their clinical findings. In addition, this will aid in gaining confidence in such methods. The framework builds on existing interpretability and explainability techniques that are currently focusing on classification models, extending them to segmentation tasks. In addition, these methods have been adapted to 3D models for volumetric analysis. The proposed framework provides methods to quantitatively compare visual explanations using infidelity and sensitivity metrics. This framework can be used by data scientists to perform post-hoc interpretations and explanations of their models, develop more explainable tools and present the findings to clinicians to increase their faith in such models. The proposed framework was evaluated based on a use case scenario of vessel segmentation models trained on Time-of-fight (TOF) Magnetic Resonance Angiogram (MRA) images of the human brain. Quantitative and qualitative results of a comparative study of different models and interpretability methods are presented. Furthermore, this paper provides an extensive overview of several existing interpretability and explainability methods.
Unsupervised Prompt Learning for Vision-Language Models
Apr 07, 2022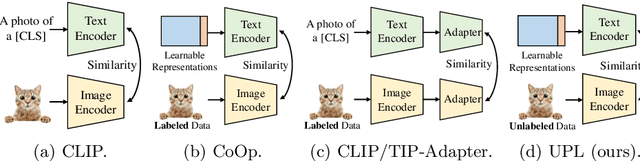
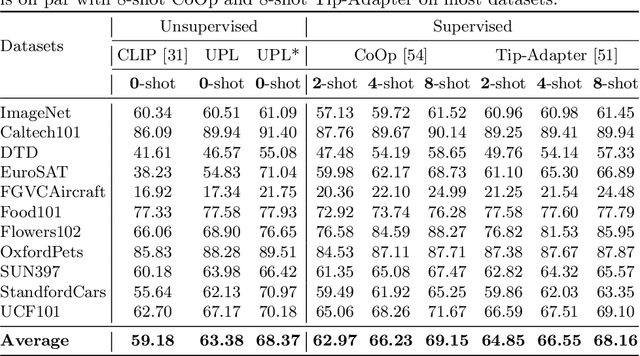
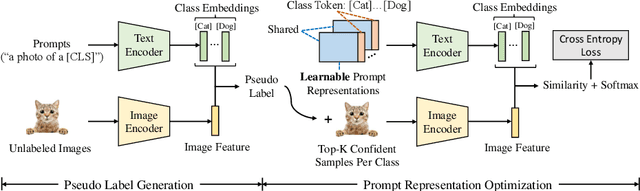
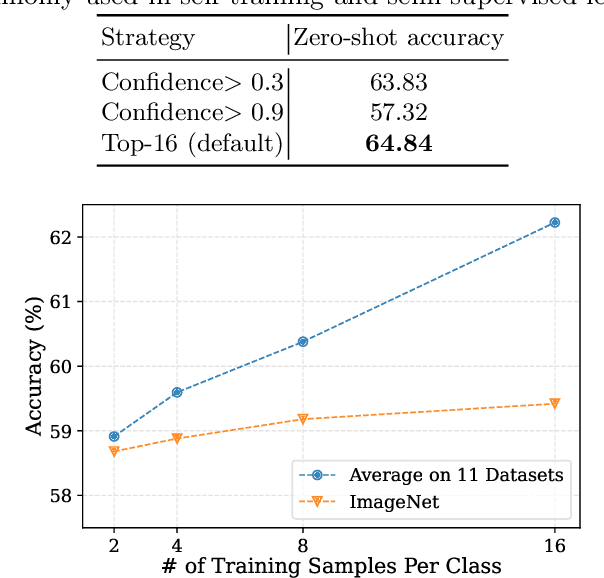
Contrastive vision-language models like CLIP have shown great progress in zero-shot transfer learning. This new paradigm uses large-scale image-text pairs for training and aligns images and texts in a common embedding space. In the inference stage, the proper text description, known as prompt, needs to be carefully designed for zero-shot transfer. To avoid laborious prompt engineering and simultaneously improve transfer performance, recent works such as CoOp, CLIP-Adapter and Tip-Adapter propose to adapt vision-language models for downstream image recognition tasks by either optimizing the continuous prompt representations or training an additional adapter network on top of the pre-trained vision-language models on a small set of labeled data. Though promising improvements are achieved, using labeled images from target datasets may violate the intention of zero-shot transfer of pre-trained vision-language models. In this paper, we propose an unsupervised prompt learning (UPL) framework, which does not require any annotations of the target dataset, to improve the zero-shot transfer of CLIP-like vision-language models. Experimentally, for zero-shot transfer, our UPL outperforms original CLIP with prompt engineering and on ImageNet as well as other 10 datasets. An enhanced version of UPL is even on par with the 8-shot CoOp and the 8-shot TIP-Adapter on most datasets while our method does not need any labeled images for training. Code and models are available at https://github.com/tonyhuang2022/UPL.
Efficient Deep Image Denoising via Class Specific Convolution
Mar 02, 2021


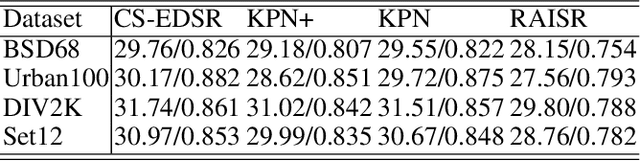
Deep neural networks have been widely used in image denoising during the past few years. Even though they achieve great success on this problem, they are computationally inefficient which makes them inappropriate to be implemented in mobile devices. In this paper, we propose an efficient deep neural network for image denoising based on pixel-wise classification. Despite using a computationally efficient network cannot effectively remove the noises from any content, it is still capable to denoise from a specific type of pattern or texture. The proposed method follows such a divide and conquer scheme. We first use an efficient U-net to pixel-wisely classify pixels in the noisy image based on the local gradient statistics. Then we replace part of the convolution layers in existing denoising networks by the proposed Class Specific Convolution layers (CSConv) which use different weights for different classes of pixels. Quantitative and qualitative evaluations on public datasets demonstrate that the proposed method can reduce the computational costs without sacrificing the performance compared to state-of-the-art algorithms.
Pre-Trained Image Processing Transformer
Dec 03, 2020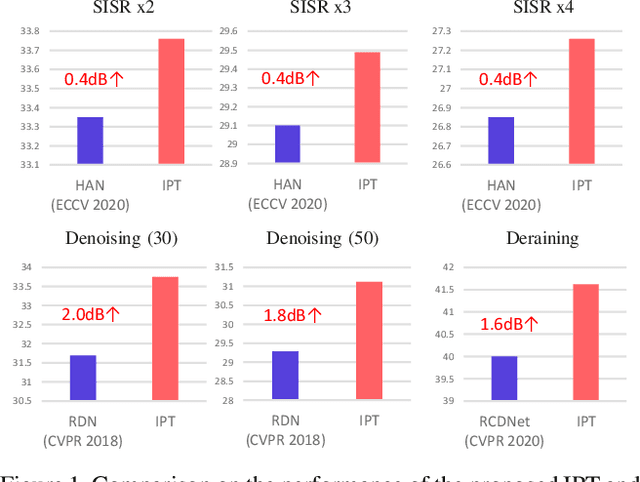

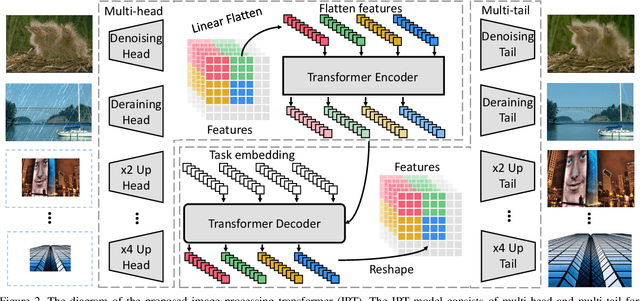
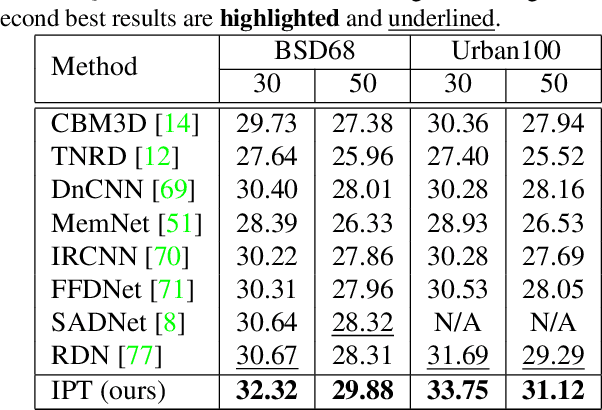
As the computing power of modern hardware is increasing strongly, pre-trained deep learning models (e.g., BERT, GPT-3) learned on large-scale datasets have shown their effectiveness over conventional methods. The big progress is mainly contributed to the representation ability of transformer and its variant architectures. In this paper, we study the low-level computer vision task (e.g., denoising, super-resolution and deraining) and develop a new pre-trained model, namely, image processing transformer (IPT). To maximally excavate the capability of transformer, we present to utilize the well-known ImageNet benchmark for generating a large amount of corrupted image pairs. The IPT model is trained on these images with multi-heads and multi-tails. In addition, the contrastive learning is introduced for well adapting to different image processing tasks. The pre-trained model can therefore efficiently employed on desired task after fine-tuning. With only one pre-trained model, IPT outperforms the current state-of-the-art methods on various low-level benchmarks.