 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rethinking Task-Incremental Learning Baselines
May 23, 2022
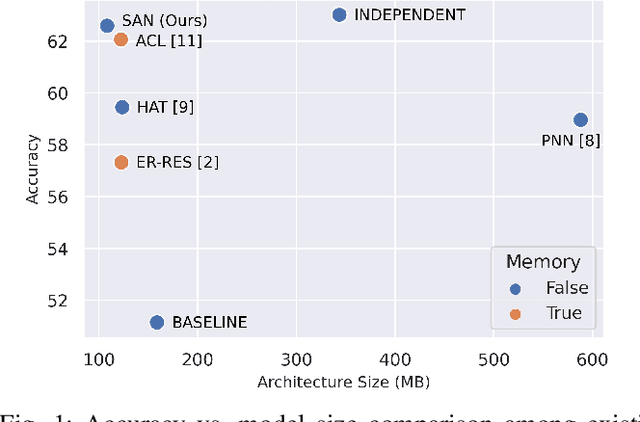
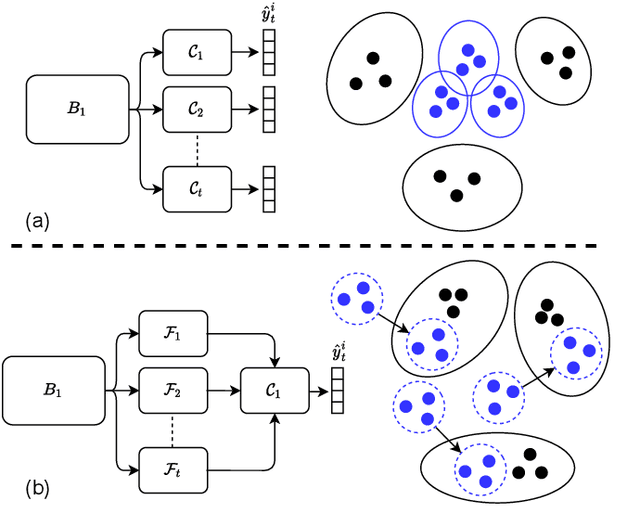
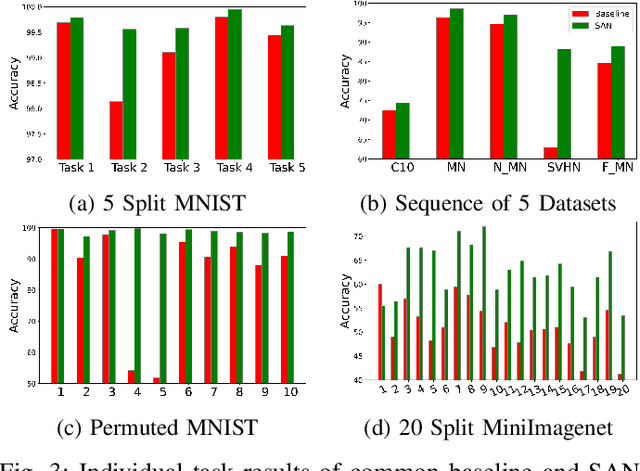
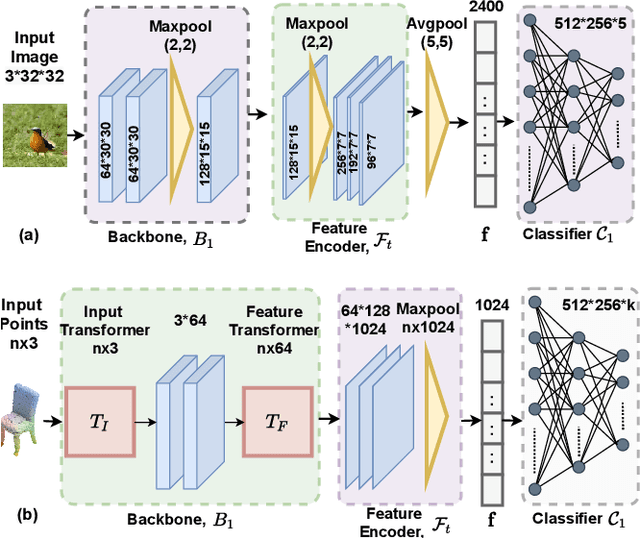
It is common to have continuous streams of new data that need to be introduced in the system in real-world applications. The model needs to learn newly added capabilities (future tasks) while retaining the old knowledge (past tasks). Incremental learning has recently become increasingly appealing for this problem. Task-incremental learning is a kind of incremental learning where task identity of newly included task (a set of classes) remains known during inference. A common goal of task-incremental methods is to design a network that can operate on minimal size, maintaining decent performance. To manage the stability-plasticity dilemma, different methods utilize replay memory of past tasks, specialized hardware, regularization monitoring etc. However, these methods are still less memory efficient in terms of architecture growth or input data costs. In this study, we present a simple yet effective adjustment network (SAN) for task incremental learning that achieves near state-of-the-art performance while using minimal architectural size without using memory instances compared to previous state-of-the-art approaches. We investigate this approach on both 3D point cloud object (ModelNet40) and 2D image (CIFAR10, CIFAR100, MiniImageNet, MNIST, PermutedMNIST, notMNIST, SVHN, and FashionMNIST) recognition tasks and establish a strong baseline result for a fair comparison with existing methods. On both 2D and 3D domains, we also observe that SAN is primarily unaffected by different task orders in a task-incremental setting.
Beyond Categorical Label Representations for Image Classification
Apr 06, 2021We find that the way we choose to represent data labels can have a profound effect on the quality of trained models. For example, training an image classifier to regress audio labels rather than traditional categorical probabilities produces a more reliable classification. This result is surprising, considering that audio labels are more complex than simpler numerical probabilities or text. We hypothesize that high dimensional, high entropy label representations are generally more useful because they provide a stronger error signal. We support this hypothesis with evidence from various label representations including constant matrices, spectrograms, shuffled spectrograms, Gaussian mixtures, and uniform random matrices of various dimensionalities. Our experiments reveal that high dimensional, high entropy labels achieve comparable accuracy to text (categorical) labels on the standard image classification task, but features learned through our label representations exhibit more robustness under various adversarial attacks and better effectiveness with a limited amount of training data. These results suggest that label representation may play a more important role than previously thought. The project website is at \url{https://www.creativemachineslab.com/label-representation.html}.
Casual 6-DoF: free-viewpoint panorama using a handheld 360 camera
Mar 31, 2022

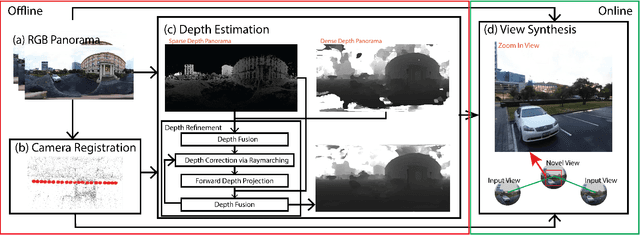
Six degrees-of-freedom (6-DoF) video provides telepresence by enabling users to move around in the captured scene with a wide field of regard. Compared to methods requiring sophisticated camera setups, the image-based rendering method based on photogrammetry can work with images captured with any poses, which is more suitable for casual users. However, existing image-based rendering methods are based on perspective images. When used to reconstruct 6-DoF views, it often requires capturing hundreds of images, making data capture a tedious and time-consuming process. In contrast to traditional perspective images, 360{\deg} images capture the entire surrounding view in a single shot, thus, providing a faster capturing process for 6-DoF view reconstruction. This paper presents a novel method to provide 6-DoF experiences over a wide area using an unstructured collection of 360{\deg} panoramas captured by a conventional 360{\deg} camera. Our method consists of 360{\deg} data capturing, novel depth estimation to produce a high-quality spherical depth panorama, and high-fidelity free-viewpoint generation. We compared our method against state-of-the-art methods, using data captured in various environments. Our method shows better visual quality and robustness in the tested scenes.
Advances on image interpolation based on ant colony algorithm
Apr 12, 2021


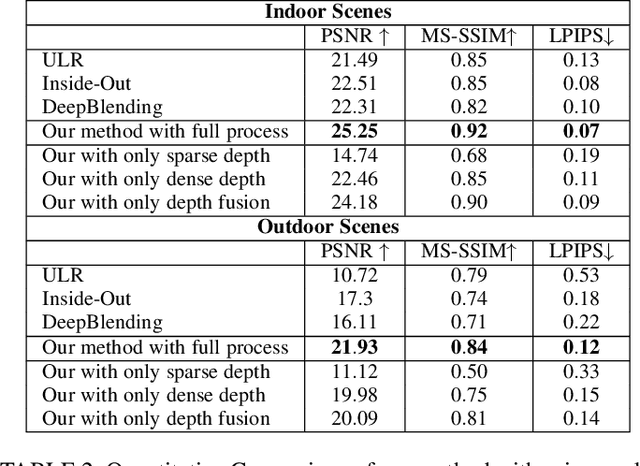
This paper presents an advance on image interpolation based on ant colony algorithm (AACA) for high-resolution image scaling. The difference between the proposed algorithm and the previously proposed optimization of bilinear interpolation based on ant colony algorithm (OBACA) is that AACA uses global weighting, whereas OBACA uses a local weighting scheme. The strength of the proposed global weighting of the AACA algorithm depends on employing solely the pheromone matrix information present on any group of four adjacent pixels to decide which case deserves a maximum global weight value or not. Experimental results are further provided to show the higher performance of the proposed AACA algorithm with reference to the algorithms mentioned in this paper.
* 17 pages, 14 figures, 3 tables
A Topology-Attention ConvLSTM Network and Its Application to EM Images
Feb 07, 2022
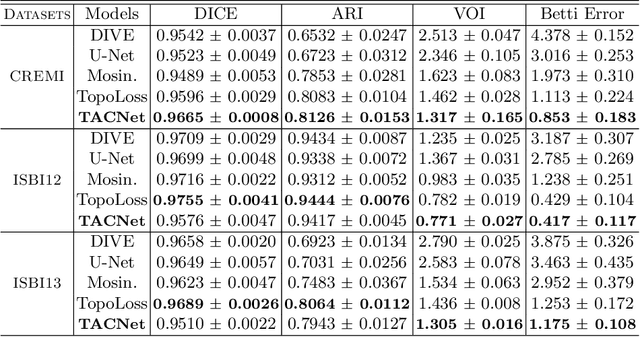
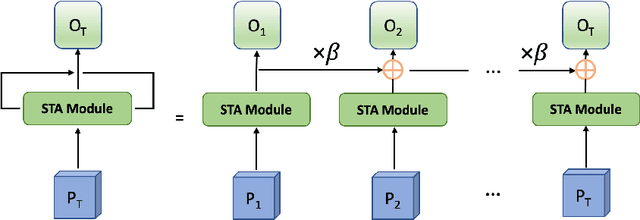
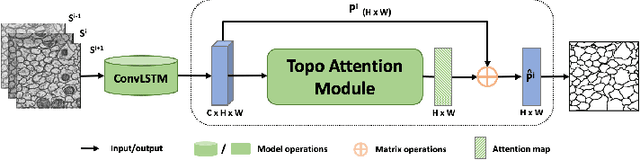
Structural accuracy of segmentation is important for finescale structures in biomedical images. We propose a novel TopologyAttention ConvLSTM Network (TACNet) for 3D image segmentation in order to achieve high structural accuracy for 3D segmentation tasks. Specifically, we propose a Spatial Topology-Attention (STA) module to process a 3D image as a stack of 2D image slices and adopt ConvLSTM to leverage contextual structure information from adjacent slices. In order to effectively transfer topology-critical information across slices, we propose an Iterative-Topology Attention (ITA) module that provides a more stable topology-critical map for segmentation. Quantitative and qualitative results show that our proposed method outperforms various baselines in terms of topology-aware evaluation metrics.
Self-Adversarial Training incorporating Forgery Attention for Image Forgery Localization
Jul 06, 2021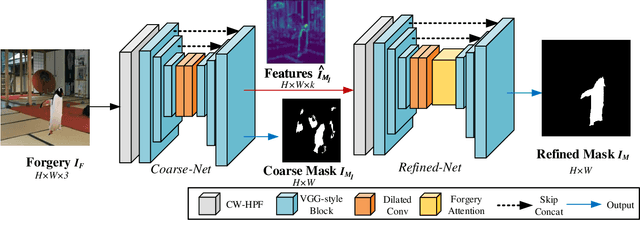
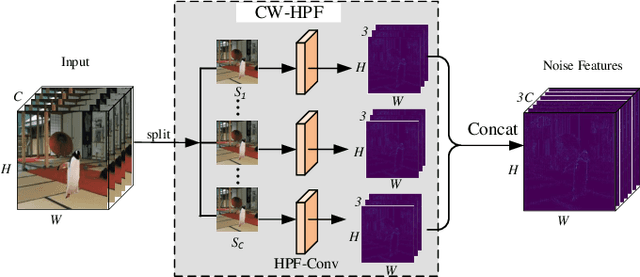
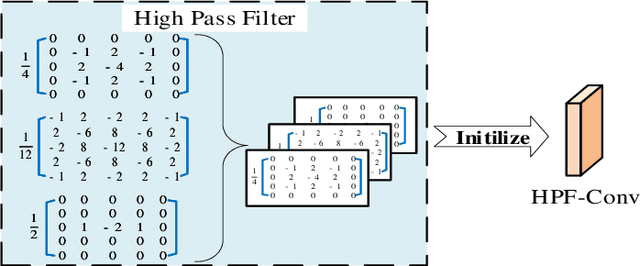
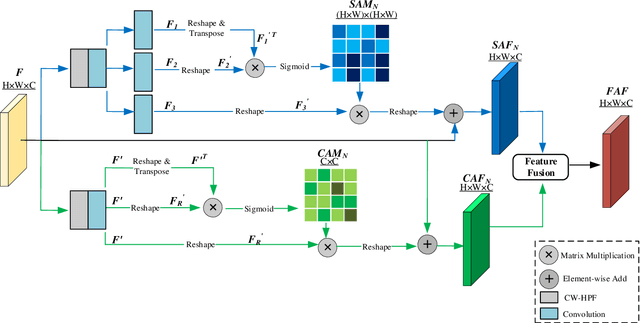
Image editing techniques enable people to modify the content of an image without leaving visual traces and thus may cause serious security risks. Hence the detection and localization of these forgeries become quite necessary and challenging. Furthermore, unlike other tasks with extensive data, there is usually a lack of annotated forged images for training due to annotation difficulties. In this paper, we propose a self-adversarial training strategy and a reliable coarse-to-fine network that utilizes a self-attention mechanism to localize forged regions in forgery images. The self-attention module is based on a Channel-Wise High Pass Filter block (CW-HPF). CW-HPF leverages inter-channel relationships of features and extracts noise features by high pass filters. Based on the CW-HPF, a self-attention mechanism, called forgery attention, is proposed to capture rich contextual dependencies of intrinsic inconsistency extracted from tampered regions. Specifically, we append two types of attention modules on top of CW-HPF respectively to model internal interdependencies in spatial dimension and external dependencies among channels. We exploit a coarse-to-fine network to enhance the noise inconsistency between original and tampered regions. More importantly, to address the issue of insufficient training data, we design a self-adversarial training strategy that expands training data dynamically to achieve more robust performance. Specifically, in each training iteration, we perform adversarial attacks against our network to generate adversarial examples and train our model on them. Extensive experimental results demonstrate that our proposed algorithm steadily outperforms state-of-the-art methods by a clear margin in different benchmark datasets.
FALCON: Fast Visual Concept Learning by Integrating Images, Linguistic descriptions, and Conceptual Relations
Mar 30, 2022
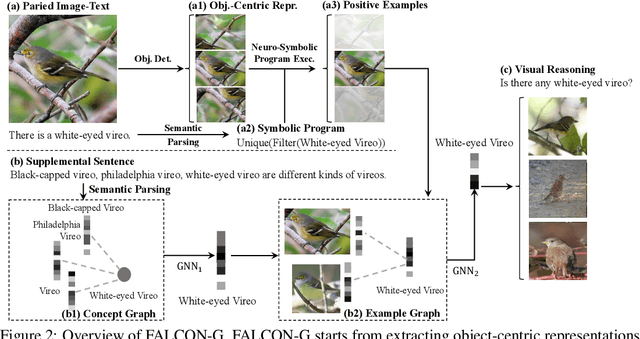
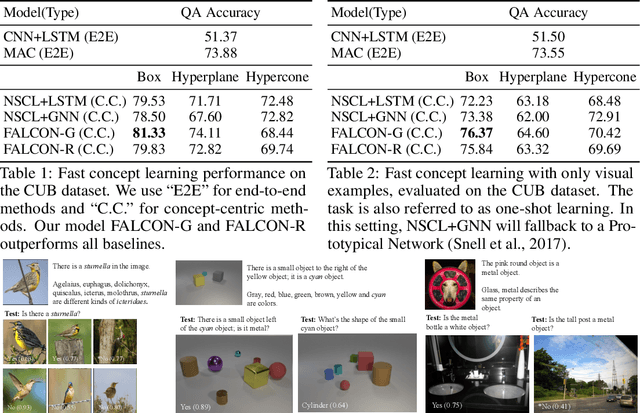
We present a meta-learning framework for learning new visual concepts quickly, from just one or a few examples, guided by multiple naturally occurring data streams: simultaneously looking at images, reading sentences that describe the objects in the scene, and interpreting supplemental sentences that relate the novel concept with other concepts. The learned concepts support downstream applications, such as answering questions by reasoning about unseen images. Our model, namely FALCON, represents individual visual concepts, such as colors and shapes, as axis-aligned boxes in a high-dimensional space (the "box embedding space"). Given an input image and its paired sentence, our model first resolves the referential expression in the sentence and associates the novel concept with particular objects in the scene. Next, our model interprets supplemental sentences to relate the novel concept with other known concepts, such as "X has property Y" or "X is a kind of Y". Finally, it infers an optimal box embedding for the novel concept that jointly 1) maximizes the likelihood of the observed instances in the image, and 2) satisfies the relationships between the novel concepts and the known ones. We demonstrate the effectiveness of our model on both synthetic and real-world datasets.
LiDAR-guided Stereo Matching with a Spatial Consistency Constraint
Feb 21, 2022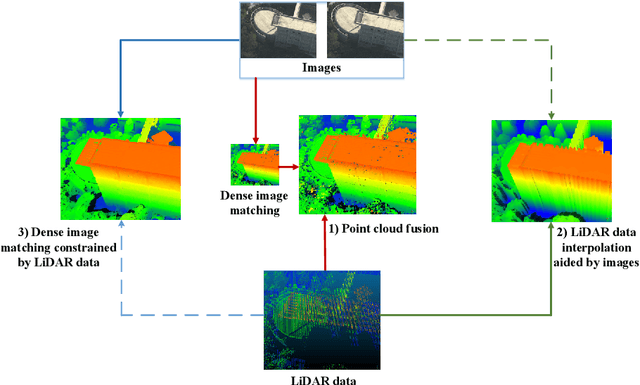
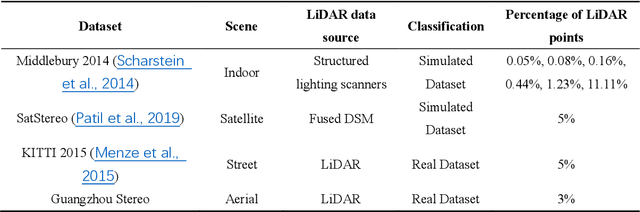
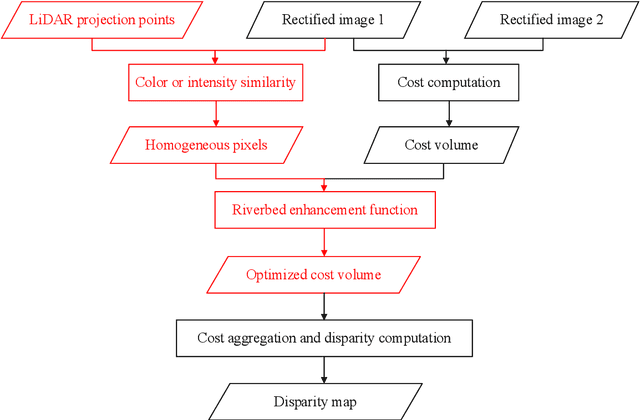
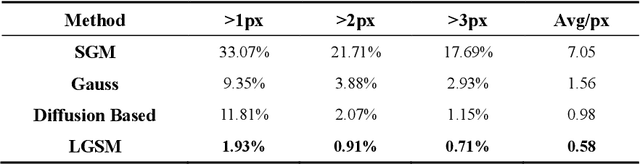
The complementary fusion of light detection and ranging (LiDAR) data and image data is a promising but challenging task for generating high-precision and high-density point clouds. This study proposes an innovative LiDAR-guided stereo matching approach called LiDAR-guided stereo matching (LGSM), which considers the spatial consistency represented by continuous disparity or depth changes in the homogeneous region of an image. The LGSM first detects the homogeneous pixels of each LiDAR projection point based on their color or intensity similarity. Next, we propose a riverbed enhancement function to optimize the cost volume of the LiDAR projection points and their homogeneous pixels to improve the matching robustness. Our formulation expands the constraint scopes of sparse LiDAR projection points with the guidance of image information to optimize the cost volume of pixels as much as possible. We applied LGSM to semi-global matching and AD-Census on both simulated and real datasets. When the percentage of LiDAR points in the simulated datasets was 0.16%, the matching accuracy of our method achieved a subpixel level, while that of the original stereo matching algorithm was 3.4 pixels. The experimental results show that LGSM is suitable for indoor, street, aerial, and satellite image datasets and provides good transferability across semi-global matching and AD-Census. Furthermore, the qualitative and quantitative evaluations demonstrate that LGSM is superior to two state-of-the-art optimizing cost volume methods, especially in reducing mismatches in difficult matching areas and refining the boundaries of objects.
FedNorm: Modality-Based Normalization in Federated Learning for Multi-Modal Liver Segmentation
May 23, 2022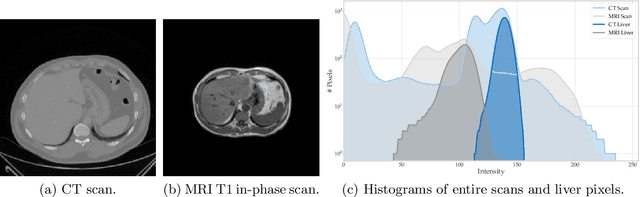

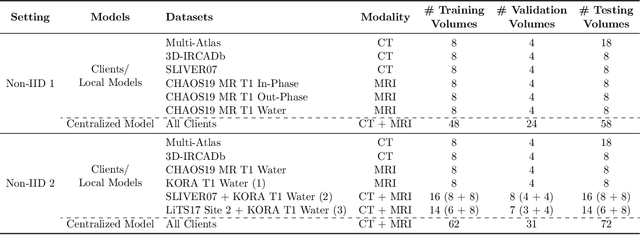
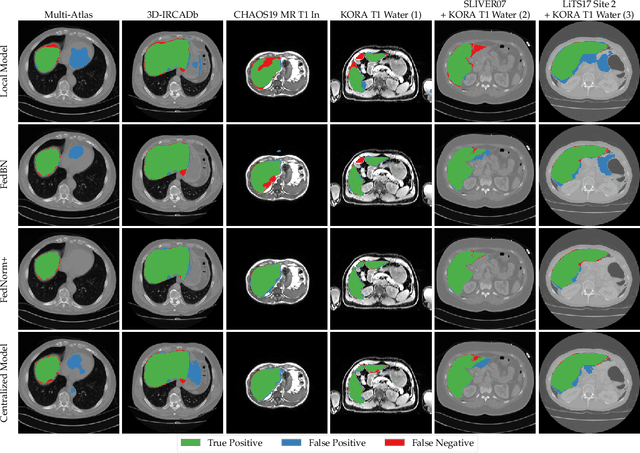
Given the high incidence and effective treatment options for liver diseases, they are of great socioeconomic importance. One of the most common methods for analyzing CT and MRI images for diagnosis and follow-up treatment is liver segmentation. Recent advances in deep learning have demonstrated encouraging results for automatic liver segmentation. Despite this, their success depends primarily on the availability of an annotated database, which is often not available because of privacy concerns. Federated Learning has been recently proposed as a solution to alleviate these challenges by training a shared global model on distributed clients without access to their local databases. Nevertheless, Federated Learning does not perform well when it is trained on a high degree of heterogeneity of image data due to multi-modal imaging, such as CT and MRI, and multiple scanner types. To this end, we propose Fednorm and its extension \fednormp, two Federated Learning algorithms that use a modality-based normalization technique. Specifically, Fednorm normalizes the features on a client-level, while Fednorm+ employs the modality information of single slices in the feature normalization. Our methods were validated using 428 patients from six publicly available databases and compared to state-of-the-art Federated Learning algorithms and baseline models in heterogeneous settings (multi-institutional, multi-modal data). The experimental results demonstrate that our methods show an overall acceptable performance, achieve Dice per patient scores up to 0.961, consistently outperform locally trained models, and are on par or slightly better than centralized models.
Unsupervised Prompt Learning for Vision-Language Models
Apr 07, 2022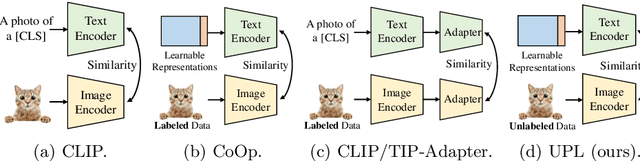
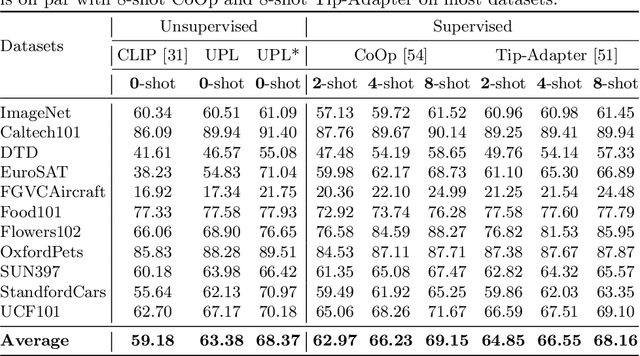
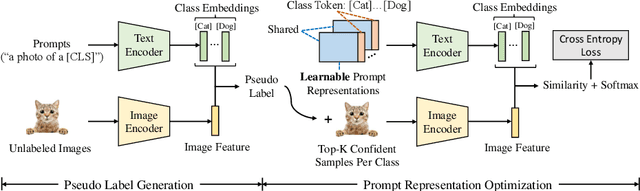
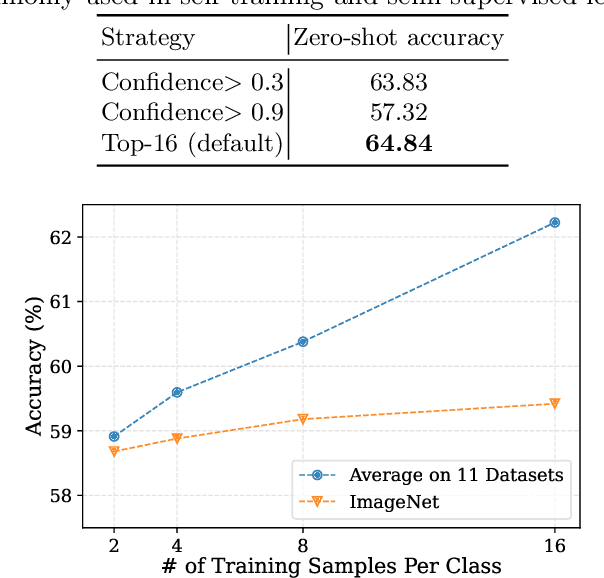
Contrastive vision-language models like CLIP have shown great progress in zero-shot transfer learning. This new paradigm uses large-scale image-text pairs for training and aligns images and texts in a common embedding space. In the inference stage, the proper text description, known as prompt, needs to be carefully designed for zero-shot transfer. To avoid laborious prompt engineering and simultaneously improve transfer performance, recent works such as CoOp, CLIP-Adapter and Tip-Adapter propose to adapt vision-language models for downstream image recognition tasks by either optimizing the continuous prompt representations or training an additional adapter network on top of the pre-trained vision-language models on a small set of labeled data. Though promising improvements are achieved, using labeled images from target datasets may violate the intention of zero-shot transfer of pre-trained vision-language models. In this paper, we propose an unsupervised prompt learning (UPL) framework, which does not require any annotations of the target dataset, to improve the zero-shot transfer of CLIP-like vision-language models. Experimentally, for zero-shot transfer, our UPL outperforms original CLIP with prompt engineering and on ImageNet as well as other 10 datasets. An enhanced version of UPL is even on par with the 8-shot CoOp and the 8-shot TIP-Adapter on most datasets while our method does not need any labeled images for training. Code and models are available at https://github.com/tonyhuang2022/UPL.