 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gigapixel Histopathological Image Analysis using Attention-based Neural Networks
Jan 30, 2021
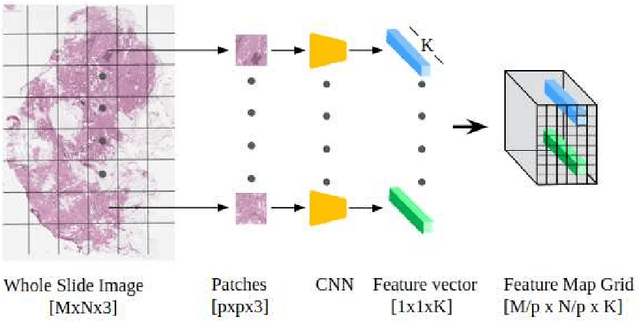
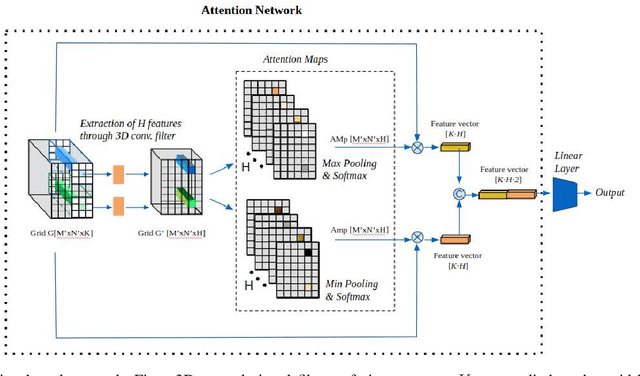
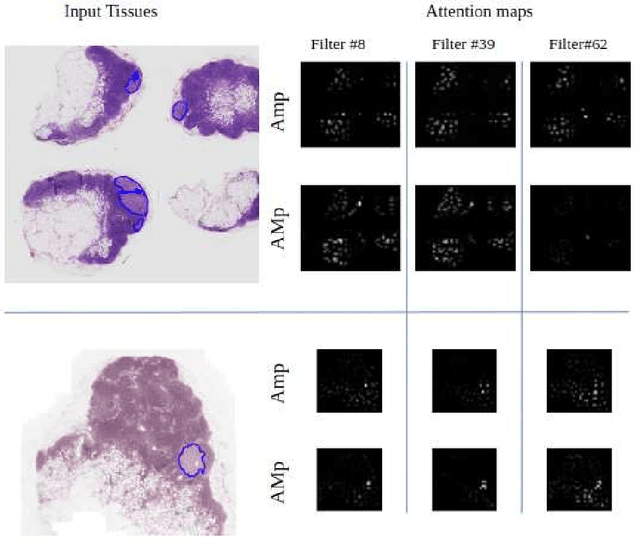
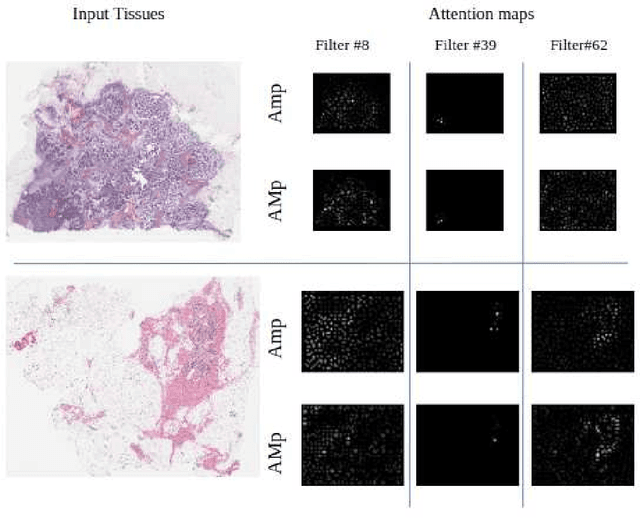
Although CNNs are widely considered as the state-of-the-art models in various applications of image analysis, one of the main challenges still open is the training of a CNN on high resolution images. Different strategies have been proposed involving either a rescaling of the image or an individual processing of parts of the image. Such strategies cannot be applied to images, such as gigapixel histopathological images, for which a high reduction in resolution inherently effects a loss of discriminative information, and in respect of which the analysis of single parts of the image suffers from a lack of global information or implies a high workload in terms of annotating the training images in such a way as to select significant parts. We propose a method for the analysis of gigapixel histopathological images solely by using weak image-level labels. In particular, two analysis tasks are taken into account: a binary classification and a prediction of the tumor proliferation score. Our method is based on a CNN structure consisting of a compressing path and a learning path. In the compressing path, the gigapixel image is packed into a grid-based feature map by using a residual network devoted to the feature extraction of each patch into which the image has been divided. In the learning path, attention modules are applied to the grid-based feature map, taking into account spatial correlations of neighboring patch features to find regions of interest, which are then used for the final whole slide analysis. Our method integrates both global and local information, is flexible with regard to the size of the input images and only requires weak image-level labels. Comparisons with different methods of the state-of-the-art on two well known datasets, Camelyon16 and TUPAC16, have been made to confirm the validity of the proposed model.
Dynamic Dual-Output Diffusion Models
Mar 08, 2022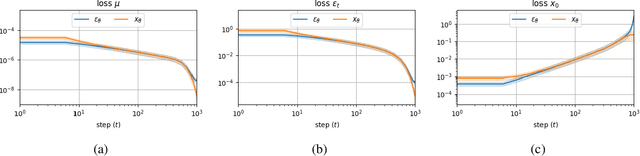
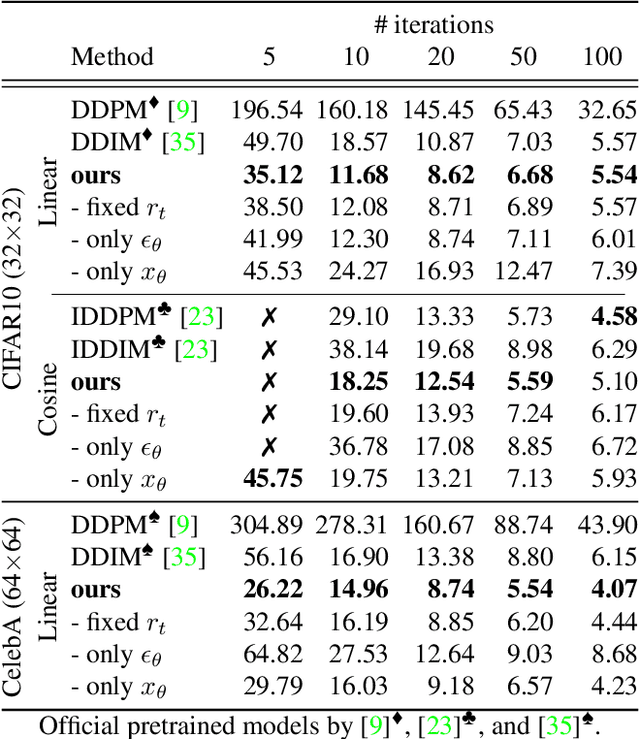
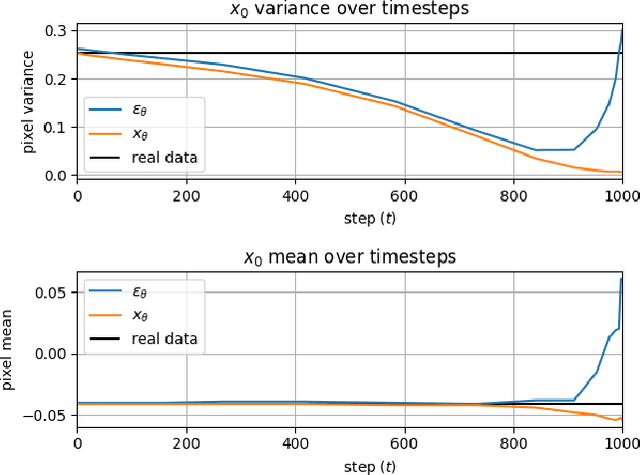
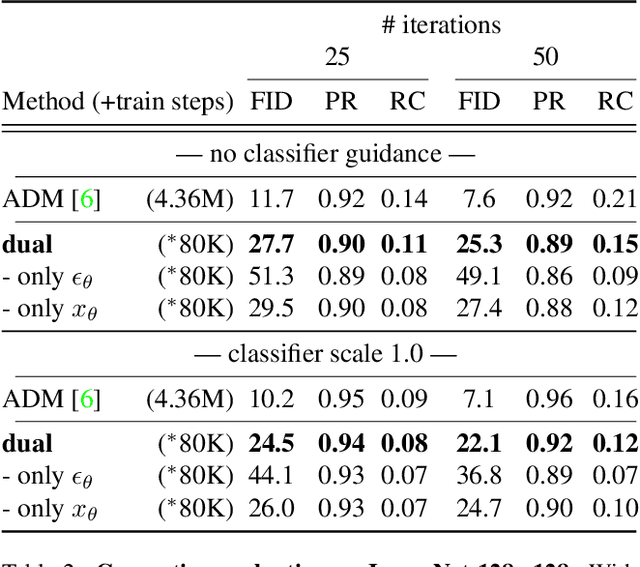
Iterative denoising-based generation, also known as denoising diffusion models, has recently been shown to be comparable in quality to other classes of generative models, and even surpass them. Including, in particular, Generative Adversarial Networks, which are currently the state of the art in many sub-tasks of image generation. However, a major drawback of this method is that it requires hundreds of iterations to produce a competitive result. Recent works have proposed solutions that allow for faster generation with fewer iterations, but the image quality gradually deteriorates with increasingly fewer iterations being applied during generation. In this paper, we reveal some of the causes that affect the generation quality of diffusion models, especially when sampling with few iterations, and come up with a simple, yet effective, solution to mitigate them. We consider two opposite equations for the iterative denoising, the first predicts the applied noise, and the second predicts the image directly. Our solution takes the two options and learns to dynamically alternate between them through the denoising process. Our proposed solution is general and can be applied to any existing diffusion model. As we show, when applied to various SOTA architectures, our solution immediately improves their generation quality, with negligible added complexity and parameters. We experiment on multiple datasets and configurations and run an extensive ablation study to support these findings.
Poly-CAM: High resolution class activation map for convolutional neural networks
Apr 28, 2022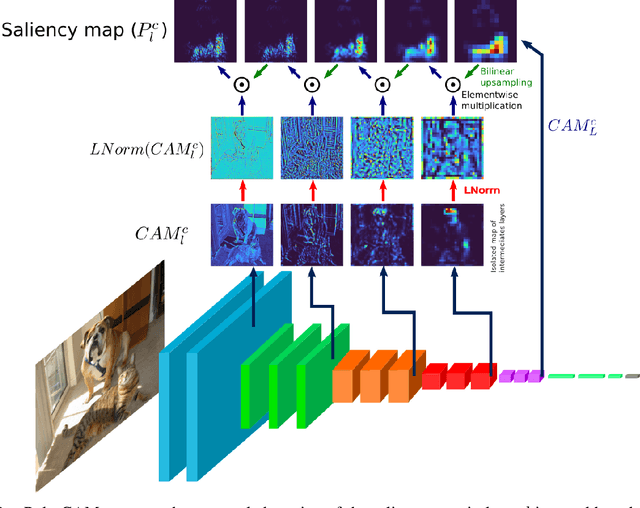
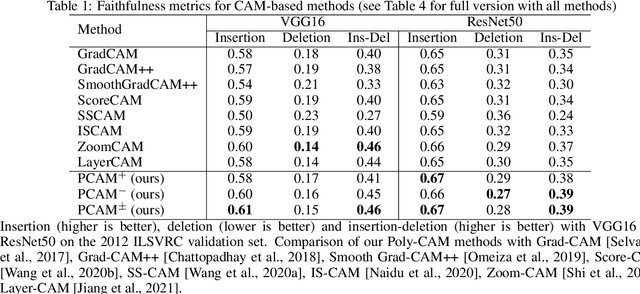

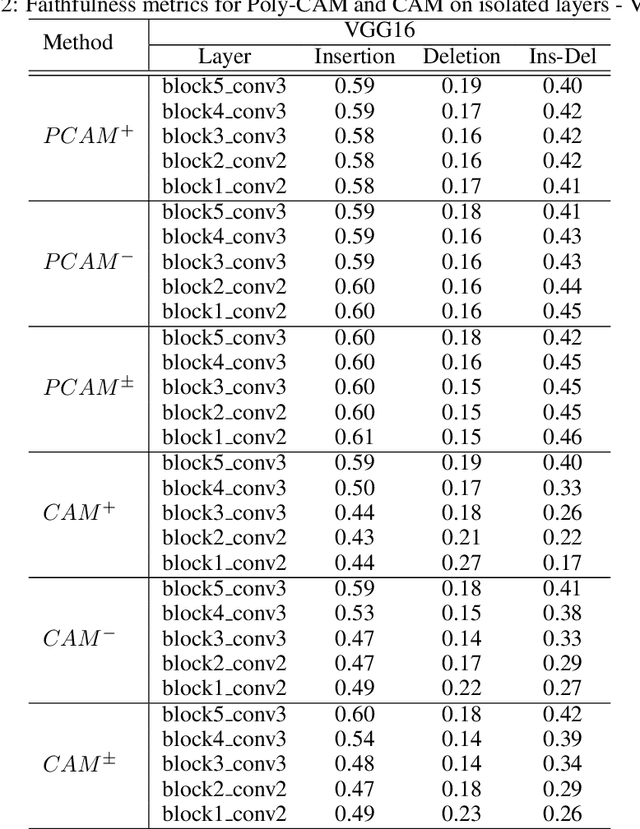
The need for Explainable AI is increasing with the development of deep learning. The saliency maps derived from convolutional neural networks generally fail in localizing with accuracy the image features justifying the network prediction. This is because those maps are either low-resolution as for CAM [Zhou et al., 2016], or smooth as for perturbation-based methods [Zeiler and Fergus, 2014], or do correspond to a large number of widespread peaky spots as for gradient-based approaches [Sundararajan et al., 2017, Smilkov et al., 2017]. In contrast, our work proposes to combine the information from earlier network layers with the one from later layers to produce a high resolution Class Activation Map that is competitive with the previous art in term of insertion-deletion faithfulness metrics, while outperforming it in term of precision of class-specific features localization.
Beyond Categorical Label Representations for Image Classification
Apr 06, 2021We find that the way we choose to represent data labels can have a profound effect on the quality of trained models. For example, training an image classifier to regress audio labels rather than traditional categorical probabilities produces a more reliable classification. This result is surprising, considering that audio labels are more complex than simpler numerical probabilities or text. We hypothesize that high dimensional, high entropy label representations are generally more useful because they provide a stronger error signal. We support this hypothesis with evidence from various label representations including constant matrices, spectrograms, shuffled spectrograms, Gaussian mixtures, and uniform random matrices of various dimensionalities. Our experiments reveal that high dimensional, high entropy labels achieve comparable accuracy to text (categorical) labels on the standard image classification task, but features learned through our label representations exhibit more robustness under various adversarial attacks and better effectiveness with a limited amount of training data. These results suggest that label representation may play a more important role than previously thought. The project website is at \url{https://www.creativemachineslab.com/label-representation.html}.
Advances on image interpolation based on ant colony algorithm
Apr 12, 2021

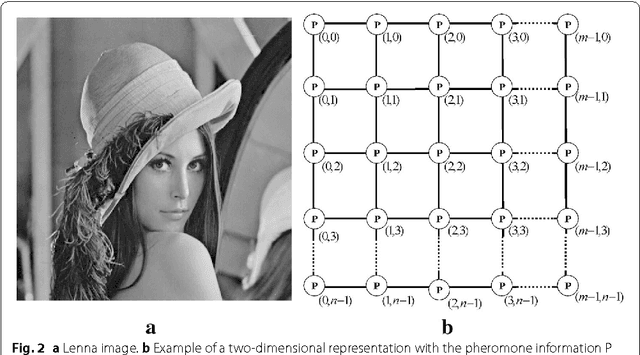

This paper presents an advance on image interpolation based on ant colony algorithm (AACA) for high-resolution image scaling. The difference between the proposed algorithm and the previously proposed optimization of bilinear interpolation based on ant colony algorithm (OBACA) is that AACA uses global weighting, whereas OBACA uses a local weighting scheme. The strength of the proposed global weighting of the AACA algorithm depends on employing solely the pheromone matrix information present on any group of four adjacent pixels to decide which case deserves a maximum global weight value or not. Experimental results are further provided to show the higher performance of the proposed AACA algorithm with reference to the algorithms mentioned in this paper.
* 17 pages, 14 figures, 3 tables
Towards Vivid and Diverse Image Colorization with Generative Color Prior
Aug 19, 2021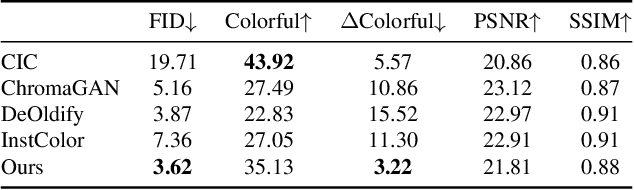
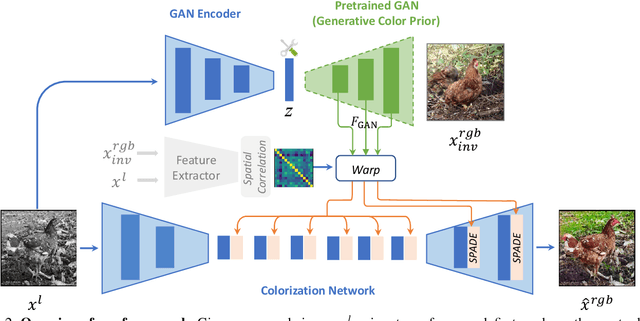


Colorization has attracted increasing interest in recent years. Classic reference-based methods usually rely on external color images for plausible results. A large image database or online search engine is inevitably required for retrieving such exemplars. Recent deep-learning-based methods could automatically colorize images at a low cost. However, unsatisfactory artifacts and incoherent colors are always accompanied. In this work, we aim at recovering vivid colors by leveraging the rich and diverse color priors encapsulated in a pretrained Generative Adversarial Networks (GAN). Specifically, we first "retrieve" matched features (similar to exemplars) via a GAN encoder and then incorporate these features into the colorization process with feature modulations. Thanks to the powerful generative color prior and delicate designs, our method could produce vivid colors with a single forward pass. Moreover, it is highly convenient to obtain diverse results by modifying GAN latent codes. Our method also inherits the merit of interpretable controls of GANs and could attain controllable and smooth transitions by walking through GAN latent space. Extensive experiments and user studies demonstrate that our method achieves superior performance than previous works.
Controllable Garment Transfer
Apr 05, 2022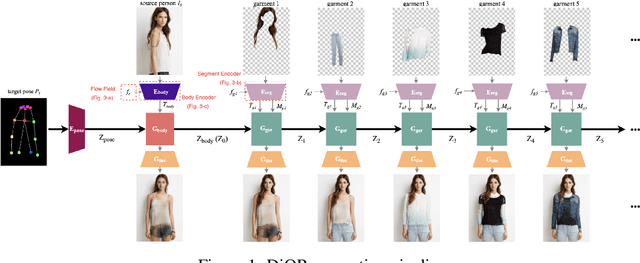
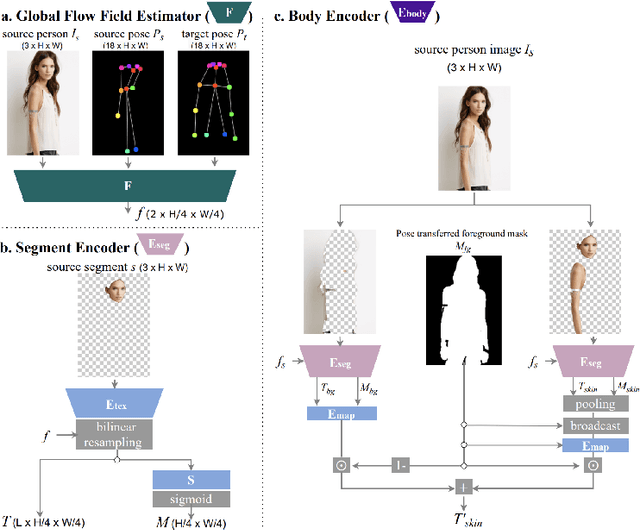


Image-based garment transfer replaces the garment on the target human with the desired garment; this enables users to virtually view themselves in the desired garment. To this end, many approaches have been proposed using the generative model and have shown promising results. However, most fail to provide the user with on the fly garment modification functionality. We aim to add this customizable option of "garment tweaking" to our model to control garment attributes, such as sleeve length, waist width, and garment texture.
How to Guide Adaptive Depth Sampling?
May 20, 2022
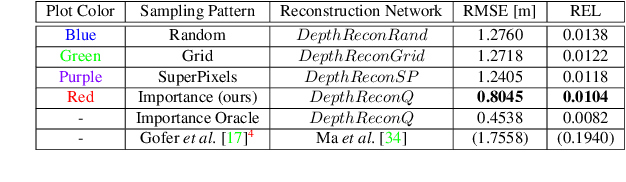
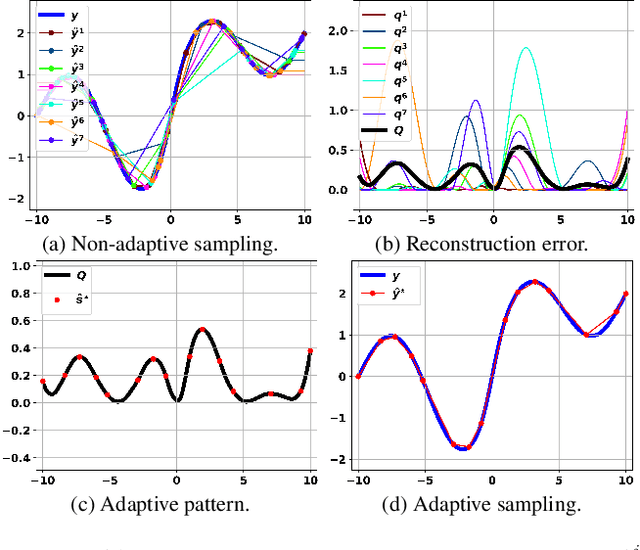

Recent advances in depth sensing technologies allow fast electronic maneuvering of the laser beam, as opposed to fixed mechanical rotations. This will enable future sensors, in principle, to vary in real-time the sampling pattern. We examine here the abstract problem of whether adapting the sampling pattern for a given frame can reduce the reconstruction error or allow a sparser pattern. We propose a constructive generic method to guide adaptive depth sampling algorithms. Given a sampling budget B, a depth predictor P and a desired quality measure M, we propose an Importance Map that highlights important sampling locations. This map is defined for a given frame as the per-pixel expected value of M produced by the predictor P, given a pattern of B random samples. This map can be well estimated in a training phase. We show that a neural network can learn to produce a highly faithful Importance Map, given an RGB image. We then suggest an algorithm to produce a sampling pattern for the scene, which is denser in regions that are harder to reconstruct. The sampling strategy of our modular framework can be adjusted according to hardware limitations, type of depth predictor, and any custom reconstruction error measure that should be minimized. We validate through simulations that our approach outperforms grid and random sampling patterns as well as recent state-of-the-art adaptive algorithms.
Adversarial synthesis based data-augmentation for code-switched spoken language identification
May 30, 2022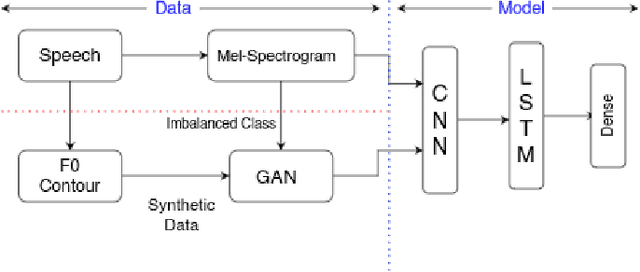
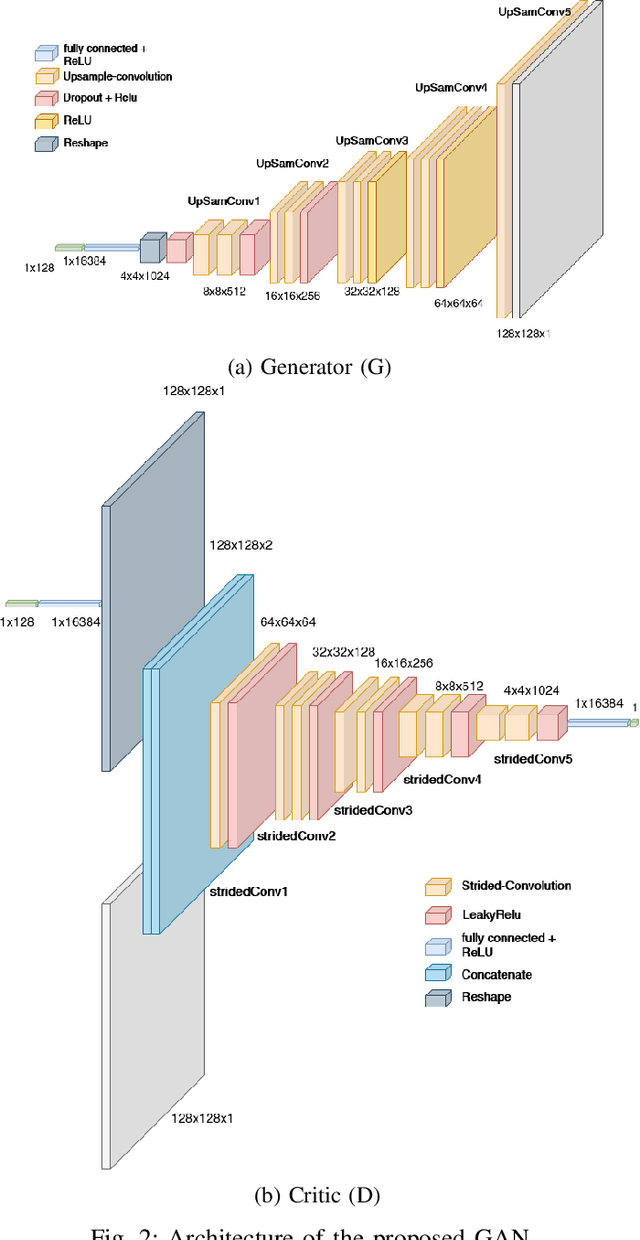
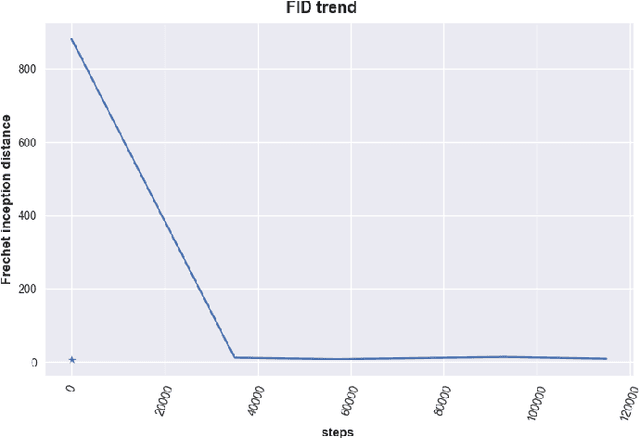
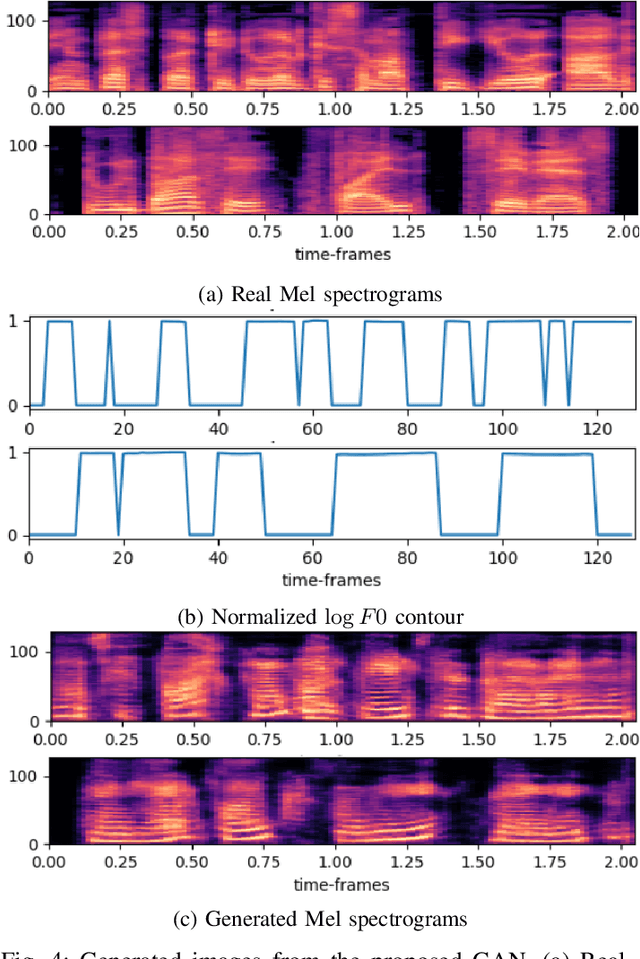
Spoken Language Identification (LID) is an important sub-task of Automatic Speech Recognition(ASR) that is used to classify the language(s) in an audio segment. Automatic LID plays an useful role in multilingual countries. In various countries, identifying a language becomes hard, due to the multilingual scenario where two or more than two languages are mixed together during conversation. Such phenomenon of speech is called as code-mixing or code-switching. This nature is followed not only in India but also in many Asian countries. Such code-mixed data is hard to find, which further reduces the capabilities of the spoken LID. Due to the lack of avalibility of this code-mixed data, it becomes a minority class in LID task. Hence, this work primarily addresses this problem using data augmentation as a solution on the minority code-switched class. This study focuses on Indic language code-mixed with English. Spoken LID is performed on Hindi, code-mixed with English. This research proposes Generative Adversarial Network (GAN) based data augmentation technique performed using Mel spectrograms for audio data. GANs have already been proven to be accurate in representing the real data distribution in the image domain. Proposed research exploits these capabilities of GANs in speech domains such as speech classification, automatic speech recognition,etc. GANs are trained to generate Mel spectrograms of the minority code-mixed class which are then used to augment data for the classifier. Utilizing GANs give an overall improvement on Unweighted Average Recall by an amount of 3.5\% as compared to a Convolutional Recurrent Neural Network (CRNN) classifier used as the baseline reference.
Self-Adversarial Training incorporating Forgery Attention for Image Forgery Localization
Jul 06, 2021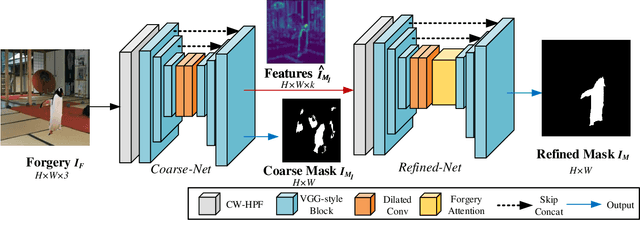
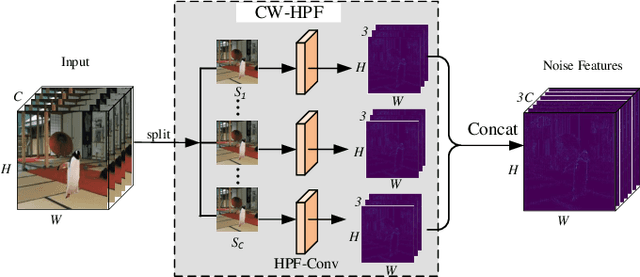
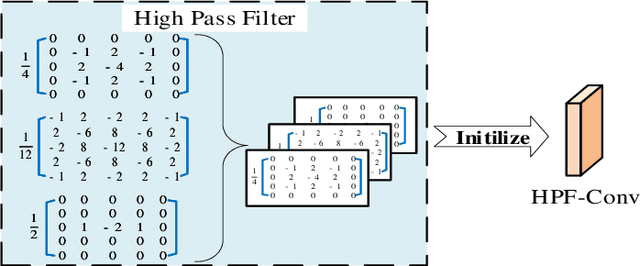
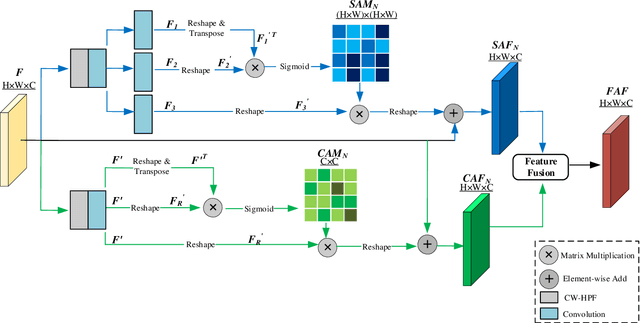
Image editing techniques enable people to modify the content of an image without leaving visual traces and thus may cause serious security risks. Hence the detection and localization of these forgeries become quite necessary and challenging. Furthermore, unlike other tasks with extensive data, there is usually a lack of annotated forged images for training due to annotation difficulties. In this paper, we propose a self-adversarial training strategy and a reliable coarse-to-fine network that utilizes a self-attention mechanism to localize forged regions in forgery images. The self-attention module is based on a Channel-Wise High Pass Filter block (CW-HPF). CW-HPF leverages inter-channel relationships of features and extracts noise features by high pass filters. Based on the CW-HPF, a self-attention mechanism, called forgery attention, is proposed to capture rich contextual dependencies of intrinsic inconsistency extracted from tampered regions. Specifically, we append two types of attention modules on top of CW-HPF respectively to model internal interdependencies in spatial dimension and external dependencies among channels. We exploit a coarse-to-fine network to enhance the noise inconsistency between original and tampered regions. More importantly, to address the issue of insufficient training data, we design a self-adversarial training strategy that expands training data dynamically to achieve more robust performance. Specifically, in each training iteration, we perform adversarial attacks against our network to generate adversarial examples and train our model on them. Extensive experimental results demonstrate that our proposed algorithm steadily outperforms state-of-the-art methods by a clear margin in different benchmark datasets.