 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SDGE: Stereo Guided Depth Estimation for 360$^\circ$ Camera Sets
Feb 29, 2024
Depth estimation is a critical technology in autonomous driving, and multi-camera systems are often used to achieve a 360$^\circ$ perception. These 360$^\circ$ camera sets often have limited or low-quality overlap regions, making multi-view stereo methods infeasible for the entire image. Alternatively, monocular methods may not produce consistent cross-view predictions. To address these issues, we propose the Stereo Guided Depth Estimation (SGDE) method, which enhances depth estimation of the full image by explicitly utilizing multi-view stereo results on the overlap. We suggest building virtual pinhole cameras to resolve the distortion problem of fisheye cameras and unify the processing for the two types of 360$^\circ$ cameras. For handling the varying noise on camera poses caused by unstable movement, the approach employs a self-calibration method to obtain highly accurate relative poses of the adjacent cameras with minor overlap. These enable the use of robust stereo methods to obtain high-quality depth prior in the overlap region. This prior serves not only as an additional input but also as pseudo-labels that enhance the accuracy of depth estimation methods and improve cross-view prediction consistency. The effectiveness of SGDE is evaluated on one fisheye camera dataset, Synthetic Urban, and two pinhole camera datasets, DDAD and nuScenes. Our experiments demonstrate that SGDE is effective for both supervised and self-supervised depth estimation, and highlight the potential of our method for advancing downstream autonomous driving technologies, such as 3D object detection and occupancy prediction.
Less is More: Fewer Interpretable Region via Submodular Subset Selection
Feb 29, 2024Image attribution algorithms aim to identify important regions that are highly relevant to model decisions. Although existing attribution solutions can effectively assign importance to target elements, they still face the following challenges: 1) existing attribution methods generate inaccurate small regions thus misleading the direction of correct attribution, and 2) the model cannot produce good attribution results for samples with wrong predictions. To address the above challenges, this paper re-models the above image attribution problem as a submodular subset selection problem, aiming to enhance model interpretability using fewer regions. To address the lack of attention to local regions, we construct a novel submodular function to discover more accurate small interpretation regions. To enhance the attribution effect for all samples, we also impose four different constraints on the selection of sub-regions, i.e., confidence, effectiveness, consistency, and collaboration scores, to assess the importance of various subsets. Moreover, our theoretical analysis substantiates that the proposed function is in fact submodular. Extensive experiments show that the proposed method outperforms SOTA methods on two face datasets (Celeb-A and VGG-Face2) and one fine-grained dataset (CUB-200-2011). For correctly predicted samples, the proposed method improves the Deletion and Insertion scores with an average of 4.9% and 2.5% gain relative to HSIC-Attribution. For incorrectly predicted samples, our method achieves gains of 81.0% and 18.4% compared to the HSIC-Attribution algorithm in the average highest confidence and Insertion score respectively. The code is released at https://github.com/RuoyuChen10/SMDL-Attribution.
A Surprising Failure? Multimodal LLMs and the NLVR Challenge
Feb 26, 2024This study evaluates three state-of-the-art MLLMs -- GPT-4V, Gemini Pro, and the open-source model IDEFICS -- on the compositional natural language vision reasoning task NLVR. Given a human-written sentence paired with a synthetic image, this task requires the model to determine the truth value of the sentence with respect to the image. Despite the strong performance demonstrated by these models, we observe they perform poorly on NLVR, which was constructed to require compositional and spatial reasoning, and to be robust for semantic and systematic biases.
SAR-AE-SFP: SAR Imagery Adversarial Example in Real Physics domain with Target Scattering Feature Parameters
Mar 02, 2024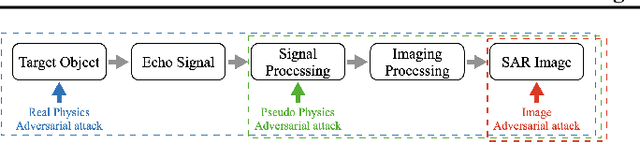
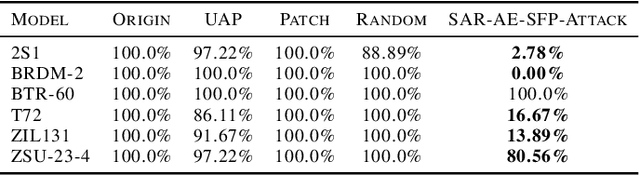
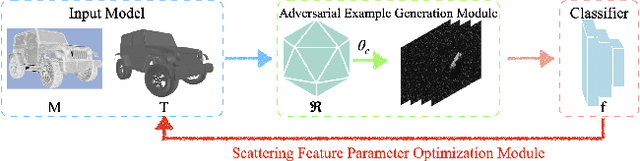
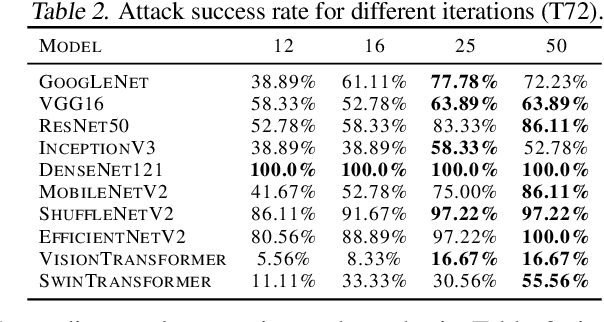
Deep neural network-based Synthetic Aperture Radar (SAR) target recognition models are susceptible to adversarial examples. Current adversarial example generation methods for SAR imagery primarily operate in the 2D digital domain, known as image adversarial examples. Recent work, while considering SAR imaging scatter mechanisms, fails to account for the actual imaging process, rendering attacks in the three-dimensional physical domain infeasible, termed pseudo physics adversarial examples. To address these challenges, this paper proposes SAR-AE-SFP-Attack, a method to generate real physics adversarial examples by altering the scattering feature parameters of target objects. Specifically, we iteratively optimize the coherent energy accumulation of the target echo by perturbing the reflection coefficient and scattering coefficient in the scattering feature parameters of the three-dimensional target object, and obtain the adversarial example after echo signal processing and imaging processing in the RaySAR simulator. Experimental results show that compared to digital adversarial attack methods, SAR-AE-SFP Attack significantly improves attack efficiency on CNN-based models (over 30\%) and Transformer-based models (over 13\%), demonstrating significant transferability of attack effects across different models and perspectives.
InstanceDiffusion: Instance-level Control for Image Generation
Feb 05, 2024Text-to-image diffusion models produce high quality images but do not offer control over individual instances in the image. We introduce InstanceDiffusion that adds precise instance-level control to text-to-image diffusion models. InstanceDiffusion supports free-form language conditions per instance and allows flexible ways to specify instance locations such as simple single points, scribbles, bounding boxes or intricate instance segmentation masks, and combinations thereof. We propose three major changes to text-to-image models that enable precise instance-level control. Our UniFusion block enables instance-level conditions for text-to-image models, the ScaleU block improves image fidelity, and our Multi-instance Sampler improves generations for multiple instances. InstanceDiffusion significantly surpasses specialized state-of-the-art models for each location condition. Notably, on the COCO dataset, we outperform previous state-of-the-art by 20.4% AP$_{50}^\text{box}$ for box inputs, and 25.4% IoU for mask inputs.
Road Surface Defect Detection -- From Image-based to Non-image-based: A Survey
Feb 06, 2024Ensuring traffic safety is crucial, which necessitates the detection and prevention of road surface defects. As a result, there has been a growing interest in the literature on the subject, leading to the development of various road surface defect detection methods. The methods for detecting road defects can be categorised in various ways depending on the input data types or training methodologies. The predominant approach involves image-based methods, which analyse pixel intensities and surface textures to identify defects. Despite their popularity, image-based methods share the distinct limitation of vulnerability to weather and lighting changes. To address this issue, researchers have explored the use of additional sensors, such as laser scanners or LiDARs, providing explicit depth information to enable the detection of defects in terms of scale and volume. However, the exploration of data beyond images has not been sufficiently investigated. In this survey paper, we provide a comprehensive review of road surface defect detection studies, categorising them based on input data types and methodologies used. Additionally, we review recently proposed non-image-based methods and discuss several challenges and open problems associated with these techniques.
A Comprehensive Survey of Convolutions in Deep Learning: Applications, Challenges, and Future Trends
Feb 28, 2024In today's digital age, Convolutional Neural Networks (CNNs), a subset of Deep Learning (DL), are widely used for various computer vision tasks such as image classification, object detection, and image segmentation. There are numerous types of CNNs designed to meet specific needs and requirements, including 1D, 2D, and 3D CNNs, as well as dilated, grouped, attention, depthwise convolutions, and NAS, among others. Each type of CNN has its unique structure and characteristics, making it suitable for specific tasks. It's crucial to gain a thorough understanding and perform a comparative analysis of these different CNN types to understand their strengths and weaknesses. Furthermore, studying the performance, limitations, and practical applications of each type of CNN can aid in the development of new and improved architectures in the future. We also dive into the platforms and frameworks that researchers utilize for their research or development from various perspectives. Additionally, we explore the main research fields of CNN like 6D vision, generative models, and meta-learning. This survey paper provides a comprehensive examination and comparison of various CNN architectures, highlighting their architectural differences and emphasizing their respective advantages, disadvantages, applications, challenges, and future trends.
CharacterGen: Efficient 3D Character Generation from Single Images with Multi-View Pose Canonicalization
Feb 28, 2024In the field of digital content creation, generating high-quality 3D characters from single images is challenging, especially given the complexities of various body poses and the issues of self-occlusion and pose ambiguity. In this paper, we present CharacterGen, a framework developed to efficiently generate 3D characters. CharacterGen introduces a streamlined generation pipeline along with an image-conditioned multi-view diffusion model. This model effectively calibrates input poses to a canonical form while retaining key attributes of the input image, thereby addressing the challenges posed by diverse poses. A transformer-based, generalizable sparse-view reconstruction model is the other core component of our approach, facilitating the creation of detailed 3D models from multi-view images. We also adopt a texture-back-projection strategy to produce high-quality texture maps. Additionally, we have curated a dataset of anime characters, rendered in multiple poses and views, to train and evaluate our model. Our approach has been thoroughly evaluated through quantitative and qualitative experiments, showing its proficiency in generating 3D characters with high-quality shapes and textures, ready for downstream applications such as rigging and animation.
FESS Loss: Feature-Enhanced Spatial Segmentation Loss for Optimizing Medical Image Analysis
Feb 13, 2024Medical image segmentation is a critical process in the field of medical imaging, playing a pivotal role in diagnosis, treatment, and research. It involves partitioning of an image into multiple regions, representing distinct anatomical or pathological structures. Conventional methods often grapple with the challenge of balancing spatial precision and comprehensive feature representation due to their reliance on traditional loss functions. To overcome this, we propose Feature-Enhanced Spatial Segmentation Loss (FESS Loss), that integrates the benefits of contrastive learning (which extracts intricate features, particularly in the nuanced domain of medical imaging) with the spatial accuracy inherent in the Dice loss. The objective is to augment both spatial precision and feature-based representation in the segmentation of medical images. FESS Loss signifies a notable advancement, offering a more accurate and refined segmentation process, ultimately contributing to heightened precision in the analysis of medical images. Further, FESS loss demonstrates superior performance in limited annotated data availability scenarios often present in the medical domain.
Machine Unlearning for Image-to-Image Generative Models
Feb 01, 2024Machine unlearning has emerged as a new paradigm to deliberately forget data samples from a given model in order to adhere to stringent regulations. However, existing machine unlearning methods have been primarily focused on classification models, leaving the landscape of unlearning for generative models relatively unexplored. This paper serves as a bridge, addressing the gap by providing a unifying framework of machine unlearning for image-to-image generative models. Within this framework, we propose a computationally-efficient algorithm, underpinned by rigorous theoretical analysis, that demonstrates negligible performance degradation on the retain samples, while effectively removing the information from the forget samples. Empirical studies on two large-scale datasets, ImageNet-1K and Places-365, further show that our algorithm does not rely on the availability of the retain samples, which further complies with data retention policy. To our best knowledge, this work is the first that represents systemic, theoretical, empirical explorations of machine unlearning specifically tailored for image-to-image generative models. Our code is available at https://github.com/jpmorganchase/l2l-generator-unlearning.