 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Attention-based Image Captioning
Apr 30, 2021
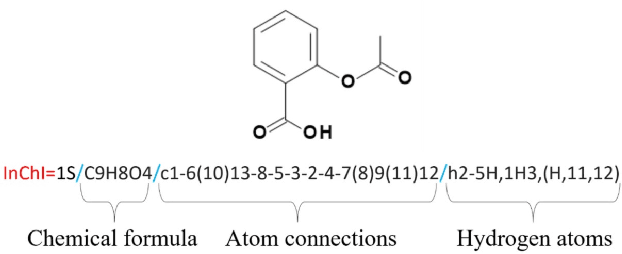
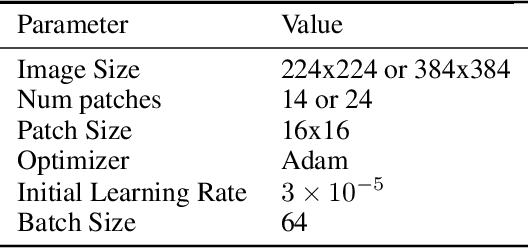
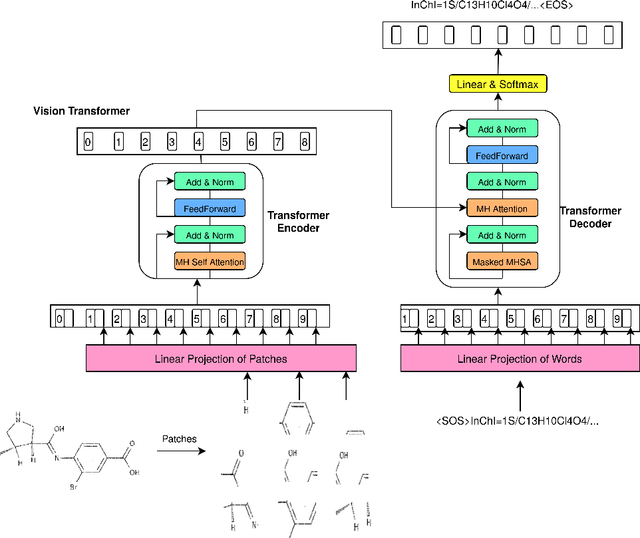
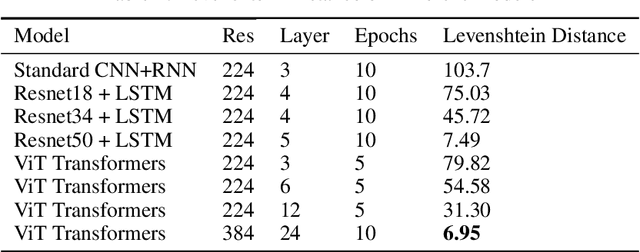
In this paper, we address the problem of image captioning specifically for molecular translation where the result would be a predicted chemical notation in InChI format for a given molecular structure. Current approaches mainly follow rule-based or CNN+RNN based methodology. However, they seem to underperform on noisy images and images with small number of distinguishable features. To overcome this, we propose an end-to-end transformer model. When compared to attention-based techniques, our proposed model outperforms on molecular datasets.
Monotonically Convergent Regularization by Denoising
Feb 10, 2022



Regularization by denoising (RED) is a widely-used framework for solving inverse problems by leveraging image denoisers as image priors. Recent work has reported the state-of-the-art performance of RED in a number of imaging applications using pre-trained deep neural nets as denoisers. Despite the recent progress, the stable convergence of RED algorithms remains an open problem. The existing RED theory only guarantees stability for convex data-fidelity terms and nonexpansive denoisers. This work addresses this issue by developing a new monotone RED (MRED) algorithm, whose convergence does not require nonexpansiveness of the deep denoising prior. Simulations on image deblurring and compressive sensing recovery from random matrices show the stability of MRED even when the traditional RED algorithm diverges.
Autonomous crater detection on asteroids using a fully-convolutional neural network
Apr 01, 2022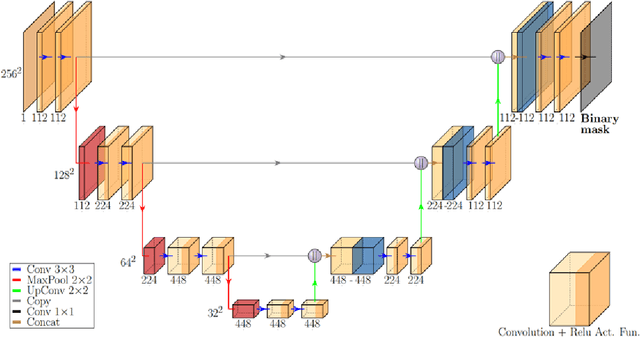



This paper shows the application of autonomous Crater Detection using the U-Net, a Fully-Convolutional Neural Network, on Ceres. The U-Net is trained on optical images of the Moon Global Morphology Mosaic based on data collected by the LRO and manual crater catalogues. The Moon-trained network will be tested on Dawn optical images of Ceres: this task is accomplished by means of a Transfer Learning (TL) approach. The trained model has been fine-tuned using 100, 500 and 1000 additional images of Ceres. The test performance was measured on 350 never before seen images, reaching a testing accuracy of 96.24%, 96.95% and 97.19%, respectively. This means that despite the intrinsic differences between the Moon and Ceres, TL works with encouraging results. The output of the U-Net contains predicted craters: it will be post-processed applying global thresholding for image binarization and a template matching algorithm to extract craters positions and radii in the pixel space. Post-processed craters will be counted and compared to the ground truth data in order to compute image segmentation metrics: precision, recall and F1 score. These indices will be computed, and their effect will be discussed for tasks such as automated crater cataloguing and optical navigation.
SALISA: Saliency-based Input Sampling for Efficient Video Object Detection
Apr 05, 2022
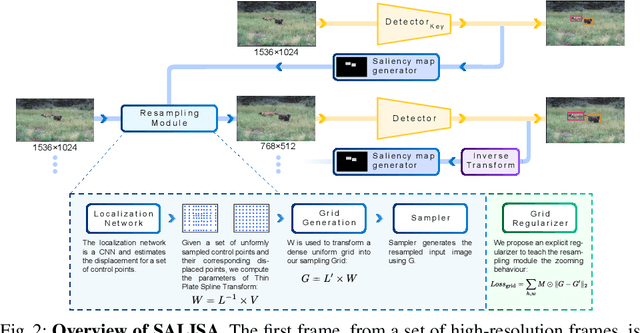
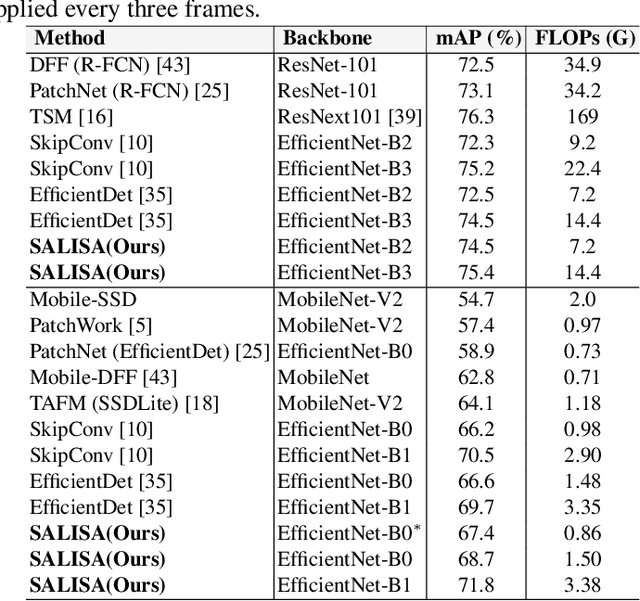

High-resolution images are widely adopted for high-performance object detection in videos. However, processing high-resolution inputs comes with high computation costs, and naive down-sampling of the input to reduce the computation costs quickly degrades the detection performance. In this paper, we propose SALISA, a novel non-uniform SALiency-based Input SAmpling technique for video object detection that allows for heavy down-sampling of unimportant background regions while preserving the fine-grained details of a high-resolution image. The resulting image is spatially smaller, leading to reduced computational costs while enabling a performance comparable to a high-resolution input. To achieve this, we propose a differentiable resampling module based on a thin plate spline spatial transformer network (TPS-STN). This module is regularized by a novel loss to provide an explicit supervision signal to learn to "magnify" salient regions. We report state-of-the-art results in the low compute regime on the ImageNet-VID and UA-DETRAC video object detection datasets. We demonstrate that on both datasets, the mAP of an EfficientDet-D1 (EfficientDet-D2) gets on par with EfficientDet-D2 (EfficientDet-D3) at a much lower computational cost. We also show that SALISA significantly improves the detection of small objects. In particular, SALISA with an EfficientDet-D1 detector improves the detection of small objects by $77\%$, and remarkably also outperforms EfficientDetD3 baseline.
Time-multiplexed Neural Holography: A flexible framework for holographic near-eye displays with fast heavily-quantized spatial light modulators
May 05, 2022
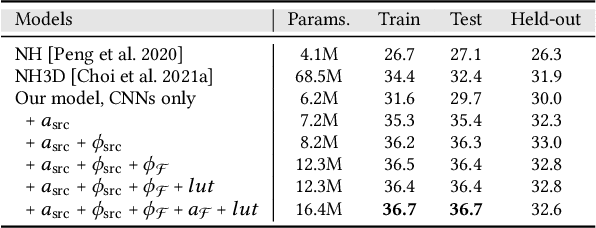

Holographic near-eye displays offer unprecedented capabilities for virtual and augmented reality systems, including perceptually important focus cues. Although artificial intelligence--driven algorithms for computer-generated holography (CGH) have recently made much progress in improving the image quality and synthesis efficiency of holograms, these algorithms are not directly applicable to emerging phase-only spatial light modulators (SLM) that are extremely fast but offer phase control with very limited precision. The speed of these SLMs offers time multiplexing capabilities, essentially enabling partially-coherent holographic display modes. Here we report advances in camera-calibrated wave propagation models for these types of holographic near-eye displays and we develop a CGH framework that robustly optimizes the heavily quantized phase patterns of fast SLMs. Our framework is flexible in supporting runtime supervision with different types of content, including 2D and 2.5D RGBD images, 3D focal stacks, and 4D light fields. Using our framework, we demonstrate state-of-the-art results for all of these scenarios in simulation and experiment.
Coupled Iterative Refinement for 6D Multi-Object Pose Estimation
Apr 26, 2022
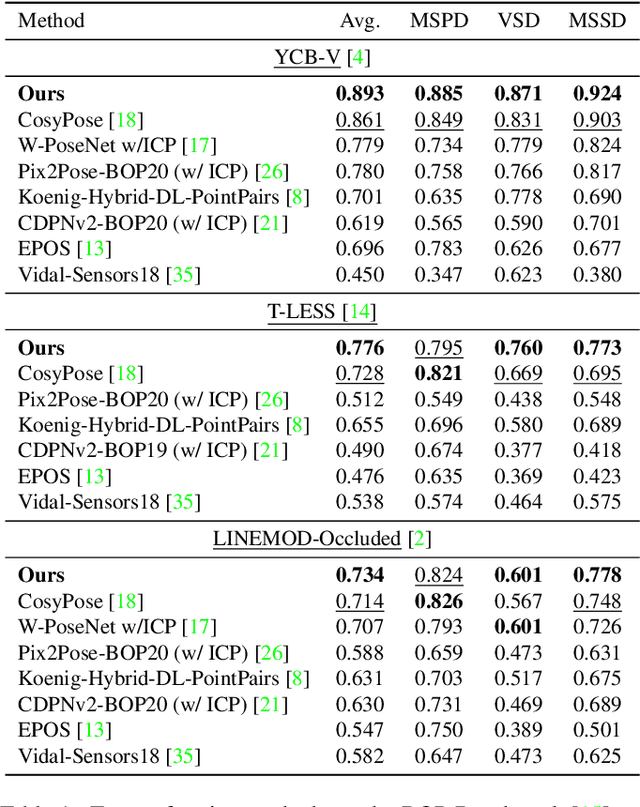
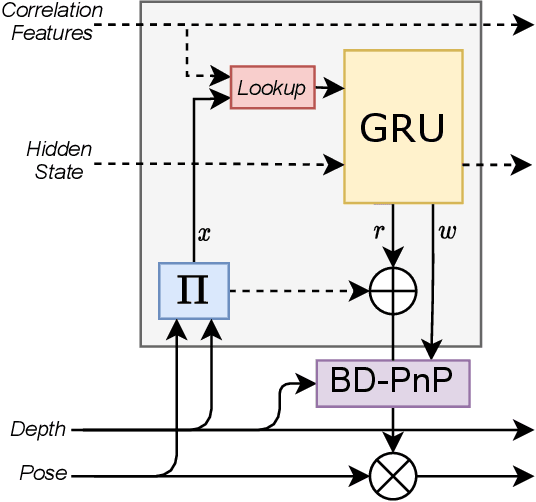
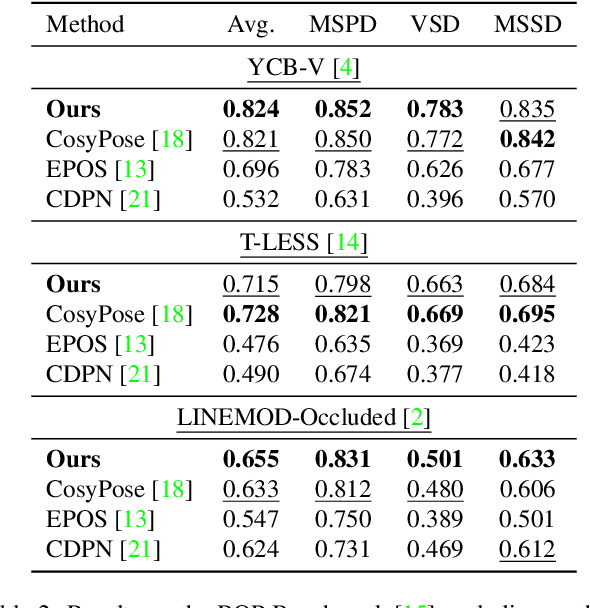
We address the task of 6D multi-object pose: given a set of known 3D objects and an RGB or RGB-D input image, we detect and estimate the 6D pose of each object. We propose a new approach to 6D object pose estimation which consists of an end-to-end differentiable architecture that makes use of geometric knowledge. Our approach iteratively refines both pose and correspondence in a tightly coupled manner, allowing us to dynamically remove outliers to improve accuracy. We use a novel differentiable layer to perform pose refinement by solving an optimization problem we refer to as Bidirectional Depth-Augmented Perspective-N-Point (BD-PnP). Our method achieves state-of-the-art accuracy on standard 6D Object Pose benchmarks. Code is available at https://github.com/princeton-vl/Coupled-Iterative-Refinement.
Secondary complementary balancing compressive imaging with a free-space balanced amplified photodetector
Mar 18, 2022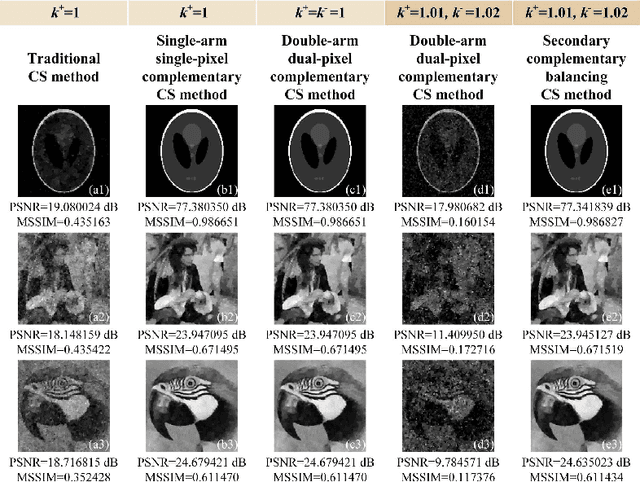

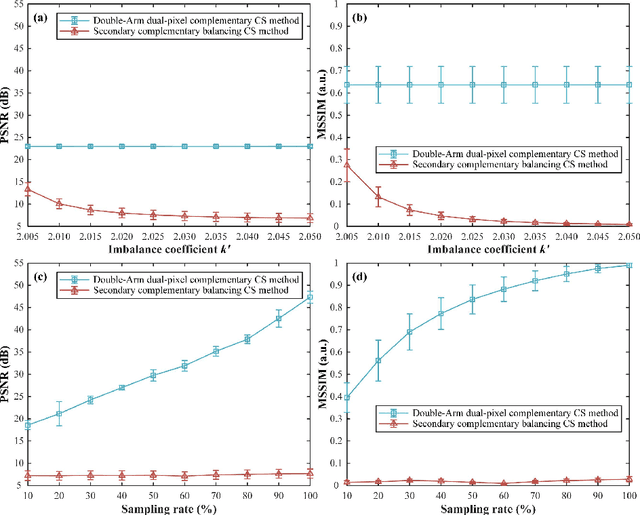

Single-pixel imaging (SPI) has attracted widespread attention because it generally uses a non-pixelated photodetector and a digital micromirror device (DMD) to acquire the object image. Since the modulated patterns seen from two reflection directions of the DMD are naturally complementary, one can apply complementary balanced measurements to greatly improve the measurement signal-to-noise ratio and reconstruction quality. However, the balance between two reflection arms significantly determines the quality of differential measurements. In this work, we propose and demonstrate a simple secondary complementary balancing mechanism to minimize the impact of the imbalance on the imaging system. In our SPI setup, we used a silicon free-space balanced amplified photodetector with 5 mm active diameter which could directly output the difference between two optical input signals in two reflection arms. Both simulation and experimental results have demonstrated that the use of secondary complementary balancing can result in a better cancellation of direct current components of measurements and a better image restoration quality.
Learning degraded image classification with restoration data fidelity
Jan 23, 2021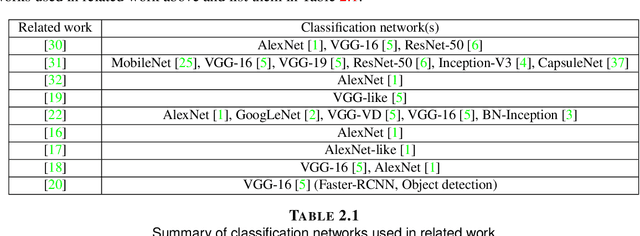
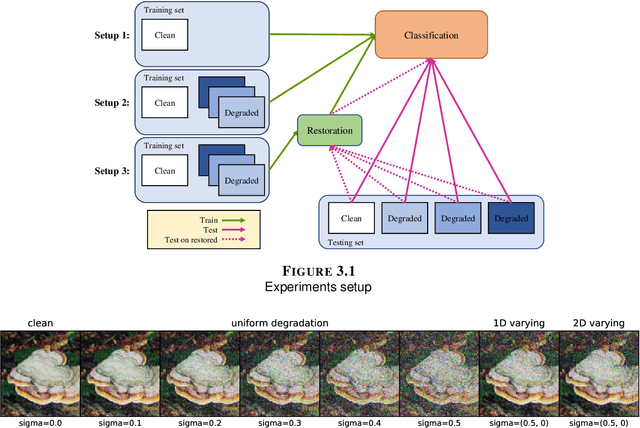
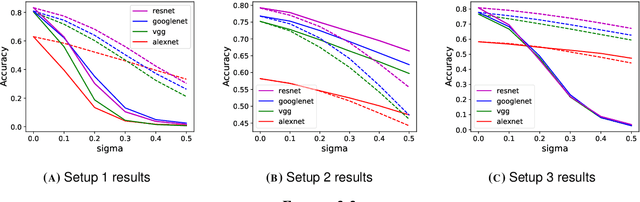
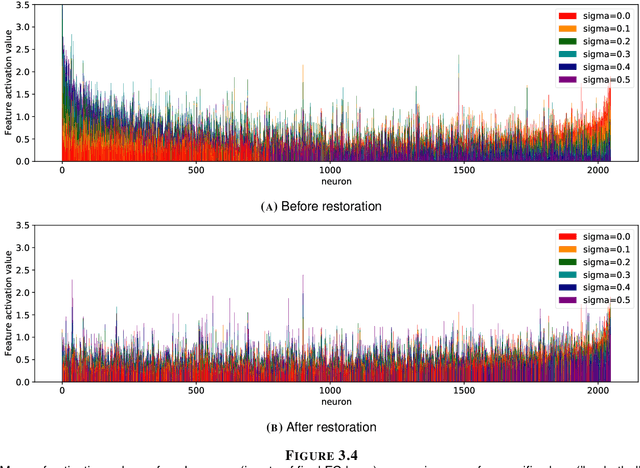
Learning-based methods especially with convolutional neural networks (CNN) are continuously showing superior performance in computer vision applications, ranging from image classification to restoration. For image classification, most existing works focus on very clean images such as images in Caltech-256 and ImageNet datasets. However, in most realistic scenarios, the acquired images may suffer from degradation. One important and interesting problem is to combine image classification and restoration tasks to improve the performance of CNN-based classification networks on degraded images. In this report, we explore the influence of degradation types and levels on four widely-used classification networks, and the use of a restoration network to eliminate the degradation's influence. We also propose a novel method leveraging a fidelity map to calibrate the image features obtained by pre-trained classification networks. We empirically demonstrate that our proposed method consistently outperforms the pre-trained networks under all degradation levels and types with additive white Gaussian noise (AWGN), and it even outperforms the re-trained networks for degraded images under low degradation levels. We also show that the proposed method is a model-agnostic approach that benefits different classification networks. Our results reveal that the proposed method is a promising solution to mitigate the effect caused by image degradation.
Level set based particle filter driven by optical flow: an application to track the salt boundary from X-ray CT time-series
Feb 17, 2022Image-based computational fluid dynamics have long played an important role in leveraging knowledge and understanding of several physical phenomena. In particular, probabilistic computational methods have opened the way to modelling the complex dynamics of systems in purely random turbulent motion. In the field of structural geology, a better understanding of the deformation and stress state both within the salt and the surrounding rocks is of great interest to characterize all kinds of subsurface long-terms energy-storage systems. The objective of this research is to determine the non-linear deformation of the salt boundary over time using a parallelized, stochastic filtering approach from x-ray computed tomography (CT) image time series depicting the evolution of salt structures triggered by gravity and under differential loading. This work represents a first step towards bringing together physical modeling and advanced stochastic image processing methods where model uncertainty is taken into account.
MOGAN: Morphologic-structure-aware Generative Learning from a Single Image
Mar 04, 2021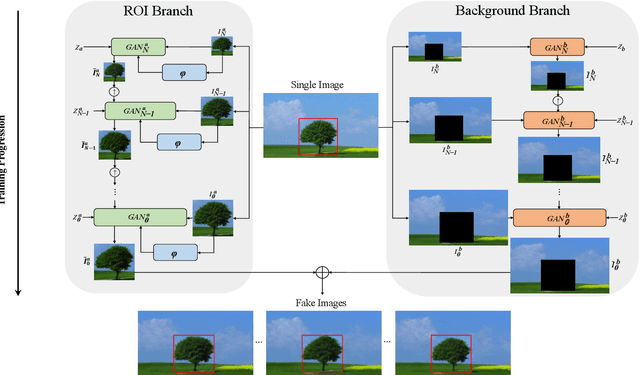
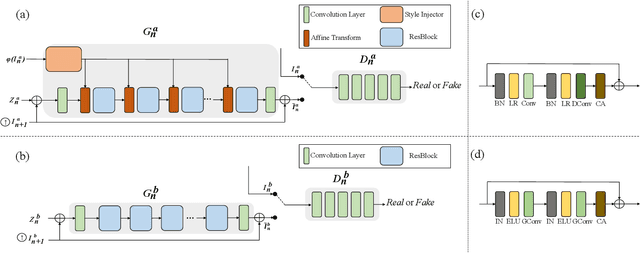

In most interactive image generation tasks, given regions of interest (ROI) by users, the generated results are expected to have adequate diversities in appearance while maintaining correct and reasonable structures in original images. Such tasks become more challenging if only limited data is available. Recently proposed generative models complete training based on only one image. They pay much attention to the monolithic feature of the sample while ignoring the actual semantic information of different objects inside the sample. As a result, for ROI-based generation tasks, they may produce inappropriate samples with excessive randomicity and without maintaining the related objects' correct structures. To address this issue, this work introduces a MOrphologic-structure-aware Generative Adversarial Network named MOGAN that produces random samples with diverse appearances and reliable structures based on only one image. For training for ROI, we propose to utilize the data coming from the original image being augmented and bring in a novel module to transform such augmented data into knowledge containing both structures and appearances, thus enhancing the model's comprehension of the sample. To learn the rest areas other than ROI, we employ binary masks to ensure the generation isolated from ROI. Finally, we set parallel and hierarchical branches of the mentioned learning process. Compared with other single image GAN schemes, our approach focuses on internal features including the maintenance of rational structures and variation on appearance. Experiments confirm a better capacity of our model on ROI-based image generation tasks than its competitive peers.