 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Analysis of Interpolation based Image In-painting Approaches
Feb 12, 2021



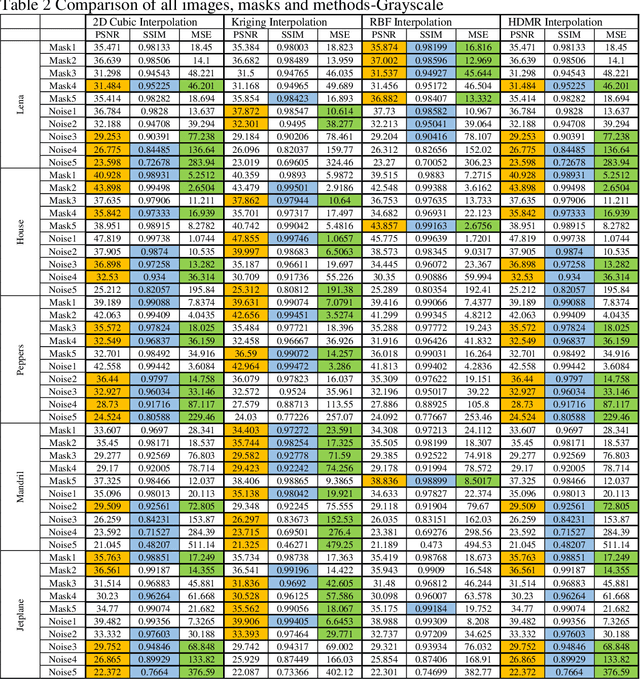
Interpolation and internal painting are one of the basic approaches in image internal painting, which is used to eliminate undesirable parts that occur in digital images or to enhance faulty parts. This study was designed to compare the interpolation algorithms used in image in-painting in the literature. Errors and noise generated on the colour and grayscale formats of some of the commonly used standard images in the literature were corrected by using Cubic, Kriging, Radial based function and High dimensional model representation approaches and the results were compared using standard image comparison criteria, namely, PSNR (peak signal-to-noise ratio), SSIM (Structural SIMilarity), Mean Square Error (MSE). According to the results obtained from the study, the absolute superiority of the methods against each other was not observed. However, Kriging and RBF interpolation give better results both for numerical data and visual evaluation for image in-painting problems with large area losses.
HeatER: An Efficient and Unified Network for Human Reconstruction via Heatmap-based TransformER
May 30, 2022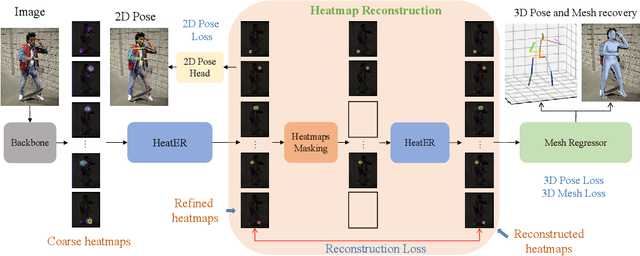
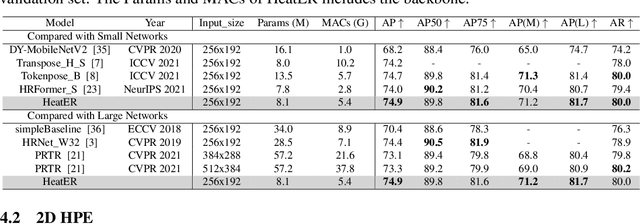
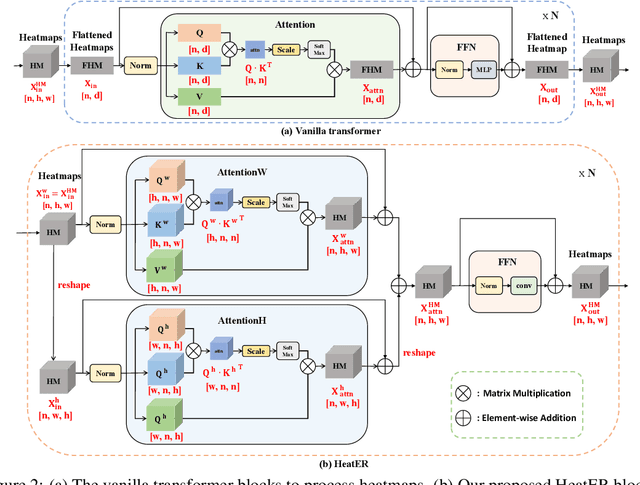
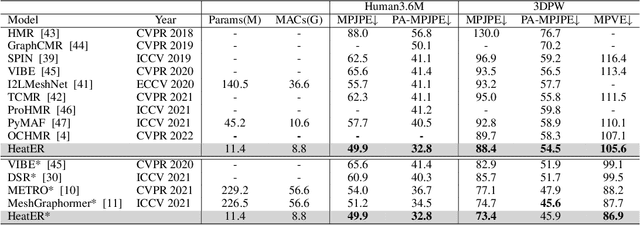
Recently, vision transformers have shown great success in 2D human pose estimation (2D HPE), 3D human pose estimation (3D HPE), and human mesh reconstruction (HMR) tasks. In these tasks, heatmap representations of the human structural information are often extracted first from the image by a CNN, and then further processed with a transformer architecture to provide the final HPE or HMR estimation. However, existing transformer architectures are not able to process these heatmap inputs directly, forcing an unnatural flattening of the features prior to input. Furthermore, much of the performance benefit in recent HPE and HMR methods has come at the cost of ever-increasing computation and memory needs. Therefore, to simultaneously address these problems, we propose HeatER, a novel transformer design which preserves the inherent structure of heatmap representations when modeling attention while reducing the memory and computational costs. Taking advantage of HeatER, we build a unified and efficient network for 2D HPE, 3D HPE, and HMR tasks. A heatmap reconstruction module is applied to improve the robustness of the estimated human pose and mesh. Extensive experiments demonstrate the effectiveness of HeatER on various human pose and mesh datasets. For instance, HeatER outperforms the SOTA method MeshGraphormer by requiring 5% of Params and 16% of MACs on Human3.6M and 3DPW datasets. Code will be publicly available.
Face-Dubbing++: Lip-Synchronous, Voice Preserving Translation of Videos
Jun 09, 2022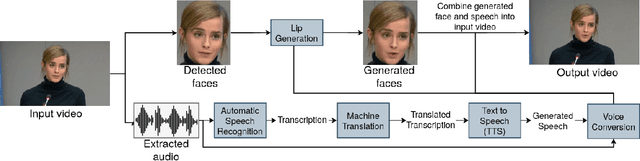
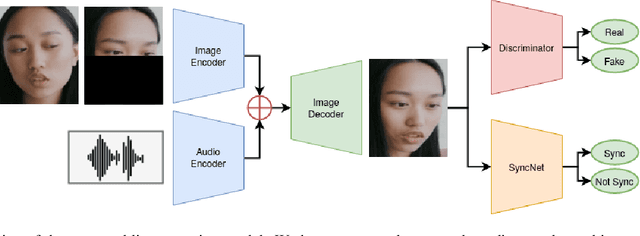
In this paper, we propose a neural end-to-end system for voice preserving, lip-synchronous translation of videos. The system is designed to combine multiple component models and produces a video of the original speaker speaking in the target language that is lip-synchronous with the target speech, yet maintains emphases in speech, voice characteristics, face video of the original speaker. The pipeline starts with automatic speech recognition including emphasis detection, followed by a translation model. The translated text is then synthesized by a Text-to-Speech model that recreates the original emphases mapped from the original sentence. The resulting synthetic voice is then mapped back to the original speakers' voice using a voice conversion model. Finally, to synchronize the lips of the speaker with the translated audio, a conditional generative adversarial network-based model generates frames of adapted lip movements with respect to the input face image as well as the output of the voice conversion model. In the end, the system combines the generated video with the converted audio to produce the final output. The result is a video of a speaker speaking in another language without actually knowing it. To evaluate our design, we present a user study of the complete system as well as separate evaluations of the single components. Since there is no available dataset to evaluate our whole system, we collect a test set and evaluate our system on this test set. The results indicate that our system is able to generate convincing videos of the original speaker speaking the target language while preserving the original speaker's characteristics. The collected dataset will be shared.
LAPAR: Linearly-Assembled Pixel-Adaptive Regression Network for Single Image Super-Resolution and Beyond
May 21, 2021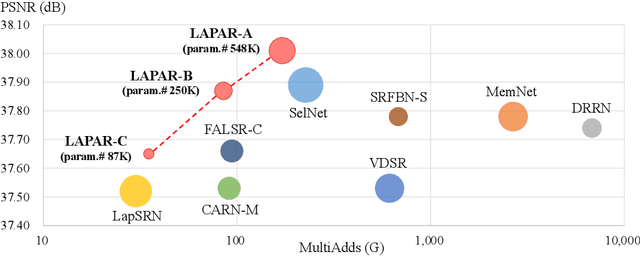
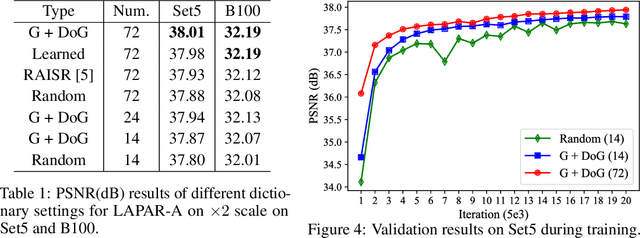
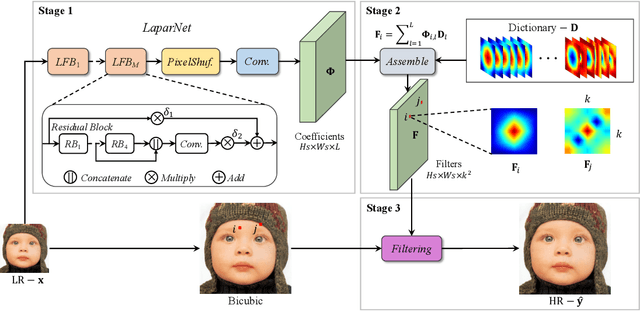
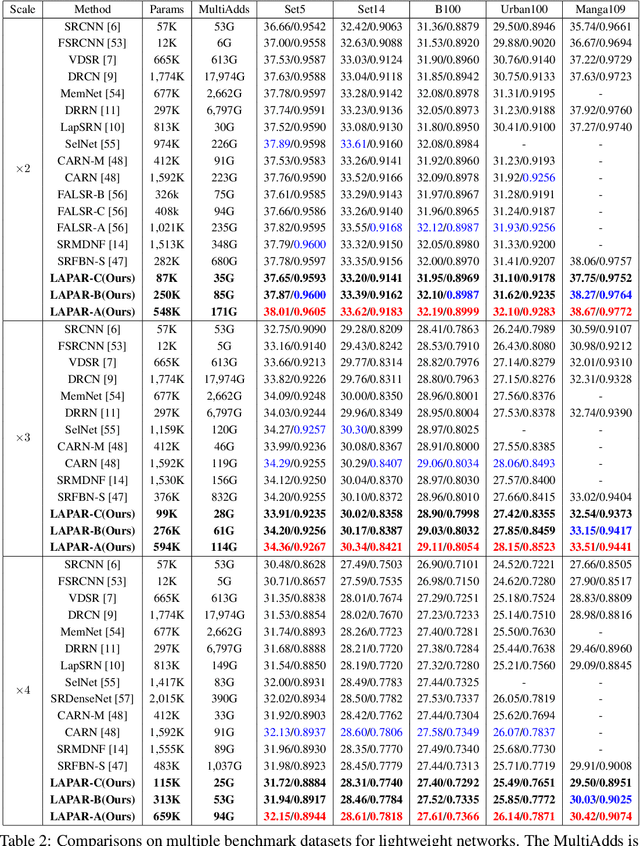
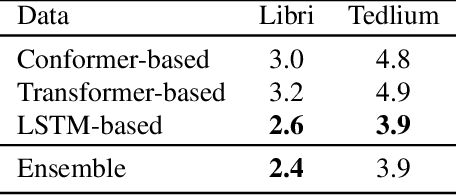
Single image super-resolution (SISR) deals with a fundamental problem of upsampling a low-resolution (LR) image to its high-resolution (HR) version. Last few years have witnessed impressive progress propelled by deep learning methods. However, one critical challenge faced by existing methods is to strike a sweet spot of deep model complexity and resulting SISR quality. This paper addresses this pain point by proposing a linearly-assembled pixel-adaptive regression network (LAPAR), which casts the direct LR to HR mapping learning into a linear coefficient regression task over a dictionary of multiple predefined filter bases. Such a parametric representation renders our model highly lightweight and easy to optimize while achieving state-of-the-art results on SISR benchmarks. Moreover, based on the same idea, LAPAR is extended to tackle other restoration tasks, e.g., image denoising and JPEG image deblocking, and again, yields strong performance. The code is available at https://github.com/dvlab-research/Simple-SR.
Cross-view Transformers for real-time Map-view Semantic Segmentation
May 05, 2022



We present cross-view transformers, an efficient attention-based model for map-view semantic segmentation from multiple cameras. Our architecture implicitly learns a mapping from individual camera views into a canonical map-view representation using a camera-aware cross-view attention mechanism. Each camera uses positional embeddings that depend on its intrinsic and extrinsic calibration. These embeddings allow a transformer to learn the mapping across different views without ever explicitly modeling it geometrically. The architecture consists of a convolutional image encoder for each view and cross-view transformer layers to infer a map-view semantic segmentation. Our model is simple, easily parallelizable, and runs in real-time. The presented architecture performs at state-of-the-art on the nuScenes dataset, with 4x faster inference speeds. Code is available at https://github.com/bradyz/cross_view_transformers.
Cross-modal Local Shortest Path and Global Enhancement for Visible-Thermal Person Re-Identification
Jun 09, 2022



In addition to considering the recognition difficulty caused by human posture and occlusion, it is also necessary to solve the modal differences caused by different imaging systems in the Visible-Thermal cross-modal person re-identification (VT-ReID) task. In this paper,we propose the Cross-modal Local Shortest Path and Global Enhancement (CM-LSP-GE) modules,a two-stream network based on joint learning of local and global features. The core idea of our paper is to use local feature alignment to solve occlusion problem, and to solve modal difference by strengthening global feature. Firstly, Attention-based two-stream ResNet network is designed to extract dual-modality features and map to a unified feature space. Then, to solve the cross-modal person pose and occlusion problems, the image are cut horizontally into several equal parts to obtain local features and the shortest path in local features between two graphs is used to achieve the fine-grained local feature alignment. Thirdly, a batch normalization enhancement module applies global features to enhance strategy, resulting in difference enhancement between different classes. The multi granularity loss fusion strategy further improves the performance of the algorithm. Finally, joint learning mechanism of local and global features is used to improve cross-modal person re-identification accuracy. The experimental results on two typical datasets show that our model is obviously superior to the most state-of-the-art methods. Especially, on SYSU-MM01 datasets, our model can achieve a gain of 2.89%and 7.96% in all search term of Rank-1 and mAP. The source code will be released soon.
Was that so hard? Estimating human classification difficulty
Mar 22, 2022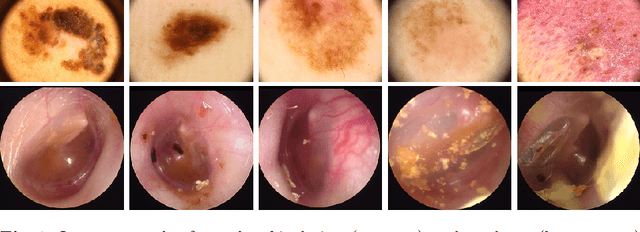
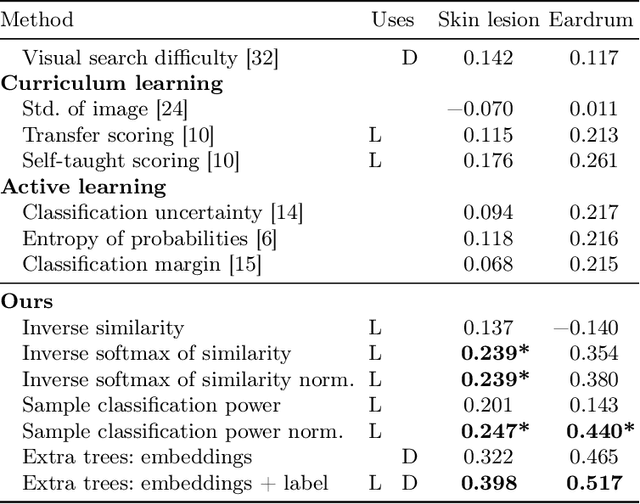
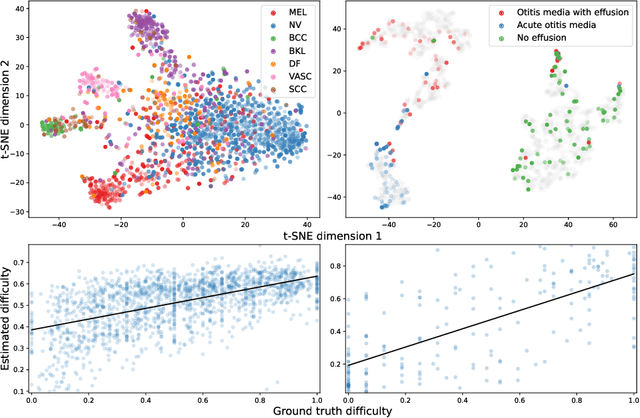
When doctors are trained to diagnose a specific disease, they learn faster when presented with cases in order of increasing difficulty. This creates the need for automatically estimating how difficult it is for doctors to classify a given case. In this paper, we introduce methods for estimating how hard it is for a doctor to diagnose a case represented by a medical image, both when ground truth difficulties are available for training, and when they are not. Our methods are based on embeddings obtained with deep metric learning. Additionally, we introduce a practical method for obtaining ground truth human difficulty for each image case in a dataset using self-assessed certainty. We apply our methods to two different medical datasets, achieving high Kendall rank correlation coefficients, showing that we outperform existing methods by a large margin on our problem and data.
Widely Distributed Radar Imaging: Unmediated ADMM Based Approach
Mar 10, 2022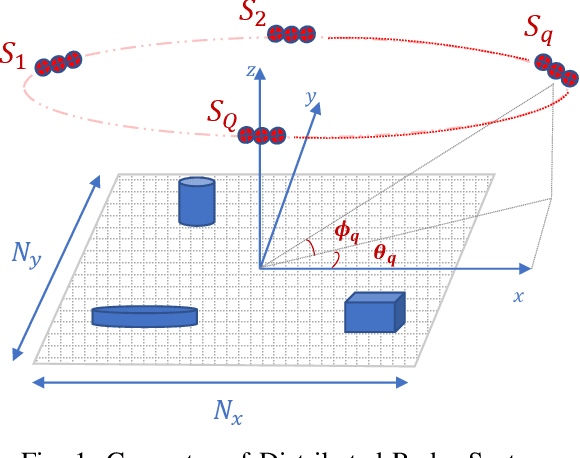
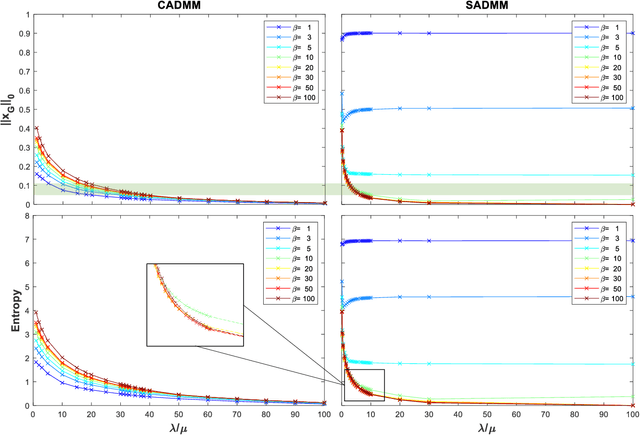
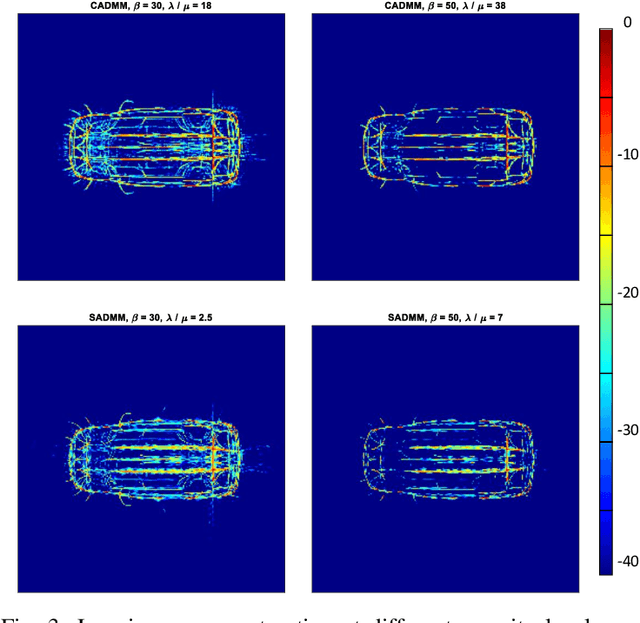
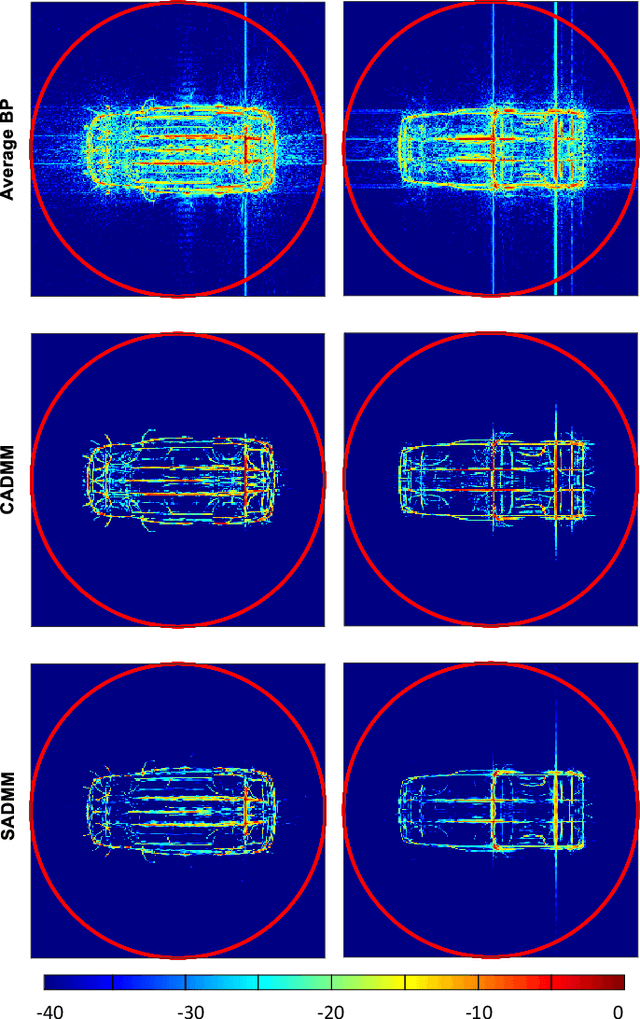
In this paper, we present a novel approach to reconstruct a unique image of an observed scene with widely distributed radar sensors. The problem is posed as a constrained optimization problem in which the global image which represents the aggregate view of the sensors is a decision variable. While the problem is designed to promote a sparse solution for the global image, it is constrained such that a relationship with local images that can be reconstructed using the measurements at each sensor is respected. Two problem formulations are introduced by stipulating two different establishments of that relationship. The proposed formulations are designed according to consensus ADMM (CADMM) and sharing ADMM (SADMM), and their solutions are provided accordingly as iterative algorithms. We drive the explicit variable updates for each algorithm in addition to the recommended scheme for hybrid parallel implementation on the distributed sensors and a central processing unit. Our algorithms are validated and their performance is evaluated exploiting Civilian Vehicles Dome data-set to realize different scenarios of practical relevance. Experimental results show the effectiveness of the proposed algorithms, especially in cases with limited measurements.
Deep Metric Learning for Few-Shot Image Classification: A Selective Review
May 17, 2021
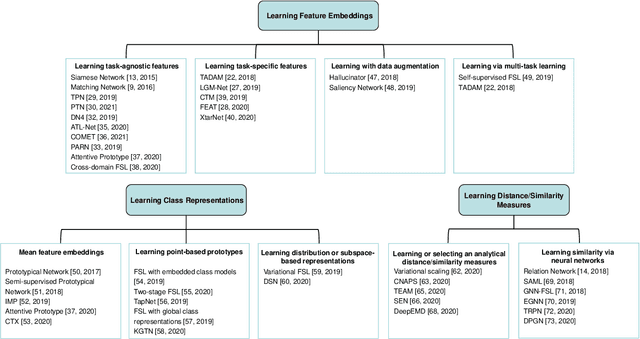
Few-shot image classification is a challenging problem which aims to achieve the human level of recognition based only on a small number of images. Deep learning algorithms such as meta-learning, transfer learning, and metric learning have been employed recently and achieved the state-of-the-art performance. In this survey, we review representative deep metric learning methods for few-shot classification, and categorize them into three groups according to the major problems and novelties they focus on. We conclude this review with a discussion on current challenges and future trends in few-shot image classification.
Using Text to Teach Image Retrieval
Nov 19, 2020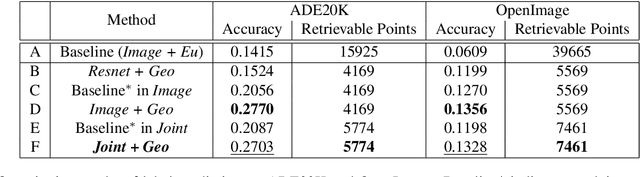
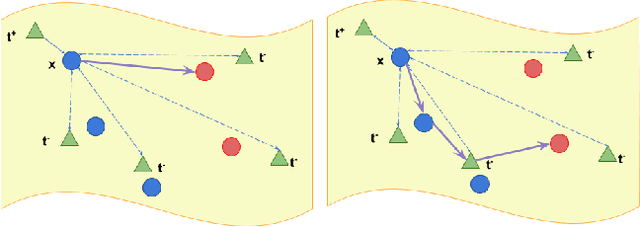
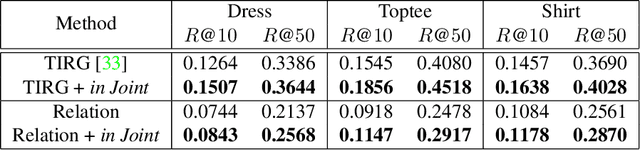

Image retrieval relies heavily on the quality of the data modeling and the distance measurement in the feature space. Building on the concept of image manifold, we first propose to represent the feature space of images, learned via neural networks, as a graph. Neighborhoods in the feature space are now defined by the geodesic distance between images, represented as graph vertices or manifold samples. When limited images are available, this manifold is sparsely sampled, making the geodesic computation and the corresponding retrieval harder. To address this, we augment the manifold samples with geometrically aligned text, thereby using a plethora of sentences to teach us about images. In addition to extensive results on standard datasets illustrating the power of text to help in image retrieval, a new public dataset based on CLEVR is introduced to quantify the semantic similarity between visual data and text data. The experimental results show that the joint embedding manifold is a robust representation, allowing it to be a better basis to perform image retrieval given only an image and a textual instruction on the desired modifications over the image