 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Behavioral Economics Approach to Interpretable Deep Image Classification. Rationally Inattentive Utility Maximization Explains Deep Image Classification
Feb 09, 2021
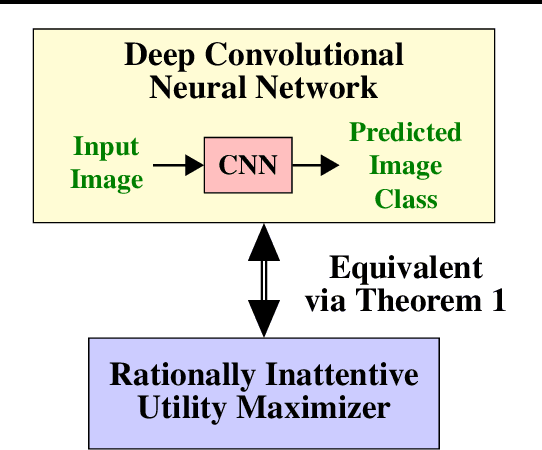

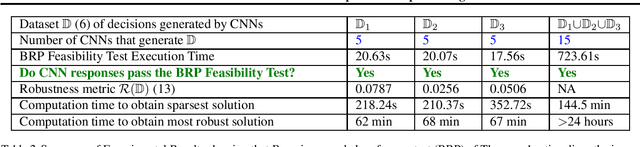
Are deep convolutional neural networks (CNNs) for image classification consistent with utility maximization behavior with information acquisition costs? This paper demonstrates the remarkable result that a deep CNN behaves equivalently (in terms of necessary and sufficient conditions) to a rationally inattentive utility maximizer, a model extensively used in behavioral economics to explain human decision making. This implies that a deep CNN has a parsimonious representation in terms of simple intuitive human-like decision parameters, namely, a utility function and an information acquisition cost. Also the reconstructed utility function that rationalizes the decisions of the deep CNNs, yields a useful preference order amongst the image classes (hypotheses).
Coupled Iterative Refinement for 6D Multi-Object Pose Estimation
Apr 26, 2022
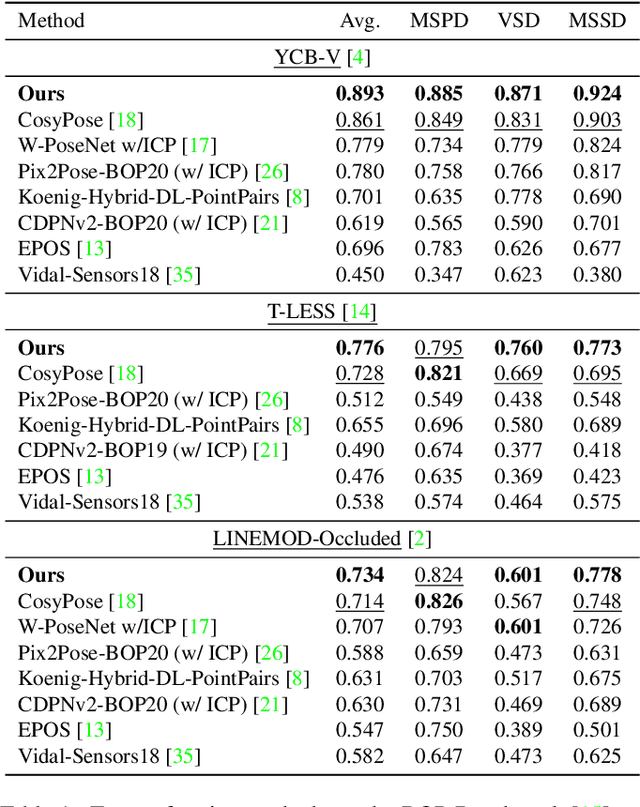
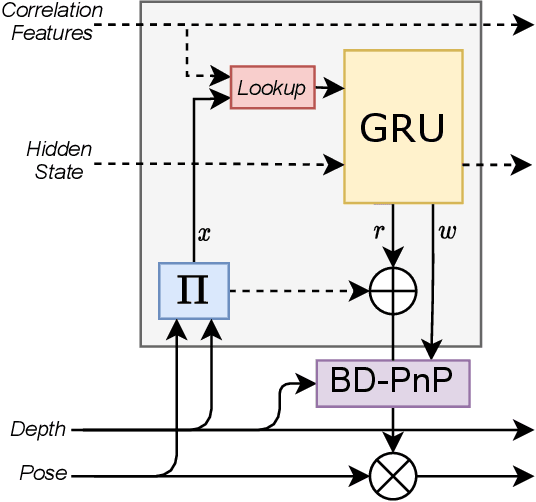
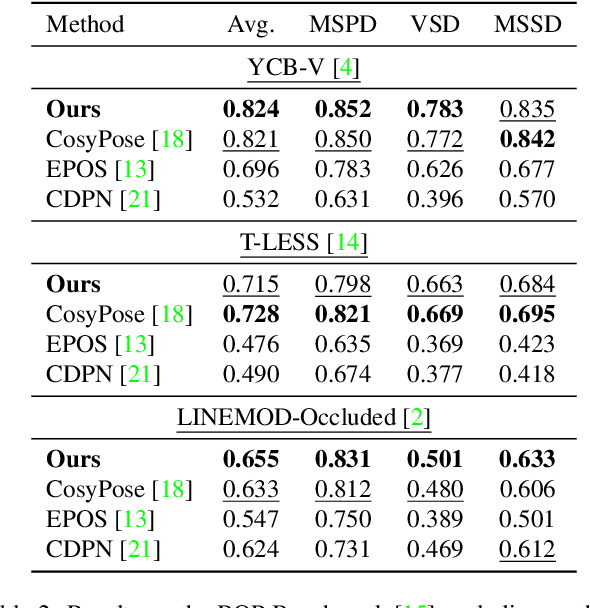
We address the task of 6D multi-object pose: given a set of known 3D objects and an RGB or RGB-D input image, we detect and estimate the 6D pose of each object. We propose a new approach to 6D object pose estimation which consists of an end-to-end differentiable architecture that makes use of geometric knowledge. Our approach iteratively refines both pose and correspondence in a tightly coupled manner, allowing us to dynamically remove outliers to improve accuracy. We use a novel differentiable layer to perform pose refinement by solving an optimization problem we refer to as Bidirectional Depth-Augmented Perspective-N-Point (BD-PnP). Our method achieves state-of-the-art accuracy on standard 6D Object Pose benchmarks. Code is available at https://github.com/princeton-vl/Coupled-Iterative-Refinement.
iWave3D: End-to-end Brain Image Compression with Trainable 3-D Wavelet Transform
Sep 18, 2021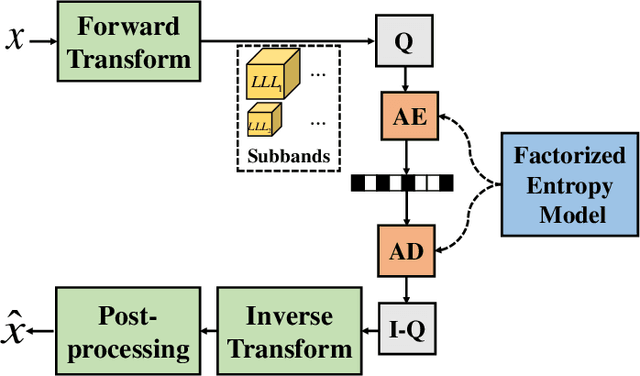
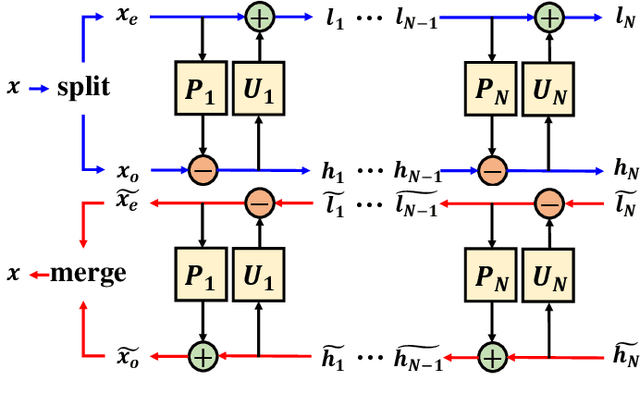
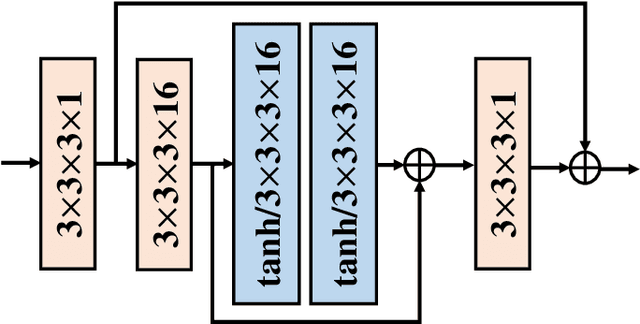
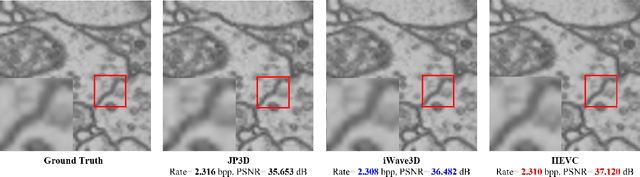
With the rapid development of whole brain imaging technology, a large number of brain images have been produced, which puts forward a great demand for efficient brain image compression methods. At present, the most commonly used compression methods are all based on 3-D wavelet transform, such as JP3D. However, traditional 3-D wavelet transforms are designed manually with certain assumptions on the signal, but brain images are not as ideal as assumed. What's more, they are not directly optimized for compression task. In order to solve these problems, we propose a trainable 3-D wavelet transform based on the lifting scheme, in which the predict and update steps are replaced by 3-D convolutional neural networks. Then the proposed transform is embedded into an end-to-end compression scheme called iWave3D, which is trained with a large amount of brain images to directly minimize the rate-distortion loss. Experimental results demonstrate that our method outperforms JP3D significantly by 2.012 dB in terms of average BD-PSNR.
Wireless Transmission of Images With The Assistance of Multi-level Semantic Information
Feb 08, 2022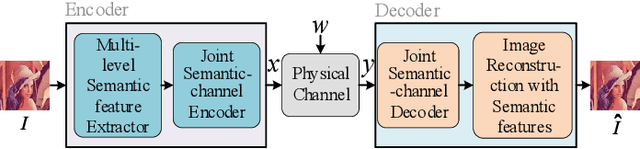
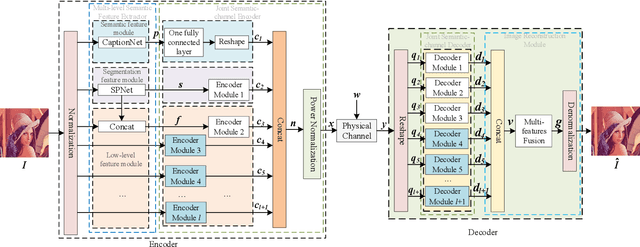
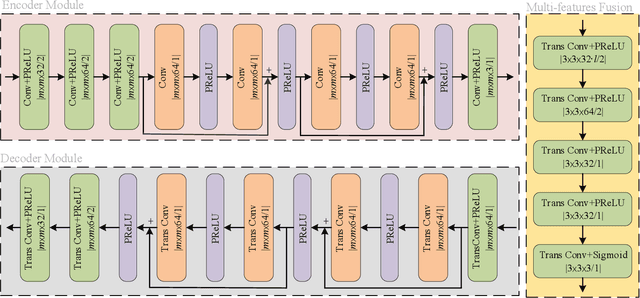
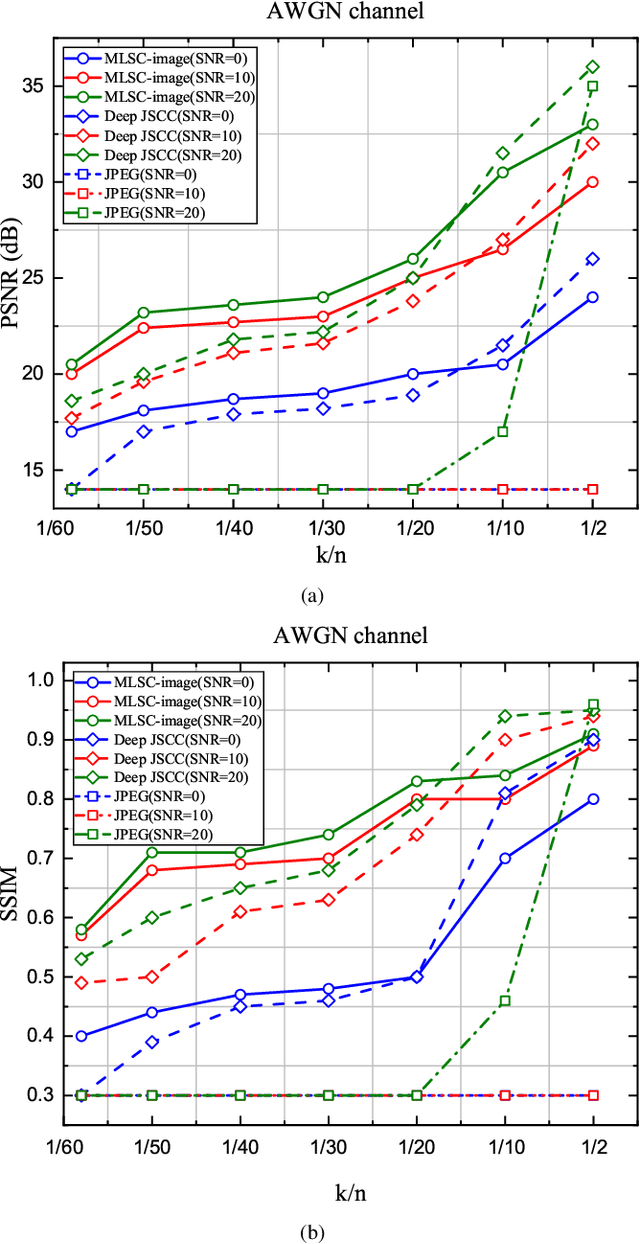
Semantic-oriented communication has been considered as a promising to boost the bandwidth efficiency by only transmitting the semantics of the data. In this paper, we propose a multi-level semantic aware communication system for wireless image transmission, named MLSC-image, which is based on the deep learning techniques and trained in an end to end manner. In particular, the proposed model includes a multilevel semantic feature extractor, that extracts both the highlevel semantic information, such as the text semantics and the segmentation semantics, and the low-level semantic information, such as local spatial details of the images. We employ a pretrained image caption to capture the text semantics and a pretrained image segmentation model to obtain the segmentation semantics. These high-level and low-level semantic features are then combined and encoded by a joint semantic and channel encoder into symbols to transmit over the physical channel. The numerical results validate the effectiveness and efficiency of the proposed semantic communication system, especially under the limited bandwidth condition, which indicates the advantages of the high-level semantics in the compression of images.
Uncertainty in Minimum Cost Multicuts for Image and Motion Segmentation
May 16, 2021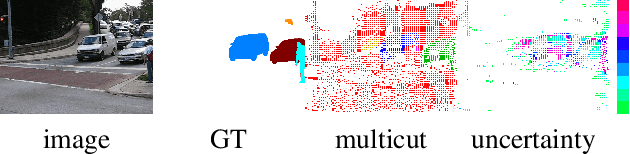

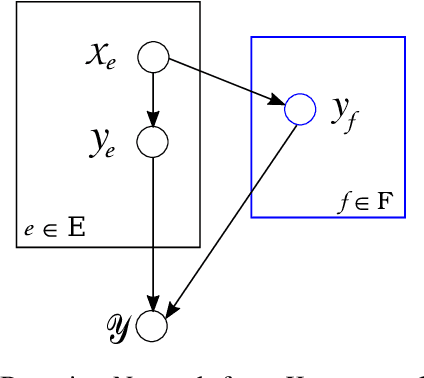

The minimum cost lifted multicut approach has proven practically good performance in a wide range of applications such as image decomposition, mesh segmentation, multiple object tracking, and motion segmentation. It addresses such problems in a graph-based model, where real-valued costs are assigned to the edges between entities such that the minimum cut decomposes the graph into an optimal number of segments. Driven by a probabilistic formulation of minimum cost multicuts, we provide a measure for the uncertainties of the decisions made during the optimization. We argue that access to such uncertainties is crucial for many practical applications and conduct an evaluation by means of sparsifications on three different, widely used datasets in the context of image decomposition (BSDS-500) and motion segmentation (DAVIS2016 and FBMS59) in terms of variation of information (VI) and Rand index (RI).
A Paired Phase and Magnitude Reconstruction for Advanced Diffusion-Weighted Imaging
Mar 28, 2022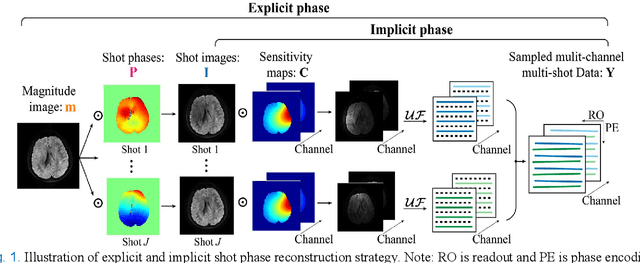
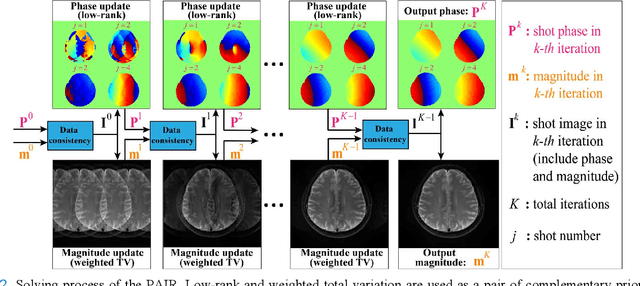
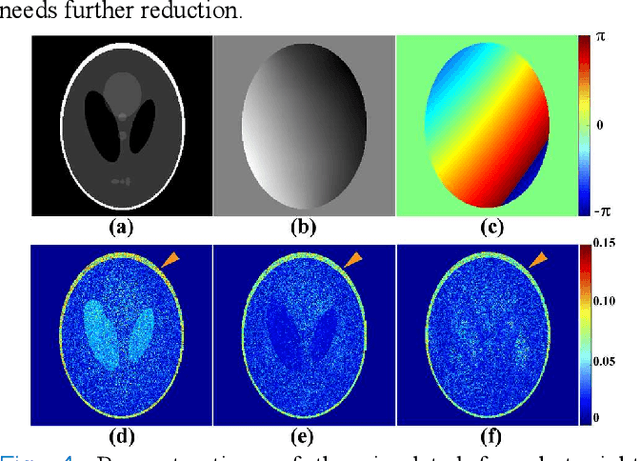
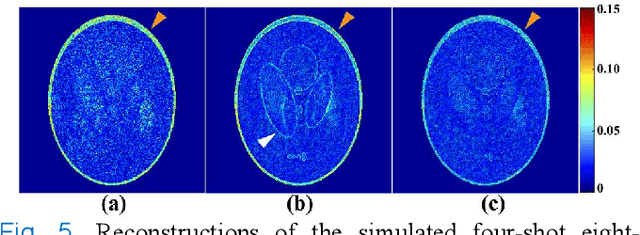
Multi-shot interleaved echo planer imaging can obtain diffusion-weighted images (DWI) with high spatial resolution and low distortion, but suffers from ghost artifacts introduced by phase variations between shots. In this work, we aim at solving the challenging reconstructions under severe motions between shots and low signal-to-noise ratio. An explicit phase model with paired phase and magnitude priors is proposed to regularize the reconstruction (PAIR). The former prior is derived from the smoothness of the shot phase and enforced with low-rankness in the k-space domain. The latter explores similar edges among multi-b-value and multi-direction DWI with weighted total variation in the image domain. Extensive simulation and in vivo results show that PAIR can remove ghost image artifacts very well under the high number of shots (8 shots) and significantly suppress the noise under the ultra-high b-value (4000 s/mm2). The explicit phase model PAIR with complementary priors has a good performance on challenging reconstructions under severe motions between shots and low signal-to-noise ratio. PAIR has great potential in the advanced clinical DWI applications and brain function research.
SALISA: Saliency-based Input Sampling for Efficient Video Object Detection
Apr 05, 2022
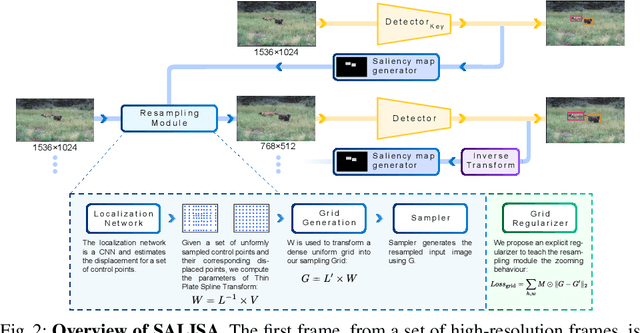
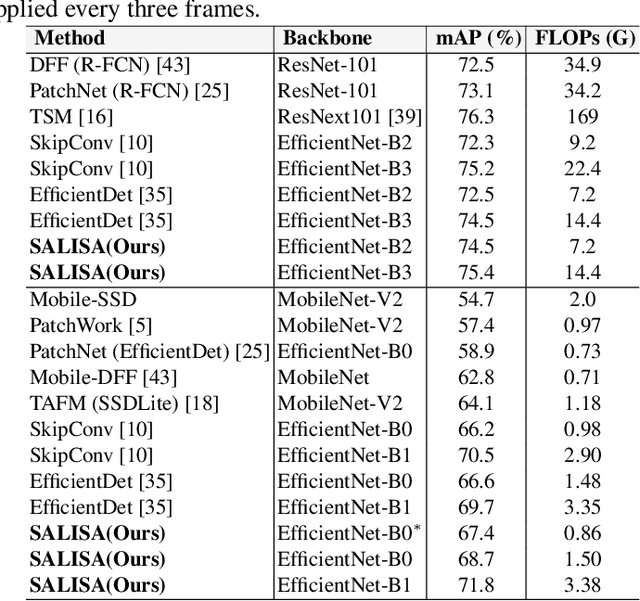

High-resolution images are widely adopted for high-performance object detection in videos. However, processing high-resolution inputs comes with high computation costs, and naive down-sampling of the input to reduce the computation costs quickly degrades the detection performance. In this paper, we propose SALISA, a novel non-uniform SALiency-based Input SAmpling technique for video object detection that allows for heavy down-sampling of unimportant background regions while preserving the fine-grained details of a high-resolution image. The resulting image is spatially smaller, leading to reduced computational costs while enabling a performance comparable to a high-resolution input. To achieve this, we propose a differentiable resampling module based on a thin plate spline spatial transformer network (TPS-STN). This module is regularized by a novel loss to provide an explicit supervision signal to learn to "magnify" salient regions. We report state-of-the-art results in the low compute regime on the ImageNet-VID and UA-DETRAC video object detection datasets. We demonstrate that on both datasets, the mAP of an EfficientDet-D1 (EfficientDet-D2) gets on par with EfficientDet-D2 (EfficientDet-D3) at a much lower computational cost. We also show that SALISA significantly improves the detection of small objects. In particular, SALISA with an EfficientDet-D1 detector improves the detection of small objects by $77\%$, and remarkably also outperforms EfficientDetD3 baseline.
Autonomous crater detection on asteroids using a fully-convolutional neural network
Apr 01, 2022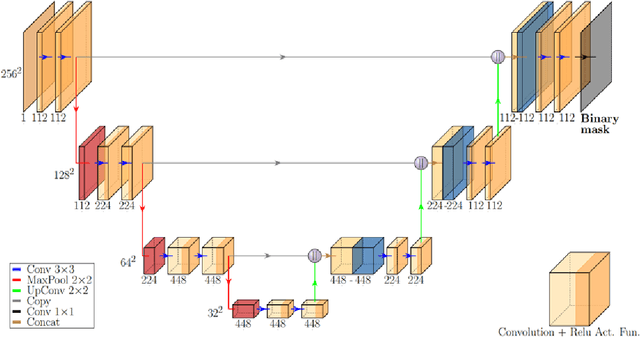



This paper shows the application of autonomous Crater Detection using the U-Net, a Fully-Convolutional Neural Network, on Ceres. The U-Net is trained on optical images of the Moon Global Morphology Mosaic based on data collected by the LRO and manual crater catalogues. The Moon-trained network will be tested on Dawn optical images of Ceres: this task is accomplished by means of a Transfer Learning (TL) approach. The trained model has been fine-tuned using 100, 500 and 1000 additional images of Ceres. The test performance was measured on 350 never before seen images, reaching a testing accuracy of 96.24%, 96.95% and 97.19%, respectively. This means that despite the intrinsic differences between the Moon and Ceres, TL works with encouraging results. The output of the U-Net contains predicted craters: it will be post-processed applying global thresholding for image binarization and a template matching algorithm to extract craters positions and radii in the pixel space. Post-processed craters will be counted and compared to the ground truth data in order to compute image segmentation metrics: precision, recall and F1 score. These indices will be computed, and their effect will be discussed for tasks such as automated crater cataloguing and optical navigation.
Hierarchical Spherical CNNs with Lifting-based Adaptive Wavelets for Pooling and Unpooling
May 31, 2022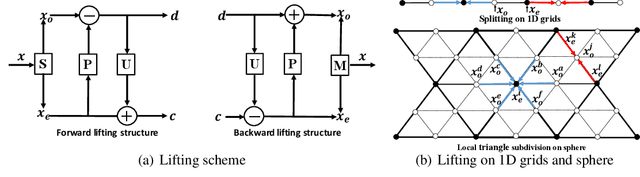
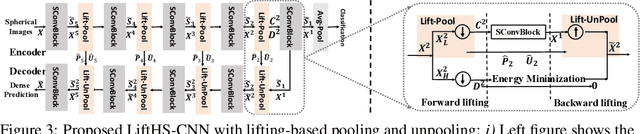


Pooling and unpooling are two essential operations in constructing hierarchical spherical convolutional neural networks (HS-CNNs) for comprehensive feature learning in the spherical domain. Most existing models employ downsampling-based pooling, which will inevitably incur information loss and cannot adapt to different spherical signals and tasks. Besides, the preserved information after pooling cannot be well restored by the subsequent unpooling to characterize the desirable features for a task. In this paper, we propose a novel framework of HS-CNNs with a lifting structure to learn adaptive spherical wavelets for pooling and unpooling, dubbed LiftHS-CNN, which ensures a more efficient hierarchical feature learning for both image- and pixel-level tasks. Specifically, adaptive spherical wavelets are learned with a lifting structure that consists of trainable lifting operators (i.e., update and predict operators). With this learnable lifting structure, we can adaptively partition a signal into two sub-bands containing low- and high-frequency components, respectively, and thus generate a better down-scaled representation for pooling by preserving more information in the low-frequency sub-band. The update and predict operators are parameterized with graph-based attention to jointly consider the signal's characteristics and the underlying geometries. We further show that particular properties are promised by the learned wavelets, ensuring the spatial-frequency localization for better exploiting the signal's correlation in both spatial and frequency domains. We then propose an unpooling operation that is invertible to the lifting-based pooling, where an inverse wavelet transform is performed by using the learned lifting operators to restore an up-scaled representation. Extensive empirical evaluations on various spherical domain tasks validate the superiority of the proposed LiftHS-CNN.
Parametric Scaling of Preprocessing assisted U-net Architecture for Improvised Retinal Vessel Segmentation
Mar 18, 2022



Extracting blood vessels from retinal fundus images plays a decisive role in diagnosing the progression in pertinent diseases. In medical image analysis, vessel extraction is a semantic binary segmentation problem, where blood vasculature needs to be extracted from the background. Here, we present an image enhancement technique based on the morphological preprocessing coupled with a scaled U-net architecture. Despite a relatively less number of trainable network parameters, the scaled version of U-net architecture provides better performance compare to other methods in the domain. We validated the proposed method on retinal fundus images from the DRIVE database. A significant improvement as compared to the other algorithms in the domain, in terms of the area under ROC curve (>0.9762) and classification accuracy (>95.47%) are evident from the results. Furthermore, the proposed method is resistant to the central vessel reflex while sensitive to detect blood vessels in the presence of background items viz. exudates, optic disc, and fovea.