 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Banana Sub-Family Classification and Quality Prediction using Computer Vision
Apr 06, 2022
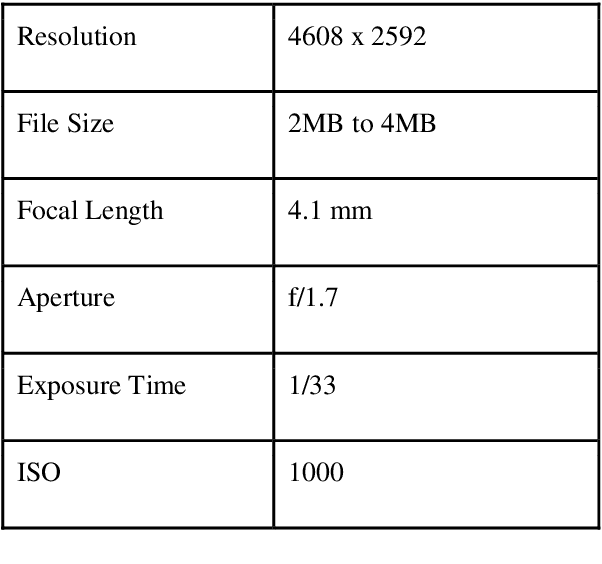
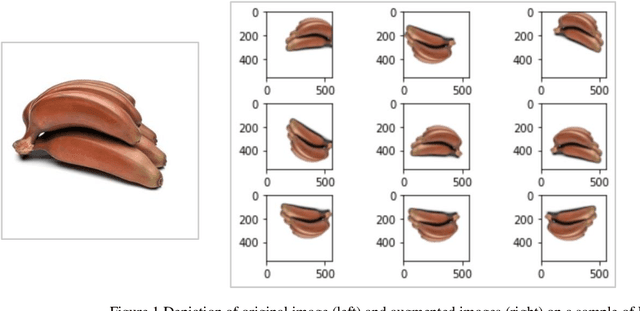

India is the second largest producer of fruits and vegetables in the world, and one of the largest consumers of fruits like Banana, Papaya and Mangoes through retail and ecommerce giants like BigBasket, Grofers and Amazon Fresh. However, adoption of technology in supply chain and retail stores is still low and there is a great potential to adopt computer-vision based technology for identification and classification of fruits. We have chosen banana fruit to build a computer vision based model to carry out the following three use-cases (a) Identify Banana from a given image (b) Determine sub-family or variety of Banana (c) Determine the quality of Banana. Successful execution of these use-cases using computer-vision model would greatly help with overall inventory management automation, quality control, quick and efficient weighing and billing which all are manual labor intensive currently. In this work, we suggest a machine learning pipeline that combines the ideas of CNNs, transfer learning, and data augmentation towards improving Banana fruit sub family and quality image classification. We have built a basic CNN and then went on to tune a MobileNet Banana classification model using a combination of self-curated and publicly-available dataset of 3064 images. The results show an overall 93.4% and 100% accuracy for sub-family/variety and for quality test classifications respectively.
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
Mar 27, 2021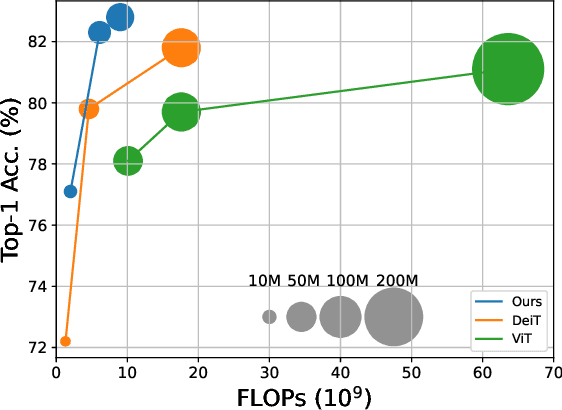
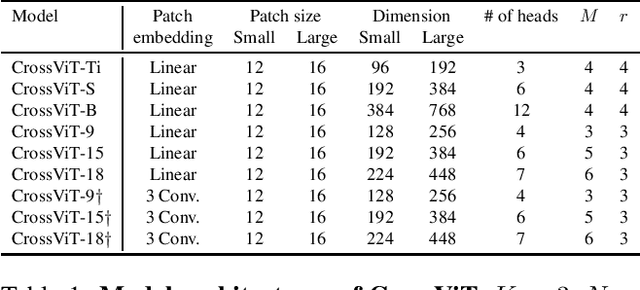
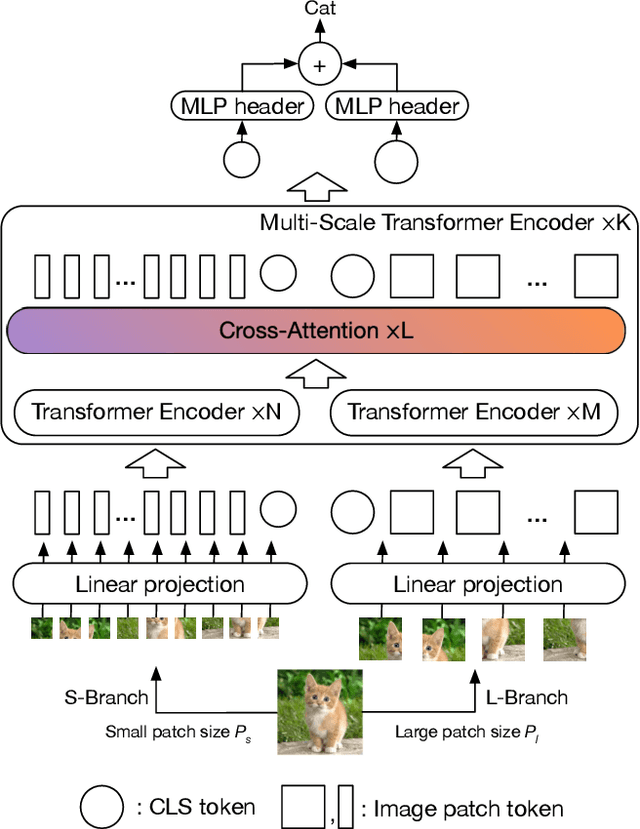
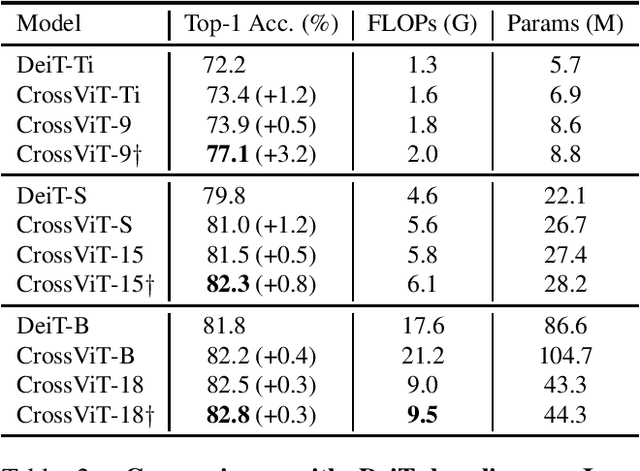
The recently developed vision transformer (ViT) has achieved promising results on image classification compared to convolutional neural networks. Inspired by this, in this paper, we study how to learn multi-scale feature representations in transformer models for image classification. To this end, we propose a dual-branch transformer to combine image patches (i.e., tokens in a transformer) of different sizes to produce stronger image features. Our approach processes small-patch and large-patch tokens with two separate branches of different computational complexity and these tokens are then fused purely by attention multiple times to complement each other. Furthermore, to reduce computation, we develop a simple yet effective token fusion module based on cross attention, which uses a single token for each branch as a query to exchange information with other branches. Our proposed cross-attention only requires linear time for both computational and memory complexity instead of quadratic time otherwise. Extensive experiments demonstrate that the proposed approach performs better than or on par with several concurrent works on vision transformer, in addition to efficient CNN models. For example, on the ImageNet1K dataset, with some architectural changes, our approach outperforms the recent DeiT by a large margin of 2\%
DR.VIC: Decomposition and Reasoning for Video Individual Counting
Mar 28, 2022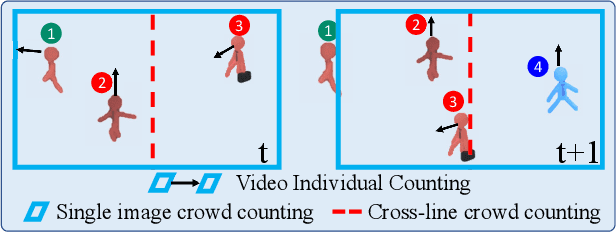
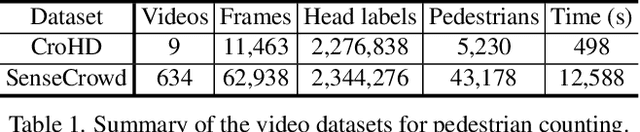
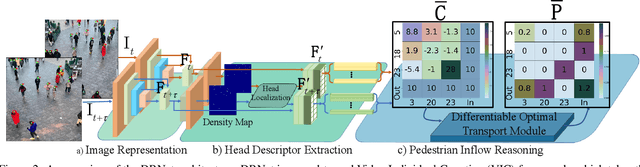
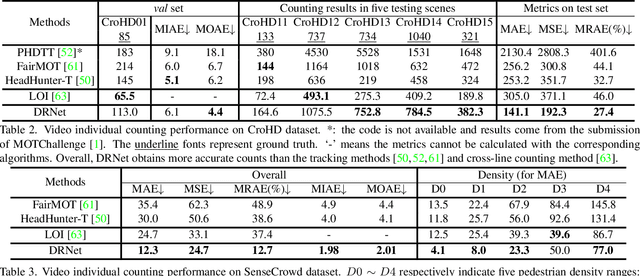
Pedestrian counting is a fundamental tool for understanding pedestrian patterns and crowd flow analysis. Existing works (e.g., image-level pedestrian counting, crossline crowd counting et al.) either only focus on the image-level counting or are constrained to the manual annotation of lines. In this work, we propose to conduct the pedestrian counting from a new perspective - Video Individual Counting (VIC), which counts the total number of individual pedestrians in the given video (a person is only counted once). Instead of relying on the Multiple Object Tracking (MOT) techniques, we propose to solve the problem by decomposing all pedestrians into the initial pedestrians who existed in the first frame and the new pedestrians with separate identities in each following frame. Then, an end-to-end Decomposition and Reasoning Network (DRNet) is designed to predict the initial pedestrian count with the density estimation method and reason the new pedestrian's count of each frame with the differentiable optimal transport. Extensive experiments are conducted on two datasets with congested pedestrians and diverse scenes, demonstrating the effectiveness of our method over baselines with great superiority in counting the individual pedestrians. Code: https://github.com/taohan10200/DRNet.
PhD Thesis. Computer-Aided Assessment of Tuberculosis with Radiological Imaging: From rule-based methods to Deep Learning
May 31, 2022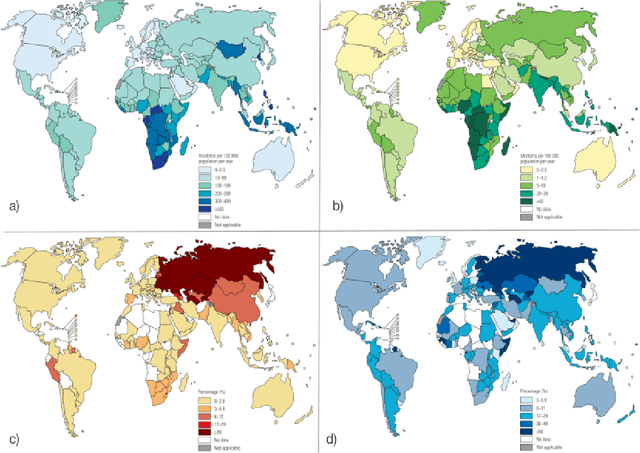
Tuberculosis (TB) is an infectious disease caused by Mycobacterium tuberculosis (Mtb.) that produces pulmonary damage due to its airborne nature. This fact facilitates the disease fast-spreading, which, according to the World Health Organization (WHO), in 2021 caused 1.2 million deaths and 9.9 million new cases. Fortunately, X-Ray Computed Tomography (CT) images enable capturing specific manifestations of TB that are undetectable using regular diagnostic tests. However, this procedure is unfeasible to process the thousands of volume images belonging to the different TB animal models and humans required for a suitable (pre-)clinical trial. To achieve suitable results, automatization of different image analysis processes is a must to quantify TB. Thus, in this thesis, we introduce a set of novel methods based on the state of the art Artificial Intelligence (AI) and Computer Vision (CV). Initially, we present an algorithm to assess Pathological Lung Segmentation (PLS). Next, a Gaussian Mixture Model ruled by an Expectation-Maximization (EM) algorithm is employed to automatically. Chapter 3 introduces a model to automate the identification of TB lesions and the characterization of disease progression. Chapter 4 extends the classification of TB lesions. Namely, we introduce a computational model to infer TB manifestations present in each lung lobe of CT scans by employing the associated radiologist reports as ground truth. In Chapter 5, we present a DL model capable of extracting disentangled information from images of different animal models, as well as information of the mechanisms that generate the CT volumes. To sum up, the thesis presents a collection of valuable tools to automate the quantification of pathological lungs. Chapter 6 elaborates on these conclusions.
Time-multiplexed Neural Holography: A flexible framework for holographic near-eye displays with fast heavily-quantized spatial light modulators
May 05, 2022

Holographic near-eye displays offer unprecedented capabilities for virtual and augmented reality systems, including perceptually important focus cues. Although artificial intelligence--driven algorithms for computer-generated holography (CGH) have recently made much progress in improving the image quality and synthesis efficiency of holograms, these algorithms are not directly applicable to emerging phase-only spatial light modulators (SLM) that are extremely fast but offer phase control with very limited precision. The speed of these SLMs offers time multiplexing capabilities, essentially enabling partially-coherent holographic display modes. Here we report advances in camera-calibrated wave propagation models for these types of holographic near-eye displays and we develop a CGH framework that robustly optimizes the heavily quantized phase patterns of fast SLMs. Our framework is flexible in supporting runtime supervision with different types of content, including 2D and 2.5D RGBD images, 3D focal stacks, and 4D light fields. Using our framework, we demonstrate state-of-the-art results for all of these scenarios in simulation and experiment.
Improving Style-Content Disentanglement in Image-to-Image Translation
Jul 09, 2020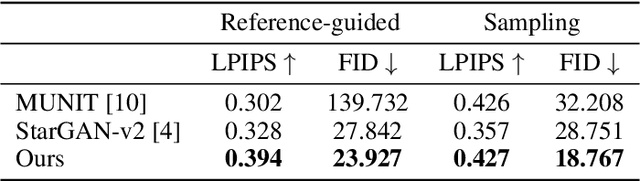


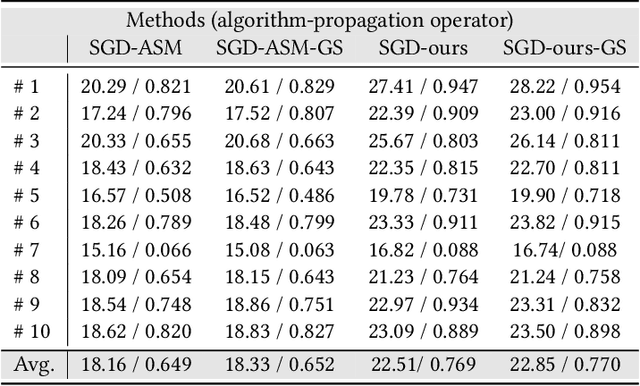
Unsupervised image-to-image translation methods have achieved tremendous success in recent years. However, it can be easily observed that their models contain significant entanglement which often hurts the translation performance. In this work, we propose a principled approach for improving style-content disentanglement in image-to-image translation. By considering the information flow into each of the representations, we introduce an additional loss term which serves as a content-bottleneck. We show that the results of our method are significantly more disentangled than those produced by current methods, while further improving the visual quality and translation diversity.
Zero-Pair Image to Image Translation using Domain Conditional Normalization
Nov 11, 2020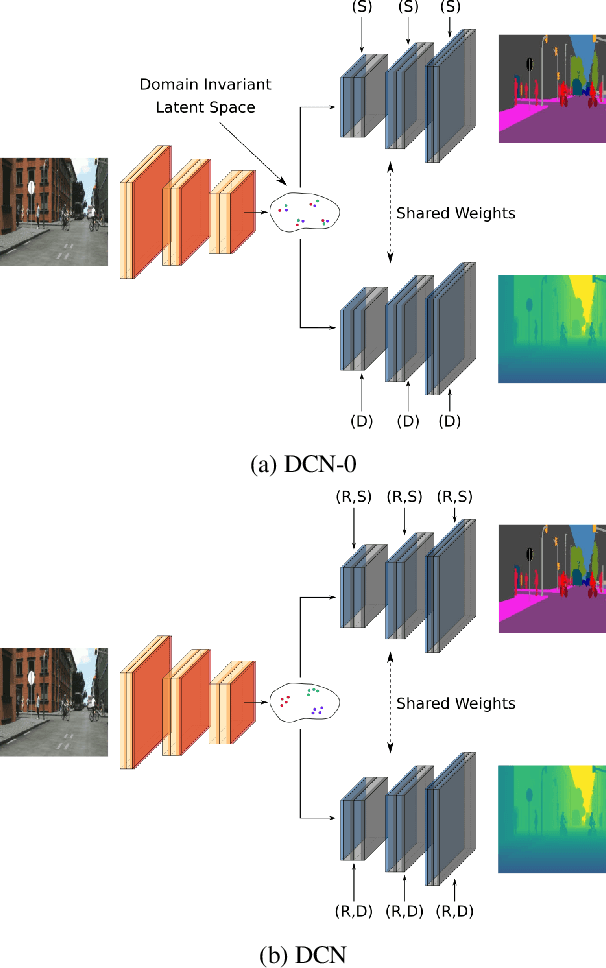
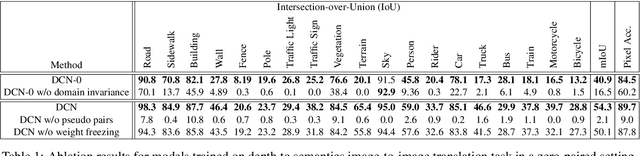
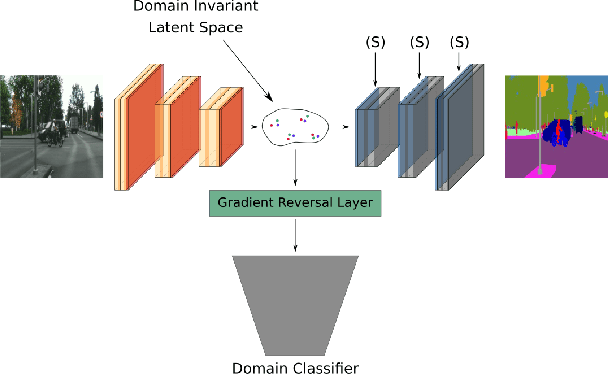

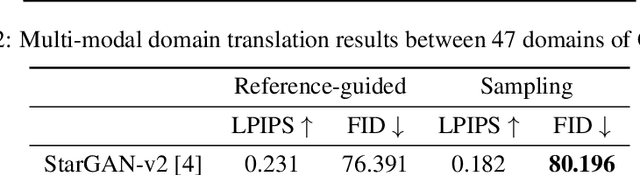
In this paper, we propose an approach based on domain conditional normalization (DCN) for zero-pair image-to-image translation, i.e., translating between two domains which have no paired training data available but each have paired training data with a third domain. We employ a single generator which has an encoder-decoder structure and analyze different implementations of domain conditional normalization to obtain the desired target domain output. The validation benchmark uses RGB-depth pairs and RGB-semantic pairs for training and compares performance for the depth-semantic translation task. The proposed approaches improve in qualitative and quantitative terms over the compared methods, while using much fewer parameters. Code available at https://github.com/samarthshukla/dcn
Visual Information Guided Zero-Shot Paraphrase Generation
Jan 22, 2022

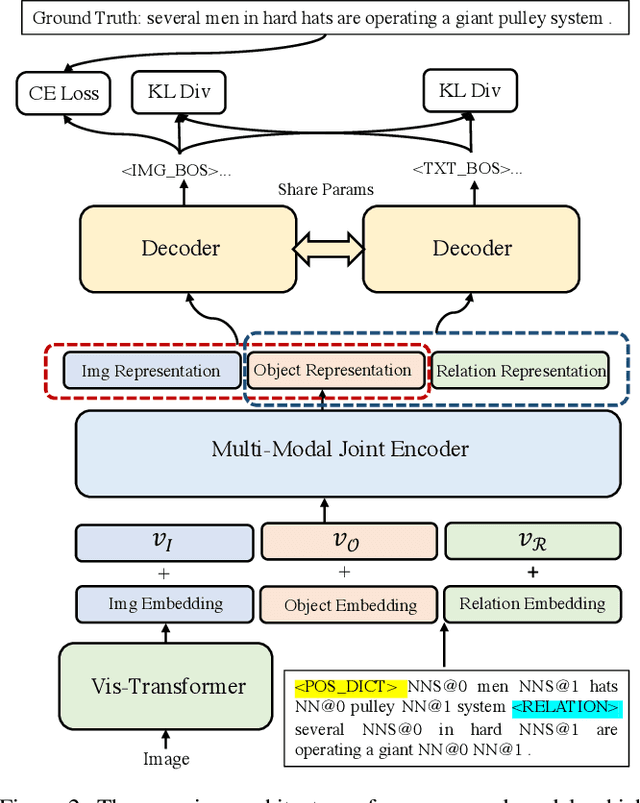
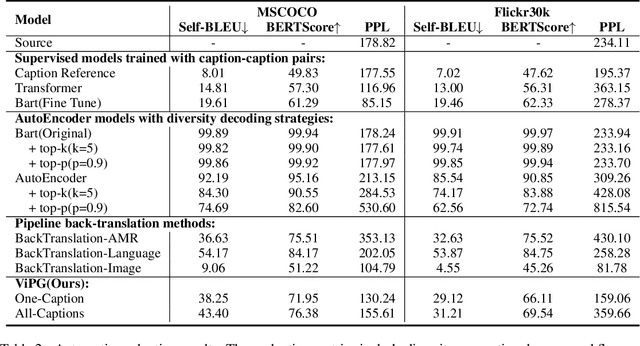
Zero-shot paraphrase generation has drawn much attention as the large-scale high-quality paraphrase corpus is limited. Back-translation, also known as the pivot-based method, is typical to this end. Several works leverage different information as "pivot" such as language, semantic representation and so on. In this paper, we explore using visual information such as image as the "pivot" of back-translation. Different with the pipeline back-translation method, we propose visual information guided zero-shot paraphrase generation (ViPG) based only on paired image-caption data. It jointly trains an image captioning model and a paraphrasing model and leverage the image captioning model to guide the training of the paraphrasing model. Both automatic evaluation and human evaluation show our model can generate paraphrase with good relevancy, fluency and diversity, and image is a promising kind of pivot for zero-shot paraphrase generation.
Data and Physics Driven Learning Models for Fast MRI -- Fundamentals and Methodologies from CNN, GAN to Attention and Transformers
Apr 01, 2022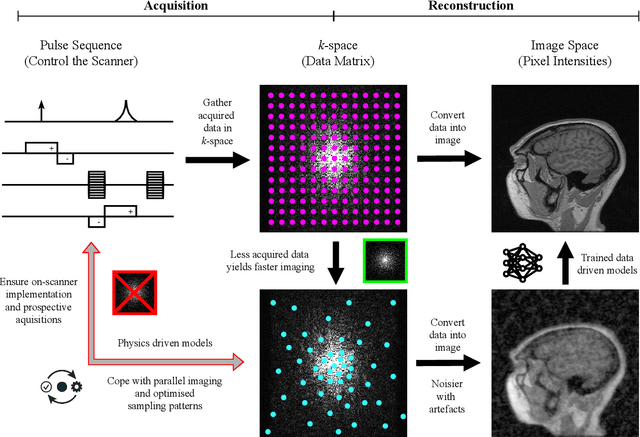
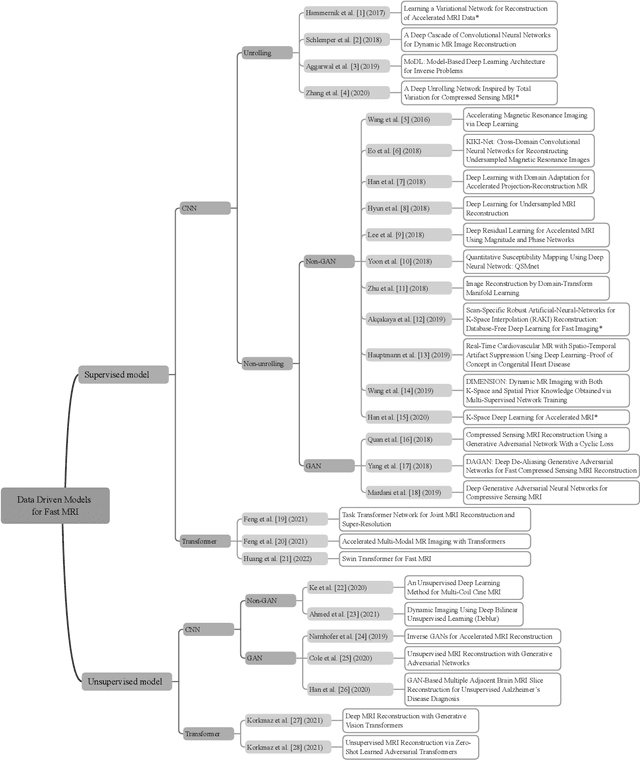
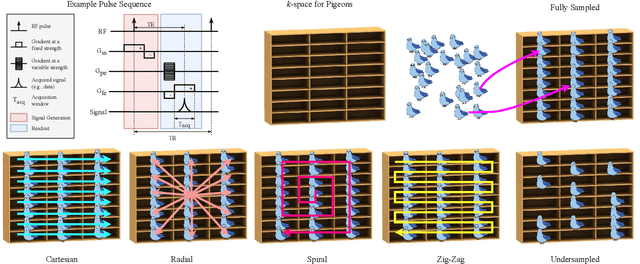
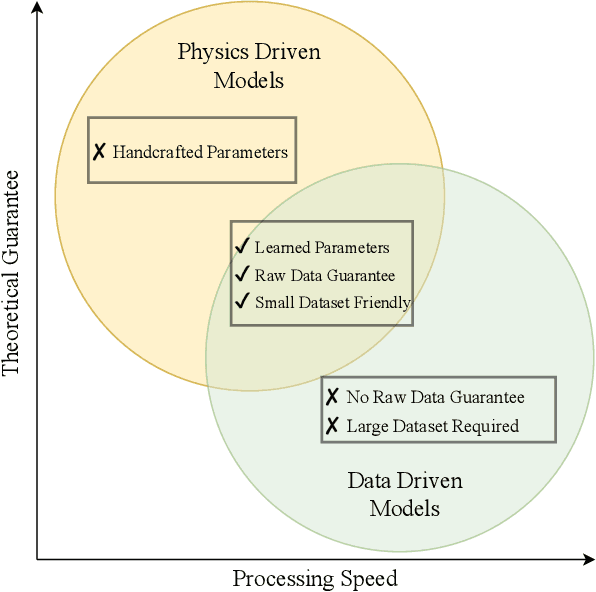
Research studies have shown no qualms about using data driven deep learning models for downstream tasks in medical image analysis, e.g., anatomy segmentation and lesion detection, disease diagnosis and prognosis, and treatment planning. However, deep learning models are not the sovereign remedy for medical image analysis when the upstream imaging is not being conducted properly (with artefacts). This has been manifested in MRI studies, where the scanning is typically slow, prone to motion artefacts, with a relatively low signal to noise ratio, and poor spatial and/or temporal resolution. Recent studies have witnessed substantial growth in the development of deep learning techniques for propelling fast MRI. This article aims to (1) introduce the deep learning based data driven techniques for fast MRI including convolutional neural network and generative adversarial network based methods, (2) survey the attention and transformer based models for speeding up MRI reconstruction, and (3) detail the research in coupling physics and data driven models for MRI acceleration. Finally, we will demonstrate through a few clinical applications, explain the importance of data harmonisation and explainable models for such fast MRI techniques in multicentre and multi-scanner studies, and discuss common pitfalls in current research and recommendations for future research directions.
Coupled Iterative Refinement for 6D Multi-Object Pose Estimation
Apr 26, 2022
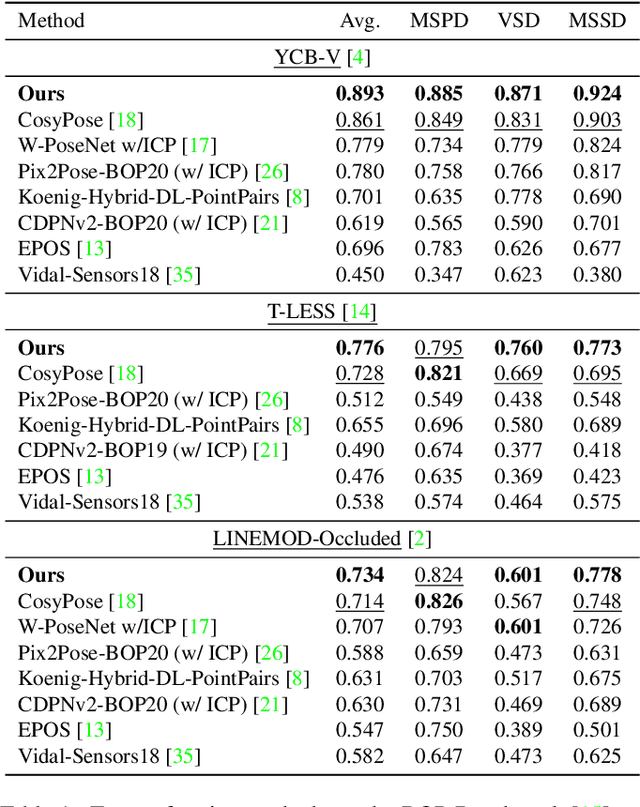
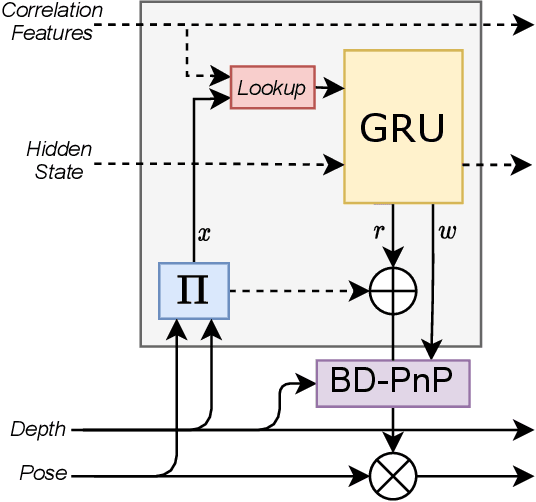
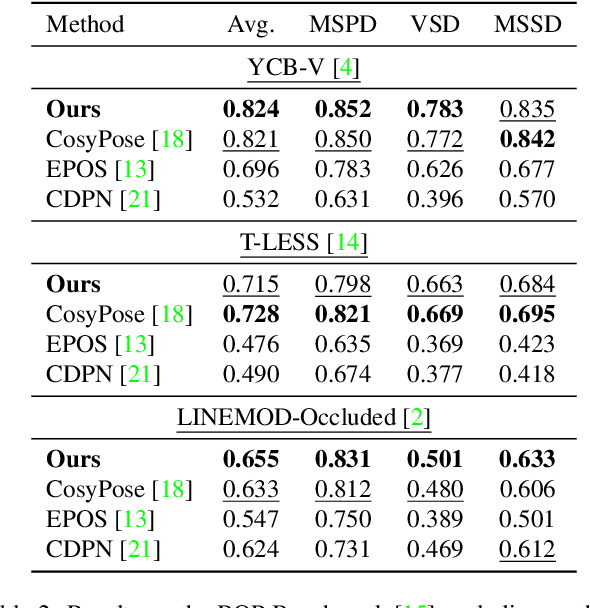
We address the task of 6D multi-object pose: given a set of known 3D objects and an RGB or RGB-D input image, we detect and estimate the 6D pose of each object. We propose a new approach to 6D object pose estimation which consists of an end-to-end differentiable architecture that makes use of geometric knowledge. Our approach iteratively refines both pose and correspondence in a tightly coupled manner, allowing us to dynamically remove outliers to improve accuracy. We use a novel differentiable layer to perform pose refinement by solving an optimization problem we refer to as Bidirectional Depth-Augmented Perspective-N-Point (BD-PnP). Our method achieves state-of-the-art accuracy on standard 6D Object Pose benchmarks. Code is available at https://github.com/princeton-vl/Coupled-Iterative-Refinement.