 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Fast Eye Detector Using Metric Learning for Iris on The Move
Feb 22, 2022
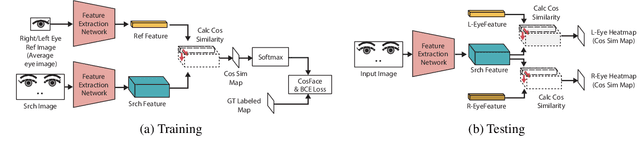


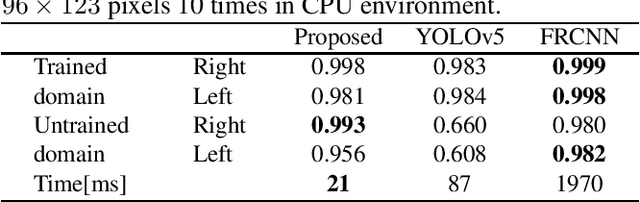
This paper proposes a fast eye detection method based on fully-convolutional Siamese networks for iris recognition. The iris on the move system requires to capture high resolution iris images from a moving subject for iris recognition. Therefore, capturing images contains both eyes at high-frame-rate increases the chance of iris imaging. In order to output the authentication result in real time, the system requires a fast eye detector extracting the left and right eye regions from the image. Our method extracts features of a partial face image and a reference eye image using Siamese network frameworks. Similarity heat maps of both eyes are created by calculating the spatial cosine similarity between extracted features. Besides, we use CosFace as a loss function for training to discriminate the left and right eyes with high accuracy even with a shallow network. Experimental results show that our method trained by CosFace is fast and accurate compared with conventional generic object detection methods.
BiasEnsemble: Revisiting the Importance of Amplifying Bias for Debiasing
May 29, 2022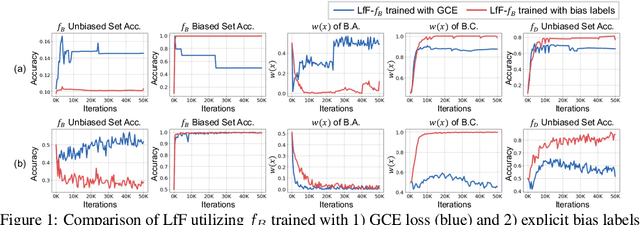
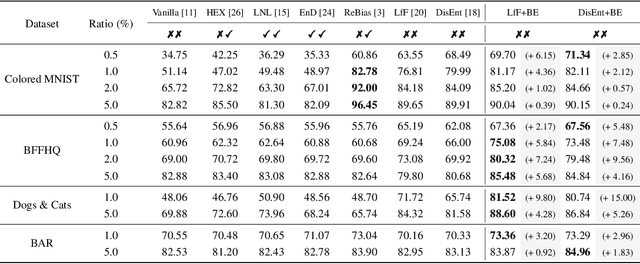
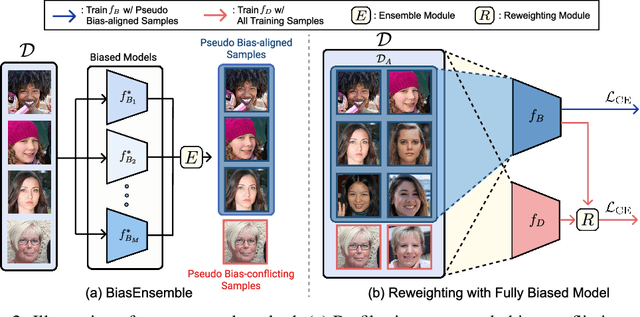

In image classification, "debiasing" aims to train a classifier to be less susceptible to dataset bias, the strong correlation between peripheral attributes of data samples and a target class. For example, even if the frog class in the dataset mainly consists of frog images with a swamp background (i.e., bias-aligned samples), a debiased classifier should be able to correctly classify a frog at a beach (i.e., bias-conflicting samples). Recent debiasing approaches commonly use two components for debiasing, a biased model $f_B$ and a debiased model $f_D$. $f_B$ is trained to focus on bias-aligned samples while $f_D$ is mainly trained with bias-conflicting samples by concentrating on samples which $f_B$ fails to learn, leading $f_D$ to be less susceptible to the dataset bias. While the state-of-the-art debiasing techniques have aimed to better train $f_D$, we focus on training $f_B$, an overlooked component until now. Our empirical analysis reveals that removing the bias-conflicting samples from the training set for $f_B$ is important for improving the debiasing performance of $f_D$. This is due to the fact that the bias-conflicting samples work as noisy samples for amplifying the bias for $f_B$. To this end, we propose a novel biased sample selection method BiasEnsemble which removes the bias-conflicting samples via leveraging additional biased models to construct a bias-amplified dataset for training $f_B$. Our simple yet effective approach can be directly applied to existing reweighting-based debiasing approaches, obtaining consistent performance boost and achieving the state-of-the-art performance on both synthetic and real-world datasets.
RTIC: Residual Learning for Text and Image Composition using Graph Convolutional Network
Apr 08, 2021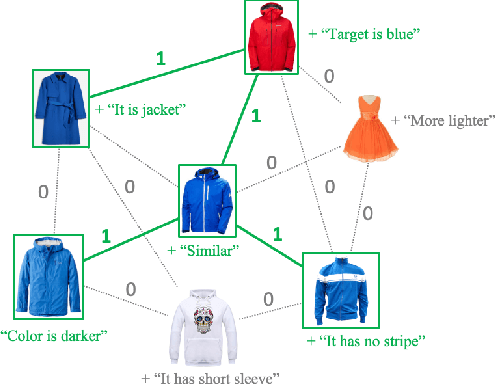
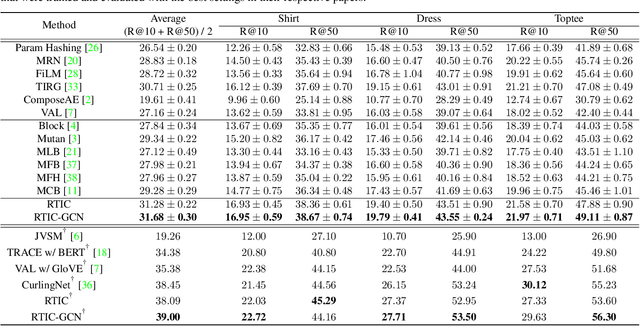
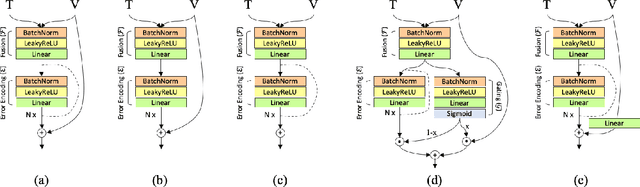
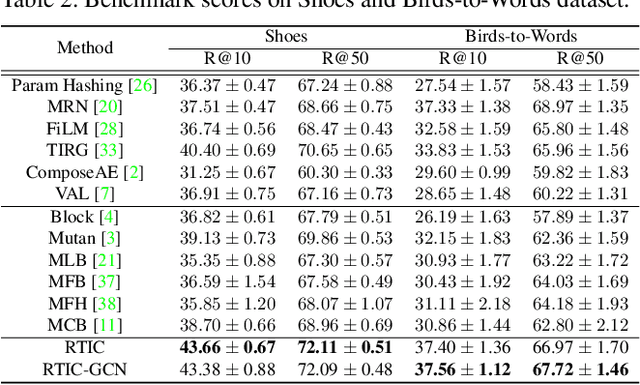
In this paper, we study the compositional learning of images and texts for image retrieval. The query is given in the form of an image and text that describes the desired modifications to the image; the goal is to retrieve the target image that satisfies the given modifications and resembles the query by composing information in both the text and image modalities. To accomplish this task, we propose a simple new architecture using skip connections that can effectively encode the errors between the source and target images in the latent space. Furthermore, we introduce a novel method that combines the graph convolutional network (GCN) with existing composition methods. We find that the combination consistently improves the performance in a plug-and-play manner. We perform thorough and exhaustive experiments on several widely used datasets, and achieve state-of-the-art scores on the task with our model. To ensure fairness in comparison, we suggest a strict standard for the evaluation because a small difference in the training conditions can significantly affect the final performance. We release our implementation, including that of all the compared methods, for reproducibility.
A Data Augmentation Method for Fully Automatic Brain Tumor Segmentation
Feb 13, 2022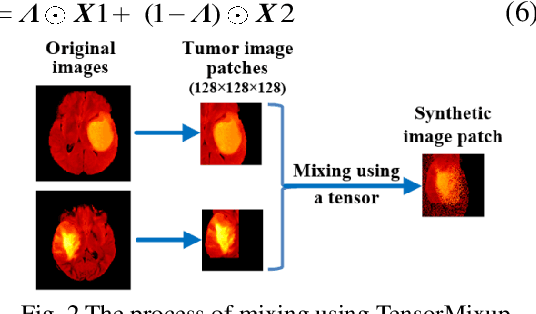

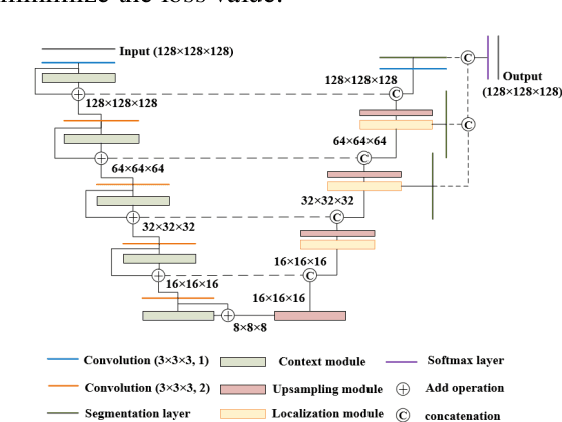
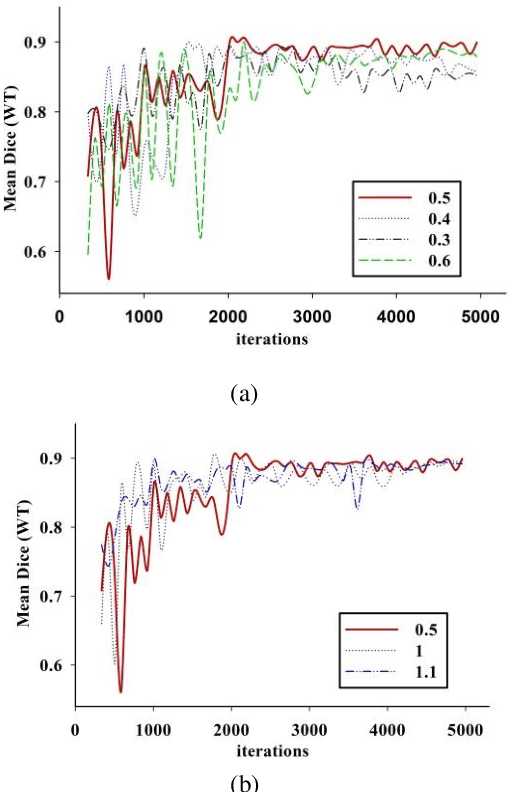
Automatic segmentation of glioma and its subregions is of great significance for diagnosis, treatment and monitoring of disease. In this paper, an augmentation method, called TensorMixup, was proposed and applied to the three dimensional U-Net architecture for brain tumor segmentation. The main ideas included that first, two image patches with size of 128 in three dimensions were selected according to glioma information of ground truth labels from the magnetic resonance imaging data of any two patients with the same modality. Next, a tensor in which all elements were independently sampled from Beta distribution was used to mix the image patches. Then the tensor was mapped to a matrix which was used to mix the one-hot encoded labels of the above image patches. Therefore, a new image and its one-hot encoded label were synthesized. Finally, the new data was used to train the model which could be used to segment glioma. The experimental results show that the mean accuracy of Dice scores are 91.32%, 85.67%, and 82.20% respectively on the whole tumor, tumor core, and enhancing tumor segmentation, which proves that the proposed TensorMixup is feasible and effective for brain tumor segmentation.
TVDIM: Enhancing Image Self-Supervised Pretraining via Noisy Text Data
Jun 13, 2021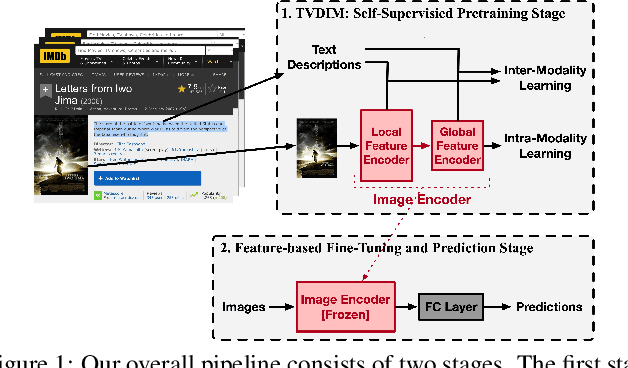
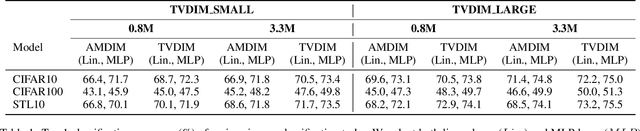
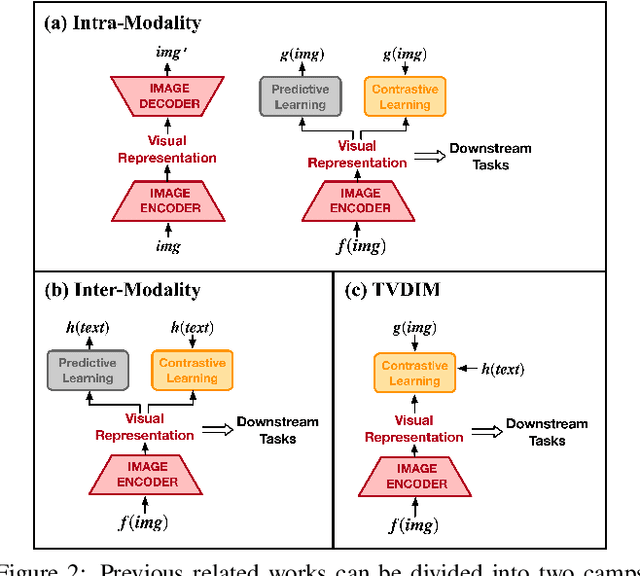
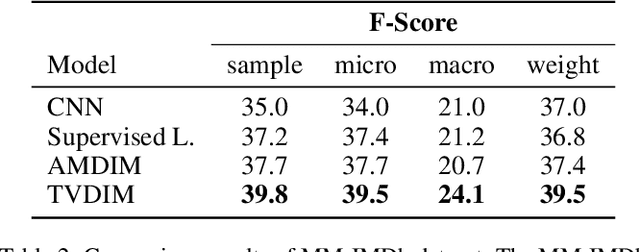
Among ubiquitous multimodal data in the real world, text is the modality generated by human, while image reflects the physical world honestly. In a visual understanding application, machines are expected to understand images like human. Inspired by this, we propose a novel self-supervised learning method, named Text-enhanced Visual Deep InfoMax (TVDIM), to learn better visual representations by fully utilizing the naturally-existing multimodal data. Our core idea of self-supervised learning is to maximize the mutual information between features extracted from multiple views of a shared context to a rational degree. Different from previous methods which only consider multiple views from a single modality, our work produces multiple views from different modalities, and jointly optimizes the mutual information for features pairs of intra-modality and inter-modality. Considering the information gap between inter-modality features pairs from data noise, we adopt a \emph{ranking-based} contrastive learning to optimize the mutual information. During evaluation, we directly use the pre-trained visual representations to complete various image classification tasks. Experimental results show that, TVDIM significantly outperforms previous visual self-supervised methods when processing the same set of images.
Diverse Single Image Generation with Controllable Global Structure though Self-Attention
Feb 09, 2021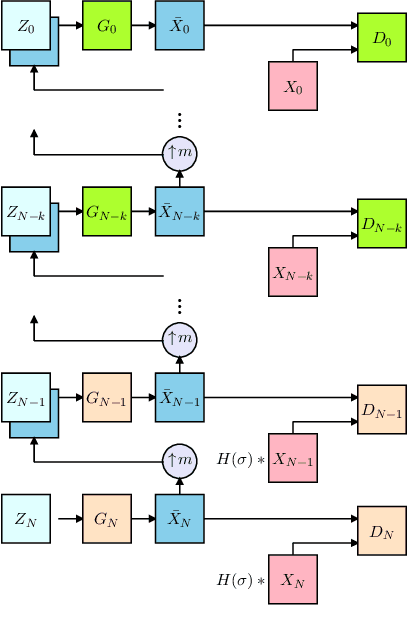

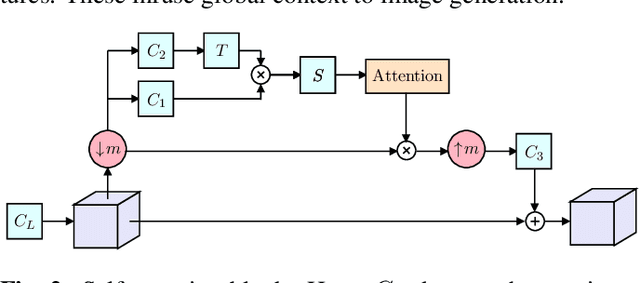
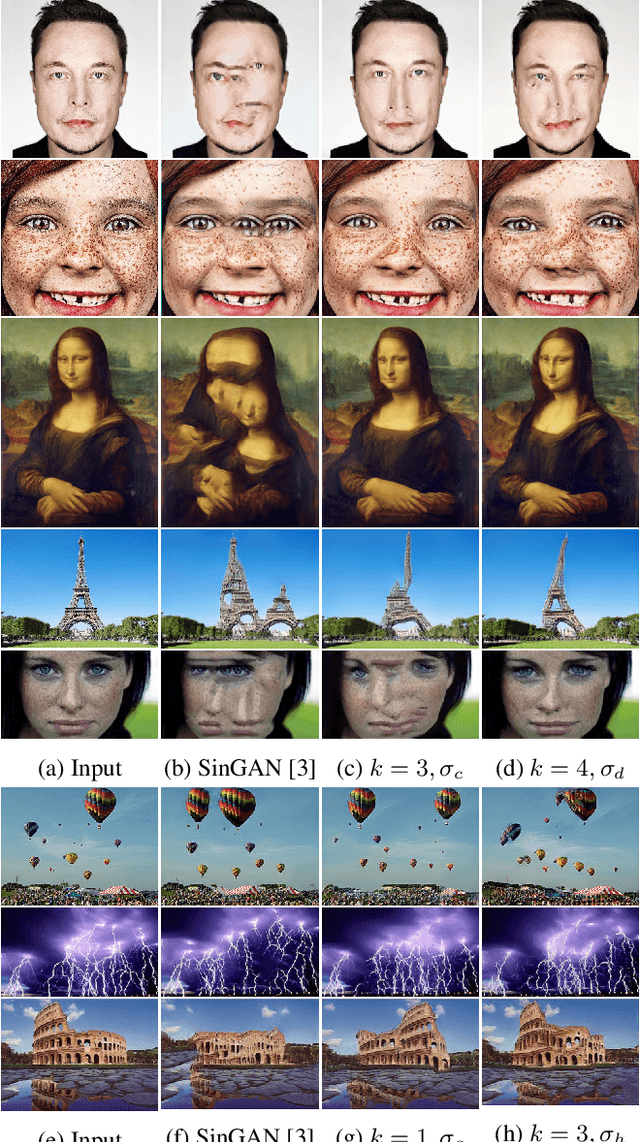
Image generation from a single image using generative adversarial networks is quite interesting due to the realism of generated images. However, recent approaches need improvement for such realistic and diverse image generation, when the global context of the image is important such as in face, animal, and architectural image generation. This is mainly due to the use of fewer convolutional layers for mainly capturing the patch statistics and, thereby, not being able to capture global statistics very well. We solve this problem by using attention blocks at selected scales and feeding a random Gaussian blurred image to the discriminator for training. Our results are visually better than the state-of-the-art particularly in generating images that require global context. The diversity of our image generation, measured using the average standard deviation of pixels, is also better.
Controlling Memorability of Face Images
Feb 24, 2022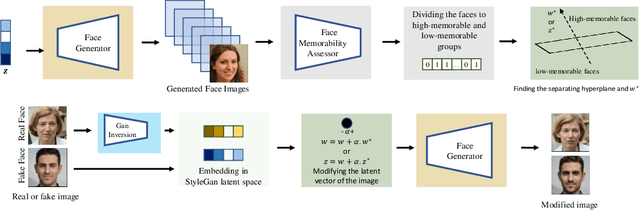


Everyday, we are bombarded with many photographs of faces, whether on social media, television, or smartphones. From an evolutionary perspective, faces are intended to be remembered, mainly due to survival and personal relevance. However, all these faces do not have the equal opportunity to stick in our minds. It has been shown that memorability is an intrinsic feature of an image but yet, it is largely unknown what attributes make an image more memorable. In this work, we aimed to address this question by proposing a fast approach to modify and control the memorability of face images. In our proposed method, we first found a hyperplane in the latent space of StyleGAN to separate high and low memorable images. We then modified the image memorability (while maintaining the identity and other facial features such as age, emotion, etc.) by moving in the positive or negative direction of this hyperplane normal vector. We further analyzed how different layers of the StyleGAN augmented latent space contribute to face memorability. These analyses showed how each individual face attribute makes an image more or less memorable. Most importantly, we evaluated our proposed method for both real and synthesized face images. The proposed method successfully modifies and controls the memorability of real human faces as well as unreal synthesized faces. Our proposed method can be employed in photograph editing applications for social media, learning aids, or advertisement purposes.
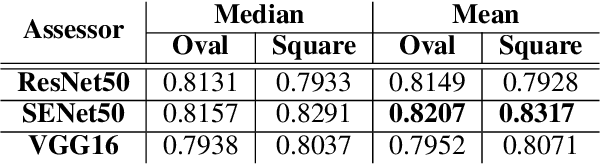
DefakeHop++: An Enhanced Lightweight Deepfake Detector
Apr 30, 2022
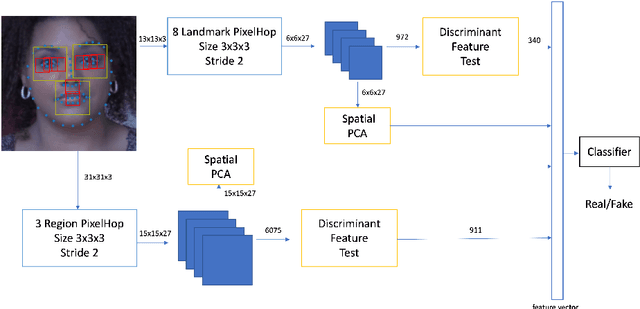
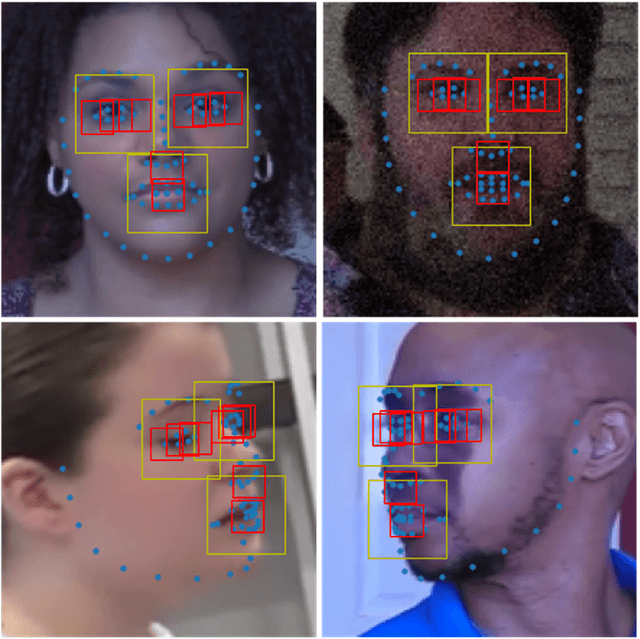
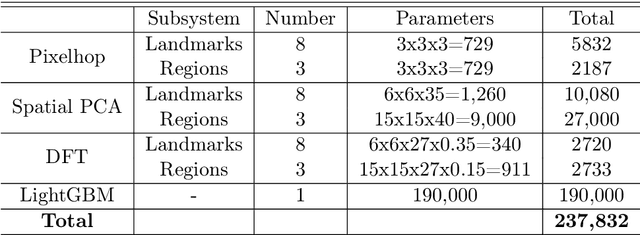
On the basis of DefakeHop, an enhanced lightweight Deepfake detector called DefakeHop++ is proposed in this work. The improvements lie in two areas. First, DefakeHop examines three facial regions (i.e., two eyes and mouth) while DefakeHop++ includes eight more landmarks for broader coverage. Second, for discriminant features selection, DefakeHop uses an unsupervised approach while DefakeHop++ adopts a more effective approach with supervision, called the Discriminant Feature Test (DFT). In DefakeHop++, rich spatial and spectral features are first derived from facial regions and landmarks automatically. Then, DFT is used to select a subset of discriminant features for classifier training. As compared with MobileNet v3 (a lightweight CNN model of 1.5M parameters targeting at mobile applications), DefakeHop++ has a model of 238K parameters, which is 16% of MobileNet v3. Furthermore, DefakeHop++ outperforms MobileNet v3 in Deepfake image detection performance in a weakly-supervised setting.
Visual Representation Learning with Self-Supervised Attention for Low-Label High-data Regime
Jan 22, 2022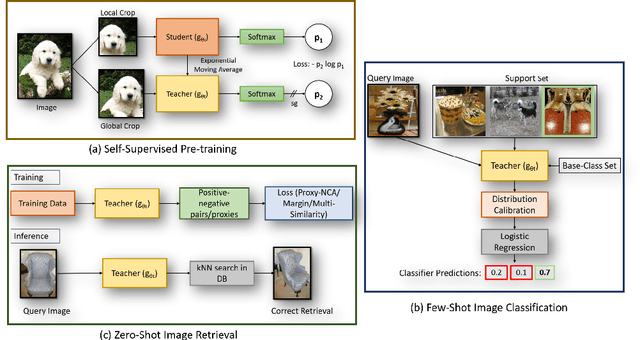
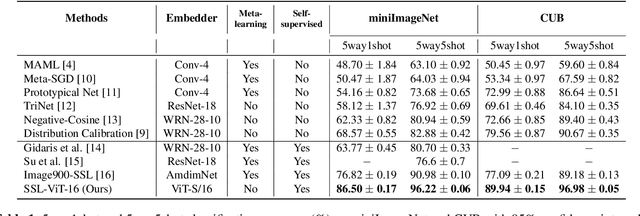
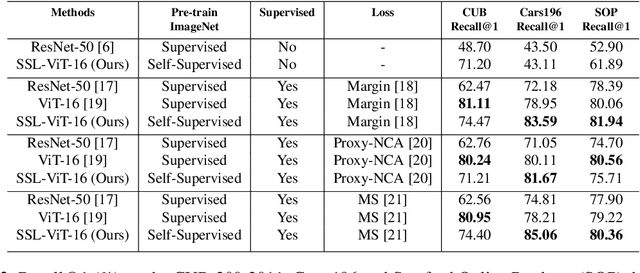

Self-supervision has shown outstanding results for natural language processing, and more recently, for image recognition. Simultaneously, vision transformers and its variants have emerged as a promising and scalable alternative to convolutions on various computer vision tasks. In this paper, we are the first to question if self-supervised vision transformers (SSL-ViTs) can be adapted to two important computer vision tasks in the low-label, high-data regime: few-shot image classification and zero-shot image retrieval. The motivation is to reduce the number of manual annotations required to train a visual embedder, and to produce generalizable, semantically meaningful and robust embeddings. For few-shot image classification we train SSL-ViTs without any supervision, on external data, and use this trained embedder to adapt quickly to novel classes with limited number of labels. For zero-shot image retrieval, we use SSL-ViTs pre-trained on a large dataset without any labels and fine-tune them with several metric learning objectives. Our self-supervised attention representations outperforms the state-of-the-art on several public benchmarks for both tasks, namely miniImageNet and CUB200 for few-shot image classification by up-to 6%-10%, and Stanford Online Products, Cars196 and CUB200 for zero-shot image retrieval by up-to 4%-11%. Code is available at \url{https://github.com/AutoVision-cloud/SSL-ViT-lowlabel-highdata}.
Interactive Multi-Class Tiny-Object Detection
Mar 29, 2022

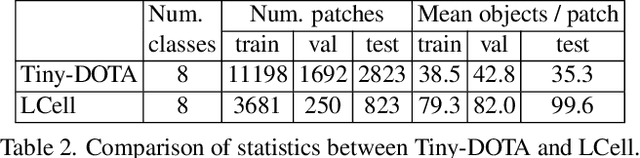
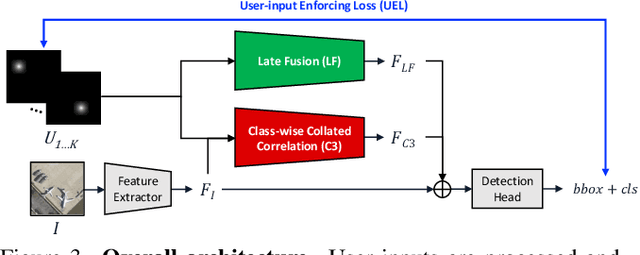
Annotating tens or hundreds of tiny objects in a given image is laborious yet crucial for a multitude of Computer Vision tasks. Such imagery typically contains objects from various categories, yet the multi-class interactive annotation setting for the detection task has thus far been unexplored. To address these needs, we propose a novel interactive annotation method for multiple instances of tiny objects from multiple classes, based on a few point-based user inputs. Our approach, C3Det, relates the full image context with annotator inputs in a local and global manner via late-fusion and feature-correlation, respectively. We perform experiments on the Tiny-DOTA and LCell datasets using both two-stage and one-stage object detection architectures to verify the efficacy of our approach. Our approach outperforms existing approaches in interactive annotation, achieving higher mAP with fewer clicks. Furthermore, we validate the annotation efficiency of our approach in a user study where it is shown to be 2.85x faster and yield only 0.36x task load (NASA-TLX, lower is better) compared to manual annotation. The code is available at https://github.com/ChungYi347/Interactive-Multi-Class-Tiny-Object-Detection.