 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Overhead-MNIST: Machine Learning Baselines for Image Classification
Jul 01, 2021
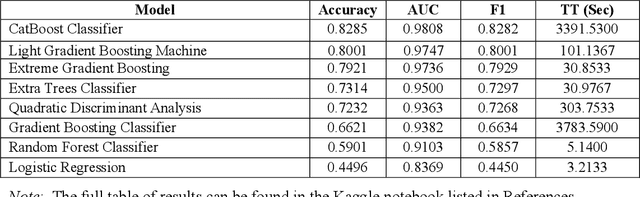

Twenty-three machine learning algorithms were trained then scored to establish baseline comparison metrics and to select an image classification algorithm worthy of embedding into mission-critical satellite imaging systems. The Overhead-MNIST dataset is a collection of satellite images similar in style to the ubiquitous MNIST hand-written digits found in the machine learning literature. The CatBoost classifier, Light Gradient Boosting Machine, and Extreme Gradient Boosting models produced the highest accuracies, Areas Under the Curve (AUC), and F1 scores in a PyCaret general comparison. Separate evaluations showed that a deep convolutional architecture was the most promising. We present results for the overall best performing algorithm as a baseline for edge deployability and future performance improvement: a convolutional neural network (CNN) scoring 0.965 categorical accuracy on unseen test data.
Dependent Multi-Task Learning with Causal Intervention for Image Captioning
May 18, 2021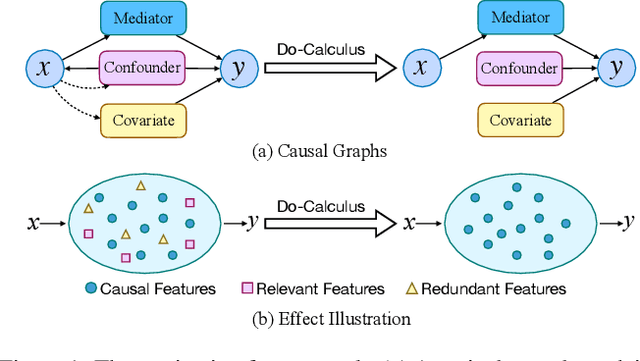
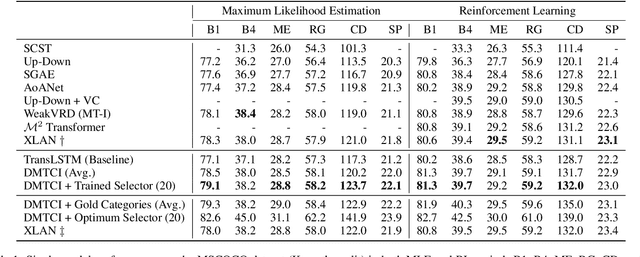
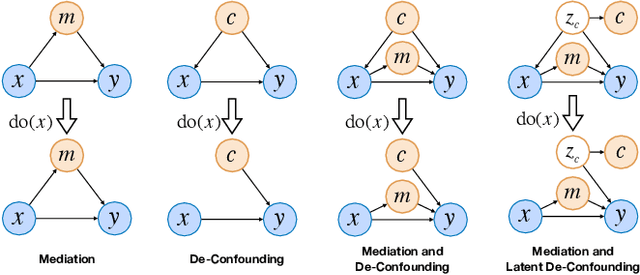
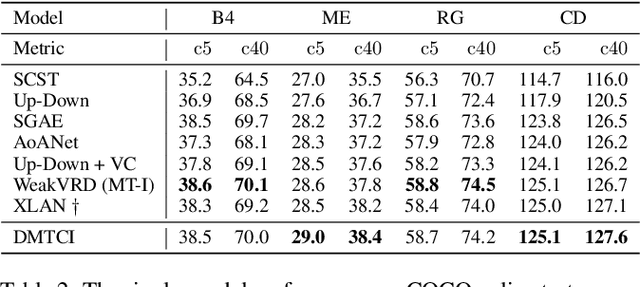
Recent work for image captioning mainly followed an extract-then-generate paradigm, pre-extracting a sequence of object-based features and then formulating image captioning as a single sequence-to-sequence task. Although promising, we observed two problems in generated captions: 1) content inconsistency where models would generate contradicting facts; 2) not informative enough where models would miss parts of important information. From a causal perspective, the reason is that models have captured spurious statistical correlations between visual features and certain expressions (e.g., visual features of "long hair" and "woman"). In this paper, we propose a dependent multi-task learning framework with the causal intervention (DMTCI). Firstly, we involve an intermediate task, bag-of-categories generation, before the final task, image captioning. The intermediate task would help the model better understand the visual features and thus alleviate the content inconsistency problem. Secondly, we apply Pearl's do-calculus on the model, cutting off the link between the visual features and possible confounders and thus letting models focus on the causal visual features. Specifically, the high-frequency concept set is considered as the proxy confounders where the real confounders are inferred in the continuous space. Finally, we use a multi-agent reinforcement learning (MARL) strategy to enable end-to-end training and reduce the inter-task error accumulations. The extensive experiments show that our model outperforms the baseline models and achieves competitive performance with state-of-the-art models.
TRT-ViT: TensorRT-oriented Vision Transformer
May 19, 2022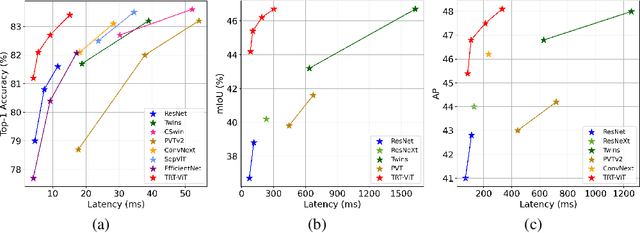
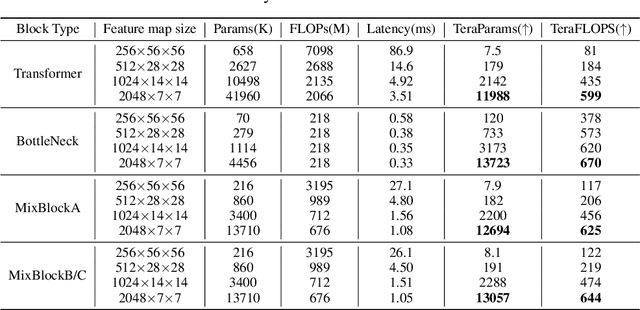
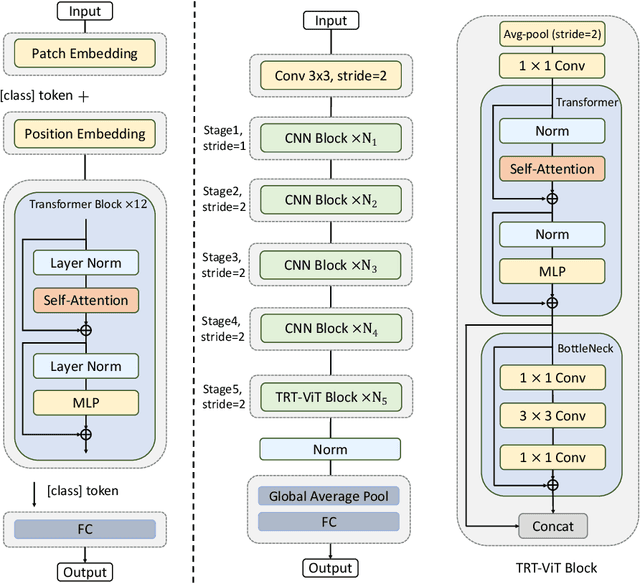
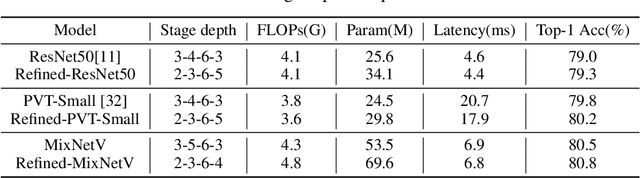
We revisit the existing excellent Transformers from the perspective of practical application. Most of them are not even as efficient as the basic ResNets series and deviate from the realistic deployment scenario. It may be due to the current criterion to measure computation efficiency, such as FLOPs or parameters is one-sided, sub-optimal, and hardware-insensitive. Thus, this paper directly treats the TensorRT latency on the specific hardware as an efficiency metric, which provides more comprehensive feedback involving computational capacity, memory cost, and bandwidth. Based on a series of controlled experiments, this work derives four practical guidelines for TensorRT-oriented and deployment-friendly network design, e.g., early CNN and late Transformer at stage-level, early Transformer and late CNN at block-level. Accordingly, a family of TensortRT-oriented Transformers is presented, abbreviated as TRT-ViT. Extensive experiments demonstrate that TRT-ViT significantly outperforms existing ConvNets and vision Transformers with respect to the latency/accuracy trade-off across diverse visual tasks, e.g., image classification, object detection and semantic segmentation. For example, at 82.7% ImageNet-1k top-1 accuracy, TRT-ViT is 2.7$\times$ faster than CSWin and 2.0$\times$ faster than Twins. On the MS-COCO object detection task, TRT-ViT achieves comparable performance with Twins, while the inference speed is increased by 2.8$\times$.
Rectifying the Shortcut Learning of Background: Shared Object Concentration for Few-Shot Image Recognition
Jul 16, 2021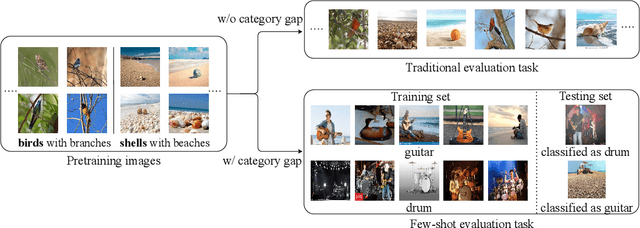
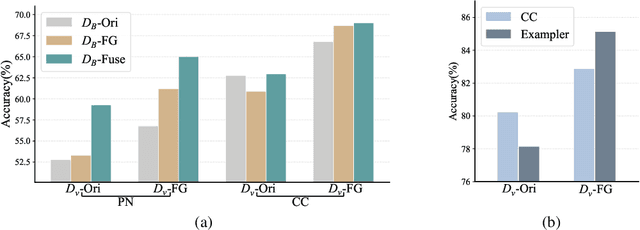
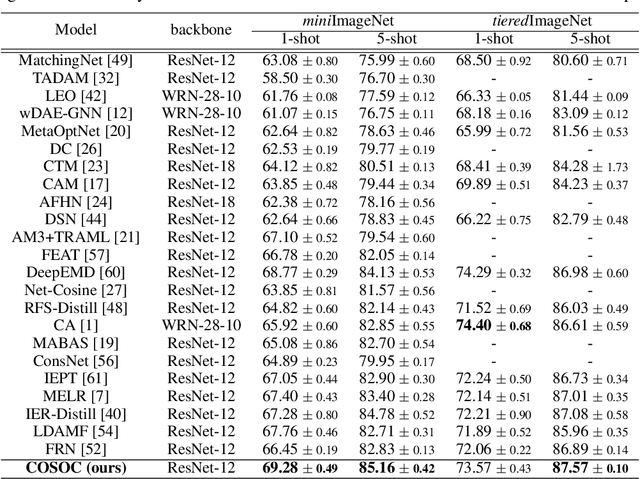
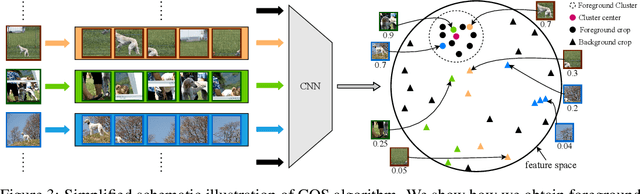
Few-Shot image classification aims to utilize pretrained knowledge learned from a large-scale dataset to tackle a series of downstream classification tasks. Typically, each task involves only few training examples from brand-new categories. This requires the pretraining models to focus on well-generalizable knowledge, but ignore domain-specific information. In this paper, we observe that image background serves as a source of domain-specific knowledge, which is a shortcut for models to learn in the source dataset, but is harmful when adapting to brand-new classes. To prevent the model from learning this shortcut knowledge, we propose COSOC, a novel Few-Shot Learning framework, to automatically figure out foreground objects at both pretraining and evaluation stage. COSOC is a two-stage algorithm motivated by the observation that foreground objects from different images within the same class share more similar patterns than backgrounds. At the pretraining stage, for each class, we cluster contrastive-pretrained features of randomly cropped image patches, such that crops containing only foreground objects can be identified by a single cluster. We then force the pretraining model to focus on found foreground objects by a fusion sampling strategy; at the evaluation stage, among images in each training class of any few-shot task, we seek for shared contents and filter out background. The recognized foreground objects of each class are used to match foreground of testing images. Extensive experiments tailored to inductive FSL tasks on two benchmarks demonstrate the state-of-the-art performance of our method.
PointDistiller: Structured Knowledge Distillation Towards Efficient and Compact 3D Detection
May 23, 2022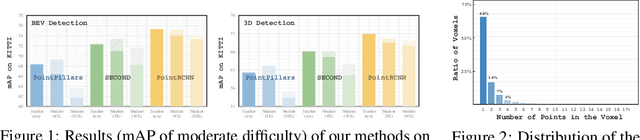
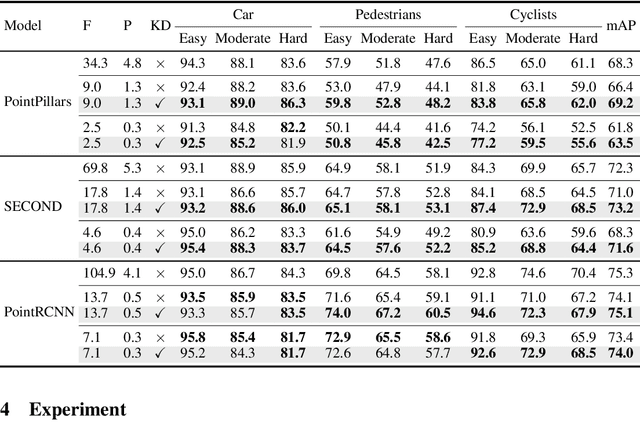
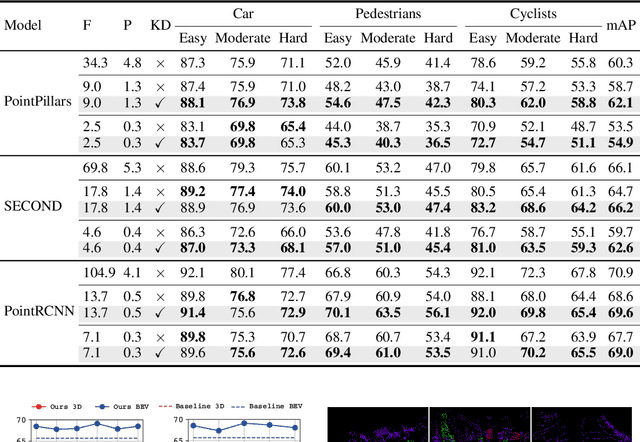
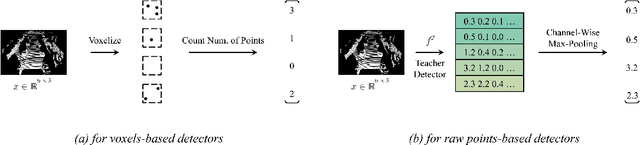
The remarkable breakthroughs in point cloud representation learning have boosted their usage in real-world applications such as self-driving cars and virtual reality. However, these applications usually have an urgent requirement for not only accurate but also efficient 3D object detection. Recently, knowledge distillation has been proposed as an effective model compression technique, which transfers the knowledge from an over-parameterized teacher to a lightweight student and achieves consistent effectiveness in 2D vision. However, due to point clouds' sparsity and irregularity, directly applying previous image-based knowledge distillation methods to point cloud detectors usually leads to unsatisfactory performance. To fill the gap, this paper proposes PointDistiller, a structured knowledge distillation framework for point clouds-based 3D detection. Concretely, PointDistiller includes local distillation which extracts and distills the local geometric structure of point clouds with dynamic graph convolution and reweighted learning strategy, which highlights student learning on the crucial points or voxels to improve knowledge distillation efficiency. Extensive experiments on both voxels-based and raw points-based detectors have demonstrated the effectiveness of our method over seven previous knowledge distillation methods. For instance, our 4X compressed PointPillars student achieves 2.8 and 3.4 mAP improvements on BEV and 3D object detection, outperforming its teacher by 0.9 and 1.8 mAP, respectively. Codes have been released at https://github.com/RunpeiDong/PointDistiller.
Visual Representation Learning with Self-Supervised Attention for Low-Label High-data Regime
Jan 22, 2022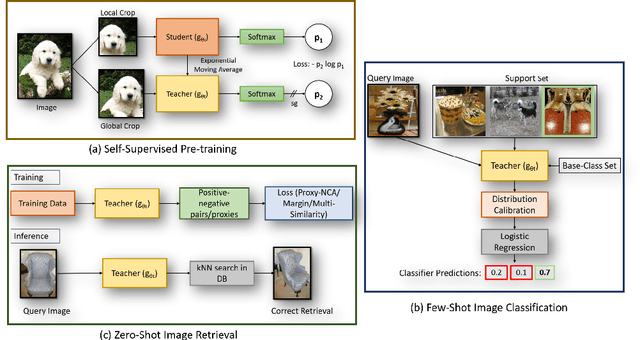
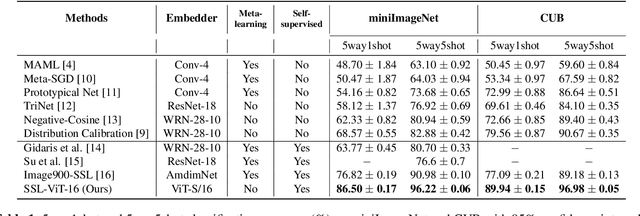
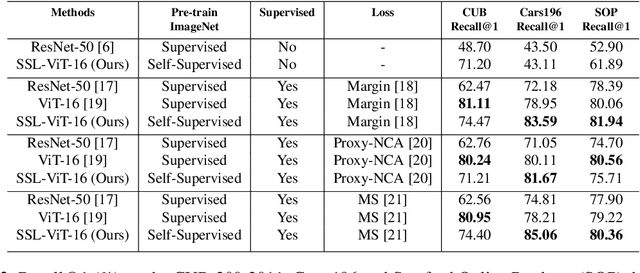

Self-supervision has shown outstanding results for natural language processing, and more recently, for image recognition. Simultaneously, vision transformers and its variants have emerged as a promising and scalable alternative to convolutions on various computer vision tasks. In this paper, we are the first to question if self-supervised vision transformers (SSL-ViTs) can be adapted to two important computer vision tasks in the low-label, high-data regime: few-shot image classification and zero-shot image retrieval. The motivation is to reduce the number of manual annotations required to train a visual embedder, and to produce generalizable, semantically meaningful and robust embeddings. For few-shot image classification we train SSL-ViTs without any supervision, on external data, and use this trained embedder to adapt quickly to novel classes with limited number of labels. For zero-shot image retrieval, we use SSL-ViTs pre-trained on a large dataset without any labels and fine-tune them with several metric learning objectives. Our self-supervised attention representations outperforms the state-of-the-art on several public benchmarks for both tasks, namely miniImageNet and CUB200 for few-shot image classification by up-to 6%-10%, and Stanford Online Products, Cars196 and CUB200 for zero-shot image retrieval by up-to 4%-11%. Code is available at \url{https://github.com/AutoVision-cloud/SSL-ViT-lowlabel-highdata}.
A Data Augmentation Method for Fully Automatic Brain Tumor Segmentation
Feb 13, 2022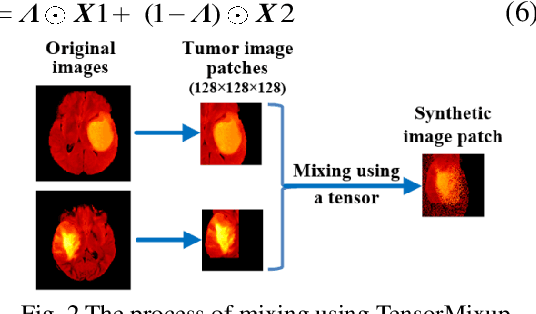

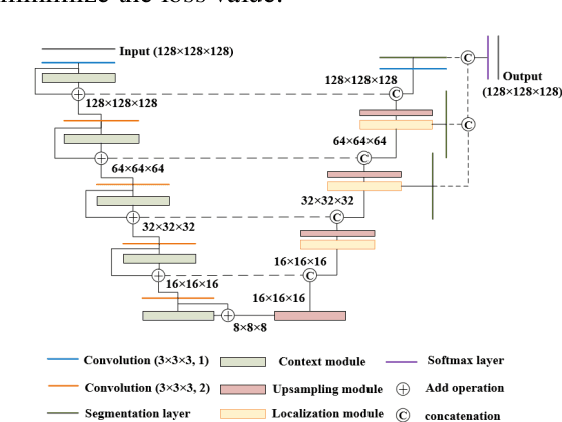
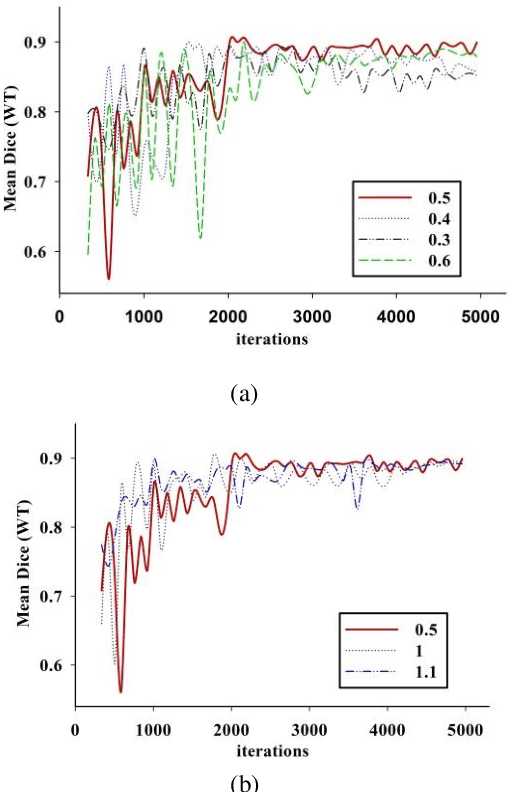
Automatic segmentation of glioma and its subregions is of great significance for diagnosis, treatment and monitoring of disease. In this paper, an augmentation method, called TensorMixup, was proposed and applied to the three dimensional U-Net architecture for brain tumor segmentation. The main ideas included that first, two image patches with size of 128 in three dimensions were selected according to glioma information of ground truth labels from the magnetic resonance imaging data of any two patients with the same modality. Next, a tensor in which all elements were independently sampled from Beta distribution was used to mix the image patches. Then the tensor was mapped to a matrix which was used to mix the one-hot encoded labels of the above image patches. Therefore, a new image and its one-hot encoded label were synthesized. Finally, the new data was used to train the model which could be used to segment glioma. The experimental results show that the mean accuracy of Dice scores are 91.32%, 85.67%, and 82.20% respectively on the whole tumor, tumor core, and enhancing tumor segmentation, which proves that the proposed TensorMixup is feasible and effective for brain tumor segmentation.
Fast Eye Detector Using Metric Learning for Iris on The Move
Feb 22, 2022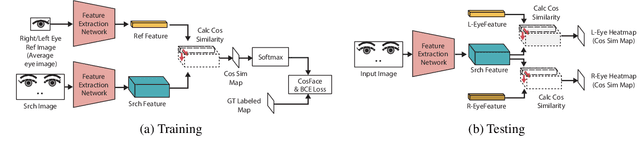


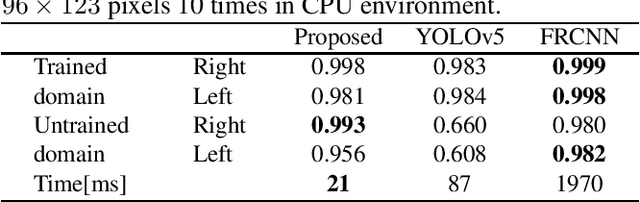
This paper proposes a fast eye detection method based on fully-convolutional Siamese networks for iris recognition. The iris on the move system requires to capture high resolution iris images from a moving subject for iris recognition. Therefore, capturing images contains both eyes at high-frame-rate increases the chance of iris imaging. In order to output the authentication result in real time, the system requires a fast eye detector extracting the left and right eye regions from the image. Our method extracts features of a partial face image and a reference eye image using Siamese network frameworks. Similarity heat maps of both eyes are created by calculating the spatial cosine similarity between extracted features. Besides, we use CosFace as a loss function for training to discriminate the left and right eyes with high accuracy even with a shallow network. Experimental results show that our method trained by CosFace is fast and accurate compared with conventional generic object detection methods.
Decision boundaries and convex hulls in the feature space that deep learning functions learn from images
Feb 05, 2022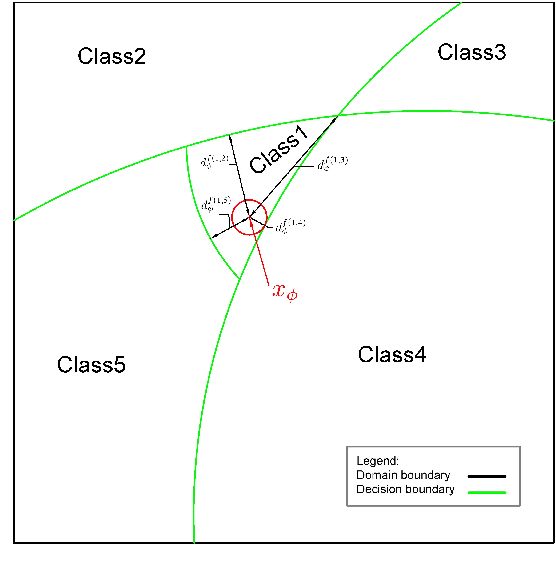
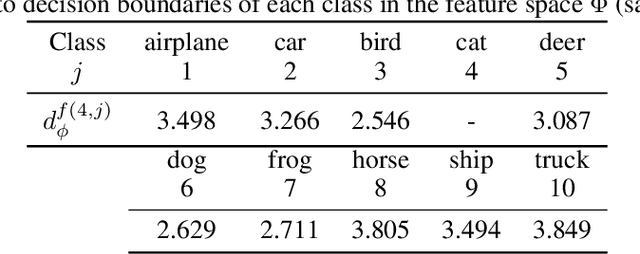
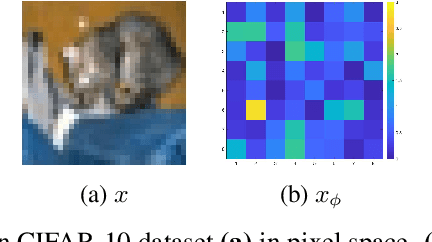
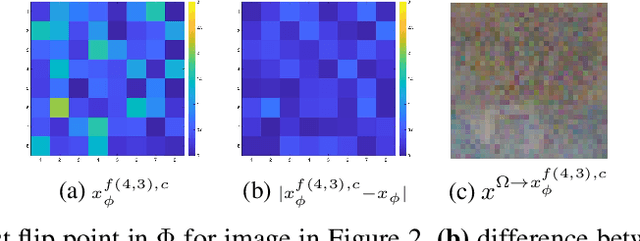
The success of deep neural networks in image classification and learning can be partly attributed to the features they extract from images. It is often speculated about the properties of a low-dimensional manifold that models extract and learn from images. However, there is not sufficient understanding about this low-dimensional space based on theory or empirical evidence. For image classification models, their last hidden layer is the one where images of each class is separated from other classes and it also has the least number of features. Here, we develop methods and formulations to study that feature space for any model. We study the partitioning of the domain in feature space, identify regions guaranteed to have certain classifications, and investigate its implications for the pixel space. We observe that geometric arrangements of decision boundaries in feature space is significantly different compared to pixel space, providing insights about adversarial vulnerabilities, image morphing, extrapolation, ambiguity in classification, and the mathematical understanding of image classification models.
TVDIM: Enhancing Image Self-Supervised Pretraining via Noisy Text Data
Jun 13, 2021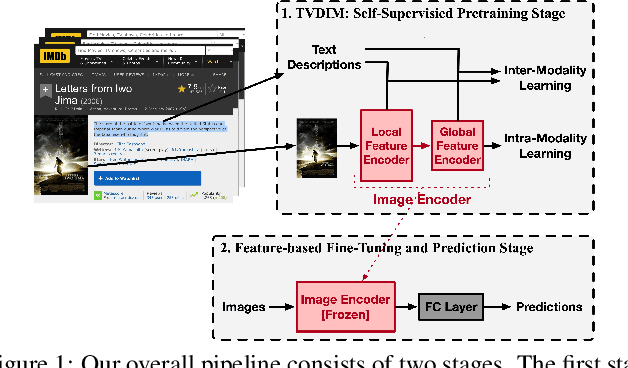
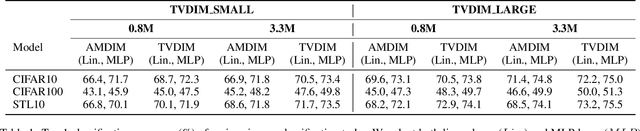
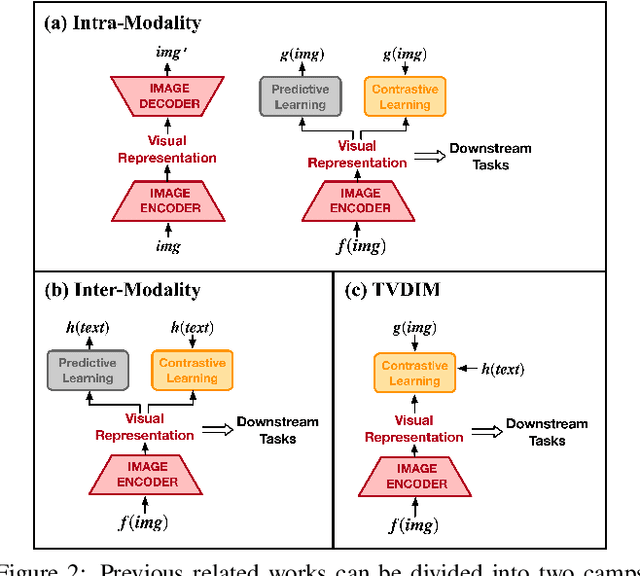
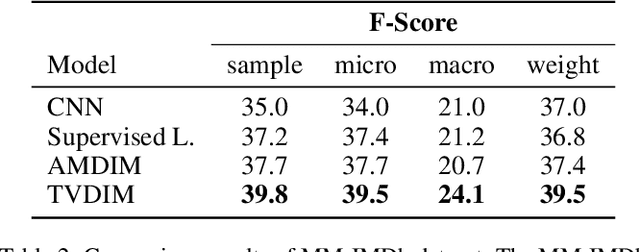
Among ubiquitous multimodal data in the real world, text is the modality generated by human, while image reflects the physical world honestly. In a visual understanding application, machines are expected to understand images like human. Inspired by this, we propose a novel self-supervised learning method, named Text-enhanced Visual Deep InfoMax (TVDIM), to learn better visual representations by fully utilizing the naturally-existing multimodal data. Our core idea of self-supervised learning is to maximize the mutual information between features extracted from multiple views of a shared context to a rational degree. Different from previous methods which only consider multiple views from a single modality, our work produces multiple views from different modalities, and jointly optimizes the mutual information for features pairs of intra-modality and inter-modality. Considering the information gap between inter-modality features pairs from data noise, we adopt a \emph{ranking-based} contrastive learning to optimize the mutual information. During evaluation, we directly use the pre-trained visual representations to complete various image classification tasks. Experimental results show that, TVDIM significantly outperforms previous visual self-supervised methods when processing the same set of images.