 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Identification of chicken egg fertility using SVM classifier based on first-order statistical feature extraction
Jan 10, 2022
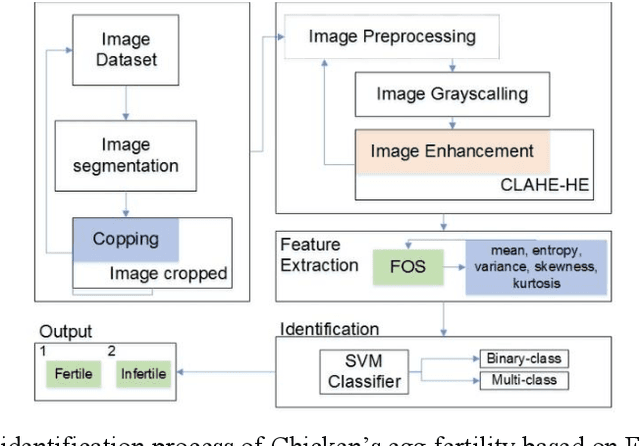
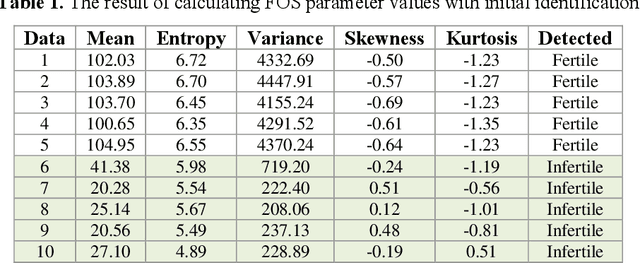

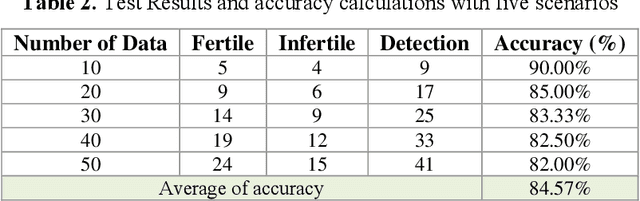
This study aims to identify chicken eggs fertility using the support vector machine (SVM) classifier method. The classification basis used the first-order statistical (FOS) parameters as feature extraction in the identification process. This research was developed based on the process's identification process, which is still manual (conventional). Although currently there are many technologies in the identification process, they still need development. Thus, this research is one of the developments in the field of image processing technology. The sample data uses datasets from previous studies with a total of 100 egg images. The egg object in the image is a single object. From these data, the classification of each fertile and infertile egg is 50 image data. Chicken egg image data became input in image processing, with the initial process is segmentation. This initial segmentation aims to get the cropped image according to the object. The cropped image is repaired using image preprocessing with grayscaling and image enhancement methods. This method (image enhancement) used two combination methods: contrast limited adaptive histogram equalization (CLAHE) and histogram equalization (HE). The improved image becomes the input for feature extraction using the FOS method. The FOS uses five parameters, namely mean, entropy, variance, skewness, and kurtosis. The five parameters entered into the SVM classifier method to identify the fertility of chicken eggs. The results of these experiments, the method proposed in the identification process has a success percentage of 84.57%. Thus, the implementation of this method can be used as a reference for future research improvements. In addition, it may be possible to use a second-order feature extraction method to improve its accuracy and improve supervised learning for classification.
* 9 Pages, 5 Figures, 2 Tables
A Visual Navigation Perspective for Category-Level Object Pose Estimation
Mar 25, 2022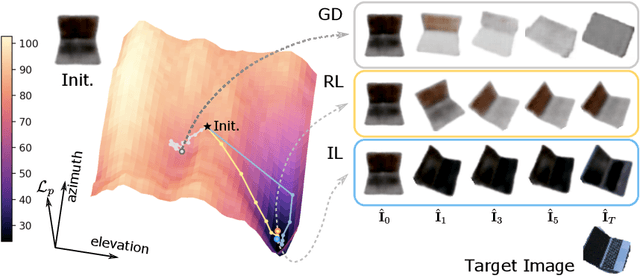
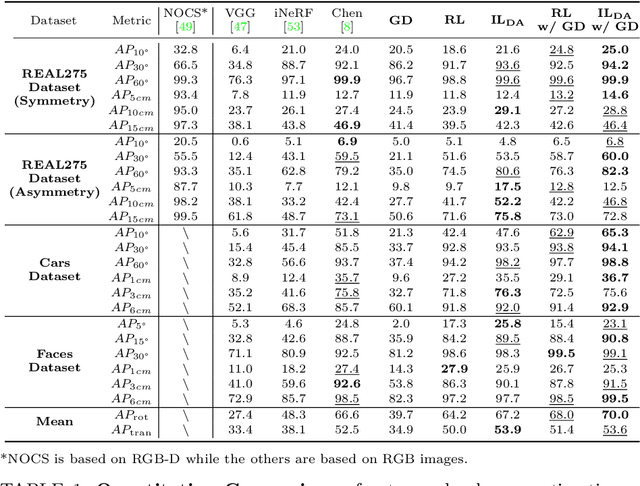
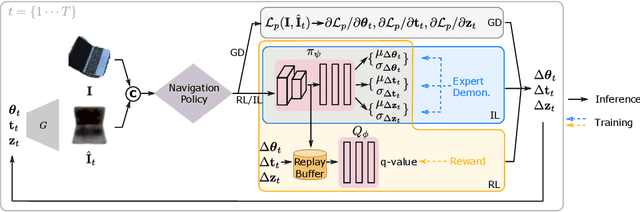
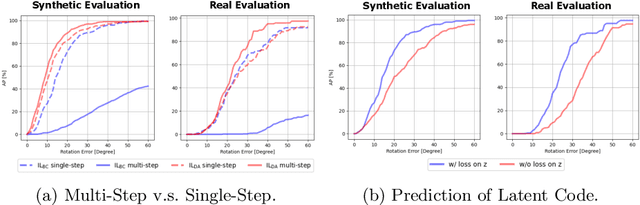
This paper studies category-level object pose estimation based on a single monocular image. Recent advances in pose-aware generative models have paved the way for addressing this challenging task using analysis-by-synthesis. The idea is to sequentially update a set of latent variables, e.g., pose, shape, and appearance, of the generative model until the generated image best agrees with the observation. However, convergence and efficiency are two challenges of this inference procedure. In this paper, we take a deeper look at the inference of analysis-by-synthesis from the perspective of visual navigation, and investigate what is a good navigation policy for this specific task. We evaluate three different strategies, including gradient descent, reinforcement learning and imitation learning, via thorough comparisons in terms of convergence, robustness and efficiency. Moreover, we show that a simple hybrid approach leads to an effective and efficient solution. We further compare these strategies to state-of-the-art methods, and demonstrate superior performance on synthetic and real-world datasets leveraging off-the-shelf pose-aware generative models.
Do learned representations respect causal relationships?
Apr 07, 2022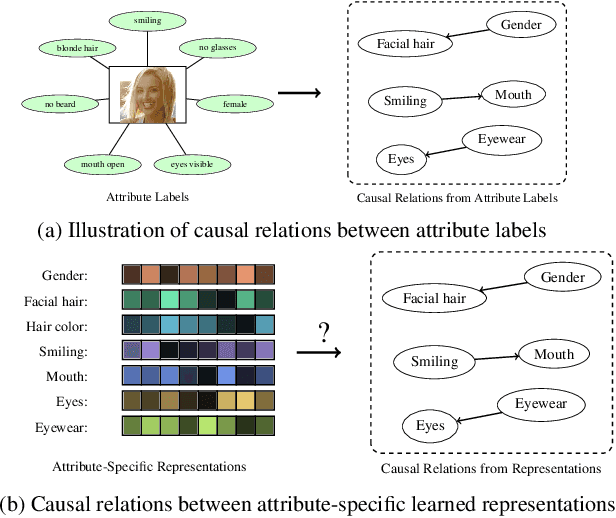
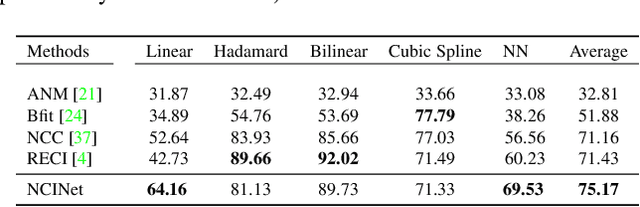


Data often has many semantic attributes that are causally associated with each other. But do attribute-specific learned representations of data also respect the same causal relations? We answer this question in three steps. First, we introduce NCINet, an approach for observational causal discovery from high-dimensional data. It is trained purely on synthetically generated representations and can be applied to real representations, and is specifically designed to mitigate the domain gap between the two. Second, we apply NCINet to identify the causal relations between image representations of different pairs of attributes with known and unknown causal relations between the labels. For this purpose, we consider image representations learned for predicting attributes on the 3D Shapes, CelebA, and the CASIA-WebFace datasets, which we annotate with multiple multi-class attributes. Third, we analyze the effect on the underlying causal relation between learned representations induced by various design choices in representation learning. Our experiments indicate that (1) NCINet significantly outperforms existing observational causal discovery approaches for estimating the causal relation between pairs of random samples, both in the presence and absence of an unobserved confounder, (2) under controlled scenarios, learned representations can indeed satisfy the underlying causal relations between their respective labels, and (3) the causal relations are positively correlated with the predictive capability of the representations.
RTIC: Residual Learning for Text and Image Composition using Graph Convolutional Network
Apr 08, 2021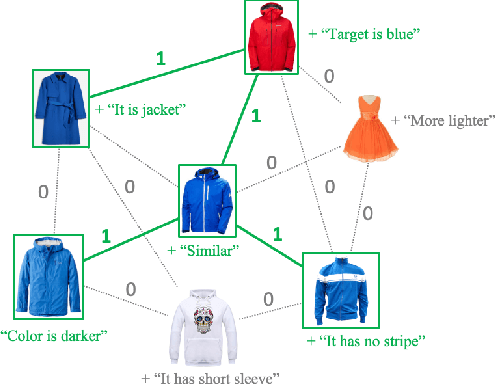
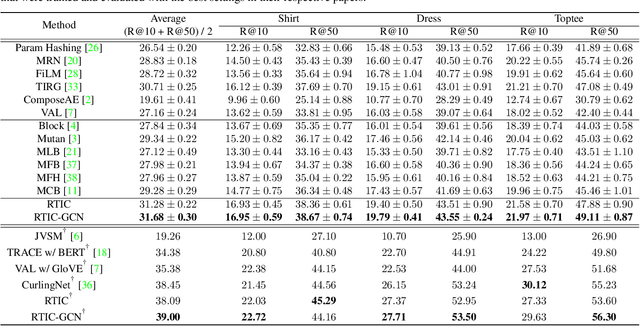
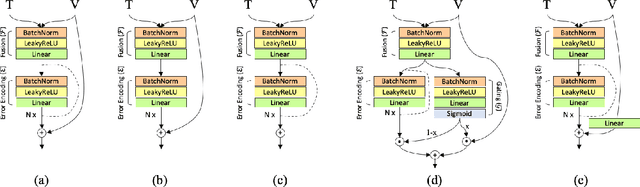
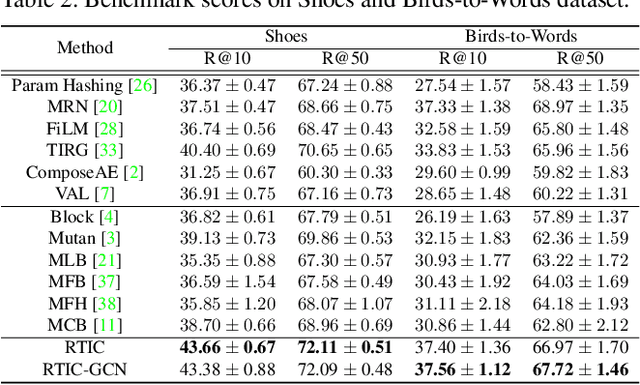
In this paper, we study the compositional learning of images and texts for image retrieval. The query is given in the form of an image and text that describes the desired modifications to the image; the goal is to retrieve the target image that satisfies the given modifications and resembles the query by composing information in both the text and image modalities. To accomplish this task, we propose a simple new architecture using skip connections that can effectively encode the errors between the source and target images in the latent space. Furthermore, we introduce a novel method that combines the graph convolutional network (GCN) with existing composition methods. We find that the combination consistently improves the performance in a plug-and-play manner. We perform thorough and exhaustive experiments on several widely used datasets, and achieve state-of-the-art scores on the task with our model. To ensure fairness in comparison, we suggest a strict standard for the evaluation because a small difference in the training conditions can significantly affect the final performance. We release our implementation, including that of all the compared methods, for reproducibility.
Towards Unified Keyframe Propagation Models
May 19, 2022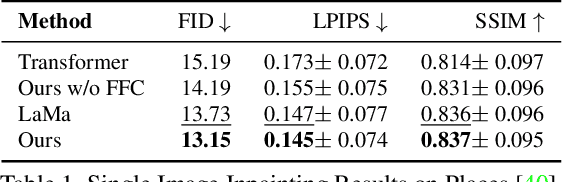
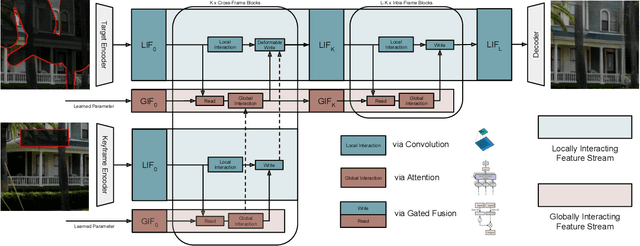
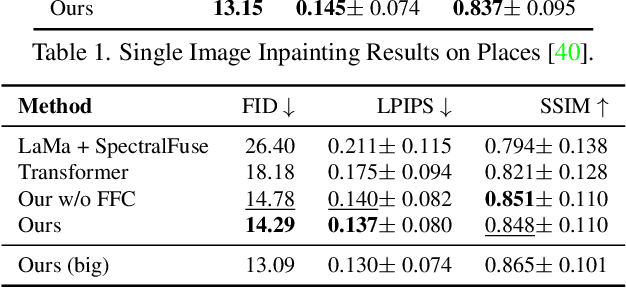

Many video editing tasks such as rotoscoping or object removal require the propagation of context across frames. While transformers and other attention-based approaches that aggregate features globally have demonstrated great success at propagating object masks from keyframes to the whole video, they struggle to propagate high-frequency details such as textures faithfully. We hypothesize that this is due to an inherent bias of global attention towards low-frequency features. To overcome this limitation, we present a two-stream approach, where high-frequency features interact locally and low-frequency features interact globally. The global interaction stream remains robust in difficult situations such as large camera motions, where explicit alignment fails. The local interaction stream propagates high-frequency details through deformable feature aggregation and, informed by the global interaction stream, learns to detect and correct errors of the deformation field. We evaluate our two-stream approach for inpainting tasks, where experiments show that it improves both the propagation of features within a single frame as required for image inpainting, as well as their propagation from keyframes to target frames. Applied to video inpainting, our approach leads to 44% and 26% improvements in FID and LPIPS scores. Code at https://github.com/runwayml/guided-inpainting
VNT-Net: Rotational Invariant Vector Neuron Transformers
May 19, 2022
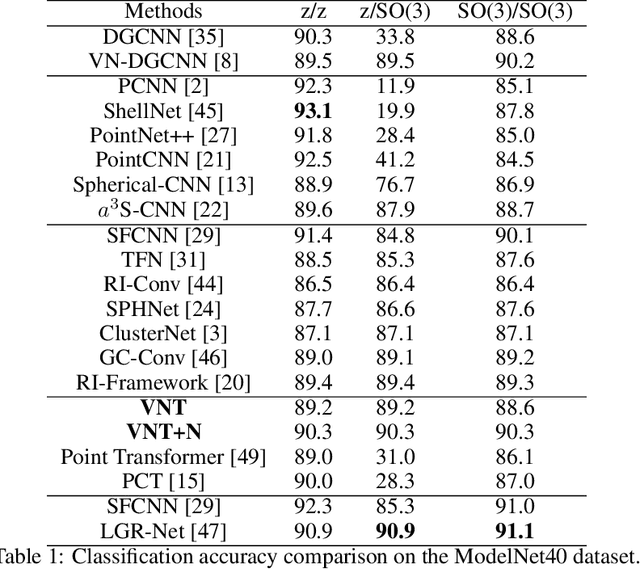
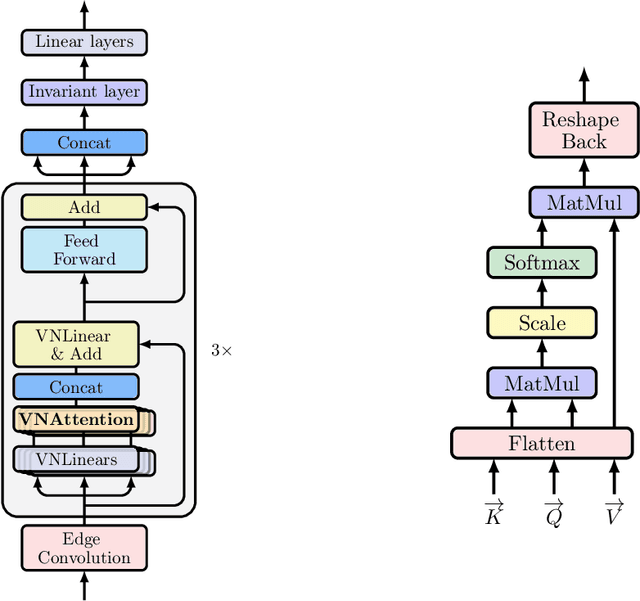
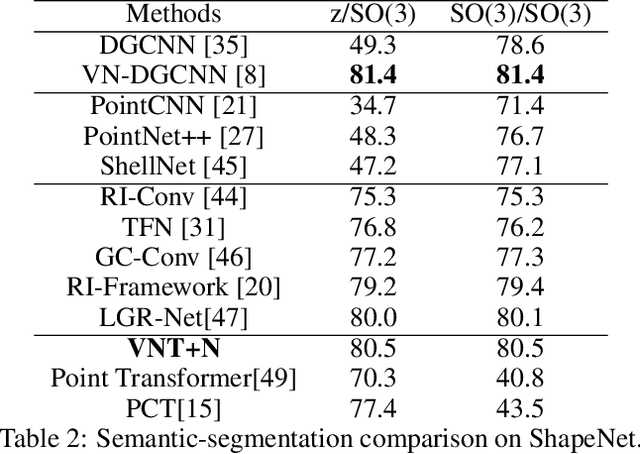
Learning 3D point sets with rotational invariance is an important and challenging problem in machine learning. Through rotational invariant architectures, 3D point cloud neural networks are relieved from requiring a canonical global pose and from exhaustive data augmentation with all possible rotations. In this work, we introduce a rotational invariant neural network by combining recently introduced vector neurons with self-attention layers to build a point cloud vector neuron transformer network (VNT-Net). Vector neurons are known for their simplicity and versatility in representing SO(3) actions and are thereby incorporated in common neural operations. Similarly, Transformer architectures have gained popularity and recently were shown successful for images by applying directly on sequences of image patches and achieving superior performance and convergence. In order to benefit from both worlds, we combine the two structures by mainly showing how to adapt the multi-headed attention layers to comply with vector neurons operations. Through this adaptation attention layers become SO(3) and the overall network becomes rotational invariant. Experiments demonstrate that our network efficiently handles 3D point cloud objects in arbitrary poses. We also show that our network achieves higher accuracy when compared to related state-of-the-art methods and requires less training due to a smaller number of hyperparameters in common classification and segmentation tasks.
Accelerating Diffusion Models via Early Stop of the Diffusion Process
May 30, 2022

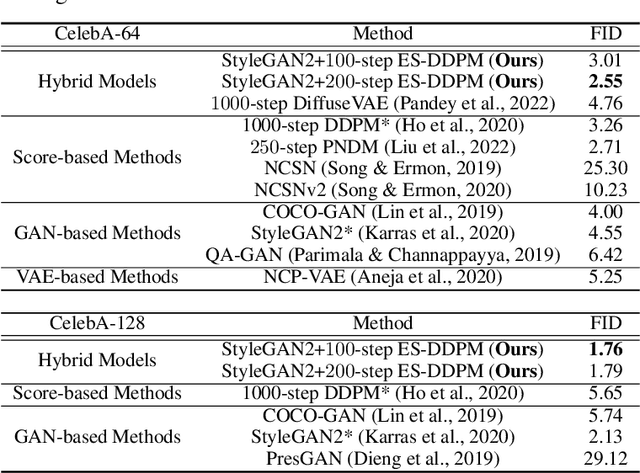
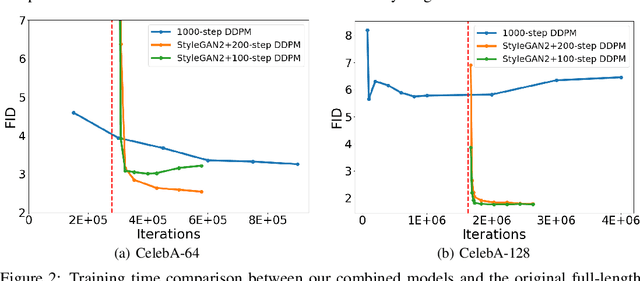
Denoising Diffusion Probabilistic Models (DDPMs) have achieved impressive performance on various generation tasks. By modeling the reverse process of gradually diffusing the data distribution into a Gaussian distribution, generating a sample in DDPMs can be regarded as iteratively denoising a randomly sampled Gaussian noise. However, in practice DDPMs often need hundreds even thousands of denoising steps to obtain a high-quality sample from the Gaussian noise, leading to extremely low inference efficiency. In this work, we propose a principled acceleration strategy, referred to as Early-Stopped DDPM (ES-DDPM), for DDPMs. The key idea is to stop the diffusion process early where only the few initial diffusing steps are considered and the reverse denoising process starts from a non-Gaussian distribution. By further adopting a powerful pre-trained generative model, such as GAN and VAE, in ES-DDPM, sampling from the target non-Gaussian distribution can be efficiently achieved by diffusing samples obtained from the pre-trained generative model. In this way, the number of required denoising steps is significantly reduced. In the meantime, the sample quality of ES-DDPM also improves substantially, outperforming both the vanilla DDPM and the adopted pre-trained generative model. On extensive experiments across CIFAR-10, CelebA, ImageNet, LSUN-Bedroom and LSUN-Cat, ES-DDPM obtains promising acceleration effect and performance improvement over representative baseline methods. Moreover, ES-DDPM also demonstrates several attractive properties, including being orthogonal to existing acceleration methods, as well as simultaneously enabling both global semantic and local pixel-level control in image generation.
Hierarchical Self-Supervised Learning for Medical Image Segmentation Based on Multi-Domain Data Aggregation
Jul 10, 2021
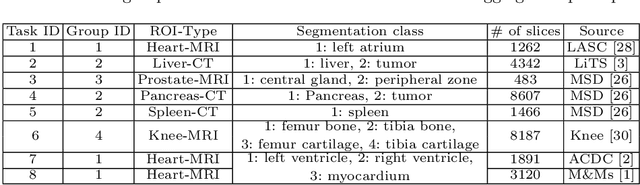
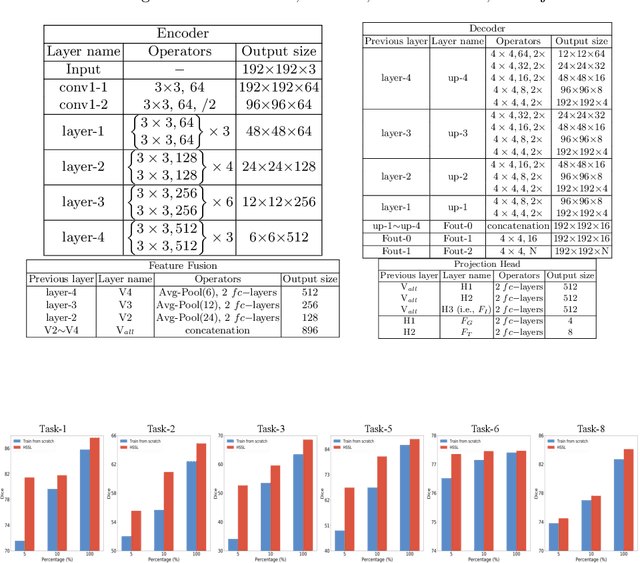
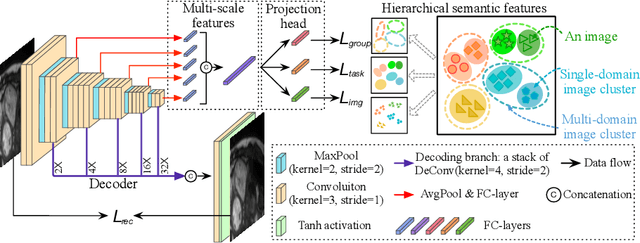
A large labeled dataset is a key to the success of supervised deep learning, but for medical image segmentation, it is highly challenging to obtain sufficient annotated images for model training. In many scenarios, unannotated images are abundant and easy to acquire. Self-supervised learning (SSL) has shown great potentials in exploiting raw data information and representation learning. In this paper, we propose Hierarchical Self-Supervised Learning (HSSL), a new self-supervised framework that boosts medical image segmentation by making good use of unannotated data. Unlike the current literature on task-specific self-supervised pretraining followed by supervised fine-tuning, we utilize SSL to learn task-agnostic knowledge from heterogeneous data for various medical image segmentation tasks. Specifically, we first aggregate a dataset from several medical challenges, then pre-train the network in a self-supervised manner, and finally fine-tune on labeled data. We develop a new loss function by combining contrastive loss and classification loss and pretrain an encoder-decoder architecture for segmentation tasks. Our extensive experiments show that multi-domain joint pre-training benefits downstream segmentation tasks and outperforms single-domain pre-training significantly. Compared to learning from scratch, our new method yields better performance on various tasks (e.g., +0.69% to +18.60% in Dice scores with 5% of annotated data). With limited amounts of training data, our method can substantially bridge the performance gap w.r.t. denser annotations (e.g., 10% vs.~100% of annotated data).
LiDAR-guided Stereo Matching with a Spatial Consistency Constraint
Feb 24, 2022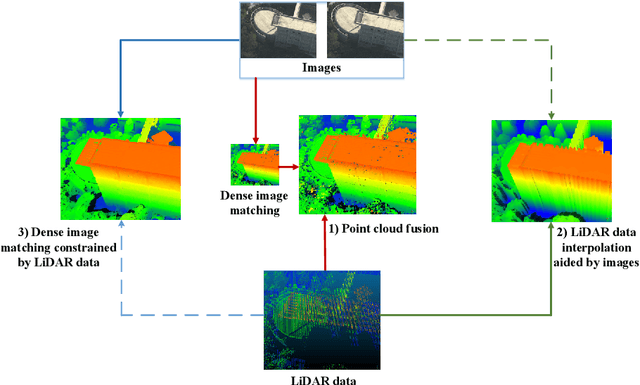
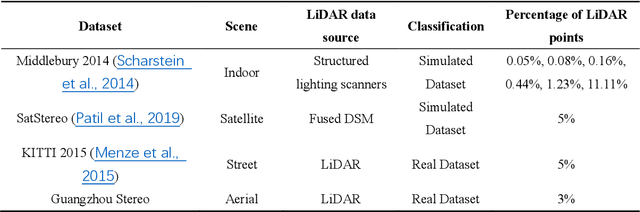
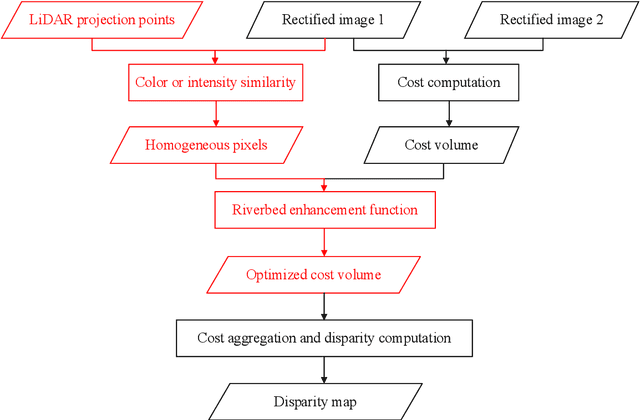
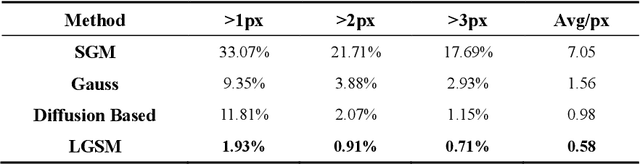
The complementary fusion of light detection and ranging (LiDAR) data and image data is a promising but challenging task for generating high-precision and high-density point clouds. This study proposes an innovative LiDAR-guided stereo matching approach called LiDAR-guided stereo matching (LGSM), which considers the spatial consistency represented by continuous disparity or depth changes in the homogeneous region of an image. The LGSM first detects the homogeneous pixels of each LiDAR projection point based on their color or intensity similarity. Next, we propose a riverbed enhancement function to optimize the cost volume of the LiDAR projection points and their homogeneous pixels to improve the matching robustness. Our formulation expands the constraint scopes of sparse LiDAR projection points with the guidance of image information to optimize the cost volume of pixels as much as possible. We applied LGSM to semi-global matching and AD-Census on both simulated and real datasets. When the percentage of LiDAR points in the simulated datasets was 0.16%, the matching accuracy of our method achieved a subpixel level, while that of the original stereo matching algorithm was 3.4 pixels. The experimental results show that LGSM is suitable for indoor, street, aerial, and satellite image datasets and provides good transferability across semi-global matching and AD-Census. Furthermore, the qualitative and quantitative evaluations demonstrate that LGSM is superior to two state-of-the-art optimizing cost volume methods, especially in reducing mismatches in difficult matching areas and refining the boundaries of objects.
* we replace an article because of the addition of journal reference, DOI, and report number information
Dependent Multi-Task Learning with Causal Intervention for Image Captioning
May 18, 2021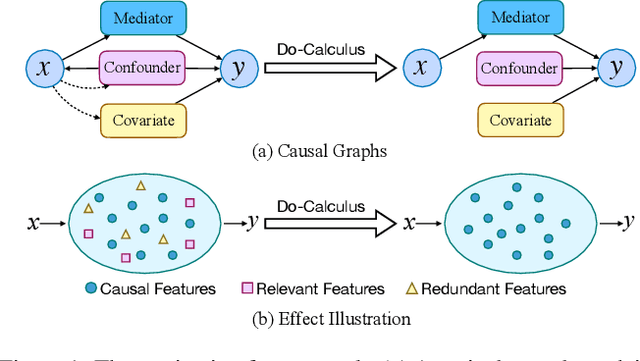
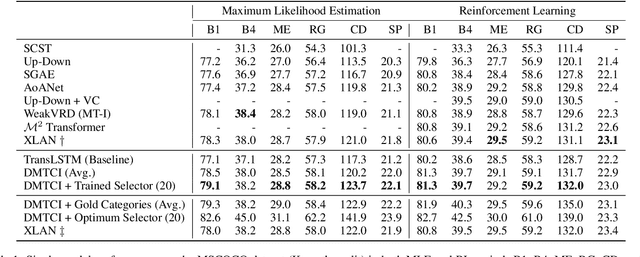
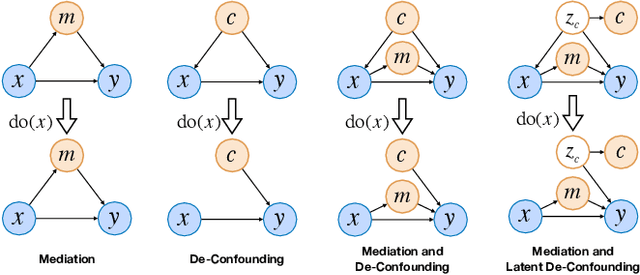
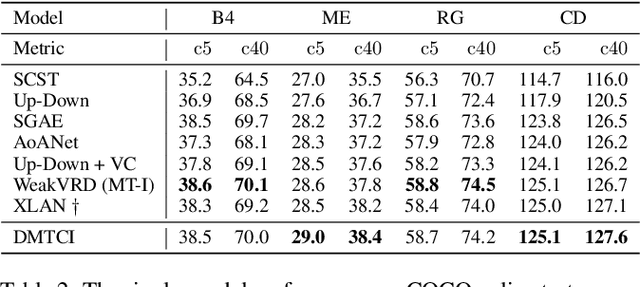
Recent work for image captioning mainly followed an extract-then-generate paradigm, pre-extracting a sequence of object-based features and then formulating image captioning as a single sequence-to-sequence task. Although promising, we observed two problems in generated captions: 1) content inconsistency where models would generate contradicting facts; 2) not informative enough where models would miss parts of important information. From a causal perspective, the reason is that models have captured spurious statistical correlations between visual features and certain expressions (e.g., visual features of "long hair" and "woman"). In this paper, we propose a dependent multi-task learning framework with the causal intervention (DMTCI). Firstly, we involve an intermediate task, bag-of-categories generation, before the final task, image captioning. The intermediate task would help the model better understand the visual features and thus alleviate the content inconsistency problem. Secondly, we apply Pearl's do-calculus on the model, cutting off the link between the visual features and possible confounders and thus letting models focus on the causal visual features. Specifically, the high-frequency concept set is considered as the proxy confounders where the real confounders are inferred in the continuous space. Finally, we use a multi-agent reinforcement learning (MARL) strategy to enable end-to-end training and reduce the inter-task error accumulations. The extensive experiments show that our model outperforms the baseline models and achieves competitive performance with state-of-the-art models.