 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Segmentation of Hyperspectral Remote Sensing Images with Superpixels
Apr 26, 2022

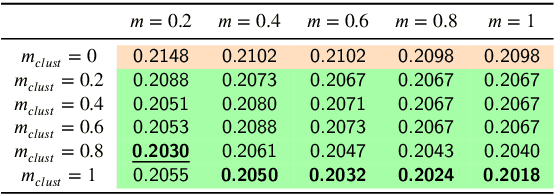
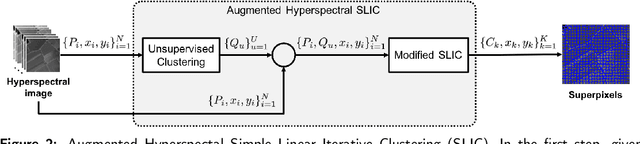
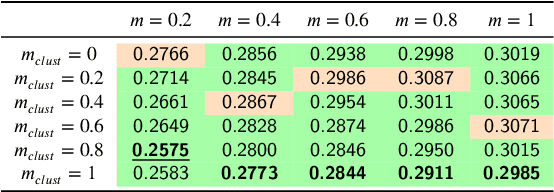
In this paper, we propose an unsupervised method for hyperspectral remote sensing image segmentation. The method exploits the mean-shift clustering algorithm that takes as input a preliminary hyperspectral superpixels segmentation together with the spectral pixel information. The proposed method does not require the number of segmentation classes as input parameter, and it does not exploit any a-priori knowledge about the type of land-cover or land-use to be segmented (e.g. water, vegetation, building etc.). Experiments on Salinas, SalinasA, Pavia Center and Pavia University datasets are carried out. Performance are measured in terms of normalized mutual information, adjusted Rand index and F1-score. Results demonstrate the validity of the proposed method in comparison with the state of the art.
Repairing Group-Level Errors for DNNs Using Weighted Regularization
Apr 04, 2022
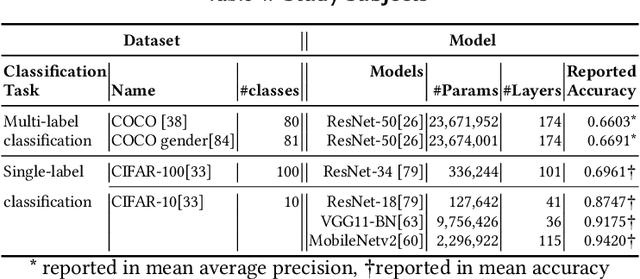
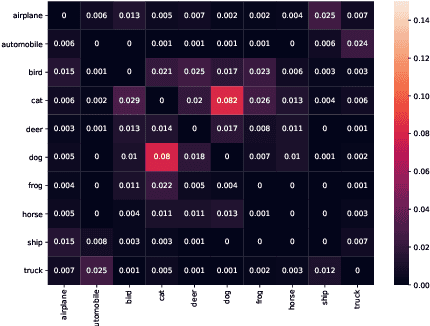
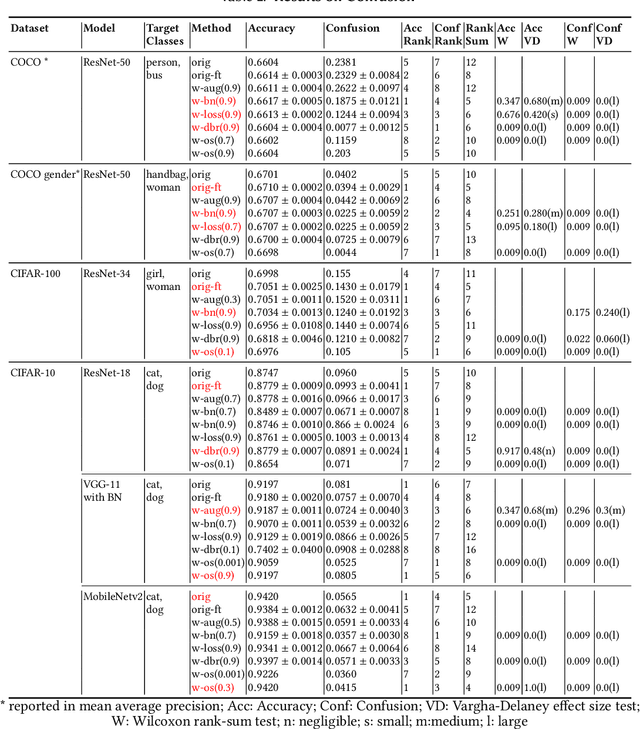
Deep Neural Networks (DNNs) have been widely used in software making decisions impacting people's lives. However, they have been found to exhibit severe erroneous behaviors that may lead to unfortunate outcomes. Previous work shows that such misbehaviors often occur due to class property violations rather than errors on a single image. Although methods for detecting such errors have been proposed, fixing them has not been studied so far. Here, we propose a generic method called Weighted Regularization (WR) consisting of five concrete methods targeting the error-producing classes to fix the DNNs. In particular, it can repair confusion error and bias error of DNN models for both single-label and multi-label image classifications. A confusion error happens when a given DNN model tends to confuse between two classes. Each method in WR assigns more weights at a stage of DNN retraining or inference to mitigate the confusion between target pair. A bias error can be fixed similarly. We evaluate and compare the proposed methods along with baselines on six widely-used datasets and architecture combinations. The results suggest that WR methods have different trade-offs but under each setting at least one WR method can greatly reduce confusion/bias errors at a very limited cost of the overall performance.
Ray Priors through Reprojection: Improving Neural Radiance Fields for Novel View Extrapolation
May 12, 2022
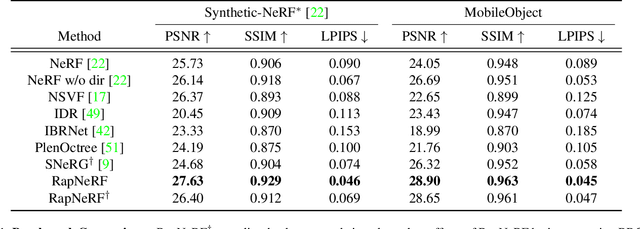
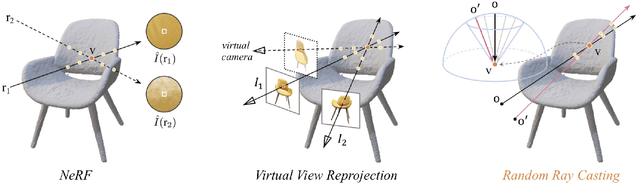
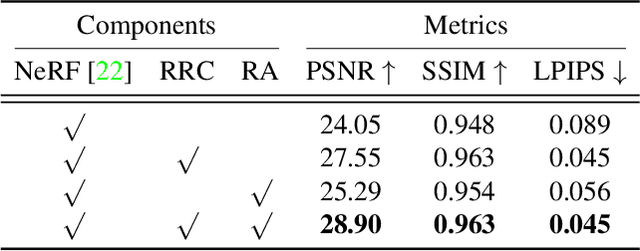
Neural Radiance Fields (NeRF) have emerged as a potent paradigm for representing scenes and synthesizing photo-realistic images. A main limitation of conventional NeRFs is that they often fail to produce high-quality renderings under novel viewpoints that are significantly different from the training viewpoints. In this paper, instead of exploiting few-shot image synthesis, we study the novel view extrapolation setting that (1) the training images can well describe an object, and (2) there is a notable discrepancy between the training and test viewpoints' distributions. We present RapNeRF (RAy Priors) as a solution. Our insight is that the inherent appearances of a 3D surface's arbitrary visible projections should be consistent. We thus propose a random ray casting policy that allows training unseen views using seen views. Furthermore, we show that a ray atlas pre-computed from the observed rays' viewing directions could further enhance the rendering quality for extrapolated views. A main limitation is that RapNeRF would remove the strong view-dependent effects because it leverages the multi-view consistency property.
The Group Loss++: A deeper look into group loss for deep metric learning
Apr 04, 2022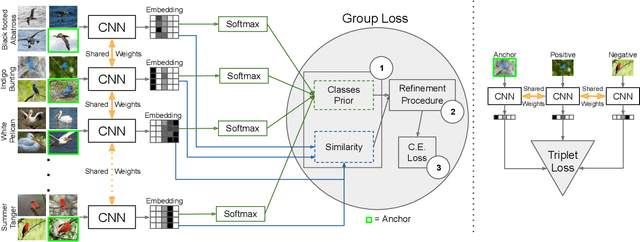
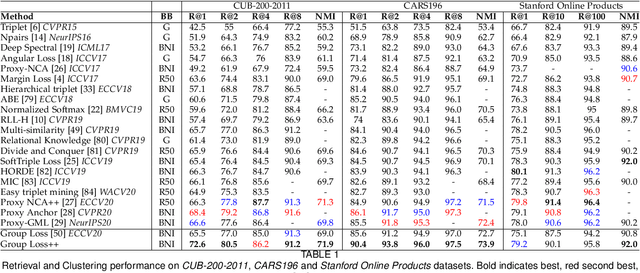
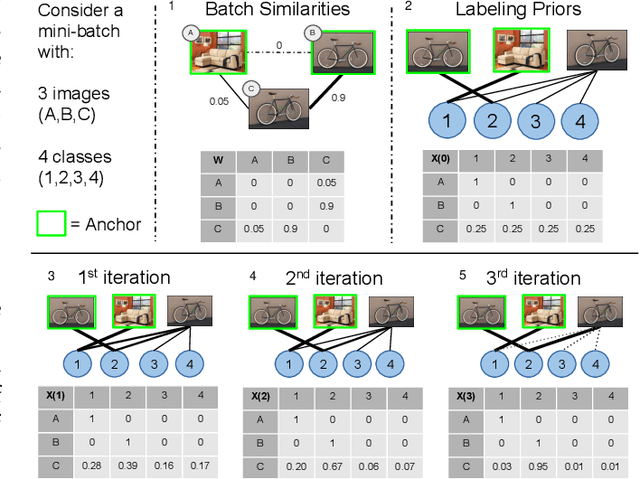
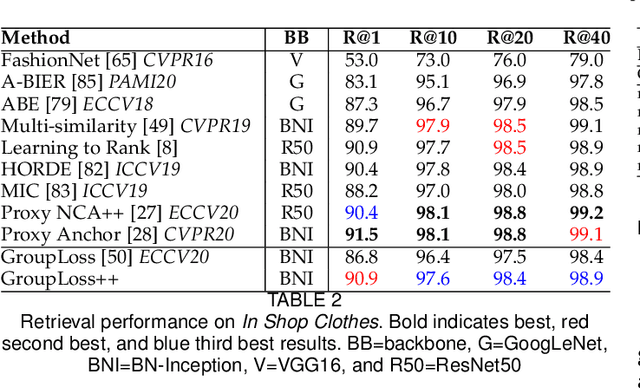
Deep metric learning has yielded impressive results in tasks such as clustering and image retrieval by leveraging neural networks to obtain highly discriminative feature embeddings, which can be used to group samples into different classes. Much research has been devoted to the design of smart loss functions or data mining strategies for training such networks. Most methods consider only pairs or triplets of samples within a mini-batch to compute the loss function, which is commonly based on the distance between embeddings. We propose Group Loss, a loss function based on a differentiable label-propagation method that enforces embedding similarity across all samples of a group while promoting, at the same time, low-density regions amongst data points belonging to different groups. Guided by the smoothness assumption that "similar objects should belong to the same group", the proposed loss trains the neural network for a classification task, enforcing a consistent labelling amongst samples within a class. We design a set of inference strategies tailored towards our algorithm, named Group Loss++ that further improve the results of our model. We show state-of-the-art results on clustering and image retrieval on four retrieval datasets, and present competitive results on two person re-identification datasets, providing a unified framework for retrieval and re-identification.
A New Gastric Histopathology Subsize Image Database (GasHisSDB) for Classification Algorithm Test: from Linear Regression to Visual Transformer
Jun 04, 2021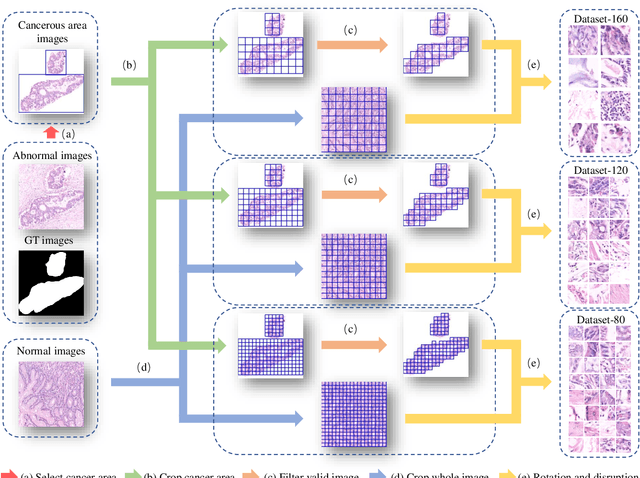
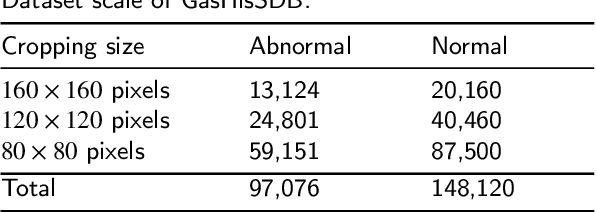
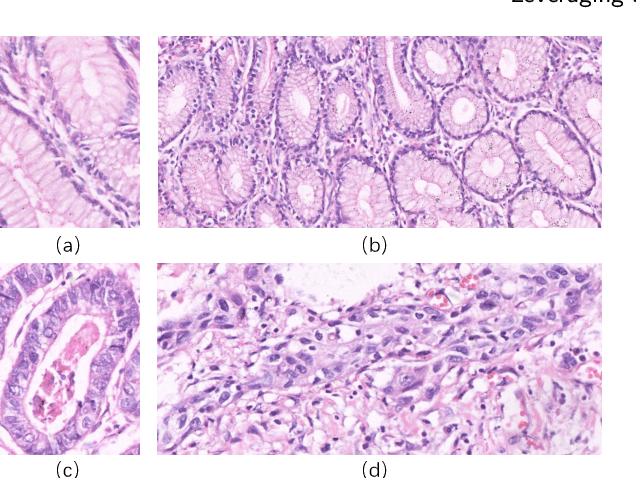
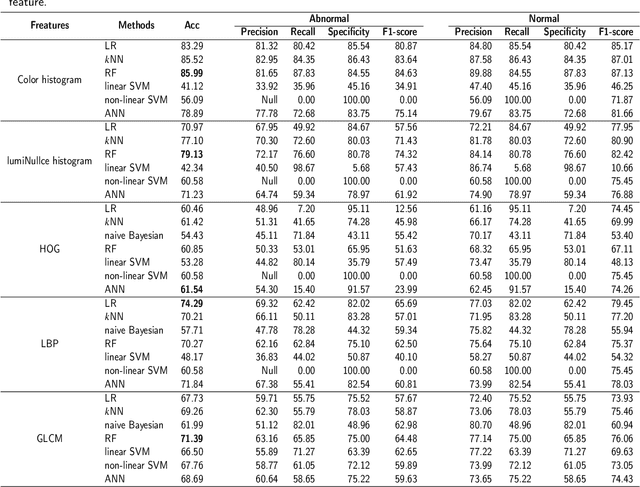
GasHisSDB is a New Gastric Histopathology Subsize Image Database with a total of 245196 images. GasHisSDB is divided into 160*160 pixels sub-database, 120*120 pixels sub-database and 80*80 pixels sub-database. GasHisSDB is made to realize the function of valuating image classification. In order to prove that the methods of different periods in the field of image classification have discrepancies on GasHisSDB, we select a variety of classifiers for evaluation. Seven classical machine learning classifiers, three CNN classifiers and a novel transformer-based classifier are selected for testing on image classification tasks. GasHisSDB is available at the URL:https://github.com/NEUhwm/GasHisSDB.git.
SpecTr: Spectral Transformer for Hyperspectral Pathology Image Segmentation
Mar 05, 2021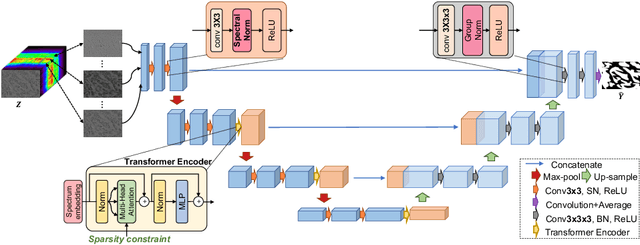
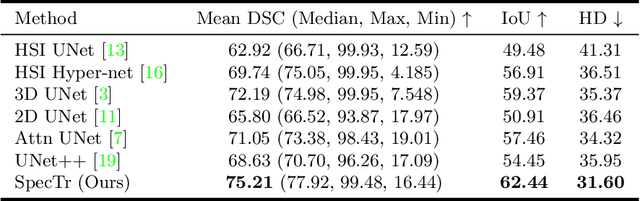
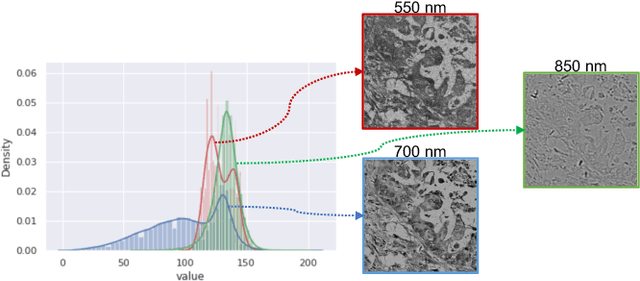
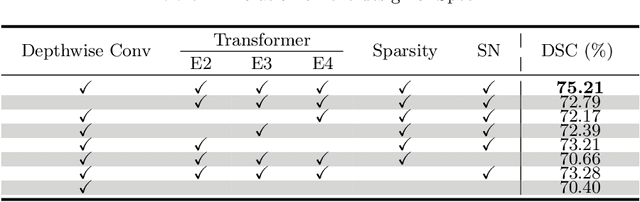
Hyperspectral imaging (HSI) unlocks the huge potential to a wide variety of applications relied on high-precision pathology image segmentation, such as computational pathology and precision medicine. Since hyperspectral pathology images benefit from the rich and detailed spectral information even beyond the visible spectrum, the key to achieve high-precision hyperspectral pathology image segmentation is to felicitously model the context along high-dimensional spectral bands. Inspired by the strong context modeling ability of transformers, we hereby, for the first time, formulate the contextual feature learning across spectral bands for hyperspectral pathology image segmentation as a sequence-to-sequence prediction procedure by transformers. To assist spectral context learning procedure, we introduce two important strategies: (1) a sparsity scheme enforces the learned contextual relationship to be sparse, so as to eliminates the distraction from the redundant bands; (2) a spectral normalization, a separate group normalization for each spectral band, mitigates the nuisance caused by heterogeneous underlying distributions of bands. We name our method Spectral Transformer (SpecTr), which enjoys two benefits: (1) it has a strong ability to model long-range dependency among spectral bands, and (2) it jointly explores the spatial-spectral features of HSI. Experiments show that SpecTr outperforms other competing methods in a hyperspectral pathology image segmentation benchmark without the need of pre-training. Code is available at https://github.com/hfut-xc-yun/SpecTr.
On the Complementarity of Images and Text for the Expression of Emotions in Social Media
Feb 11, 2022
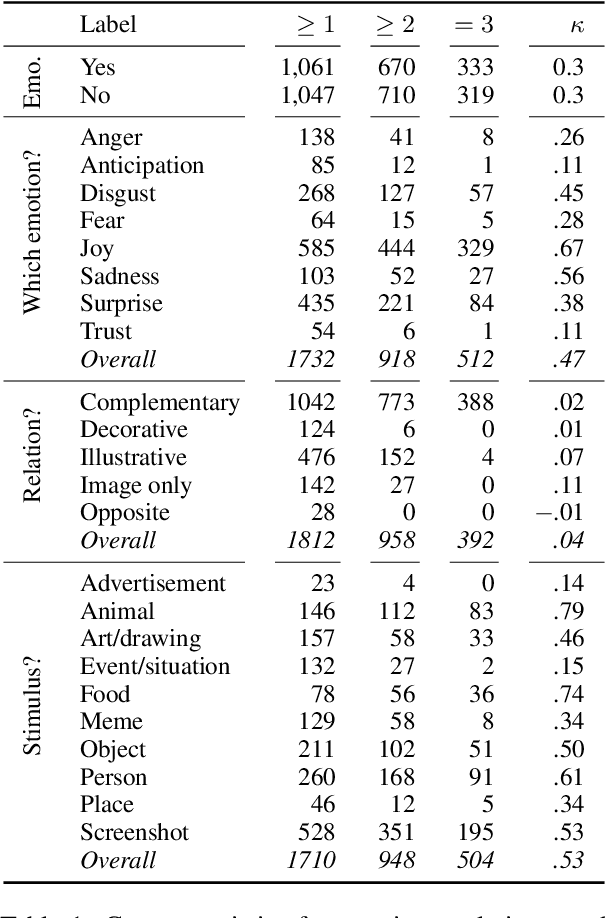


Authors of posts in social media communicate their emotions and what causes them with text and images. While there is work on emotion and stimulus detection for each modality separately, it is yet unknown if the modalities contain complementary emotion information in social media. We aim at filling this research gap and contribute a novel, annotated corpus of English multimodal Reddit posts. On this resource, we develop models to automatically detect the relation between image and text, an emotion stimulus category and the emotion class. We evaluate if these tasks require both modalities and find for the image-text relations, that text alone is sufficient for most categories (complementary, illustrative, opposing): the information in the text allows to predict if an image is required for emotion understanding. The emotions of anger and sadness are best predicted with a multimodal model, while text alone is sufficient for disgust, joy, and surprise. Stimuli depicted by objects, animals, food, or a person are best predicted by image-only models, while multimodal models are most effective on art, events, memes, places, or screenshots.
DistillAdapt: Source-Free Active Visual Domain Adaptation
May 24, 2022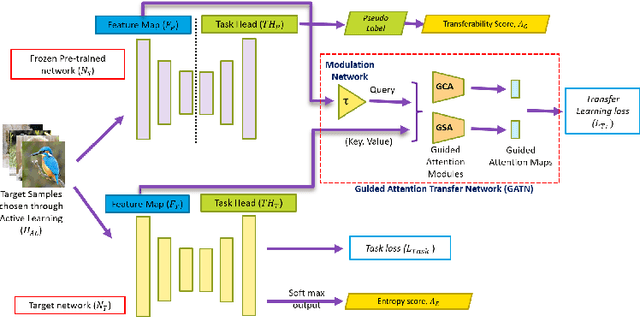

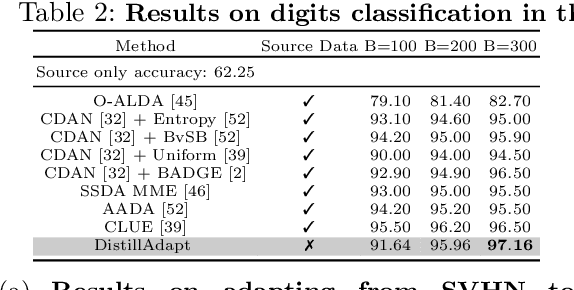
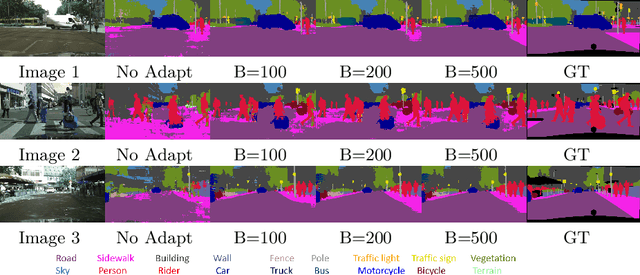
We present a novel method, DistillAdapt, for the challenging problem of Source-Free Active Domain Adaptation (SF-ADA). The problem requires adapting a pretrained source domain network to a target domain, within a provided budget for acquiring labels in the target domain, while assuming that the source data is not available for adaptation due to privacy concerns or otherwise. DistillAdapt is one of the first approaches for SF-ADA, and holistically addresses the challenges of SF-ADA via a novel Guided Attention Transfer Network (GATN) and an active learning heuristic, H_AL. The GATN enables selective distillation of features from the pre-trained network to the target network using a small subset of annotated target samples mined by H_AL. H_AL acquires samples at batch-level and balances transfer-ability from the pre-trained network and uncertainty of the target network. DistillAdapt is task-agnostic, and can be applied across visual tasks such as classification, segmentation and detection. Moreover, DistillAdapt can handle shifts in output label space. We conduct experiments and extensive ablation studies across 3 visual tasks, viz. digits classification (MNIST, SVHN), synthetic (GTA5) to real (CityScapes) image segmentation, and document layout detection (PubLayNet to DSSE). We show that our source-free approach, DistillAdapt, results in an improvement of 0.5% - 31.3% (across datasets and tasks) over prior adaptation methods that assume access to large amounts of annotated source data for adaptation.
Aligning Silhouette Topology for Self-Adaptive 3D Human Pose Recovery
Apr 04, 2022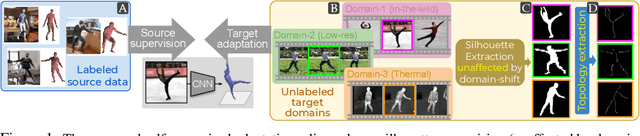
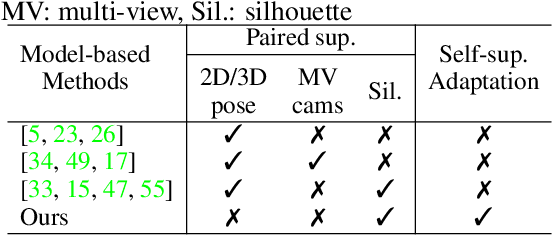
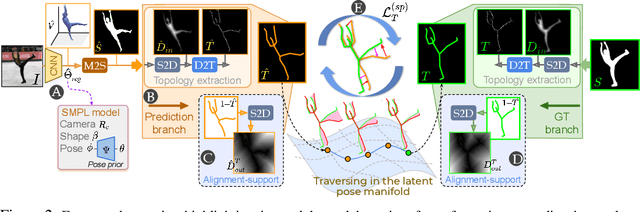
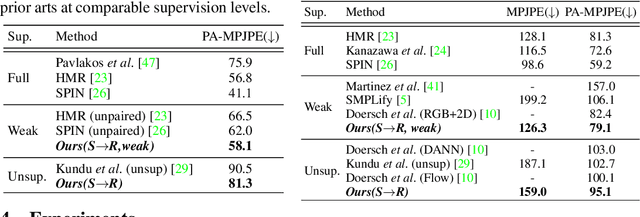
Articulation-centric 2D/3D pose supervision forms the core training objective in most existing 3D human pose estimation techniques. Except for synthetic source environments, acquiring such rich supervision for each real target domain at deployment is highly inconvenient. However, we realize that standard foreground silhouette estimation techniques (on static camera feeds) remain unaffected by domain-shifts. Motivated by this, we propose a novel target adaptation framework that relies only on silhouette supervision to adapt a source-trained model-based regressor. However, in the absence of any auxiliary cue (multi-view, depth, or 2D pose), an isolated silhouette loss fails to provide a reliable pose-specific gradient and requires to be employed in tandem with a topology-centric loss. To this end, we develop a series of convolution-friendly spatial transformations in order to disentangle a topological-skeleton representation from the raw silhouette. Such a design paves the way to devise a Chamfer-inspired spatial topological-alignment loss via distance field computation, while effectively avoiding any gradient hindering spatial-to-pointset mapping. Experimental results demonstrate our superiority against prior-arts in self-adapting a source trained model to diverse unlabeled target domains, such as a) in-the-wild datasets, b) low-resolution image domains, and c) adversarially perturbed image domains (via UAP).
BatchFormerV2: Exploring Sample Relationships for Dense Representation Learning
Apr 04, 2022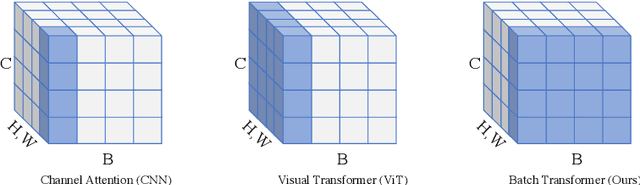
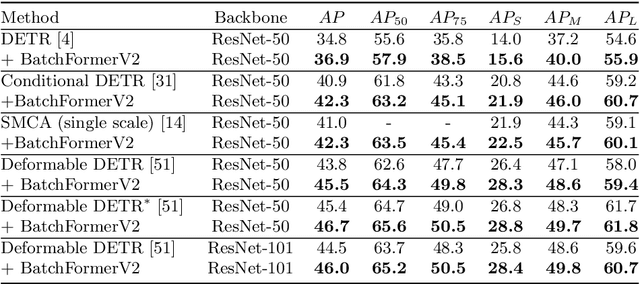
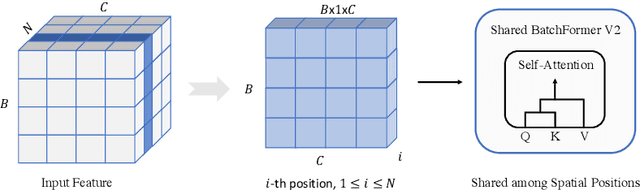

Attention mechanisms have been very popular in deep neural networks, where the Transformer architecture has achieved great success in not only natural language processing but also visual recognition applications. Recently, a new Transformer module, applying on batch dimension rather than spatial/channel dimension, i.e., BatchFormer [18], has been introduced to explore sample relationships for overcoming data scarcity challenges. However, it only works with image-level representations for classification. In this paper, we devise a more general batch Transformer module, BatchFormerV2, which further enables exploring sample relationships for dense representation learning. Specifically, when applying the proposed module, it employs a two-stream pipeline during training, i.e., either with or without a BatchFormerV2 module, where the batchformer stream can be removed for testing. Therefore, the proposed method is a plug-and-play module and can be easily integrated into different vision Transformers without any extra inference cost. Without bells and whistles, we show the effectiveness of the proposed method for a variety of popular visual recognition tasks, including image classification and two important dense prediction tasks: object detection and panoptic segmentation. Particularly, BatchFormerV2 consistently improves current DETR-based detection methods (e.g., DETR, Deformable-DETR, Conditional DETR, and SMCA) by over 1.3%. Code will be made publicly available.