 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
#PraCegoVer: A Large Dataset for Image Captioning in Portuguese
Mar 21, 2021
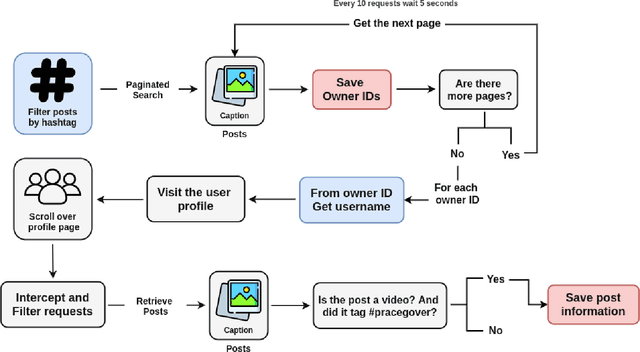


Automatically describing images using natural sentences is an important task to support visually impaired people's inclusion onto the Internet. It is still a big challenge that requires understanding the relation of the objects present in the image and their attributes and actions they are involved in. Then, visual interpretation methods are needed, but linguistic models are also necessary to verbally describe the semantic relations. This problem is known as Image Captioning. Although many datasets were proposed in the literature, the majority contains only English captions, whereas datasets with captions described in other languages are scarce. Recently, a movement called PraCegoVer arose on the Internet, stimulating users from social media to publish images, tag #PraCegoVer and add a short description of their content. Thus, inspired by this movement, we have proposed the #PraCegoVer, a multi-modal dataset with Portuguese captions based on posts from Instagram. It is the first large dataset for image captioning in Portuguese with freely annotated images. Further, the captions in our dataset bring additional challenges to the problem: first, in contrast to popular datasets such as MS COCO Captions, #PraCegoVer has only one reference to each image; also, both mean and variance of our reference sentence length are significantly greater than those in the MS COCO Captions. These two characteristics contribute to making our dataset interesting due to the linguistic aspect and the challenges that it introduces to the image captioning problem. We publicly-share the dataset at https://github.com/gabrielsantosrv/PraCegoVer.
Mixture GAN For Modulation Classification Resiliency Against Adversarial Attacks
May 29, 2022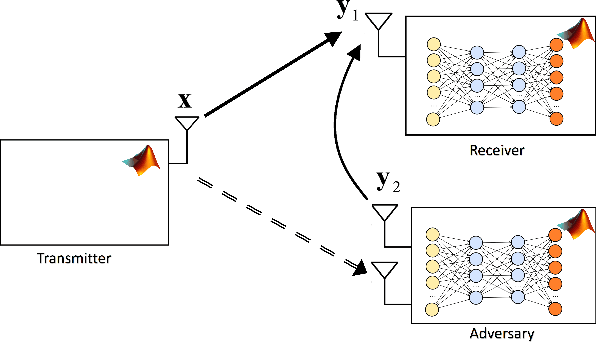
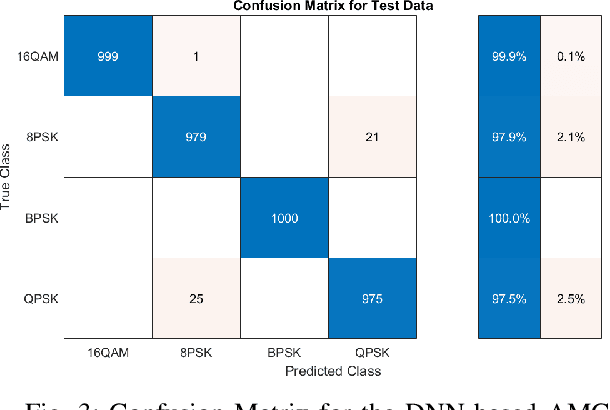
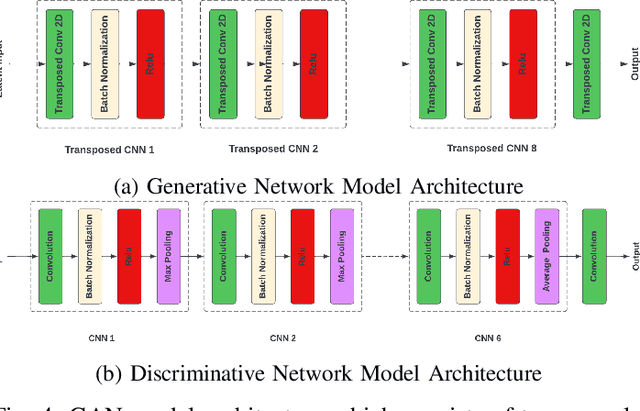
Automatic modulation classification (AMC) using the Deep Neural Network (DNN) approach outperforms the traditional classification techniques, even in the presence of challenging wireless channel environments. However, the adversarial attacks cause the loss of accuracy for the DNN-based AMC by injecting a well-designed perturbation to the wireless channels. In this paper, we propose a novel generative adversarial network (GAN)-based countermeasure approach to safeguard the DNN-based AMC systems against adversarial attack examples. GAN-based aims to eliminate the adversarial attack examples before feeding to the DNN-based classifier. Specifically, we have shown the resiliency of our proposed defense GAN against the Fast-Gradient Sign method (FGSM) algorithm as one of the most potent kinds of attack algorithms to craft the perturbed signals. The existing defense-GAN has been designed for image classification and does not work in our case where the above-mentioned communication system is considered. Thus, our proposed countermeasure approach deploys GANs with a mixture of generators to overcome the mode collapsing problem in a typical GAN facing radio signal classification problem. Simulation results show the effectiveness of our proposed defense GAN so that it could enhance the accuracy of the DNN-based AMC under adversarial attacks to 81%, approximately.
Cross-view and Cross-domain Underwater Localization based on Optical Aerial and Acoustic Underwater Images
Feb 16, 2022
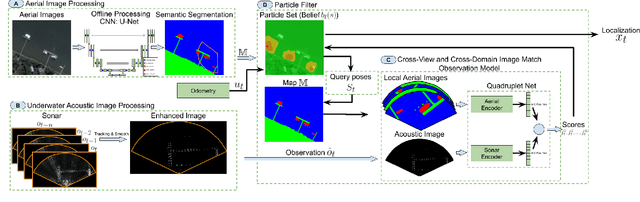

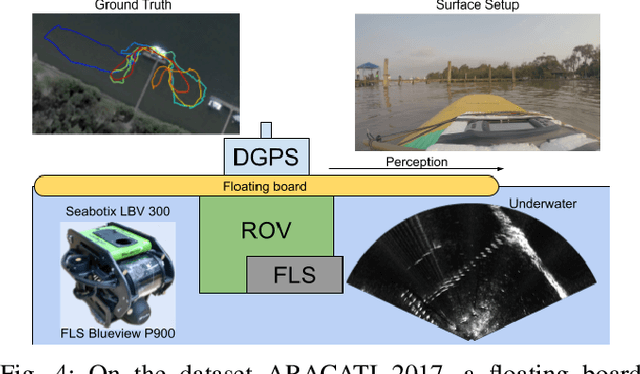
Cross-view image matches have been widely explored on terrestrial image localization using aerial images from drones or satellites. This study expands the cross-view image match idea and proposes a cross-domain and cross-view localization framework. The method identifies the correlation between color aerial images and underwater acoustic images to improve the localization of underwater vehicles that travel in partially structured environments such as harbors and marinas. The approach is validated on a real dataset acquired by an underwater vehicle in a marina. The results show an improvement in the localization when compared to the dead reckoning of the vehicle.
FV-UPatches: Enhancing Universality in Finger Vein Recognition
Jun 02, 2022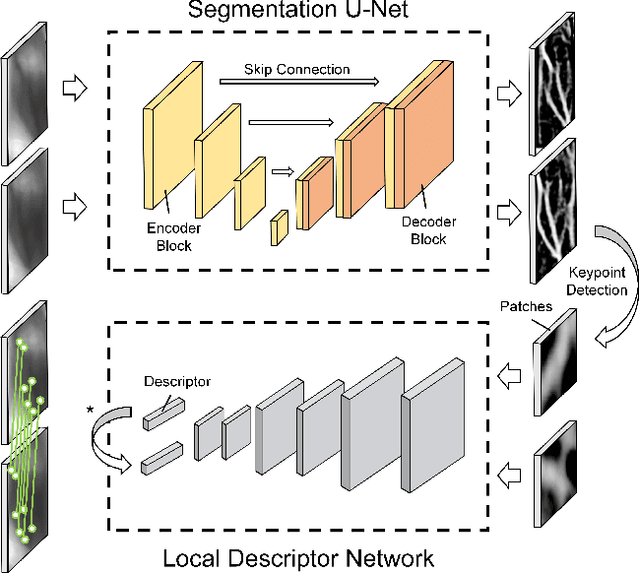


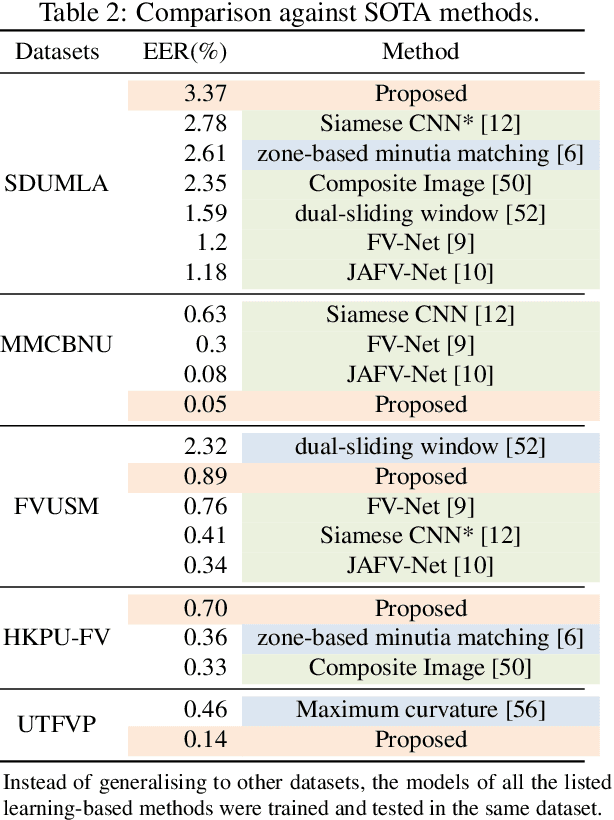
Many deep learning-based models have been introduced in finger vein recognition in recent years. These solutions, however, suffer from data dependency and are difficult to achieve model generalization. To address this problem, we are inspired by the idea of domain adaptation and propose a universal learning-based framework, which achieves generalization while training with limited data. To reduce differences between data distributions, a compressed U-Net is introduced as a domain mapper to map the raw region of interest image onto a target domain. The concentrated target domain is a unified feature space for the subsequent matching, in which a local descriptor model SOSNet is employed to embed patches into descriptors measuring the similarity of matching pairs. In the proposed framework, the domain mapper is an approximation to a specific extraction function thus the training is only a one-time effort with limited data. Moreover, the local descriptor model can be trained to be representative enough based on a public dataset of non-finger-vein images. The whole pipeline enables the framework to be well generalized, making it possible to enhance universality and helps to reduce costs of data collection, tuning and retraining. The comparable experimental results to state-of-the-art (SOTA) performance in five public datasets prove the effectiveness of the proposed framework. Furthermore, the framework shows application potential in other vein-based biometric recognition as well.
Reflection and Rotation Symmetry Detection via Equivariant Learning
Mar 31, 2022
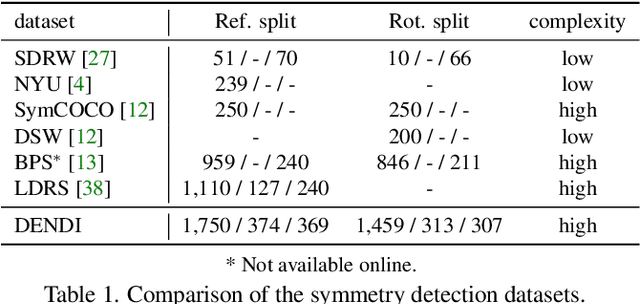
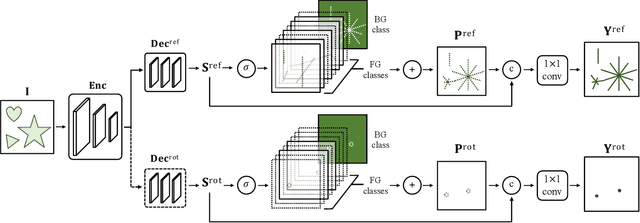
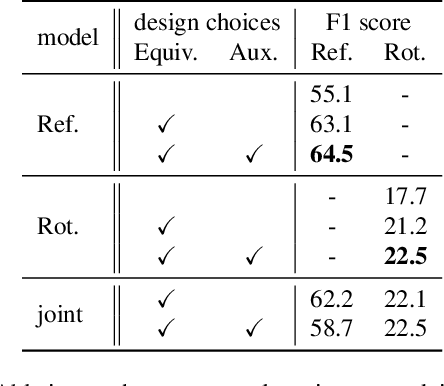
The inherent challenge of detecting symmetries stems from arbitrary orientations of symmetry patterns; a reflection symmetry mirrors itself against an axis with a specific orientation while a rotation symmetry matches its rotated copy with a specific orientation. Discovering such symmetry patterns from an image thus benefits from an equivariant feature representation, which varies consistently with reflection and rotation of the image. In this work, we introduce a group-equivariant convolutional network for symmetry detection, dubbed EquiSym, which leverages equivariant feature maps with respect to a dihedral group of reflection and rotation. The proposed network is built end-to-end with dihedrally-equivariant layers and trained to output a spatial map for reflection axes or rotation centers. We also present a new dataset, DENse and DIverse symmetry (DENDI), which mitigates limitations of existing benchmarks for reflection and rotation symmetry detection. Experiments show that our method achieves the state of the arts in symmetry detection on LDRS and DENDI datasets.
Intrinsic Image Decomposition using Paradigms
Nov 20, 2020
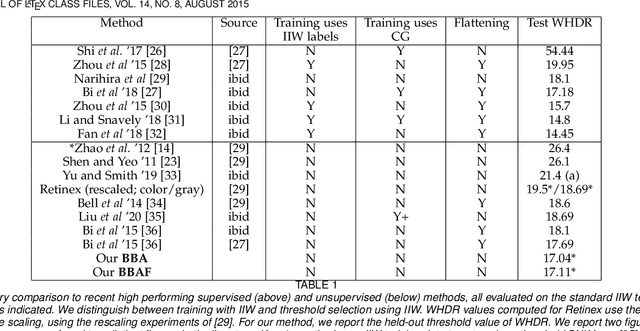


Intrinsic image decomposition is the classical task of mapping image to albedo. The WHDR dataset allows methods to be evaluated by comparing predictions to human judgements ("lighter", "same as", "darker"). The best modern intrinsic image methods learn a map from image to albedo using rendered models and human judgements. This is convenient for practical methods, but cannot explain how a visual agent without geometric, surface and illumination models and a renderer could learn to recover intrinsic images. This paper describes a method that learns intrinsic image decomposition without seeing WHDR annotations, rendered data, or ground truth data. The method relies on paradigms - fake albedos and fake shading fields - together with a novel smoothing procedure that ensures good behavior at short scales on real images. Long scale error is controlled by averaging. Our method achieves WHDR scores competitive with those of strong recent methods allowed to see training WHDR annotations, rendered data, and ground truth data. Because our method is unsupervised, we can compute estimates of the test/train variance of WHDR scores; these are quite large, and it is unsafe to rely small differences in reported WHDR.
Adversarial collision attacks on image hashing functions
Nov 18, 2020
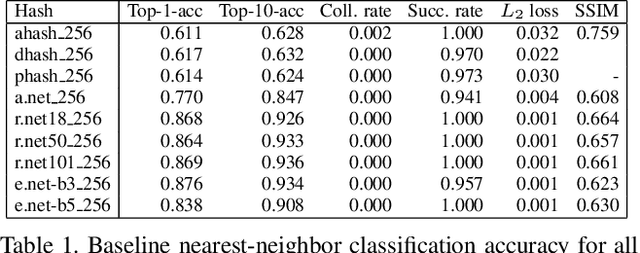
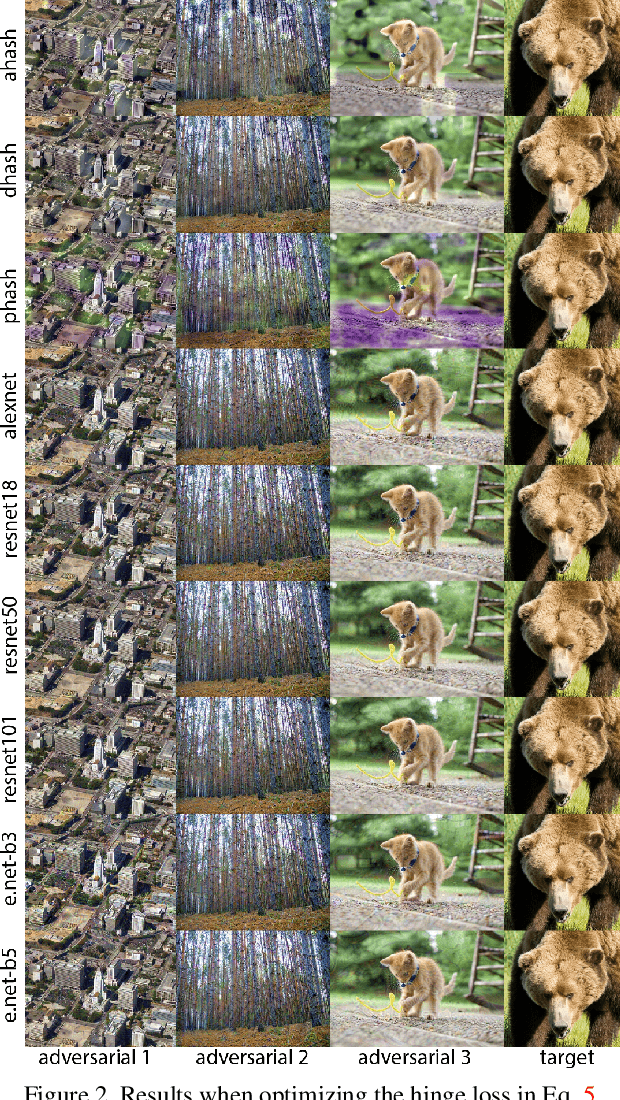
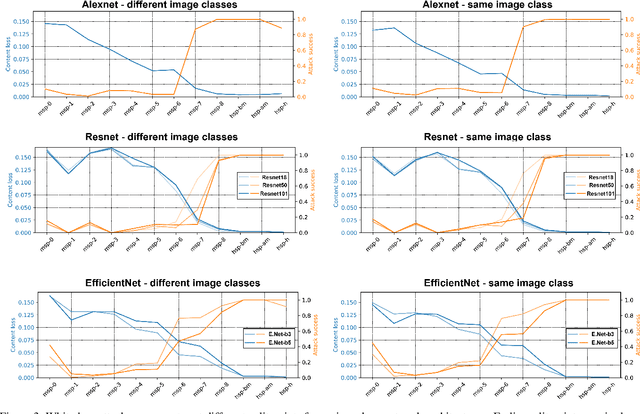
Hashing images with a perceptual algorithm is a common approach to solving duplicate image detection problems. However, perceptual image hashing algorithms are differentiable, and are thus vulnerable to gradient-based adversarial attacks. We demonstrate that not only is it possible to modify an image to produce an unrelated hash, but an exact image hash collision between a source and target image can be produced via minuscule adversarial perturbations. In a white box setting, these collisions can be replicated across nearly every image pair and hash type (including both deep and non-learned hashes). Furthermore, by attacking points other than the output of a hashing function, an attacker can avoid having to know the details of a particular algorithm, resulting in collisions that transfer across different hash sizes or model architectures. Using these techniques, an adversary can poison the image lookup table of a duplicate image detection service, resulting in undefined or unwanted behavior. Finally, we offer several potential mitigations to gradient-based image hash attacks.
A Survey on Video Action Recognition in Sports: Datasets, Methods and Applications
Jun 02, 2022
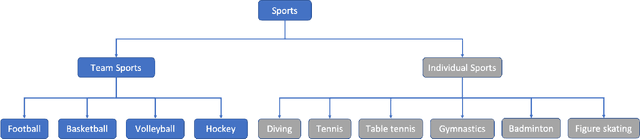
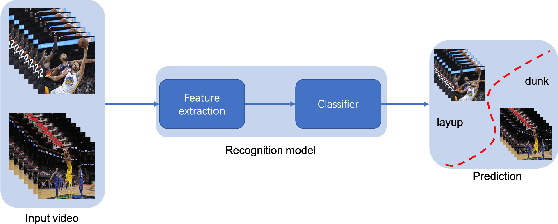
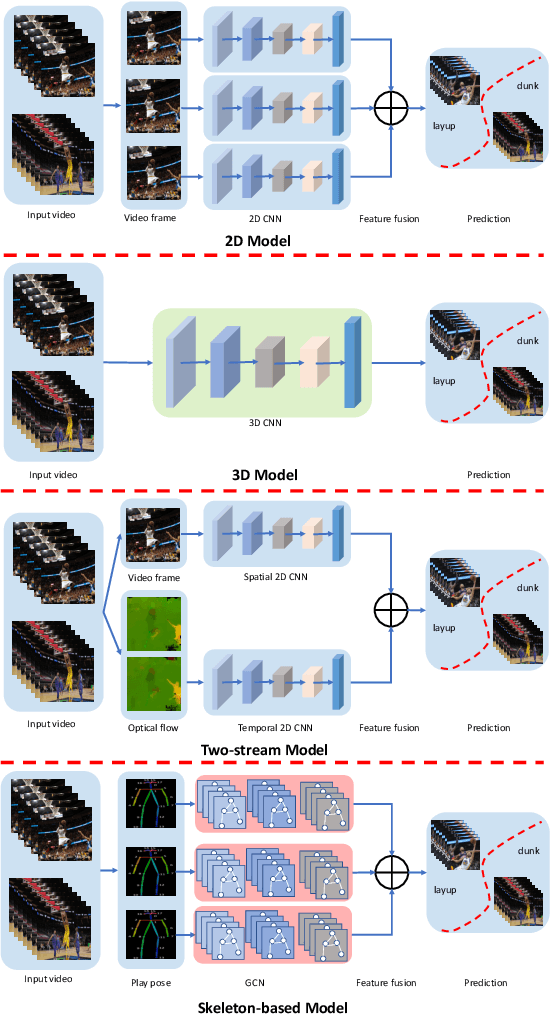
To understand human behaviors, action recognition based on videos is a common approach. Compared with image-based action recognition, videos provide much more information. Reducing the ambiguity of actions and in the last decade, many works focused on datasets, novel models and learning approaches have improved video action recognition to a higher level. However, there are challenges and unsolved problems, in particular in sports analytics where data collection and labeling are more sophisticated, requiring sport professionals to annotate data. In addition, the actions could be extremely fast and it becomes difficult to recognize them. Moreover, in team sports like football and basketball, one action could involve multiple players, and to correctly recognize them, we need to analyse all players, which is relatively complicated. In this paper, we present a survey on video action recognition for sports analytics. We introduce more than ten types of sports, including team sports, such as football, basketball, volleyball, hockey and individual sports, such as figure skating, gymnastics, table tennis, tennis, diving and badminton. Then we compare numerous existing frameworks for sports analysis to present status quo of video action recognition in both team sports and individual sports. Finally, we discuss the challenges and unsolved problems in this area and to facilitate sports analytics, we develop a toolbox using PaddlePaddle, which supports football, basketball, table tennis and figure skating action recognition.
Decision boundaries and convex hulls in the feature space that deep learning functions learn from images
Feb 17, 2022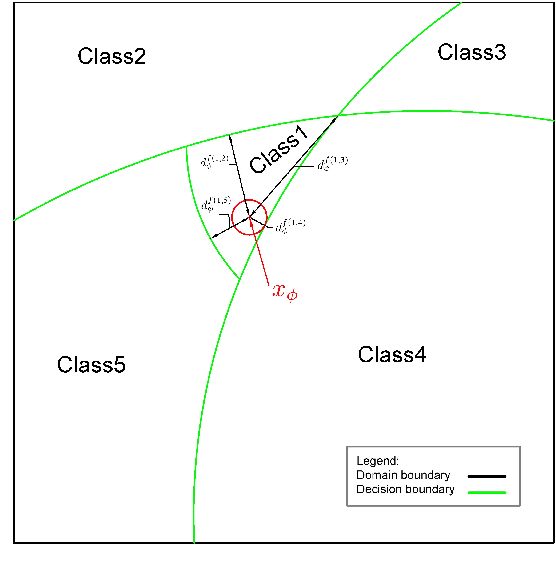
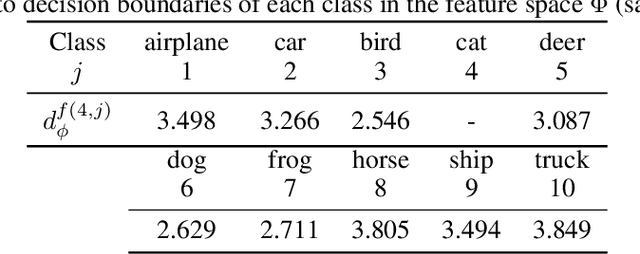
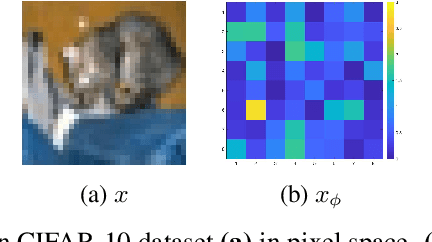
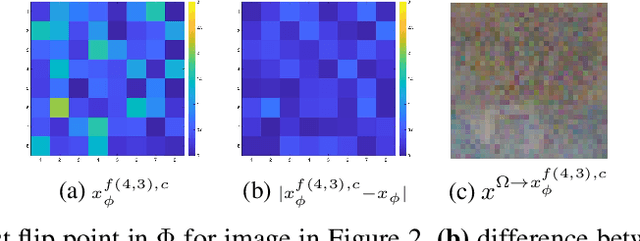
The success of deep neural networks in image classification and learning can be partly attributed to the features they extract from images. It is often speculated about the properties of a low-dimensional manifold that models extract and learn from images. However, there is not sufficient understanding about this low-dimensional space based on theory or empirical evidence. For image classification models, their last hidden layer is the one where images of each class is separated from other classes and it also has the least number of features. Here, we develop methods and formulations to study that feature space for any model. We study the partitioning of the domain in feature space, identify regions guaranteed to have certain classifications, and investigate its implications for the pixel space. We observe that geometric arrangements of decision boundaries in feature space is significantly different compared to pixel space, providing insights about adversarial vulnerabilities, image morphing, extrapolation, ambiguity in classification, and the mathematical understanding of image classification models.
Self-Organized Variational Autoencoders (Self-VAE) for Learned Image Compression
May 28, 2021
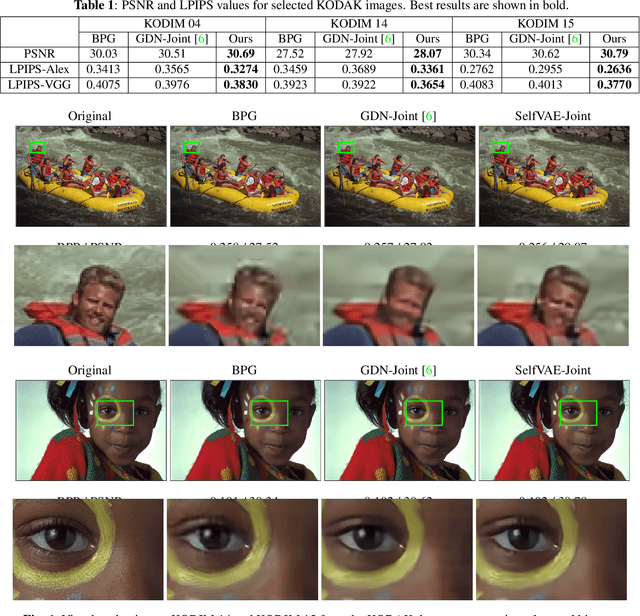
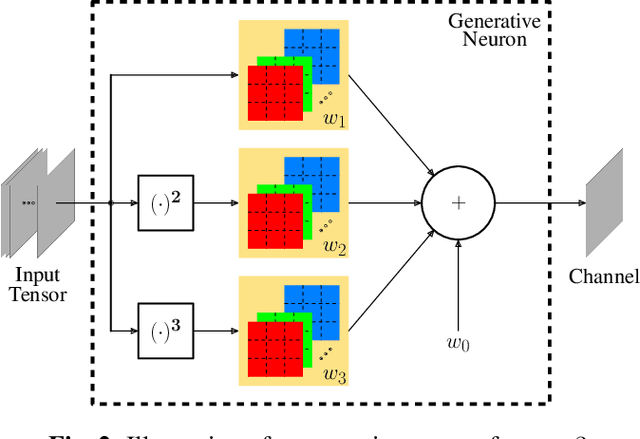
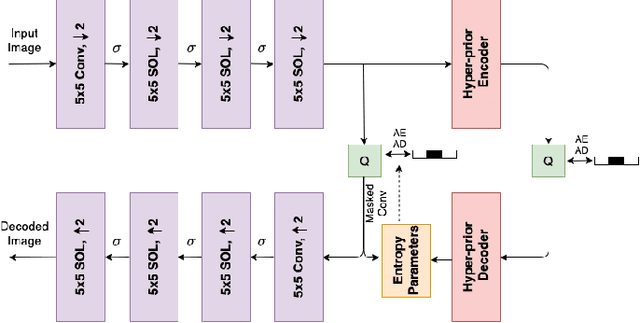
In end-to-end optimized learned image compression, it is standard practice to use a convolutional variational autoencoder with generalized divisive normalization (GDN) to transform images into a latent space. Recently, Operational Neural Networks (ONNs) that learn the best non-linearity from a set of alternatives, and their self-organized variants, Self-ONNs, that approximate any non-linearity via Taylor series have been proposed to address the limitations of convolutional layers and a fixed nonlinear activation. In this paper, we propose to replace the convolutional and GDN layers in the variational autoencoder with self-organized operational layers, and propose a novel self-organized variational autoencoder (Self-VAE) architecture that benefits from stronger non-linearity. The experimental results demonstrate that the proposed Self-VAE yields improvements in both rate-distortion performance and perceptual image quality.