 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GPU Acceleration for Synthetic Aperture Sonar Image Reconstruction
Jan 14, 2021
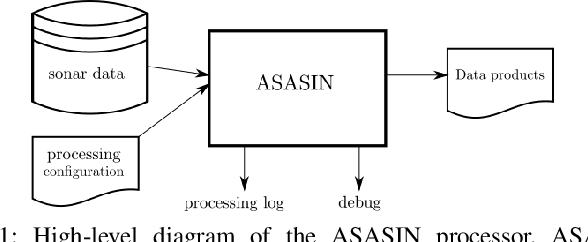
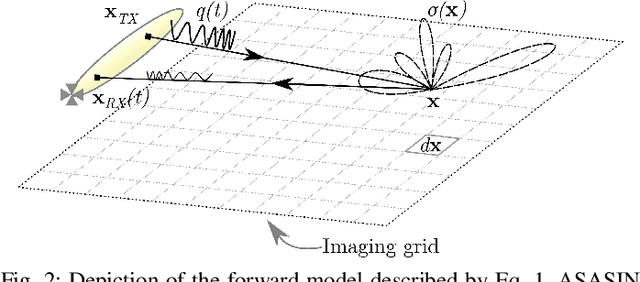
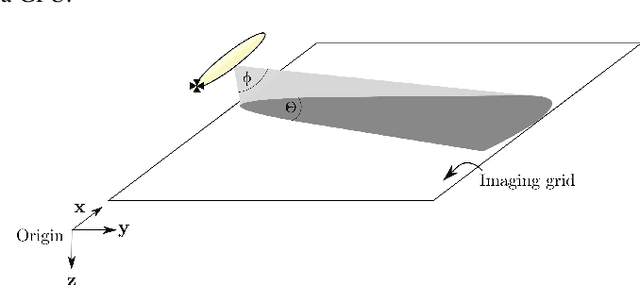
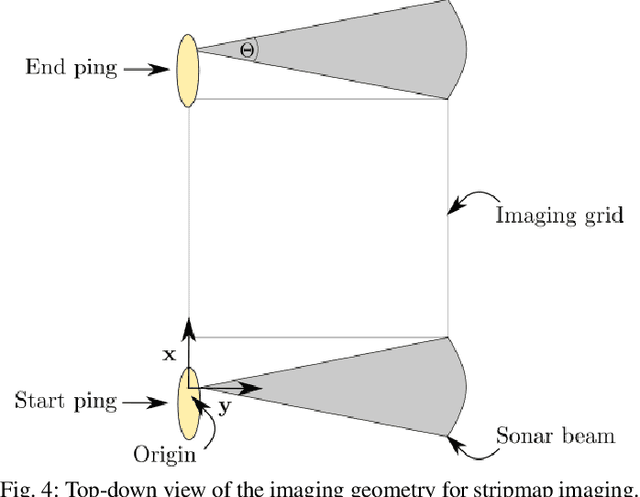
Synthetic aperture sonar (SAS) image reconstruction, or beamforming as it is often referred to within the SAS community, comprises a class of computationally intensive algorithms for creating coherent high-resolution imagery from successive spatially varying sonar pings. Image reconstruction is usually performed topside because of the large compute burden necessitated by the procedure. Historically, image reconstruction required significant assumptions in order to produce real-time imagery within an unmanned underwater vehicle's (UUV's) size, weight, and power (SWaP) constraints. However, these assumptions result in reduced image quality. In this work, we describe ASASIN, the Advanced Synthetic Aperture Sonar Imagining eNgine. ASASIN is a time domain backprojection image reconstruction suite utilizing graphics processing units (GPUs) allowing real-time operation on UUVs without sacrificing image quality. We describe several speedups employed in ASASIN allowing us to achieve this objective. Furthermore, ASASIN's signal processing chain is capable of producing 2D and 3D SAS imagery as we will demonstrate. Finally, we measure ASASIN's performance on a variety of GPUs and create a model capable of predicting performance. We demonstrate our model's usefulness in predicting run-time performance on desktop and embedded GPU hardware.
Efficient Automated Deep Learning for Time Series Forecasting
May 13, 2022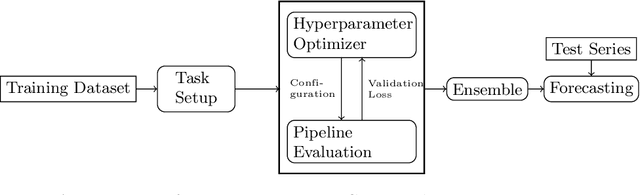
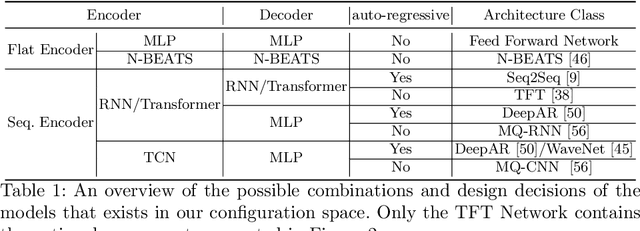
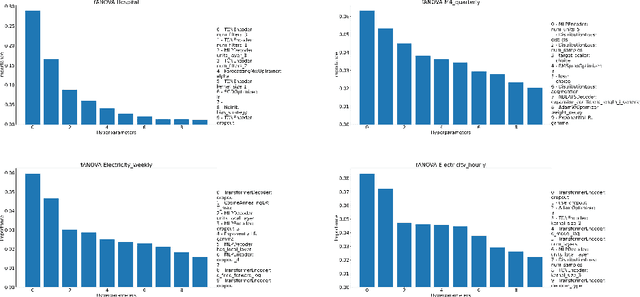
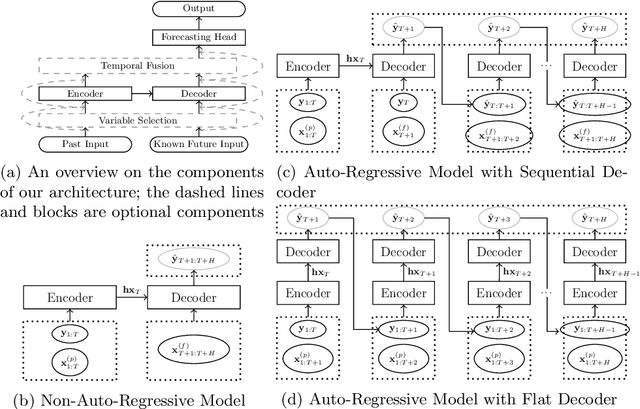
Recent years have witnessed tremendously improved efficiency of Automated Machine Learning (AutoML), especially Automated Deep Learning (AutoDL) systems, but recent work focuses on tabular, image, or NLP tasks. So far, little attention has been paid to general AutoDL frameworks for time series forecasting, despite the enormous success in applying different novel architectures to such tasks. In this paper, we propose an efficient approach for the joint optimization of neural architecture and hyperparameters of the entire data processing pipeline for time series forecasting. In contrast to common NAS search spaces, we designed a novel neural architecture search space covering various state-of-the-art architectures, allowing for an efficient macro-search over different DL approaches. To efficiently search in such a large configuration space, we use Bayesian optimization with multi-fidelity optimization. We empirically study several different budget types enabling efficient multi-fidelity optimization on different forecasting datasets. Furthermore, we compared our resulting system, dubbed Auto-PyTorch-TS, against several established baselines and show that it significantly outperforms all of them across several datasets.
WKGM: Weight-K-space Generative Model for Parallel Imaging Reconstruction
May 08, 2022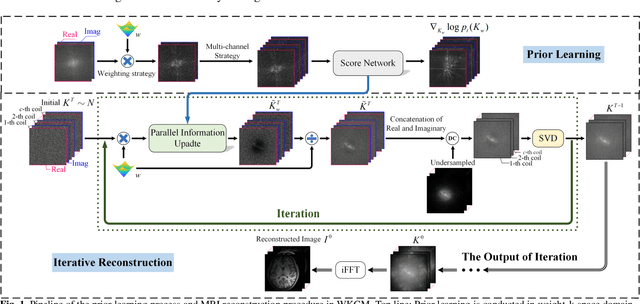
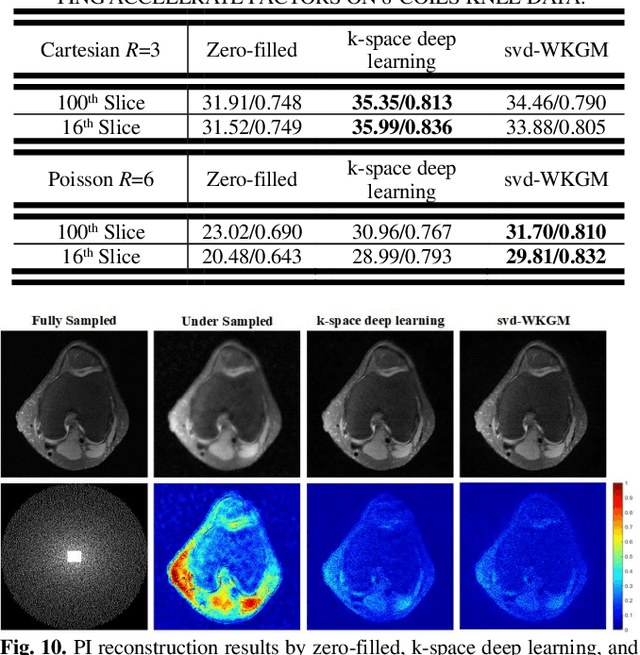
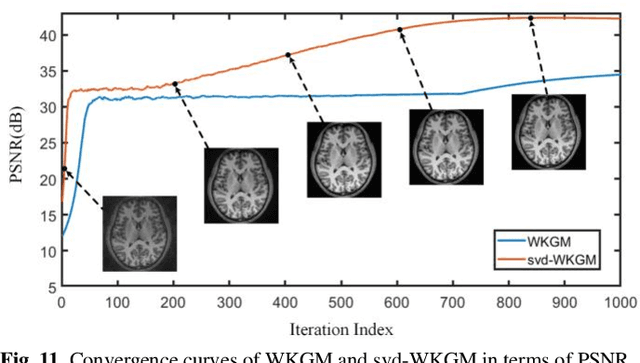
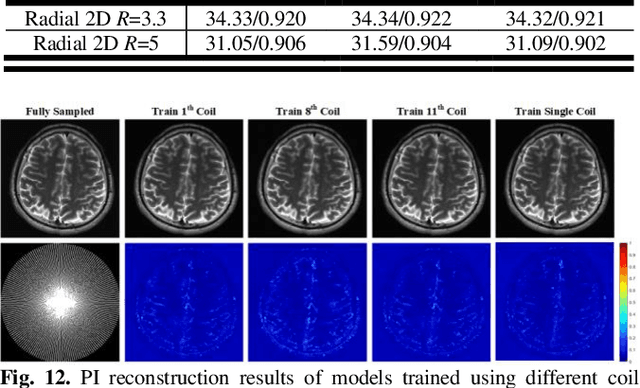
Parallel Imaging (PI) is one of the most im-portant and successful developments in accelerating magnetic resonance imaging (MRI). Recently deep learning PI has emerged as an effective technique to accelerate MRI. Nevertheless, most approaches have so far been based image domain. In this work, we propose to explore the k-space domain via robust generative modeling for flexible PI reconstruction, coined weight-k-space generative model (WKGM). Specifically, WKGM is a generalized k-space domain model, where the k-space weighting technology and high-dimensional space strategy are efficiently incorporated for score-based generative model training, resulting in good and robust reconstruction. In addition, WKGM is flexible and thus can synergistically combine various traditional k-space PI models, generating learning-based priors to produce high-fidelity reconstructions. Experimental results on datasets with varying sampling patterns and acceleration factors demonstrate that WKGM can attain state-of-the-art reconstruction results under the well-learned k-space generative prior.
Behavioral Economics Approach to Interpretable Deep Image Classification. Rationally Inattentive Utility Maximization Explains Deep Image Classification
Feb 16, 2021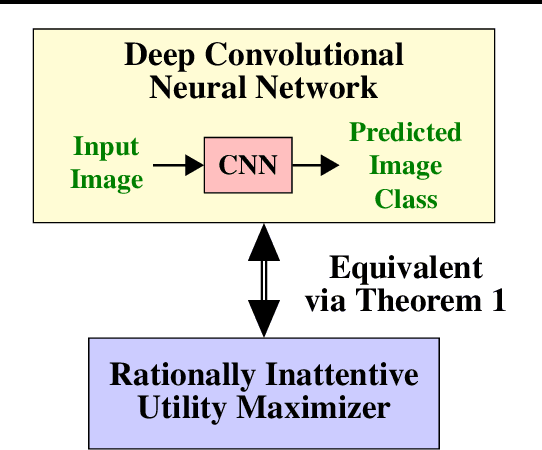

Are deep convolutional neural networks (CNNs) for image classification consistent with utility maximization behavior with information acquisition costs? This paper demonstrates the remarkable result that a deep CNN behaves equivalently (in terms of necessary and sufficient conditions) to a rationally inattentive utility maximizer, a model extensively used in behavioral economics to explain human decision making. This implies that a deep CNN has a parsimonious representation in terms of simple intuitive human-like decision parameters, namely, a utility function and an information acquisition cost. Also the reconstructed utility function that rationalizes the decisions of the deep CNNs, yields a useful preference order amongst the image classes (hypotheses).
Image Translation via Fine-grained Knowledge Transfer
Dec 21, 2020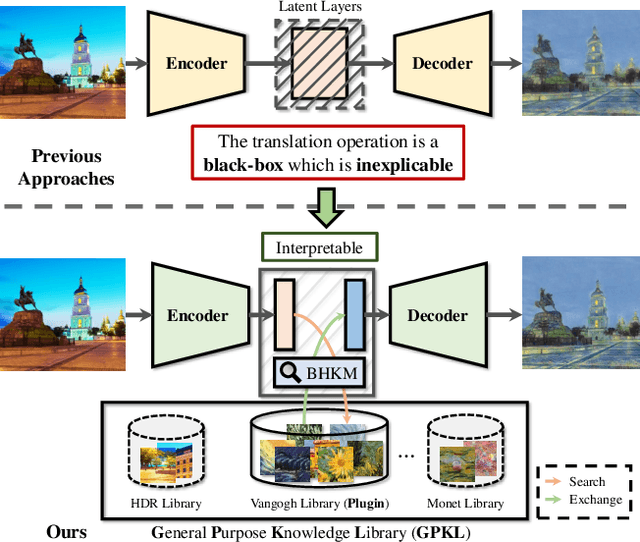



Prevailing image-translation frameworks mostly seek to process images via the end-to-end style, which has achieved convincing results. Nonetheless, these methods lack interpretability and are not scalable on different image-translation tasks (e.g., style transfer, HDR, etc.). In this paper, we propose an interpretable knowledge-based image-translation framework, which realizes the image-translation through knowledge retrieval and transfer. In details, the framework constructs a plug-and-play and model-agnostic general purpose knowledge library, remembering task-specific styles, tones, texture patterns, etc. Furthermore, we present a fast ANN searching approach, Bandpass Hierarchical K-Means (BHKM), to cope with the difficulty of searching in the enormous knowledge library. Extensive experiments well demonstrate the effectiveness and feasibility of our framework in different image-translation tasks. In particular, backtracking experiments verify the interpretability of our method. Our code soon will be available at https://github.com/AceSix/Knowledge_Transfer.
Location-free Human Pose Estimation
May 25, 2022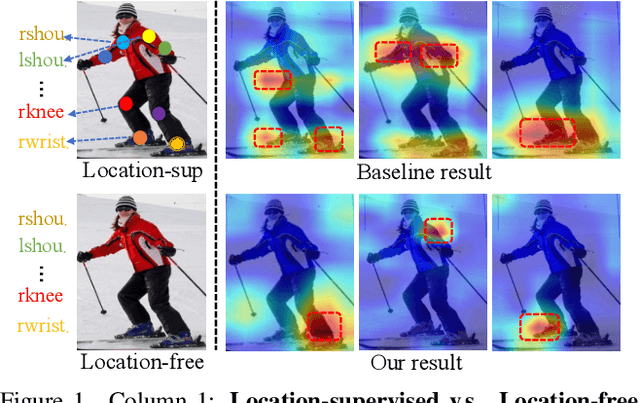
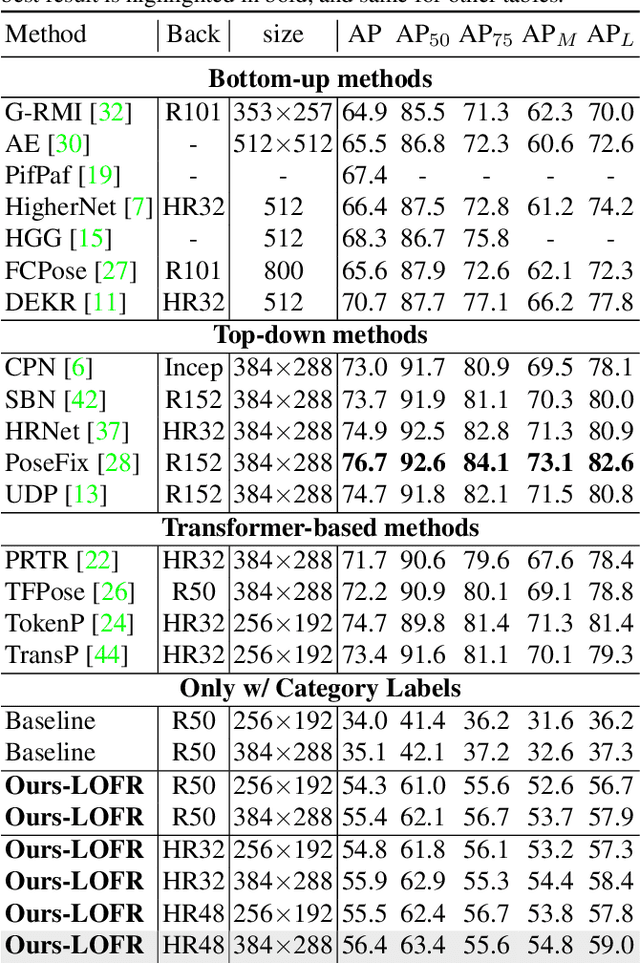
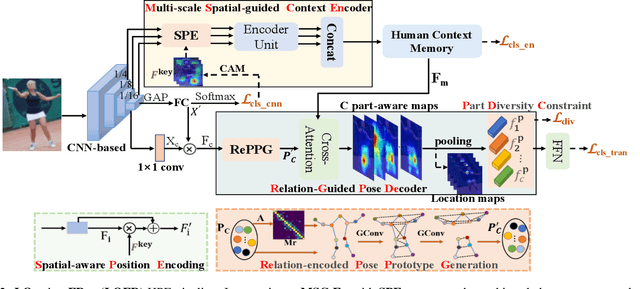
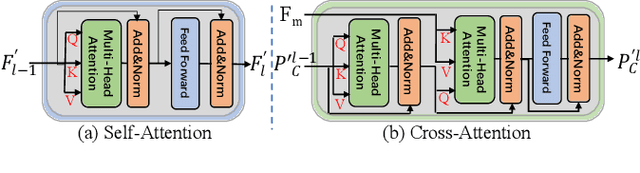
Human pose estimation (HPE) usually requires large-scale training data to reach high performance. However, it is rather time-consuming to collect high-quality and fine-grained annotations for human body. To alleviate this issue, we revisit HPE and propose a location-free framework without supervision of keypoint locations. We reformulate the regression-based HPE from the perspective of classification. Inspired by the CAM-based weakly-supervised object localization, we observe that the coarse keypoint locations can be acquired through the part-aware CAMs but unsatisfactory due to the gap between the fine-grained HPE and the object-level localization. To this end, we propose a customized transformer framework to mine the fine-grained representation of human context, equipped with the structural relation to capture subtle differences among keypoints. Concretely, we design a Multi-scale Spatial-guided Context Encoder to fully capture the global human context while focusing on the part-aware regions and a Relation-encoded Pose Prototype Generation module to encode the structural relations. All these works together for strengthening the weak supervision from image-level category labels on locations. Our model achieves competitive performance on three datasets when only supervised at a category-level and importantly, it can achieve comparable results with fully-supervised methods with only 25\% location labels on MS-COCO and MPII.
Velocity continuation with Fourier neural operators for accelerated uncertainty quantification
Mar 27, 2022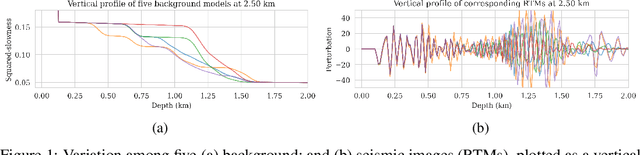
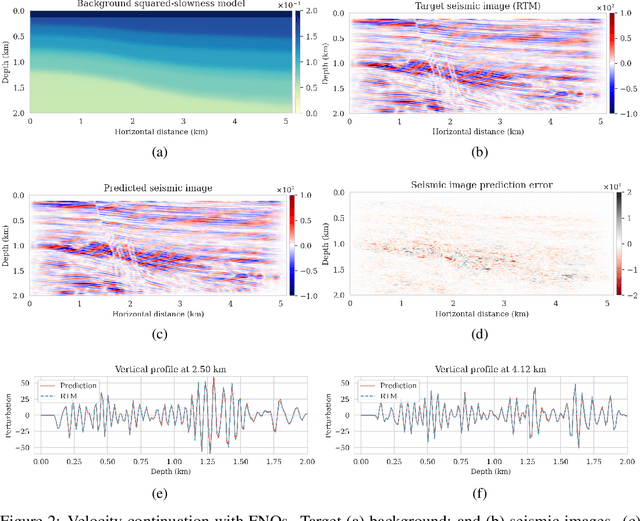
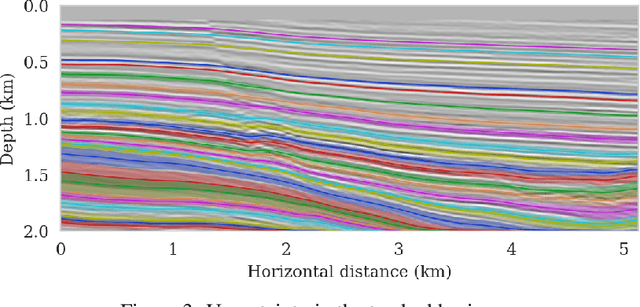
Seismic imaging is an ill-posed inverse problem that is challenged by noisy data and modeling inaccuracies -- due to errors in the background squared-slowness model. Uncertainty quantification is essential for determining how variability in the background models affects seismic imaging. Due to the costs associated with the forward Born modeling operator as well as the high dimensionality of seismic images, quantification of uncertainty is computationally expensive. As such, the main contribution of this work is a survey-specific Fourier neural operator surrogate to velocity continuation that maps seismic images associated with one background model to another virtually for free. While being trained with only 200 background and seismic image pairs, this surrogate is able to accurately predict seismic images associated with new background models, thus accelerating seismic imaging uncertainty quantification. We support our method with a realistic data example in which we quantify seismic imaging uncertainties using a Fourier neural operator surrogate, illustrating how variations in background models affect the position of reflectors in a seismic image.
On the Exploitation of Deepfake Model Recognition
Apr 09, 2022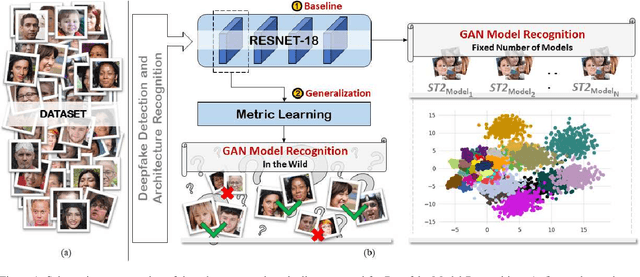


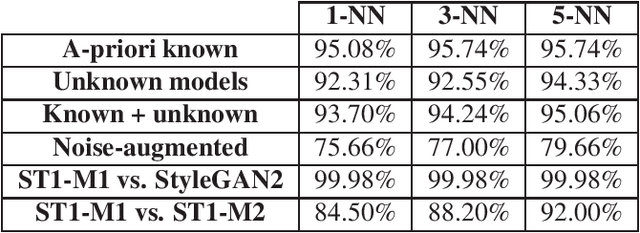
Despite recent advances in Generative Adversarial Networks (GANs), with special focus to the Deepfake phenomenon there is no a clear understanding neither in terms of explainability nor of recognition of the involved models. In particular, the recognition of a specific GAN model that generated the deepfake image compared to many other possible models created by the same generative architecture (e.g. StyleGAN) is a task not yet completely addressed in the state-of-the-art. In this work, a robust processing pipeline to evaluate the possibility to point-out analytic fingerprints for Deepfake model recognition is presented. After exploiting the latent space of 50 slightly different models through an in-depth analysis on the generated images, a proper encoder was trained to discriminate among these models obtaining a classification accuracy of over 96%. Once demonstrated the possibility to discriminate extremely similar images, a dedicated metric exploiting the insights discovered in the latent space was introduced. By achieving a final accuracy of more than 94% for the Model Recognition task on images generated by models not employed in the training phase, this study takes an important step in countering the Deepfake phenomenon introducing a sort of signature in some sense similar to those employed in the multimedia forensics field (e.g. for camera source identification task, image ballistics task, etc).
Semi-Supervised Deep Ensembles for Blind Image Quality Assessment
Jun 29, 2021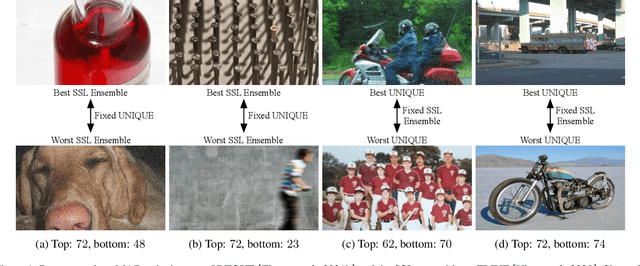
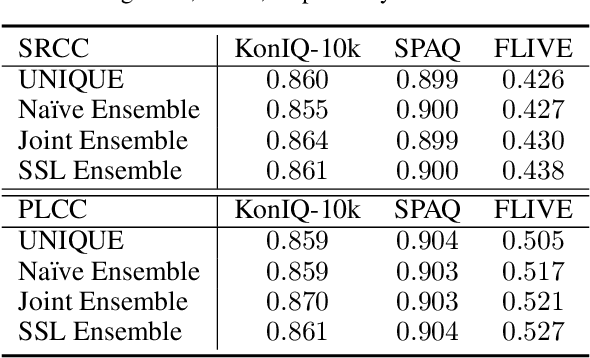
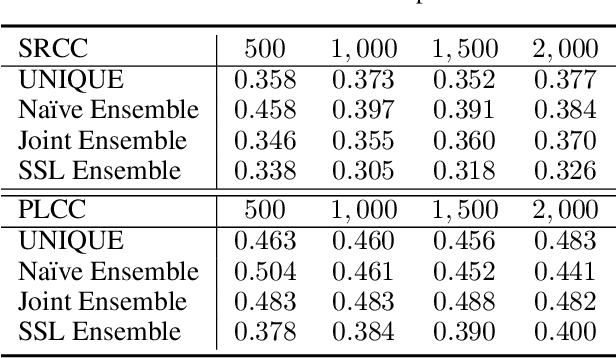
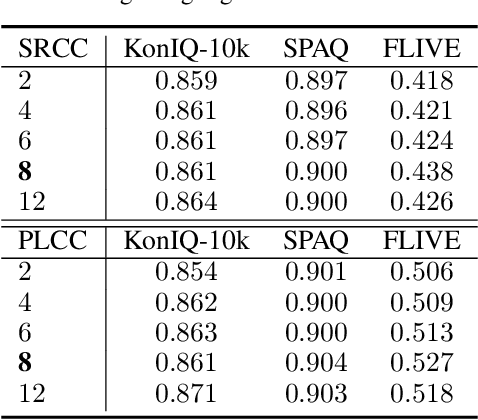
Ensemble methods are generally regarded to be better than a single model if the base learners are deemed to be "accurate" and "diverse." Here we investigate a semi-supervised ensemble learning strategy to produce generalizable blind image quality assessment models. We train a multi-head convolutional network for quality prediction by maximizing the accuracy of the ensemble (as well as the base learners) on labeled data, and the disagreement (i.e., diversity) among them on unlabeled data, both implemented by the fidelity loss. We conduct extensive experiments to demonstrate the advantages of employing unlabeled data for BIQA, especially in model generalization and failure identification.
Scene Clustering Based Pseudo-labeling Strategy for Multi-modal Aerial View Object Classification
May 13, 2022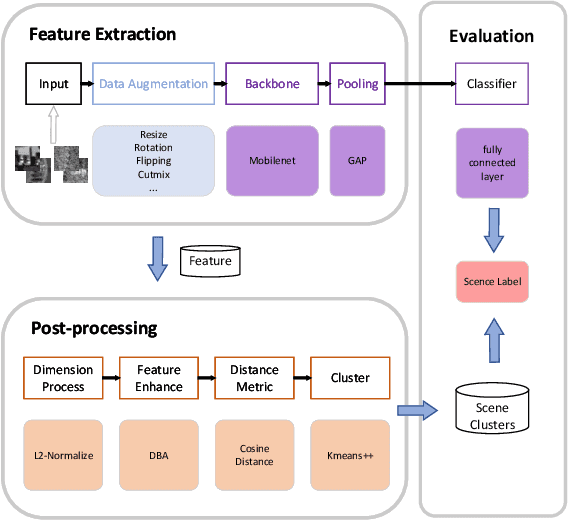
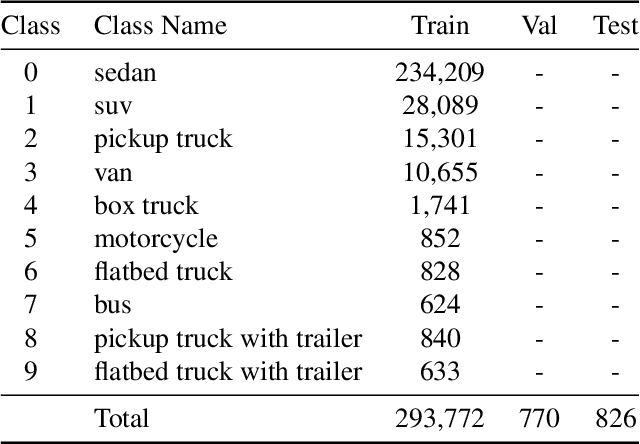
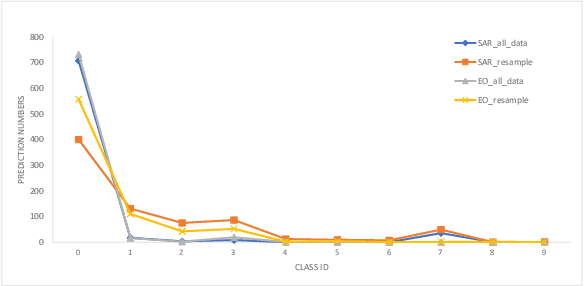
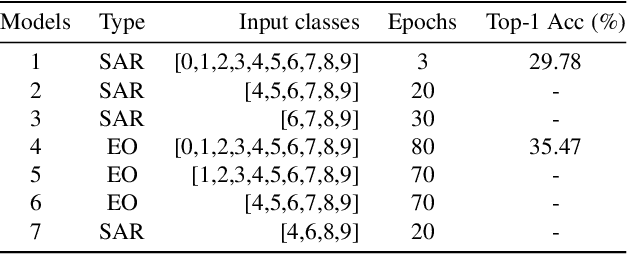
Multi-modal aerial view object classification (MAVOC) in Automatic target recognition (ATR), although an important and challenging problem, has been under studied. This paper firstly finds that fine-grained data, class imbalance and various shooting conditions preclude the representational ability of general image classification. Moreover, the MAVOC dataset has scene aggregation characteristics. By exploiting these properties, we propose Scene Clustering Based Pseudo-labeling Strategy (SCP-Label), a simple yet effective method to employ in post-processing. The SCP-Label brings greater accuracy by assigning the same label to objects within the same scene while also mitigating bias and confusion with model ensembles. Its performance surpasses the official baseline by a large margin of +20.57% Accuracy on Track 1 (SAR), and +31.86% Accuracy on Track 2 (SAR+EO), demonstrating the potential of SCP-Label as post-processing. Finally, we win the championship both on Track1 and Track2 in the CVPR 2022 Perception Beyond the Visible Spectrum (PBVS) Workshop MAVOC Challenge. Our code is available at https://github.com/HowieChangchn/SCP-Label.