 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Good Image Generator Is What You Need for High-Resolution Video Synthesis
Apr 30, 2021
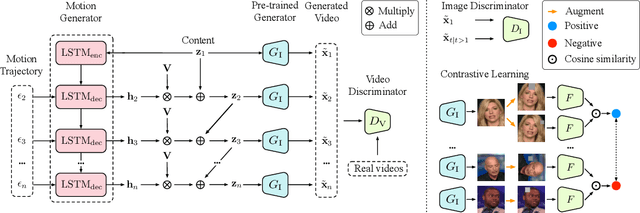



Image and video synthesis are closely related areas aiming at generating content from noise. While rapid progress has been demonstrated in improving image-based models to handle large resolutions, high-quality renderings, and wide variations in image content, achieving comparable video generation results remains problematic. We present a framework that leverages contemporary image generators to render high-resolution videos. We frame the video synthesis problem as discovering a trajectory in the latent space of a pre-trained and fixed image generator. Not only does such a framework render high-resolution videos, but it also is an order of magnitude more computationally efficient. We introduce a motion generator that discovers the desired trajectory, in which content and motion are disentangled. With such a representation, our framework allows for a broad range of applications, including content and motion manipulation. Furthermore, we introduce a new task, which we call cross-domain video synthesis, in which the image and motion generators are trained on disjoint datasets belonging to different domains. This allows for generating moving objects for which the desired video data is not available. Extensive experiments on various datasets demonstrate the advantages of our methods over existing video generation techniques. Code will be released at https://github.com/snap-research/MoCoGAN-HD.
TransClaw U-Net: Claw U-Net with Transformers for Medical Image Segmentation
Jul 12, 2021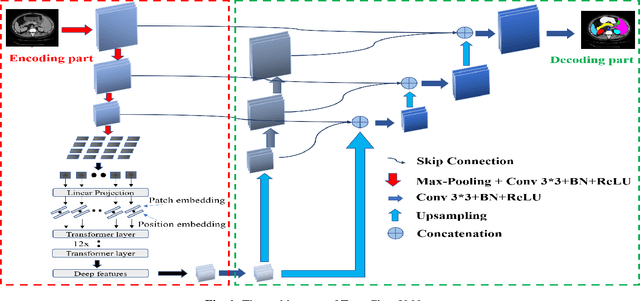
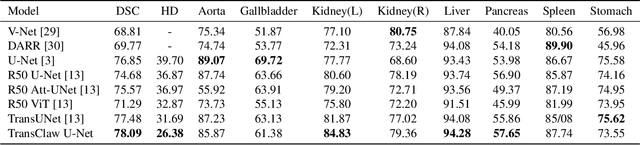
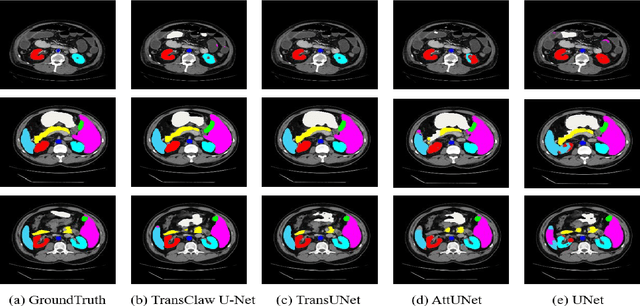

In recent years, computer-aided diagnosis has become an increasingly popular topic. Methods based on convolutional neural networks have achieved good performance in medical image segmentation and classification. Due to the limitations of the convolution operation, the long-term spatial features are often not accurately obtained. Hence, we propose a TransClaw U-Net network structure, which combines the convolution operation with the transformer operation in the encoding part. The convolution part is applied for extracting the shallow spatial features to facilitate the recovery of the image resolution after upsampling. The transformer part is used to encode the patches, and the self-attention mechanism is used to obtain global information between sequences. The decoding part retains the bottom upsampling structure for better detail segmentation performance. The experimental results on Synapse Multi-organ Segmentation Datasets show that the performance of TransClaw U-Net is better than other network structures. The ablation experiments also prove the generalization performance of TransClaw U-Net.
Effects of Auxiliary Knowledge on Continual Learning
Jun 03, 2022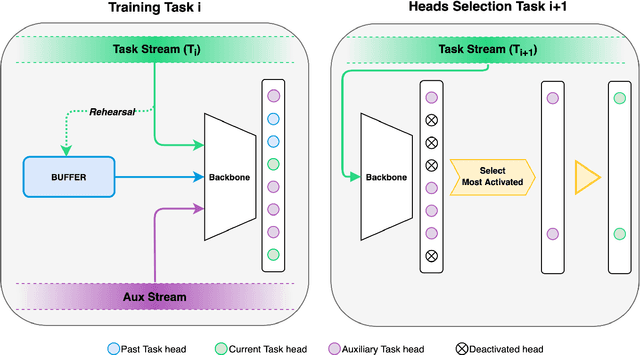
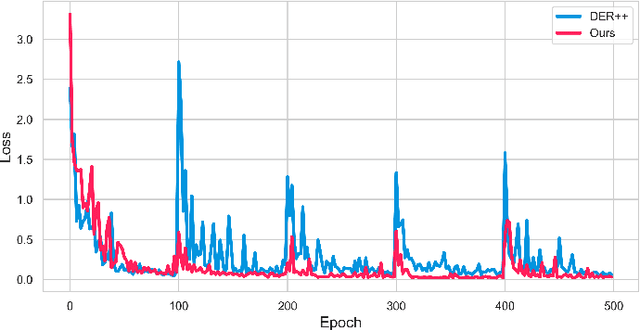
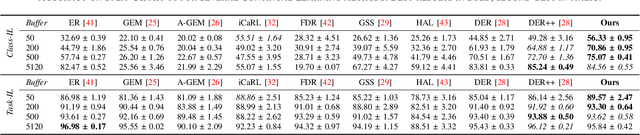
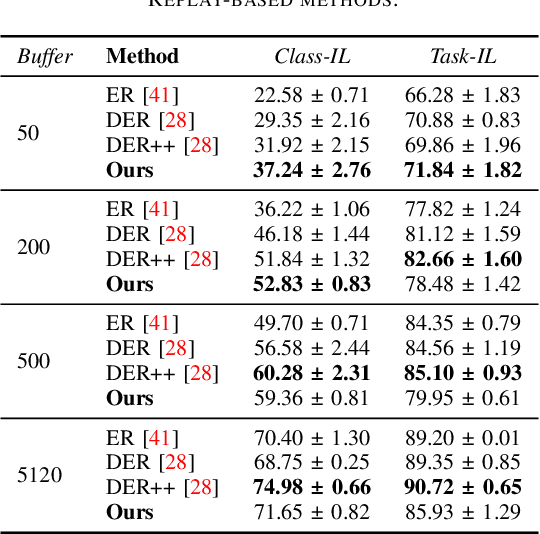
In Continual Learning (CL), a neural network is trained on a stream of data whose distribution changes over time. In this context, the main problem is how to learn new information without forgetting old knowledge (i.e., Catastrophic Forgetting). Most existing CL approaches focus on finding solutions to preserve acquired knowledge, so working on the past of the model. However, we argue that as the model has to continually learn new tasks, it is also important to put focus on the present knowledge that could improve following tasks learning. In this paper we propose a new, simple, CL algorithm that focuses on solving the current task in a way that might facilitate the learning of the next ones. More specifically, our approach combines the main data stream with a secondary, diverse and uncorrelated stream, from which the network can draw auxiliary knowledge. This helps the model from different perspectives, since auxiliary data may contain useful features for the current and the next tasks and incoming task classes can be mapped onto auxiliary classes. Furthermore, the addition of data to the current task is implicitly making the classifier more robust as we are forcing the extraction of more discriminative features. Our method can outperform existing state-of-the-art models on the most common CL Image Classification benchmarks.
Saliency-Aware Class-Agnostic Food Image Segmentation
Feb 13, 2021
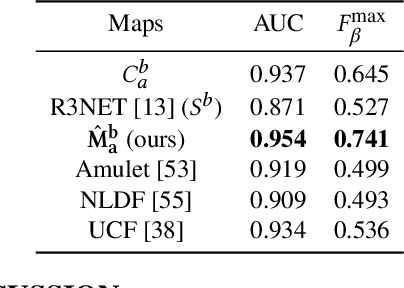
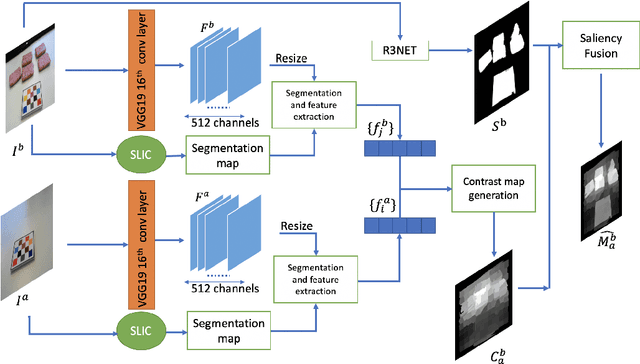
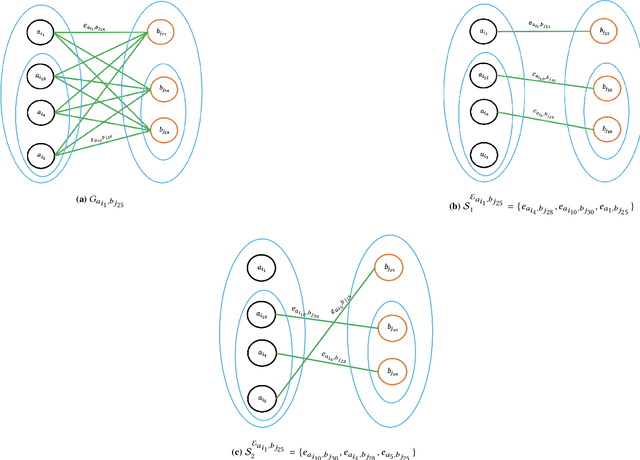
Advances in image-based dietary assessment methods have allowed nutrition professionals and researchers to improve the accuracy of dietary assessment, where images of food consumed are captured using smartphones or wearable devices. These images are then analyzed using computer vision methods to estimate energy and nutrition content of the foods. Food image segmentation, which determines the regions in an image where foods are located, plays an important role in this process. Current methods are data dependent, thus cannot generalize well for different food types. To address this problem, we propose a class-agnostic food image segmentation method. Our method uses a pair of eating scene images, one before start eating and one after eating is completed. Using information from both the before and after eating images, we can segment food images by finding the salient missing objects without any prior information about the food class. We model a paradigm of top down saliency which guides the attention of the human visual system (HVS) based on a task to find the salient missing objects in a pair of images. Our method is validated on food images collected from a dietary study which showed promising results.
A psychological theory of explainability
May 17, 2022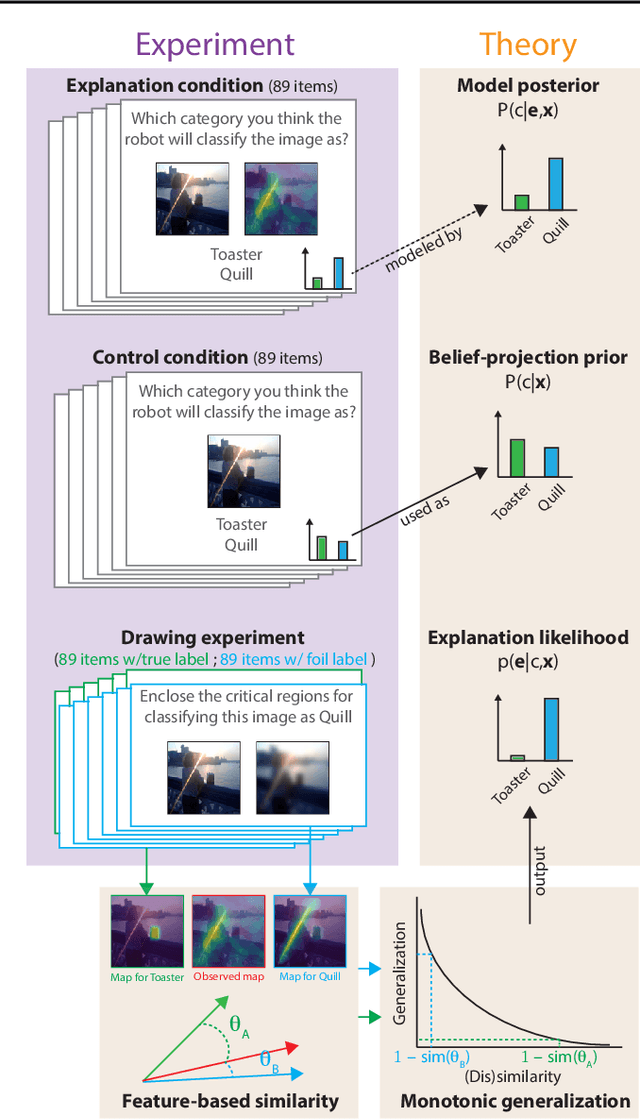
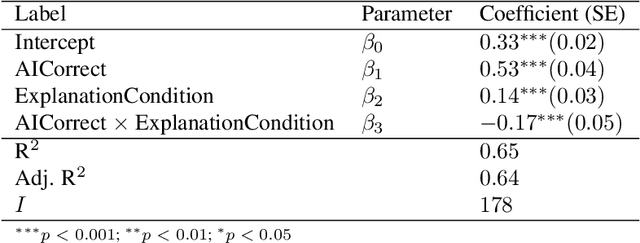
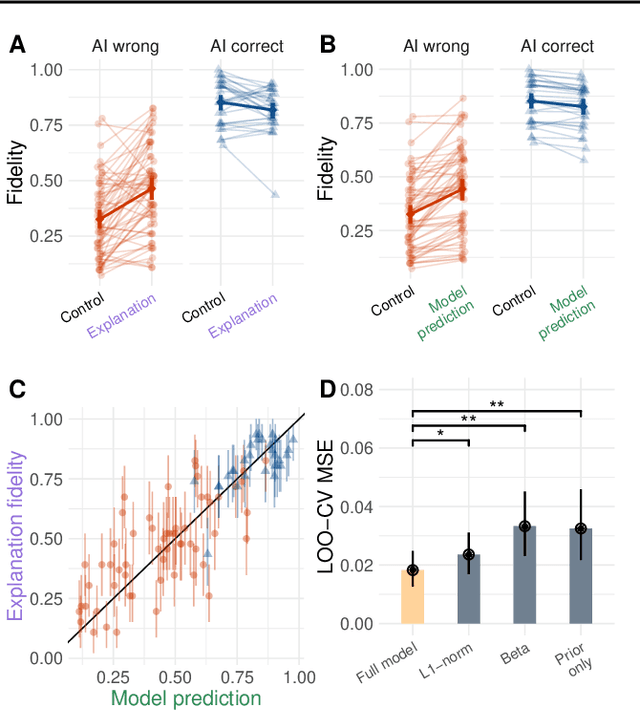
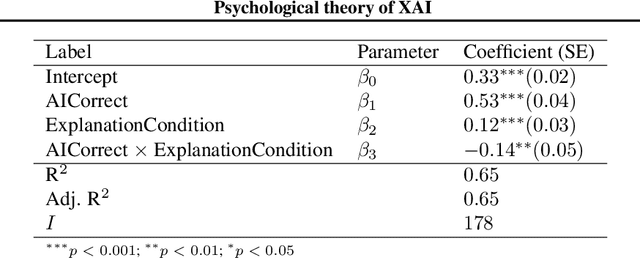
The goal of explainable Artificial Intelligence (XAI) is to generate human-interpretable explanations, but there are no computationally precise theories of how humans interpret AI generated explanations. The lack of theory means that validation of XAI must be done empirically, on a case-by-case basis, which prevents systematic theory-building in XAI. We propose a psychological theory of how humans draw conclusions from saliency maps, the most common form of XAI explanation, which for the first time allows for precise prediction of explainee inference conditioned on explanation. Our theory posits that absent explanation humans expect the AI to make similar decisions to themselves, and that they interpret an explanation by comparison to the explanations they themselves would give. Comparison is formalized via Shepard's universal law of generalization in a similarity space, a classic theory from cognitive science. A pre-registered user study on AI image classifications with saliency map explanations demonstrate that our theory quantitatively matches participants' predictions of the AI.
Learning Muti-expert Distribution Calibration for Long-tailed Video Classification
May 22, 2022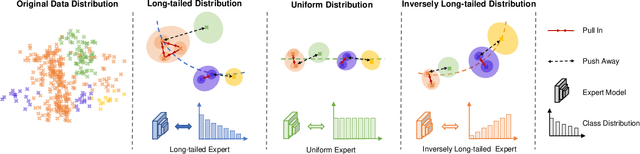
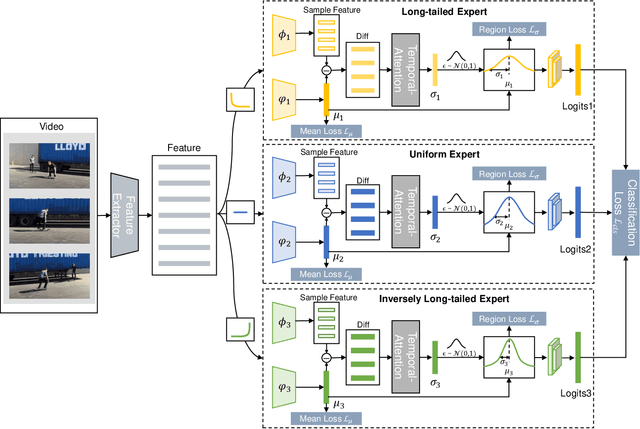

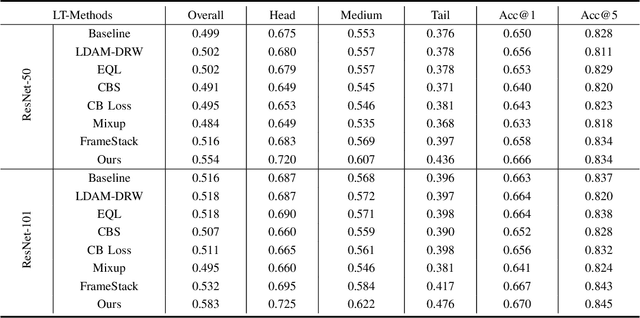
Most existing state-of-the-art video classification methods assume the training data obey a uniform distribution. However, video data in the real world typically exhibit long-tail class distribution and imbalance, which extensively results in a model bias towards head class and leads to relatively low performance on tail class. While the current long-tail classification methods usually focus on image classification, adapting it to video data is not a trivial extension. We propose an end-to-end multi-experts distribution calibration method based on two-level distribution information to address these challenges. The method jointly considers the distribution of samples in each class (intra-class distribution) and the diverse distributions of overall data (inter-class distribution) to solve the problem of imbalanced data under long-tailed distribution. By modeling this two-level distribution information, the model can consider the head classes and the tail classes and significantly transfer the knowledge from the head classes to improve the performance of the tail classes. Extensive experiments verify that our method achieves state-of-the-art performance on the long-tailed video classification task.
Global Filter Networks for Image Classification
Jul 01, 2021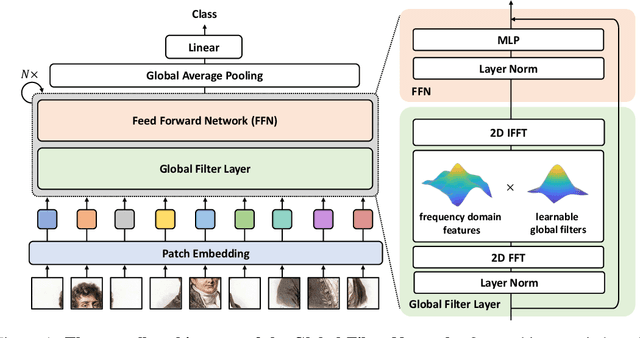

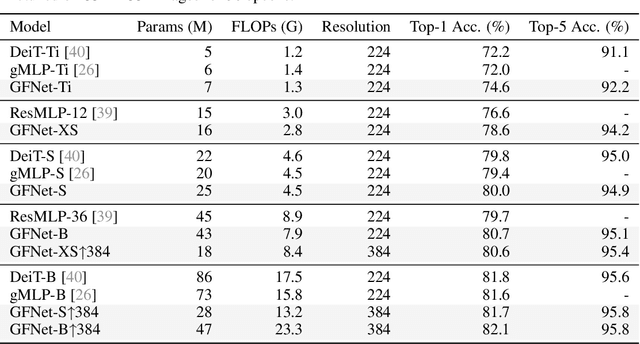
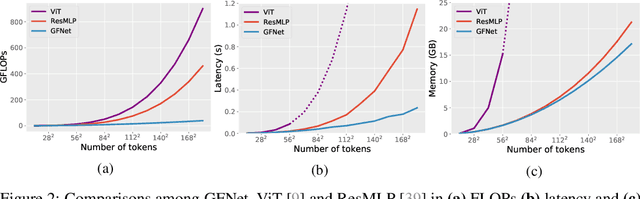
Recent advances in self-attention and pure multi-layer perceptrons (MLP) models for vision have shown great potential in achieving promising performance with fewer inductive biases. These models are generally based on learning interaction among spatial locations from raw data. The complexity of self-attention and MLP grows quadratically as the image size increases, which makes these models hard to scale up when high-resolution features are required. In this paper, we present the Global Filter Network (GFNet), a conceptually simple yet computationally efficient architecture, that learns long-term spatial dependencies in the frequency domain with log-linear complexity. Our architecture replaces the self-attention layer in vision transformers with three key operations: a 2D discrete Fourier transform, an element-wise multiplication between frequency-domain features and learnable global filters, and a 2D inverse Fourier transform. We exhibit favorable accuracy/complexity trade-offs of our models on both ImageNet and downstream tasks. Our results demonstrate that GFNet can be a very competitive alternative to transformer-style models and CNNs in efficiency, generalization ability and robustness. Code is available at https://github.com/raoyongming/GFNet
On the focusing of thermal images
Mar 15, 2022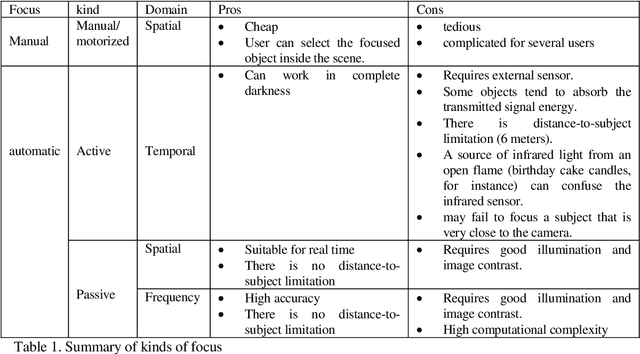
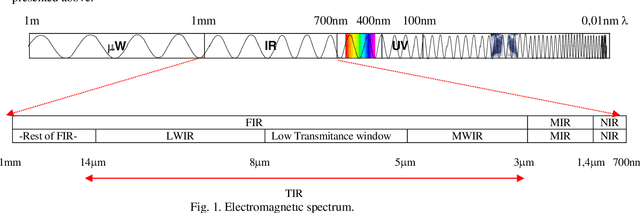

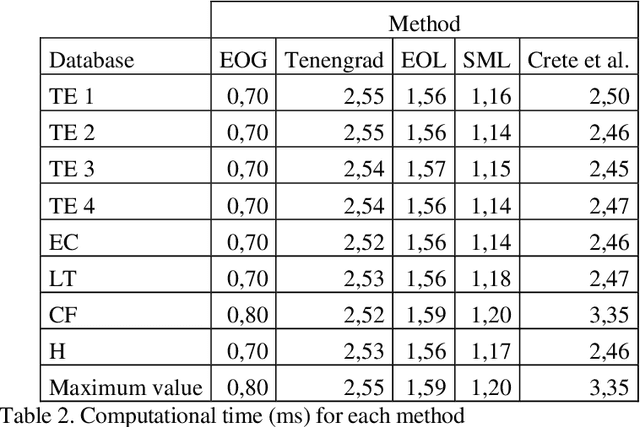
In this paper we present a new thermographic image database suitable for the analysis of automatic focus measures. This database consists of 8 different sets of scenes, where each scene contains one image for 96 different focus positions. Using this database we evaluate the usefulness of six focus measures with the goal to determine the optimal focus position. Experimental results reveal that an accurate automatic detection of optimal focus position is possible, even with a low computational burden. We also present an acquisition tool able to help the acquisition of thermal images. To the best of our knowledge, this is the first study about automatic focus of thermal images.
* 11 pages, published in Pattern Recognition Letters, Volume 32, Issue 11, 2011, Pages 1548-1557
Validation of image systems simulation technology using a Cornell Box
May 10, 2021
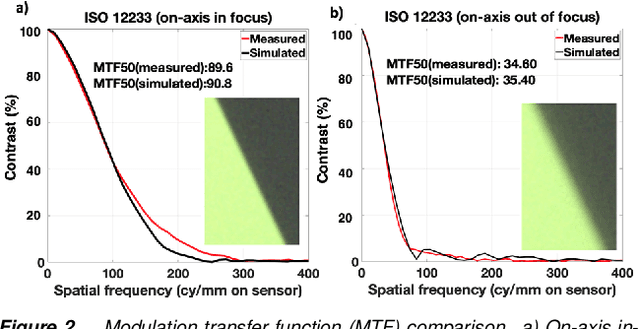
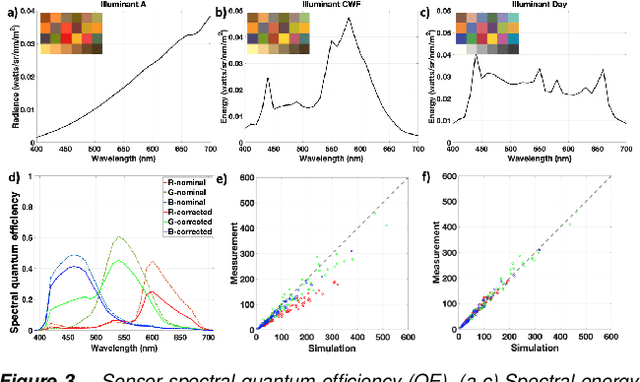

We describe and experimentally validate an end-to-end simulation of a digital camera. The simulation models the spectral radiance of 3D-scenes, formation of the spectral irradiance by multi-element optics, and conversion of the irradiance to digital values by the image sensor. We quantify the accuracy of the simulation by comparing real and simulated images of a precisely constructed, three-dimensional high dynamic range test scene. Validated end-to-end software simulation of a digital camera can accelerate innovation by reducing many of the time-consuming and expensive steps in designing, building and evaluating image systems.
Recent Advances in Embedding Methods for Multi-Object Tracking: A Survey
May 22, 2022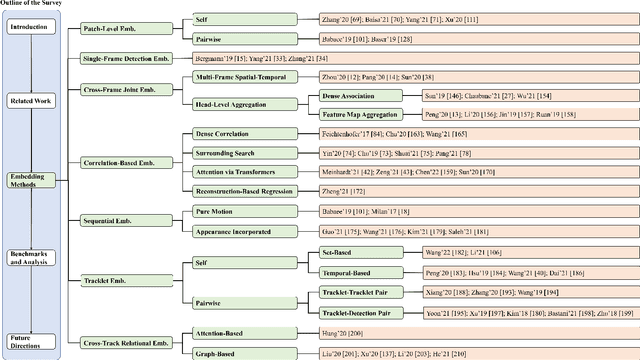

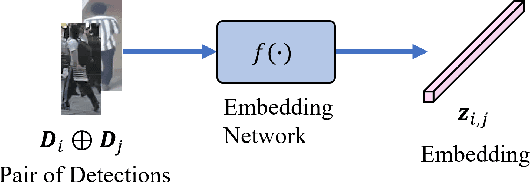
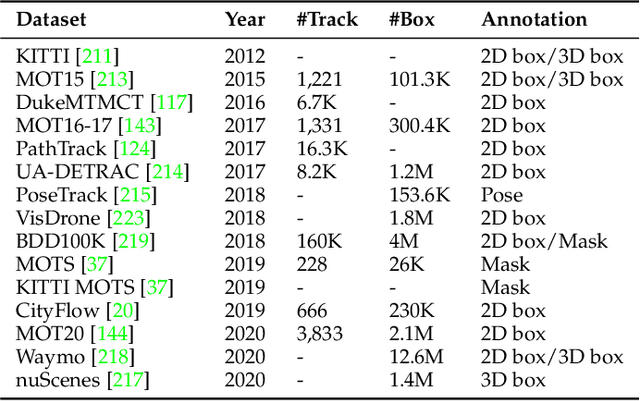
Multi-object tracking (MOT) aims to associate target objects across video frames in order to obtain entire moving trajectories. With the advancement of deep neural networks and the increasing demand for intelligent video analysis, MOT has gained significantly increased interest in the computer vision community. Embedding methods play an essential role in object location estimation and temporal identity association in MOT. Unlike other computer vision tasks, such as image classification, object detection, re-identification, and segmentation, embedding methods in MOT have large variations, and they have never been systematically analyzed and summarized. In this survey, we first conduct a comprehensive overview with in-depth analysis for embedding methods in MOT from seven different perspectives, including patch-level embedding, single-frame embedding, cross-frame joint embedding, correlation embedding, sequential embedding, tracklet embedding, and cross-track relational embedding. We further summarize the existing widely used MOT datasets and analyze the advantages of existing state-of-the-art methods according to their embedding strategies. Finally, some critical yet under-investigated areas and future research directions are discussed.