 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Discrete-continuous Action Space Policy Gradient-based Attention for Image-Text Matching
Apr 21, 2021
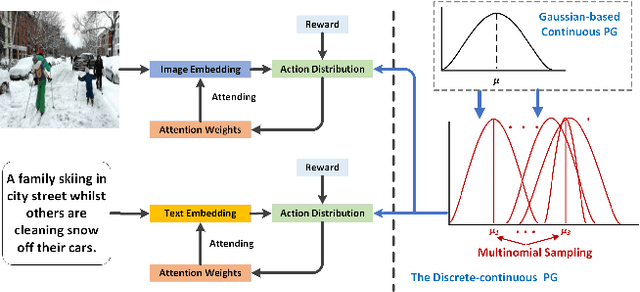
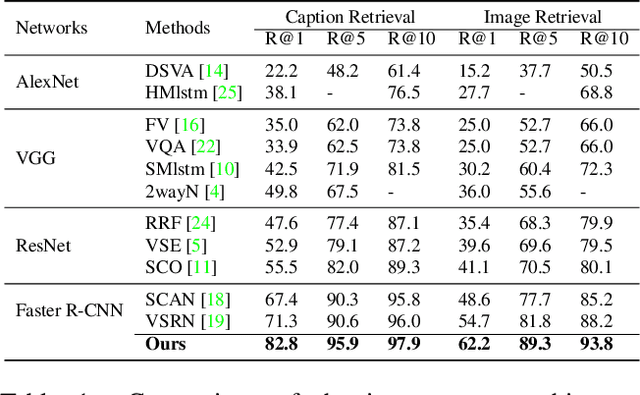
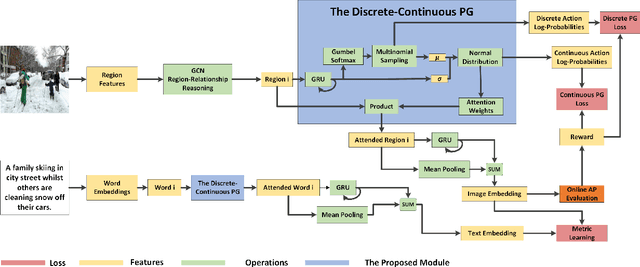
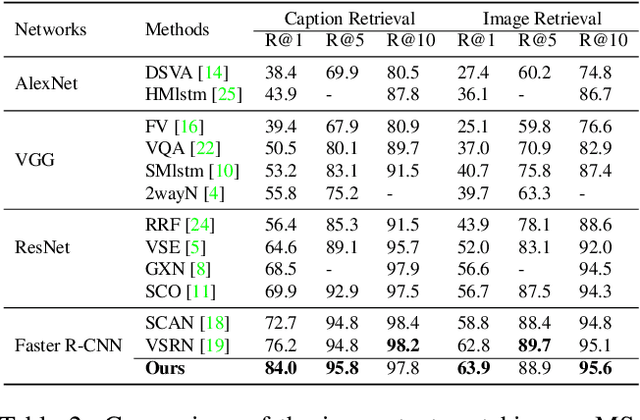
Image-text matching is an important multi-modal task with massive applications. It tries to match the image and the text with similar semantic information. Existing approaches do not explicitly transform the different modalities into a common space. Meanwhile, the attention mechanism which is widely used in image-text matching models does not have supervision. We propose a novel attention scheme which projects the image and text embedding into a common space and optimises the attention weights directly towards the evaluation metrics. The proposed attention scheme can be considered as a kind of supervised attention and requiring no additional annotations. It is trained via a novel Discrete-continuous action space policy gradient algorithm, which is more effective in modelling complex action space than previous continuous action space policy gradient. We evaluate the proposed methods on two widely-used benchmark datasets: Flickr30k and MS-COCO, outperforming the previous approaches by a large margin.
CNN-Augmented Visual-Inertial SLAM with Planar Constraints
May 05, 2022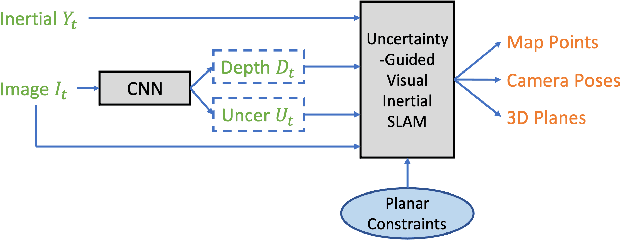
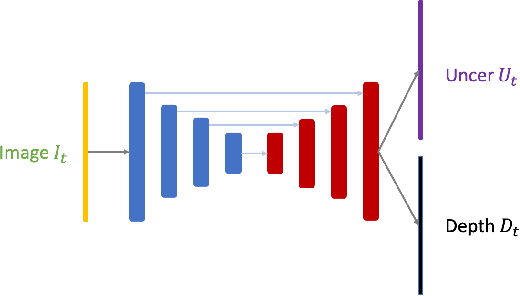

We present a robust visual-inertial SLAM system that combines the benefits of Convolutional Neural Networks (CNNs) and planar constraints. Our system leverages a CNN to predict the depth map and the corresponding uncertainty map for each image. The CNN depth effectively bootstraps the back-end optimization of SLAM and meanwhile the CNN uncertainty adaptively weighs the contribution of each feature point to the back-end optimization. Given the gravity direction from the inertial sensor, we further present a fast plane detection method that detects horizontal planes via one-point RANSAC and vertical planes via two-point RANSAC. Those stably detected planes are in turn used to regularize the back-end optimization of SLAM. We evaluate our system on a public dataset, \ie, EuRoC, and demonstrate improved results over a state-of-the-art SLAM system, \ie, ORB-SLAM3.
Poly-CAM: High resolution class activation map for convolutional neural networks
May 05, 2022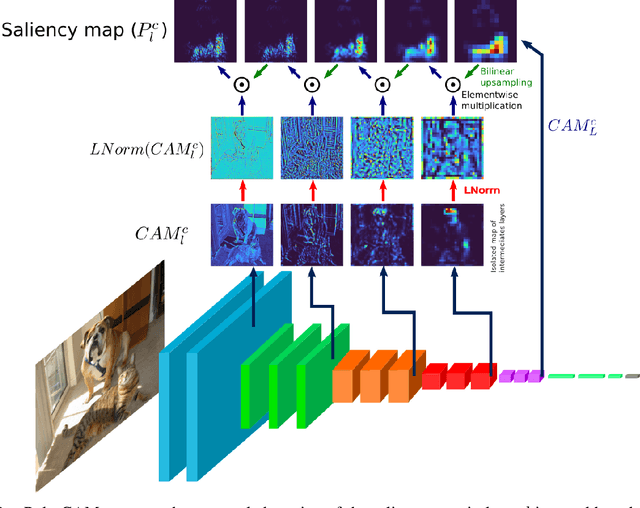
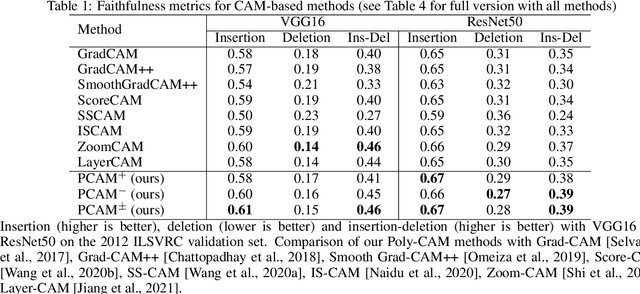

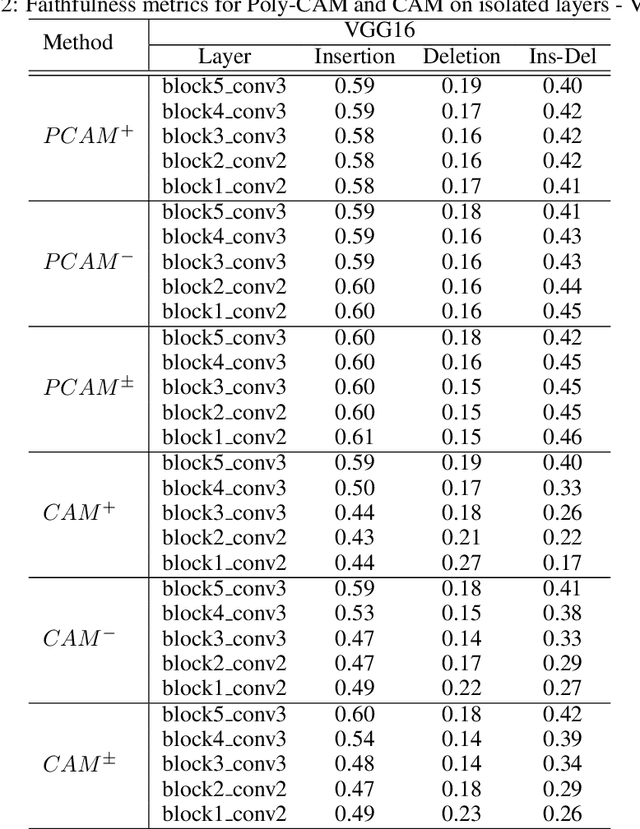
The need for Explainable AI is increasing with the development of deep learning. The saliency maps derived from convolutional neural networks generally fail in localizing with accuracy the image features justifying the network prediction. This is because those maps are either low-resolution as for CAM [Zhou et al., 2016], or smooth as for perturbation-based methods [Zeiler and Fergus, 2014], or do correspond to a large number of widespread peaky spots as for gradient-based approaches [Sundararajan et al., 2017, Smilkov et al., 2017]. In contrast, our work proposes to combine the information from earlier network layers with the one from later layers to produce a high resolution Class Activation Map that is competitive with the previous art in term of insertion-deletion faithfulness metrics, while outperforming it in term of precision of class-specific features localization.
Masked Spectrogram Modeling using Masked Autoencoders for Learning General-purpose Audio Representation
Apr 26, 2022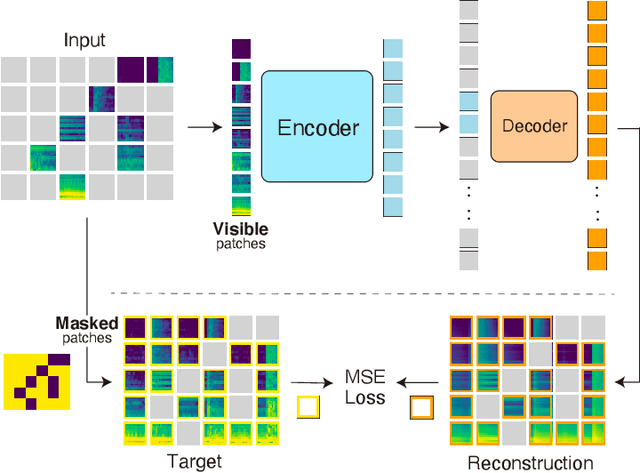
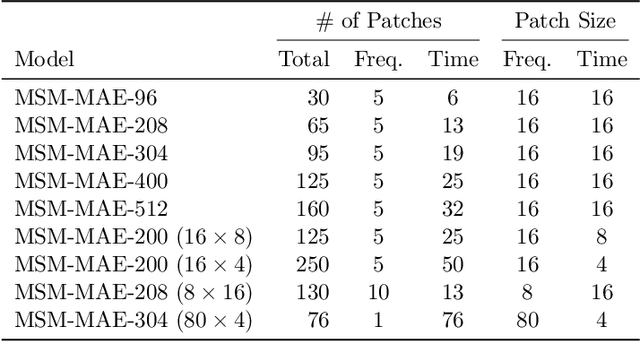
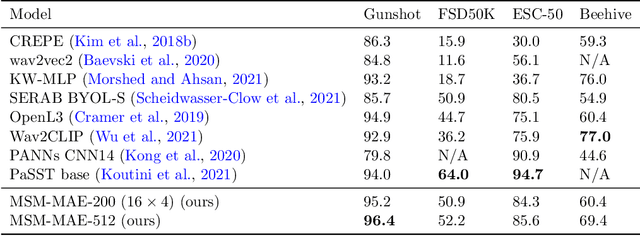
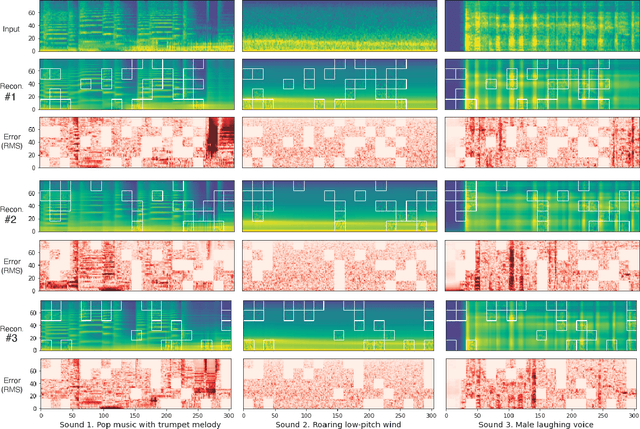
Recent general-purpose audio representations show state-of-the-art performance on various audio tasks. These representations are pre-trained by self-supervised learning methods that create training signals from the input. For example, typical audio contrastive learning uses temporal relationships among input sounds to create training signals, whereas some methods use a difference among input views created by data augmentations. However, these training signals do not provide information derived from the intact input sound, which we think is suboptimal for learning representation that describes the input as it is. In this paper, we seek to learn audio representations from the input itself as supervision using a pretext task of auto-encoding of masked spectrogram patches, Masked Spectrogram Modeling (MSM, a variant of Masked Image Modeling applied to audio spectrogram). To implement MSM, we use Masked Autoencoders (MAE), an image self-supervised learning method. MAE learns to efficiently encode the small number of visible patches into latent representations to carry essential information for reconstructing a large number of masked patches. While training, MAE minimizes the reconstruction error, which uses the input as training signal, consequently achieving our goal. We conducted experiments on our MSM using MAE (MSM-MAE) models under the evaluation benchmark of the HEAR 2021 NeurIPS Challenge. Our MSM-MAE models outperformed the HEAR 2021 Challenge results on seven out of 15 tasks (e.g., accuracies of 73.4% on CREMA-D and 85.8% on LibriCount), while showing top performance on other tasks where specialized models perform better. We also investigate how the design choices of MSM-MAE impact the performance and conduct qualitative analysis of visualization outcomes to gain an understanding of learned representations. We make our code available online.
Learned Block-based Hybrid Image Compression
Jan 18, 2021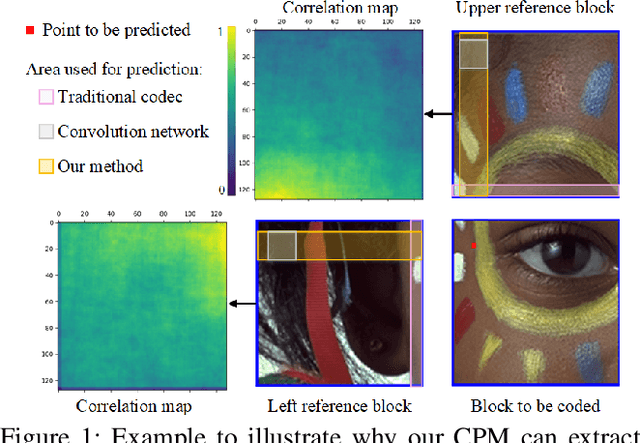
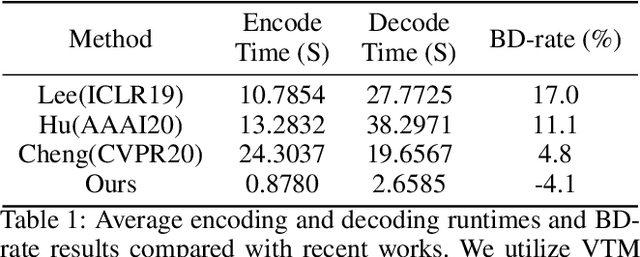
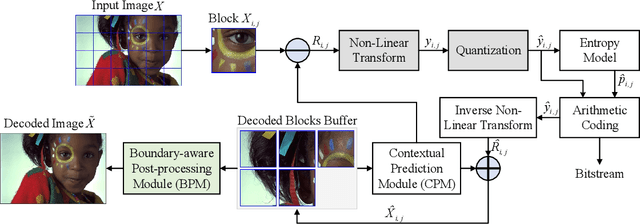
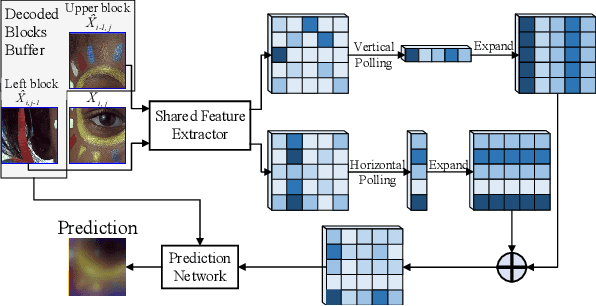
Recent works on learned image compression perform encoding and decoding processes in a full-resolution manner, resulting in two problems when deployed for practical applications. First, parallel acceleration of the autoregressive entropy model cannot be achieved due to serial decoding. Second, full-resolution inference often causes the out-of-memory(OOM) problem with limited GPU resources, especially for high-resolution images. Block partition is a good design choice to handle the above issues, but it brings about new challenges in reducing the redundancy between blocks and eliminating block effects. To tackle the above challenges, this paper provides a learned block-based hybrid image compression (LBHIC) framework. Specifically, we introduce explicit intra prediction into a learned image compression framework to utilize the relation among adjacent blocks. Superior to context modeling by linear weighting of neighbor pixels in traditional codecs, we propose a contextual prediction module (CPM) to better capture long-range correlations by utilizing the strip pooling to extract the most relevant information in neighboring latent space, thus achieving effective information prediction. Moreover, to alleviate blocking artifacts, we further propose a boundary-aware postprocessing module (BPM) with the edge importance taken into account. Extensive experiments demonstrate that the proposed LBHIC codec outperforms the VVC, with a bit-rate conservation of 4.1%, and reduces the decoding time by approximately 86.7% compared with that of state-of-the-art learned image compression methods.
Toward Zero-Shot Unsupervised Image-to-Image Translation
Jul 28, 2020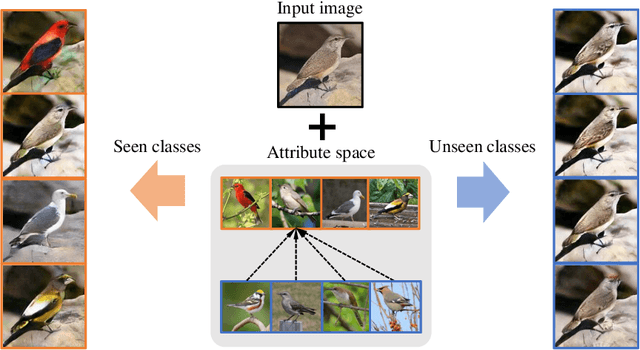
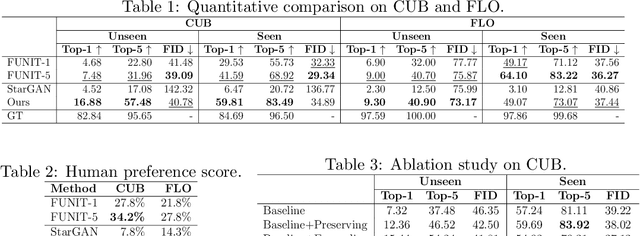
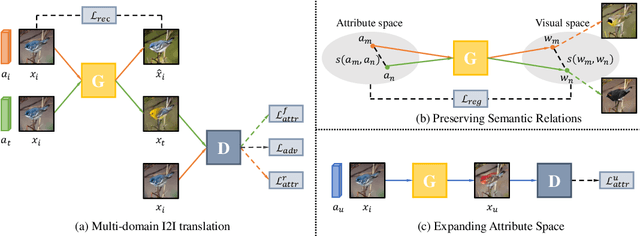

Recent studies have shown remarkable success in unsupervised image-to-image translation. However, if there has no access to enough images in target classes, learning a mapping from source classes to the target classes always suffers from mode collapse, which limits the application of the existing methods. In this work, we propose a zero-shot unsupervised image-to-image translation framework to address this limitation, by associating categories with their side information like attributes. To generalize the translator to previous unseen classes, we introduce two strategies for exploiting the space spanned by the semantic attributes. Specifically, we propose to preserve semantic relations to the visual space and expand attribute space by utilizing attribute vectors of unseen classes, thus encourage the translator to explore the modes of unseen classes. Quantitative and qualitative results on different datasets demonstrate the effectiveness of our proposed approach. Moreover, we demonstrate that our framework can be applied to many tasks, such as zero-shot classification and fashion design.
Nonlinear motion separation via untrained generator networks with disentangled latent space variables and applications to cardiac MRI
May 20, 2022
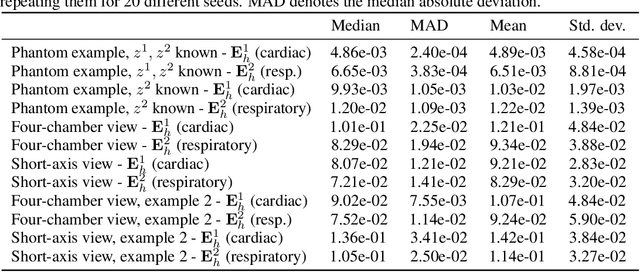
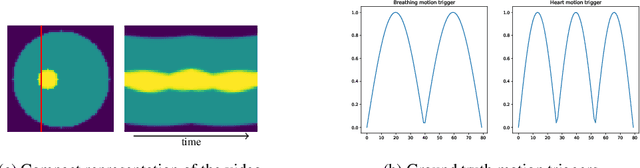
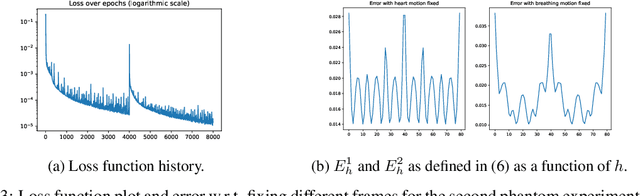
In this paper, a nonlinear approach to separate different motion types in video data is proposed. This is particularly relevant in dynamic medical imaging (e.g. PET, MRI), where patient motion poses a significant challenge due to its effects on the image reconstruction as well as for its subsequent interpretation. Here, a new method is proposed where dynamic images are represented as the forward mapping of a sequence of latent variables via a generator neural network. The latent variables are structured so that temporal variations in the data are represented via dynamic latent variables, which are independent of static latent variables characterizing the general structure of the frames. In particular, different kinds of motion are also characterized independently of each other via latent space disentanglement using one-dimensional prior information on all but one of the motion types. This representation allows to freeze any selection of motion types, and to obtain accurate independent representations of other dynamics of interest. Moreover, the proposed algorithm is training-free, i.e., all the network parameters are learned directly from a single video. We illustrate the performance of this method on phantom and real-data MRI examples, where we successfully separate respiratory and cardiac motion.
DONet: Dual-Octave Network for Fast MR Image Reconstruction
May 12, 2021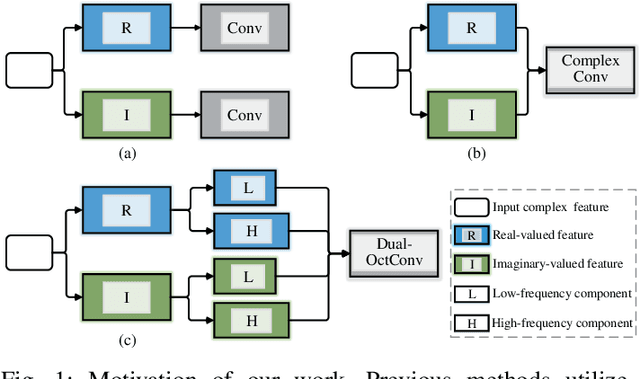
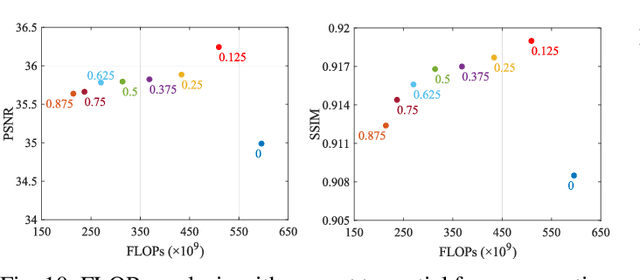

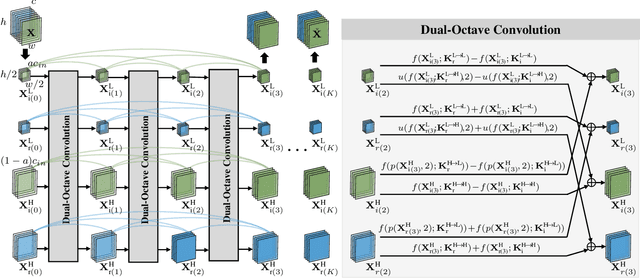
Magnetic resonance (MR) image acquisition is an inherently prolonged process, whose acceleration has long been the subject of research. This is commonly achieved by obtaining multiple undersampled images, simultaneously, through parallel imaging. In this paper, we propose the Dual-Octave Network (DONet), which is capable of learning multi-scale spatial-frequency features from both the real and imaginary components of MR data, for fast parallel MR image reconstruction. More specifically, our DONet consists of a series of Dual-Octave convolutions (Dual-OctConv), which are connected in a dense manner for better reuse of features. In each Dual-OctConv, the input feature maps and convolutional kernels are first split into two components (ie, real and imaginary), and then divided into four groups according to their spatial frequencies. Then, our Dual-OctConv conducts intra-group information updating and inter-group information exchange to aggregate the contextual information across different groups. Our framework provides three appealing benefits: (i) It encourages information interaction and fusion between the real and imaginary components at various spatial frequencies to achieve richer representational capacity. (ii) The dense connections between the real and imaginary groups in each Dual-OctConv make the propagation of features more efficient by feature reuse. (iii) DONet enlarges the receptive field by learning multiple spatial-frequency features of both the real and imaginary components. Extensive experiments on two popular datasets (ie, clinical knee and fastMRI), under different undersampling patterns and acceleration factors, demonstrate the superiority of our model in accelerated parallel MR image reconstruction.
Feedback Network for Mutually Boosted Stereo Image Super-Resolution and Disparity Estimation
Jun 02, 2021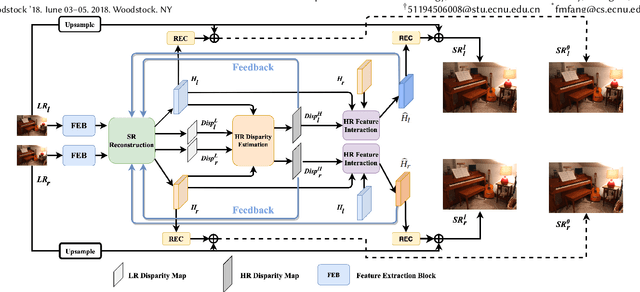
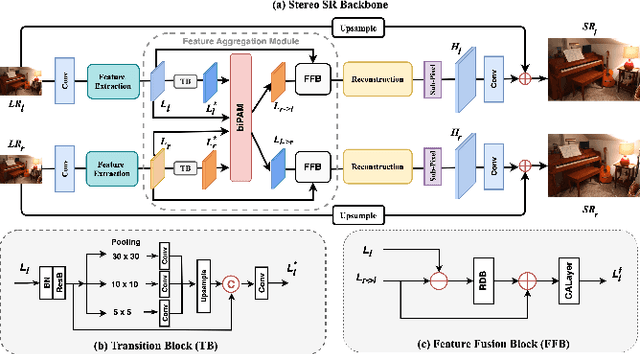

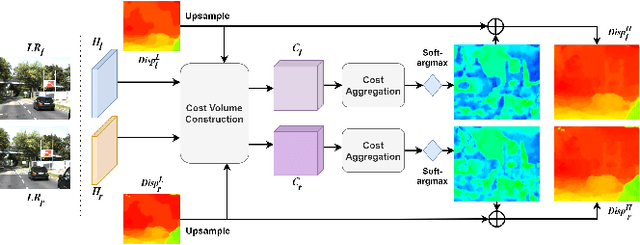
Under stereo settings, the problem of image super-resolution (SR) and disparity estimation are interrelated that the result of each problem could help to solve the other. The effective exploitation of correspondence between different views facilitates the SR performance, while the high-resolution (HR) features with richer details benefit the correspondence estimation. According to this motivation, we propose a Stereo Super-Resolution and Disparity Estimation Feedback Network (SSRDE-FNet), which simultaneously handles the stereo image super-resolution and disparity estimation in a unified framework and interact them with each other to further improve their performance. Specifically, the SSRDE-FNet is composed of two dual recursive sub-networks for left and right views. Besides the cross-view information exploitation in the low-resolution (LR) space, HR representations produced by the SR process are utilized to perform HR disparity estimation with higher accuracy, through which the HR features can be aggregated to generate a finer SR result. Afterward, the proposed HR Disparity Information Feedback (HRDIF) mechanism delivers information carried by HR disparity back to previous layers to further refine the SR image reconstruction. Extensive experiments demonstrate the effectiveness and advancement of SSRDE-FNet.
Synergy Between Semantic Segmentation and Image Denoising via Alternate Boosting
Feb 24, 2021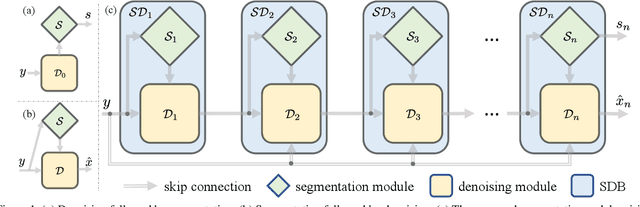
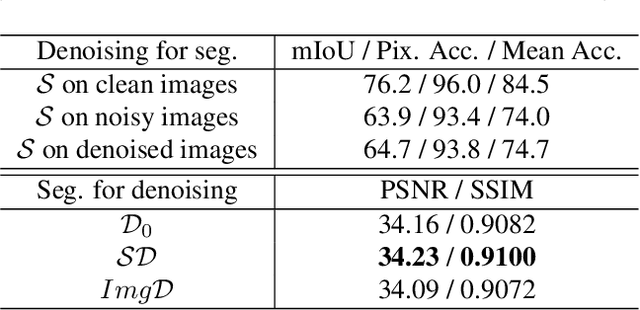
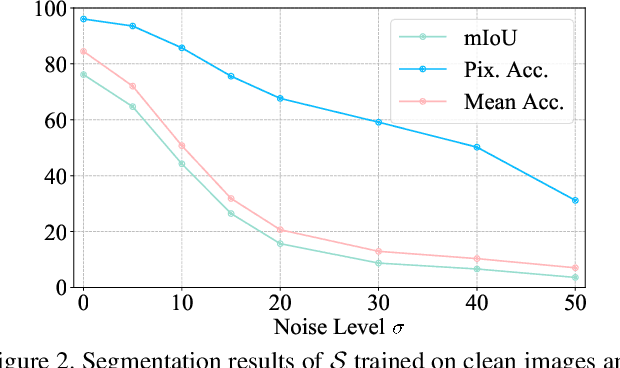
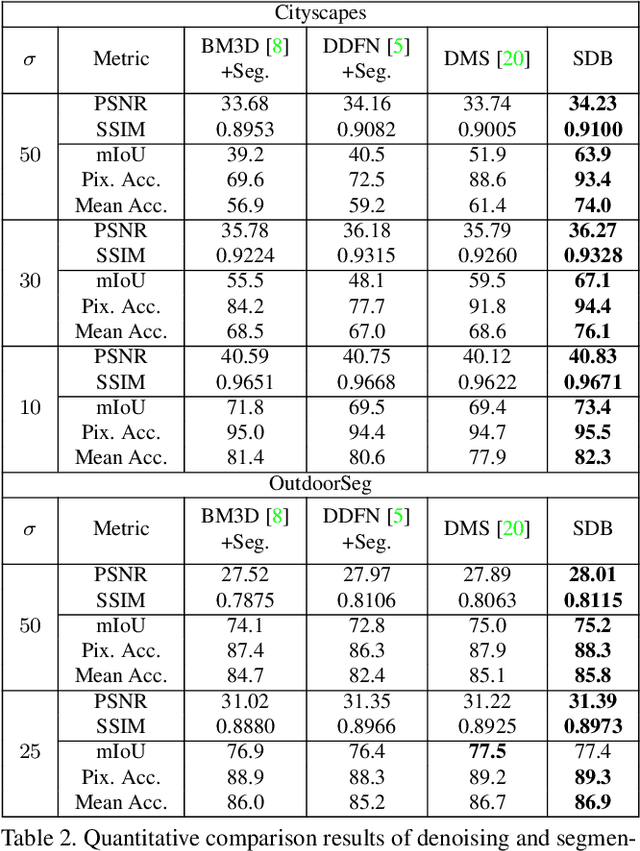
The capability of image semantic segmentation may be deteriorated due to noisy input image, where image denoising prior to segmentation helps. Both image denoising and semantic segmentation have been developed significantly with the advance of deep learning. Thus, we are interested in the synergy between them by using a holistic deep model. We observe that not only denoising helps combat the drop of segmentation accuracy due to noise, but also pixel-wise semantic information boosts the capability of denoising. We then propose a boosting network to perform denoising and segmentation alternately. The proposed network is composed of multiple segmentation and denoising blocks (SDBs), each of which estimates semantic map then uses the map to regularize denoising. Experimental results show that the denoised image quality is improved substantially and the segmentation accuracy is improved to close to that of clean images. Our code and models will be made publicly available.