 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Feb 07, 2022

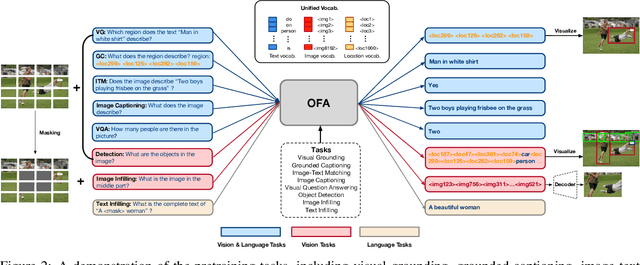
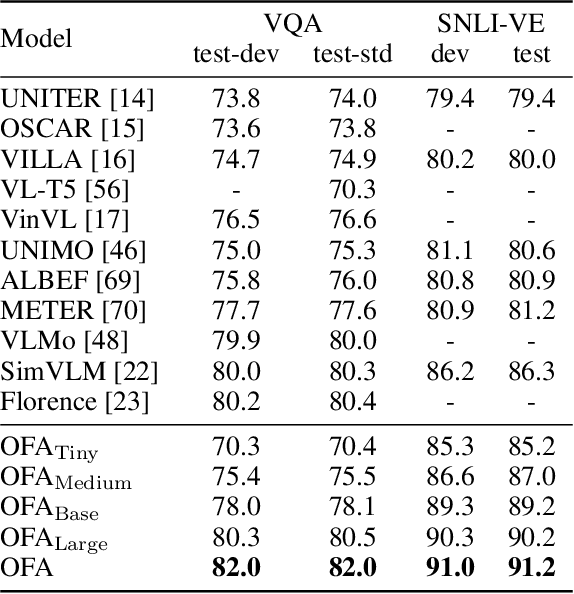
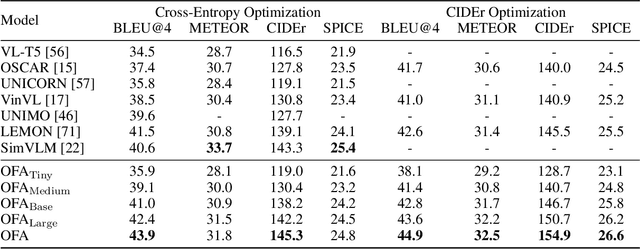
In this work, we pursue a unified paradigm for multimodal pretraining to break the scaffolds of complex task/modality-specific customization. We propose OFA, a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework based on the encoder-decoder architecture. OFA performs pretraining and finetuning with task instructions and introduces no extra task-specific layers for finetuning. Experimental results show that OFA achieves new state-of-the-arts on a series of multimodal tasks, including image captioning (COCO test CIDEr: 149.6), text-to-image generation (COCO test FID: 10.5), VQA (test-std acc.: 80.02), SNLI-VE (test acc.: 90.20), and referring expression comprehension (RefCOCO / RefCOCO+ / RefCOCOg test acc.: 92.93 / 90.10 / 85.20). Through extensive analyses, we demonstrate that OFA reaches comparable performance with uni-modal pretrained models (e.g., BERT, MAE, MoCo v3, SimCLR v2, etc.) in uni-modal tasks, including NLU, NLG, and image classification, and it effectively transfers to unseen tasks and domains. Code shall be released soon at http://github.com/OFA-Sys/OFA
Instance-aware Remote Sensing Image Captioning with Cross-hierarchy Attention
May 11, 2021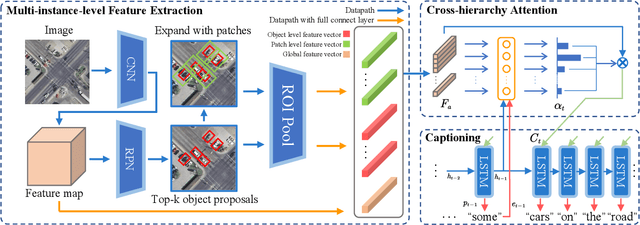


The spatial attention is a straightforward approach to enhance the performance for remote sensing image captioning. However, conventional spatial attention approaches consider only the attention distribution on one fixed coarse grid, resulting in the semantics of tiny objects can be easily ignored or disturbed during the visual feature extraction. Worse still, the fixed semantic level of conventional spatial attention limits the image understanding in different levels and perspectives, which is critical for tackling the huge diversity in remote sensing images. To address these issues, we propose a remote sensing image caption generator with instance-awareness and cross-hierarchy attention. 1) The instances awareness is achieved by introducing a multi-level feature architecture that contains the visual information of multi-level instance-possible regions and their surroundings. 2) Moreover, based on this multi-level feature extraction, a cross-hierarchy attention mechanism is proposed to prompt the decoder to dynamically focus on different semantic hierarchies and instances at each time step. The experimental results on public datasets demonstrate the superiority of proposed approach over existing methods.
UNIMO-2: End-to-End Unified Vision-Language Grounded Learning
Mar 17, 2022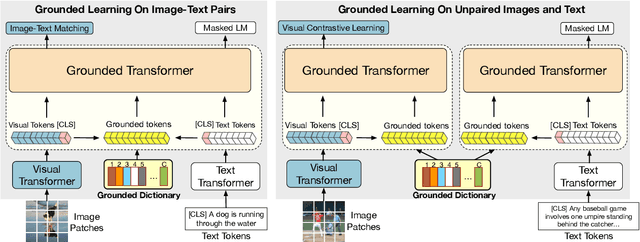
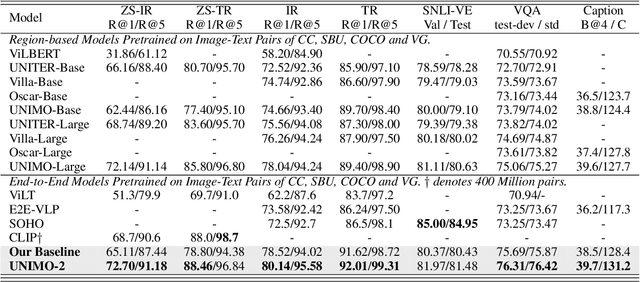
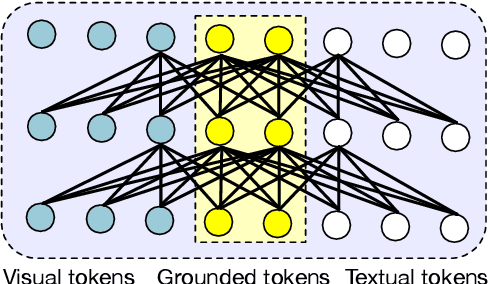

Vision-Language Pre-training (VLP) has achieved impressive performance on various cross-modal downstream tasks. However, most existing methods can only learn from aligned image-caption data and rely heavily on expensive regional features, which greatly limits their scalability and performance. In this paper, we propose an end-to-end unified-modal pre-training framework, namely UNIMO-2, for joint learning on both aligned image-caption data and unaligned image-only and text-only corpus. We build a unified Transformer model to jointly learn visual representations, textual representations and semantic alignment between images and texts. In particular, we propose to conduct grounded learning on both images and texts via a sharing grounded space, which helps bridge unaligned images and texts, and align the visual and textual semantic spaces on different types of corpora. The experiments show that our grounded learning method can improve textual and visual semantic alignment for improving performance on various cross-modal tasks. Moreover, benefiting from effective joint modeling of different types of corpora, our model also achieves impressive performance on single-modal visual and textual tasks. Our code and models are public at the UNIMO project page https://unimo-ptm.github.io/.
A Mixed Quantization Network for Computationally Efficient Mobile Inverse Tone Mapping
Mar 12, 2022
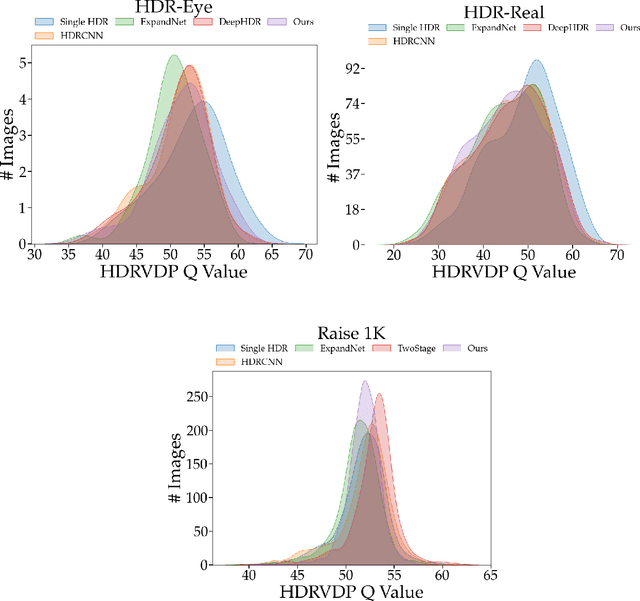
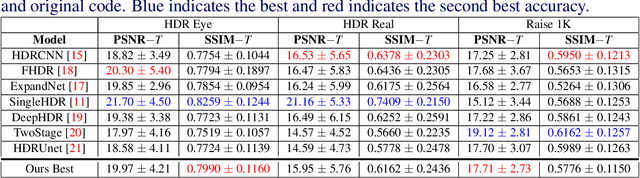
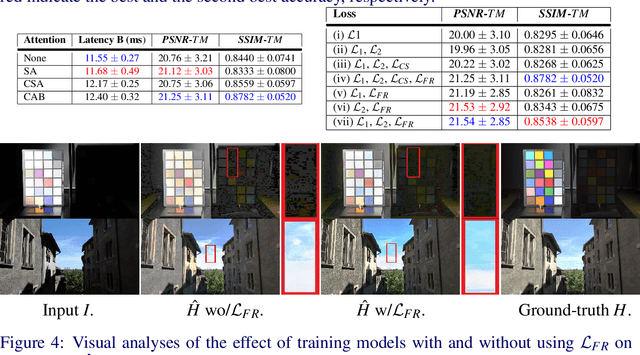
Recovering a high dynamic range (HDR) image from a single low dynamic range (LDR) image, namely inverse tone mapping (ITM), is challenging due to the lack of information in over- and under-exposed regions. Current methods focus exclusively on training high-performing but computationally inefficient ITM models, which in turn hinder deployment of the ITM models in resource-constrained environments with limited computing power such as edge and mobile device applications. To this end, we propose combining efficient operations of deep neural networks with a novel mixed quantization scheme to construct a well-performing but computationally efficient mixed quantization network (MQN) which can perform single image ITM on mobile platforms. In the ablation studies, we explore the effect of using different attention mechanisms, quantization schemes, and loss functions on the performance of MQN in ITM tasks. In the comparative analyses, ITM models trained using MQN perform on par with the state-of-the-art methods on benchmark datasets. MQN models provide up to 10 times improvement on latency and 25 times improvement on memory consumption.
Image Composition Assessment with Saliency-augmented Multi-pattern Pooling
Apr 07, 2021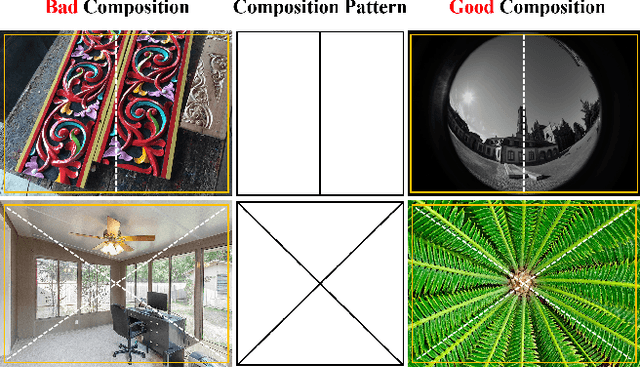
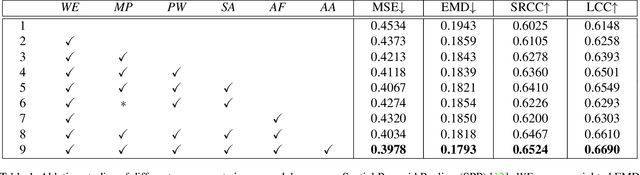
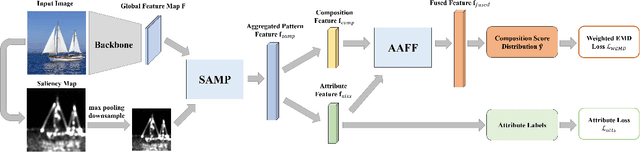
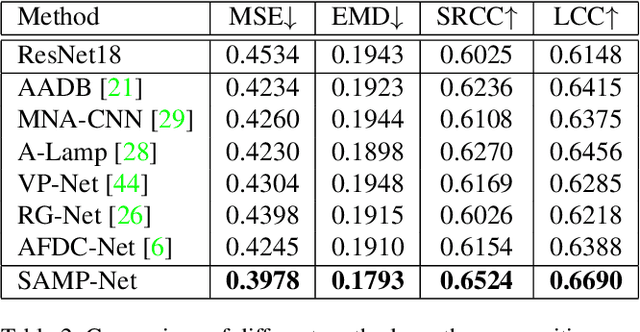
Image composition assessment is crucial in aesthetic assessment, which aims to assess the overall composition quality of a given image. However, to the best of our knowledge, there is neither dataset nor method specifically proposed for this task. In this paper, we contribute the first composition assessment dataset CADB with composition scores for each image provided by multiple professional raters. Besides, we propose a composition assessment network SAMP-Net with a novel Saliency-Augmented Multi-pattern Pooling (SAMP) module, which analyses visual layout from the perspectives of multiple composition patterns. We also leverage composition-relevant attributes to further boost the performance, and extend Earth Mover's Distance (EMD) loss to weighted EMD loss to eliminate the content bias. The experimental results show that our SAMP-Net can perform more favorably than previous aesthetic assessment approaches and offer constructive composition suggestions.
Contrastive Identification of Covariate Shift in Image Data
Aug 19, 2021



Identifying covariate shift is crucial for making machine learning systems robust in the real world and for detecting training data biases that are not reflected in test data. However, detecting covariate shift is challenging, especially when the data consists of high-dimensional images, and when multiple types of localized covariate shift affect different subspaces of the data. Although automated techniques can be used to detect the existence of covariate shift, our goal is to help human users characterize the extent of covariate shift in large image datasets with interfaces that seamlessly integrate information obtained from the detection algorithms. In this paper, we design and evaluate a new visual interface that facilitates the comparison of the local distributions of training and test data. We conduct a quantitative user study on multi-attribute facial data to compare two different learned low-dimensional latent representations (pretrained ImageNet CNN vs. density ratio) and two user analytic workflows (nearest-neighbor vs. cluster-to-cluster). Our results indicate that the latent representation of our density ratio model, combined with a nearest-neighbor comparison, is the most effective at helping humans identify covariate shift.
Transformer with Fourier Integral Attentions
Jun 01, 2022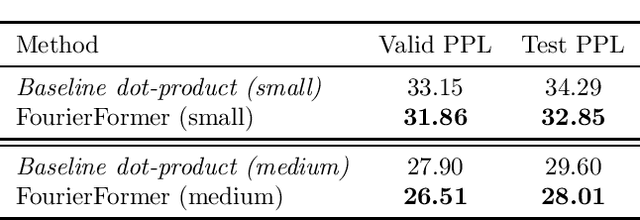



Multi-head attention empowers the recent success of transformers, the state-of-the-art models that have achieved remarkable success in sequence modeling and beyond. These attention mechanisms compute the pairwise dot products between the queries and keys, which results from the use of unnormalized Gaussian kernels with the assumption that the queries follow a mixture of Gaussian distribution. There is no guarantee that this assumption is valid in practice. In response, we first interpret attention in transformers as a nonparametric kernel regression. We then propose the FourierFormer, a new class of transformers in which the dot-product kernels are replaced by the novel generalized Fourier integral kernels. Different from the dot-product kernels, where we need to choose a good covariance matrix to capture the dependency of the features of data, the generalized Fourier integral kernels can automatically capture such dependency and remove the need to tune the covariance matrix. We theoretically prove that our proposed Fourier integral kernels can efficiently approximate any key and query distributions. Compared to the conventional transformers with dot-product attention, FourierFormers attain better accuracy and reduce the redundancy between attention heads. We empirically corroborate the advantages of FourierFormers over the baseline transformers in a variety of practical applications including language modeling and image classification.
ResMLP: Feedforward networks for image classification with data-efficient training
May 07, 2021
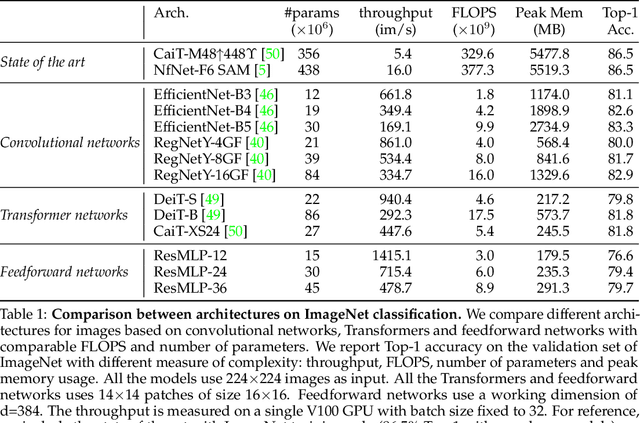
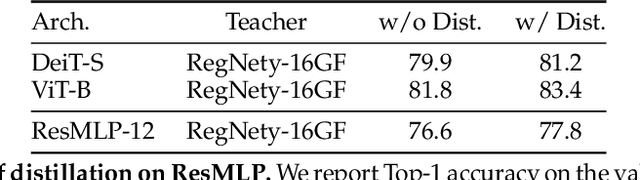
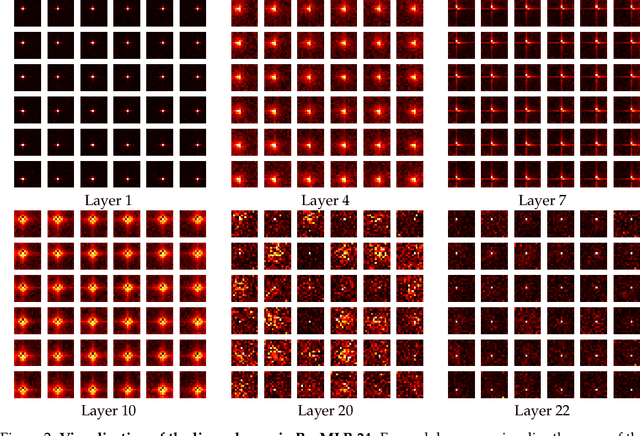
We present ResMLP, an architecture built entirely upon multi-layer perceptrons for image classification. It is a simple residual network that alternates (i) a linear layer in which image patches interact, independently and identically across channels, and (ii) a two-layer feed-forward network in which channels interact independently per patch. When trained with a modern training strategy using heavy data-augmentation and optionally distillation, it attains surprisingly good accuracy/complexity trade-offs on ImageNet. We will share our code based on the Timm library and pre-trained models.
Benchmark of DNN Model Search at Deployment Time
Jun 01, 2022
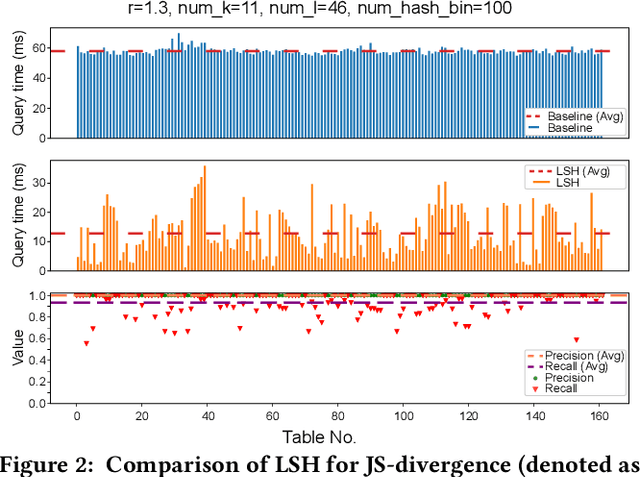
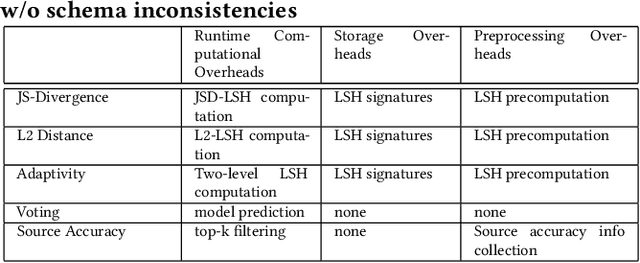
Deep learning has become the most popular direction in machine learning and artificial intelligence. However, the preparation of training data, as well as model training, are often time-consuming and become the bottleneck of the end-to-end machine learning lifecycle. Reusing models for inferring a dataset can avoid the costs of retraining. However, when there are multiple candidate models, it is challenging to discover the right model for reuse. Although there exist a number of model sharing platforms such as ModelDB, TensorFlow Hub, PyTorch Hub, and DLHub, most of these systems require model uploaders to manually specify the details of each model and model downloaders to screen keyword search results for selecting a model. We are lacking a highly productive model search tool that selects models for deployment without the need for any manual inspection and/or labeled data from the target domain. This paper proposes multiple model search strategies including various similarity-based approaches and non-similarity-based approaches. We design, implement, and evaluate these approaches on multiple model inference scenarios, including activity recognition, image recognition, text classification, natural language processing, and entity matching. The experimental evaluation showed that our proposed asymmetric similarity-based measurement, adaptivity, outperformed symmetric similarity-based measurements and non-similarity-based measurements in most of the workloads.
Learning With Context Feedback Loop for Robust Medical Image Segmentation
Mar 04, 2021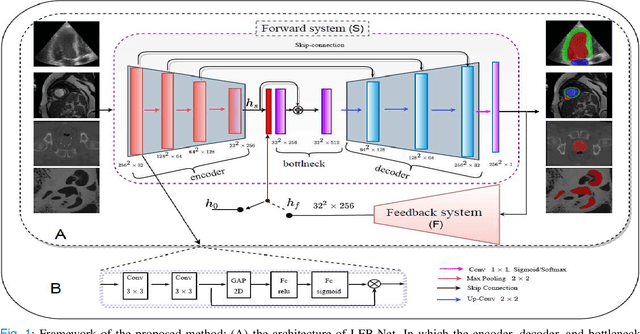
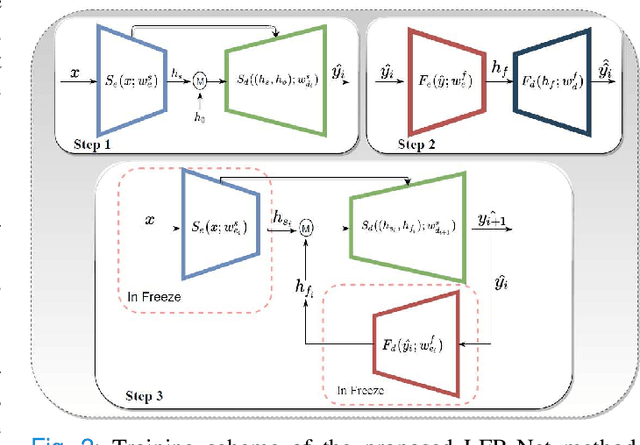
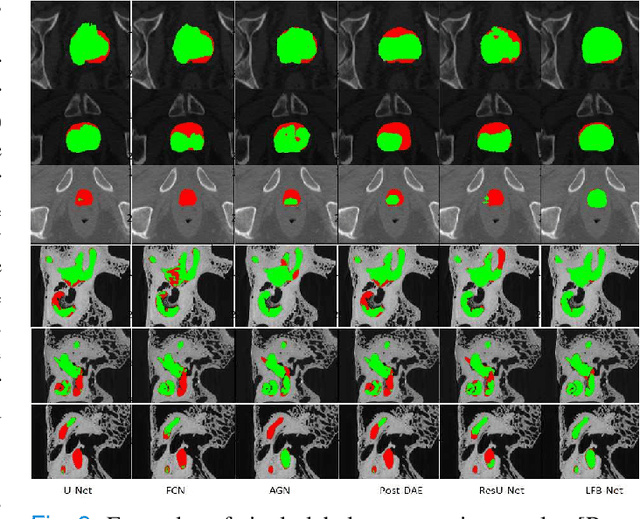
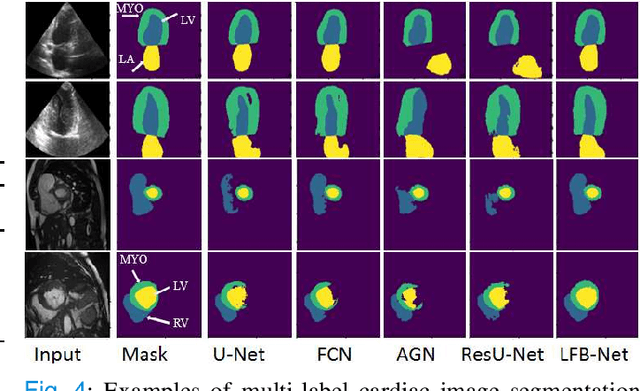
Deep learning has successfully been leveraged for medical image segmentation. It employs convolutional neural networks (CNN) to learn distinctive image features from a defined pixel-wise objective function. However, this approach can lead to less output pixel interdependence producing incomplete and unrealistic segmentation results. In this paper, we present a fully automatic deep learning method for robust medical image segmentation by formulating the segmentation problem as a recurrent framework using two systems. The first one is a forward system of an encoder-decoder CNN that predicts the segmentation result from the input image. The predicted probabilistic output of the forward system is then encoded by a fully convolutional network (FCN)-based context feedback system. The encoded feature space of the FCN is then integrated back into the forward system's feed-forward learning process. Using the FCN-based context feedback loop allows the forward system to learn and extract more high-level image features and fix previous mistakes, thereby improving prediction accuracy over time. Experimental results, performed on four different clinical datasets, demonstrate our method's potential application for single and multi-structure medical image segmentation by outperforming the state of the art methods. With the feedback loop, deep learning methods can now produce results that are both anatomically plausible and robust to low contrast images. Therefore, formulating image segmentation as a recurrent framework of two interconnected networks via context feedback loop can be a potential method for robust and efficient medical image analysis.