 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TransHash: Transformer-based Hamming Hashing for Efficient Image Retrieval
May 05, 2021
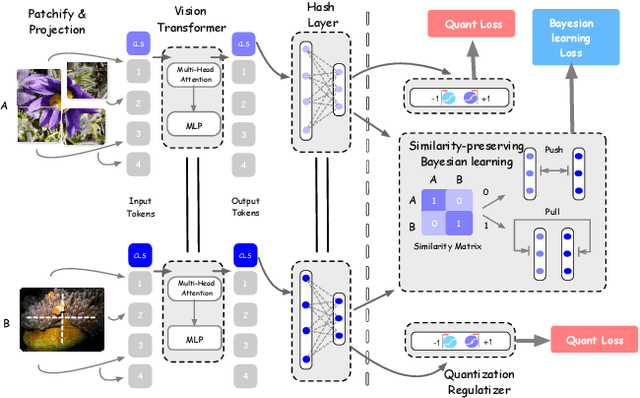
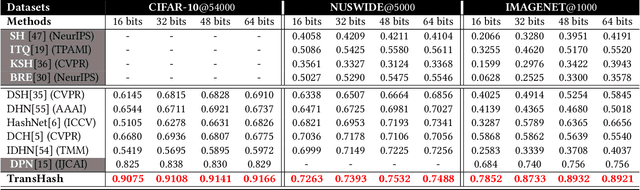
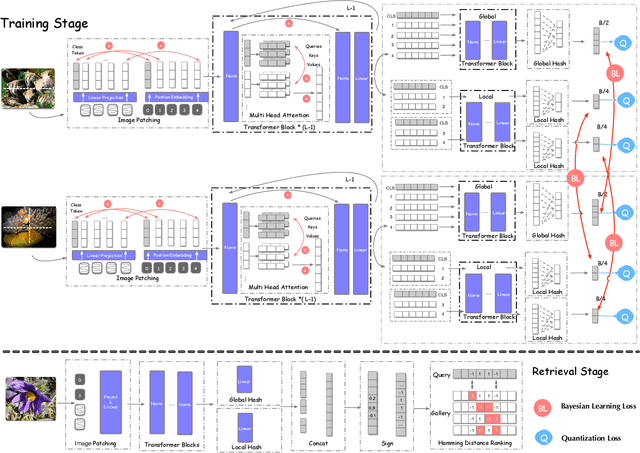

Deep hamming hashing has gained growing popularity in approximate nearest neighbour search for large-scale image retrieval. Until now, the deep hashing for the image retrieval community has been dominated by convolutional neural network architectures, e.g. \texttt{Resnet}\cite{he2016deep}. In this paper, inspired by the recent advancements of vision transformers, we present \textbf{Transhash}, a pure transformer-based framework for deep hashing learning. Concretely, our framework is composed of two major modules: (1) Based on \textit{Vision Transformer} (ViT), we design a siamese vision transformer backbone for image feature extraction. To learn fine-grained features, we innovate a dual-stream feature learning on top of the transformer to learn discriminative global and local features. (2) Besides, we adopt a Bayesian learning scheme with a dynamically constructed similarity matrix to learn compact binary hash codes. The entire framework is jointly trained in an end-to-end manner.~To the best of our knowledge, this is the first work to tackle deep hashing learning problems without convolutional neural networks (\textit{CNNs}). We perform comprehensive experiments on three widely-studied datasets: \textbf{CIFAR-10}, \textbf{NUSWIDE} and \textbf{IMAGENET}. The experiments have evidenced our superiority against the existing state-of-the-art deep hashing methods. Specifically, we achieve 8.2\%, 2.6\%, 12.7\% performance gains in terms of average \textit{mAP} for different hash bit lengths on three public datasets, respectively.
Curiously Effective Features for Image Quality Prediction
Jun 10, 2021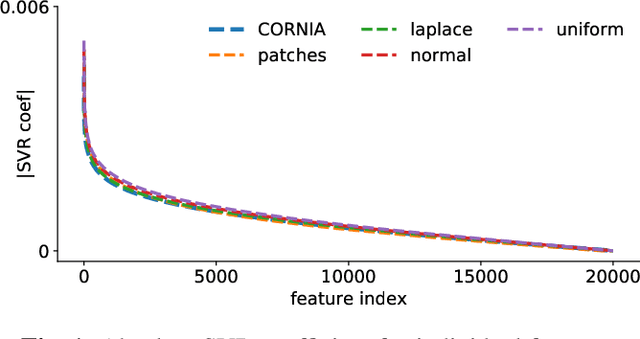
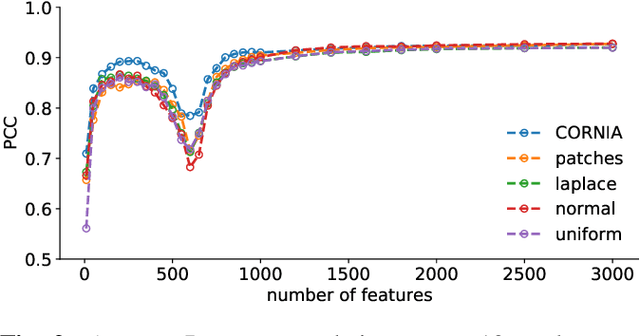
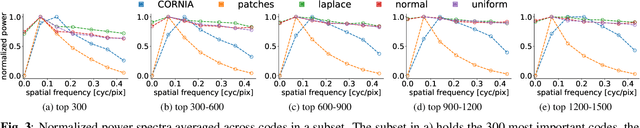
The performance of visual quality prediction models is commonly assumed to be closely tied to their ability to capture perceptually relevant image aspects. Models are thus either based on sophisticated feature extractors carefully designed from extensive domain knowledge or optimized through feature learning. In contrast to this, we find feature extractors constructed from random noise to be sufficient to learn a linear regression model whose quality predictions reach high correlations with human visual quality ratings, on par with a model with learned features. We analyze this curious result and show that besides the quality of feature extractors also their quantity plays a crucial role - with top performances only being achieved in highly overparameterized models.
A Survey of Super-Resolution in Iris Biometrics with Evaluation of Dictionary-Learning
Mar 27, 2022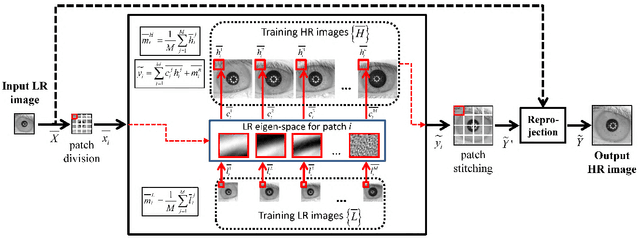
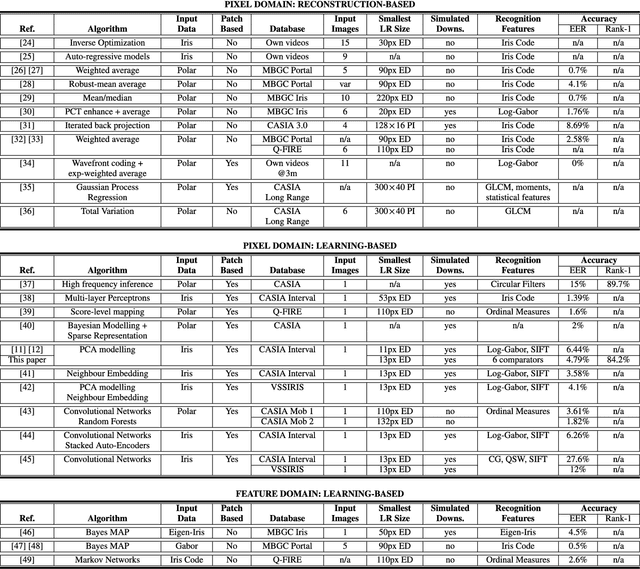
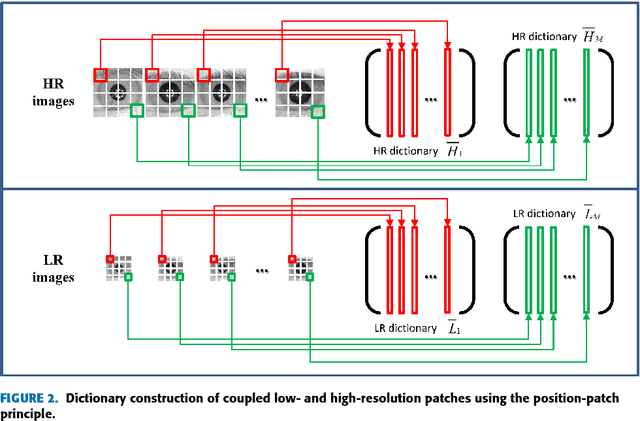

The lack of resolution has a negative impact on the performance of image-based biometrics. While many generic super-resolution methods have been proposed to restore low-resolution images, they usually aim to enhance their visual appearance. However, a visual enhancement of biometric images does not necessarily correlate with a better recognition performance. Reconstruction approaches need thus to incorporate specific information from the target biometric modality to effectively improve recognition. This paper presents a comprehensive survey of iris super-resolution approaches proposed in the literature. We have also adapted an Eigen-patches reconstruction method based on PCA Eigen-transformation of local image patches. The structure of the iris is exploited by building a patch-position dependent dictionary. In addition, image patches are restored separately, having their own reconstruction weights. This allows the solution to be locally optimized, helping to preserve local information. To evaluate the algorithm, we degraded high-resolution images from the CASIA Interval V3 database. Different restorations were considered, with 15x15 pixels being the smallest resolution. To the best of our knowledge, this is among the smallest resolutions employed in the literature. The framework is complemented with six public iris comparators, which were used to carry out biometric verification and identification experiments. Experimental results show that the proposed method significantly outperforms both bilinear and bicubic interpolation at very low-resolution. The performance of a number of comparators attains an impressive Equal Error Rate as low as 5%, and a Top-1 accuracy of 77-84% when considering iris images of only 15x15 pixels. These results clearly demonstrate the benefit of using trained super-resolution techniques to improve the quality of iris images prior to matching.
Image Sentiment Transfer
Jun 19, 2020
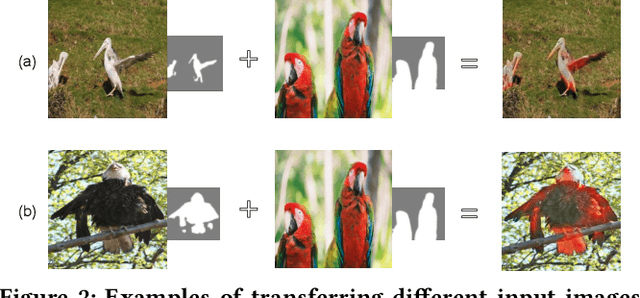
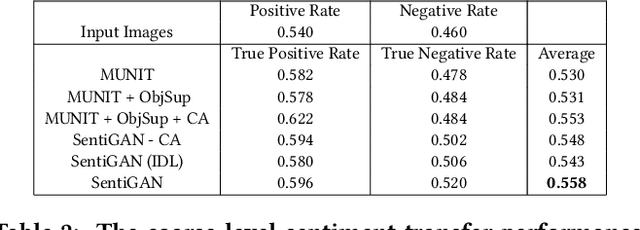
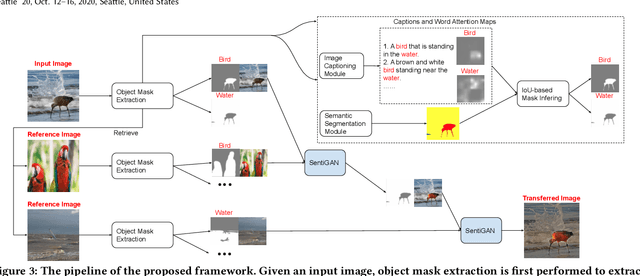
In this work, we introduce an important but still unexplored research task -- image sentiment transfer. Compared with other related tasks that have been well-studied, such as image-to-image translation and image style transfer, transferring the sentiment of an image is more challenging. Given an input image, the rule to transfer the sentiment of each contained object can be completely different, making existing approaches that perform global image transfer by a single reference image inadequate to achieve satisfactory performance. In this paper, we propose an effective and flexible framework that performs image sentiment transfer at the object level. It first detects the objects and extracts their pixel-level masks, and then performs object-level sentiment transfer guided by multiple reference images for the corresponding objects. For the core object-level sentiment transfer, we propose a novel Sentiment-aware GAN (SentiGAN). Both global image-level and local object-level supervisions are imposed to train SentiGAN. More importantly, an effective content disentanglement loss cooperating with a content alignment step is applied to better disentangle the residual sentiment-related information of the input image. Extensive quantitative and qualitative experiments are performed on the object-oriented VSO dataset we create, demonstrating the effectiveness of the proposed framework.
Region of Interest focused MRI to Synthetic CT Translation using Regression and Classification Multi-task Network
Mar 30, 2022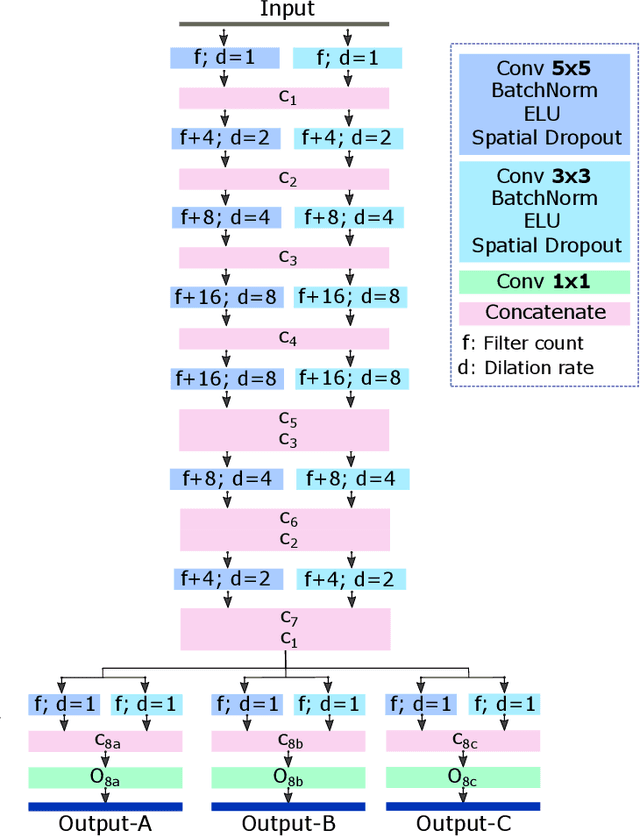
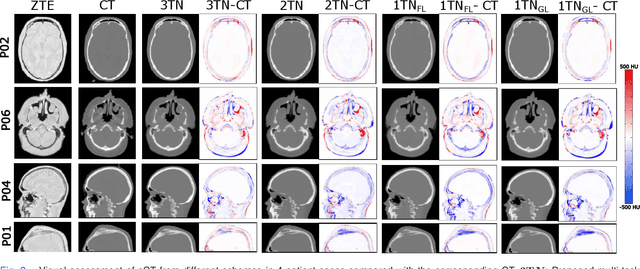
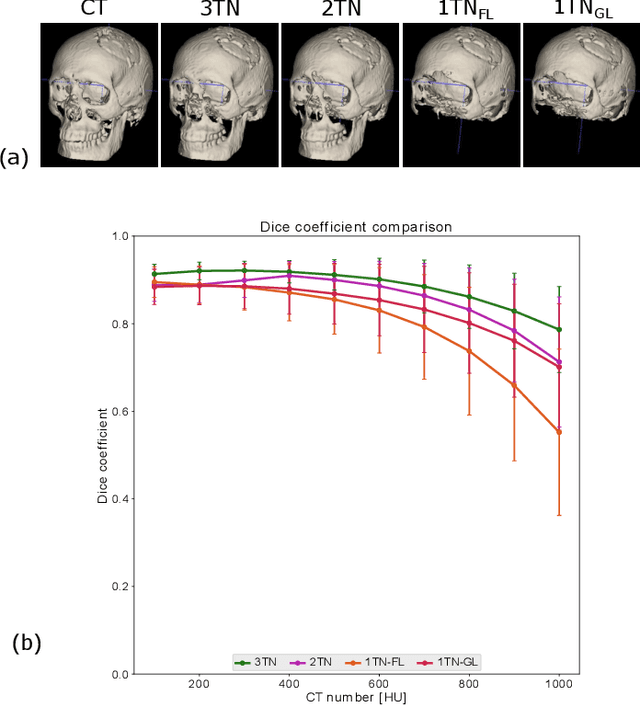
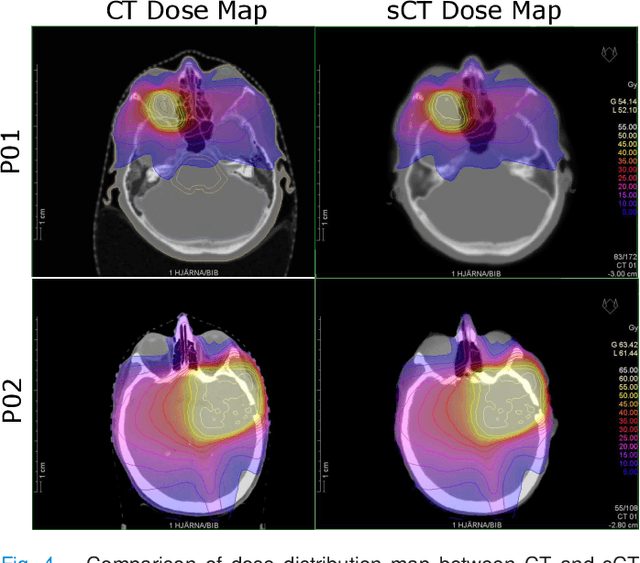
In this work, we present a method for synthetic CT (sCT) generation from zero-echo-time (ZTE) MRI aimed at structural and quantitative accuracies of the image, with a particular focus on the accurate bone density value prediction. We propose a loss function that favors a spatially sparse region in the image. We harness the ability of a multi-task network to produce correlated outputs as a framework to enable localisation of region of interest (RoI) via classification, emphasize regression of values within RoI and still retain the overall accuracy via global regression. The network is optimized by a composite loss function that combines a dedicated loss from each task. We demonstrate how the multi-task network with RoI focused loss offers an advantage over other configurations of the network to achieve higher accuracy of performance. This is relevant to sCT where failure to accurately estimate high Hounsfield Unit values of bone could lead to impaired accuracy in clinical applications. We compare the dose calculation maps from the proposed sCT and the real CT in a radiation therapy treatment planning setup.
Masked Spectrogram Modeling using Masked Autoencoders for Learning General-purpose Audio Representation
Apr 26, 2022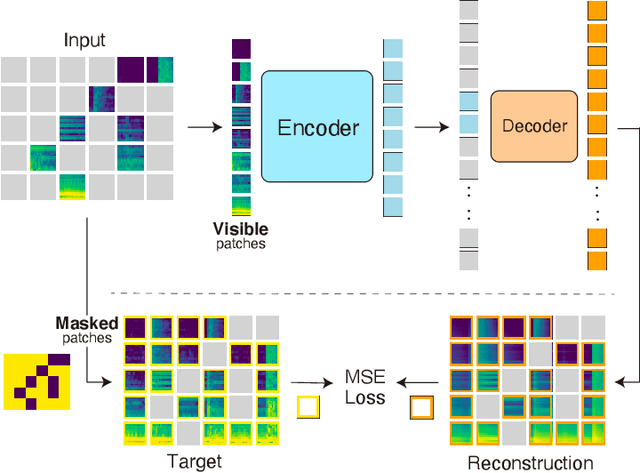
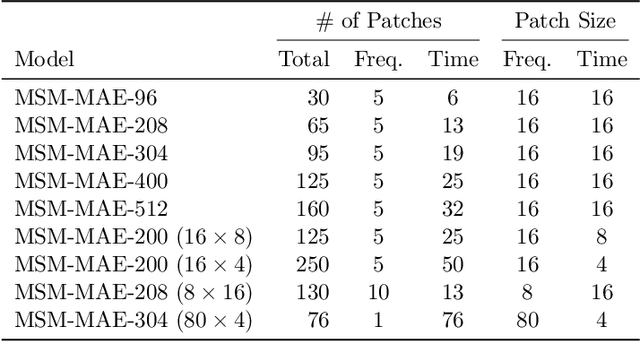
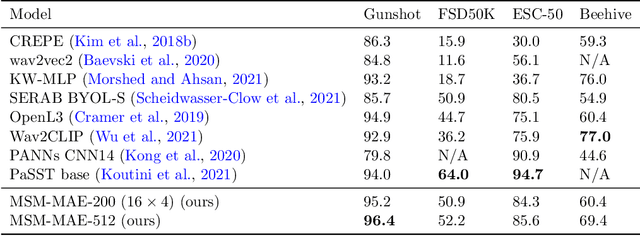
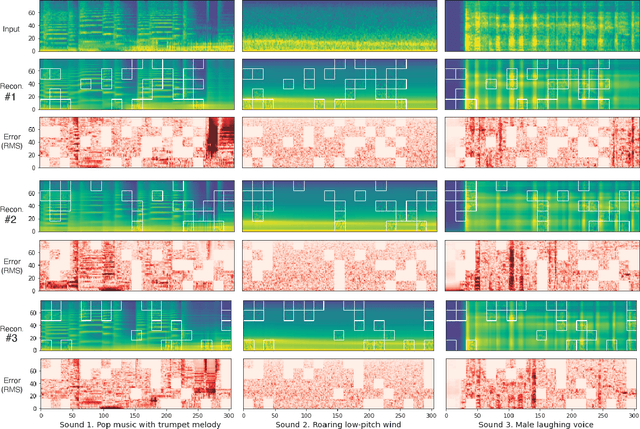
Recent general-purpose audio representations show state-of-the-art performance on various audio tasks. These representations are pre-trained by self-supervised learning methods that create training signals from the input. For example, typical audio contrastive learning uses temporal relationships among input sounds to create training signals, whereas some methods use a difference among input views created by data augmentations. However, these training signals do not provide information derived from the intact input sound, which we think is suboptimal for learning representation that describes the input as it is. In this paper, we seek to learn audio representations from the input itself as supervision using a pretext task of auto-encoding of masked spectrogram patches, Masked Spectrogram Modeling (MSM, a variant of Masked Image Modeling applied to audio spectrogram). To implement MSM, we use Masked Autoencoders (MAE), an image self-supervised learning method. MAE learns to efficiently encode the small number of visible patches into latent representations to carry essential information for reconstructing a large number of masked patches. While training, MAE minimizes the reconstruction error, which uses the input as training signal, consequently achieving our goal. We conducted experiments on our MSM using MAE (MSM-MAE) models under the evaluation benchmark of the HEAR 2021 NeurIPS Challenge. Our MSM-MAE models outperformed the HEAR 2021 Challenge results on seven out of 15 tasks (e.g., accuracies of 73.4% on CREMA-D and 85.8% on LibriCount), while showing top performance on other tasks where specialized models perform better. We also investigate how the design choices of MSM-MAE impact the performance and conduct qualitative analysis of visualization outcomes to gain an understanding of learned representations. We make our code available online.
Quantifying Visual Image Quality: A Bayesian View
Feb 22, 2021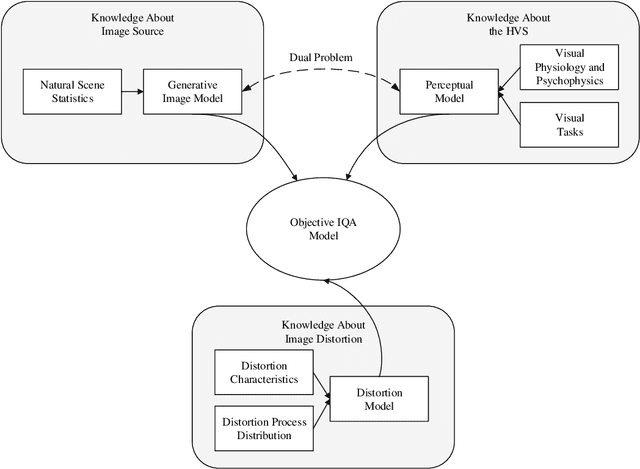
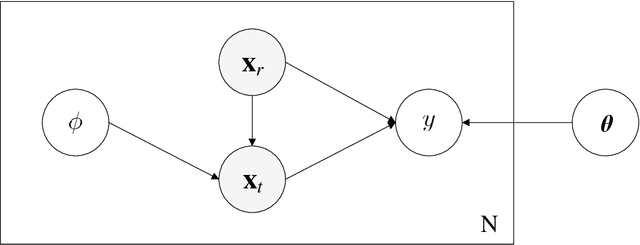


Image quality assessment (IQA) models aim to establish a quantitative relationship between visual images and their perceptual quality by human observers. IQA modeling plays a special bridging role between vision science and engineering practice, both as a test-bed for vision theories and computational biovision models, and as a powerful tool that could potentially make profound impact on a broad range of image processing, computer vision, and computer graphics applications, for design, optimization, and evaluation purposes. IQA research has enjoyed an accelerated growth in the past two decades. Here we present an overview of IQA methods from a Bayesian perspective, with the goals of unifying a wide spectrum of IQA approaches under a common framework and providing useful references to fundamental concepts accessible to vision scientists and image processing practitioners. We discuss the implications of the successes and limitations of modern IQA methods for biological vision and the prospect for vision science to inform the design of future artificial vision systems.
CD$^2$-pFed: Cyclic Distillation-guided Channel Decoupling for Model Personalization in Federated Learning
Apr 08, 2022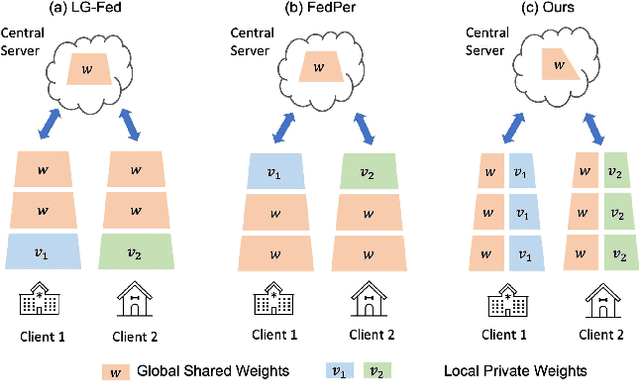
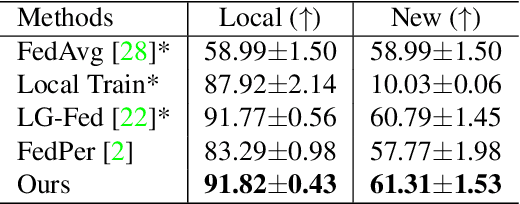
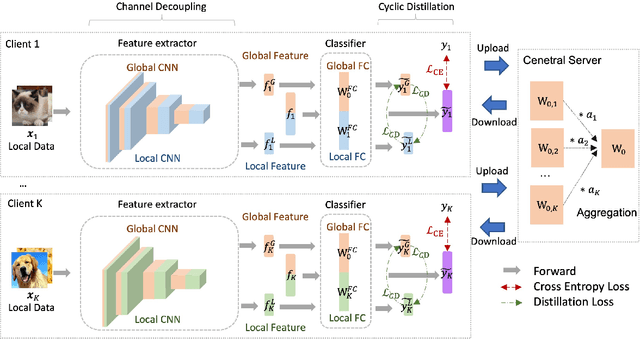
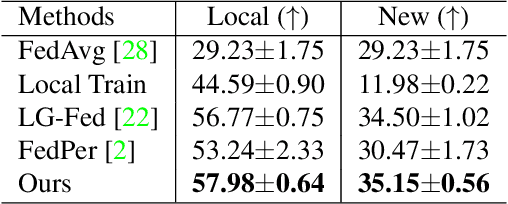
Federated learning (FL) is a distributed learning paradigm that enables multiple clients to collaboratively learn a shared global model. Despite the recent progress, it remains challenging to deal with heterogeneous data clients, as the discrepant data distributions usually prevent the global model from delivering good generalization ability on each participating client. In this paper, we propose CD^2-pFed, a novel Cyclic Distillation-guided Channel Decoupling framework, to personalize the global model in FL, under various settings of data heterogeneity. Different from previous works which establish layer-wise personalization to overcome the non-IID data across different clients, we make the first attempt at channel-wise assignment for model personalization, referred to as channel decoupling. To further facilitate the collaboration between private and shared weights, we propose a novel cyclic distillation scheme to impose a consistent regularization between the local and global model representations during the federation. Guided by the cyclical distillation, our channel decoupling framework can deliver more accurate and generalized results for different kinds of heterogeneity, such as feature skew, label distribution skew, and concept shift. Comprehensive experiments on four benchmarks, including natural image and medical image analysis tasks, demonstrate the consistent effectiveness of our method on both local and external validations.
Hardware System Implementation for Human Detection using HOG and SVM Algorithm
May 05, 2022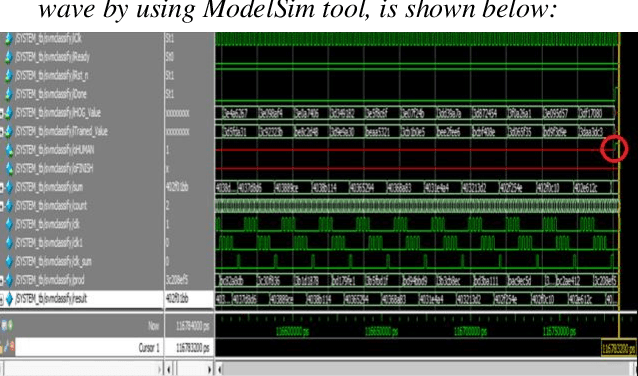
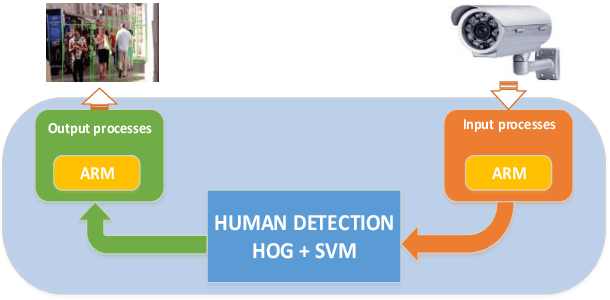


Human detection is a popular issue and has been widely used in many applications. However, including complexities in computation, leading to the human detection system implemented hardly in real-time applications. This paper presents the architecture of hardware, a human detection system that was simulated in the ModelSim tool. As a co-processor, this system was built to off-load to Central Processor Unit (CPU) and speed up the computation timing. The 130x66 RGB pixels of static input image attracted features and classify by using the Histogram of Oriented Gradient (HOG) algorithm and Support Vector Machine (SVM) algorithm, respectively. As a result, the accuracy rate of this system reaches 84.35 percent. And the timing for detection decreases to 0.757 ms at 50MHz frequency (54 times faster when this system was implemented in software by using the Matlab tool).
Give Me Your Attention: Dot-Product Attention Considered Harmful for Adversarial Patch Robustness
Mar 25, 2022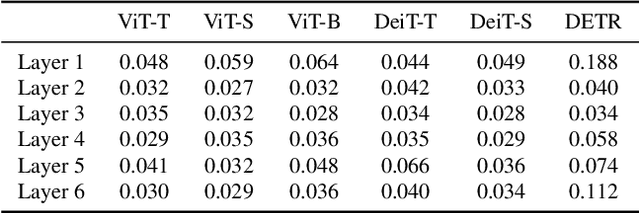
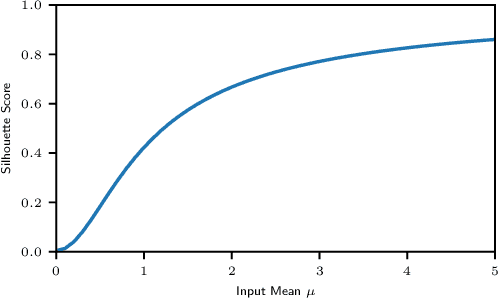
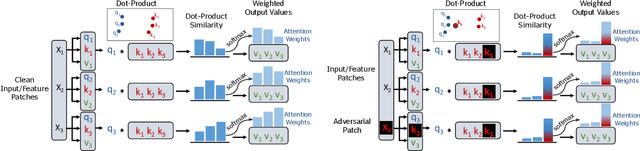
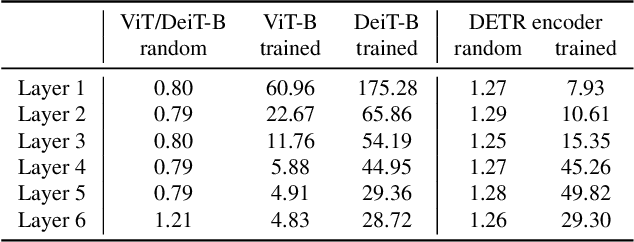
Neural architectures based on attention such as vision transformers are revolutionizing image recognition. Their main benefit is that attention allows reasoning about all parts of a scene jointly. In this paper, we show how the global reasoning of (scaled) dot-product attention can be the source of a major vulnerability when confronted with adversarial patch attacks. We provide a theoretical understanding of this vulnerability and relate it to an adversary's ability to misdirect the attention of all queries to a single key token under the control of the adversarial patch. We propose novel adversarial objectives for crafting adversarial patches which target this vulnerability explicitly. We show the effectiveness of the proposed patch attacks on popular image classification (ViTs and DeiTs) and object detection models (DETR). We find that adversarial patches occupying 0.5% of the input can lead to robust accuracies as low as 0% for ViT on ImageNet, and reduce the mAP of DETR on MS COCO to less than 3%.