 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Combining 3D Image and Tabular Data via the Dynamic Affine Feature Map Transform
Jul 13, 2021
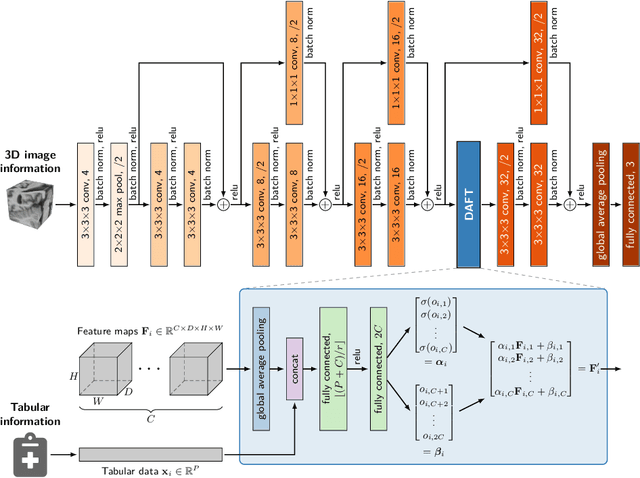

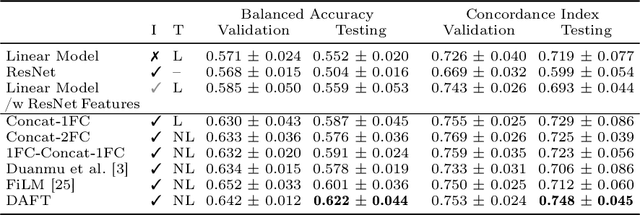
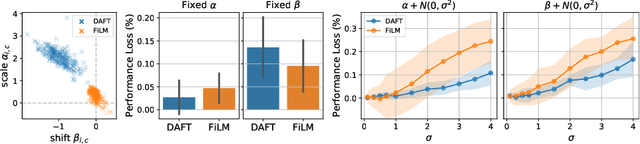
Prior work on diagnosing Alzheimer's disease from magnetic resonance images of the brain established that convolutional neural networks (CNNs) can leverage the high-dimensional image information for classifying patients. However, little research focused on how these models can utilize the usually low-dimensional tabular information, such as patient demographics or laboratory measurements. We introduce the Dynamic Affine Feature Map Transform (DAFT), a general-purpose module for CNNs that dynamically rescales and shifts the feature maps of a convolutional layer, conditional on a patient's tabular clinical information. We show that DAFT is highly effective in combining 3D image and tabular information for diagnosis and time-to-dementia prediction, where it outperforms competing CNNs with a mean balanced accuracy of 0.622 and mean c-index of 0.748, respectively. Our extensive ablation study provides valuable insights into the architectural properties of DAFT. Our implementation is available at https://github.com/ai-med/DAFT.
CNN-Augmented Visual-Inertial SLAM with Planar Constraints
May 05, 2022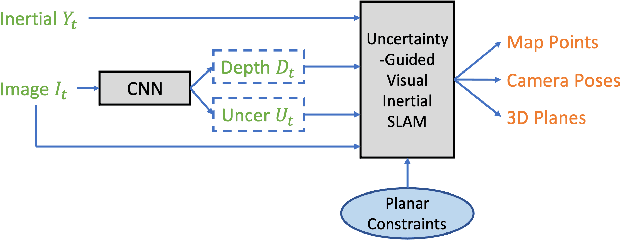
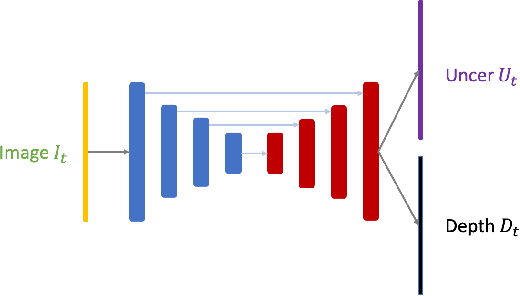

We present a robust visual-inertial SLAM system that combines the benefits of Convolutional Neural Networks (CNNs) and planar constraints. Our system leverages a CNN to predict the depth map and the corresponding uncertainty map for each image. The CNN depth effectively bootstraps the back-end optimization of SLAM and meanwhile the CNN uncertainty adaptively weighs the contribution of each feature point to the back-end optimization. Given the gravity direction from the inertial sensor, we further present a fast plane detection method that detects horizontal planes via one-point RANSAC and vertical planes via two-point RANSAC. Those stably detected planes are in turn used to regularize the back-end optimization of SLAM. We evaluate our system on a public dataset, \ie, EuRoC, and demonstrate improved results over a state-of-the-art SLAM system, \ie, ORB-SLAM3.
Boundary-aware Information Maximization for Self-supervised Medical Image Segmentation
Feb 16, 2022Unsupervised pre-training has been proven as an effective approach to boost various downstream tasks given limited labeled data. Among various methods, contrastive learning learns a discriminative representation by constructing positive and negative pairs. However, it is not trivial to build reasonable pairs for a segmentation task in an unsupervised way. In this work, we propose a novel unsupervised pre-training framework that avoids the drawback of contrastive learning. Our framework consists of two principles: unsupervised over-segmentation as a pre-train task using mutual information maximization and boundary-aware preserving learning. Experimental results on two benchmark medical segmentation datasets reveal our method's effectiveness in improving segmentation performance when few annotated images are available.
Transparency strategy-based data augmentation for BI-RADS classification of mammograms
Mar 20, 2022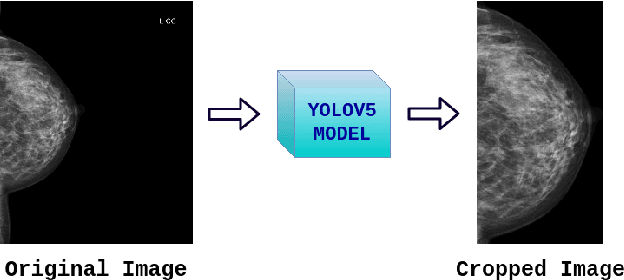

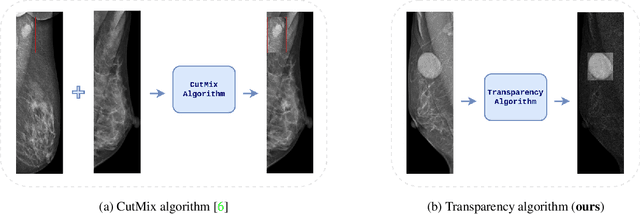
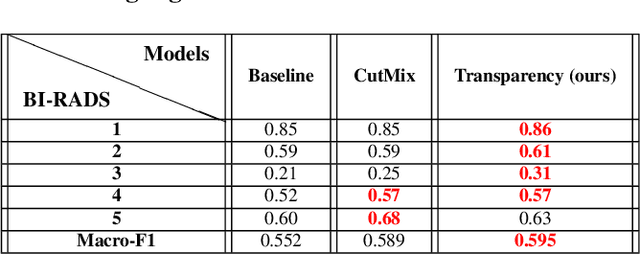
Image augmentation techniques have been widely investigated to improve the performance of deep learning (DL) algorithms on mammography classification tasks. Recent methods have proved the efficiency of image augmentation on data deficiency or data imbalance issues. In this paper, we propose a novel transparency strategy to boost the Breast Imaging Reporting and Data System (BI-RADS) scores of mammograms classifier. The proposed approach utilizes the Region of Interest (ROI) information to generate more high-risk training examples from original images. Our extensive experiments were conducted on our benchmark mammography dataset. The experiment results show that the proposed approach surpasses current state-of-the-art data augmentation techniques such as Upsampling or CutMix. The study highlights that the transparency method is more effective than other augmentation strategies for BI-RADS classification and can be widely applied for our computer vision tasks.
Analysis of Convolutional Decoder for Image Caption Generation
Mar 08, 2021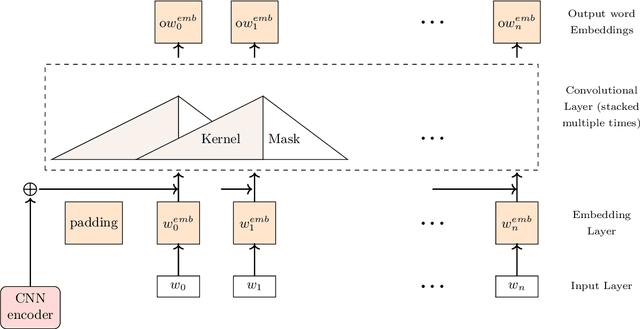

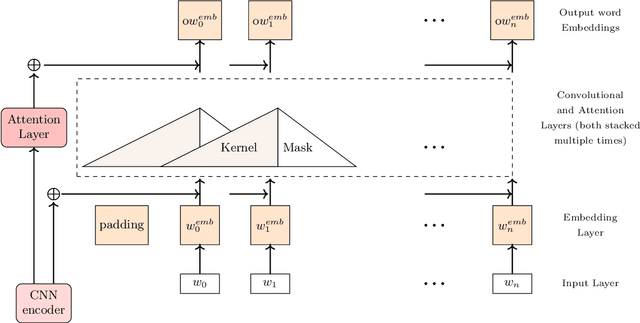
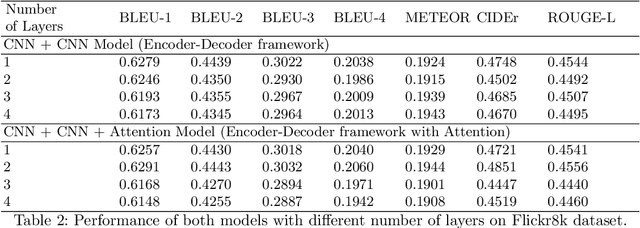
Recently Convolutional Neural Networks have been proposed for Sequence Modelling tasks such as Image Caption Generation. However, unlike Recurrent Neural Networks, the performance of Convolutional Neural Networks as Decoders for Image Caption Generation has not been extensively studied. In this work, we analyse various aspects of Convolutional Neural Network based Decoders such as Network complexity and depth, use of Data Augmentation, Attention mechanism, length of sentences used during training, etc on performance of the model. We perform experiments using Flickr8k and Flickr30k image captioning datasets and observe that unlike Recurrent Neural Network based Decoder, Convolutional Decoder for Image Captioning does not generally benefit from increase in network depth, in the form of stacked Convolutional Layers, and also the use of Data Augmentation techniques. In addition, use of Attention mechanism also provides limited performance gains with Convolutional Decoder. Furthermore, we observe that Convolutional Decoders show performance comparable with Recurrent Decoders only when trained using sentences of smaller length which contain up to 15 words but they have limitations when trained using higher sentence lengths which suggests that Convolutional Decoders may not be able to model long-term dependencies efficiently. In addition, the Convolutional Decoder usually performs poorly on CIDEr evaluation metric as compared to Recurrent Decoder.
Poly-CAM: High resolution class activation map for convolutional neural networks
May 05, 2022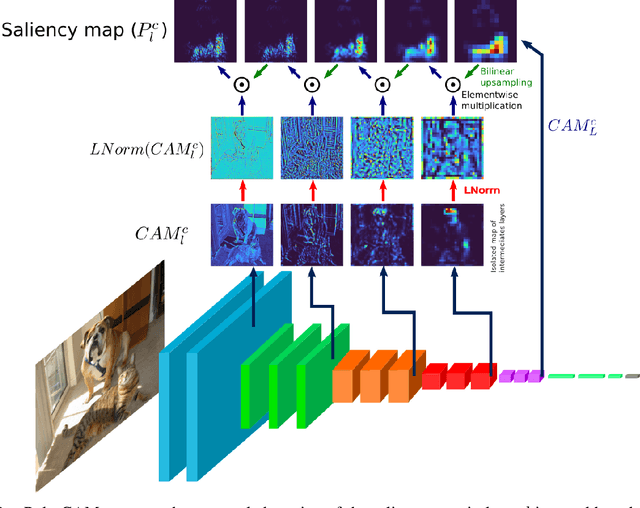
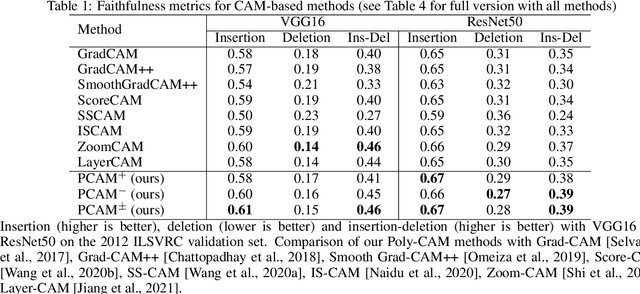

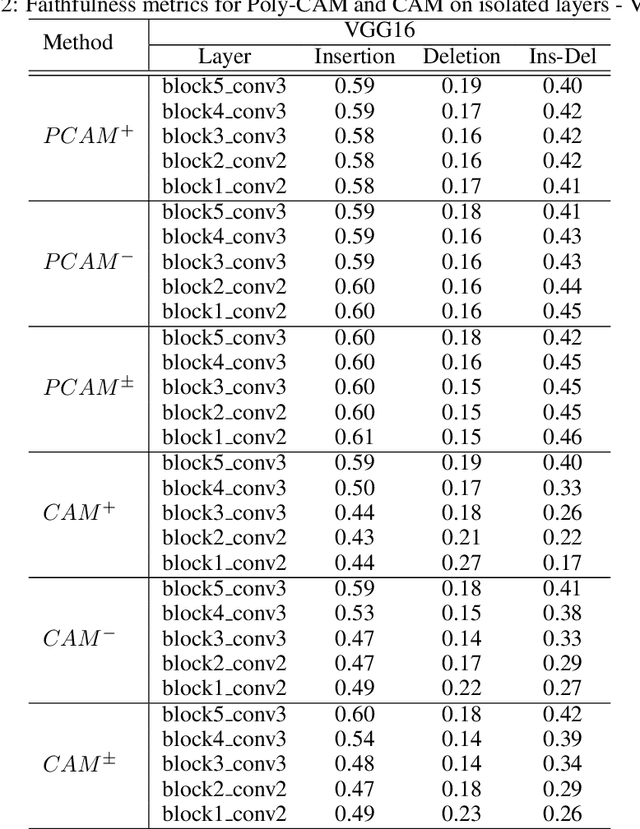
The need for Explainable AI is increasing with the development of deep learning. The saliency maps derived from convolutional neural networks generally fail in localizing with accuracy the image features justifying the network prediction. This is because those maps are either low-resolution as for CAM [Zhou et al., 2016], or smooth as for perturbation-based methods [Zeiler and Fergus, 2014], or do correspond to a large number of widespread peaky spots as for gradient-based approaches [Sundararajan et al., 2017, Smilkov et al., 2017]. In contrast, our work proposes to combine the information from earlier network layers with the one from later layers to produce a high resolution Class Activation Map that is competitive with the previous art in term of insertion-deletion faithfulness metrics, while outperforming it in term of precision of class-specific features localization.
Multimodal Deep Learning Framework for Image Popularity Prediction on Social Media
May 18, 2021
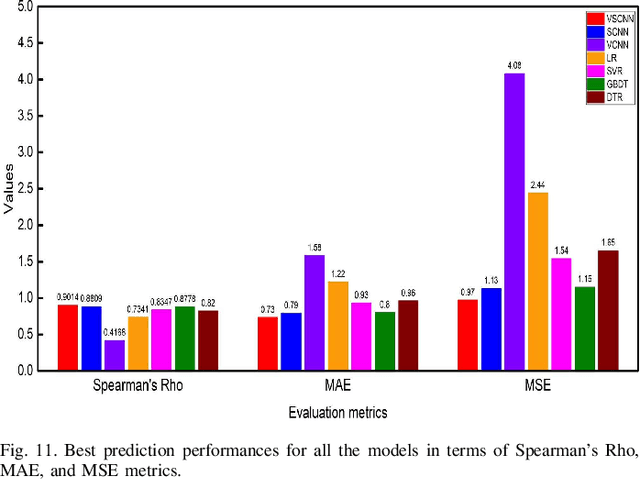
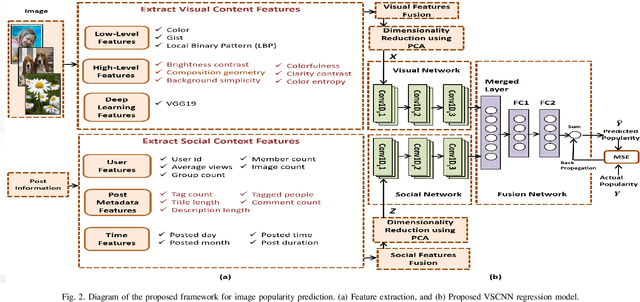
Billions of photos are uploaded to the web daily through various types of social networks. Some of these images receive millions of views and become popular, whereas others remain completely unnoticed. This raises the problem of predicting image popularity on social media. The popularity of an image can be affected by several factors, such as visual content, aesthetic quality, user, post metadata, and time. Thus, considering all these factors is essential for accurately predicting image popularity. In addition, the efficiency of the predictive model also plays a crucial role. In this study, motivated by multimodal learning, which uses information from various modalities, and the current success of convolutional neural networks (CNNs) in various fields, we propose a deep learning model, called visual-social convolutional neural network (VSCNN), which predicts the popularity of a posted image by incorporating various types of visual and social features into a unified network model. VSCNN first learns to extract high-level representations from the input visual and social features by utilizing two individual CNNs. The outputs of these two networks are then fused into a joint network to estimate the popularity score in the output layer. We assess the performance of the proposed method by conducting extensive experiments on a dataset of approximately 432K images posted on Flickr. The simulation results demonstrate that the proposed VSCNN model significantly outperforms state-of-the-art models, with a relative improvement of greater than 2.33%, 7.59%, and 14.16% in terms of Spearman's Rho, mean absolute error, and mean squared error, respectively.
* 14 pages, 11 figures, 7 tables
LINN: Lifting Inspired Invertible Neural Network for Image Denoising
May 07, 2021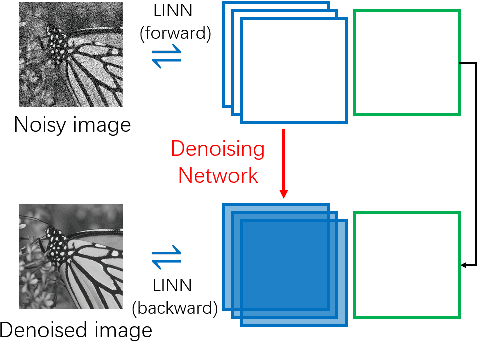
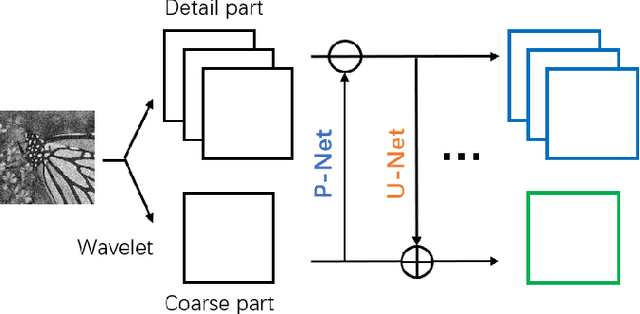
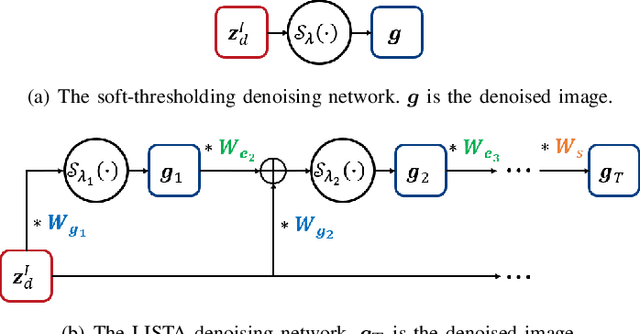

In this paper, we propose an invertible neural network for image denoising (DnINN) inspired by the transform-based denoising framework. The proposed DnINN consists of an invertible neural network called LINN whose architecture is inspired by the lifting scheme in wavelet theory and a sparsity-driven denoising network which is used to remove noise from the transform coefficients. The denoising operation is performed with a single soft-thresholding operation or with a learned iterative shrinkage thresholding network. The forward pass of LINN produces an over-complete representation which is more suitable for denoising. The denoised image is reconstructed using the backward pass of LINN using the output of the denoising network. The simulation results show that the proposed DnINN method achieves results comparable to the DnCNN method while only requiring 1/4 of learnable parameters.
Unsupervised Cross-lingual Image Captioning
Oct 03, 2020


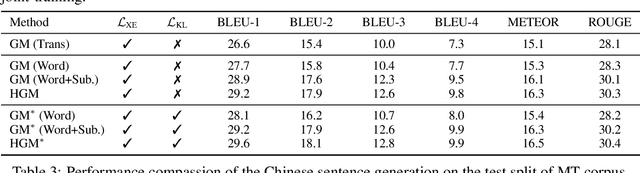
Most recent image captioning works are conducted in English as the majority of image-caption datasets are in English. However, there are a large amount of non-native English speakers worldwide. Generating image captions in different languages is worth exploring. In this paper, we present a novel unsupervised method to generate image captions without using any caption corpus. Our method relies on 1) a cross-lingual auto-encoding, which learns the scene graph mapping function along with the scene graph encoders and sentence decoders on machine translation parallel corpora, and 2) an unsupervised feature mapping, which seeks to map the encoded scene graph features from image modality to sentence modality. By leveraging cross-lingual auto-encoding, cross-modal feature mapping, and adversarial learning, our method can learn an image captioner to generate captions in different languages. We verify the effectiveness of our proposed method on the Chinese image caption generation. The comparisons against several baseline methods demonstrate the effectiveness of our approach.
A Survey of Super-Resolution in Iris Biometrics with Evaluation of Dictionary-Learning
Mar 27, 2022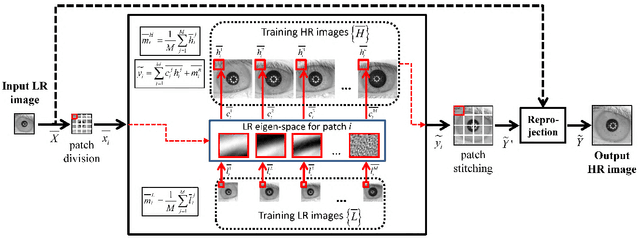
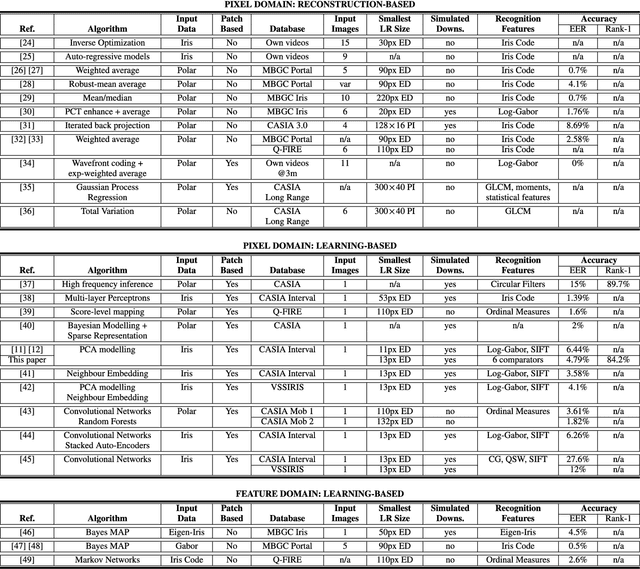
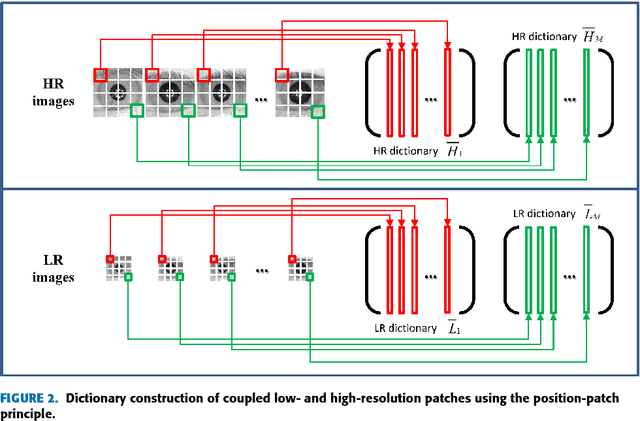

The lack of resolution has a negative impact on the performance of image-based biometrics. While many generic super-resolution methods have been proposed to restore low-resolution images, they usually aim to enhance their visual appearance. However, a visual enhancement of biometric images does not necessarily correlate with a better recognition performance. Reconstruction approaches need thus to incorporate specific information from the target biometric modality to effectively improve recognition. This paper presents a comprehensive survey of iris super-resolution approaches proposed in the literature. We have also adapted an Eigen-patches reconstruction method based on PCA Eigen-transformation of local image patches. The structure of the iris is exploited by building a patch-position dependent dictionary. In addition, image patches are restored separately, having their own reconstruction weights. This allows the solution to be locally optimized, helping to preserve local information. To evaluate the algorithm, we degraded high-resolution images from the CASIA Interval V3 database. Different restorations were considered, with 15x15 pixels being the smallest resolution. To the best of our knowledge, this is among the smallest resolutions employed in the literature. The framework is complemented with six public iris comparators, which were used to carry out biometric verification and identification experiments. Experimental results show that the proposed method significantly outperforms both bilinear and bicubic interpolation at very low-resolution. The performance of a number of comparators attains an impressive Equal Error Rate as low as 5%, and a Top-1 accuracy of 77-84% when considering iris images of only 15x15 pixels. These results clearly demonstrate the benefit of using trained super-resolution techniques to improve the quality of iris images prior to matching.